







文章目录
引用:
1. 碎片化学习之数学(二):Categorical Distribution
2. 重参数化技巧(Gumbel-Softmax)
3. max,softmax和argmax的关系
4. PyTorch 32.Gumbel-Softmax Trick
5. 为什么深度网络(vgg,resnet)最后都不使用softmax(概率归一)函数,而是直接加fc层
6. 通俗易懂地理解Gumbel Softmax
7. Gumbel-Softmax Trick和Gumbel分布
因为最近看了师姐推荐的论文里面使用了gumbel softmax,正巧虽然原来对argmax和softmax有一定认识,但是并不了解具体原理。因此特地花时间学习了一点。有一些个人理解不一定对。。
1. argmax、onehot、softmax
为了了解什么是gumbel softmax,首先要对argmax以及他对应的onehot有一个认识。
举例:[3 5 6 1 2]
argmax:求一组数里面最大值的位置。2(6在数组中下标)
onehot:可以用来表示一组数里面最大值和其他数的关系。[3 5 6 1 2] -> [3 5 6 1 2]-[6 6 6 6 6] -> [-3 -1 0 -5 -4] -> [-1 -1 0 -1 -1] -> [0 0 1 0 0 ]
softmax:可以看出输出是一个数组,且每个都是0到1之间,所有数加起来是1(如同概率)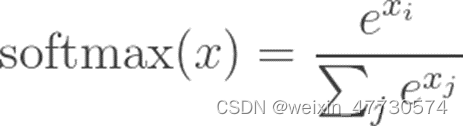
为什么神经网络里面经常出现这个东西?
一般在推理过程中,需要比较分数,这个时候往往我们需要的输出是分数最高的那个,需要argmax。(此时不是必须用softmax转化为概率,而且softmax也不改变数据之间的大小关系,只是将其映射到0~1之间)。
但是在神经网络训练学习的过程中,argmax无法实现方向梯度传播,因此需要有一个连续可导的函数代替argmax完成训练当中的一步。
- argmax、onehot、softmax之间的关系推导
引用自3. max,softmax和argmax的关系
1. Log sum exp(x)是max的平滑近似

2. softmax是onehot的平滑近似
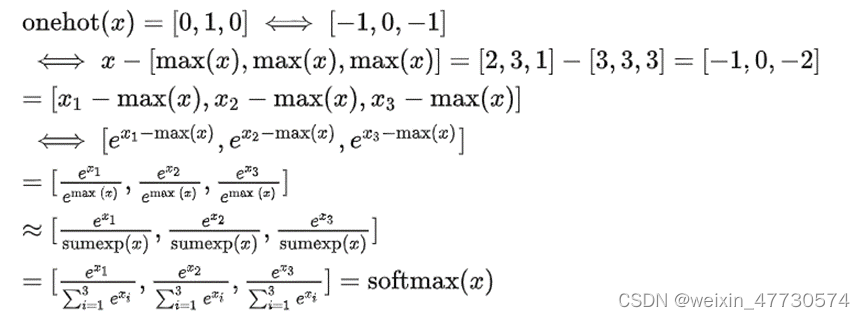
即onehot(x)约等于softmax(x)。softmax为onehot(onehot也可以看作是一组数里面最大值的体现,因此这里的onehot的1的位置对应最大值的位置)的平滑近似。具体的,可以近似log softmax(x)=onehot(+1)
3.softmax可以求出argmax

Argmax(x)=求和range(len(x))*onehot(x)=求和range(len(x))*softmax(x),输出的是最大值的位置(加权平均)。但其实很多文章将argmax的输出和onehot等同。
※在实际应用中,并未将softmax取代onehot。而是在正向传播的时候用argmax(onehot),在反向传播的时候用softmax。没有利用argmax和softmax之间的关系,而是在反向传播的时候利用softmax代替onehot。
2. softmax-random choice
(1) 解决argmax不可导
y_hard = y_hard-y+y = (y_hard-y).detach()+y,detach不参与梯度计算。
正向传输时使用了y_hard也就是argmax结果。
反向传输时只用了y,y本身是y_soft,是softmax结果,从而可导。
(2) 解决argmax缺乏探索性(即argmax是一个onehot,直接返回的一直是max的那个操作)
可以设置一个探索率eps,当随机生成的概率r小于该探索率eps时,则随机采样一个操作,否则选择概率最大的操作。
3. Gumbel 结合argmax和softmax
3.1 gumbel argmax

-
什么是gumbel分布?
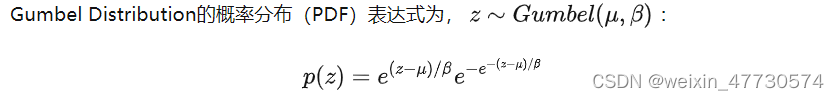
其累计概率分布(CDF)表达式为
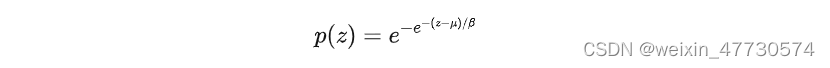
-
为什么要这样做?
为了解决argmax的探索性。引入了gumbel噪声,使argmax结果引入了变化,随机性转移至gumble噪声。
而且softmax只是一种结果看起来像概率的结果。我们需要的一种方法不仅选出动作,而且遵从概率的含义。这也解释了我们为什么要选gumbel噪声。 -
为什么选择gumbel噪声?
因为加上gumbel后能严格等价于从categorical distribution的采样结果。(即取对数后加上噪声后求最大值的操作概率还和之前未加噪声的概率一致,证明见通俗易懂地理解Gumbel Softmax,1. 碎片化学习之数学(二):Categorical Distribution)- ※ 而且gumbel分布是专门用来建模从其他分布(比如高斯分布)采样出来的极值形成的分布,而我们这里“使用argmax挑出概率最大的那个类别索引”就属于取极值的操作,所以它属于极值分布。
- 因此,对于一个取[x1,x2,…,xn]的取极值操作中,本身其就是一个从属于极值分布的操作,即p(max=x1)=p1, p(max=x2)=p2, …, p(max=xn)=pn,p1到pn都符合极值分布中对应x1,x2,…,xn位置的采样。
- 为了实现取对数加上噪声后[logx1+g1, logx2+g2, …, logxn+gn]取极值操作时,p(max=logx1+g1)=p1, p(max=logx2+g2)=p2, …, p(max=logxn+gn)=pn仍然成立,则g1, g2, …, gn需要也服从取极值操作的概率分布。(见下图,来源通俗易懂地理解Gumbel Softmax)
- 这里我们设p(max=g1)=q1, p(max=g2)=q2, …, p(max=gn)=qn。可以知道,这里q1, q2, …, qn的取值也是符合极值分布中对应g1, g2, …, gn位置的采样。
- 那么如何生成q1, q2, …, qn呢?这个采样方法实际上是很巧妙的,首先它从均匀分布U(0,1)中采样出一个随机值u作为累计概率界限。然后要采样的概率分布中从前往后不断累加起来(即累计概率),当累加的值超过随机值u时,我们就取这个累计概率对应的gi(利用累积概率分布的反函数)。
相当于我在0到1之间随机选一个累积概率,作为需要采样概率分布的目标累积概率,最终获得对应的变量gi作为采样结果。 - 那么我们利用这个方法,ui~U(0,1),利用累积概率反函数得到gi=-log(-log(ui))。

-
什么是categorical分布?
通俗点讲,就是每个类别的概率相加为1.

那么,如果我们展开式子会发现,x的随机性的确只与gi有关。
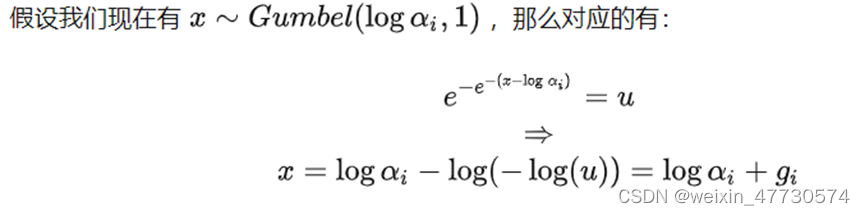


即α一般是一个指数(softmax是onehot的指数形式),如v的指数,噪声g是-log(-log(ui)),那么xi为以v为中心的gumbel分布进行采样。然后取xi的argmax得到onehot满足categorical分布。
3.2 gumbel softmax
我们吧上述结论带入softmax,将logαi看做vi,可以得到以下表达式。

当随着训练的进行,温度系数 T从大变小,从而使得计算结果更趋向于One-Hot分布,解决了前向传播和反向传播的差异性问题。如下示意图所示,当温度系数较大时,输出更接近于均匀分布;当温度系数较小时,输出更接近于One-Hot分布。
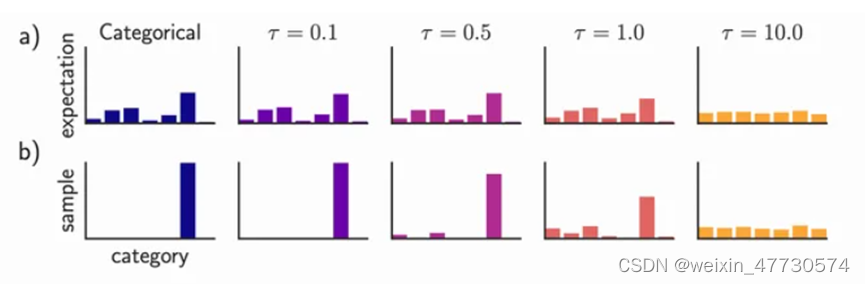
a) 不同温度系数对应的Gumbel-Softmax随机变量示意图
b) 当τ趋于0时,从Gumbel-Softmax分布中的采样和从离散分布中的采样相同
(1) 解决argmax不可导
和上面一样,使用了y_hard = y_hard-y+y = (y_hard-y).detach()+y
(2) 解决argmax缺乏探索性
引入gumble噪声。引入了变化,随机性转移至gumble噪声,解决argmax缺乏探索性。
在实际过程中,同样地,是用argmax正向传播,而gumbel softmax只是反向传播。
总结:
- argmax求最大值;
- softmax也可以获取最大值,且可导(虽然softmax拥有相加为1的特性所以很多人喜欢拿它来当作概率,但其实并不是真正的取最大值概率,其破坏了原本数据取最值的概率分布)。
- gumbel argmax可以反应实际求最大值的概率(同时照顾到了随机性),最后用argmax求最大值。
- gumbel softmax是先用gumbel方法反应实际求最大值的概率(同时照顾到了随机性),最后用softmax替代argmax求最大值,从而可导。
伪代码
0、原版 softmax:
logits = model(x)
probs = softmax(logits)
r = torch.multinomial(probs, num_samples) //按概率采样
采到的 r 都是整数 ID,后面可以用 r 去查 embedding table。缺点是采样这一步把计算图弄断了。
1、Gumbel-Max Trick:
logits = model(x)
g = sample_gumbel(x.size())
r = torch.argmax(logits + g)
采到的 r 都是整数 ID,后面可以用 r 去查 embedding table。计算图连起来了,但 argmax 仍不可导。
2、Gumbel-Softmax Trick:
logits = model(x)
g = sample_gumbel(x.size())
r = F.softmax(logits + g)
采到的 r 都是概率分布,后面可以用 r 把 embedding table 里的各个条目加权平均混合起来,假装是一个单词拿去用。虽然计算图可导了,但是训练和推断不一致!训练时模型见到的都是各个 word embedding 的混合,而非独立的 word embedding!
3、Gumbel-Softmax Trick + Straight-Though Estimator:
logits = model(x)
g = sample_gumbel(x.size())
r = F.softmax(logits + g)
r_hard = torch.argmax( r )
r = (r_hard - r).detach() + r
采到的 r 都是整数 ID,后面可以用 r 去查 embedding table
前向传播使用 r_hard 获得独立的单词,反向传播使用 r(即 softmax 的结果)的梯度。一切都很完美。
logits = model(x)
g = sample_gumbel(x.size())
r = logits + g # 注意这一行去掉了 softmax
r_hard = torch.argmax( r )
r = (r_hard - r).detach() + r
这其实也是一种 Straight-Through Estimator的实现,确实也是可导的,但应该是不如原先那个好的。Straight-Through Estimator 的意思是说,如果你遇到某一层不可导,你就当它的梯度是 identity,直接把梯度漏下去。因为 softmax 函数本身就是 argmax 的近似,所以用可导的 softmax 的梯度来代替不可导的 argmax 的梯度是更合理的。你胡乱 straight-through 那肯定是不好的。

















 1754
1754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









