







注:本文章大部分内容来自Datawhale官方教程,这里仅作笔记用于回顾。
一、背景知识
作用:为了对人类语言的内在规律进行建模,研究者们提出使用语言模型(language model)来准确预测词序列中 下一个词 或者 缺失的词 的概率。
演化过程:
-
统计语言模型(Statistical Language Model, SLM):使用马尔可夫假设(Markov Assumption)来建模语言序列的 𝑛 元(𝑛-gram)语言模型
-
神经语言模型(Neural Language Model, NLM):基于神经网络构建语言模型,如循环神经网络(Recurrent Neural Networks, RNN),并学习上下文相关的词表示(即分布式词向量),也被称为词嵌入(Word Embedding)。代表性工作:word2vec
-
预训练语言模型(Pre-trained Language Model, PLM):使用大量的无标注数据预训练双向 LSTM(Bidirectional LSTM, biLSTM)或者Transformer,然后在下游任务上进行微调(Fine-Tuning)。代表性工作:ELMo、BERT、GPT-1/2
-
大语言模型(Large Language Model, LLM):基于“扩展法则”(Scaling Law),即通过增加模型参数或训练数据,可以提升下游任务的性能,同时具有小模型不具有的“涌现能力”(Emergent Abilities)。代表性工作:GPT-3、ChatGPT、Claude、Llama

二、构建大模型
通常来说,大模型的构建过程可以分为预训练(Pretraining)、有监督微调(Supervised Fine-tuning, SFT)、基于人类反馈的强化学习对齐(Reinforcement Learning from Human Feedback, RLHF)三个阶段。接下来,我们依次介绍一下这三个阶段:
1. 预训练
预训练指使用海量的数据进行模型参数的初始学习,旨在为模型参数寻找到一个优质的“起点”。这一概念最初在计算机视觉领域萌芽,通过在ImageNet(一个大型图像数据集)上的训练,为模型参数奠定了坚实的基础。随后,这一理念被自然语言处理(NLP)领域采纳,word2vec开创先河,利用未标注文本构建词嵌入模型;ELMo、BERT及GPT-1则进一步推动了“预训练-微调”范式的普及。
起初,预训练技术专注于解决特定类别的下游任务,例如文本分类、序列标注、序列到序列生成等传统NLP任务。OpenAI在GPT-2的研究中,提出了一种创新思路——通过大规模文本数据预训练,打造能够应对广泛任务的通用解决方案,并在GPT-3中将这一理念扩展至前所未有的超大规模。
在BERT等早期预训练模型中,模型架构和训练任务呈现出多样化特征。然而,随着GPT系列模型的兴起,“解码器架构+预测下一个词”的策略证明了其卓越效能,成为了当前主流的大模型技术路线。
在预训练过程中,首要任务是搜集和清洗海量的文本数据,确保剔除潜在的有害内容。鉴于模型的知识库几乎完全源自训练数据,数据的质量与多样性对模型性能至关重要。因此,获取高质、多元的数据集,并对其进行严谨的预处理,是打造高性能语言模型的关键步骤。
当前,多数开源模型的预训练均基于数T的token。例如,Llama-1、Llama-2、Llama-3的预训练规模分别为1T、2T和15T。除了对数据量的苛刻要求,预训练阶段对计算资源的需求也极为庞大。以Llama-1的65B参数模型为例,其在2,048块A100 80GB GPU集群上进行了接近三周的训练。此外,预训练过程中还涉及诸多细节,诸如数据配比、学习率调度、模型行为监测等,这些往往缺乏公开的最佳实践指导,需要研发团队具备深厚的训练经验与故障排查能力,以规避训练过程中的回溯与重复迭代,节约计算资源,提高训练效率。
总体而言,预训练不仅是一项技术挑战,更是一场对数据质量、算力投入与研发智慧的综合考验。
2. 有监督微调
经过大规模预训练后,模型已经具备较强的模型能力,能够编码丰富的世界知识,但是由于预训练任务形式所限,这些模型更擅长于文本补全,并不适合直接解决具体的任务。
尽管引入了诸如上下文学习(In-Context Learning, ICL)等提示学习策略以增强模型的适应性,但模型本身在下游任务解决上的能力仍受限。为了克服这一局限,预训练后的大型语言模型往往需经历微调过程,以提升其在特定任务中的表现。
目前来说,比较广泛使用的微调技术是“有监督微调”(也叫做指令微调,Instruction Tuning),该方法利用成对的任务输入与预期输出数据,训练模型学会以问答的形式解答问题,从而解锁其任务解决潜能。经过指令微调后,大语言模型能够展现出较强的指令遵循能力,可以通过零样本学习的方式解决多种下游任务。
然而,值得注意的是,指令微调并非无中生有地传授新知,而是更多地扮演着催化剂的角色,激活模型内在的潜在能力,而非单纯地灌输信息。
相较于预训练所需的海量数据,指令微调所需数据量显著减少,从几十万到上百万条不等的数据,均可有效激发模型的通用任务解决能力,甚至有研究表明,少量高质量的指令数据(数千至数万条)亦能实现令人满意的微调效果。这不仅降低了对计算资源的依赖,也提升了微调的灵活性与效率。
3. 基于人类反馈的强化学习对齐
除了提升任务的解决能力外,大语言模型与人类期望、需求及价值观的对齐(Alignment)至关重要,这对于大模型的应用具有重要的意义。
OpenAI在 2022 年初发布了 InstructGPT 论文,详尽阐述了如何实现语言模型与人类对齐。论文提出了基于人类反馈的强化学习对齐(Reinforcement Learning from Human Feedback, RLHF),通过指令微调后的强化学习,提升模型的人类对齐度。RLHF的核心在于构建一个反映人类价值观的奖励模型(Reward Model)。这一模型的训练依赖于专家对模型多种输出的偏好排序,通过偏好数据训练出的奖励模型能够有效评判模型输出的质量。
目前还有很多工作试图去除复杂的强化学习算法,或其他使用 SFT 方式来达到与 RLHF 相似的效果,从而简化模型的对齐过程。例如,直接偏好优化(Direct Preference Optimization, DPO),它通过与有监督微调相似的复杂度实现模型与人类对齐,是一种典型的不需要强化学习的对齐算法。相比RLHF,DPO不再需要在训练过程中针对大模型进行采样,同时超参数的选择更加容易。
4. 例子
最后,我们以开源大模型Llama-2-Chat为例,简要介绍一下其训练过程。

整个过程起始于利用公开数据进行预训练,获得Llama-2。在此之后,通过有监督微调创建了Llama-2-Chat的初始版本。随后,使用基于人类反馈的强化学习(RLHF)方法来迭代地改进模型,具体包括拒绝采样(Rejection Sampling)和近端策略优化(Proximal Policy Optimization, PPO)。在RLHF阶段,人类偏好数据也在并行迭代,以保持奖励模型的更新。
三、开源大模型和闭源大模型
我们不难发现,构建大模型不仅需要海量的数据,更依赖于强大的计算能力,以确保模型能够快速迭代和优化,从而达到预期的性能水平。鉴于此,全球范围内能够独立承担起如此庞大计算成本的机构屈指可数。这些机构可以分为以下两大阵营:
1. 开源大模型
选择将模型开源的组织,他们秉持着促进学术交流和技术创新的理念,让全球的研究者和开发者都能受益于这些模型。通过开放模型的代码和数据集,他们加速了整个AI社区的发展,促进了创新和技术的民主化。这一阵营的代表有Meta AI、浪潮信息等。
1.1 源大模型开源体系
截止到目前,浪潮信息已经发布了三个大模型:源1.0 ,源2.0 和 源2.0-M32,其中 源1.0 开放了模型API、高质量中文数据集和代码,源2.0 和 源2.0-M32 采用全面开源策略,全系列模型参数和代码均可免费下载使用。
1.1.1 源1.0
2021年9月,源1.0大模型发布,它采用76层的Transformer Decoder结构,使用5T数据训练,拥有2457亿参数量,超越OpenAI研发的GPT-3,成为全球最大规模的AI巨量模型,表现出了出色的中文理解与创作能力。

1.1.2 源2.0
2023年11月,源2.0大模型发布,它使用10T数据训练,包括1026亿、518亿、21亿 三款参数规模,在数理逻辑、代码生成等方面表现出色。
在算法方面,与传统Attention对输入的所有文字一视同仁不同,源2.0提出了局部注意力过滤增强机制(Localized Filtering-based Attention, LFA),它假设自然语言相邻词之间有更强的语义关联,因此针对局部依赖进行了建模,最后使得模型精度提高3.53%。

1.1.3 源2.0-M32
2024年5月,源2.0-M32发布,它是一个混合专家(Mixture of Experts, MoE)大模型,使用2000B Tokens训练,包含400亿参数,37亿激活参数
源2.0-M32 包含32个专家,基于LFA+Attention Router的MoE模型结构。源2.0-M32 在数理逻辑、代码生成、知识等方面精度对标Llama3-70B,推理算力降至1/19。

1.2 LLaMA系列
LLaMA 系列模型是 Meta 开源的一组参数规模 从 7B 到 70B 的基础语言模型。LLaMA 于2023 年 2 月发布,2023 年 7 月发布了 LLaMA2 模型,并于 2024 年 4 月 18 日发布了 LLaMA3 模型。它们都是在数万亿个字符上训练的,展示了如何仅使用公开可用的数据集来训练最先进的模型,而不需要依赖专有或不可访问的数据集。这些数据集包括 Common Crawl、Wikipedia、OpenWebText2、RealNews、Books 等。LLaMA 模型使用了大规模的数据过滤和清洗技术,以提高数据质量和多样性,减少噪声和偏见。LLaMA 模型还使用了高效的数据并行和流水线并行技术,以加速模型的训练和扩展。特别地,LLaMA 13B 在 CommonsenseQA 等 9 个基准测试中超过了 GPT-3 (175B),而 LLaMA 65B 与最优秀的模型 Chinchilla-70B 和 PaLM-540B 相媲美。LLaMA 通过使用更少的字符来达到最佳性能,从而在各种推理预算下具有优势。
1.3 通义千问
通义千问由阿里巴巴基于“通义”大模型研发,于 2023 年 4 月正式发布。2023 年 9 月,阿里云开源了 Qwen(通义千问)系列工作。2024 年 2 月 5 日,开源了 Qwen1.5(Qwen2 的测试版)。并于 2024 年 6 月 6 日正式开源了 Qwen2。 Qwen2 是一个 decoder-Only 的模型,采用 SwiGLU 激活、RoPE、GQA的架构。中文能力相对来说非常不错的开源模型。
目前,已经开源了 5 种模型大小:0.5B、1.5B、7B、72B 的 Dense 模型和 57B (A14B)的 MoE 模型;所有模型均支持长度为 32768 token 的上下文。并将 Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 的上下文长度扩展至 128K token。
链接:通义官网
1.4 GLM系列
GLM 系列模型是清华大学和智谱 AI 等合作研发的语言大模型。2023 年 3 月 发布了 ChatGLM。6 月发布了 ChatGLM 2。10 月推出了 ChatGLM3。2024 年 1 月 16 日 发布了 GLM4,并于 2024 年 6 月 6 日正式开源。
GLM-4-9B-Chat 支持多轮对话的同时,还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等功能。
开源了对话模型 GLM-4-9B-Chat、基础模型 GLM-4-9B、长文本对话模型 GLM-4-9B-Chat-1M(支持 1M 上下文长度)、多模态模型GLM-4V-9B 等全面对标
链接:智谱清言
1.5 百川系列
Baichuan 是由百川智能开发的开源可商用的语言大模型。其基于Transformer 解码器架构(decoder-only)。
2023 年 6 月 15 日发布了 Baichuan-7B 和 Baichuan-13B。百川同时开源了预训练和对齐模型,预训练模型是面向开发者的“基座”,而对齐模型则面向广大需要对话功能的普通用户。
Baichuan2 于 2023年 9 月 6 日推出。发布了 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化。
2024 年 1 月 29 日 发布了 Baichuan 3。但是目前还没有开源。
链接:百小应
2. 闭源大模型
另一类则是保持模型闭源的公司,它们通常将模型作为核心竞争力,用于提供专有服务或产品,以维持商业优势。闭源模型通常伴随着专有技术和服务,企业可以通过API等方式提供给客户使用,而不直接公开模型的细节或代码。这种模式有助于保障公司的商业利益,同时也为用户提供了稳定和安全的服务。这一阵营的代表有OpenAI、百度等。
2.1 GPT系列
OpenAI 公司在 2018 年提出的 GPT(Generative Pre-Training) 模型是典型的 生成式预训练语言模型 之一。
GPT 模型的基本原则是通过语言建模将世界知识压缩到仅解码器 (decoder-only) 的 Transformer 模型中,这样它就可以恢复(或记忆)世界知识的语义,并充当通用任务求解器。它能够成功的两个关键点:
- 训练能够准确预测下一个单词的 decoder-only 的 Transformer 语言模型
- 扩展语言模型的大小
OpenAI 在 LLM 上的研究大致可以分为以下几个阶段:
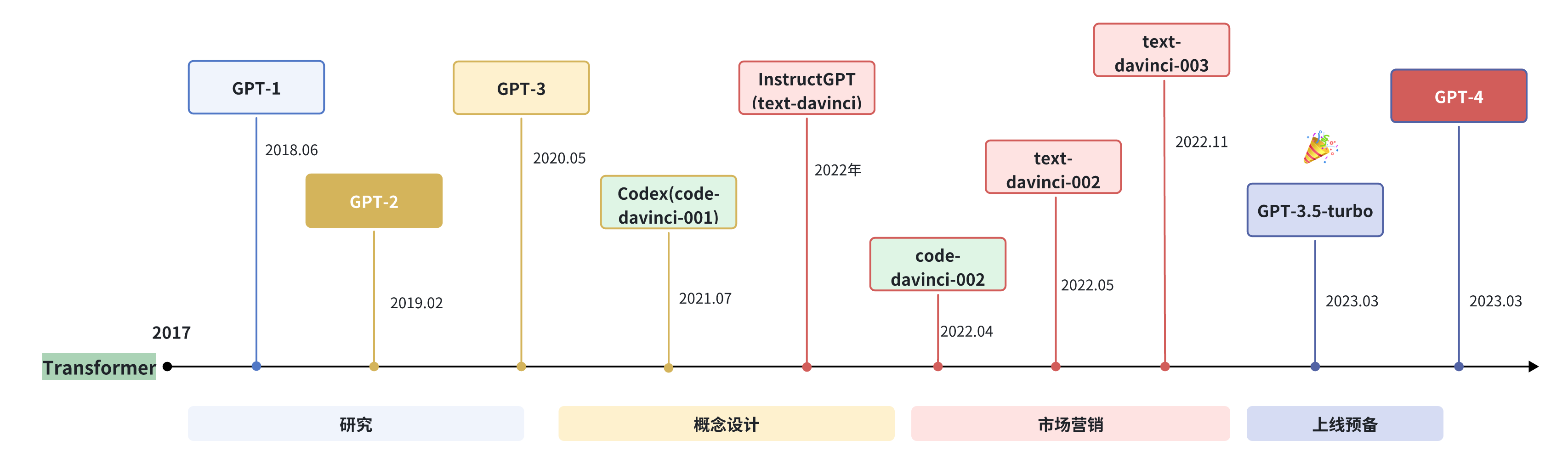
2.1.1 ChatGPT
2022 年 11 月,OpenAI 发布了基于 GPT 模型(GPT-3.5 和 GPT-4) 的会话应用 ChatGPT。由于与人类交流的出色能力,ChatGPT 自发布以来就引发了人工智能社区的兴奋。ChatGPT 是基于强大的 GPT 模型开发的,具有特别优化的会话能力。
ChatGPT 从本质上来说是一个 LLM 应用,是基于基座模型开发出来的,与基座模型有本质的区别。其支持 GPT-3.5 和 GPT-4 两个版本。
现在的 ChatGPT 支持最长达 32,000 个字符,知识截止日期是 2021 年 9 月,它可以执行各种任务,包括代码编写、数学问题求解、写作建议等。ChatGPT 在与人类交流方面表现出了卓越的能力:拥有丰富的知识储备,对数学问题进行推理的技能,在多回合对话中准确追踪上下文,并且与人类安全使用的价值观非常一致。后来,ChatGPT 支持插件机制,这进一步扩展了 ChatGPT 与现有工具或应用程序的能力。到目前为止,它似乎是人工智能历史上最强大的聊天机器人。ChatGPT 的推出对未来的人工智能研究具有重大影响,它为探索类人人工智能系统提供了启示。
2.1.2 GPT-4
2023 年 3 月发布的 GPT-4,它将文本输入扩展到多模态信号。GPT3.5 拥有 1750 亿 个参数,而 GPT4 的参数量官方并没有公布,但有相关人员猜测,GPT-4 在 120 层中总共包含了 1.8 万亿参数,也就是说,GPT-4 的规模是 GPT-3 的 10 倍以上。因此,GPT-4 比 GPT-3.5 解决复杂任务的能力更强,在许多评估任务上表现出较大的性能提升。
最近的一项研究通过对人为生成的问题进行定性测试来研究 GPT-4 的能力,这些问题包含了各种各样的困难任务,并表明 GPT-4 可以比之前的 GPT 模型(如 GPT3.5 )实现更优越的性能。此外,由于六个月的迭代校准(在 RLHF 训练中有额外的安全奖励信号),GPT-4 对恶意或挑衅性查询的响应更安全,并应用了一些干预策略来缓解 LLM 可能出现的问题,如幻觉、隐私和过度依赖。
2.1.3 GPT-4o
2024 年 5 月 14 日,新一代旗舰生成模型 GPT-4o 正式发布。GPT-4o 具备了对文本、语音、图像三种模态的深度理解能力,反应迅速且富有情感色彩,极具人性化。而且 GPT-4o 是完全免费的,虽然每天的免费使用次数是有限的。
2.2 Claude系列
Claude 系列模型是由 OpenAI 离职人员创建的 Anthropic 公司开发的闭源语言大模型。
链接:App unavailable \ Anthropic
最早的 Claude 于 2023 年 3 月 15 日发布,在 2023 年 7 月 11 日,更新至 Claude-2, 并在 2024 年 3 月 4 日更新至 Claude-3。
Claude 3 系列包括三个不同的模型,分别是 Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus,它们的能力依次递增,旨在满足不同用户和应用场景的需求。
2.3 PaLM/Gemini系列
PaLM 系列语言大模型由 Google 开发。其初始版本于 2022 年 4 月发布,并在 2023 年 3 月公开了 API。2023 年 5 月,Google 发布了 PaLM 2,2024 年 2 月 1 日,Google 将 Bard(之前发布的对话应用) 的底层大模型驱动由 PaLM2 更改为 Gemini,同时也将原先的 Bard 更名为 Gemini。
链接:https://ai.google/discover/palm2/
目前的 Gemini 是第一个版本,即 Gemini 1.0,根据参数量不同分为 Ultra, Pro 和 Nano 三个版本。
2.4 文心一言
文心一言是基于百度文心大模型的知识增强语言大模型,于 2023 年 3 月在国内率先开启邀测。文心一言的基础模型文心大模型于 2019 年发布 1.0 版,现已更新到 4.0 版本。更进一步划分,文心大模型包括 NLP 大模型、CV 大模型、跨模态大模型、生物计算大模型、行业大模型。中文能力相对来说非常不错的闭源模型。
链接:文心一言
2.5 星火大模型
讯飞星火认知大模型是科大讯飞发布的语言大模型,支持多种自然语言处理任务。该模型于 2023 年 5 月首次发布,后续经过多次升级。2023 年 10 月,讯飞发布了讯飞星火认知大模型 V3.0。2024 年 1 月,讯飞发布了讯飞星火认知大模型 V3.5,在语言理解,文本生成,知识问答等七个方面进行了升级,并且支持 system 指令,插件调用等多项功能。
四、大模型时代挖掘模型能力的开发范式
进入大模型时代,人工智能领域的边界正以前所未有的速度扩展,而如何充分挖掘大模型的内在潜能,成为了应用开发者面前的一道关键课题。
在这一背景下,不同的应用场景催生了多样化的应用开发策略,这些策略不仅展现了大模型应用开发的丰富可能性,也预示着未来AI技术在各行业落地的广阔前景。
1. Prompt工程
Prompt工程(Prompt Engineering)是指通过精心构造提示(Prompt),直接调教大模型,解决实际问题。
为了更充分地挖掘大模型的潜能,出现了以下两种技术:
-
上下文学习(In-Context Learning, ICL):将任务说明及示例融入提示文本之中,利用模型自身的归纳能力,无需额外训练即可完成新任务的学习。
-
思维链提示(Chain-of-Thought, CoT):引入连贯的逻辑推理链条至提示信息内,显著增强了模型处理复杂问题时的解析深度与广度。
2. Embedding辅助
尽管大模型具有非常出色的能力,然而在实际应用场景中,仍然会出现大模型无法满足我们需求的情况,主要有以下几方面原因:
-
知识局限性:大模型的知识来源于训练数据,而这些数据主要来自于互联网上已经公开的资源,对于一些实时性的或者非公开的,由于大模型没有获取到相关数据,这部分知识也就无法被掌握。
-
数据安全性:为了使得大模型能够具备相应的知识,就需要将数据纳入到训练集进行训练。然而,对于企业来说,数据的安全性至关重要,任何形式的数据泄露都可能对企业构成致命的威胁。
-
大模型幻觉:由于大模型是基于概率统计进行构建的,其输出本质上是一系列数值运算。因此,有时会出现模型“一本正经地胡说八道”的情况,尤其是在大模型不具备的知识或不擅长的场景中。
因此,将知识提前转成Embedding向量,存入知识库,然后通过检索将知识作为背景信息,这样就相当于给LLM外接大脑,使大模型能够运用这些外部知识,生成准确且符合上下文的答案,同时能够减少模型幻觉的出现。
3. 参数高效微调
在实际应用场景中,大模型还会经常出现以下问题:
-
大模型在当前任务上能力不佳,如果提升其能力?
-
另外,怎么使大模型学习其本身不具备的能力呢?
这些问题的答案是模型微调。
模型微调也被称为指令微调(Instruction Tuning)或者有监督微调(Supervised Fine-tuning, SFT),首先需要构建指令训练数据,然后通过有监督的方式对大模型的参数进行微调。经过模型微调后,大模型能够更好地遵循和执行人类指令,进而完成下游任务。
然而,由于大模型的参数量巨大, 进行全量参数微调需要消耗非常多的算力。为了解决这一问题,研究者提出了参数高效微调(Parameter-efficient Fine-tuning),也称为轻量化微调 (Lightweight Fine-tuning),这些方法通过训练极少的模型参数,同时保证微调后的模型表现可以与全量微调相媲美。
五、大模型应用开发基础知识
通常,一个完整的大模型应用包含一个客户端和一个服务端。
客户端接收到用户请求后,将请求输入到服务端,服务端经过计算得到输出后,返回给客户端回复用户的请求。

1. 客户端
在大模型应用中,客户端需要接受用户请求,并且能将回复返回给用户。
目前,客户端通常使用 Gradio 和 Streamlit 进行开发。
1.1 Gradio
Gradio 有输入输出组件、控制组件、布局组件几个基础模块,其中
-
输入输出组件用于展示内容和获取内容,如:
Textbox文本、Image图像 -
布局组件用于更好地规划组件的布局,如:
Column(把组件放成一列)、Row(把组件放成一行)-
推荐使用
gradio.Blocks()做更多丰富交互的界面,gradio.Interface()只支持单个函数交互
-
-
控制组件用于直接调用函数,无法作为输入输出使用,如:
Button(按钮)、ClearButton(清除按钮)
Gradio的设计哲学是将输入和输出组件与布局组件分开。输入组件(如
Textbox、Slider等)用于接收用户输入,输出组件(如Label、Image等)用于显示函数的输出结果。而布局组件(如Tabs、Columns、Row等)则用于组织和排列这些输入和输出组件,以创建结构化的用户界面。
如果想了解更多组件详情,可查看 官方文档;
另外,如果想设计更复杂的界面风格,还可以查看学习 官方文档:主题
1.2 Streamlit
Streamlit 中没有gradio的输入和输出概念,也没有布局组件的概念。
Streamlit每个组件都是独立的,需要用什么直接查看官方文档即可,大致有如下几种组件:
-
页面元素
-
文本
-
数据表格
-
图标绘制(柱状图,散点图等等)
-
输入(文本框,按钮,下拉框,滑块,复选框,文件上传,等等)
-
多媒体(图片,音频,视频)
-
布局和容器
-
Chat(聊天对话控件)
-
状态(进度条,加载中,等等元素)
-
第三方组件(提供了更加丰富的组件)
-
-
应用逻辑
-
导航和页面(可以切换页面)
-
执行流程
-
缓存和状态
-
连接和加密(可连接数据库,也可以对内容进行加密处理)
-
自定义组件
-
公共组件(用户信息存储,帮助,以及输出html)
-
Config(使用配置文件,来定义一些内容)
-
-
工具
-
应用测试
-
命令行
-
2. 服务端
在大模型应用中,服务端需要与大模型进行交互,大模型接受到用户请求后,经过复杂的计算,得到模型输出。
目前,服务端主要有以下两种方式:
1.1 直接调用大模型API:
将请求直接发送给相应的服务商,如openai,讯飞星火等,等待API返回大模型回复
✔️ 优点:
-
便捷性: 不需要关心模型的维护和更新,服务商通常会负责这些工作。
-
资源效率: 避免了本地硬件投资和维护成本,按需付费,灵活调整成本支出。
-
稳定性与安全性: 专业团队管理,可能提供更好的系统稳定性和数据安全性措施。
-
扩展性: API服务易于集成到现有的应用和服务中,支持高并发请求。
✖️ 缺点:
-
网络延迟: 需要稳定的网络连接,可能会受到网络延迟的影响。
-
数据隐私: 数据需要传输到服务商的服务器,可能涉及数据安全和隐私问题。
-
成本控制: 高频次或大量数据的调用可能会导致较高的费用。
-
依赖性: 受制于服务商的政策变化,如价格调整、服务条款变更等。
1.2 大模型本地部署
在本地GPU或者CPU上,下载模型文件,并基于推理框架进行部署大模型
✔️ 优点:
-
数据主权: 数据完全在本地处理,对于敏感数据处理更为安全。
-
性能可控: 可以根据需求优化配置,减少网络延迟,提高响应速度。
-
成本固定: 初始投入后,长期运行成本相对固定,避免了按使用量付费的不确定性。
-
定制化: 更容易针对特定需求进行模型微调或扩展。
✖️ 缺点:
-
硬件投资: 需要强大的计算资源,如高性能GPU,初期投资成本较高。
-
运维复杂: 需要自行管理模型的更新、维护和故障排查。
-
技术门槛: 对于非专业团队而言,模型的部署和优化可能较为复杂。
-
资源利用率: 在低负载情况下,本地硬件资源可能无法充分利用。
综上,选择哪种方式取决于具体的应用场景、数据敏感性、预算以及对延迟和性能的需求。

















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









