







 本文深入探讨了子空间学习中的两种重要降维方法——主成分分析(PCA)和线性判别分析(LDA)。PCA通过最大化数据的新表征方差来降维,而LDA则是有监督的降维方法,旨在最大化类间方差同时最小化类内方差。两者都在样本空间中定义新坐标系,但LDA考虑了类别信息,适用于分类任务。PCA和LDA都可以通过特征值分解解决,但LDA对数据分布有更强的假设。
本文深入探讨了子空间学习中的两种重要降维方法——主成分分析(PCA)和线性判别分析(LDA)。PCA通过最大化数据的新表征方差来降维,而LDA则是有监督的降维方法,旨在最大化类间方差同时最小化类内方差。两者都在样本空间中定义新坐标系,但LDA考虑了类别信息,适用于分类任务。PCA和LDA都可以通过特征值分解解决,但LDA对数据分布有更强的假设。
1. 引入:子空间学习与降维
什么是子空间学习?
- 子空间学习大意是指通过投影,实现高维特征向低维空间的映射,是一种经典的降维思想。绝大多数的维数约简(降维,投影)算法都算是子空间学习,如PCA、LDA、LPP、LLE等;
- 本文只介绍前两种维数约减算法,即主成分分析(PCA)和线性判别分析(LDA)。
什么是降维?什么情况下需要降维?
- 降维:寻找一组映射对样本进行重新表示(representation);
- 原样本: x = [ x 1 ; x 2 ; . . . ; x d ] ∈ R d x=[x_1;x_2;...;x_d]∈\mathbb{R}^d x=[x1;x2;...;xd]∈Rd;新表示: y = [ y 1 ; y 2 ; . . . ; y m ] ∈ R m ( m < d ) y=[y_1;y_2;...;y_m]∈\mathbb{R}^m(m<d) y=[y1;y2;...;ym]∈Rm(m<d);降维目标:学习映射 ϕ ( x ) = y \phi(x)=y ϕ(x)=y;
- 我们知道,样本空间是由样本的各个属性张成的空间,假设每个样本有 d d d个属性,则样本空间就是一个 d d d维空间, d d d维空间中的每个点就是一个样本的表示(representation);
- 降维就是学习一个从原样本空间到新样本空间(子空间,即维度小于 d d d,假设为 m m m维)的映射,使得新样本空间中每个点是一个样本的新的表示,也就是说,每个样本的表示从 d d d维向量简化为了 m m m维向量,这显然是一件好事。
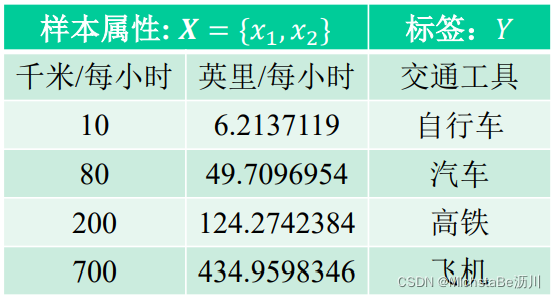
需要降维的情况:如数据冗余。下图中前两列表达的是同一个意思,造成了数据冗余,对此,应当进行降维。
数据冗余的弊端?维度灾难!
- 增加计算机开销(存储空间、计算资源);
- 采样困难。
2. 主成分分析(PCA)
假设:映射 ϕ ( ⋅ ) \phi(·) ϕ(⋅)是线性映射,线性映射的实质就是定义了一个新坐标。
ϕ ( ⋅ ) : W T x = y ∈ R m , W = [ w 1 , w 2 , . . . , w m ] ∈ R d × m \phi(·):W^Tx=y∈\mathbb{R}^m,W=[w_1,w_2,...,w_m]∈\mathbb{R}^{d×m} ϕ(⋅):WTx=y∈Rm,W=[w1,w2,...,wm]∈Rd×m
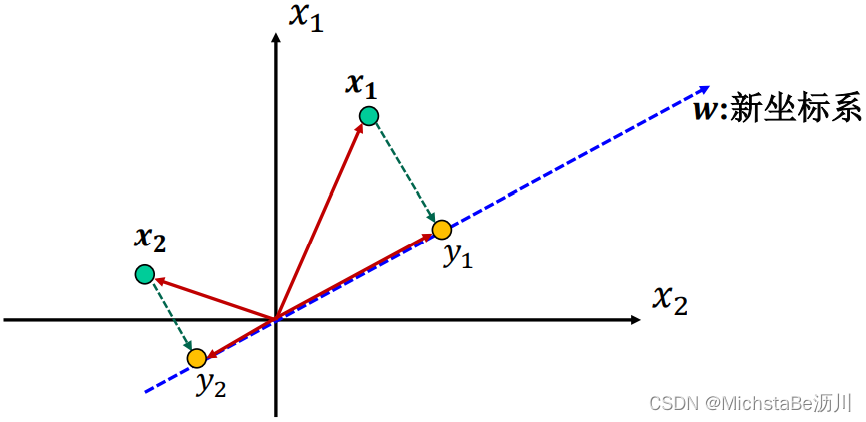
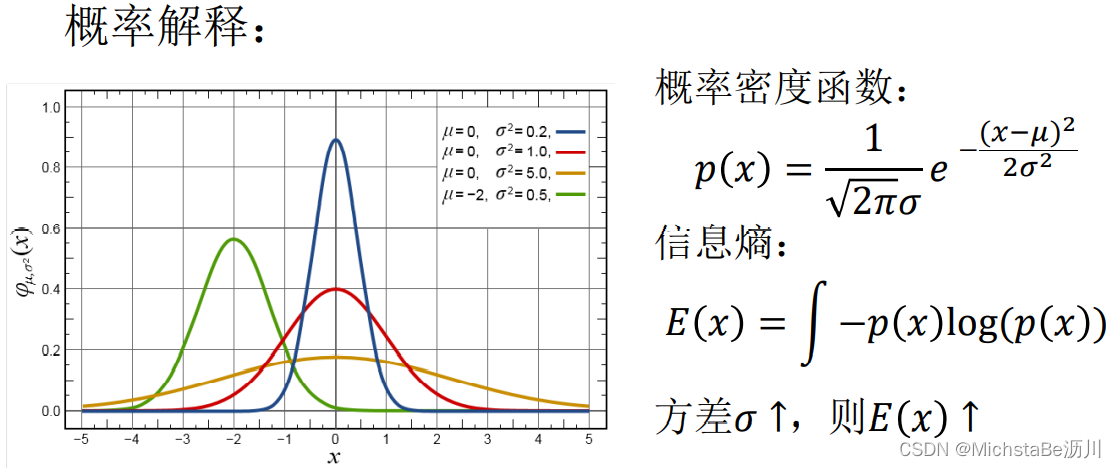
最大方差理论: 在信号处理中认为信号具有较大的方差,噪声有较小的方差。 即新坐标系上数据方差应越大越好。
2.1 目标函数
在新坐标系下最大化数据新表征的方差: max w ∑ i = 1 n ( y i − y ˉ ) 2 , \max\limits_w\sum\limits_{i=1}^n(y_i-\bar{y})^2, wmaxi=1∑n(yi−yˉ)2, s.t. y i = w T x i , ∣ ∣ w ∣ ∣ = 1. \text{s.t.}\quad y_i=w^Tx_i,||w||=1. s.t.yi=wTxi,∣∣w∣∣=1.第二个约束条件是为了坐标系标准化。矩阵化表示: max W ∑ i = 1 n ∣ ∣ y i − y ˉ ∣ ∣ 2 , \max\limits_W\sum\limits_{i=1}^n||y_i-\bar{y}||^2, Wmaxi=1∑n∣∣yi−yˉ∣∣2, s.t. y i = W T x i , W T W = I . \text{s.t.}\quad y_i=W^Tx_i,W^TW=I. s.t.yi=WTxi,WTW=I.其中 W = [ w 1 , . . . , w m ] ∈ R d × m W=[w_1,...,w_m]∈\mathbb{R}^{d×m} W=[w1,...,wm]∈Rd×m,第二个约束条件保证坐标系为标准正交坐标系,也可表示为 ∣ ∣ w i ∣ ∣ = 1 , w i T w j = 0 ||w_i||=1,w_i^Tw_j=0 ∣∣wi∣∣=1,wiTwj=0。PCA降维的过程可以通过数据乘以矩阵来表示,因此是一个线性变换。
- 原样本: x = [ x 1 ; x 2 ; . . . ; x d ] ∈ R d x=[x_1;x_2;...;x_d]∈\mathbb{R}^d x=[x1;x2;...;xd]∈Rd
- 新表示: y = [ y 1 ; y 2 ; . . . ; y m ] ∈ R m ( m < d ) y=[y_1;y_2;...;y_m]∈\mathbb{R}^m(m<d) y=[y1;y2;...;ym]∈Rm(m<d)
PCA的目标函数推导: f ( W ) = ∑ i = 1 n ∣ ∣ y i − y ˉ ∣ ∣ 2 = ∑ i = 1 n ( y i − y ˉ ) T ( y i − y ˉ ) = ∑ i = 1 n t r ( ( y i − y ˉ ) ( y i − y ˉ ) T ) f(W)=\sum\limits_{i=1}^n||y_i-\bar{y}||^2=\sum\limits_{i=1}^n(y_i-\bar{y})^T(y_i-\bar{y})=\sum\limits_{i=1}^ntr((y_i-\bar{y})(y_i-\bar{y})^T) f(W)=i=1∑n∣∣yi−yˉ∣∣2=i=1∑n(yi−yˉ)T(yi−yˉ)=i=1∑ntr((y
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2269
2269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









