








论文链接:https://arxiv.org/pdf/2311.13240.pdf
注:本notes不介绍calibration相关的基础知识,如有兴趣请自行阅读相关文献~
1 Introduction
- Calibration在早期气象学中被称为validity或reliability,以表示forecasters的可信度;
- Calibration的意义
- 可解释性:用户能够知道模型的可靠程度,并由此决定是否相信这一预测;
- 减少幻觉:https://arxiv.org/pdf/2103.15025.pdf,https://arxiv.org/pdf/1910.08684.pdf;
2 Calibration Evaluation Tasks and Data
- Causal language modeling (CLM),给定序列预测下一个token;使用PILE数据集的训练集和测试集,测试时在测试序列中随机采样一个位置进行生成;
- Facts generation (FG),用于评估模型对事实知识的记忆能力,即factuality;使用T-REx实体链接数据集,测试时让模型生成实体的第一个token;
- Multi-task language understanding (MLU),用于评估模型的understanding和reasoning能力;使用MMLU基准,测试时为模型提供5个in-context samples,以多选问答的方式进行评估。
3 Calibration in Pre-training Stage
- Base model:Pythia 70M-12B(共8个模型),训练数据为PILE,每1000个训练步(1个epoch)存1个checkpoint,共143个,1000步以内存了11个checkpoints,因此共有154个checkpoints;
- 参数量实验使用所有8个模型,训练步实验使用Pythia 1B4, 2 n × 1000 2^n\times1000 2n×1000步的checkpoints,以及256和512步的checkpoints来观察欠拟合模型。
Parameter Scales
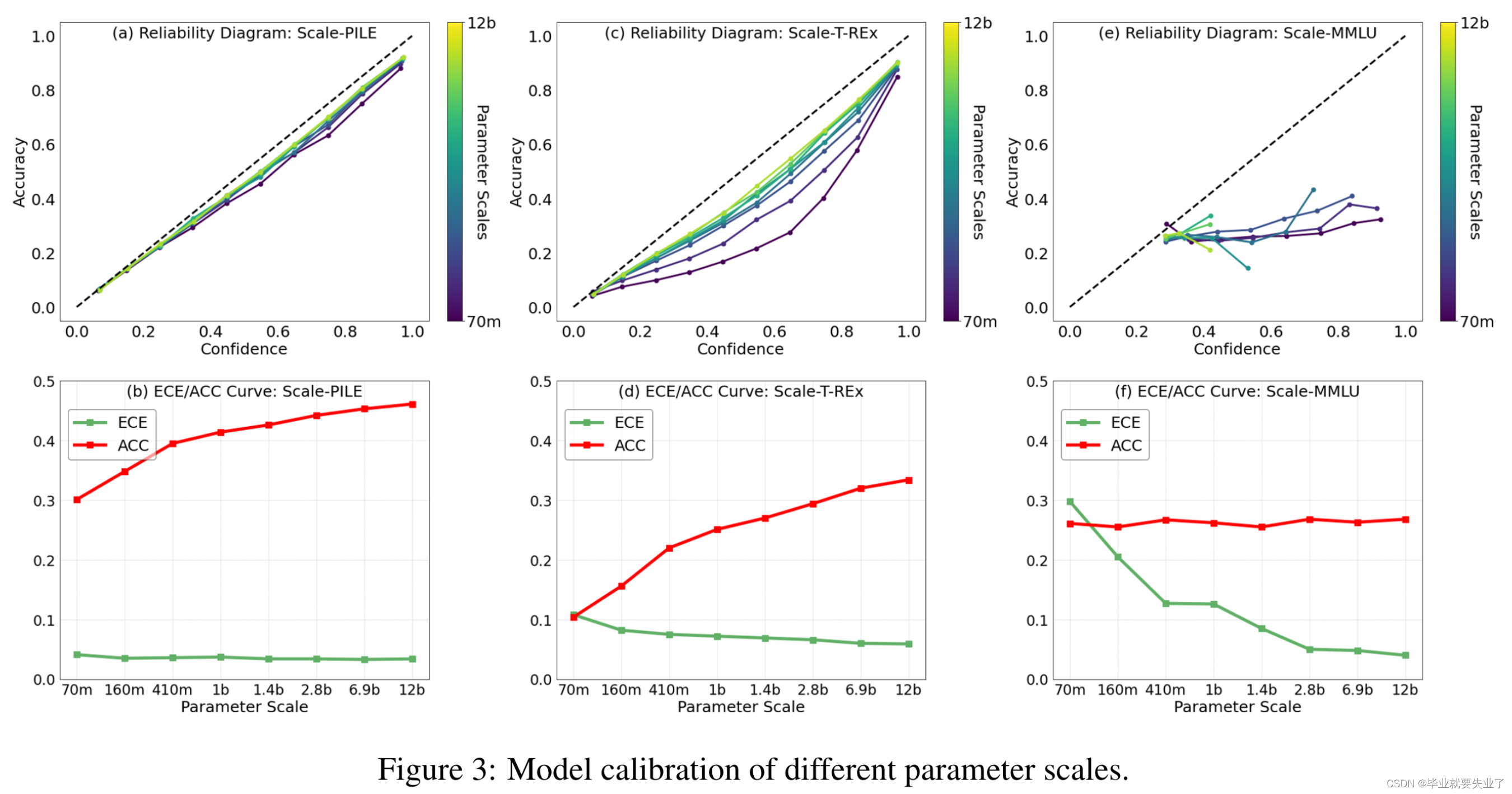
一个比较有意思的发现是,当参数量增大,confidence distribution倾向于坍缩到一个很小的区间内。
Training Dynamics

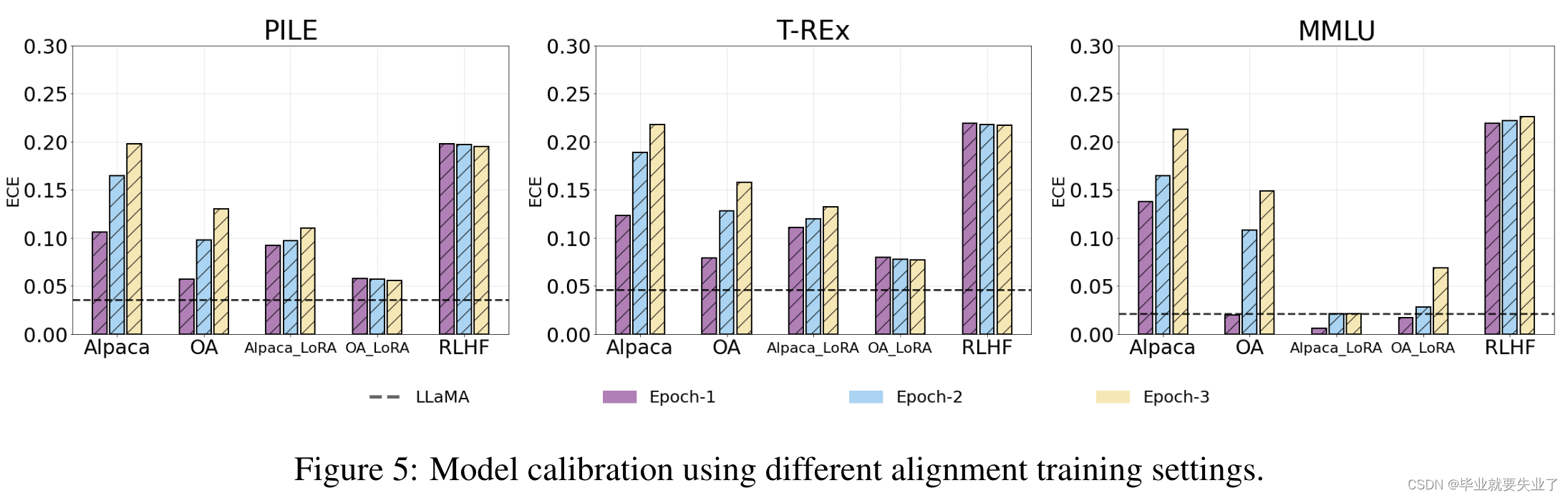
4 Calibration in Alignment Stage
- Base model:LLaMA 7B.
Instruction Tuning
- Training data:OpenAssistant Conversations优于Alpaca,因为更为多样;

- Training methods:LoRA优于全参微调,PEFT方法可以通过减少灾难性遗忘改善calibration,见https://arxiv.org/pdf/2305.19249.pdf;
- Training dynamics:改善指令数据的规模和多样性可能有助于改善calibration,不过未进行验证。
RLHF
- RLHF基本不改变calibration.
参考文献:
https://arxiv.org/pdf/2311.13240.pdf
https://arxiv.org/pdf/2103.15025.pdf
https://arxiv.org/pdf/1910.08684.pdf
https://arxiv.org/pdf/2305.19249.pdf















 1236
1236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









