







[论文阅读]LDSA: Learning Dynamic Subtask Assignment in Cooperative Multi-Agent Reinforcement Learning
标题含义:LDSA: 在合作式多智能体强化学习中学习动态任务分配
文章来源:NeurIPS 2022
原文链接:https://arxiv.org/abs/2205.02561
博主是一个科研萌新,刚刚入门多智能体强化学习。如有对本论文理解错误或不周之处,还请各位大佬海涵与斧正。
摘要
为了保证训练时的效率和scalability,绝大部分MARL会让智能体共享策略或价值网络。在许多复杂的多智能体任务中,我们希望不同的智能体具有处理不同子任务的特定能力。不加选择地共享参数可能会导致所有智能体的行为相似,这将限制探索效率并降低最终性能。为了平衡训练复杂性和智能体行为的多样性,文章提出LDSA框架来学习协作 MARL 中的动态子任务分配。
简介
许多复杂的多智能体任务可以视为许多子任务的组合,每一个子任务的transition和奖励函数是不一样的,解决每一个子任务需要特定的能力,而全参数共享可能导致智能体的行为都是相似的,阻碍了智能体策略的多样性。其中一个解决方法为按照子任务划分智能体,为每一个子任务学习一个网络。这个方法有两个难点:(1)如何划分子任务(2)如何实现智能体的分配。
之前有一篇叫做RODE: Learning Roles to Decompose Multi-Agent Tasks是较早研究这个方向的,RODE希望在不引入先验知识的情况下,通过划分联合动作空间,依据动作效果对动作进行聚类来实现子任务的划分。在LDSA一文中,作者认为RODE可能会在某些基本动作是所有子任务所需的情况下失效,而且当动作对环境产生的效果变化较为频繁时,界定动作的效果是比较困难的。[?]
文章提出了LDSA框架。具体来说文章提出了:
①subtask encoder 子任务编码器。子任务编码器依据子任务的identity,构建了每一个子任务的向量表征(vector representation )。
②trajectory encoding network 轨迹编码网络。动作观察历史轨迹反应了一个智能体的行为习惯和能力,可以作为选择子任务的重要依据。轨迹编码网络用于获取并编码每一个智能体的动作观察历史轨迹。
③subtask decoder 轨迹解码器。根据子任务表征生成每个子任务的策略参数,这也可以避免不同子任务之间策略的相似性。
④引入两个正则化来稳定训练,增大子任务之间的差异性。
然后,对于每个时间步长,每个智能体根据其动作观察历史和所有子任务表征的余弦相似度来获取子任务选择的分类分布,并使用 Gumbel-Softmax对子任务进行采样进行训练。
preliminaries
问题建模


方法
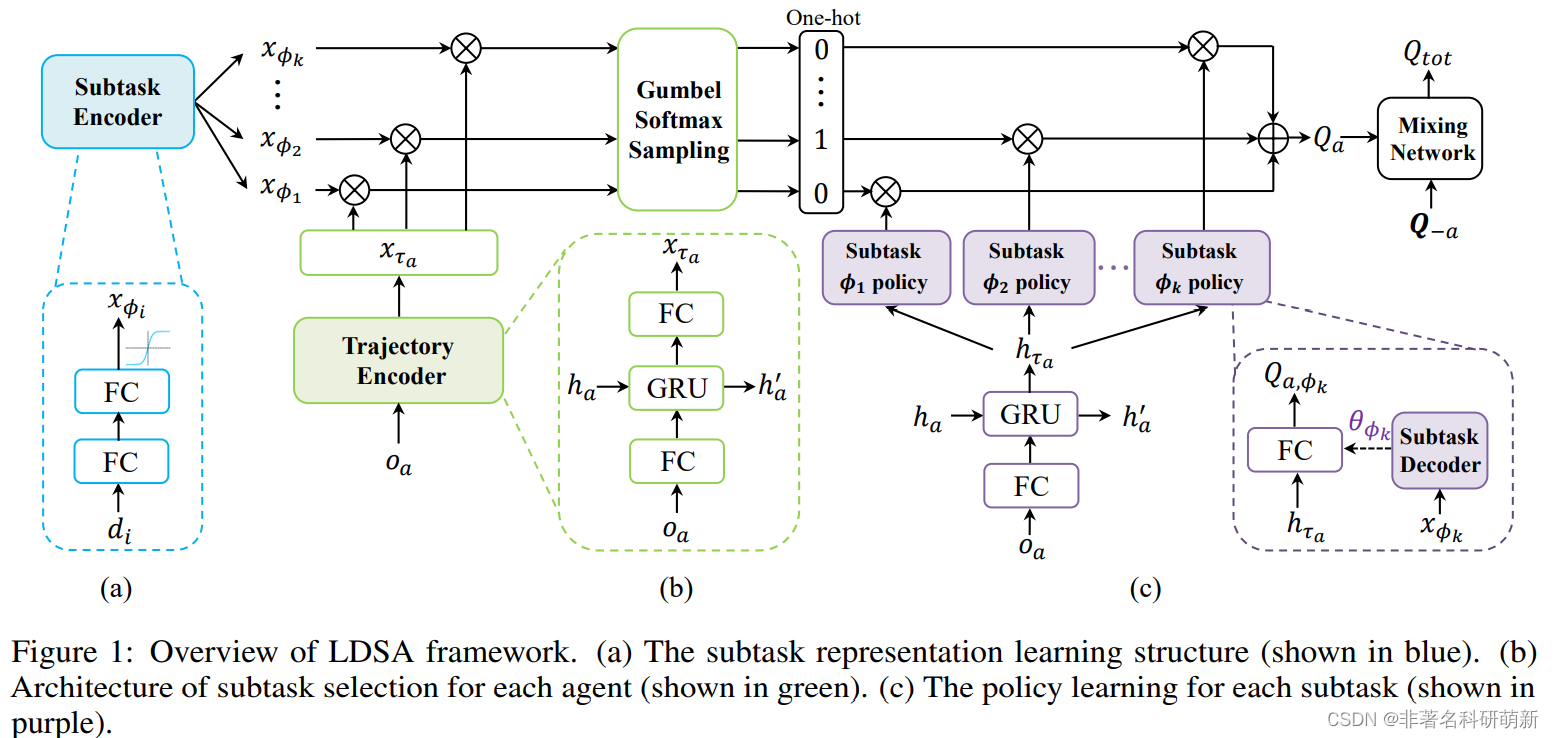
子任务表征
首先介绍如何构造一组不同的子任务来分解多智能体任务,如图1(a) 蓝色 部分所示。为了消除对先验知识的依赖并将其应用于更广泛的多智能体任务,根据子任务的identity i i i 为每个子任务 ϕ i \phi_i ϕi学习向量表征 x ϕ i x_{\phi_i} xϕi[?]。采用两层全链接层来学习子任务编码器 f e ( ⋅ ∣ θ e ) : R k − > R m f_e(·|\theta_e): R^k->R^m fe(⋅∣θe):Rk−>Rm。子任务编码器将子任务 ϕ i \phi_i ϕi的独热标识映射到 m 维表示空间,激活函数tanh用于限制输出大小。
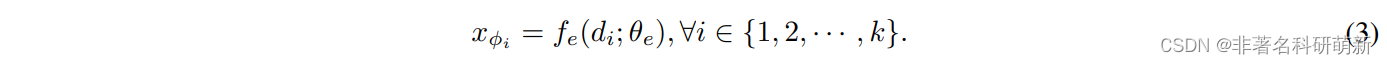
当子任务相似度较高,进行任务分解是没有意义的,为了保持子任务之间的不同,提出了:
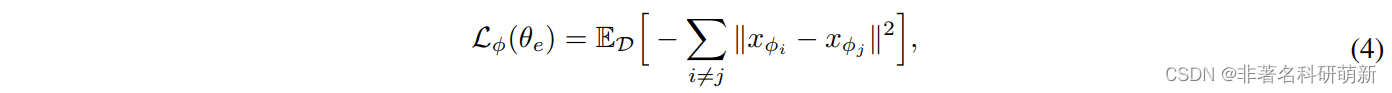
子任务表征学习贯穿整个训练过程,可以自动适应环境的动态变化。
基于能力的子任务选择 (Ability-based subtask selection)
通过子任务表征划分完任务后,文章根据每个智能体的能力设计了子任务选择策略。正如前文所说,智能体的行为观察历史可以反映其行为习惯和潜在能力。 如图1(b) 绿色所示,利用由 GRU和两个全连接网络组成的轨迹编码器 f h ( ⋅ ∣ θ h ) f_h(·|\theta_h) fh(⋅∣θh)来获取每个智能体的动作观察历史。 该编码器是共享的,将智能体的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4003
4003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









