






一、背景介绍
这节课是本次实战营的第四堂课,主要内容是目标检测与MMDetection,那我们马上开始吧!
所谓“目标检测”,顾名思义就是给定一张图片,输出结果图上用矩形框圈出所有可识别物体同时预测每个物体的类别,具体在细分领域有:人脸识别、智慧城市、自动驾驶、下游视觉任务。一定要注意目标检测和图像分类的不同之处,具体如下图所示:

引入滑窗(Sliding Windows)概念,是一个固定大小的窗口,在输入图像中遍历所有的位置,在每个位置都使用分类模型识别本时刻窗口中的内容,此外滑窗大小、长宽也并不固定。
试验整明效果不错,但是具体大规模实验中就不得不考虑效率问题:

基于此,大概有两个改进思路:①使用启发式算法替换暴力遍历;

②减少冗余计算,使用卷积网络实现密集预测。一般而言,第二种思路比较常见。

改进思路:用用卷积一次性计算所有特征,再取出对应位置的特征完成分类

在特征图上进行密集预测:

目标检测的基本范式:

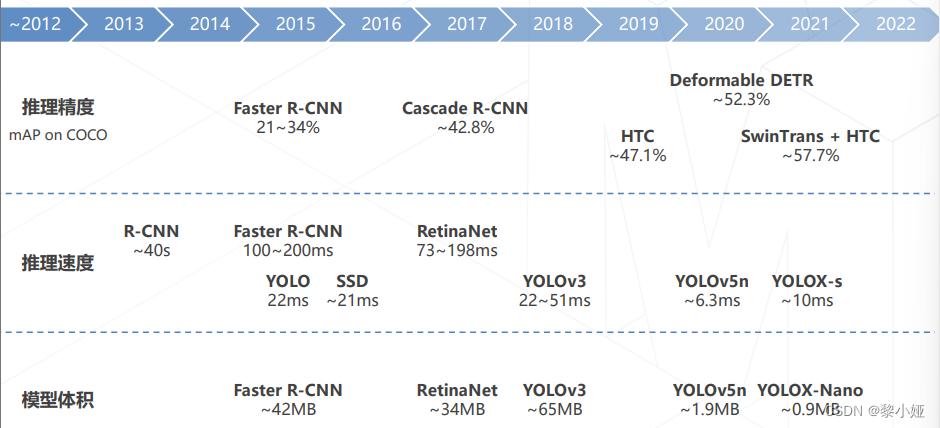
目标检测技术的演进:

二、基础知识
框、边界框(Bounding Box)

注意:区域(Region)、区域提议(Region Proposal,Proposal)、感兴趣区域(Region of Interest,RoI)、锚框(Anchor Box,Anchor)虽然表述不同,但是都指框的概念。
交并比(Intersection Over Union):两矩形框交集面积与并集面积之比,是矩形框重合程度的衡量指标,完全重合为1,完全不重合为0.效果如下图所示:

置信度(Confidence Score):模型认可自身预测结果的程度,通常需要为每个框预测一个置信度,大部分算法取分类模型预测物体属于特定类别的概率,部分算法让模型独立于分类单独预测一个置信度。置信度越高越可靠。
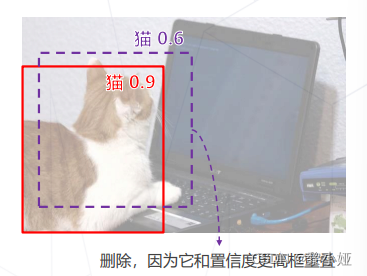
非极大值抑制(Non-Maximum Suppression):滑窗类算法通常会在物体周围给出多个相近的检测框,这些框实际指向同一物体,只需要保留其中置信度最高的,而实现这一项需要通过非极大值抑制(NMS)算法实现,如下图所示:

边界框回归(Bounding Box Regression)

边界框编码 (Bbox Coding): 边界框的绝对偏移量在数值上通常较大,不利于神经网络训练,通常需要对偏移量进行编码,作为回归模型的预测目标。

二、目标检测算法
两阶段的目标检测算法


Region-based CNN 2013

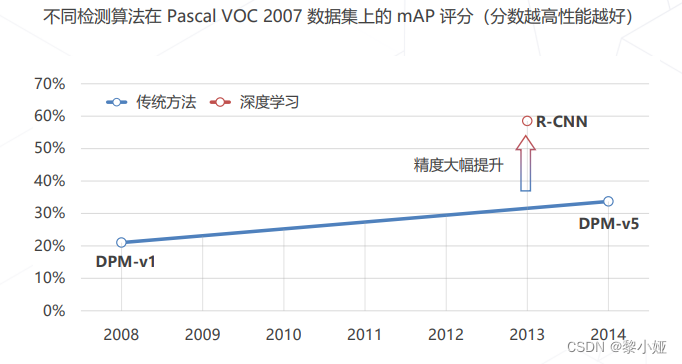
相比于传统方法:
存在的一个问题是慢:区域提议一般产生 2000 个框,每个框都需要送入 CNN 前传,推理一张图要几秒至几十秒,故而有了如下改进:
Fast R-CNN 2014

训练:

速度和精度:


降低区域提议的计算成本:
区域提议 → 在图中找到包含物体的框 → 不需要区分类别的检测问题
①特定位置的特征包含其感受野内图像的信息,且已达到足够的抽象层级
②基于特征做二分类就可以预测感受野内是否包含物体,从而实现区域提议

朴素方法的局限:
①图中有不同大小的物体,区域提议算法需要产生不同尺寸的提议框,以适应不同尺寸的物体;
②物体可能有一定程度重合,区域提议算法要有能力在同一位置产生不同尺寸的提议框,以适应重合的情况。
锚框(Anchor)
在原图上设置不同尺寸的基准框为锚框,基于特征独立预测每个锚框中是否包含物体
①可以生成不同尺寸的提议框;
②可以在同一位置生成多个提议框覆盖不同物体。

多尺度检测技术
重要性在于图像中物体大小可能有很大差异 (10 px ~ 500 px)
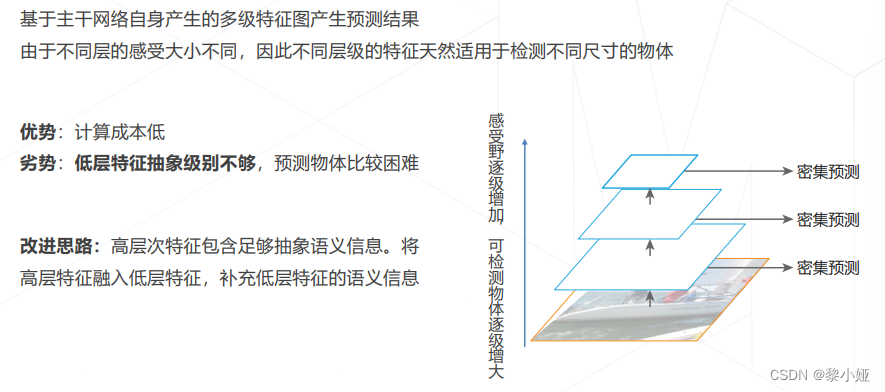
多尺度技术出现之前,模型多基于单级特征图进行预测,通常为主干网络的倒数第二层,受限于结构(感受野)和锚框的尺寸范围,只擅长中等大小的物体另一方面,高层特征图经过多次采样,位置信息逐层丢失,小物体检测能力较弱,定位精度较低
引入图像金字塔,将图像缩放到不同大小,检测算法在不同大小图像上即可检测出不同大小物体,如下图所示:

优点在于算法不经改动可以适应不同尺度的物体;缺点在于计算成本成倍增加。
层次化特征
特征金字塔网络(Feature Pyramid Network (2016)

特征金字塔网络应用于Fast R-CNN中:

单阶段的目标检测算法


YOLO 2015
最早的单阶段算法之一。

YOLO的分类和回归目标

YOLO的损失函数

YOLO的优缺点

SSD 2016

SSD的损失函数

因为单阶段算法需要为每个位置的每个锚框预测一个类别,训练时需要为每个预测计算分类损失,而在一些训练图中锚框的数量远远大于真值框(数万 vs 数个),就会产生正负样本不均衡问题,如下图所示:
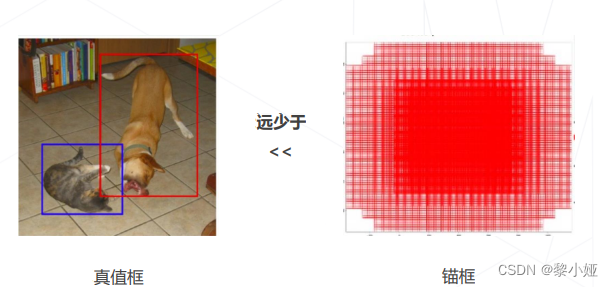
解决样本不均衡问题:①两阶段检测器通过区域提议拒绝了大量负样本,区域检测头接收的正负样本比例并不悬殊;②单阶段检测器则需要专门处理样本不均衡问题

困难负样本

不同负样本对损失函数的贡献:

降低简单负样本的损失:

Focal Loss

其他应用:
RetinaNet 2017
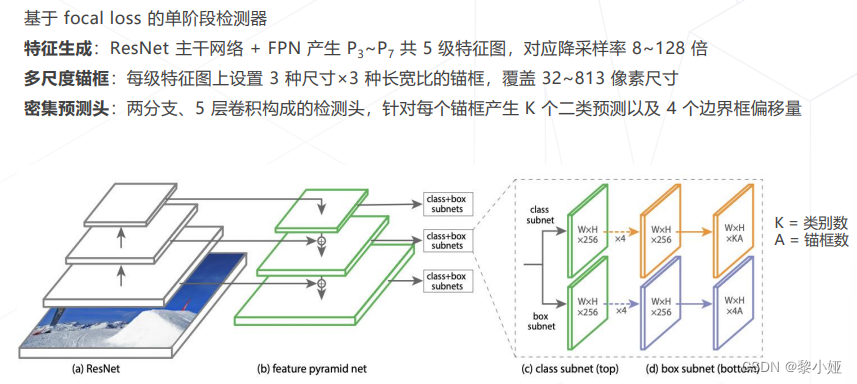
YOLO v3


无锚框目标检测算法
基于锚框

无锚框

具体效果如下:

实际应用有:
FCOS 2019

FCOS 的多尺度匹配

FCOS的预测目标

FCOS的损失函数

CenterNet 2019

CenterNet的主要流程:

Detection Transformers
DETR 2020

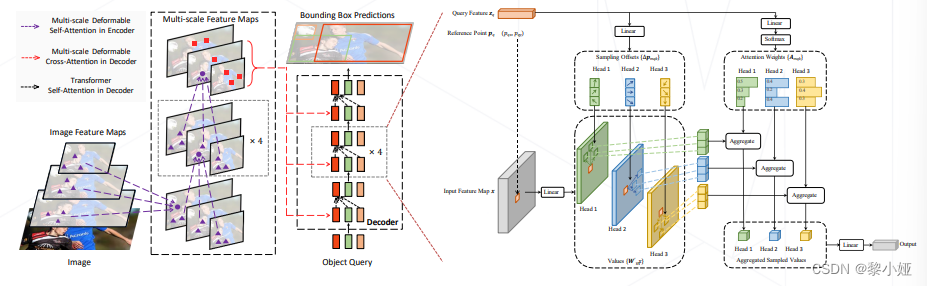
Deformable DETR 2021
DETR 的注意力机制收敛很慢,收敛 ≈ 注意力机制注意到特定的位置;
Deformable DETR 借鉴 Deformable Conv 的方式,显示建模 query 注意的位置,收敛速度更快。
目标检测模型的评估方法
正确结果 (True Positive):算法检测到了某类物体 (Positive),图中也确实有这个物体,检测结果正确 (True)
假阳性 (False Positive):算法检测到了某类物体 (Positive),但图中其实没有这个物体,检测结果错误 (False)
假阴性 (False Negative):算法没有检测到物体 (Negative),但图中其实有某类物体,检测结果错误 (False)
检测到的衡量标准:对于某个检测框,图中存在同类型的真值框且与之交并比大于阈值(通常取0.5)

准确率与召回率:


PR曲线、AP值: 为得到阈值无关的评分,可以遍历阈值,并对 Precision 和 Recall 求平均。
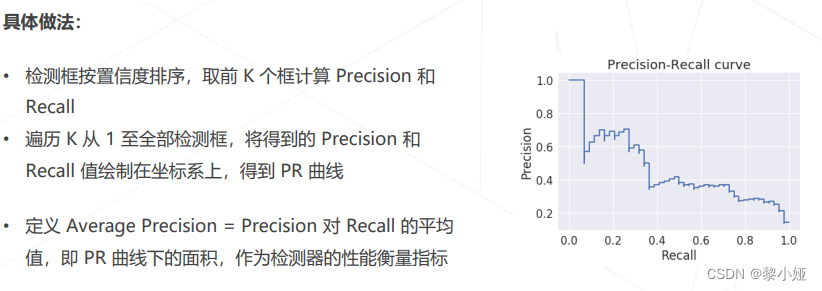
Mean AP:分类别统计AP,并按类别平均即得到 Mean AP
完整计算流程:
①将数据集中全部图像上的检测框按预测类别分类
②对于某一类别的所有检测框,计算 AP:
按置信度将该类别的所有检测框排序
逐一与真值框比较,判定 TP 或 FP ,并绘制 PR 曲线
对 PR 曲线插值,计算 AP
③求所有类别的 AP 的平均,得到 Mean AP
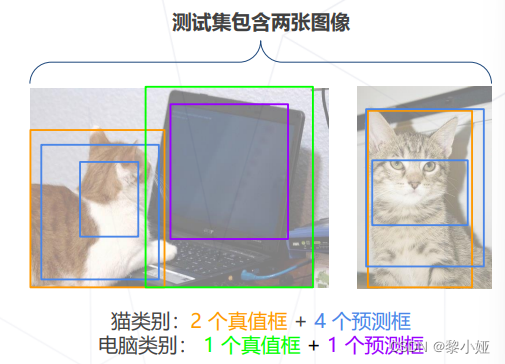
部分数据集(如 COCO)还要求在不同的 IoU 阈值下计算 Mean AP,得到 AP50,AP75 等指标可衡量检测器在不同定位精度要求下的性能。
三、MMDetection
这是OpenMMLab专门为目标检测开发的工具包,2018年发布,到2022年9月已经更新到了3.0的版本,在科研论文、学术比赛、工业落地等各个方面都有广泛应用。
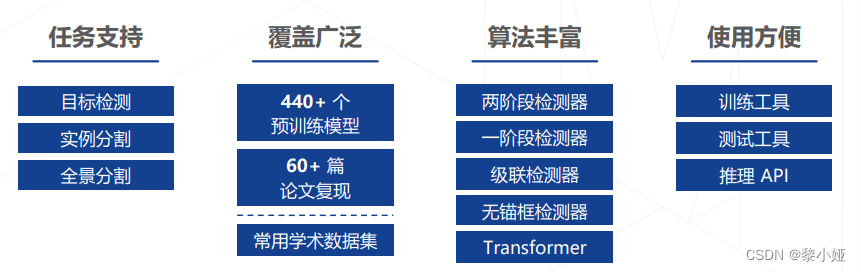
MMDetection 提供 400 余个性能优良的预训练模型,开箱即用,几行 Python API 即可调用强大的检测能力;MMDetection 涵盖 60 余个目标检测算法,并提供方便易用的工具,经过简单的配置文件改写和调参就可以训练自己的目标检测模型。
模型搭建:可以使用 MIM 配置 MMCV 和 MMDetection
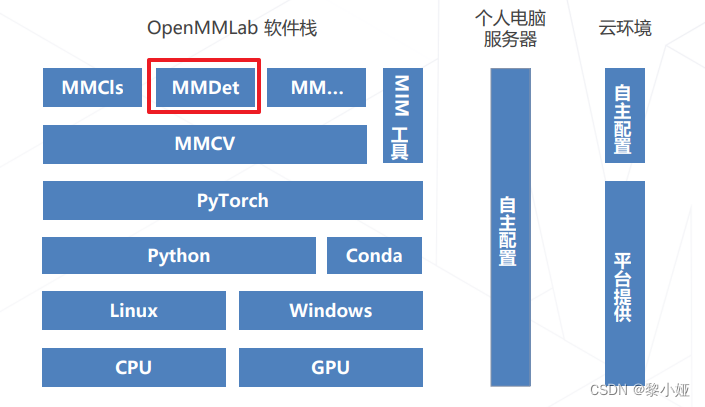
代码库结构:GitHub - open-mmlab/mmdetection: OpenMMLab Detection Toolbox and Benchmark

配置文件的运作方式
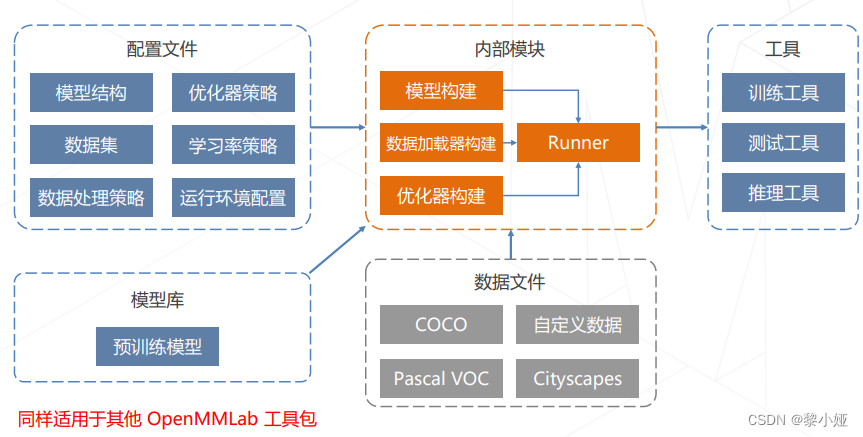
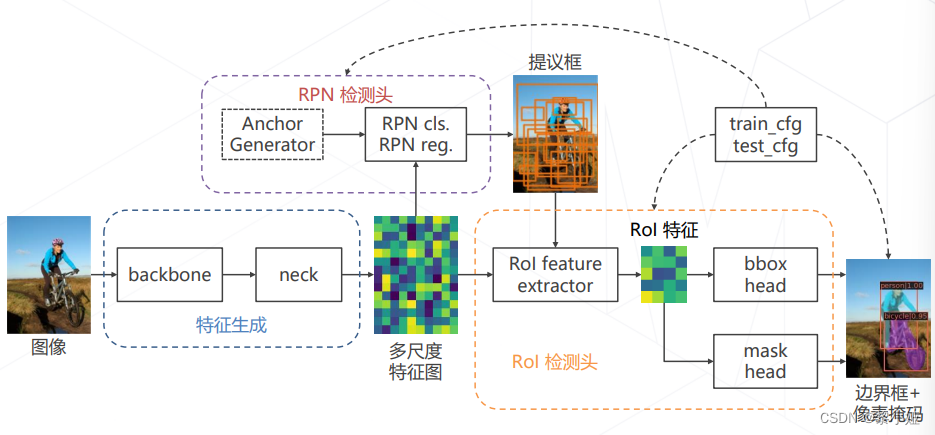
两阶段检测器:
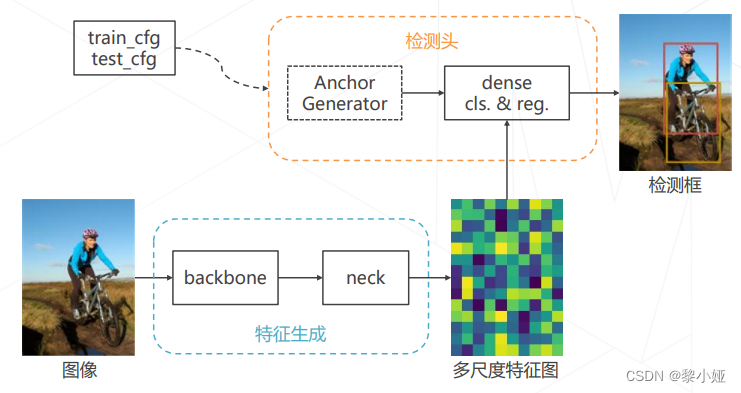
单阶段检测器
这里也只是简单介绍,其余具体代码详见OpenMMLab官网(OpenMMLab · GitHub)














 7288
7288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









