






 本文探讨了OpenCompass在大模型评测中的应用,包括评测InternLM2-Chat-7B模型的性能,强调了评测模型的必要性、方法(如自动化与人机交互)以及OpenCompass的6大维度评测框架。同时,文章指出了当前评测领域的挑战,如缺乏高质量中文评测集和高成本的人工测试。
本文探讨了OpenCompass在大模型评测中的应用,包括评测InternLM2-Chat-7B模型的性能,强调了评测模型的必要性、方法(如自动化与人机交互)以及OpenCompass的6大维度评测框架。同时,文章指出了当前评测领域的挑战,如缺乏高质量中文评测集和高成本的人工测试。
目录
作业
- 使用 OpenCompass 评测 InternLM2-Chat-7B 模型在 C-Eval 数据集上的性能
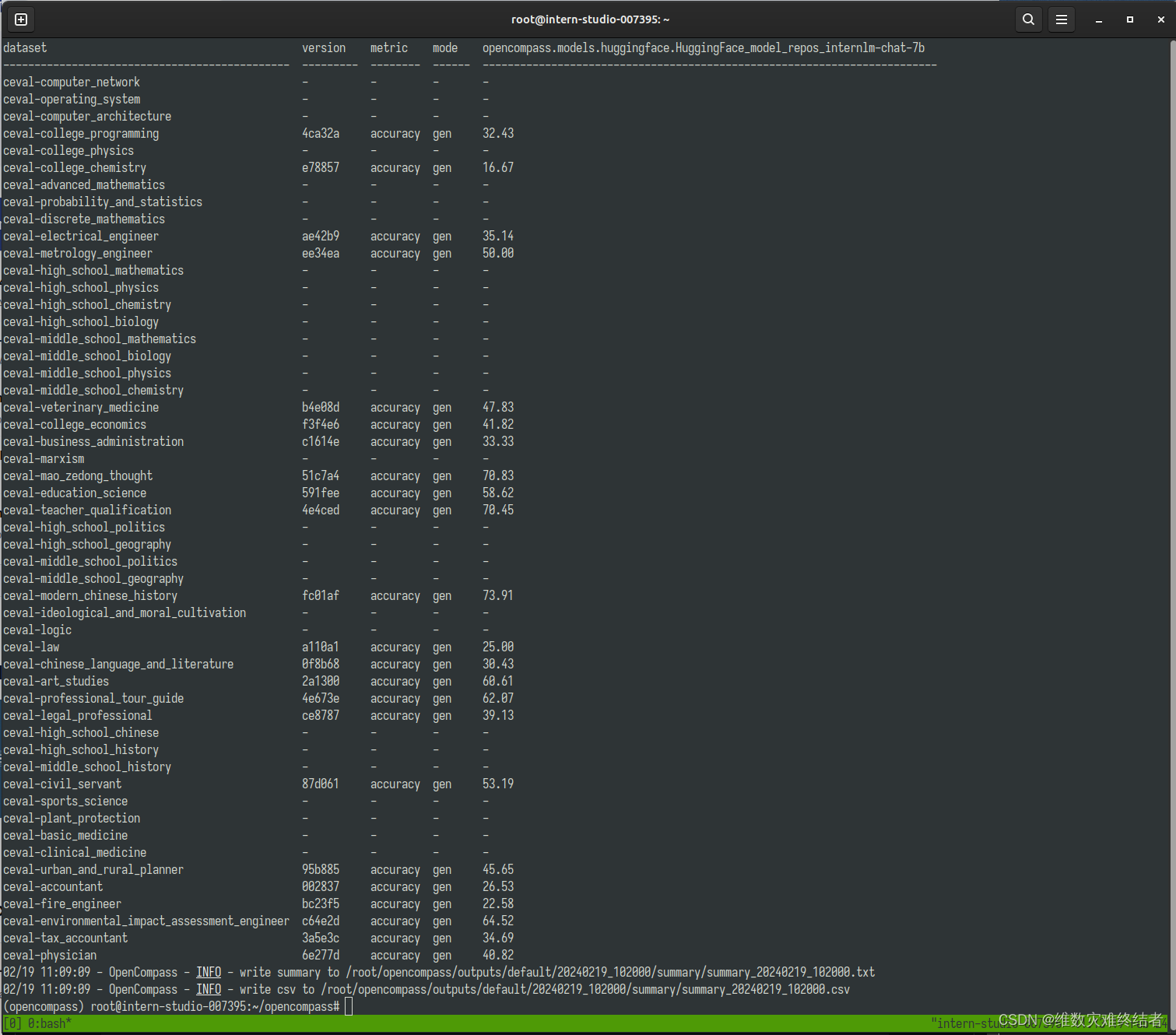
(结果中有部分数据缺失,根据 debug 显示,可能是huggingface模型加载或开发机存储空间不足的问题)
笔记
模型评测
- 为什么需要评测
模型的类型众多(text-to-text, text-to-task, text-to-image, text-to-video, text-to-3D),需要有一个相对客观公平统一的框架来判断其生成质量
- 模型选型
知道模型的边界在哪里
- 模型能力提升
- 真实应用场景效果评测
- 需要评测什么
- 知识、推理、语言
传统 NLP 任务
- 长文本、智能体、多轮对话
LLM 评测
- 情感、认知、价值观
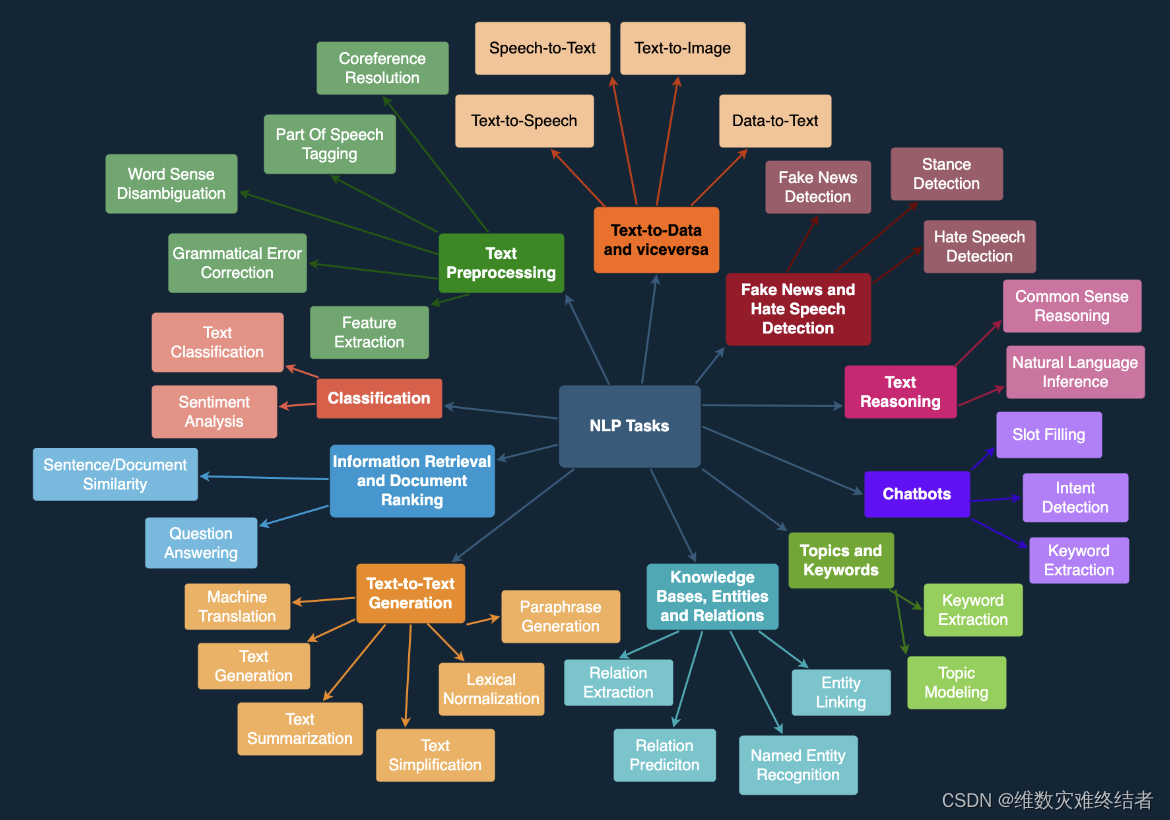
- 如何评测大语言模型
大模型可以分为基座模型和对话模型(经过指令微调的模型)
- 自动化客观评测
- 人机交互评测
人类评价
- 基于大模型的大模型评测
使用模型评价,如 JudgeLM
- 基于提示词工程
使用不同的 Prompt,提问同一个问题,观察回答是否一致,以此检验模型对 Prompt 的敏感性,也即模型问答的鲁棒性
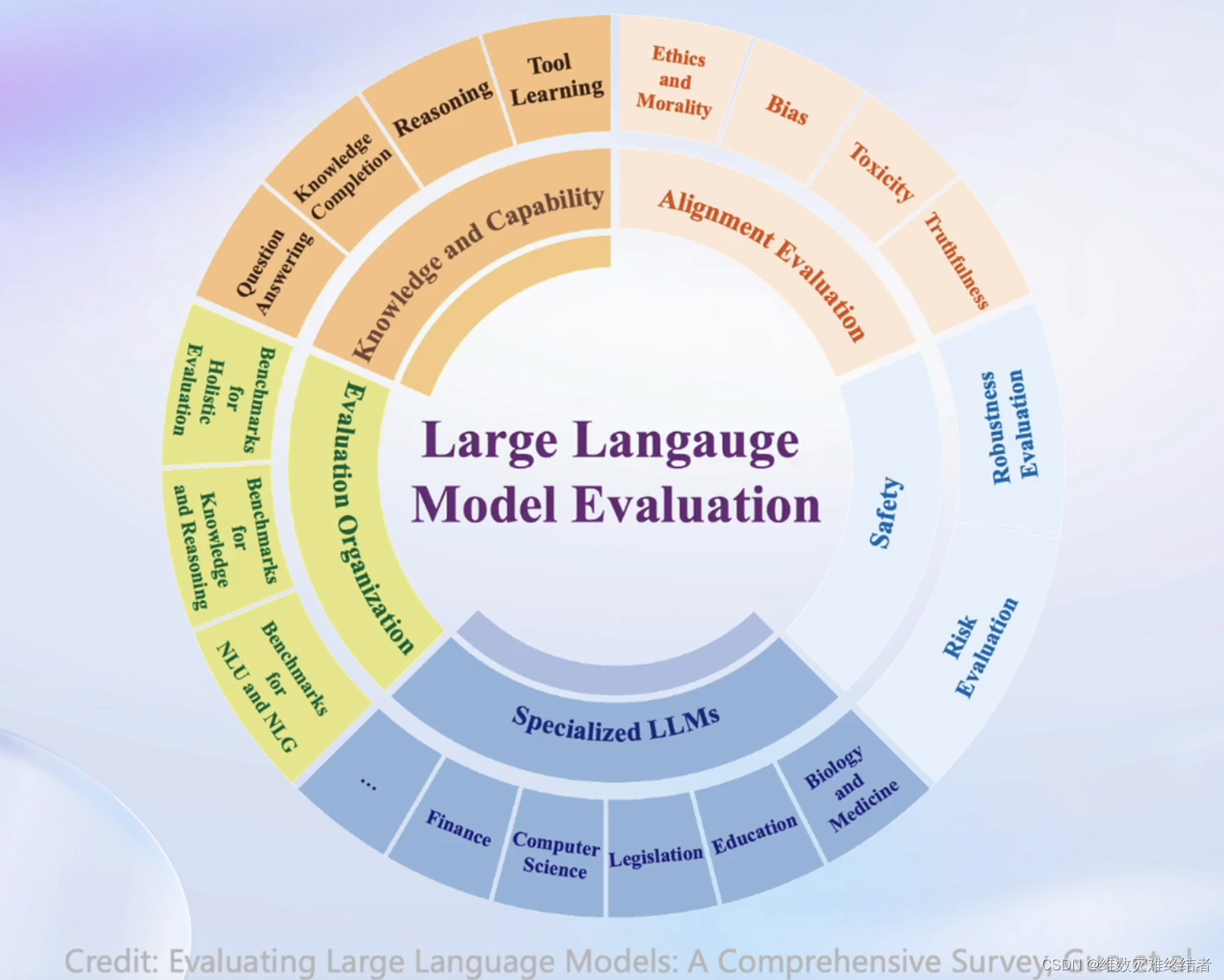
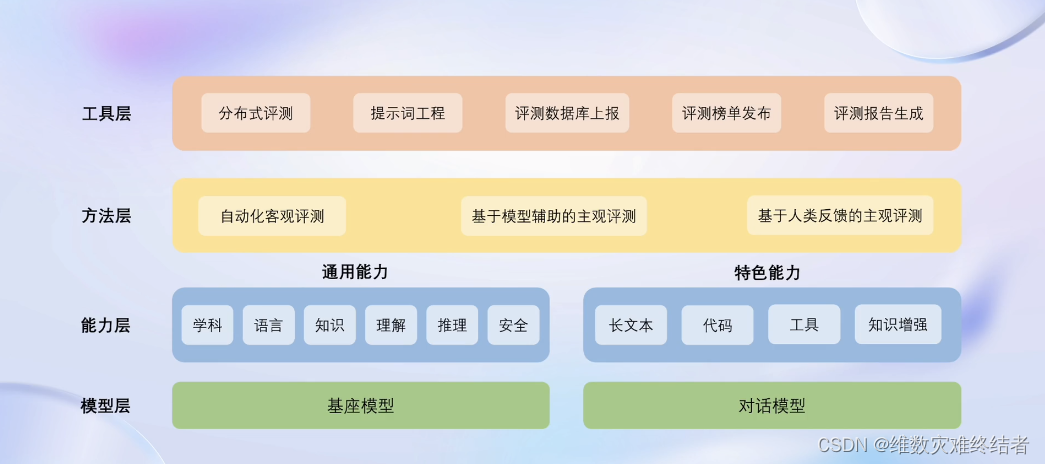
OpenCompass 能力框架
- 6大维度,100+评测集,50万+评测题目
- 适配任意形式的模型
- 并行设计处理
- 模型榜单
- MMBench
- LawBench
- MedBench

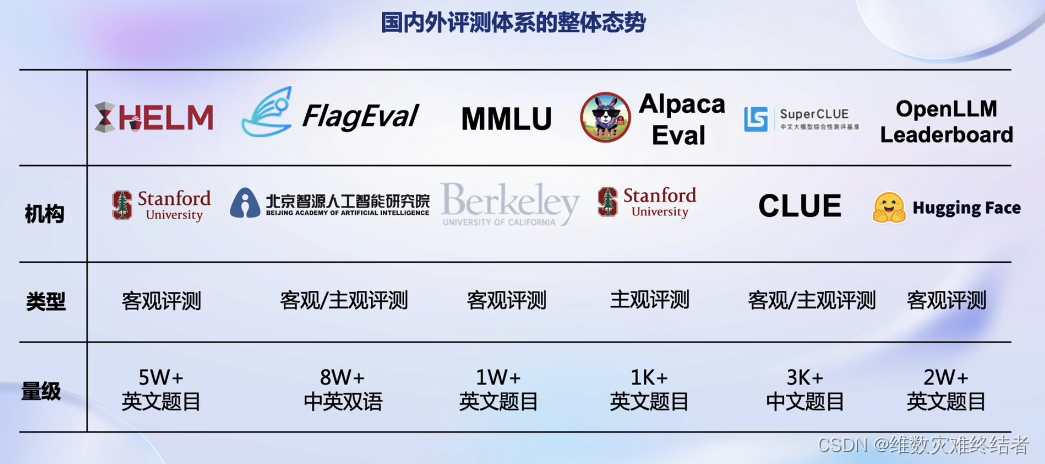
大模型评测领域的挑战
- 缺少高质量中文评测集
- 难以准确提取答案
- 能力维度不足
- 测试集混入训练集
- 人工测试成本高昂















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









