







SqueezeNet 论文原文:SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
SqueezeNext 论文原文:SqueezeNext: Hardware-Aware Neural Network Design
1. SqueezeNet
文章标题:SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
作者单位:DeepScale;UC Berkeley;Stanford University
数据集:ImageNet
网络精度:TOP-1 Accuracy 57.5%、TOP-5 Accuracy 80.3%(和 AlexNet 差不多),但模型仅为 0.47MB (比 AlexNet 小 510 倍)。【但是这里要注意的是,SqueezeNet 本身的实际模型大小为 4.8MB ,其自身并不具备将模型压缩至 0.47MB 的能力,是因为这里还利用了 Deep Compression 的技术对模型做进一步压缩,有标题党嫌疑】
1.1 核心思路
- 用1x1卷积替代3x3卷积:1x1卷积比3x3卷积少9倍的参数量;
- 减少3x3卷积的输入通道数:3×3卷积层的参数量=输入通道数×卷积核层数×(3×3),所以文章认为不仅需要减少3x3卷积的使用(第一条),在使用3x3卷积时也要减少输入通道数;
- 后置下采样层位置(3-4个Fire Module之后才接着一个池化层,不同于传统的卷积-池化-卷积-池化…):文章认为更大的特征图拥有更多的信息(我认为这或许也是精度和模型size之间的一种tradeoff,不可避免地,更大的特征图会让此特征图后的模型参数量和计算量增加,那么达到了增加网络精度的目的,但是同时模型size也跟着变大了)。
简而言之,核心思路第一、第二条主要为了减小模型的size,而第三条主要为了提高模型精度,但同时也增大了模型的size。
1.2 详解
1. Fire Module

注:上图 squeeze 和 expand 中的 1x1 卷积和 3x3 卷积的数量和比例并不是固定的,可进行调整。
Fire Module 由两部分组成:squeeze 和 expand。
squeeze 部分只包含 1x1 卷积(为什么这么设计?对应核心思路第一条);
expand 部分既有 1x1 卷积也有 3x3 卷积(前一层的特征图分别经过 1x1卷积和 3x3 卷积,将得到的新特征图按照通道进行拼接[这里借鉴了 Inception ,这里的3x3卷积进行了补零操作,所以整个 Fire Module 过程中的图像分辨率都保持不变,仅是通道数发生了变化)。
在实际使用 Fire Module 时,应该设置 squeeze 的 1x1 卷积个数小于 expand 中的卷积核个数之和(包括 1x1 卷积和 3x3 卷积),以保证 3x3 卷积的输入通道数比较小(对应核心思路第二条)。
2. 网络结构

注:left to right : SqueezeNet, SqueezeNet with simple bypass, SqueezeNet with complex bypass
其中,上图中间和最右侧结构借鉴了 ResNet 的思想。
其实,SqueezeNet 的架构也是借鉴了 VGG 的形式,对卷积(Fire Module)进行堆叠。这里最后一层的全连接层替换成了全局平均池化,也大大减少了参数量。
3. SqueezeNet的具体参数

4. SqueezeNet的性能表现

SqueezeNet 在 ImageNet 数据集上的 TOP-1 Accuracy 为 57.5%,TOP-5 Accuracy 为 80.3%,与 AlexNet 相似。
2. SqueezeNext
文章标题:SqueezeNext: Hardware-Aware Neural Network Design
作者单位:EECS;UC Berkeley
数据集:ImageNet
网络精度:TOP-1 Accuracy 59.24%(1.0 SqueezeNext 23v5)
2.1 核心思路
SqueezeNext 是基于 SqueezeNet 进行改进的“软硬兼并”的轻量化网络,以往的论文大多都只讲了网络如何设计,并没有涉及硬件,而 SqueezeNext还从硬件角度分析如何提速。基于 SqueezeNet 的改进:
- 将 SqueezeNet 中的 two-stage squeeze module(也就是Fire Module)并为一步,减少了通道数进而减少了参数;
- 将3x3卷积分解(low rank filters)为 3x1 卷积和 1x3 卷积,参数量由 k 2 k^2 k2 降为 2k,同时移除了 Fire Module 第二步中的 1x1 卷积分支;
- 引入 ResNet 的 shortcut 结构;
- 通过硬件实现的结果发现,前面层的 block 计算效率低,因而减少前面层的 block 数量,增加后面层的 block 数量。
另外,文章多次提及深度可分离卷积在硬件上的运行效果不好(计算密度差)。
2.2 详解
1. ShuffleNext的block(最右侧)

最后一个 1x1 卷积的作用是将通道数升回至初始输入通道数,以进行相加操作。
更为直观的 block 结构: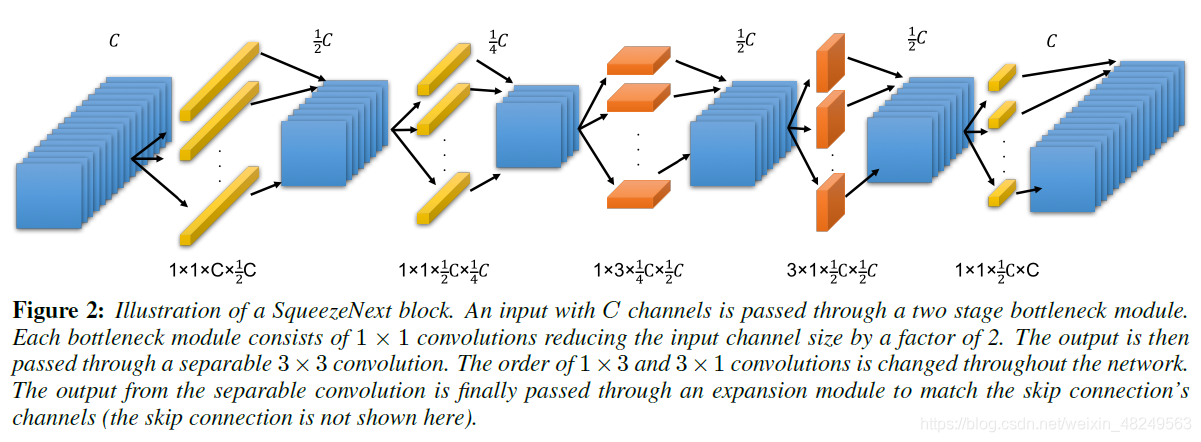
2. 网络结构
在硬件实现前的结构设计:
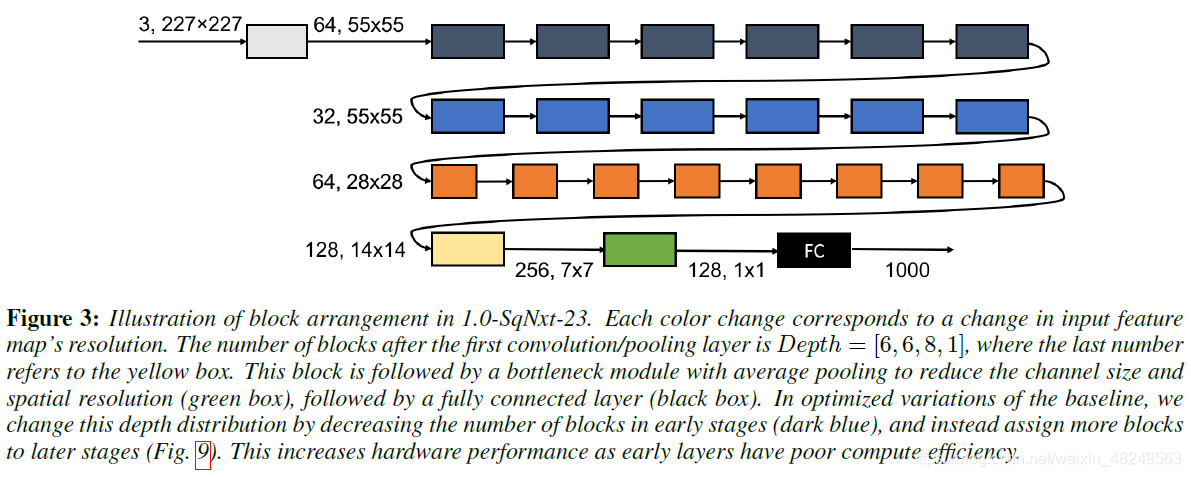
其中,不同颜色的 block 代表特征图的分辨率发生变化,绿色为平均池化层,黑色为全连接层。
作者在上述结构的基础上,进行不同网络结构 Inference 时间比较实验:
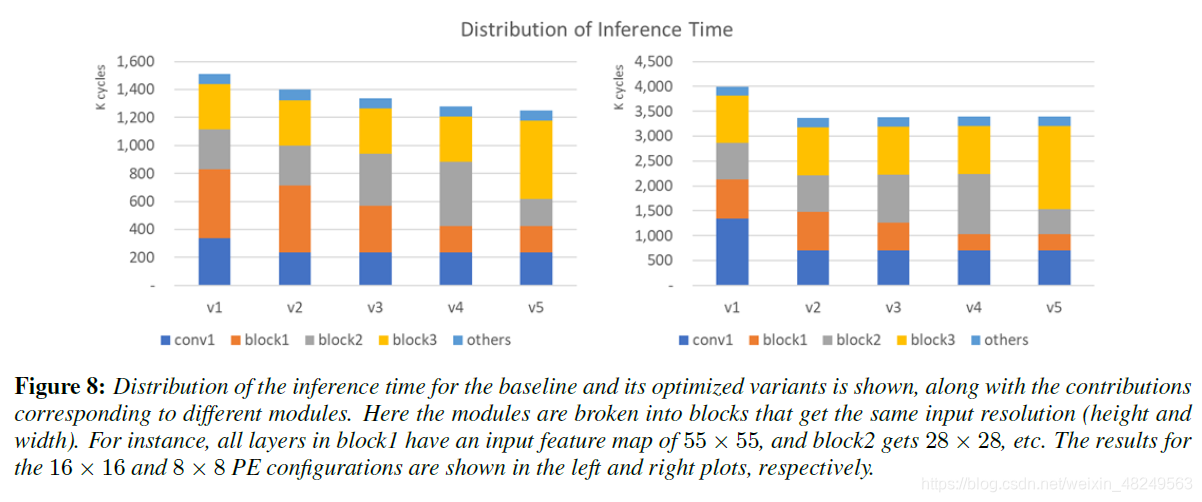
在硬件实现后的结构设计:
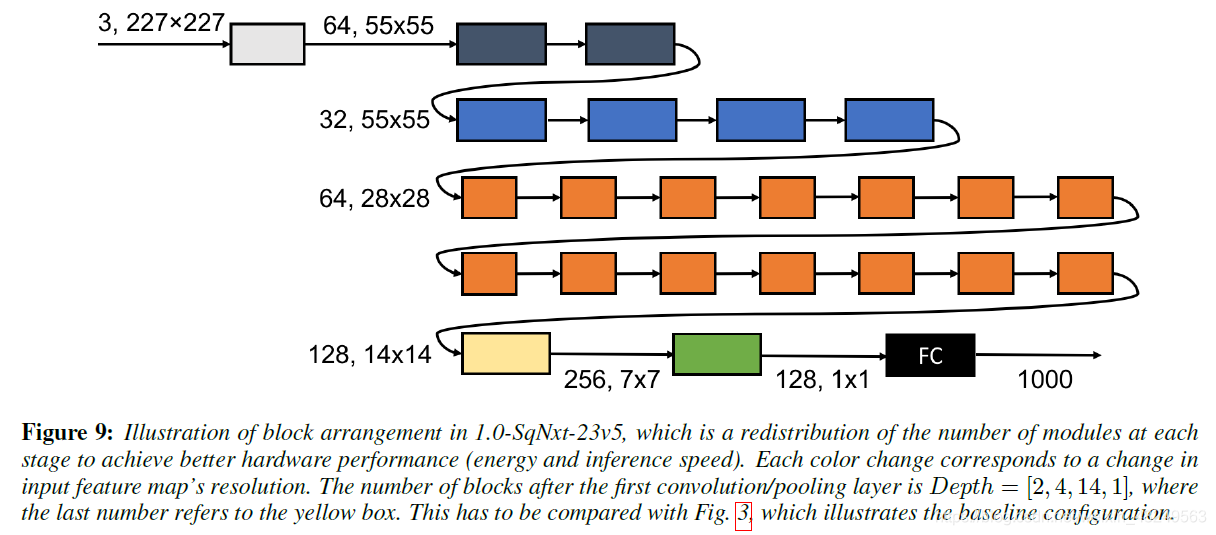
3. SqueezeNext的性能表现
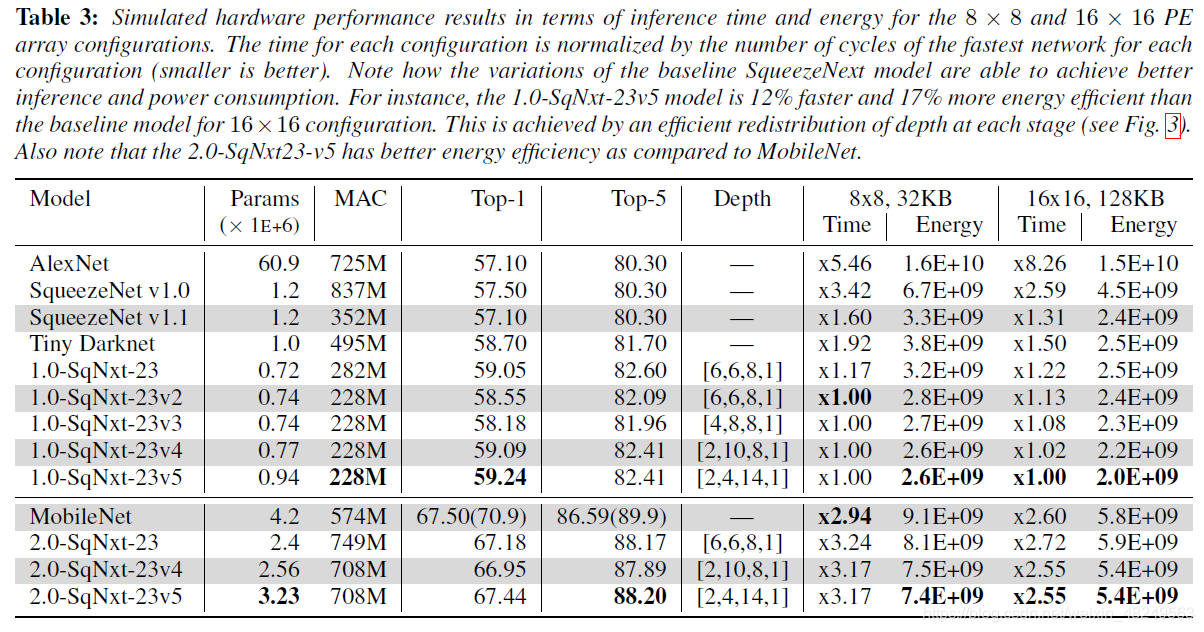
不论是 SqueezeNet 还是 SqueezeNext ,其主要比较对象是 AlexNet,Squeeze 系列的精度都比 MobileNet 系列低。

















 3712
3712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









