







前文:torchvision onnx 模型导出_星魂非梦的博客-CSDN博客
本文onnx 模型: 轻量化神经网络之SqueezeNetONNX文件-深度学习文档类资源-CSDN下载
1. 模型描述
squeezenet1_0 来自于论文: ICLR-2017SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
squeezenet1_1 来自于 official squeezenet repo. 它比 squeezenet1_0 少 2.4x 的计算量和略少的参数,但不牺牲精度。
他们在 imagenet 数据集上使用预训练模型的 1-crop 错误率如下:
| Model structure | Top-1 error | Top-5 error |
|---|---|---|
| squeezenet1_0 | 41.90 | 19.58 |
| squeezenet1_1 | 41.81 | 19.38 |
| Model structure | 模型大小 |
|---|---|
| squeezenet1_0 onnx | 4.77MB |
| squeezenet1_1 onnx | 4.72MB |
2. squeezenet1_0 和 squeezenet1_1

3. 核心部件
Fire 代码:
class Fire(nn.Module):
def __init__(
self,
inplanes: int,
squeeze_planes: int,
expand1x1_planes: int,
expand3x3_planes: int
) -> None:
super(Fire, self).__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.squeeze_activation(self.squeeze(x))
return torch.cat([
self.expand1x1_activation(self.expand1x1(x)),
self.expand3x3_activation(self.expand3x3(x))
], 1)可视化:
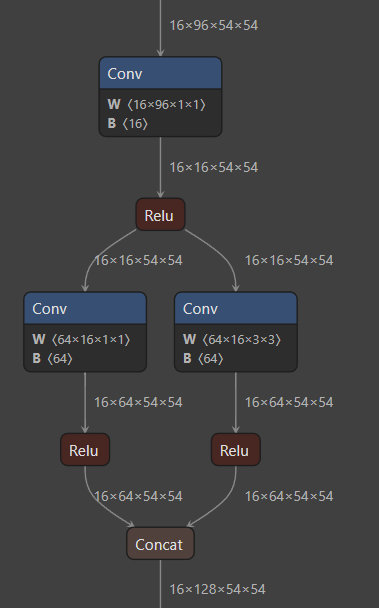
模型细节:
1. Fire 模块中,先使用 1x1 卷积压缩通道数,再使用两个并行分支扩大通道数,最后再concat;
好处:减少了 3x3 卷积的通道数,从而减少参数量。
2. 整体来说,使用 MaxPool 进行下采样;
4. 总结
- SqueezeNet 开拓了模型压缩这一方向;
- 参数量少;
- SqueezeNet的Fire模块的两个分支的计算方式不同,在GPU并行计算两个分支时,运算量较小的分支会等待运算量较大的分支,于是丧失了网络的并行性,因为小分支的计算量小的优点无法体现出来;SqueezeNet的通过更深的深度置换更少的参数数量虽然能减少网络的参数,但是其丧失了网络的并行能力,测试时间反而会更长;
- 论文的题目标题党,问题的主要症结在于AlexNet本身全连接节点过于庞大,50倍参数的减少和SqueezeNet的设计并没有关系,考虑去掉全连接之后3倍参数的减少更为合适;题目中的0.5MB的模型标题党,0.5MB的模型主要得益于Deep Compression。
参考链接:SqueezeNet详解 - 知乎




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











