







目录
前言:
CNN网络模型一直在追求识别成功率,从AlexNet到VGGNet模型,识别精度不断提高,TOP-5错误率从15.3%下降到7.3%,但参数数量也越来越多,但参数数量也越来越多,从60M增加到140M。过多的参数降低了分布式训练的效率,也给数据传输所需的网络带宽造成很大的负担。如何在保证识别精度的情况下,对网络参数进行压缩是需要进一步研究的方向。
本篇介绍的SqueezeNet模型(压缩模型)就是为了解决这一问题而提出的网路模型。本篇先阐述SqueezeNet模型的基本理论,然后解读Caffe的实现,最后介绍Caffe环境下的训练方法。
SqueezeNet模型原理
SqueezeNet设计目标不是为了得到最佳的CNN识别精度,而是希望在简化网络复杂度的同时保证网络模型的识别精度。
SqeezeNet模型的设计用以下三个方法简化网络复杂度:
(1)替换3x3的卷积核为1x1的卷积核。从AlexNet模型发展到现在,因为设计上的简洁和有效性,卷积核的大小都选择3x3.SqueezeNet模型用1x1的卷积核替换3x3的卷积核可以让网络参数缩小9倍。但是为了不影响识别精度,只做了部分替换。
(2)减少输入3x3卷积的输入特征数量。将卷积层分解为squeeze层以及expand层,并封装为一个Fire Module。
(3)在整个网络后期进行下采样,使得卷积层有较大的activation maps。
Fire Module
Fire Module是SqueezeNet的核心构件,其思想非常简单。即将一个卷积层分解为一个Squeeze层和一个expand层,并各自带上Relu激活曾。squeeze层包含全部都是1x1的卷积核,共有S个。expand层包含1x1核3x3的卷积核,其中1x1的卷积核有E1个,3x3的卷积核有E3个,要求满足S<(E1+E3)。如下图FireModule结构:
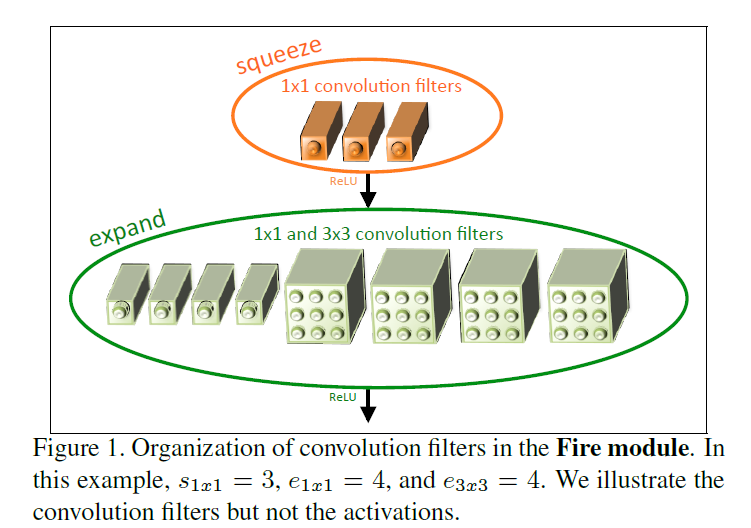
SqueezeNet模型结构
SqueezeNet的网络模型结构如图:
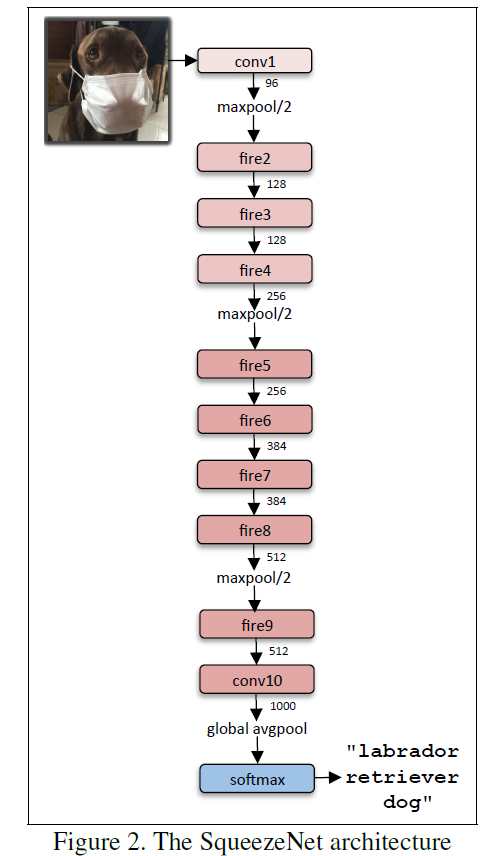
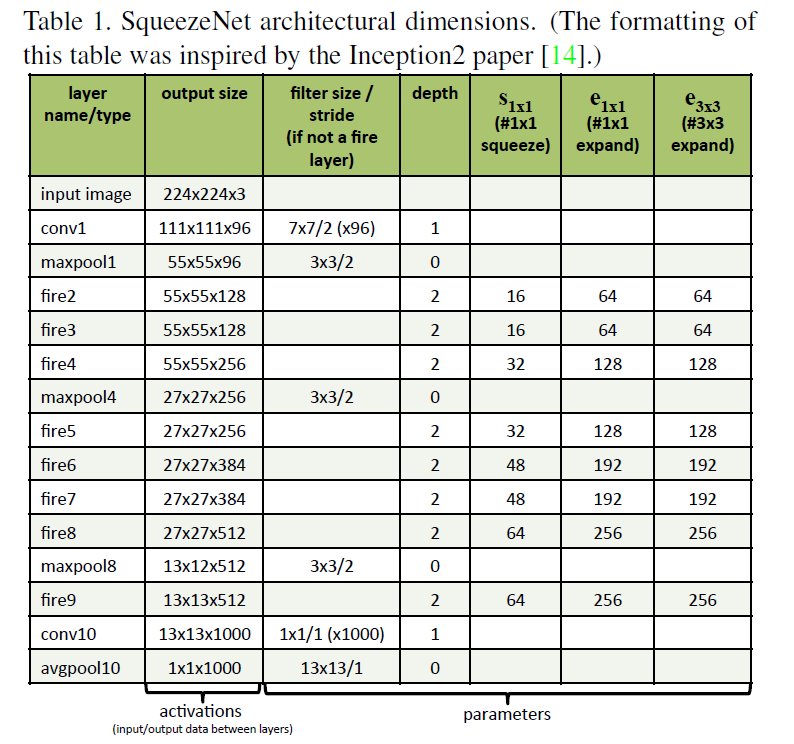
SqueezeNet模型共有九层Fire Module,中间穿插了三个MAX pooling层,最后一层用Average Pooling层替换全连接层是的参数大量减少。SqueezeNet网络模型在最上层核下层各保留了一个卷积层,这样做的目的是保证输入输出的大小可掌握。其他参数细节设置在下面caffe实现中会详细介绍。下表给出了每层的维度:
SqueezeNet模型特点
(1)SqueezeNet比AlexNet的参数减少的50倍,模型大小只有4.8M,在性能好的FPGA上可以运行起来,并且能带来与AlexNet相当的识别精度。
(2)SqueezeNet证明了小的神经网络也能达到很好的识别精度,这使得未来将嵌入式设备或移动设备植入神经网络成为一种可能。
SqueezeNet网络实现
# please cite:
# @article{SqueezeNet,
# Author = {Forrest N. Iandola and Matthew W. Moskewicz and Khalid Ashraf and Song Han and William J. Dally and Kurt Keutzer},
# Title = {SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and $<$1MB model size},
# Journal = {arXiv:1602.07360},
# Year = {2016}
# }
layer {
name: "data" //data层
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
crop_size: 227
mean_value: 104
mean_value: 117
mean_value: 123
}
data_param {
source: "examples/imagenet/ilsvrc12_train_lmdb" //训练数据集
batch_size: 32
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
crop_size: 227
mean_value: 104
mean_value: 117
mean_value: 123
}
data_param {
source: "examples/imagenet/ilsvrc12_val_lmdb"
batch_size: 25 #not *iter_size
backend: LMDB
}
}
layer { //第一个卷积层,缩小输入图像,提取96维特征
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 64
kernel_size: 3
stride: 2
weight_filler {
type: "xavier"
}
}
}
layer { //RELU层
name: "relu_conv1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1" //第一个Max Pooling层,降采样,缩小一半
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer { //第一个fire模块,模块内先用squeeze层减少通道数,再用expand层增加通道数
name: "fire2/squeeze1x1"
type: "Convolution"
bottom: "pool1"
top: "fire2/squeeze1x1"
convolution_param {
num_output: 16
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire2/relu_squeeze1x1"
type: "ReLU"
bottom: "fire2/squeeze1x1"
top: "fire2/squeeze1x1"
}
layer {
name: "fire2/expand1x1"
type: "Convolution"
bottom: "fire2/squeeze1x1"
top: "fire2/expand1x1"
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire2/relu_expand1x1"
type: "ReLU"
bottom: "fire2/expand1x1"
top: "fire2/expand1x1"
}
layer {
name: "fire2/expand3x3"
type: "Convolution"
bottom: "fire2/squeeze1x1"
top: "fire2/expand3x3"
convolution_param {
num_output: 64
pad: 1 //增加一个像素边界,是的1x1和3x3filter对齐
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire2/relu_expand3x3"
type: "ReLU"
bottom: "fire2/expand3x3"
top: "fire2/expand3x3"
}
layer {
name: "fire2/concat"
type: "Concat"
bottom: "fire2/expand1x1"
bottom: "fire2/expand3x3"
top: "fire2/concat"
}
layer {
name: "fire3/squeeze1x1"
type: "Convolution"
bottom: "fire2/concat"
top: "fire3/squeeze1x1"
convolution_param {
num_output: 16
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire3/relu_squeeze1x1"
type: "ReLU"
bottom: "fire3/squeeze1x1"
top: "fire3/squeeze1x1"
}
layer {
name: "fire3/expand1x1"
type: "Convolution"
bottom: "fire3/squeeze1x1"
top: "fire3/expand1x1"
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire3/relu_expand1x1"
type: "ReLU"
bottom: "fire3/expand1x1"
top: "fire3/expand1x1"
}
layer {
name: "fire3/expand3x3"
type: "Convolution"
bottom: "fire3/squeeze1x1"
top: "fire3/expand3x3"
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire3/relu_expand3x3"
type: "ReLU"
bottom: "fire3/expand3x3"
top: "fire3/expand3x3"
}
layer {
name: "fire3/concat"
type: "Concat"
bottom: "fire3/expand1x1"
bottom: "fire3/expand3x3"
top: "fire3/concat"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "fire3/concat"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fire4/squeeze1x1"
type: "Convolution"
bottom: "pool3"
top: "fire4/squeeze1x1"
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire4/relu_squeeze1x1"
type: "ReLU"
bottom: "fire4/squeeze1x1"
top: "fire4/squeeze1x1"
}
layer {
name: "fire4/expand1x1"
type: "Convolution"
bottom: "fire4/squeeze1x1"
top: "fire4/expand1x1"
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire4/relu_expand1x1"
type: "ReLU"
bottom: "fire4/expand1x1"
top: "fire4/expand1x1"
}
layer {
name: "fire4/expand3x3"
type: "Convolution"
bottom: "fire4/squeeze1x1"
top: "fire4/expand3x3"
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire4/relu_expand3x3"
type: "ReLU"
bottom: "fire4/expand3x3"
top: "fire4/expand3x3"
}
layer {
name: "fire4/concat"
type: "Concat"
bottom: "fire4/expand1x1"
bottom: "fire4/expand3x3"
top: "fire4/concat"
}
layer {
name: "fire5/squeeze1x1"
type: "Convolution"
bottom: "fire4/concat"
top: "fire5/squeeze1x1"
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire5/relu_squeeze1x1"
type: "ReLU"
bottom: "fire5/squeeze1x1"
top: "fire5/squeeze1x1"
}
layer {
name: "fire5/expand1x1"
type: "Convolution"
bottom: "fire5/squeeze1x1"
top: "fire5/expand1x1"
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire5/relu_expand1x1"
type: "ReLU"
bottom: "fire5/expand1x1"
top: "fire5/expand1x1"
}
layer {
name: "fire5/expand3x3"
type: "Convolution"
bottom: "fire5/squeeze1x1"
top: "fire5/expand3x3"
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire5/relu_expand3x3"
type: "ReLU"
bottom: "fire5/expand3x3"
top: "fire5/expand3x3"
}
layer {
name: "fire5/concat"
type: "Concat"
bottom: "fire5/expand1x1"
bottom: "fire5/expand3x3"
top: "fire5/concat"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "fire5/concat"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fire6/squeeze1x1"
type: "Convolution"
bottom: "pool5"
top: "fire6/squeeze1x1"
convolution_param {
num_output: 48
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire6/relu_squeeze1x1"
type: "ReLU"
bottom: "fire6/squeeze1x1"
top: "fire6/squeeze1x1"
}
layer {
name: "fire6/expand1x1"
type: "Convolution"
bottom: "fire6/squeeze1x1"
top: "fire6/expand1x1"
convolution_param {
num_output: 192
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire6/relu_expand1x1"
type: "ReLU"
bottom: "fire6/expand1x1"
top: "fire6/expand1x1"
}
layer {
name: "fire6/expand3x3"
type: "Convolution"
bottom: "fire6/squeeze1x1"
top: "fire6/expand3x3"
convolution_param {
num_output: 192
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire6/relu_expand3x3"
type: "ReLU"
bottom: "fire6/expand3x3"
top: "fire6/expand3x3"
}
layer {
name: "fire6/concat"
type: "Concat"
bottom: "fire6/expand1x1"
bottom: "fire6/expand3x3"
top: "fire6/concat"
}
layer {
name: "fire7/squeeze1x1"
type: "Convolution"
bottom: "fire6/concat"
top: "fire7/squeeze1x1"
convolution_param {
num_output: 48
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire7/relu_squeeze1x1"
type: "ReLU"
bottom: "fire7/squeeze1x1"
top: "fire7/squeeze1x1"
}
layer {
name: "fire7/expand1x1"
type: "Convolution"
bottom: "fire7/squeeze1x1"
top: "fire7/expand1x1"
convolution_param {
num_output: 192
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire7/relu_expand1x1"
type: "ReLU"
bottom: "fire7/expand1x1"
top: "fire7/expand1x1"
}
layer {
name: "fire7/expand3x3"
type: "Convolution"
bottom: "fire7/squeeze1x1"
top: "fire7/expand3x3"
convolution_param {
num_output: 192
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire7/relu_expand3x3"
type: "ReLU"
bottom: "fire7/expand3x3"
top: "fire7/expand3x3"
}
layer {
name: "fire7/concat"
type: "Concat"
bottom: "fire7/expand1x1"
bottom: "fire7/expand3x3"
top: "fire7/concat"
}
layer {
name: "fire8/squeeze1x1"
type: "Convolution"
bottom: "fire7/concat"
top: "fire8/squeeze1x1"
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire8/relu_squeeze1x1"
type: "ReLU"
bottom: "fire8/squeeze1x1"
top: "fire8/squeeze1x1"
}
layer {
name: "fire8/expand1x1"
type: "Convolution"
bottom: "fire8/squeeze1x1"
top: "fire8/expand1x1"
convolution_param {
num_output: 256
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire8/relu_expand1x1"
type: "ReLU"
bottom: "fire8/expand1x1"
top: "fire8/expand1x1"
}
layer {
name: "fire8/expand3x3"
type: "Convolution"
bottom: "fire8/squeeze1x1"
top: "fire8/expand3x3"
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire8/relu_expand3x3"
type: "ReLU"
bottom: "fire8/expand3x3"
top: "fire8/expand3x3"
}
layer {
name: "fire8/concat"
type: "Concat"
bottom: "fire8/expand1x1"
bottom: "fire8/expand3x3"
top: "fire8/concat"
}
layer {
name: "fire9/squeeze1x1"
type: "Convolution"
bottom: "fire8/concat"
top: "fire9/squeeze1x1"
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire9/relu_squeeze1x1"
type: "ReLU"
bottom: "fire9/squeeze1x1"
top: "fire9/squeeze1x1"
}
layer {
name: "fire9/expand1x1"
type: "Convolution"
bottom: "fire9/squeeze1x1"
top: "fire9/expand1x1"
convolution_param {
num_output: 256
kernel_size: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire9/relu_expand1x1"
type: "ReLU"
bottom: "fire9/expand1x1"
top: "fire9/expand1x1"
}
layer {
name: "fire9/expand3x3"
type: "Convolution"
bottom: "fire9/squeeze1x1"
top: "fire9/expand3x3"
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
}
}
layer {
name: "fire9/relu_expand3x3"
type: "ReLU"
bottom: "fire9/expand3x3"
top: "fire9/expand3x3"
}
layer {
name: "fire9/concat"
type: "Concat"
bottom: "fire9/expand1x1"
bottom: "fire9/expand3x3"
top: "fire9/concat"
}
layer {
name: "drop9" //最后一个fire模块后,增加一个Dropout层
type: "Dropout"
bottom: "fire9/concat"
top: "fire9/concat"
dropout_param {
dropout_ratio: 0.5 //丢弃率为50%
}
}
layer { //第二个卷积层,为图的每个像素预测1000个分类
name: "conv10"
type: "Convolution"
bottom: "fire9/concat"
top: "conv10"
convolution_param {
num_output: 1000
kernel_size: 1
weight_filler {
type: "gaussian"
mean: 0.0
std: 0.01
}
}
}
layer {
name: "relu_conv10"
type: "ReLU"
bottom: "conv10"
top: "conv10"
}
layer { //average pooling层得到1000类
name: "pool10"
type: "Pooling"
bottom: "conv10"
top: "pool10"
pooling_param {
pool: AVE
global_pooling: true
}
}
layer { //softmax层,使用softmax函数归一化为概率
name: "loss"
type: "SoftmaxWithLoss"
bottom: "pool10"
bottom: "label"
top: "loss"
#include {
# phase: TRAIN
#}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "pool10"
bottom: "label"
top: "accuracy"
#include {
# phase: TEST
#}
}
layer {
name: "accuracy_top5"
type: "Accuracy"
bottom: "pool10"
bottom: "label"
top: "accuracy_top5"
#include {
# phase: TEST
#}
accuracy_param {
top_k: 5
}
}















 954
954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









