





文章标题:A graph-based semi-supervised reject inference framework considering imbalanced data distribution for consumer credit scoring
作者:Yanzhe Kang, Ning Jia , Runbang Cui, Jiang Deng
期刊:Applied Soft Computing Journal 105 (2021) 107259
摘要
信用评分在中国消费金融业引起了越来越多的关注。传统的方法很容易受到样本选择偏差的影响,因为它们只使用被接受的申请人样本,而申请人群体也包括被拒绝的申请人。拒绝推论(Reject Inference)是一种为被拒绝的申请人推断好/坏标签的技术,可以克服信用评分上的偏见。然而,先前提出的拒绝推论方法常会忽略所接受数据中的不平衡分布,这意味着在大多数实际的消费贷款申请中,好的申请者比坏的申请者多很多。对拒绝数据的忽视和接受数据的不平衡分布都削弱了当前信用评分模型的性能。在本文中,我们提出了一个新的拒绝推论框架,考虑了消费者信用评分的不平衡数据分布。首先,我们使用一种先进的基于图的半监督学习算法来解决拒绝推论问题,即标签扩散(label spreading)。其次,面对接受申请人的好样本和坏样本分布不平衡,我们在拒绝推理之前使用改进的合成少数群体过采样技术(Synthetic Minority Over-sampling Technique)进行不平衡学习。然后,在我们提出的信用评分建模框架中,研究了六个二分类模型。最后,我们使用中国一家领先的金融技术公司提供的数据,展示了四个精确的实验以及所提出框架的性能和鲁棒性A/B测试。实验结果表明,该框架在不同的评分指标上表现优于传统的评分模型,代表了一种促进信用评分研究和改进金融技术实践的渐进式方式。
1 引言
本文提出一个基于图的半监督RI框架,该框架考虑了消费信用评分中不平衡的数据分布。首先,使用一种改进的合成少数群体过采样技术,称为边界覆盖,对不平衡的接受数据进行过采样,并获得RI的平衡训练数据集。其次,基于这个重新平衡的数据集,我们使用被拒绝申请人的标签传播算法来解决RI问题。这两者都促进了RI研究。第三,我们将两个行业基准模型和四个基于树的集成学习模型用于基础分类器来训练信用评分模型。最后,我们提出了四个精确的实验,以及所提出框架的性能和鲁棒性A/B测试。实验结果表明,该框架在不同的评估指标上的表现优于比较评分模型,代表了一种渐进的信用评分方法,丰富了信用评分研究,促进了良好的金融技术实践。
本文的其余部分组织如下。首先,第二节提供了相关研究的文献综述。然后,在第三节中介绍了我们的新框架的方法,其中详细介绍了标签扩展和边界覆盖算法。第四节介绍了实验设计,第五节介绍了实验结果和讨论。最后,在第六节中讨论了未来工作的结论和方向。
2 文献综述
3 准备工作
消费者贷款实践中使用的数据结构,如图所示

贷款申请人可分为两部分:允许借款的申请人,不能拒绝借款的申请人。我们可以知道被接受的申请人是否会根据他们的偿还表现来全额偿还贷款,所以这些数据有好/坏的分类标签。我们不知道被拒绝的申请人是如何表现的,所以他们没有标签。如果信用风险管理是合理的,好的申请人远多于坏的申请人。因此,贷款申请人包括标记和未标记的数据,而且标签数据的分布不平衡。
3.1 标签扩散(label spreading)
标签扩散是一种最先进的基于图的半监督学习算法。它是基于两个一致性先验的假设。首先,附近的点可能有相同的标签,也称为局部假设,另一个是全局假设,这意味着相同结构上的可能有相同的标签。这些假设构成了基于图的半监督学习算法的基本思想。它已被证明在许多现实问题中是一种有效的方法。考虑到这些有希望的结果,我们试图试探其在RI问题中的有效性。
首先,我们使用半监督学习方法来描述RI问题。让 D L D_L DL={( x i x_i xi, y i y_i yi)|i=1,…,l}成为被接受的申请人,或者说, D L D_L DL是已标记数据集。 Y L Y_L YL={ y 1 y_1 y1,…, y l y_l yl)∈{0,1}}表示信用评分中的分类标签,其中0代表好申请人,1代表坏申请人。让 D U D_U DU={( x i x_i xi, y i y_i yi)|i=l+1,…,l+u}成为被拒绝的申请人,也就是他们没有标签, Y U Y_U YU={ y l + 1 y_{l+1} yl+1,…, y l + u y_{l+u} yl+u)∈{0,1}}是被拒绝申请者需要被预测的标签。使得 X L + U X_{L+U} XL+U={ x l + 1 x_{l+1} xl+1,…, x l + u x_{l+u} xl+u})∈ R L + U R^{L+U} RL+U,它结合了已标记数据集和未标记数据集的特征。RI问题可以从 X L + U X_{L+U} XL+U和 Y L Y_L YL转换为 Y U Y_U YU的估计。
标签传播的主要思想是在图上传播标签。基于这两个相似性假设,我们创建了一个全连接图g,其中节点N={1,…,n}都是 X L + U X^L+U XL+U中的数据点。图g中的边E代表节点之间的示例相似之处。这些相似性的值由亲和矩阵W给出,E中的边缘(i,j)用 w i j w_ij wij进行加权。
考虑到在数据特征维数中可能包含共线性,本文利用宽度为
σ
\sigma
σ的高斯核节点i和j之间的Mahalanobis距离
∣
∣
||
∣∣x_i
−
-
−x_j
∣
∣
M
||_M
∣∣M定义了亲和矩阵W中的每个
w
i
j
w_ij
wij。
w
i
j
=
e
x
p
(
−
∣
∣
x
i
−
x
j
∣
∣
M
2
2
σ
2
)
=
e
x
p
[
−
(
x
i
−
x
j
)
T
∑
−
1
(
x
i
−
x
j
)
2
σ
2
]
w_{ij}=exp(-\frac{||x_i-x_j||_M^2}{2\sigma^2})=exp[-\frac{(x_i-x_j)^T∑^{-1}(x_i-x_j)}{2\sigma^2}]
wij=exp(−2σ2∣∣xi−xj∣∣M2)=exp[−2σ2(xi−xj)T∑−1(xi−xj)]
这个距离测度的定义是对原始标签扩展算法的一个改进,其中使用了欧几里得距离。需要指出的是,如果经过仔细的数据预处理操作,如主成分分析(PCA),则将每个主分量轴重新调整为具有单位方差,则将变换空间中的Mahalanobis距离降低到标准欧几里得距离。因此,如果特征是独立同分布的,并且不贡献,欧几里得距离可以直接使用。
注意:当且仅当 x i x_i xi和 x j x_j xj是“邻居”时, w i j = w j i w_{ij}=w_{ji} wij=wji并且都是非零的。因此,我们有 w i i = 0 w_{ii}=0 wii=0。假设一个节点的标签可以通过边缘传播到所有的节点,节点越近,权重就越大,即标签可以传播得更容易。
从标签已知的节点开始,标签扩展算法作为一个迭代过程进行。每个未标记节点的标签值由其相邻节点及其初始值贡献。经过几次迭代后,将确认这些未标记节点的最终标签。给出了RI详细标签扩展算法作为Algorithm1。
Algorithm 1 Label spreading algorithm for RI
Input: X L + U X_{L+U} XL+U, Y L Y_L YL, Y U Y_U YU
Output: 对应于 X L + U X_{L+U} XL+U的类标签 Y ^ ∗ \hat{Y}^{*} Y^∗
1.计算亲和矩阵W中i≠j的每个 w i j w_{ij} wij
2.计算一个对角矩阵V,其中 v i j = ∑ j w i j v_{ij}=\sum_jw_{ij} vij=∑jwij
3.给定一个clapping factor α∈(0,1)
4.定义矩阵 S = V − 1 2 W V 1 2 S=V^{-\frac{1}{2}}WV^{\frac{1}{2}} S=V−21WV21,即归一化拉普拉斯量
5.标记和未标记数据 Y ^ = ( y 1 , . . . , y l , y l + 1 , . . . , y l + u ) \hat{Y}=(y_1,...,y_l,y_{l+1},...,y_{l+u}) Y^=(y1,...,yl,yl+1,...,yl+u),即 Y ^ = Y L + Y U \hat{Y}=Y_L+Y_U Y^=YL+YU
6.初始化 0 ^ = ( y 1 , . . . , y l , 0 , . . . , 0 ) \hat{0}=(y_1,...,y_l,0,...,0) 0^=(y1,...,yl,0,...,0)
7.迭代 Y ^ ( t + 1 ) = α S Y ^ ( t ) + ( 1 − α ) Y ^ ( 0 ) \hat{Y}(t+1)=αS\hat{Y}(t)+(1-α)\hat{Y}(0) Y^(t+1)=αSY^(t)+(1−α)Y^(0),直到收敛
8.在 Y ^ ∗ \hat{Y}^{*} Y^∗中使用相应的标签 y i ∗ y_i^{*} yi∗来标记每个点 x i x_i xi
结果表明,给定概率亲和力矩阵W和已接受申请人的标签,该算法迭代更新未标记数据。一个问题是,这种操作可能涉及大量的计算。因此,在以下部分中,我们证明了该操作的收敛性。我们证明了序列 Y ^ ( t ) \hat{Y}(t) Y^(t)收敛, Y ^ ( t ) \hat{Y}(t) Y^(t)的极限是 Y ^ ∗ = ( 1 − α ) ( I − α S ) Y ^ ( 0 ) \hat{Y}^*=(1-\alpha)(I-\alpha S)\hat{Y}(0) Y^∗=(1−α)(I−αS)Y^(0),其中I是一个单位矩阵。
通过在步骤(6)中使用的迭代方程
Y
^
(
t
+
1
)
=
α
S
Y
^
(
t
)
+
(
1
−
α
)
Y
^
(
0
)
\hat{Y}(t+1)=αS\hat{Y}(t)+(1-α)\hat{Y}(0)
Y^(t+1)=αSY^(t)+(1−α)Y^(0),我们有:
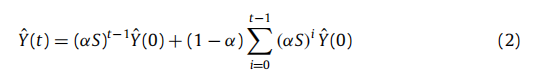
请注意,该矩阵S类似于随机矩阵
P
=
D
−
1
W
=
D
−
1
/
2
S
D
1
/
2
P=D^{-1}W=D^{-1/2}SD^{1/2}
P=D−1W=D−1/2SD1/2,即他们具有相同的特征值。由于P是一个公式的随机矩阵,它的特征值在[-1,1]之间,考虑到α∈(0,1),αS的特征值在(-1,1)。因此
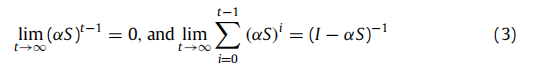
因此,
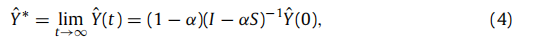
现在我们可以通过计算
I
−
α
S
I-αS
I−αS的逆来得到
Y
^
∗
\hat{Y}^*
Y^∗。
为了减轻过拟合问题,标签扩展算法为上述迭代算法引入了一个正则化框架。损失函数见式(5),其中λ>0是正则化参数。
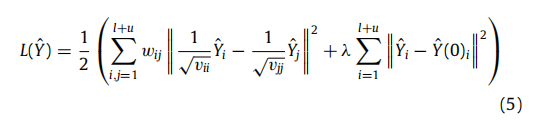
该损失函数可以分为两个加权约束:第一个是平滑约束,这表明一个良好的分类函数在相邻样本之间不应变化太大。第二个是拟合约束,这意味着分类函数不应该与初始标签分配有显著差异。参数λ捕获了这两个相互竞争的约束条件之间的权衡。然后,通过求解等式(6)中的一个最小化问题,得到了
Y
^
∗
\hat{Y}^*
Y^∗。我们相信,标签扩展可以通过这个正则化框架来适应RI问题,这有助于我们提出的框架。

3.2 Borderline-SMOTE
在RI的实践中,被拒绝的申请人标签是通过被接受的数据推断出来的,其中包括两种被接受的申请人,拖欠或全额支付。这两个类构成了一个二元分类问题。然而,它们通常分布不平衡,坏申请者的数量通常比号申请人的数量少的多。在学习不平衡的背景下,坏申请者被称为少数类,而好的被称为多数类。为了克服分类模型学习中的偏差,过去几年提出了各种不平衡学习算法,边界覆盖算法就是其中之一。为了做一个具体的介绍,我们在下面建立了一些符号。
为了更清楚地解释边界覆盖算法,我们使用 D A D_A DA来描述已接受的申请人数据,这与3.1中的 D L D_L DL含义相同。给定 D A = ( x i , y i ) ∣ i = 1 , . . . , m D_A={(x_i,y_i)|i=1,...,m} DA=(xi,yi)∣i=1,...,m有m个例子, D A D_A DA中的每个 x i x_i xi都构成一个n维特征空间X中的实例。Y是由 y i y_i yi组成的标签向量,与已识别的实例 x i x_i xi相关联。Y有可能是0或1,它们代表好申请人和坏申请人。考虑不平衡分布,我们定义了两个子集, D A m i n ⊂ D A D_{Amin}⊂D_A DAmin⊂DA和 D A m a j ⊂ D A D_{Amaj}⊂D_A DAmaj⊂DA,其中 D A m i n D_{Amin} DAmin是 D A D_A DA中的少数类(坏)例子的数据集, D A m a j D_{Amaj} DAmaj是多数类(好)例子的数据集。请注意, D A m i n ∪ D A m a j = D A D_{Amin}∪D_{Amaj}=D_A DAmin∪DAmaj=DA, D A m i n ∩ D A m a j = 0 D_{Amin}∩D_{Amaj}=0 DAmin∩DAmaj=0。
Borderline-SMOTE是SMOTE技术的改进,是一种广泛使用的过采样方法。SMOTE的主要思想是在少数类中插入一些虚拟的例子,形成平衡分布。它假设如果两个真实的少数类示例彼此相似,则可以在它们之间创建虚拟的少数类示例。这种相似性可以通过特征空间中的距离测量来定义,如欧几里得距离。由于少数的例子彼此不同,我们可以在特征空间中创建许多人工合成的少数例子。
具体来说,要基于给定的少数示例
x
i
∈
D
A
m
i
n
x_i∈D_{Amin}
xi∈DAmin创建一个合成的少数示例
x
n
e
w
x_new
xnew,步骤如下。首先,找到
x
i
∈
D
A
m
i
n
x_i∈D_{Amin}
xi∈DAmin的k个最近邻。注意,
x
i
∈
D
A
m
i
n
x_i∈D_{Amin}
xi∈DAmin的k个最近邻是
D
A
m
i
n
D_{Amin}
DAmin的k个例子,它们到
x
i
x_i
xi的欧几里得距离在特征空间X中是最小的(k是一个指定的整数)。其次,随机选择k个最近邻中的一个邻居,表示为
x
i
∗
x_i^*
xi∗。第三,计算
x
i
x_i
xi和
x
i
∗
x_i^*
xi∗之间的特征向量差。第四,乘以[0,1]之间的随机实数σ,并将该项加到
x
i
x_i
xi中。然后,合成的少数
x
n
e
w
x_{new}
xnew可以被描述为式(7):

我们看到
x
n
e
w
x_{new}
xnew是沿着
x
i
x_i
xi和随机选择的最近邻
x
i
∗
x_i^*
xi∗之间线段的一个点。这样,通过考虑选择不同的
x
i
x_i
xi,可以重复创建合成的少数群体例子,直到平衡。
虽然SMOTE算法已经显示出许多良好的好处,但该算法仍然有缺点,如过泛化。这主要受到它创建合成样本的方式的限制。事实上,SMOTE为每个原始的少数族例子生成相同数量的合成数据样本,但只考虑少数人邻居例子的分布。如果一个随机选择的邻居接近一些大多族例子,这个合成的例子可能更类似于大多族例子,特别是当它位于少数族和多数族之间的边界附近时。因此,两类之间重叠的情况增加。
例如,在图2中,示例1是使用两个少数族样本创建的合成样本,我们看到它更有可能留在少数族,因为它的邻居大多是少数族。然而,虽然示例2和3是由少数族创建的和成样本,但它们更类似于多数族,因为它们非常接近一些多数族。因此,我们看到,SMOTE的样本生成机制存在一些局限性。

作为一种改进的过采样方法,Borderline-SMOTE被提出来克服限制,因为它区分一个合成样本是否属于少数族。具体而言,这可以通过如下实现:
首先,在 D A D_A DA中找到每个 x i ∈ D A m i n x_i∈D_{Amin} xi∈DAmin的p最近邻,并用 D i : p D_{i:p} Di:p来表述它们。第二,对于每个 x i x_i xi,确定属于多数族的最近邻数,即获取 ∣ D i : p ∩ D A m i n ∣ |D_{i:p}∩D_{Amin}| ∣Di:p∩DAmin∣的值,并表示这些属于 D i : p ∩ D A m i n D_{i:p}∩D_{Amin} Di:p∩DAmin的邻居为 x i : p m a j x_{i:pmaj} xi:pmaj。第三,对于每个 x i x_i xi,考虑以下情况:
如果
∣
D
i
:
p
∩
D
A
m
i
n
∣
|D_{i:p}∩D_{Amin}|
∣Di:p∩DAmin∣满足式(8),将
x
i
x_i
xi定义为“危险”样本;

如果
∣
D
i
:
p
∩
D
A
m
i
n
∣
|D_{i:p}∩D_{Amin}|
∣Di:p∩DAmin∣满足式(9),将
x
i
x_i
xi定义为“安全”样本;

如果
∣
D
i
:
p
∩
D
A
m
i
n
∣
|D_{i:p}∩D_{Amin}|
∣Di:p∩DAmin∣满足式(10),将
x
i
x_i
xi定义为“噪音”样本;
最后,“危险”样本被用于基于原始SMOTE在边界附近创建合成的样本,这意味着
D
A
m
i
n
D_{Amin}
DAmin中每个“危险”样本的k个最近邻,并随机选择一个样本进行插值。
根据式(8)可知,如果 x i x_i xi的多数族邻居多于少数族邻居,那么它就会被表示为“危险”。此外,我们认为,位于少数族和多数族边界上的危险集对于模型优化有更有价值的信息,因为它们更有可能被错误分类。此外,应该注意的是,如果 x i x_i xi的所有k近邻都是多数族样本,那么这个 x i x_i xi被视为“噪音”样本,因为它们总是被错误分类,即没有生成合成样本。
我们提供了一个例子来说明Borderline-SMOTE算法是如何工作的。假设p最近邻数是6,图3中给出三个典型点。L点有2个少数族邻居和4个多数族邻居,所以它被标记为“危险”样本。M点有5个少数族邻居和1个多数族邻居,所以是“安全”样本。N点的邻居都是多数族样本,所以是一个“噪音”样本。比较图2和图3,可以看到SMOTE和Borderline-SMOTE之间的主要区别是,前者为所有少数族样本生成合成样本,后者只为这些更接近边界的少数族样本生成样本,即“危险”样本。
在某种程度上,这些自适应合成的样本有助于增强原始的训练集,这通常可以显著提高学习能力。因此,为了在最终预测中具有更好地性能,在我们提出的框架中,我们使用边界覆盖算法对RI所接受的申请人数据进行过采样。

3.3 基本分类器
SVM、决策树、随机森林、梯度上升决策树、XGBoost、LightGBM
3.3.1 随机森林
3.3.2 梯度上升决策树
3.3.3 XGBoost
3.3.4 LightGBM
4 构建框架
在本文中,我们提出了一种新的基于图的半监督RI框架,它考虑了训练数据的不平衡的RI分布。在这个框架中,接受(标记)和拒绝(未标记)数据都用于训练信用评分模型。
首先,使用分层抽样将所接受的数据分为两部分,初步训练样本和测试样本。这个郭长城也被称为hold-out方法,可以帮助我们通过测试性能来评估我们的框架。然后,考虑到标记初步训练样本的不平衡分布可能影响RI的有效性,利用Borderline-SMOTE通过抽样进行重新平衡,从而避免丢失多数族的过多信息。此外,通过随机抽样生成一个被拒绝的样本数据集,并将这些数据添加到平衡的初步训练样本中,这两个样本集构成了一个具有标记和未标记数据的组合训练样本集。此外,我们还使用标签扩散算法来腿短未标记数据的标签。最后,使用一个已获得所有标签的训练数据集来训练基础分类器进行信用评分建模。因此,可以使用所提出的框架来预测消费贷款新申请人的还款表现。算法2和图4给出详细过程。
Algorithm 2 Graph-based semi-supervised RI framework for imbalanced data distribution
Input: 已接收数据集 D L D_L DL,被拒绝数据集 D U D_U DU
Output: 预测结果 Y ^ L T E \hat{Y}_L^{TE} Y^LTE
1.将 D L D_L DL分为初步训练集 D L P T A D_L^{PTA} DLPTA和测试集 D L T E D_L^{TE} DLTE
2.随机采样 D U D_U DU,然后获得大小为S的 D U : S D_{U:S} DU:S
3.使用Borderline-SMOTE过采样 D L P T A D_L^{PTA} DLPTA来获得 B D L P T A BD_L^{PTA} BDLPTA
4.将 B D L P T A BD_L^{PTA} BDLPTA和 D U : S D_{U:S} DU:S组合为 D R D_R DR
5.在 D R D_R DR中扩展标签,然后获得最终的训练集 D L T A D_L^{TA} DLTA
6.选择一个基础分类器,并训练 D L T A D_L^{TA} DLTA进行信用评分
7.生成对测试数据 D L T E D_L^{TE} DLTE的预测,然后得到 Y ^ L T E \hat{Y}_L^{TE} Y^LTE

具体说,给定一个标记为
D
L
D_L
DL的不平衡接收数据及和一个未标记的拒绝数据集
D
U
D_U
DU,该框架的第一步是使用hold-out方法将
D
L
D_L
DL划分为训练集
D
L
P
T
A
D_L^{PTA}
DLPTA和测试集
D
L
T
E
D_L^{TE}
DLTE。第二部是使用随机抽样来生成一个被拒绝的数据集
D
U
:
S
D_{U:S}
DU:S,
D
U
:
S
D_{U:S}
DU:S的大小是一个给定数字S。接下来,我们使用边界覆盖算法对少数族进行过采样,以获得一个平衡的初步训练数据集
B
D
L
P
T
A
BD_L^{PTA}
BDLPTA。然后,我们结合
B
D
L
P
T
A
BD_L^{PTA}
BDLPTA和D,得到一个训练数据集
D
R
D_R
DR。为了推断
D
U
:
S
D_{U:S}
DU:S的标签,我们使用标签扩展算法训练
D
R
D_R
DR。因此,我们得到了一个最终的训练数据集
D
L
T
A
D_L^{TA}
DLTA,所有的样本都有标记,并选择了一个基础分类器来训练一个有效的信用评分模型。最后,利用测试集来推断预测结果。

图5(a)说明了具有大量未标记数据的不平衡的申请人数据。图5(b)说明了Borderline-SMOTE算法如何生成合成的少数族样本。图5(c)说明了Borderline-SMOTE过采样后的平衡数据。图5(d)说明了标签扩展后的信用评分最终训练数据。
我们相信,Borderline-SMOTE和标签扩展的影响可以增强基础分类器的学习。在第四节中,我们给出了一个详细的评估。此外,我们认为被拒绝集的样本大小会影响最终信用评分模型的性能。实证分析的结果见第5节。
5 实验
5.1 数据集
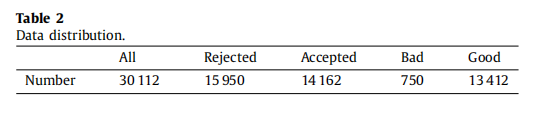
该数据集涵盖了从2015年3月1日至2017年3月31日的30,112个贷款例子。如表2所示有15950个拒绝例和14162个接受例,拒绝率为112.6%。在这些被接受的申请者中,750名连续三次每月付款的人被贴上“坏”的标签,而13,412名根据合同支付费用的申请人被贴上了“好”的标签,其不平衡比例为1:17.88。我们知道,在这个特定的财务情况下,被拒绝的族明显比被接受的族要大,所以RI是相当重要的。此外,这个数据集的不平衡比率确实比公开的数据集要大得多,比如来自UCI机器学习存储库的德国和澳大利亚的数据集,这使得我们的研究更能代表现实生活中的应用程序。
被接受的申请人数据集包括具有100多个好/坏标签的贷款申请人的个人信息和还款表现,而对于被拒绝的,有22个特征包含11个连续特征和11个离散特征,但既没有好/坏标签或还款表现。因此,连续特征和离散特征之间的共同特征是这22个特征。考虑到数据保密性的保护,并符合公司的规定,我们进行了一些修改,并将连续特征更名为FC,并将离散特征更名为FD。以下是对这些功能的简要描述:
FC0:所购汽车的价格
FC1:贷款金额
FC2:汽车价格与贷款之比
FC3:贷款利息
FC4:贷款期
FC5:工作年限
FC6:年龄
FC7:月收入
FC8、FC9、FC10:个人地址信息
FD0:性别
FD1:教育水平
FD2:住房状况
FD3:单元类型
FD4:工作岗位
FD5:居住省
FD6:还款方式
FD7:婚姻状况
FD8、FD9、FD10:亲属信息
5.2 模型评价
为了探讨该框架的有效性和鲁棒性,我们将其预测性能与五个基准信用评分模型进行了比较。这些模型使用不同的方法来处理被接受和被拒绝的数据,如“定义为坏”的RI方法和外推法。然后,使用不同的基分类器对每个模型进行训练。模型,并按表4进行比较。

Benchmark model (BM). BM是一种传统的信用评分模型(二分类),学习使用接受坏的和好的申请者。换句话说,被拒绝的数据不包括在BM模型中。此外,该模型没有使用不平衡的学习方法,因此由于使用原始数据,接受数据中好群和坏群的分布是不平衡的。
RI using ‘‘Define as bad’’ (RI-DAB). RI-DAB模型使用名为“定义为坏值”的RI方法,即。被拒绝的样本都被标记为坏的,然后添加到已接受的数据中。不使用不平衡的学习方法。
RI using extrapolation (RI-EXP). RI-EXP模型使用名为“外推”的RI方法,它根据从被接受的申请者那里学到的评分模型为拒绝者分配好-坏标签。然后就可以估计一个通常的信用评分模型。这里也没有使用不平衡的学习方法。
RI using label spreading (RI-LS). RI-LS模型使用半监督学习算法标签扩展来处理被拒绝数据的RI,而无需不平衡学习。
Proposed RI framework based on Borderline-SMOTE and label spreading (RI-BSLS). RI-BSLS是我们提出的新的信用评分框架,它使用了一个过采样的接受数据集和一个随机采样的拒绝数据子集。接下来是一个二元分类模型的训练。
考虑到我们实验的全面性,我们设计了另一个基准模型(BM-BS),其中不平衡的接受数据使用Borderline-SMOTE采样到平衡数据集,然后用于训练没有任何拒绝数据的二进制分类器。该模型旨在测试分类性能的提高是否是因为RI,而仅仅是因为学习不平衡。
5.3 实验设计

步骤1:数据预处理。 对于具有已接受和已拒绝申请人的实验原始数据集,我们在每个特征中填充缺失的值,然后对离散特征进行One-hot编码。最后,对每个特征都应用了规范化。
步骤2:数据采样。 采用hold-out方法划分已接受的数据,使80%的数据用于预训练,其余20%用于测试。分层抽样不平衡接受数据和拒绝数据之间的分布。然后,对被拒绝的数据进行随机采样,生成RI的子集。最后,将被拒绝的集合汇集到一个预训练集中,以生成RI和模型训练的训练集。
步骤3:贴上标签。 使用不同的方法对训练集中的未标记数据应用了RI。
步骤4:模型培训。 使用步骤3中准备的训练数据集构建了基础分类器。然后,对分类器的超参数进行了微调。
步骤5:预测。 将步骤4中导出的分类模型应用于测试集。
步骤6:评估。 使用六个评估指标来评估评估模型的性能。
5.4 数据预处理
首先,连续特征中缺失的值用其平均值填充。未填充离散特性中缺少的值。在实际的消费贷款场景中,离散特征中的缺失值可能意味着一些关键的个人信息。所以它们被认为是一种特殊的属性和其他属性。其次,范围超过95%的特征被删除。第三,采用one-hot对离散特征编码,即将具有N个值的属性转换为N个二进制属性。然后,利用word embedding技术将one-hot向量转换为低维连续特征。最后,为了消除不同数据分布的影响,加快学习算法的收敛速度,通过去除均值并扩展到单位方差,对所有特征进行了归一化,如式(11)。经过数据预处理后,用来学习信用评分模型的特征数为187个。

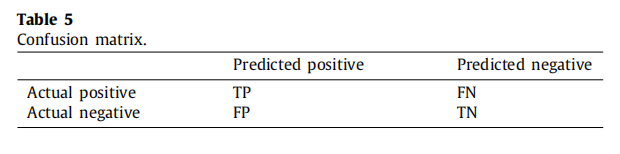
5.5 评估指标
七种常用的指标:准确性(accuracy)、精度(precision)、召回率(recall)、F1-measure、Cohen’s kappa(CK)、AUC和KS。
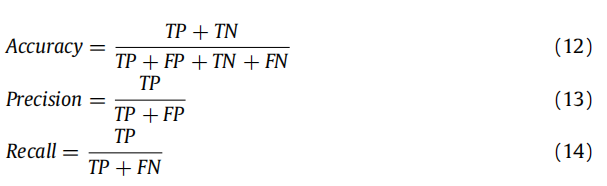
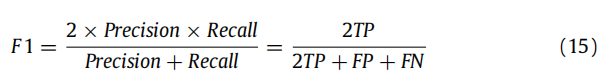

AUC,是基于ROC曲线下的面积。ROC曲线是真阳性率(TPR)和假阳性率(FPR)之间权衡的二维图形说明



另外,F1、CK、AUC和KS的值均在0和1之间。这些指标达到的范围越高,我们得到的预测性能就越好。
5.6 统计检验
利用非参数化的弗里德曼测试,比较了所有模型的排序性能。弗里德曼测试统计量是使用分类技术在不同测试数据集上的平均排名性能来计算的,定义如下:
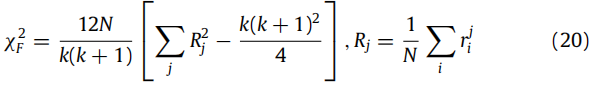
N表示本文中使用的数据集的数量。k是模型的总数。
r
j
i
r_j^i
rji是模型j在数据集i上的秩。
R
j
R_j
Rj是算法的平均秩。
χ
F
2
χ_F^2
χF2统计量是根据具有k-1自由度的卡方(χ2)分布来分布的。
弗里德曼检验的零假设是“所有的信用评分模型的表现都是相同的”,或者,“它们的平均排名是相等的”。如果被拒绝,我们应该使用事后的尼梅尼测试进行两对比较进行详细观察。如果相应的平均等级至少存在关键差异(CD),则两个信用评分模型的表现会有显著差异,定义如下:

k表示模型的数量,N表示数据集的数量,
q
α
q_α
qα可以从[P. Nemenyi, Distribution-free multiple comparisons, in: Biometrics, Vol. 18,International Biometric Soc 1441 I ST, NW, SUITE 700, WASHINGTON, DC20005-2210, 1962, p. 263.]中获得。
5.7 超参数优化
在我们提出的框架中,超参数优化被分为两部分:边界目标的调整和基础分类器的调整。请注意,当我们调整一个部分的超参数时,另一个部分的超参数会被锁定为常数值。
具体地说,在Borderline-SMOTE的调整中,有两个重要的超参数。第一个是被接受申请人的最近邻居的数量,以确定少数例子是否处于危险之中。另一个是驱动传统SMOTE算法的坏申请者k的最近邻居的数量。在调整m和k的过程中,将六个基本分类器的超参数设置为其默认值。最终结果表明,当p=9和k=10时,测试样本中的分类性能最大化,这些设置用于基础分类器的后一种优化。
我们使用网格搜索来搜索每个基分类器中的最优超参数。表6显示了六个基本分类器的搜索空间。具体来说,对于LR和SVM,惩罚参数C使用一个长度为10的指数区间进行调优,而SVM则用了一个RBF内核。此外,对于RF、GBDT、XGBoost和LightGBM,树n_estimators的数量和树max_depth的最大深度都使用1的整数间隔进行调优。然后,对于GBDT、XGBoost和LightGBM,学习速率参数learning_rate也使用0.01的小数间隔进行调整。

6 结果
6.1 使用传统分类器的实验结果
6.2 四个基于树的分类器的实验结果
6.3 对提出框架的ROC分析
6.4 重要性测试结果
6.5 拒收样本量的影响
6.6 在线A/B测试
7 研究结论及未来工作
随着我国消费金融的快速发展,信贷风险管理受到越来越多的关注。针对RI问题以及在已接受的申请人数据中的不平衡分布的影响,我们提出了一个基于图的半监督RI框架的信用评分应用。采用了一种改进的过采样边界线模拟方法和一种先进的基于图的半监督学习算法标签扩展。通过详细的实验和在线A/B测试,结果表明,它在不同的评价指标上优于比较基准,对金融技术具有重要价值。
然而,我们提出的方法也有一些局限性。首先,当使用Borderline-SMOTE算法时,生成的新的合成示例可能位于重叠区域。此外,它还可以引入额外的噪音。Borderline-SMOTE算法对高维数据不是很有效。此外,考虑到标签扩展算法涉及大量计算,应提高RI框架的计算效率。
因此,在未来的工作中,对具有改进的混合不平衡学习算法的框架研究需要进一步的探索。此外,RI框架的计算性能也应该得到提高。RI的拒绝样本量的最优选择方法是另一个研究方向。最后,需要研究改进的异构集成模型和深度学习算法,以提高预测性能。
















 5898
5898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









