







在这个任务中,词就是Graph中的节点,而词与词之间的边,则利用“共现”关系来确定。所谓“共现”,就是共同出现,即在一个给定大小的滑动窗口内的词,认为是共同出现的,而这些单词间也就存在着边,举例:“淡黄的长裙,蓬松的头发 牵着我的手看最新展出的油画”
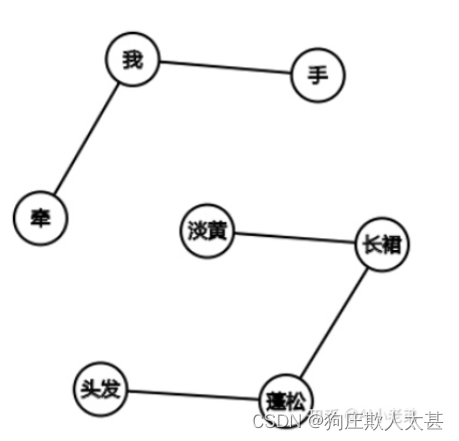
相对于PageRank里的无权有向图,这里建立的是无权无向图,原论文中对于关键词提取任务主要也是构建的无向无权图,对于有向图,论文提到是基于词的前后顺序角度去考虑,即给定窗口,比如对于“长裙”来说,“淡黄”与它之间是入边,而“蓬松”与它之间是出边,但是效果都要比无向图差。
构造好图后,剩下的就是按照PageRank的公式进行迭代计算
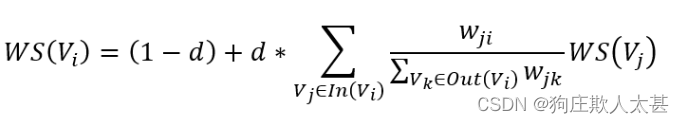
这个权重,是针对摘要任务中的句子相似度而言的。
最终效果还是不错的
from collections import OrderedDict
import numpy as np
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
nlp = spacy.load('en_core_web_sm')
class TextRank4Keyword():
"""Extract keywords from text"""
def __init__(self):
self.d = 0.85 # damping coefficient, usually is .85
self.min_diff = 1e-5 # convergence threshold
self.steps = 10 # iteration steps
self.node_weight = None # save keywords and its weight
def set_stopwords(self, stopwords):
"""Set stop words"""
for word in STOP_WORDS.union(set(stopwords)):
lexeme = nlp.vocab[word]
lexeme.is_stop = True
def sentence_segment(self, doc, candidate_pos, lower):
"""Store those words only in cadidate_pos"""
sentences = []
for sent in doc.sents:
selected_words = []
for token in sent:
# Store words only with cadidate POS tag
if token.pos_ in candidate_pos and token.is_stop is False:
if lower is True:
selected_words.append(token.text.lower())
else:
selected_words.append(token.text)
sentences.append(selected_words)
return sentences
def get_vocab(self, sentences):
"""Get all tokens"""
vocab = OrderedDict()
i = 0
for sentence in sentences:
for word in sentence:
if word not in vocab:
vocab[word] = i
i += 1
return vocab
def get_token_pairs(self, window_size, sentences):
"""Build token_pairs from windows in sentences"""
token_pairs = list()
for sentence in sentences:
for i, word in enumerate(sentence):
for j in range(i+1, i+window_size):
if j >= len(sentence):
break
pair = (word, sentence[j])
if pair not in token_pairs:
token_pairs.append(pair)
return token_pairs
def symmetrize(self, a):
return a + a.T - np.diag(a.diagonal())
def get_matrix(self, vocab, token_pairs):
"""Get normalized matrix"""
# Build matrix
vocab_size = len(vocab)
g = np.zeros((vocab_size, vocab_size), dtype='float')
for word1, word2 in token_pairs:
i, j = vocab[word1], vocab[word2]
g[i][j] = 1
# Get Symmeric matrix
g = self.symmetrize(g)
# Normalize matrix by column
norm = np.sum(g, axis=0)
g_norm = np.divide(g, norm, where=norm!=0) # this is ignore the 0 element in norm
return g_norm
def get_keywords(self, number=10):
"""Print top number keywords"""
node_weight = OrderedDict(sorted(self.node_weight.items(), key=lambda t: t[1], reverse=True))
for i, (key, value) in enumerate(node_weight.items()):
#print(key + ' - ' + str(value))
print(key)
if i > number:
break
def analyze(self, text,
candidate_pos=['NOUN', 'PROPN'],
window_size=4, lower=False, stopwords=list()):
"""Main function to analyze text"""
# Set stop words
self.set_stopwords(stopwords)
# Pare text by spaCy
doc = nlp(text)
# Filter sentences
sentences = self.sentence_segment(doc, candidate_pos, lower) # list of list of words
# Build vocabulary
vocab = self.get_vocab(sentences)
# Get token_pairs from windows
token_pairs = self.get_token_pairs(window_size, sentences)
# Get normalized matrix
g = self.get_matrix(vocab, token_pairs)
# Initionlization for weight(pagerank value)
pr = np.array([1] * len(vocab))
# Iteration
previous_pr = 0
for epoch in range(self.steps):
pr = (1-self.d) + self.d * np.dot(g, pr)
if abs(previous_pr - sum(pr)) < self.min_diff:
break
else:
previous_pr = sum(pr)
# Get weight for each node
node_weight = dict()
for word, index in vocab.items():
node_weight[word] = pr[index]
self.node_weight = node_weight
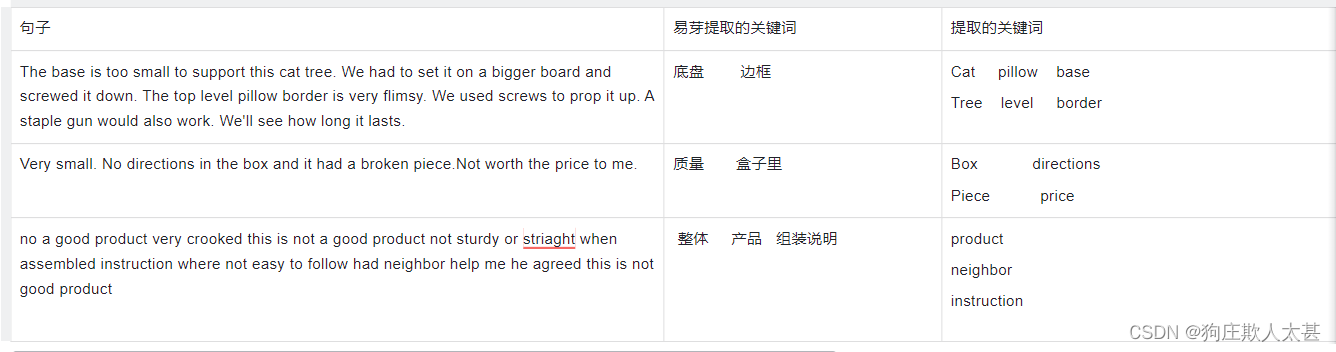
text = """
no a good product very crooked this is not a good product not sturdy or striaght when assembled instruction where not easy to follow had neighbor help me he agreed this is not good product
"""
tr4w = TextRank4Keyword()
tr4w.analyze(text, candidate_pos = ['NOUN', 'PROPN'], window_size=2, lower=False)
tr4w.get_keywords(5)














 7827
7827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









