







机器学习学习记录之sklearn特征选择SelectKBest类
首先申明本人为小白,只是为了方便记录自己的学习过程并且监督自己所写的专栏,有什么问题欢迎各位大佬在评论区指正或者讨论。另外,需要引用请注明出处(虽然不是完全原创但是也是自己辛辛苦苦查资料写的啊QAQ),谢谢。
言归正传,遇到这个函数正如标题所言是在学习特征选择时,看到知乎上的回答“机器学习中,有哪些特征选择的工程方法?”(作者:城东链接:https://www.zhihu.com/question/28641663/answer/110165221),3.1.2相关系数法部分,代码中有这样一句:
SelectKBest(lambda X, Y: array(map(lambda x:pearsonr(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
尝试直接用了一下发现“array”没有定义…
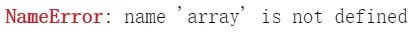
这个语句乍得一下好像也不是很明白,其中用到了lambda匿名函数,还有pearsonr函数,最关键的是SelectKBest这个类没有遇见过,所以下面我会从SelectKBest这个类怎么用开始写到对这句代码的理解以及对原始代码的错误进行修改。
SelectKBest()类
首先贴一张sklearn的官方文档链接,更详细内容可参看:https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.SelectKBest.html
SelectKBest()参数
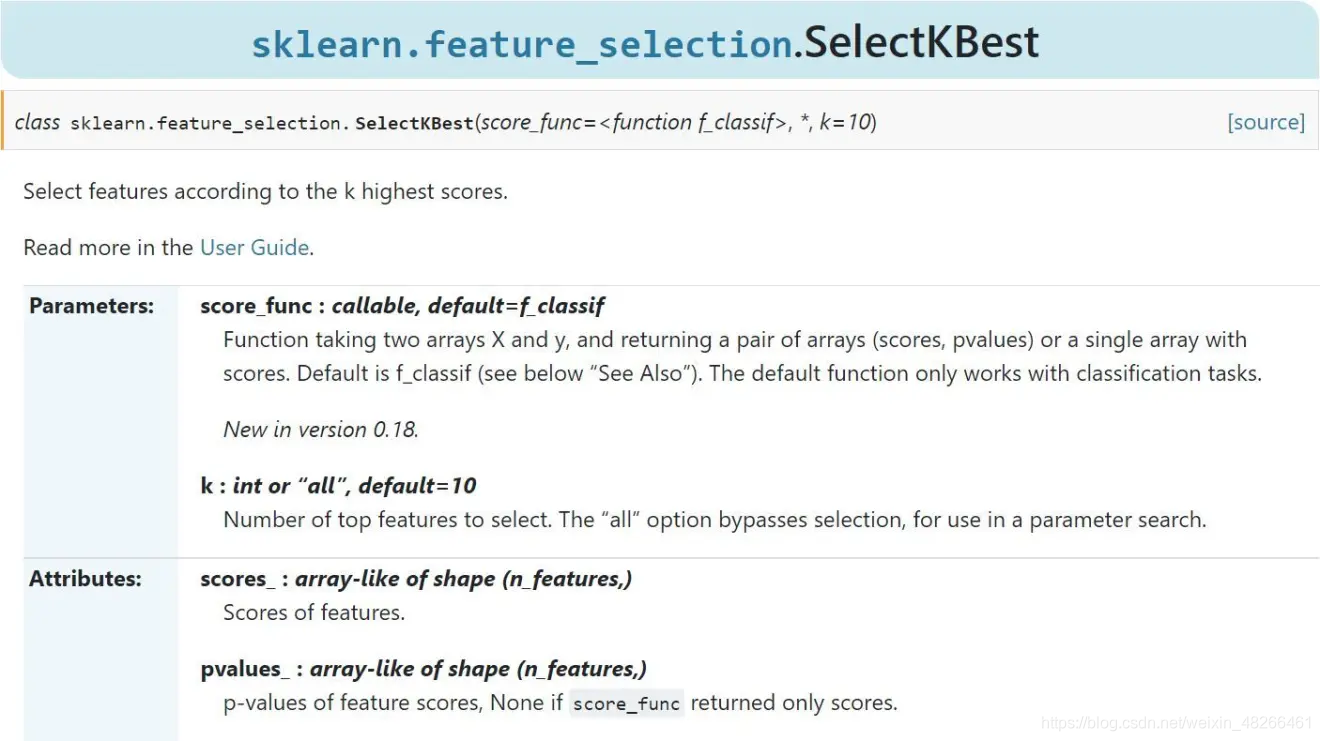
由上可以看到用法和参数以及属性,这里主要提参数。
参数共有两个,一个是score_func(往下会更详尽解析):这是一个用于打分机制的函数,函数接受两个数组X和y,并返回一对数组(scores,pvalue)或带scores的单个数组。默认值为f_classif。且默认仅适用于分类任务;一个是k:这个很好理解,需要选择的最佳特征个数(正如函数名表明的),默认值为10,填入all则用于参数搜索。

来看score_func,可调用,默认的f_classif,即利用ANOVA方法(方差分析(Analysis of Variance)又称F检验)来给特征打分,除此之外还有mutual_info_classif(基于互信息)、chi2(卡方检验)的方法来给特征打分后进行特征选择,这三种就可以用于常用的过滤法。还有f_regression,mutual_info_regression则可以用于回归问题。剩下的还有SelectPercentile (基于最高得分的百分位)等,可以根据以上举例选择需要的函数或者放入自己写的函数。
SelectKBest()方法
fit_transform()方法想必大家已经很熟悉了,这里主要提一下get_support() 方法,可以得到被选择特征的掩码或索引。之前用VarianceThreshold的时候发现返回值原始列名没有了,再一个一个对照谁是被留下的特征很麻烦,可以使用这个函数来解决问题,之前用到的代码如下:
selectorV = VarianceThreshold(threshold=3)
features = selectorV.fit_transform(features)
select_name_index0 = selectorV.get_support(indices=True)# 所有留下特征的索引值
features = pd.DataFrame(data2,columns=all_cols[select_name_index0])
语句解析及错误修改
接下来看以下语句:
SelectKBest(lambda X, Y: array(map(lambda x:pearsonr(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
首先是最简单的参数k=2,选择分数最高的两个特征。 拆开看score_func参数的内容:lambda x:pearson(x,Y)是计算x(猜测为每一个特征)与Y(猜测为预测结果)的pearson系数。然后map(lambda x:pearsonr(x, Y), X.T,map函数会以第二个参数序列中的每一个元素调用 function 函数,即完成了上述所说计算,返回包含每次 function 函数返回值的新列表。接下来是外围的array函数。
array函数是之前没有遇到过的函数(后面就打脸了),下面主要说array函数:
报错问题解决即为导入相关包:from numpy import *(作者:qq_42452643,链接:https://blog.csdn.net/qq_42452643/article/details/82776938)(也可以直接导入array,或者写numpy.array)。
在搜索到上述解决方案时,我突然想起这就是从现有数组生成ndarray的方法…
代码变成了这样:
SelectKBest(lambda X, Y: numpy.array(map(lambda x:pearsonr(x, Y), X)), k=2).fit_transform(iris.data, iris.target)
接下来又是另一个错误了,
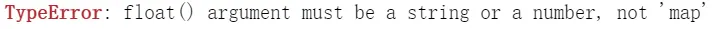
map函数在Python 3.x 下返回迭代器,而numpy.array()需写入list。解决方法是在map前再套一个list()。(作者:coding上下求索,链接:https://blog.csdn.net/shangxiaqiusuo1/article/details/84336339)
代码又变成了这样: `
SelectKBest(lambda X, Y: numpy.array(list(map(lambda x:pearsonr(x, Y), X))), k=2).fit_transform(iris.data, iris.target)`
然而错误并没有结束!!!(转置.T在我使用的时候被我删掉了)所以又出现了这样的错误:
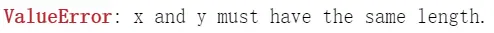
我突然反应过来,要计算的是每一个特征与预测结果的关系,这样不加转置则相当于是每一个样本与预测结果的关系了,不符合预期要求。
最后修改得到的正确代码如下:
SelectKBest(lambda X, Y: array(list(map(lambda x: pearsonr(x, Y)[0], X.T))).T, k=2).fit_transform(iris.data, iris.target)
首先在lambda函数中转置iris.data可以得到4列特征值,获得最后结果再转置复原得到每一个样本所对应2个特征的值。 至于中间为什么有个pearsonr(x, Y)[0]是因为如下:

scipy.stats.pearsonr(x, y)返回值这里只需要返回的r值即皮尔森系数即可。
完整代码如下:
selector = SelectKBest(lambda X, Y: np.array(list(map(lambda x: pearsonr(x, Y)[0], X.T))).T, k=2)
iris_data = pd.DataFrame(selector.fit_transform(iris.data, iris.target),columns=np.array(iris.feature_names)[selector.get_support(indices=True)])
运行结果如下:
终于达到了预期成果!
由上再有一个lambda函数,就是将特征和预测结果的关系代入上述函数计算,最后返回分数列表,再根据选出最好的2个特征,特征选择便完成,结果如上图所示。
总结
总结:运用SelectKBest类创建对象修改score_func参数,选择需要的函数或者放入自己写的函数,k值选择预期的参数或者进行参数搜索,即可完成一定需求的特征选择。

















 1451
1451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









