






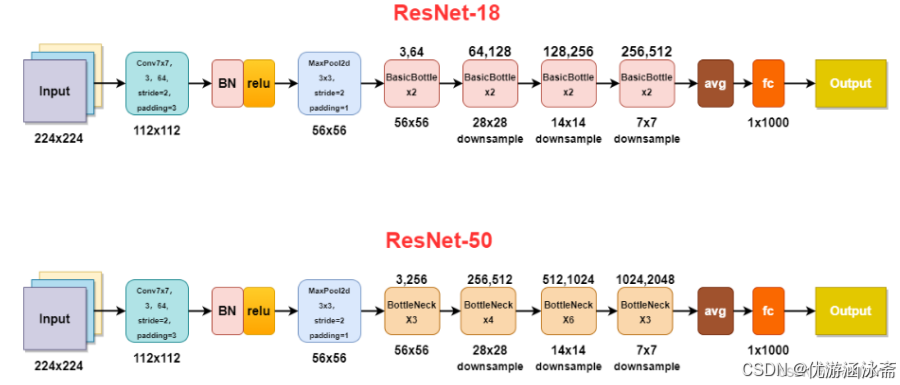
锚框的生成是RPN区域建议网络必要的组成部分,文章引自
通过一个3*3的卷积核对输入特征进行卷积,不改变输入特征的长宽,只改变通道数,卷积操作之后,输出的每一个特征点都会映射k个锚框
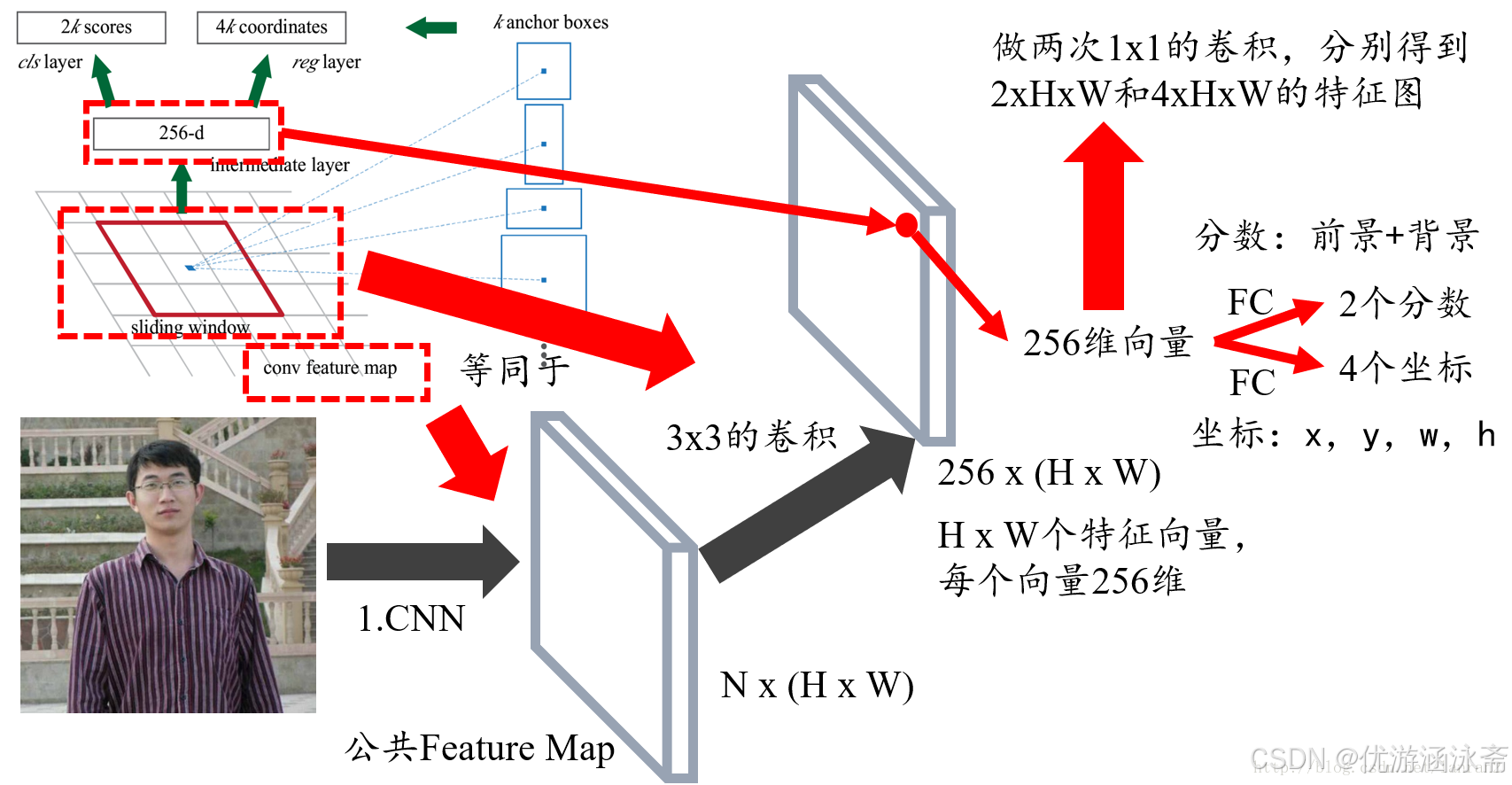
这个k是怎么来的呢,每个像素点对应原图的一个框,这个框需要进行预测,他应该长什么样子,所以设定k个框来对应这个锚点,并通过分类来判断这个框是前景还是背景,然后通过回归对锚框进行优化。用代码来实现一下,代码摘自faster Rcnn
导入numpy
import numpy as np这里会有一个base_size,原始大小,生成base_anchor
定义生成框(总的),这段代码首先利用base_size生成base_anchor,是一个[0,0,15,15],之后生成一个以基础框长宽比生成的锚框,之后通过结合以尺度生成的锚框来得出最终的锚框
def generate_anchors(base_size=16, ratios=[0.5, 1, 2], scales=2**np.arange(3,6)):
base_anchor = np.array([1, 1, base_size, base_size]) - 1
ratio_anchors = _ratio_enum(base_anchor, ratios)
# 下面是用来生成一组锚点,这是将锚框长宽比与尺度结合起来
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales)
for i in range(ratio_anchors.shape[0])])
return anchors定义长宽比锚框
def _ratio_enum(anchor, ratios):
w, h, x_ctr, y_ctr = _whctrs(anchor)
# 原始锚框的面积
size = w * h
# 计算指定比例的面积,有三个[0.5,1,2]
size_ratios = size / ratios
# round是四舍五入到指定的位数,开根号相当于长×宽开根号得出宽
ws = np.round(np.sqrt(size_ratios))
# 宽乘以长宽比
hs = np.round(ws * ratios)
# 生成锚点坐标,锚框坐标,左上角和右下角,生成一个[左上x1,左上y1,右下x1右下y1],[左上x2,左上y2,右下x2,右下y2]
# [左上x3,左上y3,右下x3,右下y3],[左上x4,左上y4,右下x4,右下y4],这是一个尺度的
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors定义获取中心点坐标
def _whctrs(anchor):
"""
return width, height, x_center, y_center for an anchor(window)
w:长度减去对应的x坐标,再加1
h:宽度减去对应的y坐标,再加1
x_ctr:将锚点的起始坐标加上宽度的一半减去0.5就是下面的额公式
"""
w = anchor[2] - anchor[0] + 1
h = anchor[3] - anchor[1] + 1
x_ctr = anchor[0] + 0.5 * (w - 1)
y_ctr = anchor[1] + 0.5 * (h - 1)
return w, h, x_ctr, y_ctr定义生成单个锚框
def _mkanchors(ws, hs, x_ctr, y_ctr):
ws = ws[:, np.newaxis]
# 转换为二维数组,或列向量,是一列的向量
hs = hs[:, np.newaxis]
# hstack用于水平堆叠数组,锚点四个坐标,左上角x,y坐标,右下角x,y坐标
anchors = np.hstack((x_ctr - 0.5 * (ws - 1),
y_ctr - 0.5 * (hs - 1),
x_ctr + 0.5 * (ws - 1),
y_ctr + 0.5 * (hs - 1)))
return anchors定义尺度生成的锚框
def _scale_enum(anchor, scales):
"""
尺度就是面积
根据给定的锚点和尺度,为每个尺度生成一组新的锚点(锚框)
"""
w, h, x_ctr, y_ctr = _whctrs(anchor)
# scales = [scale1,scale2,scale3]
#宽的尺度大小,[w*scale1,h*scale1],[w*scale2,h*scale2],[w*scale3,h*scale3]
ws = w * scales
# 高的尺度大小
hs = h * scales
# 得出三个尺度大小的锚框坐标,上面得出三个长宽比大小的锚框,最后这两个结合在一起
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors主函数
if __name__ == '__main__':
import time
# 获取当前时间
t = time.time()
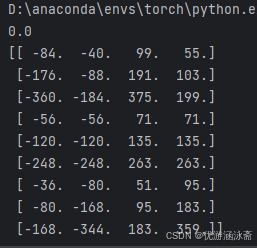
a = generate_anchors()
# 打印生成的时间
print(time.time() - t)
print(a)打印

















 6687
6687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









