







最近被要求做爬虫,因为前期沟通失误,导致返工好几轮。(现在还在返工)
最终还是成功了,做了一个封装的代码项目,并exe
exe 长这样

点击后可以得到一个tkinter写出的界面,如图所示:
点击后可以在桌面上得到

废话不多说,目录如下。
目录
以及tkinter结束后千万不能忘记写的一行代码(非常重要)
完整代码
import requests
import json
import pandas as pd
import time
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为
import datetime
import tkinter as tk
import openpyxl
#爬虫代做+v:j1yzbzjpzyxz
#时间函数
def getdate(self,beforeOfDay):
today = datetime.datetime.now()
# 计算偏移量
offset = datetime.timedelta(days=-beforeOfDay)
# 获取想要的日期的时间
re_date = (today + offset).strftime('%Y-%m-%d')
return re_date
#zgzf采购网网页生成函数
def getSearchlist():
search_list=['#你想在该网站搜索的关键词']
url_list=[]
for i in range(len(search_list)):
for o in range(3):
a=o+1
url_list=url_list+["https://search.ccgp.gov.cn/bxsearch?searchtype=2&page_index="+str(a)+"&bidSort=&buyerName=&projectId=&pinMu=&bidType=&dbselect=bidx&kw="+search_list[i]+"&start_time="+getdate(0,3)+"&end_time="+str(datetime.datetime.now().strftime('%Y-%m-%d'))+"&timeType=2&displayZone=陕西&zoneId=&pppStatus=0&agentName="]
return url_list
#zgzf采购网网页爬取函数
def ccgp():
web_list=[]
region_list=[]
time_list=[]
dady_list=[]
title_list=[]
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'}
for p in range(len(getSearchlist())):
time.sleep(6)
url2 =getSearchlist()[p]
response2 = requests.get(url= url2,headers=header)
response2.encoding = 'utf-8'
wb_data2 = response2.text
html = etree.HTML(wb_data2)
www=html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li/a/@href')
for i in range(len(www)):
i=i+1
web_list=web_list+html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/a/@href')
title_list=title_list+[str(html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/a[@href]/text()')).split("\\r\\n ")[1].split("\\r\\n")[0]]
time_list=time_list+[str(html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/span/text()[1]')).split("['")[1].split(" ")[0]]
dady_list=dady_list+[str(html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/span/text()[1]')).split("|")[1].split("\\r\\n ")[0]]
ww=html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/span/a/text()')
if ww==[]:
region_list=region_list+['None']
else:
region_list=region_list+html.xpath('//div/div/div[1]/ul/li['+str(i)+']/span/a[@href="javascript:void(0)"]/text()')
i=i-1
a=pd.DataFrame({'标题':title_list,'地区':region_list,'时间':time_list,'采购人':dady_list,'详细网址':web_list})
a=a[a['地区']=='陕西']
a.to_excel(excel_writer = r"F:\\desktop\\导出结果(爬虫中国政府采购网).xlsx")
return a
#陕西省政府采购网
def get_ccgpshaanxi_Searchlist():
search_list=['#你想在该网站搜索的关键词']
url_list=[]
for i in range(len(search_list)):
url_list=url_list+["http://www.ccgp-shaanxi.gov.cn/freecms/rest/v1/notice/selectInfoMoreChannel.do?&siteId=a7a15d60-de5b-42f2-b35a-7e3efc34e54f&channel=&title=&content="+search_list[i]+"®ionCode=¬iceType=&operationStartTime="+getdate(0,1)+"%2000:00:00&operationEndTime="+str(datetime.datetime.now().strftime('%Y-%m-%d'))+"%2023:59:59&currPage=1&pageSize=10&cityOrArea="]
return url_list
def ccgpshaanxi():
title=[]
dady=[]
agency=[]
web=[]
reigon=[]
budget=[]
issue_time=[]
notice=[]
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'}
for p in range(len(get_ccgpshaanxi_Searchlist())):
url2 =get_ccgpshaanxi_Searchlist()[p]
response2 = requests.get(url= url2,headers=headers)
response2 .encoding = 'utf-8'
wb_data_2 = response2.text
html = etree.HTML(wb_data_2)
for i in range(len(json.loads(wb_data_2)['data'])):
title=title+[json.loads(wb_data_2)['data'][i]['title']]
web=web+["http://www.ccgp-shaanxi.gov.cn/freecms"+json.loads(wb_data_2)['data'][i]['htmlpath']]
reigon=reigon+[json.loads(wb_data_2)['data'][i]['regionName']]
issue_time=issue_time+[json.loads(wb_data_2)['data'][i]['openTenderTime']]
notice=notice+[json.loads(wb_data_2)['data'][i]['noticeTime']]
budget=budget+[str(json.loads(wb_data_2)['data'][i]['budget'])]
dady=dady+[str(json.loads(wb_data_2)['data'][i]['purchaser'])]
a=pd.DataFrame({'标题':title,'发布时间':issue_time,'notice':notice,'预算(元)':budget,'发布地区':reigon,'详细网址1':web,'甲方':dady})
a.to_excel(excel_writer=r"F:\\desktop\\导出结果(陕西省政府采购网).xlsx")
return a
#陕西省招投标平台
def get_bulletin_Searchlist():
search_list=['#你想在该网站搜索的关键词']
url_list=[]
for i in range(len(search_list)):
url_list=url_list+["http://bulletin.sntba.com/xxfbcmses/search/bulletin.html?searchDate="+getdate(0,2)+"&dates=2&categoryId=88&industryName=&area=&status=&publishMedia=&sourceInfo=&showStatus=&word="+str(search_list[i])]
return url_list
def bulletin():
title=[]
web=[]
reigon=[]
issue_time=[]
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'}
for x in range(len(get_bulletin_Searchlist())):
response3 = requests.get(url=get_bulletin_Searchlist()[x],headers=headers)
time.sleep(6)
wb_data3 = response3.text
html = etree.HTML(wb_data3)
jishu=html.xpath('//table//tr/td/a/text()')
for i in range(len(jishu)):
i=i+2
title=title+[str(html.xpath('//table//tr['+str(i)+']/td/a/text()')).split('t')[6].split('\r')[0]]
web=web+[str(html.xpath('//table//tr['+str(i)+']/td/a/@href')).split("'")[1]]
reigon=reigon+[str(html.xpath('//table//tr['+ str(i) +']/td[3]/span/text()')).split('t')[6].split('\r')[0]]
issue_time=issue_time+[str(html.xpath('//table//tr ['+ str(i) +']/td[5]/text()')).split('t')[6].split('\r')[0]]
i=i-2
a=pd.DataFrame({'标题':title,'原网址':web,'发布时间':issue_time,'发布地区':reigon})
a.to_excel(excel_writer = r"F:\\desktop\\导出结果(陕西省招标投标公共服务平台).xlsx")
return a
#设计按钮
from tkinter import *
root= tk.Tk()
root.title('爬虫招标信息采集——中国陕西')
root.geometry('400x240') # 这里的乘号不是 * ,而是小写英文字母 x
btn1 = Button(root,text="中国政府采购网",command=ccgp())
btn1.place(relx=0.2,rely=0.4, relwidth=0.3, relheight=0.1)
btn1.pack()
btn2 = Button(root,text="陕西省政府采购网",command=ccgpshaanxi())
btn2.place(relx=0.4,rely=0.4, relwidth=0.6,relheight=0.1)
btn2.pack()
btn3 = Button(root,text="陕西省招标投标公共服务平台",command=bulletin())
btn3.place(relx=0.6,rely=0.4, relwidth=0.9,relheight=0.1)
btn3.pack()
theLabel = tk.Label(root,text="点击按钮获得今日招投标信息",justify=tk.LEFT,compound = tk.CENTER,font=("华文行楷",20),fg = "grey")
theLabel.pack()
root.mainloop()
# In[ ]:
以下是代码解析。
首先,是库的引用部分
库的引用
import json
import pandas as pd
import time
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为
import datetime
import tkinter as tk
import openpyxl因为我本人比较惯用Xpath ,所以这次的爬虫项目也选用Xpath来制作。
特别说明,最下面那个openpyxl库本来不在我的引用范围,但是函数封装后exe时报错了,根据错误提示,没有找到openpyxl库,所以我pip install了这个库且import了一下,错误就解决了。
def时间函数
#时间函数
def getdate(self,beforeOfDay):
today = datetime.datetime.now()
# 计算偏移量
offset = datetime.timedelta(days=-beforeOfDay)
# 获取想要的日期的时间
re_date = (today + offset).strftime('%Y-%m-%d')
return re_date这个时间函数超级有用!!!
因为很多招投标网站储存信息的网站都是包含时间的
举个例子
(网站长这样)
http://search.ccgp.gov.cn/bxsearch?searchtype=2&page_index=1&bidSort=0&buyerName=&projectId=&pinMu=0&bidType=0&dbselect=bidx&kw=%E7%9A%84&start_time=2022%3A07%3A02&end_time=2022%3A08%3A02&timeType=3&displayZone=&zoneId=&pppStatus=0&agentName=这个网站的连接中包含————start_time=2022%3A07%3A02&end_time=2022%3A08%3A02
就是网址中时间和日期的表达
get date函数就是计算
根据当天日期往前推若干天得到的日期
例如:输入getdate(,2)
就可得到距离当天日期两天前的日期
详细用法见生成中国政府采购网的爬虫列表的代码。
爬取目标网站的链接生成
def getSearchlist():
search_list=['#你想在该网站搜索的关键词']
url_list=[]
for i in range(len(search_list)):
for o in range(3):
a=o+1
url_list=url_list+["https://search.ccgp.gov.cn/bxsearch?searchtype=2&page_index="+str(a)+"&bidSort=&buyerName=&projectId=&pinMu=&bidType=&dbselect=bidx&kw="+search_list[i]+"&start_time="+getdate(0,3)+"&end_time="+str(datetime.datetime.now().strftime('%Y-%m-%d'))+"&timeType=2&displayZone=陕西&zoneId=&pppStatus=0&agentName="]#自行解析的网站链接
return url_list如图,输入关键词,可以得含有当天信息的网站网址。
目标网站的爬取函数
def ccgp():
web_list=[]
region_list=[]
time_list=[]
dady_list=[]
title_list=[]
###建立爬取字段
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'}
###设置当前爬取请求头
for p in range(len(getSearchlist())):
time.sleep(6)###这个网站请求过快会被屏蔽,所以使用time.sleep(6)暂停六秒再进行请求
url2 =getSearchlist()[p]###依次遍历前面getSearchlist()中包含的网站
response2 = requests.get(url= url2,headers=header) ###开始请求
response2.encoding = 'utf-8'
wb_data2 = response2.text
html = etree.HTML(wb_data2)
www=html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li/a/@href')###获取该页有多少条信息需要爬取
for i in range(len(www)):###根据需要信息条数进行遍历
i=i+1
###开始爬取 web_list=web_list+html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/a/@href')
title_list=title_list+[str(html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/a[@href]/text()')).split("\\r\\n ")[1].split("\\r\\n")[0]]
time_list=time_list+[str(html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/span/text()[1]')).split("['")[1].split(" ")[0]]
dady_list=dady_list+[str(html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/span/text()[1]')).split("|")[1].split("\\r\\n ")[0]]
ww=html.xpath('//div[5]/div[2]/div/div/div[1]/ul/li['+str(i)+']/span/a/text()')
if ww==[]:
region_list=region_list+['None']
else:
region_list=region_list+html.xpath('//div/div/div[1]/ul/li['+str(i)+']/span/a[@href="javascript:void(0)"]/text()')
i=i-1
a=pd.DataFrame({'标题':title_list,'地区':region_list,'时间':time_list,'采购人':dady_list,'详细网址':web_list})
###筛选爬取地区
a=a[a['地区']=='陕西']
###导出为excel
a.to_excel(excel_writer = r"F:\\desktop\\导出结果(爬虫中国政府采购网).xlsx")
return a
其他两个网站的爬取基本与中国政府采购网类似,不多赘述,接下来讲解
tkinter部分
#设计按钮
from tkinter import *
root= tk.Tk()
root.title('爬虫招标信息采集')
root.geometry('400x240') # 这里的乘号不是 * ,而是小写英文字母 x
btn1 = Button(root,text="1号采购网",command=ccgp())
btn1.place(relx=0.2,rely=0.4, relwidth=0.3, relheight=0.1)
btn1.pack()
btn2 = Button(root,text="2号采购网",command=ccgpshaanxi())
btn2.place(relx=0.4,rely=0.4, relwidth=0.6,relheight=0.1)
btn2.pack()
btn3 = Button(root,text="3号招标投标公共服务平台",command=bulletin())
btn3.place(relx=0.6,rely=0.4, relwidth=0.9,relheight=0.1)
btn3.pack()
theLabel = tk.Label(root,text="点击按钮获得今日招投标信息",justify=tk.LEFT,compound = tk.CENTER,font=("华文行楷",20),fg = "grey")
theLabel.pack()
root.mainloop()关于tkinter部分其实非常简单,写一个程序框,在框中设置三个按钮,点击后触发相应网站的函数就可以了,举例说明
设置框的函数
root= tk.Tk()
root.title('爬虫招标信息采集——中国陕西')
root.geometry('400x240') # 这里的乘号不是 * ,而是小写英文字母 x设置按钮的函数
btn1 = Button(root,text="中国政府采购网",command=ccgp()#触发函数写在这里)
btn1.place(relx=0.2,rely=0.4, relwidth=0.3, relheight=0.1)
btn1.pack()额外添加的设置背景文字的函数
theLabel = tk.Label(root,text="点击按钮获得今日招投标信息",justify=tk.LEFT,compound = tk.CENTER,font=("华文行楷",20),fg = "grey")
theLabel.pack()
以及tkinter结束后千万不能忘记写的一行代码(非常重要)
root.mainloop()最后程序就长这样
以上工作全部完成且确定函数没问题后,我们讲所有函数整合成一个项目,保存为.py的格式
如图所示
pycharm下.py文件长这样。
关于封装exe教程
使用的exe工具
首先,我用的是anaconda系列的python编译器(非常好用,暴怒推荐),使用anaconda prompt
如图所示,就是这个东西
点击以后可以得到:
一个小黑框
这个小黑框就是我们操作并封装exe的重心,在本次项目中我使用虚拟环境进行exe
建立exe的虚拟环境
首先,在小黑框中输入
conda -n XXX(你想起的虚拟环境名字) python=XXX(你想用的python版本编号例如:XXX可以写为3.6)
如果不指定版本
只写
conda -n XXX(你想起的虚拟环境名字)
就好在创建过程中需要回复(y/n),Yes,再激活虚拟环境
激活前:
激活后:
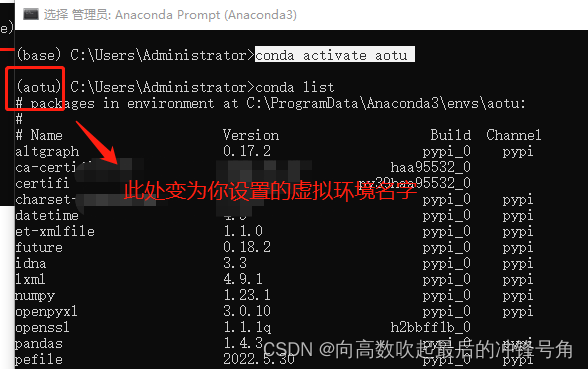
conda安装的虚拟环境,会把虚拟环境的目录生成在anaconda安装目录下的env目录下,如果想找到之前建立的虚拟环境可以在此目录下搜索,或者在黑框中输入
conda info --envs来查看所有虚拟环境
上面我们已经创建并激活了你想要的虚拟环境,创建后可通过conda list可以查看当前虚拟环境里已经安装的库。
查看后如图所示:
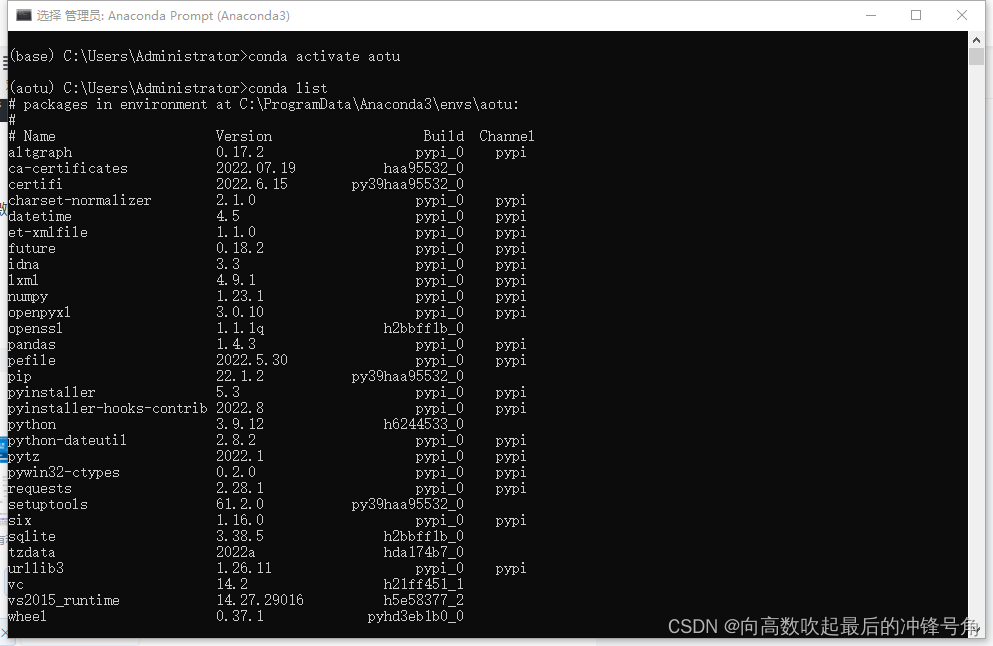
虚拟环境配置
如果发现该虚拟环境中没有你想封装的py文件import的库
可以通过在虚拟环境中pip解决,如下所示:
pip install xxx(库名)
解决问题
本次爬虫需要pip的库为
pip install requests
pip install pandas
pip install datetime
pip install lxml
pip install pyinstaller
其中
pip install pyinstaller
必不可少 打包路径展示
接下来是在找到需要exe的py文件的路径
在小黑框中通过cd解决
例如:
我的文件放在桌面的a文件夹中我将输入
cd Desktop\a打包exe命令
Pyinstaller -F -w -i XXX(py文件名).py运行过程展示
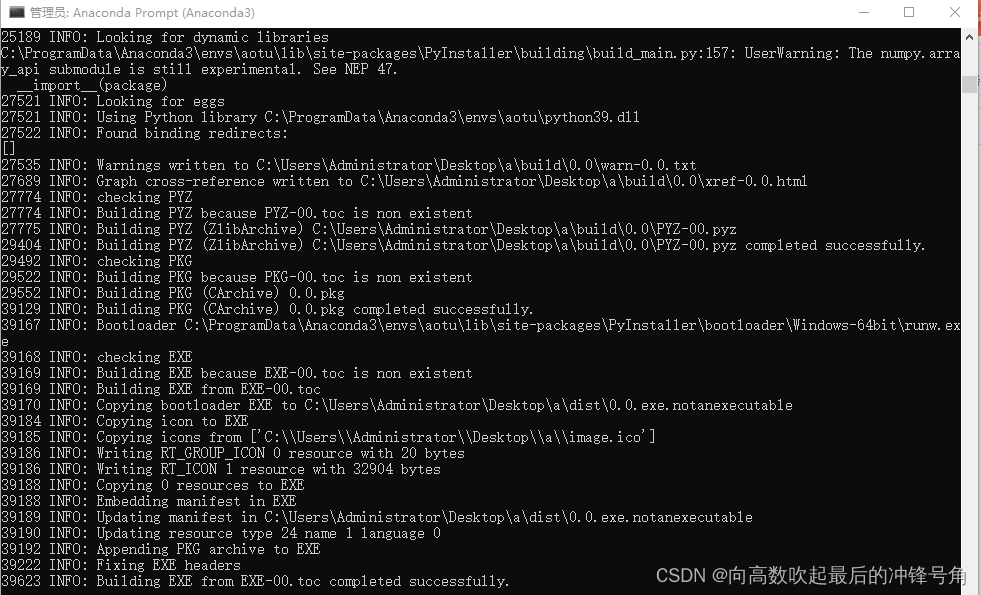
美化logo
如果想要换个好看的图片做logo
可以将你喜欢的图片在线转换成.ico的形式(下个链接可以满足)
然后将.ico格式的图片与.py文件置于统一目录下
使用
Pyinstaller -F -w -i XXX(图片转化ico后的名字).ico XXX(打包程序名).py结果
最终可以在该路径下dist文件中,得到打包好的exe程序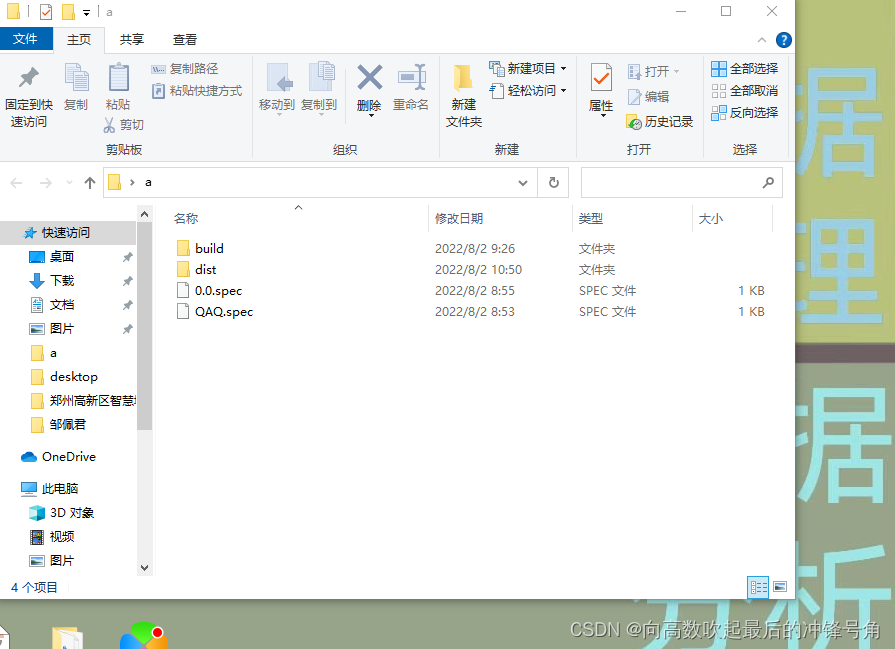

















 2196
2196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









