







以图像算法开发的名义入职的第一天,直属领导不在,隔壁通讯组小头目说,你就做个爬虫吧......虫吧......吧......
没办法,写吧。但很久以前只写过很简单的爬虫,这次就边学边写。
基本功能:爬取某招投标网站上的项目内容和具体每个项目的截止日期时间,有关键字查询功能和截止日期设置功能。
已添加的后续功能:QQ聊天和电子邮件提示功能。
待添加的后续功能:网页UI或者程序UI
目标网站为招标公告,由于是数据是动态加载的url不变的多页表格内容,按爬取静态网站的方法是不可行,参考文章Python 爬虫爬取多页数据中的内容,首先对按F12对本网页工作原理进行分析。
第一部分:获取公告名称和相应id
F12打开控制台,选择Network->XHR,Ctrl+R重新跳转下,点击Name下的文件,选择Headers,下方显示的就是请求头文件信息,可以看到这是一个POST请求。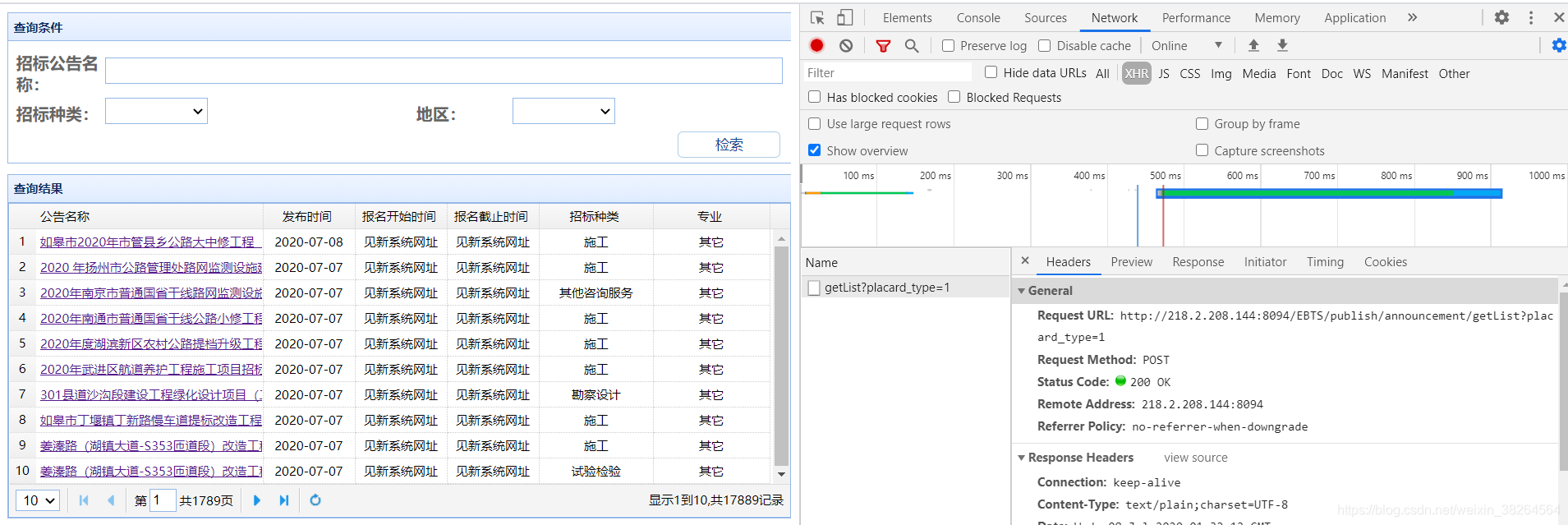
而我们要的消息就在Response中。
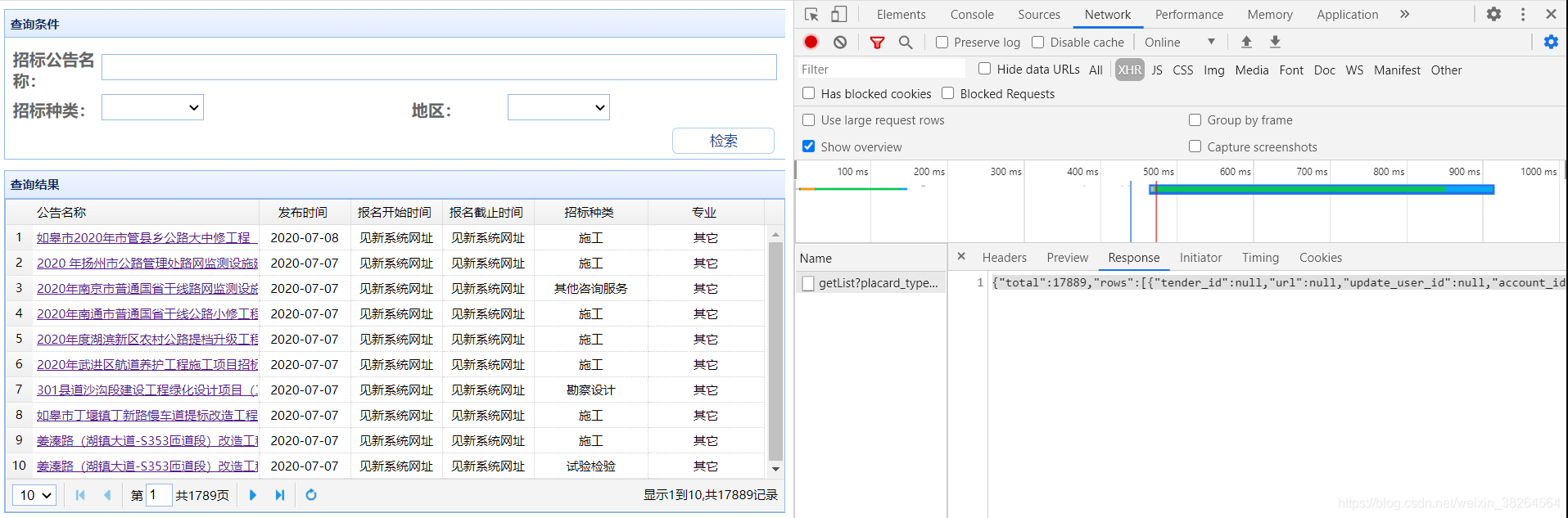
使用Python模拟请求,在Headers下找到Request Headers部分,这是请求的头数据。同时观察Form Data部分,可见这部分定义了请求的表格的页码和每页的行数。进行模拟发送请求时,改变这部分内容就能获取不同页上的数据。
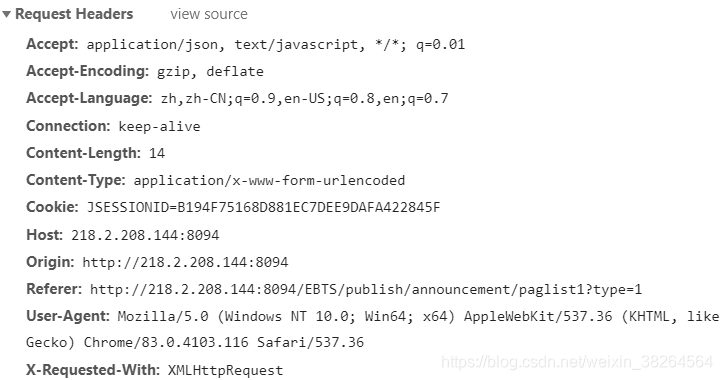

将这部分内容复制后做整理,使用request.post就能获得response内容。
def visit_home(x=10):#默认找前10页
#模拟头部分
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh,zh-CN;q=0.9,en-US;q=0.8,en;q=0.7',
'Connection': 'keep-alive',
'Content-Length': '14',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'JSESSIONID=6938F495DAA5F25B2E458C7AB108BEDF',
'Host': '218.2.208.144:8094',
'Origin': 'http://218.2.208.144:8094',
'Referer': 'http://218.2.208.144:8094/EBTS/publish/announcement/paglist1?type=1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
#模拟form data部分
form_data = {
'page':'1',
'rows': '10'
}
#空字典存放信息
home_dict = {}
#从第一页开始
times = 1
while times <= x:
form_data['page'] = times
#注意url是Name下的链接,不是网址
url = 'http://218.2.208.144:8094/EBTS/publish/announcement/getList?placard_type=1'
response = requests.post(url, data=form_data, headers=headers)
#请求到的信息,解析后选择转为字符串形式方便无脑操作
soup = BeautifulSoup(response.content, "html5lib")
soup = str(soup)
for i in range(1,11):#由于每页有10行即10个信息,故分可以根据关键字分为11段,其中有效信息在第2到第11段
str1 = soup.split('placard_name":"')[i].split('","bid_id')#提取公告名称
str2 = soup.split('placard_id":"')[i].split('","project_id')#提取公告ID
str3 = soup.split('is_new_tuisong":"')[i].split('","remark_id')#提取是否是修改型的公告
for key in home_dict:#防止项目名称重名
if str1[0] in key:
str1[0]=str1[0]+str(time.time())
home_dict[(str1[0])]=([str2[0],str3[0]])#存入字典
times= times+1
time.sleep(1)#防止频繁访问
return home_dict注意: url不是网址,是Name下的那个链接。
如此则获得了公告名称和相应的id以及这个公告是否是首次发布,id用于访问具体公告页面,提取截止日期,是否是首次发布涉及访问的网页前缀网址不同。
第二部分:访问具体公告网址并获取截止日期
进入几个具体的公告中,同样按F12在控制台中查看信息,发现这个请求是GET形式的。
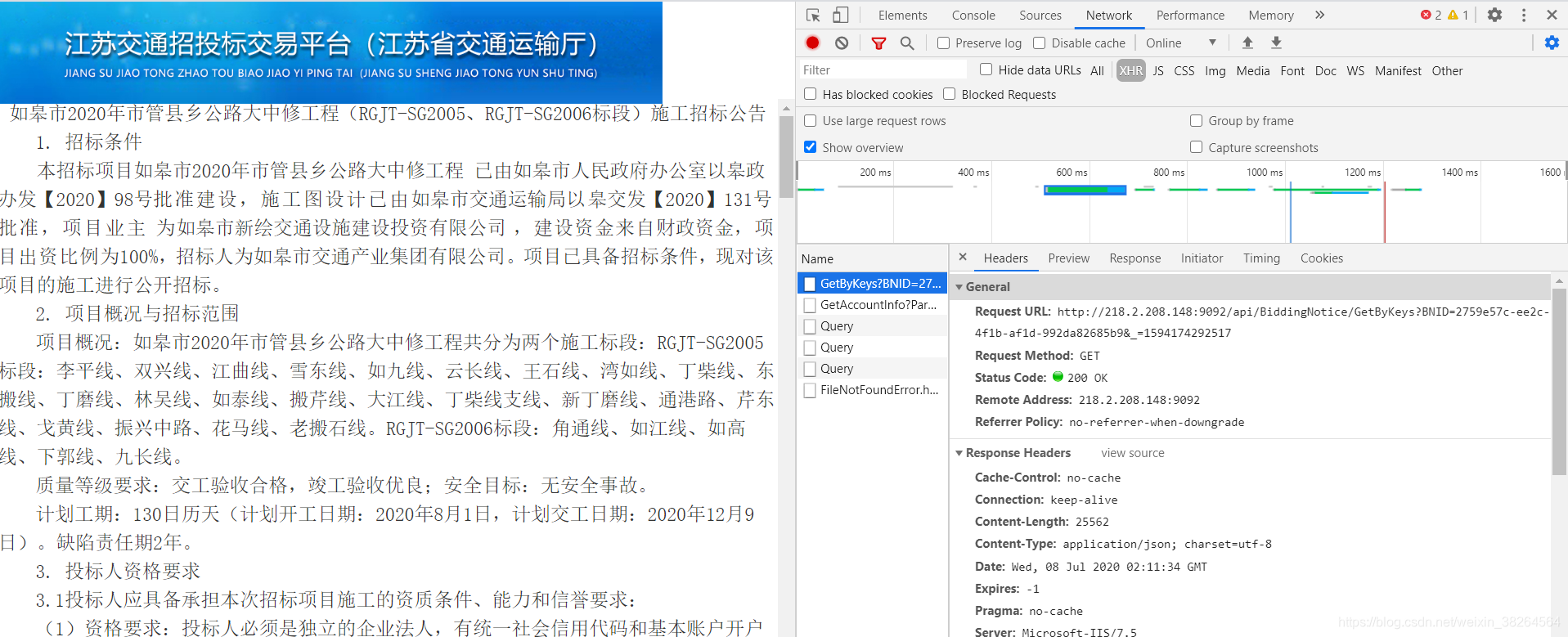
此处我犯了次失误,没注意到公告其实有两种,一种是普通公告,一种是更正公告,前者在链接中使用BNID,后者则使用TNAID做区分,且后来才发现这在最初POSE返回的文档中就有标记,首次发布的公告“is_new_tuisong”设定为1,而修改过的公告则“is_new_tuisong”设定为2。故应注意观察网址和属性的变化。注意此处的url依然是Name中的链接而非原网址。
将GET到的文本转为json格式并对需要的部分内容进行提取。BNNAME是普通公告名,TNANAME为更正公告名,KBBEGINTIME为截止日期。
def get_data(address_list,str_data):
msg_content = ''
num = 1
data_address_first1 = 'http://218.2.208.148:9092/api/BiddingNotice/GetByKeys?BNID='#普通公告链接头
data_address_first2 = 'http://218.2.208.148:9092/api/BiddingNoticeAdditional/GetByKeys?TNAID='#更正公告链接头
for i in address_list:
if "gengzhenggonggao#" in i:#判断是否为更正公告
address_url = data_address_first2+str(i).split("#")[1]
return_data = requests.get(address_url)
try:
task = str(json.loads(return_data.content).get('TNANAME'))#更正公告的标题,普通公告中没有这个TNANAME项
state = json.loads(return_data.content).get('KBBEGINTIME')
state = str(state)
str_state = state.replace("T"," ")
#对截止日期的字符串进行处理,成为datatime时间日期格式
str_state = datetime.datetime.strptime(str_state, '%Y-%m-%d %H:%M:%S')
#与设置的截止日期对比
if str_state>=str_data:
print(str(num),task,"公告截止日期:",str_state)
msg_content = msg_content+str(num)+" : "+task+" 公告截止日期:"+str(str_state)+'\n'
else:
print(str(num),task,"公告截止日期早于初始日期")
msg_content = msg_content+str(num)+" : "+task+" 公告截止日期早于初始日期"+'\n'
except:
task = "项目网址出错"
str_state = "未能获取时间"
print(str(num),task,str_state)
msg_content = msg_content+str(num)+" : "+task+" "+str_state+'\n'
else:
address_url = data_address_first1+str(i)
return_data = requests.get(address_url)
try:
task = str(json.loads(return_data.content).get('BNNAME'))
state = json.loads(return_data.content).get('KBBEGINTIME')
state = str(state)
str_state = state.replace("T"," ")
#对截止日期的字符串进行处理,成为datatime时间日期格式
str_state = datetime.datetime.strptime(str_state, '%Y-%m-%d %H:%M:%S')
#与设置的截止日期对比
if str_state>=str_data:
print(str(num),task,"公告截止日期:",str_state)
msg_content = msg_content+str(num)+" : "+task+" 公告截止日期:"+str(str_state)\
+'\n'
else:
print(str(num),task,"公告截止日期早于初始日期")
msg_content = msg_content+str(num)+" : "+task+" 公告截止日期早于初始日期"+'\n'
except:
task = "项目网址出错"
str_state = "未能获取时间"
print(str(num),task,str_state)
msg_content = msg_content+str(num)+" : "+task+" "+str_state+'\n'
#此处为了统一方便,直接从具体公告信息内再次调出公告名,而放弃使用之前字典中的公告名
num = num + 1
return msg_content这里的日期时间大约已经没问题了_(:зゝ∠)_
第三部分: 判断输入关键字是否出现函数和输入时间转换函数
#判断输入关键字是否出现函数
def get_name(str_key,home_dict):
address_list = []
if len(str_key)!=0:
for key in home_dict:
if str_key in key:
if int((home_dict[key])[1])==2:#即非首次发布的公告
address_list.append("gengzhenggonggao#"+str(home_dict[key][0]))
else:
address_list.append(str(home_dict[key][0]))
if len(address_list)<1:
print("没有相应公告!")
sys.exit(0)
else:
for key in home_dict:
if int((home_dict[key])[1])==2:#即非首次发布的公告
address_list.append("gengzhenggonggao#"+str(home_dict[key][0]))
else:
address_list.append(str(home_dict[key][0]))
if len(address_list)<1:
print("没有相应公告!")
sys.exit(0)
return address_list#输入时间转换函数
def trans_time(str_data):
if len(str_data) == 0:
str_data = datetime.datetime.now()#默认时间
return str_data
else:
try:
str_data = datetime.datetime.strptime(str_data, '%Y-%m-%d %H:%M:%S')
return str_data
except:
print("日期时间格式错误!")
sys.exit(0)大约是修正了日期时间问题_(:зゝ∠)_
目前的全部代码
保存为crawler.py,如下:
# -*- coding: utf-8 -*-
import requests,json
import re
from bs4 import BeautifulSoup
import time
import datetime
import sys
from e import post_email
from qq2 import send2QQ
def visit_home(x=10):#默认找前10页
#模拟头部分
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh,zh-CN;q=0.9,en-US;q=0.8,en;q=0.7',
'Connection': 'keep-alive',
'Content-Length': '14',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'JSESSIONID=6938F495DAA5F25B2E458C7AB108BEDF',
'Host': '218.2.208.144:8094',
'Origin': 'http://218.2.208.144:8094',
'Referer': 'http://218.2.208.144:8094/EBTS/publish/announcement/paglist1?type=1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
#模拟form data部分
form_data = {
'page':'1',
'rows': '10'
}
#空字典存放信息
home_dict = {}
#从第一页开始
times = 1
while times <= x:
form_data['page'] = times
#注意url是Name下的链接,不是网址
url = 'http://218.2.208.144:8094/EBTS/publish/announcement/getList?placard_type=1'
response = requests.post(url, data=form_data, headers=headers)
#请求到的信息,解析后选择转为字符串形式方便无脑操作
soup = BeautifulSoup(response.content, "html5lib")
soup = str(soup)
for i in range(1,11):#由于每页有10行即10个信息,故分可以根据关键字分为11段,其中有效信息在第2到第11段
str1 = soup.split('placard_name":"')[i].split('","bid_id')#提取公告名称
str2 = soup.split('placard_id":"')[i].split('","project_id')#提取公告ID
str3 = soup.split('is_new_tuisong":"')[i].split('","remark_id')#提取是否是修改型的公告
for key in home_dict:#防止项目名称重名
if str1[0] in key:
str1[0]=str1[0]+str(time.time())
home_dict[(str1[0])]=([str2[0],str3[0]])#存入字典
times= times+1
time.sleep(1)#防止频繁访问
return home_dict
#判断输入关键字是否出现函数
def get_name(str_key,home_dict):
address_list = []
if len(str_key)!=0:
for key in home_dict:
if str_key in key:
if int((home_dict[key])[1])==2:#即非首次发布的公告
address_list.append("gengzhenggonggao#"+str(home_dict[key][0]))
else:
address_list.append(str(home_dict[key][0]))
if len(address_list)<1:
print("没有相应公告!")
sys.exit(0)
else:
for key in home_dict:
if int((home_dict[key])[1])==2:#即非首次发布的公告
address_list.append("gengzhenggonggao#"+str(home_dict[key][0]))
else:
address_list.append(str(home_dict[key][0]))
if len(address_list)<1:
print("没有相应公告!")
sys.exit(0)
return address_list
def get_data(address_list,str_data):
msg_content = ''
num = 1
data_address_first1 = 'http://218.2.208.148:9092/api/BiddingNotice/GetByKeys?BNID='#普通公告链接头
data_address_first2 = 'http://218.2.208.148:9092/api/BiddingNoticeAdditional/GetByKeys?TNAID='#更正公告链接头
for i in address_list:
if "gengzhenggonggao#" in i:#判断是否为更正公告
address_url = data_address_first2+str(i).split("#")[1]
return_data = requests.get(address_url)
try:
task = str(json.loads(return_data.content).get('TNANAME'))#更正公告的标题,普通公告中没有这个TNANAME项
state = json.loads(return_data.content).get('KBBEGINTIME')
state = str(state)
str_state = state.replace("T"," ")
#对截止日期的字符串进行处理,成为datatime时间日期格式
str_state = datetime.datetime.strptime(str_state, '%Y-%m-%d %H:%M:%S')
#与设置的截止日期对比
if str_state>=str_data:
print(str(num),task,"公告截止日期:",str_state)
msg_content = msg_content+str(num)+" : "+task+" 公告截止日期:"+str(str_state)+'\n'
else:
print(str(num),task,"公告截止日期早于初始日期")
msg_content = msg_content+str(num)+" : "+task+" 公告截止日期早于初始日期"+'\n'
except:
task = "项目网址出错"
str_state = "未能获取时间"
print(str(num),task,str_state)
msg_content = msg_content+str(num)+" : "+task+" "+str_state+'\n'
else:
address_url = data_address_first1+str(i)
return_data = requests.get(address_url)
try:
task = str(json.loads(return_data.content).get('BNNAME'))
state = json.loads(return_data.content).get('KBBEGINTIME')
state = str(state)
str_state = state.replace("T"," ")
#对截止日期的字符串进行处理,成为datatime时间日期格式
str_state = datetime.datetime.strptime(str_state, '%Y-%m-%d %H:%M:%S')
#与设置的截止日期对比
if str_state>=str_data:
print(str(num),task,"公告截止日期:",str_state)
msg_content = msg_content+str(num)+" : "+task+" 公告截止日期:"+str(str_state)\
+'\n'
else:
print(str(num),task,"公告截止日期早于初始日期")
msg_content = msg_content+str(num)+" : "+task+" 公告截止日期早于初始日期"+'\n'
except:
task = "项目网址出错"
str_state = "未能获取时间"
print(str(num),task,str_state)
msg_content = msg_content+str(num)+" : "+task+" "+str_state+'\n'
#此处为了统一方便,直接从具体公告信息内再次调出公告名,而放弃使用之前字典中的公告名
num = num + 1
return msg_content
#输入时间转换函数
def trans_time(str_data):
if len(str_data) == 0:
str_data = datetime.datetime.now()#默认时间
return str_data
else:
try:
str_data = datetime.datetime.strptime(str_data, '%Y-%m-%d %H:%M:%S')
return str_data
except:
print("日期时间格式错误!")
sys.exit(0)
if __name__ == "__main__":
str_key = input("请输入想查找的关键字,或直接按回车搜索全部:")
str_data = input('请按形如"2020-06-30 08:30:00"的格式输入起始日期,默认日期为今日今时:')
str_data = trans_time(str_data)
time1 = time.time()
home_dict = visit_home(x=10)
address_list = get_name(str_key,home_dict)
msg_content = get_data(address_list,str_data)
print("本次耗时:{:.2f}秒".format(time.time()-time1))
post_email(msg_content)
send2QQ(msg_content,name="QQ窗口名")附加功能部分1:将爬虫结果群发邮件
主要参考Python实现自动发送邮件和python使用QQ邮箱实现自动发送邮件;后来使用Yandex邮箱替换QQ邮箱,不需要授权码,直接使用密码登录,邮箱申请很简单,Yandex开启smtp服务可参考链接,全部勾都打上。相比QQ邮箱最大的问题是Yandex邮箱似乎被很多邮箱认为是垃圾邮件,需要手动去垃圾箱找并设备白名单,且由于是毛子邮箱,其发送延迟比较大的。
群发时报错AttributeError: 'list' object has no attribute 'decode' 的问题参考替换;
保存于文件e.py中:
#smtplib用于邮件的发信动作
import smtplib
from email.mime.text import MIMEText
#email用于构建邮件内容
from email.header import Header
#用于构建邮件头
def post_email(content="python测试"):
#发信方的信息:发信邮箱,QQ邮箱授权码
from_addr = '自己的邮箱地址'
password = '授权码或者密码'
#收信方邮箱
to_addr = ['目标邮箱地址1','目标邮箱地址2']#字符串列表则可以给多人发送
#to_addr = '目标邮箱地址'
#发信服务器
#smtp_server = 'smtp.qq.com'
smtp_server = 'smtp.yandex.com'
#邮箱正文内容,第一个参数为内容,第二个参数为格式(plain 为纯文本),第三个参数为编码
msg = MIMEText(str(content),'plain','utf-8')
#邮件头信息
msg['From'] = Header(from_addr)
msg['To'] = Header(','.join(to_addr))
msg['Subject'] = Header('python test')
#开启发信服务,这里使用的是加密传输
server = smtplib.SMTP_SSL()
server.connect(smtp_server, 465)
#登录发信邮箱
server.login(from_addr, password)
#发送邮件
server.sendmail(from_addr, to_addr, msg.as_string())
#关闭服务器
server.quit()
if __name__=="__main__":
post_email()附加功能部分2:将爬虫结果发送到指定QQ窗口
主要参考QQ自动发送消息,由于qqbot已经死了,而酷Q实在太麻烦,最终还是选择pywin32对窗口进行操作。
保存于文件qq2.py中:
import win32gui
import win32con
import win32clipboard as w
def send2QQ(msg = "想发的消息",name = "QQ窗口名"):
#将测试消息复制到剪切板中
w.OpenClipboard()
w.EmptyClipboard()
w.SetClipboardData(win32con.CF_UNICODETEXT, msg)
w.CloseClipboard()
#获取窗口句柄
handle = win32gui.FindWindow(None, name)
if 1 == 1:
#填充消息
win32gui.SendMessage(handle, 770, 0, 0)
#回车发送消息
win32gui.SendMessage(handle, win32con.WM_KEYDOWN, win32con.VK_RETURN, 0)
if __name__=="__main__":
send2QQ()
有个缺点,发完消息会停留在消息窗口,不会自动返回原窗口。
附加功能部分3:短信
参考Python3使用twilio模块发送短(免)信(费)的方法(详细)可以弄个免费试用,2020年10月初始附送15.5美刀的样子。
# -*- coding:utf-8 -*-
from twilio.rest import Client
def send_message(messages, receive_number='+86171XXXX1121'):#设置的接收人号码
"""
| *信息内容* | *接收信息号码* |
| 自动发送 | +86171XXXX1121 |
:param messages: 发送信息的内容
:receive_number: 需要再twilio网站验证号码才能接收
网址:https://www.twilio.com/console/phone-numbers/verified
"""
phone_number = '+135XXXX3140' # 步骤6由网站分配的
account_sid = "ACd92fxxx20743"
auth_token = "731cxxx7319"
def beging_sending_message(msg, target_number):
try:
client = Client(account_sid, auth_token)
client.messages.create(to=target_number, from_=phone_number, body=msg)
return True
except Exception:
return False
if beging_sending_message(messages, receive_number):
print("短信已成功发送至%s" % receive_number)
else:
print("短信发送失败!!!")
if __name__ == "__main__":
send_message("中文测试")后续功能开发中

















 2286
2286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









