






本文目录
写在最前
项目的github网址(https://github.com/THUDM/ChatGLM-6B)中有解决问题专用的Issues模块
建议遇到问题先将部分报错写在这里进行查询,大概率能找到问题的解决方法
本文章只用于记录个人在使用过程中遇到的问题,供以后回忆之用。
个人windows电脑部署时遇到
以下都是在运行cli_demo.py遇到
KeyError: ‘chatglm’
# 出现异常描述
(ai) Q:\Python\project\ChatGLM\ChatGLM-6B-main>python cli_demo.py
Traceback (most recent call last):
File "cli_demo.py", line 7, in <module>
tokenizer = AutoTokenizer.from_pretrained("THUDM/ChatGLM-6B", trust_remote_code=True)
File "Q:\IDE\Python\vitrual_enviroment\ai\lib\site-packages\transformers\models\auto\tokenization_auto.py", line 362, in from_pretrained
config = AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
File "Q:\IDE\Python\vitrual_enviroment\ai\lib\site-packages\transformers\models\auto\configuration_auto.py", line 371, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
KeyError: 'chatglm'
问题原因:transformers版本有问题
推荐版本是4.27.1 ,但是好像不太行
解决方法
- 在出现这个问题之前,我先遇到了一个问题提示找不到模型,然后我查了以后有人说是因为transformer版本太低,然后我就把版本提升到4.3以上的一个版本,然后就出现了上所示问题
- 重新去github上找人答疑时,有人说需要版本得是transformers 4.28.1,我就死马当活马医重新pip install,发现解决了,进入下一个问题
OSError/AssertionError/Failed to load cpm_kernels
(ai) Q:\Python\project\ChatGLM\ChatGLM-6B-main>python cli_demo.py
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
Explicitly passing a `revision` is encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
--- Logging error ---
Traceback (most recent call last):
File "C:\Users\user/.cache\huggingface\modules\transformers_modules\ChatGLM-6B\quantization.py", line 19, in <module>
from cpm_kernels.kernels.base import LazyKernelCModule, KernelFunction, round_up
File "Q:\IDE\Python\vitrual_enviroment\ai\lib\site-packages\cpm_kernels\__init__.py", line 1, in <module>
from . import library
File "Q:\IDE\Python\vitrual_enviroment\ai\lib\site-packages\cpm_kernels\library\__init__.py", line 2, in <module>
from . import cuda
File "Q:\IDE\Python\vitrual_enviroment\ai\lib\site-packages\cpm_kernels\library\cuda.py", line 7, in <module>
cuda = Lib.from_lib("cuda", ctypes.WinDLL("nvcuda.dll"))
File "q:\ide\python\cpython37\lib\ctypes\__init__.py", line 356, in __init__
self._handle = _dlopen(self._name, mode)
OSError: [WinError 126] 找不到指定的模块。
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "q:\ide\python\cpython37\lib\logging\__init__.py", line 1034, in emit
msg = self.format(record)
File "q:\ide\python\cpython37\lib\logging\__init__.py", line 880, in format
return fmt.format(record)
File "q:\ide\python\cpython37\lib\logging\__init__.py", line 619, in format
record.message = record.getMessage()
File "q:\ide\python\cpython37\lib\logging\__init__.py", line 380, in getMessage
msg = msg % self.args
TypeError: not all arguments converted during string formatting
Call stack:
File "cli_demo.py", line 8, in <module>
model = AutoModel.from_pretrained("THUDM\ChatGLM-6B", trust_remote_code=True).half().cuda()
File "Q:\IDE\Python\vitrual_enviroment\ai\lib\site-packages\transformers\models\auto\auto_factory.py", line 467, in from_pretrained
pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs
File "Q:\IDE\Python\vitrual_enviroment\ai\lib\site-packages\transformers\modeling_utils.py", line 2629, in from_pretrained
model = cls(config, *model_args, **model_kwargs)
File "C:\Users\user/.cache\huggingface\modules\transformers_modules\ChatGLM-6B\modeling_chatglm.py", line 1061, in __init__
self.quantize(self.config.quantization_bit, self.config.quantization_embeddings, use_quantization_cache=True, empty_init=True)
File "C:\Users\user/.cache\huggingface\modules\transformers_modules\ChatGLM-6B\modeling_chatglm.py", line 1424, in quantize
from .quantization import quantize, QuantizedEmbedding, QuantizedLinear, load_cpu_kernel
File "<frozen importlib._bootstrap>", line 983, in _find_and_load
File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 677, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 728, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "C:\Users\user/.cache\huggingface\modules\transformers_modules\ChatGLM-6B\quantization.py", line 46, in <module>
logger.warning("Failed to load cpm_kernels:", exception)
Message: 'Failed to load cpm_kernels:'
Arguments: (OSError(22, '找不到指定的模块。', None, 126, None),)
No compiled kernel found.
Compiling kernels : C:\Users\user\.cache\huggingface\modules\transformers_modules\ChatGLM-6B\quantization_kernels_parallel.c
Compiling gcc -O3 -fPIC -pthread -fopenmp -std=c99 C:\Users\user\.cache\huggingface\modules\transformers_modules\ChatGLM-6B\quantization_kernels_parallel.c -shared -o C:\Users\user\.cache\huggingface\modules\transformers_modules\ChatGLM-6B\quant
ization_kernels_parallel.so
'gcc' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
Compile default cpu kernel failed, using default cpu kernel code.
Compiling gcc -O3 -fPIC -std=c99 C:\Users\user\.cache\huggingface\modules\transformers_modules\ChatGLM-6B\quantization_kernels.c -shared -o C:\Users\user\.cache\huggingface\modules\transformers_modules\ChatGLM-6B\quantization_kernels.so
'gcc' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
Compile default cpu kernel failed.
Failed to load kernel.
Cannot load cpu or cuda kernel, quantization failed:
Traceback (most recent call last):
File "cli_demo.py", line 8, in <module>
model = AutoModel.from_pretrained("THUDM\ChatGLM-6B", trust_remote_code=True).half().cuda()
File "Q:\IDE\Python\vitrual_enviroment\ai\lib\site-packages\transformers\models\auto\auto_factory.py", line 467, in from_pretrained
pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs
File "Q:\IDE\Python\vitrual_enviroment\ai\lib\site-packages\transformers\modeling_utils.py", line 2629, in from_pretrained
model = cls(config, *model_args, **model_kwargs)
File "C:\Users\user/.cache\huggingface\modules\transformers_modules\ChatGLM-6B\modeling_chatglm.py", line 1061, in __init__
self.quantize(self.config.quantization_bit, self.config.quantization_embeddings, use_quantization_cache=True, empty_init=True)
File "C:\Users\user/.cache\huggingface\modules\transformers_modules\ChatGLM-6B\modeling_chatglm.py", line 1439, in quantize
self.transformer = quantize(self.transformer, bits, use_quantization_cache=use_quantization_cache, empty_init=empty_init, **kwargs)
File "C:\Users\user/.cache\huggingface\modules\transformers_modules\ChatGLM-6B\quantization.py", line 464, in quantize
assert kernels is not None
AssertionError
问题原因:配置内容没有修改、依赖包不完整
解决方法
这里有多个问题需要解决
-
gcc编译器未安装
- 项目的readme有写(位于使用方式/环境安装部分),如果安装时需要用cpu运行,必须安装gcc与openmp
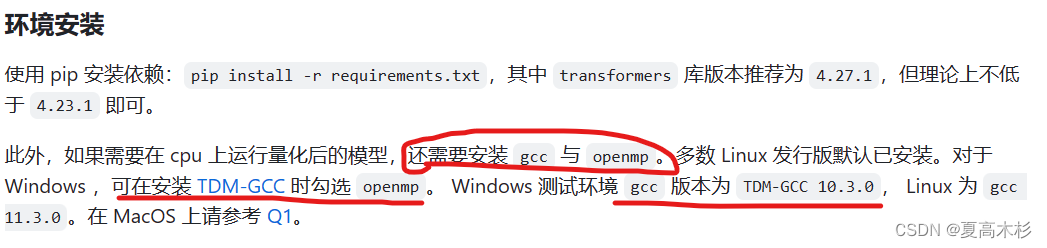
- 下载的地址位于 (https://jmeubank.github.io/tdm-gcc/) 点进去以后因为推荐的是TDM-GCC 10.3.0,因此单击TDM-GCC 10.3.0 release,进去之后再点击(tdm64-gcc-10.3.0-2.exe)下载。
- 下载完成后点击运行文件,点create,然后点下一步,遇到能选openmp的时候记得选上就行
-
配置内容未修改
- 这里首先,要修改模型文件中的(即THUDM\ChatGLM-6B下的,或是model中的)THUDM/ChatGLM-6B/quantization.py这一文件
from cpm_kernels.kernels.base import LazyKernelCModule, KernelFunction, round_up这行注释掉,后面会飘红也没关系,不用改- 把kernels = Kernel(…)注释掉,替换为kernels =CPUKernel() # 说实话这一步是否有用我不是很确定,后续重新运行时依然提示
NameError: name 'CPUKernel' is not defined,但是不影响程序运行 - 再把已缓存的.cache目录下文件删掉!!! ,这里看报错的地方,我的缓存文件在 File “C:\Users\user/.cache\huggingface\modules\transformers_modules\ChatGLM-6B\quantization.py”
- 把.cache后面的huggingface文件夹直接删除
- 最后要记得修改cli_demo.py中的内容
model = AutoModel.from_pretrained("THUDM\ChatGLM-6B", trust_remote_code=True).half().cuda()- 改成:
model = AutoModel.from_pretrained("THUDM\ChatGLM-6B", trust_remote_code=True).float()
以上修改完成后,我的程序就已经可以运行了

想要运行web_demo2.py时遇到
No matching distribution found for streamlit-chat
(ai) Q:\Python\project\ChatGLM\ChatGLM-6B-main>pip install streamlit-chat
ERROR: Could not find a version that satisfies the requirement streamlit-chat (from versions: 0.0.1)
ERROR: No matching distribution found for streamlit-chat
问题原因:组件必须要在python>3.8的环境才能运行!!!!
哇这个问题真的是没把我弄死,streamlit很容易就用pip install 下载完成了,后面的streamlit-chat怎么也下载不了,经历了查资料、换源等一系列操作之后,我决定从PYPI官网下载,如愿以偿让我找到了就在我用如下命令进行下载时
(ai) Q:\Python\project\ChatGLM\ChatGLM-6B-main>pip --default-timeout=100 install streamlit_chat-0.0.2.2-py3-none-any.whl
Processing q:\python\project\chatglm\chatglm-6b-main\streamlit_chat-0.0.2.2-py3-none-any.whl
Requirement already satisfied: streamlit>=0.63 in q:\ide\python\vitrual_enviroment\ai\lib\site-packages (from streamlit-chat==0.0.2.2) (1.23.1)
ERROR: Package 'streamlit-chat' requires a different Python: 3.7.2 not in '>=3.8'
WARNING: You are using pip version 22.0.3; however, version 23.1.2 is available.
You should consider upgrading via the 'Q:\IDE\Python\vitrual_enviroment\ai\Scripts\python.exe -m pip install --upgrade pip' command.
看懂了吗xdm,这个组件必须要在python>3.8的环境才能运行。。















 5672
5672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









