







摘要
手部姿势估计 (HPE) 对许多应用至关重要,但传统的基于相机的 CM-HPE 方法完全受制于视线 (LoS)。本文利用能够绕过障碍物的射频视觉(RF-vision)来实现遮挡 HPE(human pose estimation),并引入OCHID-Fi 作为第一个具有 3D 姿态估计能力的 RF-HPE 方法。鉴于RF成像具有人类难以理解的性质,OCHID-Fi 采用了跨模态和跨域训练过程。它使用预训练的 CMHPE 网络和同步的 CM/RF 数据集,指导其复值 RF-HPE 网络在视距条件下的训练,随后再通过对抗性学习进一步将从标记的 LoS 域学到的知识转移到未标记的遮挡域,使 OCHID-Fi 能够泛化到看不见的遮挡场景。
1 介绍
射频视觉(RF-vision)具有低复杂性(因此可以实时响应)、能源效率和易于部署性。这些优势促使人们使用 RF 视觉来解决 OV 未解决的问题 。RF-vision 的最大优势之一,即遮挡鲁棒性,仅被 RF-Pose轻微触及,因为粗粒度人体姿态估计仅在 LoS 域中训练并直接用于遮挡场景,而不考虑造成遮挡的障碍物的影响。文中重点利用RF视觉来对遮挡场景执行细粒度3D手势估计。
1.1主要挑战
- 关键点的非欧几里德映射:RF 数据不享受从信号空间到关键点位置的直接欧几里德映射。因此深度学习模型很难揭示内在关系。
- 低分辨率、复值RF 数据的模型设计:CM-HPE 模型无法处理低分辨率复值RF 数据,而RF-HGR 模型专为分类而设计,而RF-HPE 本质上是回归任务。
-
遮挡场景的模型训练:遮挡场景中的射频数据会受到障碍物反射和折射的显着影响。在这种场景下为 RF-HPE 模型设计训练机制非常重要
1.2主要贡献
OCHID-Fi 通过预训练 CM-HPE 模型辅助的跨模态训练将射频信号转换为手部关键点,在视距场景中的数据收集过程中采用一对同步的摄像头和射频传感器。CM-HPE 网络首先使用 OptiTrack系统收集的伪地面实况进行训练,随后通过监督 OCH-Net 和 RF 地面实况数据将其学到的知识转移到 OCH-Net。
设计了一个深度复值网络来处理复值射频数据执行特征提取。完成第一阶段训练使得深度复值网络 OCH-Net(闭塞手部网络)能够在视距(LoS)情况下独立工作,第二阶段训练 OCH-AL(闭塞手部对抗学习)将进一步在跨区域传递知识。以无监督的方式利用对抗性学习。
-
OCHID Fi将知识从OV转移到RF,有效地弥合了复杂的RFvision数据和手关键点之间的差距。
-
OCH-Net被提议作为复值RF-HPE模型来拟合RF信号,从而有可能充分利用固有的RF特征。
-
OCH-AL以无监督的方式利用对抗性学习,从而将知识从LoS领域进一步转移到被遮挡的领域。
在 OV 完全失效的遮挡场景中,OCHIDFi 在视距条件下实现了与 CM-HPE 相似的精度,实证结果还表明,OCHID-Fi 可以推广到不可见的遮挡场景。

2 Related Work
HGR的实现有很多通过照片和视频的OV方法,但无法满足HPE问题的需求,因为HGR只是分类问题,对手势进行分类,不是准确地估计手部的关键点。当然,为了解决HPE问题,也有很多基于视觉的方案,例如handfoldingnet使用深度图像作为输入,openpose采用多摄像头系统进行细粒度的手部关键点检测,其他也有依靠神经网络来提取手部关键点单个 RGB 图像。
不幸的是,所有这些方法都无法在手隐藏在纸板或袖子后面的遮挡情况下完成 HPE 任务。最近的研究表明,区分人体不同部位反射的射频信号是可能的。身体部位的形状和动作幅度会影响反射射频信号的强度,从而能够通过深度分析重建人体姿势。尽管RF已成功解决 HGR,但这些解决方案与 HPE 的要求不兼容。
3 OCHID-Fi Design
三个关键组件,深度跨模态框架、深度复值网络 OCH-Net 以及深度对抗学习算法 OCH-AL。相机和射频传感器根据其不同位置进行外部校准,并使用网络时间协议进行同步。在将射频信号输入神经模型之前,采用射频预处理模块来抑制噪声并提高信号质量。 RF 预处理模块采用平滑滤波器和带通滤波器来处理 RF 信号 。
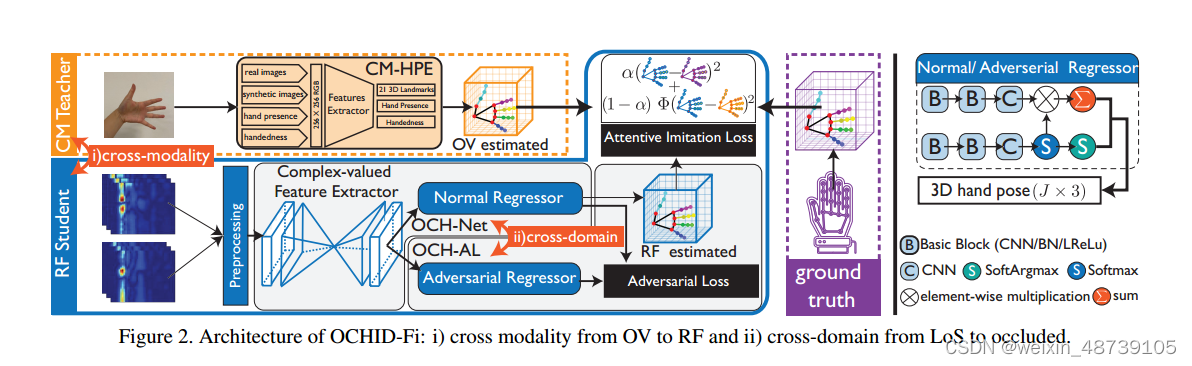
C1:使用从 OptiTrack 获得的地面实况来预训练 CM-HPE 网络,并通过最小化注意力模仿损失,在 LoS 情况下将知识跨模态从 CM-HPE 转移到 RF-HPE。
C2:为了处理复值 RF 信号,构建了 RF-HPE 网络 OCH-Net 作为复值特征提取器和 2D-3D 回归器。
C3:为了推广到具有看不见的障碍的遮挡域,我们进一步采用对抗性学习将知识从 LoS 域转移到遮挡域。具体来说,添加对抗性回归器以与 OCH-Net 回归器形成极小极大游戏,从而允许无监督训练。
3.1 Deep Cross-Modality Framework
解决将RF信号映射到首部关键点的挑战,采用注意力模仿损失:T表示教师OV网络,S表示学生RF网络,y为groundtruth。


3.2 OCH-Net:深层复杂视角
射频张量由来自多个天线的数据组成。单个 RF 脉冲不足以满足视觉需求,因此在时间和空间上(通过不同的天线)发射多个脉冲,并将接收到的信号组合起来形成 RF 张量 X,其每个元素都是具有 I/Q 分量的复数x(n, t, d) = xI + jxQ,其中n、t和d分别表示天线阵列中的发射机-接收机对、RF脉冲的数量和离散距离段的数量[8]。特别是,每个 x(n, t, d) 的相位携带有关目标相对位移的重要信息。为了充分利用 RF 数据 I/Q 组件的潜力,提出了专门处理复值 RF 数据张量的 OCH-Net。

1 Building Blocks for Complex
2 OCH-Net Architecture
特征提取器基于具有跳跃连接的流行编码器-解码器架构 [32] 。编码器和解码器块通过跳跃连接配对并连接,以促进信息流。
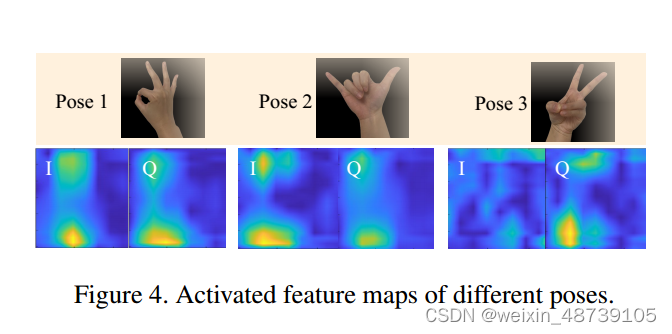
系统中的每个编码器块由复值卷积层、批量归一化层和具有泄漏 ReLU 的非线性激活层组成。每三个块之后,通道数量增加,并应用最大池化层来增强最突出的特征并减少隐藏层的维度,从而降低复杂度。一旦瓶颈块提取潜在空间中的表示,就会利用上采样层来反转解码过程的压缩。将解码后的特征输入回归器以映射到 3D 手部关键点。回归器的下分支恢复 2D 手部关键点,而上分支恢复关键点的深度。最后,通过结合 2D 和深度估计来重建 3D 关键点。OCH-Net的必要性:I 和 Q 数据生成的特征图具有显着差异,其中亮黄色区域代表特征图中激活的神经元。仅依靠 RF 数据的 I 或 Q 分量作为输入可能不足以捕获 RF 数据的所有内在特征以估计手部姿势。
3.3 Deep Adversarial Learning for Occlusion
由于 OCH-Net 仅适用于正常域,因此我们需要将学到的知识转移到遮挡域,该训练算法的目标是最大化遮挡域中的回归精度。
Minimax Game:引入无监督训练方法,利用极大极小博弈最小化在遮挡域上的预期损失,同时在正常域上保持较好的性能。利用视差差异理论来实现。
Bounding Output Space:与分类任务(HGR)相比,HPE 涉及具有更大输出空间的回归。具体来说,如果我们考虑存在于尺寸为高度 H、宽度 W 和深度 R 的 3D 体素空间中的目标手部姿势,并将每个输出体素视为一个类,我们将有 H × W × R 类。因此,大量的输出类将增加遮挡域错误的范围。因此,有必要减少HPE网络的输出空间。关键点位置存在内在的稀疏性,这表明输出空间大小可以限制在一个有限的集合内。
4 评估
4.1 实验设置
OV数据集:1080 × 1920 pixels和 30 Hz 帧速率的相机。
RF 数据集:由于不可能从商用设备(例如 iPhone)访问原始信号,使用10 个天线的IR-UWB雷达来模拟这种 RF 传感器。 帧速率设置为150 Hz,摄像头和射频传感器均连接至 PC 进行同步。
OptiTrack用于获取 3D 手势地面实况,评估使用 10 小时的正常条件数据(120,000 个样本)来训练 OCH-Net,然后这些数据加上额外的 2 小时的遮挡数据(24,000 个样本)来训练 OCH-AL(对抗学习),最后使用所有剩余数据进行测试。
教师网络:MediaPipe Hands。MediaPipe Hands的两个关键参数设置为1和0.5,即最大手数和最小检测置信度。该网络首先使用 OptiTrack 收集的 OV 数据和地面实况进行预训练。随后,我们利用 MediaPipe 的输出和基本事实将知识传输到 OCH-Net。
train details:在NVIDIA RTX 1080 GPU 的服务器上训练和评估我们的方法。在 Python 3.8.16 和 Pytorch 1.10.0 上实现了 OCH-Net 和 OCH-AL。输入 RF 张量的大小为 10 × 40 × 40,比例因子a为0.5。特征提取器中,每个卷积层的通道数在编码器中设置为 10、64、128、256 和 512,在解码器中设置为 512、256、128、64 和 32。batch size为8,并采用Adam优化器,lr为0.001,β1为0.9,β2为0.999。
评估指标:正确关键点百分比 (PCK) 指标,还计算了掌指关节 (MCP)、近端指间关节 (PIP)、远端指间关节 (DIP) 和指尖关节的 PCK。
4.2 性能评估
两种现有的 RF 视觉方法作为基线,即 Person-in-WiFi [43] 和 RF-Pose [52]
1 Performance of OCH-Net
目前还没有针对射频视觉手部姿势设计的直接相关研究工作。因此,必须修改当前的人体骨骼神经网络模型使其与OCH-Net相当。具体来说,保留其网络架构的主要部分,但替换其输入和输出以匹配我们的 HPE 任务。此外,OCH-Net 可以适应不同数量的 RF 数据流,因为网络将其视为输入通道的数量。为了验证这一点,我们通过从 RF 天线收集的 10 个数据流中提取 2 个数据流来创建另一个基线 OCH-Net-Slim。
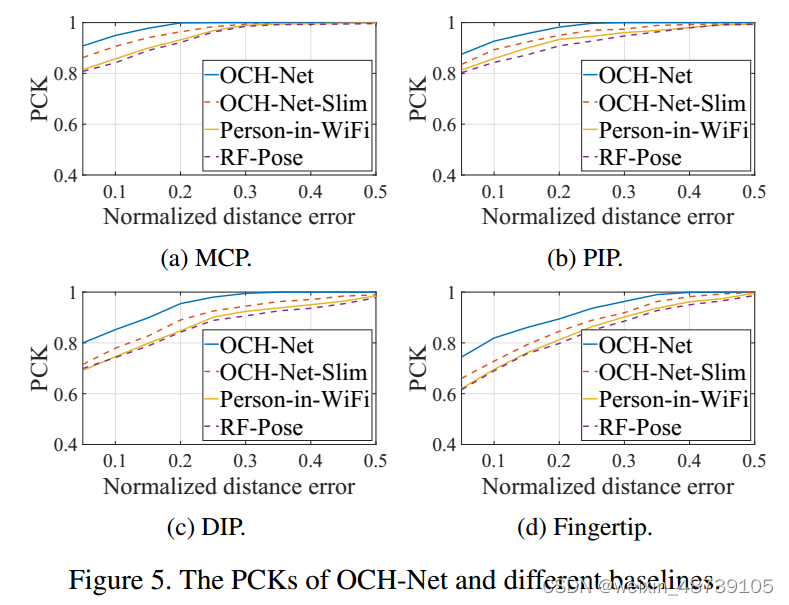
与这两个基线相比,使用 OCH-Net 有两个主要优点。一方面,OCHNet 从地面实况和教师网络中获取知识,有效地弥合了复杂的射频视觉数据和手部关键点之间的差距。这使我们能够实现非欧几里得映射。另一方面,OCH-Net 中的深层复值构建块更适合解释和编码 RF 数据。
2 Performance of OCH-AL under Occlusion
采用 OCH-AL 框架来从正常域适应到封闭域。来自所有 4 种类型障碍物(即木材、塑料、玻璃和纸板)的数据都用于适应。
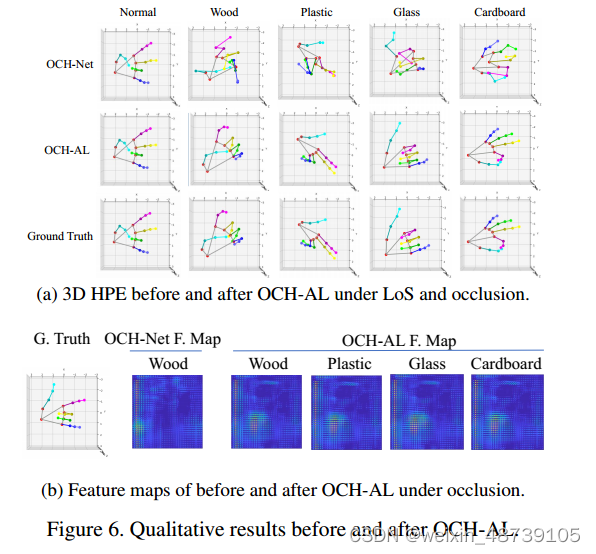
在图 7 中绘制了 OCH-AL 在不同关键点上的性能。结果显示 OCH-AL 对于 MCP、PIP、DIP 和指尖分别实现了 0.9998、0.9890、0.9410 和 0.8506 的 PCKs@0.2。相比之下,OCH-Net 对于相同关键点的 PCK@0.2 分别为 0.9904、0.8934、0.7772 和 0.4615。这些发现表明 OCH-AL 成功地将 OCHNet 从正常域适应到遮挡域,从而使所有手部部件的性能得到显着提高。

3 Generalization to Unseen Occluded Scenarios
验证 OCH-AL 的普适性,具体来说,从木材、塑料、玻璃和纸板中选择三种类型的障碍物进行适应,并留下一种进行测试。研究结果表明,OCH-AL 产生了显着的 PCK@0.2 分数,远远超过 OCH-Net 的平均 PCK。此外,当障碍物是塑料或纸板时,OCH-AL 的性能略好于当障碍物是玻璃或木材时,这可能是由于这些材料的介电常数和损耗角正切较低。
4 Adversarial Learning Algorithm Comparison
将OCH-AL与其他两种对抗性学习算法 DANN [21] 和 MCD [33] 进行比较,在所有三种算法中使用相同的特征提取器。虽然 MCD 和 DANN 帮助 OCH-Net 适应遮挡,但它们在正常域中的平均 PCK@0.2 分别减少了 0.10 和 0.13。相比之下,OCH-AL 在正常域和遮挡域中都保持一致的性能。如3.4节所述,OCHAL是专门为HPE回归任务设计的,通过限制输出空间的大小,因此它实现了成功的域适应,同时避免了不必要的参数更新,从而保留了OCH-Net在正常域中的性能。
5 Inference Time of OCHID-Fi
在推理阶段,只保留特征提取 和正常回归器进行评估。将 OCH-Net 的推理时间与三个基线进行比较,OCH-Net 的平均推理时间为 14ms,仅比基线略高最多 5ms。额外计算开销的主要原因是复值神经网络的使用。如果用 Real-Net 替换 OCH-Net,推理时间将减少到 10ms。
5 总结
利用精心设计的跨模态框架,我们展示了 OCHID-Fi 以非欧几里得方式将射频信号映射到手部关键点的能力。
此外,OCHID-Fi 成功地调整了其神经模型 OCH-Net,利用对抗性学习的力量来处理多样化的障碍。大量实验表明,即使在遮挡场景下,OCHID-Fi 在 HPE 中也能实现高精度。结果有力地支持了该方法的有效性,显示了其在人机交互(HCI)、智能家居控制和医疗康复等领域的实际应用潜力。















 3381
3381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









