






 博主使用pvnet训练自制custom数据集时,发现源码对自制数据处理不完善,训练集和测试集相同,影响网络训练和泛化性。博主解读源码后发现是使用同一json文件所致,修改handle_custom_dataset.py脚本生成train.json和test.json,并给出训练时修改dataset_catalog.py文件的步骤。
博主使用pvnet训练自制custom数据集时,发现源码对自制数据处理不完善,训练集和测试集相同,影响网络训练和泛化性。博主解读源码后发现是使用同一json文件所致,修改handle_custom_dataset.py脚本生成train.json和test.json,并给出训练时修改dataset_catalog.py文件的步骤。
题主在使用pvnet训练自制的custom数据集时发现pvnet的源码里对自制custom数据的处理不是很完善,发现在自制数据集进行实验时训练集和测试集用的是同一个:
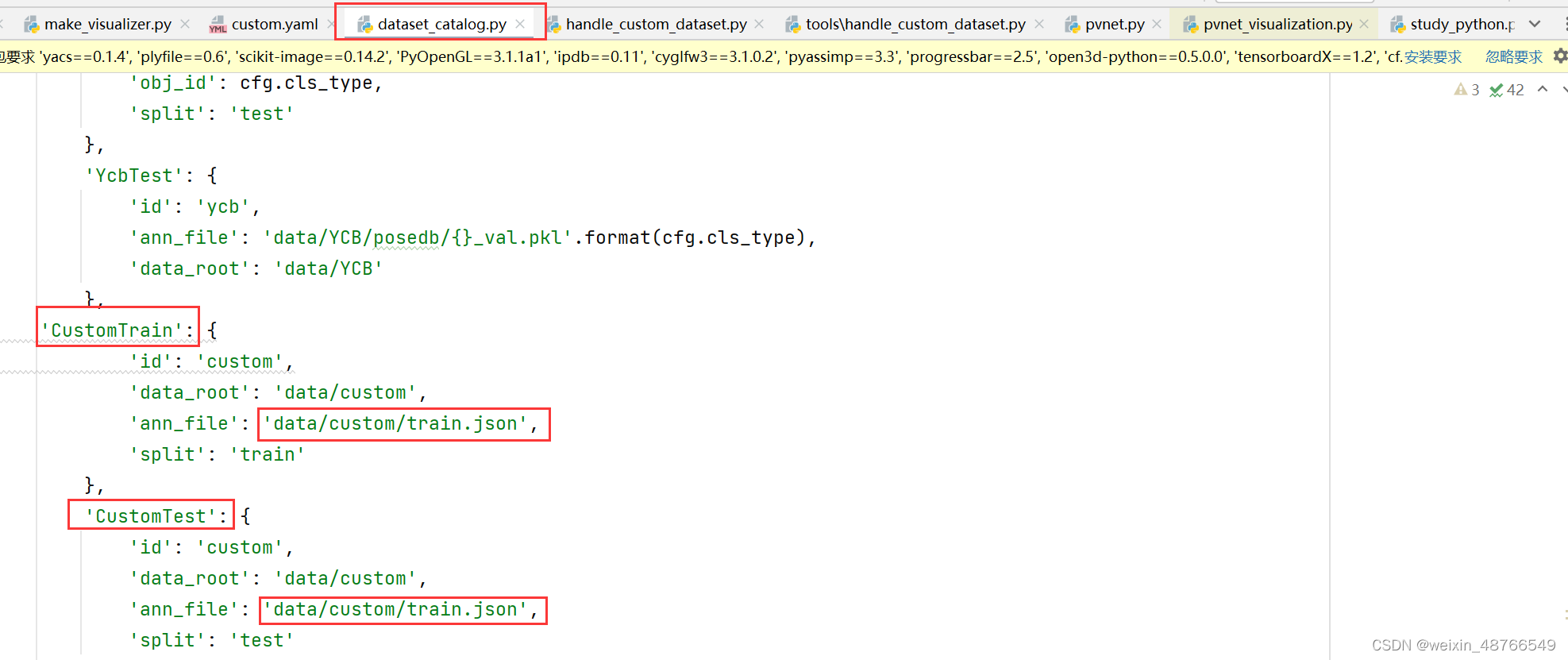
在训练时也发现训练集和测试集用的确实是同一个,所以这势必会严重影响网络的训练及泛化性等一些重要的指标,于是题主便转向作者的github上提出issue,在等了一天后没有回复,本着不打扰别人的原则,再三思索下把issue关了,决定自己解读作者的源码并进行修改:
进行一段时间的源码解读后发现影响训练的直接原因是训练和测试用的是同一个json文件,于是便顺藤摸瓜发现 handle_custom_dataset.py 是处理自制数据集并导出train.json文件的脚本,于是对这个源码进行修改,废话不多说,直接附上改后的代码和注释:
"""
by WillieChen
2024/1/13
"""
import os
from plyfile import PlyData
import numpy as np
from lib.csrc.fps import fps_utils
from lib.utils.linemod.opengl_renderer import OpenGLRenderer
import tqdm
from PIL import Image
from lib.utils import base_utils
import json
import random, shutil
def read_ply_points(ply_path):
ply = PlyData.read(ply_path)
data = ply.elements[0].data
points = np.stack([data['x'], data['y'], data['z']], axis=1)
return points
def sample_fps_points(data_root):
ply_path = os.path.join(data_root, 'model.ply') # model.ply 改写为自己的模型名
ply_points = read_ply_points(ply_path)
fps_points = fps_utils.farthest_point_sampling(ply_points, 8, True)
np.savetxt(os.path.join(data_root, 'fps.txt'), fps_points)
def get_model_corners(model):
min_x, max_x = np.min(model[:, 0]), np.max(model[:, 0])
min_y, max_y = np.min(model[:, 1]), np.max(model[:, 1])
min_z, max_z = np.min(model[:, 2]), np.max(model[:, 2])
corners_3d = np.array([
[min_x, min_y, min_z],
[min_x, min_y, max_z],
[min_x, max_y, min_z],
[min_x, max_y, max_z],
[max_x, min_y, min_z],
[max_x, min_y, max_z],
[max_x, max_y, min_z],
[max_x, max_y, max_z],
])
return corners_3d
def record_ann(model_meta, img_id, ann_id, images_train, annotations_train, images_test, annotations_test,): # 主要是修改这个函数
data_root = model_meta['data_root']
corner_3d = model_meta['corner_3d']
center_3d = model_meta['center_3d']
fps_3d = model_meta['fps_3d']
K = model_meta['K']
pose_dir = os.path.join(data_root, 'pose') # data/custom/pose
rgb_dir = os.path.join(data_root, 'rgb') # data/custom/rgb
mask_dir = os.path.join(data_root, 'mask') # data/custom/mask
filenames = []
for root, dirs, files in os.walk(rgb_dir): # 使用for循环将 rgb_dir里的文件名读取出来,存放在以files命名的列表中,后面有几句代码不写也行,直接用files进行后续操作
for name in files: # 从files列表中读取文件名,存储在空列表 filenames中
filenames.append(name) # list:['1001.png', '1006.png', '1009.png', '1010.png' 。。。]
break
# print(filenames)
filenum = len(filenames)
# print(filenum)
num_train = int(filenum * 0.8) # 将图片数量取80%作为训练集,也就是以8:2的比例进行训练和测试,后续想要调整比例改参数0.8即可
# print(num_train) # 995
sample_train = random.sample(filenames, num_train) # 使用random.sample() 函数对总数据集随机采样 num_train张图片
# print(sample_train)
sample_test = list(set(filenames).difference(set(sample_train))) # 在总数据集中取出不同于训练集的图片作为测试集
# print(sample_test)
# print(len(sample_test)) # 249
for name in sample_train: # 训练集部分,根据源码进行改写
name2num = name.split('.', 1)[0]
ind = name2num # class str
rgb_path = os.path.join(rgb_dir, '{}.jpg'.format(ind))
rgb = Image.open(rgb_path)
img_size = rgb.size
img_id = int(ind) + 1
info = {'file_name': rgb_path, 'height': img_size[1], 'width': img_size[0], 'id': img_id}
images_train.append(info)
pose_path = os.path.join(pose_dir, '{}.npy'.format(ind))
pose = np.load(pose_path)
pose = pose[:3, :]
corner_2d = base_utils.project(corner_3d, K, pose)
center_2d = base_utils.project(center_3d[None], K, pose)[0]
fps_2d = base_utils.project(fps_3d, K, pose)
mask_path = os.path.join(mask_dir, '{}.png'.format(ind))
ann_id = int(ind) + 1
anno = {'mask_path': mask_path, 'image_id': img_id, 'category_id': 1, 'id': ann_id}
anno.update({'corner_3d': corner_3d.tolist(), 'corner_2d': corner_2d.tolist()})
anno.update({'center_3d': center_3d.tolist(), 'center_2d': center_2d.tolist()})
anno.update({'fps_3d': fps_3d.tolist(), 'fps_2d': fps_2d.tolist()})
anno.update({'K': K.tolist(), 'pose': pose.tolist()})
anno.update({'data_root': rgb_dir})
anno.update({'type': 'real', 'cls': 'cat'})
annotations_train.append(anno)
for name in sample_test: # 测试集部分,根据源码进行改写
name2num = name.split('.',1)[0]
ind = name2num
rgb_path = os.path.join(rgb_dir, '{}.jpg'.format(ind))
rgb = Image.open(rgb_path)
img_size = rgb.size
img_id = int(ind) + 1 # img_id 和 id从 1开始
info = {'file_name': rgb_path, 'height': img_size[1], 'width': img_size[0], 'id': img_id}
images_test.append(info)
pose_path = os.path.join(pose_dir, '{}.npy'.format(ind))
pose = np.load(pose_path)
pose = pose[:3, :]
corner_2d = base_utils.project(corner_3d, K, pose)
center_2d = base_utils.project(center_3d[None], K, pose)[0]
fps_2d = base_utils.project(fps_3d, K, pose)
mask_path = os.path.join(mask_dir, '{}.png'.format(ind))
ann_id = int(ind) + 1 # ann_id 和 id从 1开始
anno = {'mask_path': mask_path, 'image_id': img_id, 'category_id': 1, 'id': ann_id}
anno.update({'corner_3d': corner_3d.tolist(), 'corner_2d': corner_2d.tolist()})
anno.update({'center_3d': center_3d.tolist(), 'center_2d': center_2d.tolist()})
anno.update({'fps_3d': fps_3d.tolist(), 'fps_2d': fps_2d.tolist()})
anno.update({'K': K.tolist(), 'pose': pose.tolist()})
anno.update({'data_root': rgb_dir})
anno.update({'type': 'real', 'cls': 'cat'})
annotations_test.append(anno)
return img_id, ann_id # 其实这两个值没什么用,也可以返回,后续调用不接收即可
def custom_to_coco(data_root): # 基于源码进行改写,导出 train.json和 test.json文件
model_path = os.path.join(data_root, 'model.ply') # model.ply 改写为自己的模型名
renderer = OpenGLRenderer(model_path)
K = np.loadtxt(os.path.join(data_root, 'camera.txt'))
model = renderer.model['pts'] / 1000
corner_3d = get_model_corners(model)
center_3d = (np.max(corner_3d, 0) + np.min(corner_3d, 0)) / 2
fps_3d = np.loadtxt(os.path.join(data_root, 'fps.txt'))
model_meta = {
'K': K,
'corner_3d': corner_3d,
'center_3d': center_3d,
'fps_3d': fps_3d,
'data_root': data_root,
}
img_id = 0
ann_id = 0
images_train = []
annotations_train = []
images_test = []
annotations_test = []
img_id, ann_id = record_ann(model_meta, img_id, ann_id, images_train, annotations_train, images_test, annotations_test)
categories = [{'supercategory': 'none', 'id': 1, 'name': 'yourclass'}] # yourclass 改写为自己的物体类别名
instance_train = {'images': images_train, 'annotations': annotations_train, 'categories': categories}
instance_test = {'images': images_test, 'annotations': annotations_test, 'categories': categories}
anno_path_train = os.path.join(data_root, 'train.json')
with open(anno_path_train, 'w') as f:
json.dump(instance_train, f)
anno_path_test = os.path.join(data_root, 'test.json')
with open(anno_path_test, 'w') as f:
json.dump(instance_test, f)以上代码中模型名称需改为自己模型的名字,yourclass 需改为你自己的物体类别名。将我的代码复制粘贴到tools/handle_custom_dataset.py中运行后会在data_root路径下生成train.json和test.json两个文件:
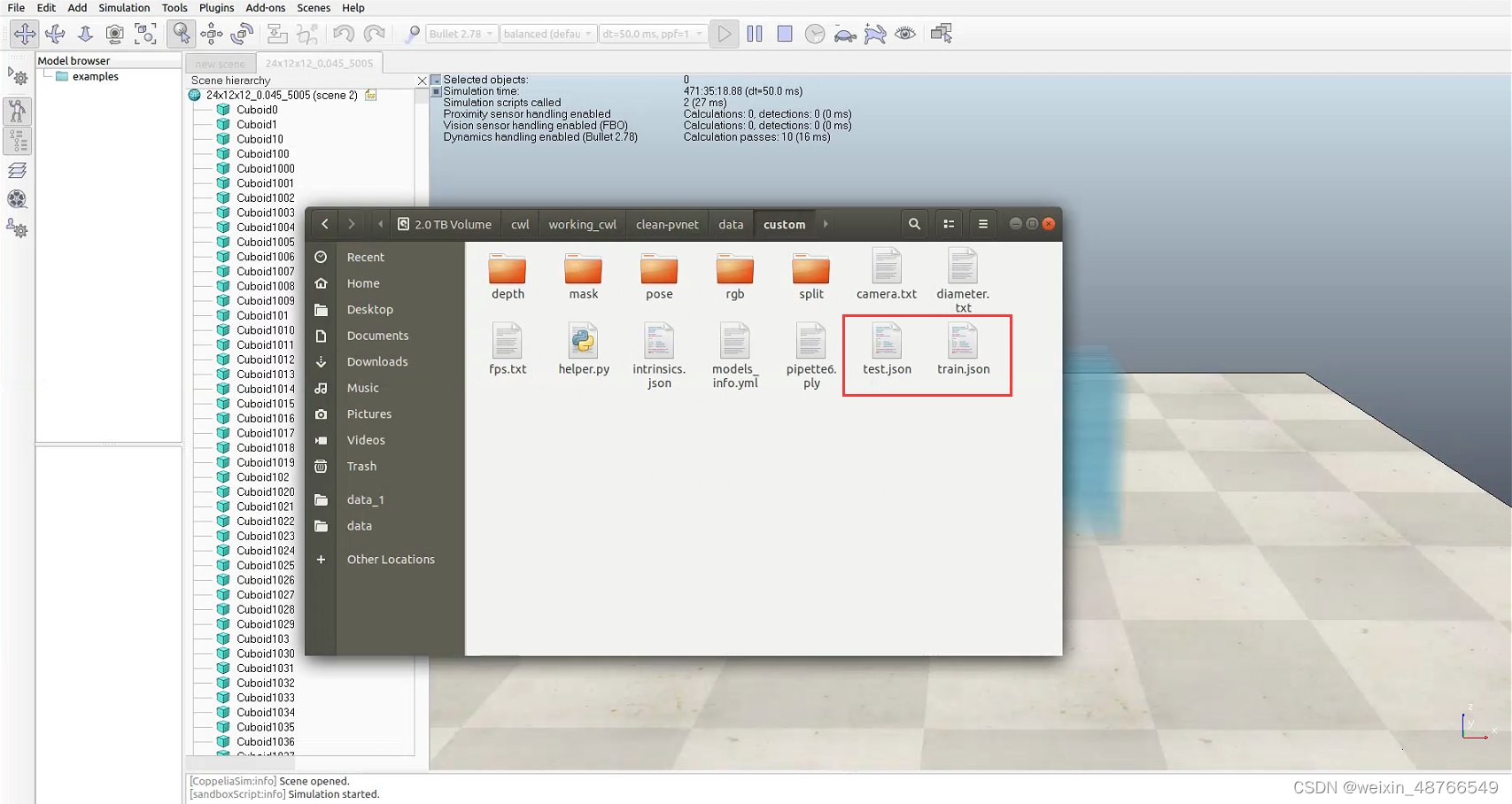
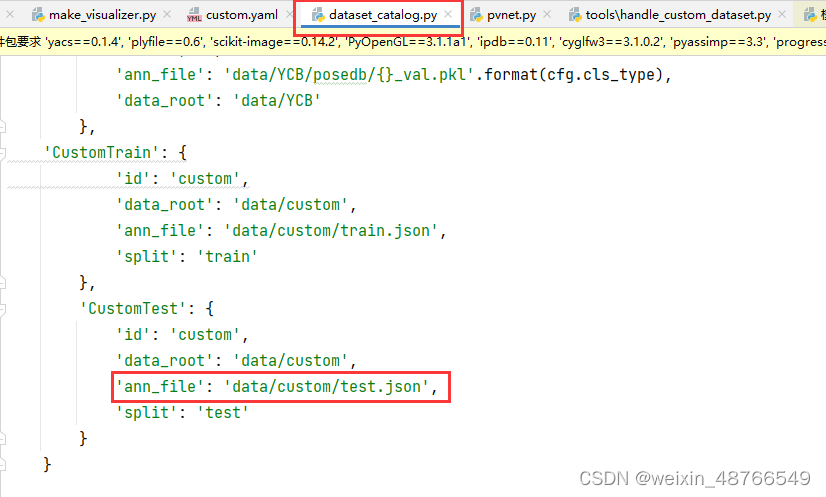
另外训练时需将开头提到的dataset_catalog.py文件中的"ann_file"的值改为自己 test.json的路径名:
以上便是划分数据集的所有步骤,我还写了一点pvnet测试时将可视化图片和位姿信息导出的代码,大家感兴趣的话后续再分享。创作不易,希望大家点点赞和关注!!!

















 1205
1205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









