






目录
Step1:define a set of function
Back to step 1:Redesign the model
摘要
本周学习了深度学习的步骤与机器学习类似,不同之处在于深度学习里的函数是由神经网络组成的,每一个神经元是一个函数,神经元的参数由权重和偏置组成。在深度学习中,交叉熵是用来衡量实际概率分布与预测概率分布之间差异的一种度量方法,常用于分类问题中,用来衡量模型的预测结果与真实标签之间的差异性,交叉熵越小,说明模型的预测结果越好。反向传播就是用链式求导法则来计算导数,反向传播能够有效率的计算出损失函数,用于更新模型参数。在预测神奇宝贝Pokemon的CP值时,我们可以选择不同的函数来预测输出,需要通过定义Loss Function来评估函数的好坏,并通过Gradient Descent来找到最佳的参数。如果函数过于复杂,会出现过拟合的问题,需要加入正则化来平衡模型的复杂度和准确度。在使用模型进行预测时,要注意选择合适的函数、调整参数和评估指标,以获得更好的预测效果。
ABSTRACT
This week, I learned about the steps involved in deep learning, which are similar to those in machine learning, with the difference being that the functions in deep learning are composed of neural networks, with each neuron being a function whose parameters are made up of weights and biases. In deep learning, cross entropy is a measure used to assess the difference between actual and predicted probability distributions, commonly used in classification problems to evaluate the difference between model prediction results and true labels. The smaller the cross entropy, the better the model predictions. Backpropagation is a technique that uses the chain rule to calculate derivatives and effectively computes the loss function used for updating model parameters. When predicting CP values for Pokémon, we can use different functions to predict the output, define a loss function to evaluate the quality of the function, and use gradient descent to find the best parameters. If the function is too complex, overfitting can occur, so regularization is added to balance model complexity and accuracy. When using models for prediction, it is important to choose appropriate functions, adjust parameters and evaluation metrics to obtain better prediction results.
一、深度学习简介
深度学习的步骤与机器学习一样,define a set of function 里的一个function就是一个 neural network。

Step1:define a set of function
不同的neural组合成了neural network;每个neural里都有自己的w、b;用不同的方法连接这些neural network就得到了不同的structures。
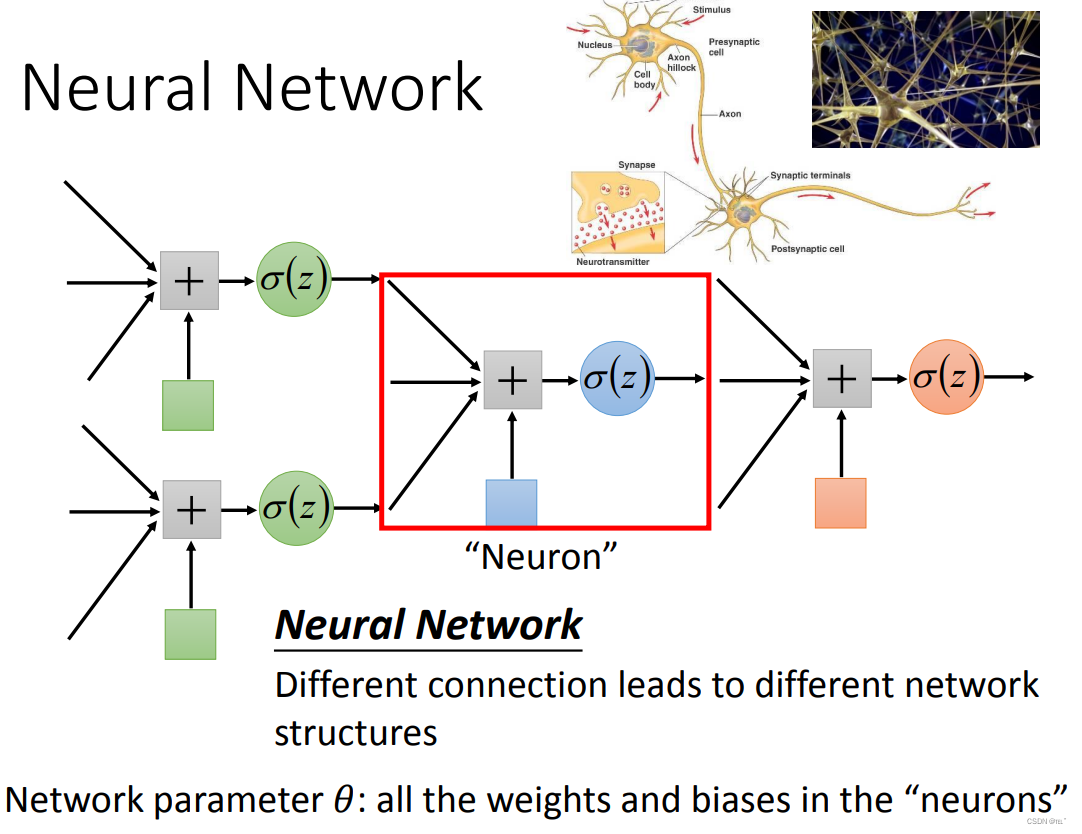
如何连接这些neural呢?
将neural排成一排一排,假设neural的w、b是如图所示的值,输入值通过sigmoid函数,就可以得到数值,再依次代入每一个neural,就可以得到输出值。如输入1、-1输出是0.62、0.83;输入是0、0输出是0.51、0.85。(一个neural就是一个函数)

简化来说,由很多排的Layer,每个Layer里有很多的neural;相邻层Layer里的neural相互连接,前一排的输出值为下一排的输入值。整个network由Input Layer、Output Layer、Hidden Layers组成。深度学习(Deep Learning)里的Deep就是Many Hidden Layers。
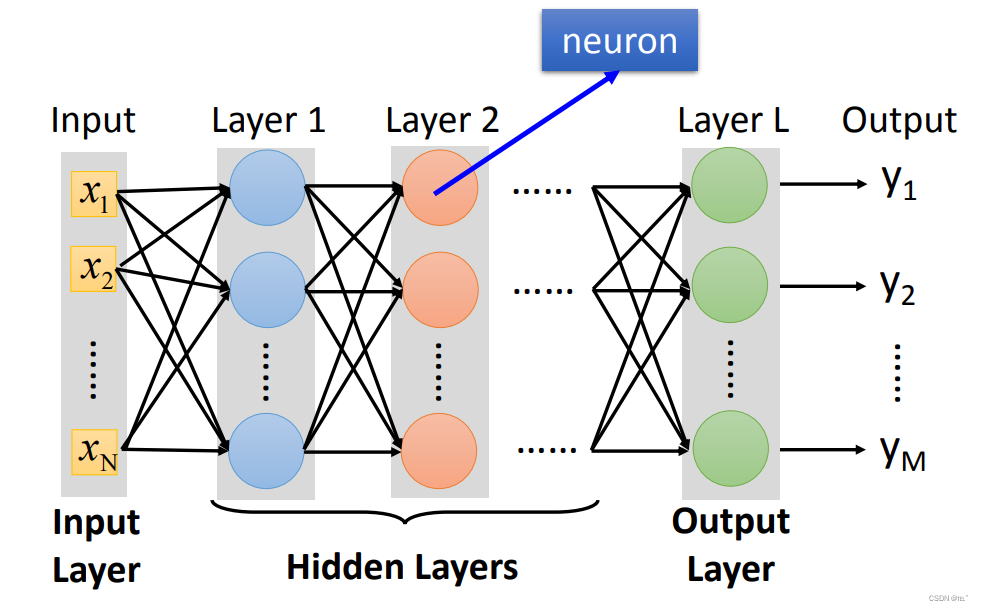
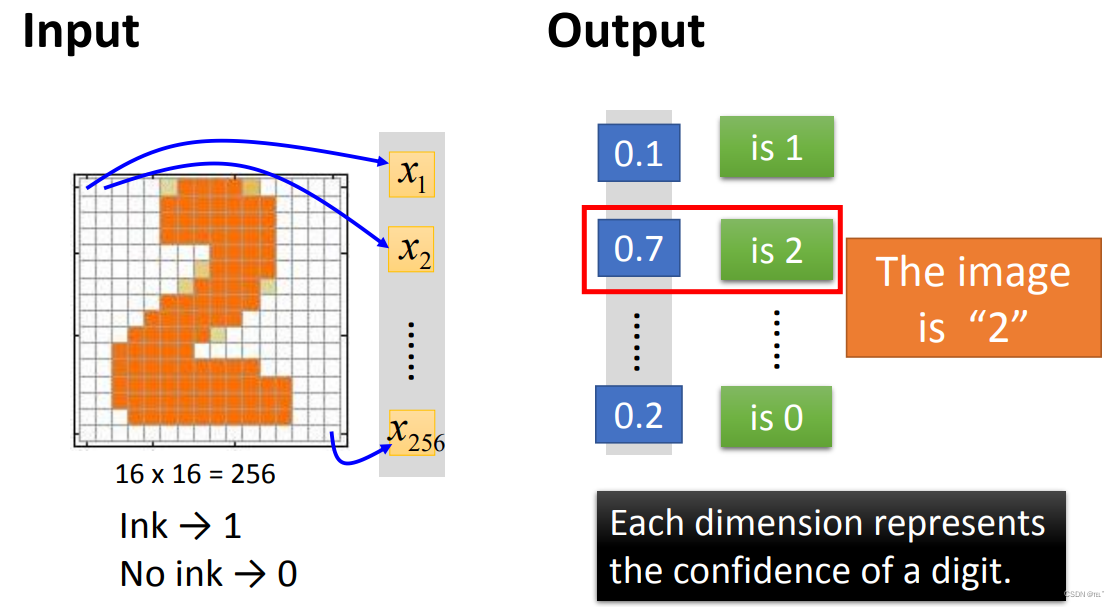
Example:
输入一张16*16的图片,一共有256个数据,每个数据代表一个x输入,有颜色的部分是1,没颜色的部分是0。输出的是对应每一个数字的概率为多少。
Step2:goodness of function
假设输入一张图片,输出的是y,计算y与target y的cross entropy(交叉熵),得出的值Loss即可评估当前参数的好坏。

Step3:pick the best function
Gradient Descent:随机给个初始值,计算每一个参数的偏微分,计算gradient,更新参数,不断反复,直到找到一组好的参数。
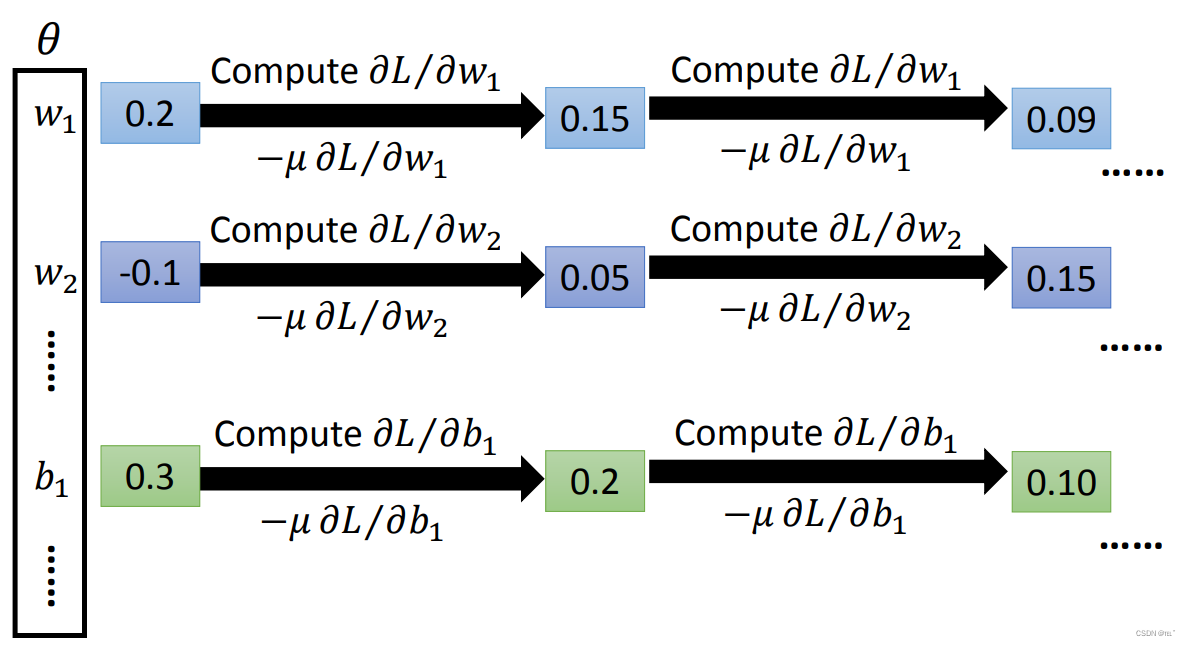
二、反向传播
用Gradient Descent方法与之前的方法类似,最大的差别就是neural network里有大量的参数。所以我们要有效地计算这些参数就要用到backpropagation。backpropagation其实就是Gradient Descent,backpropagation能够有效率的计算出Loss。

Chain Rule:即链式求导法则

Forward pass:计算函数z对w的导数
Backward pass:计算函数C对z的导数
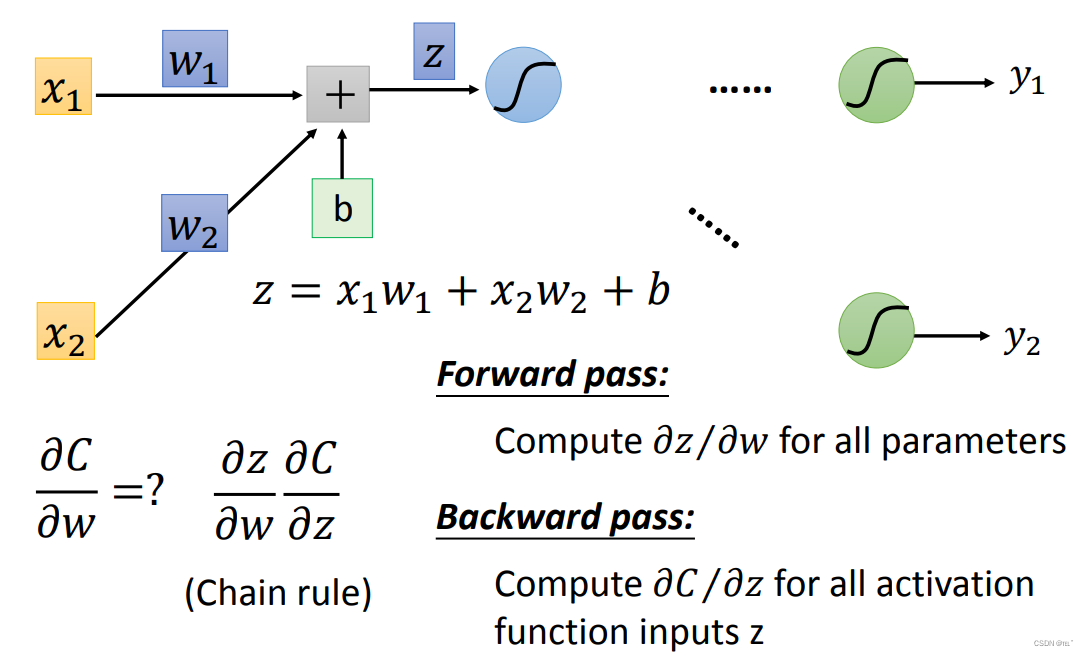
Forward pass: 输入x的值就是所求导得出来的值,经过Sigmoid函数所求出来的值就是下一个对w求导所得出来的值。
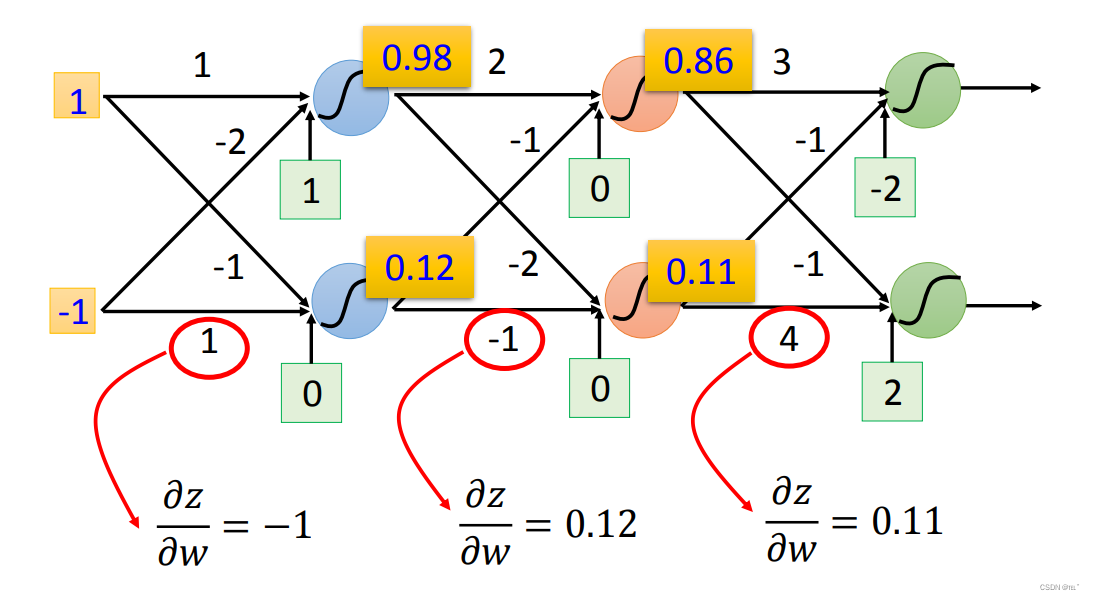
Backward pass:计算函数C对z的导数可以用链式法则,先求a对z的导数,再求C对a的导数。

a对z的导数即为图中的蓝色函数,即对Sigmoid函数求导。

C对a的导数可以用链式法则分解成z1对a的导数,C对z1的导数;加上z2对a的导数,C对z2的导数。(假设现在只有两个neural)分解成一个代表一个neural。z1对a的导数就是w3;z2对a的导数就是w4。

假设y现在就是output layer,计算C对z1的导数就是y1对z1的导数乘以C对y1的导数;计算C对z2的导数就是y2对z2的导数乘以C对y2的导数。

假设不在output layer,如果求得C对za的导数;C对zb的导数,就可以求得C对z1的导数,以此类推,直到知道了output layer的值就可以求得C对z1的导数。(总之就是要找到output layer,所以先算靠近output layer的neural的偏微分,更加有效率)
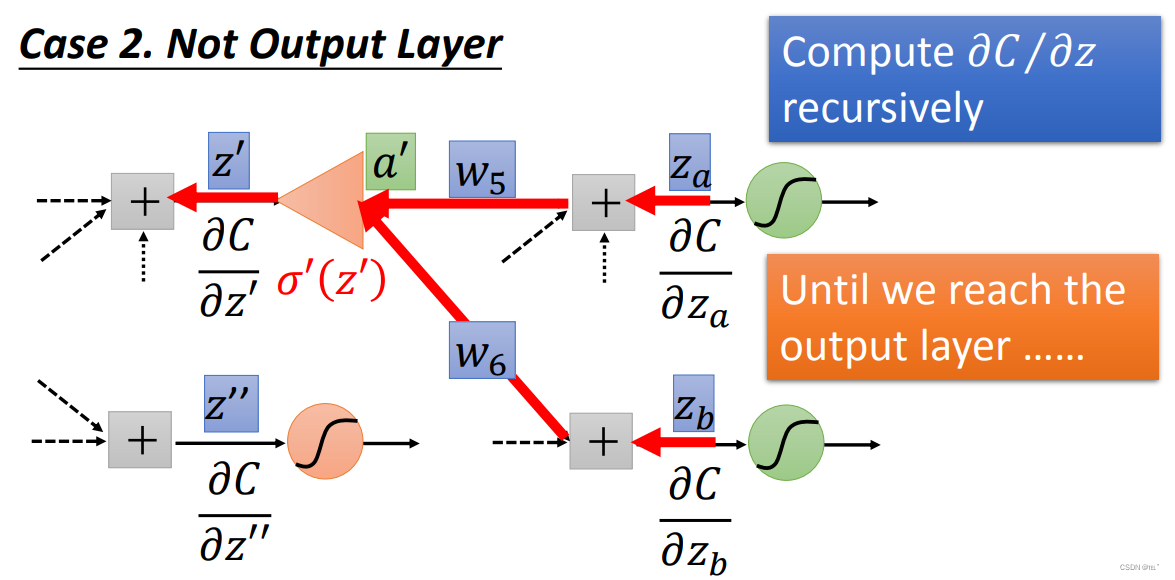
C对z1的导数、C对z2的导数求得,就可以求得C对z的导数,得到如下图所示。

三、预测神奇宝贝Pokemon
Step1:Model
找一个函数来预测,输入的是Pokemon,输出的是Pokemon的CP值(战斗力值)。假设 y = b + w*X(cp),X(cp)代表进化前的Pokemon的CP值,y代表进化后的Pokemon的CP值,w、b为参数。

可以将无穷无尽组的w、b组合来代入预测函数,但是显然 f3函数是不正确的,因为输出值为负的,以我们要选择合理的函数。
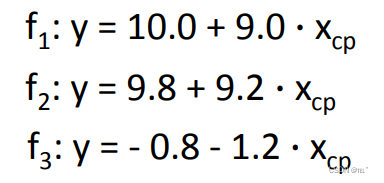
考虑到Pokemon的进化前的CP值、HP值(血量)、重量、身高等参数,可以得到如图所示的线性函数。
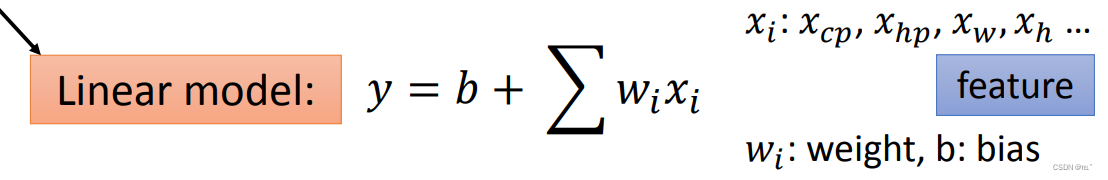
Step2:Goodness of Function
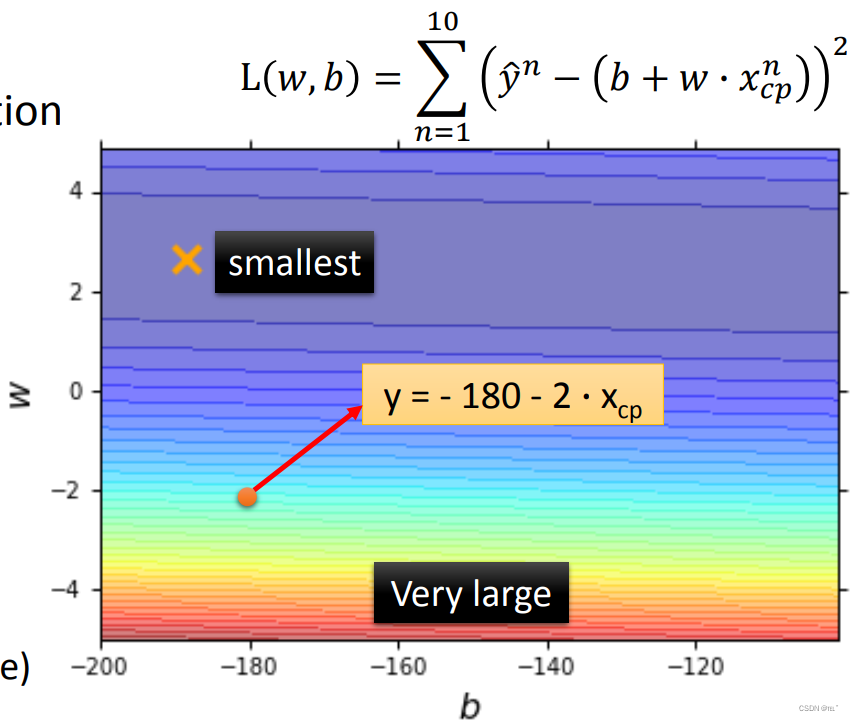
定义一个Loss Function,输入的是上面步骤一所定义的函数,输出的是这个函数的好坏(来衡量w、b的好坏)。如下图所示,将参数代入函数所得出的值,与真正的值相减求差的平方,所得到的值即为评估这个函数好坏的值。

图上的每一个点都代表着一个Function,横轴代表b,纵轴代表w,颜色越偏红,代表数值越大,则这个函数越差;反之颜色越偏蓝,代表数值越小,则这个函数越好;
Step3:Best Function
下面就是挑选一个做好的函数,找出一组w、b代入函数,使Loss最小。
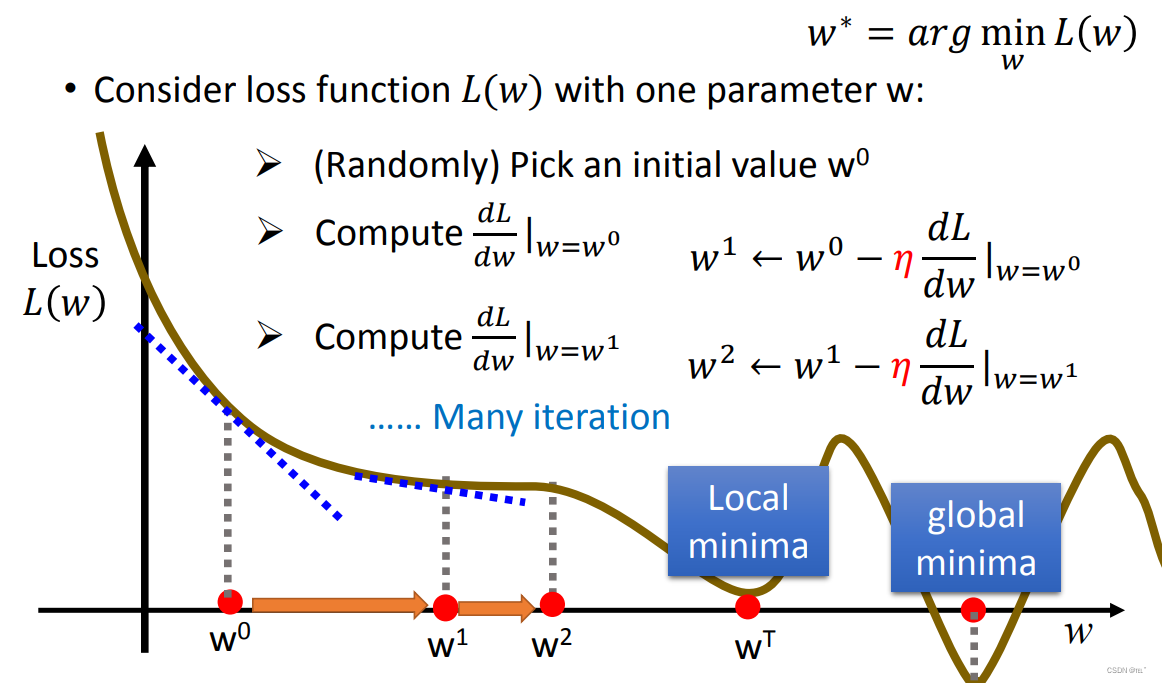
Gradient Descent:假设未知参数只有w
- 随机选取一个w0
- 计算w=w0时的微分(求偏导得出函数斜率)如果斜率为正,则增加w值,反之斜率为负,减少w值,增加或减少w值取决于斜率的大小。
- 反复进行以上两个步骤。
有两个参数也是类似以上的步骤。

根据求导法则,L对w求偏导;L对b求偏导,如下图所示。
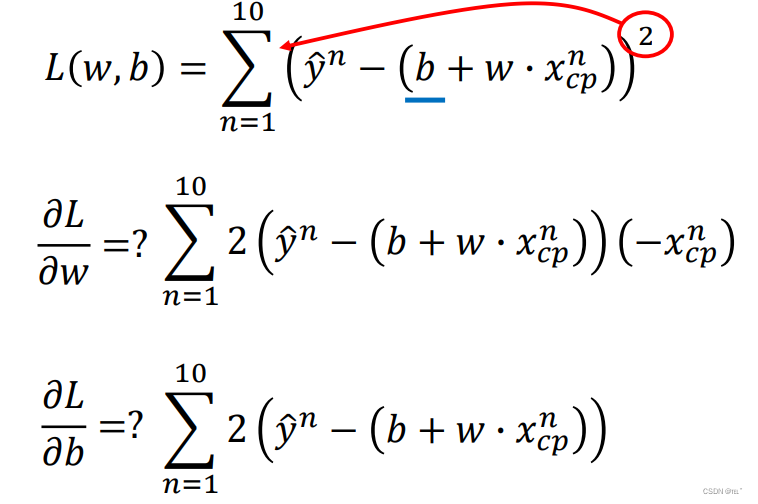
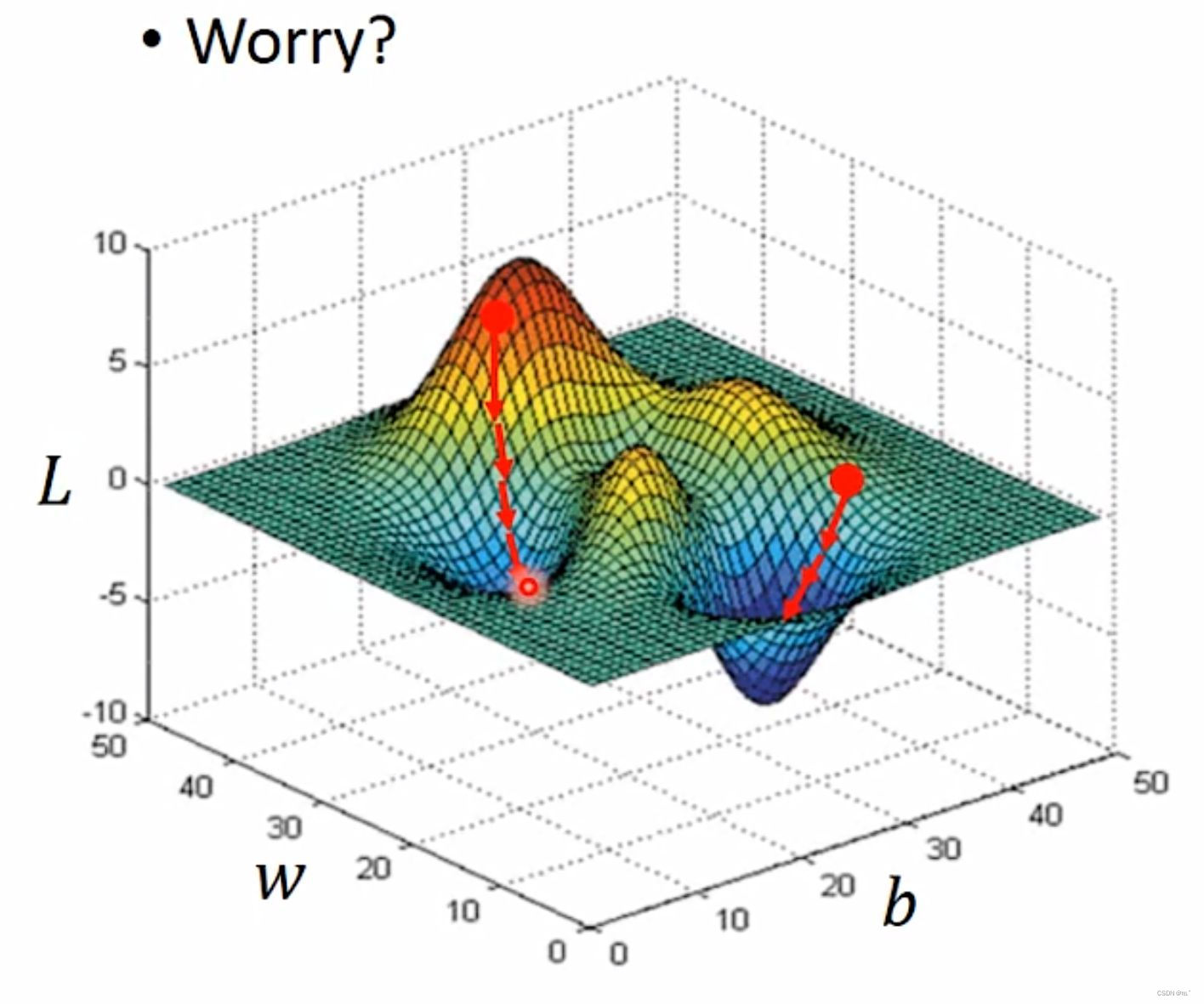
Gradient Descent也有不足之处,如果Loss Function如图所示,假设在随机取值的值在红色位置,那按照偏微分所求得的方向,会在第一个蓝色位置取得最佳的w、b的组合,显然这并不是最佳位置;假设在第二个红色位置随机取值,那按照偏微分所求得的方向,会取得最佳的w、b的组合。 但是在linear regression里则不用担心这个问题,因为loss function没有由上一周所学得的local minima的问题。
How is the results?
经过训练,得到 b = -188.4; w = 2.7为最佳的值,误差为31.9,得到的结果如图所示。

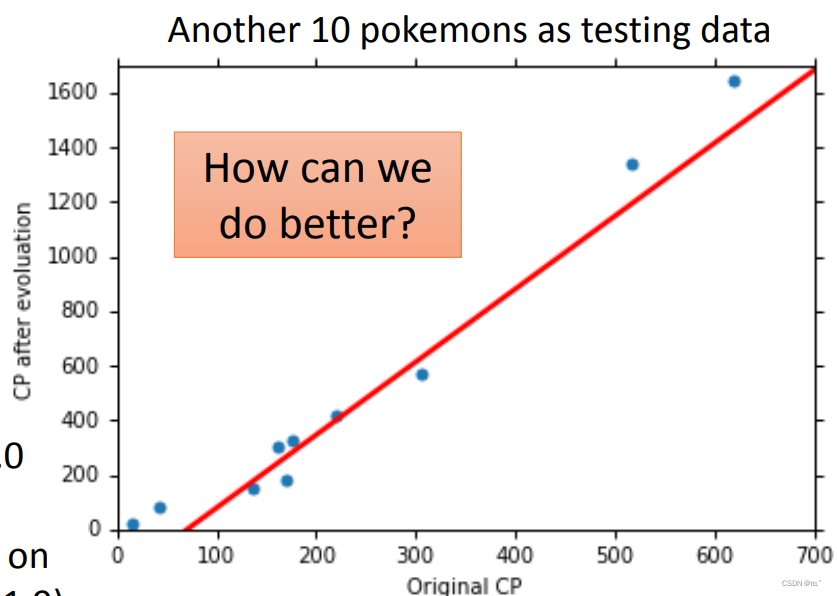
新测试了十只Pokemon,由图可知,可以大致预测到进化后的Pokemon的CP值,误差为35.0,对比之前31.9大了一点。在原来CP值特别大、特别小的地方预测误差较大。所以我们需要一个更加复杂的Model来预测的更加精准,误差更小。
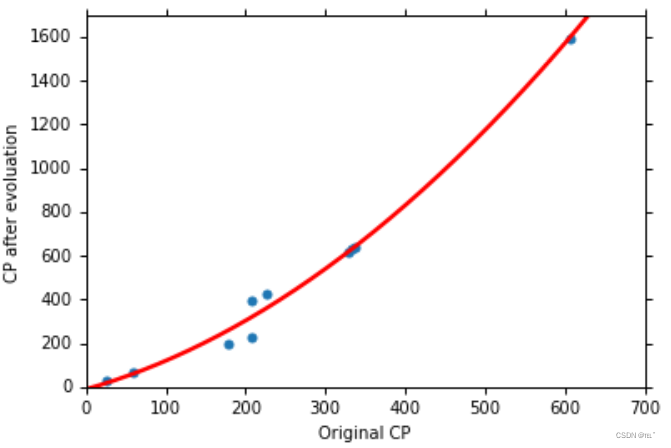
引入二次式,再用三个步骤来求得 b = -10.3 ;w1 = 1.0; w2 = 0.0027。

所得结果如图,平均误差为15.4,预测更加的准确。
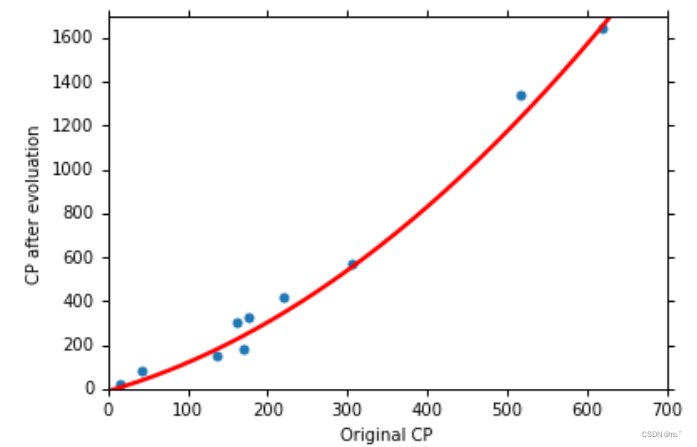
用同样的函数来预测新的十只Pokemon,平均误差为18.4,预测更加的准确。
引入三次式,再用三个步骤来求得 b = 6.4 ;w1 = 0.66; w2 = 0.0043; w3 = -0.0000018。
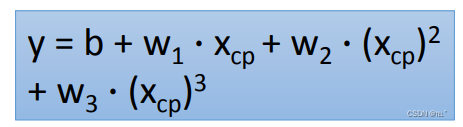
所得结果如图,平均误差为15.3,预测的比二次式的稍微好了一点,二次式的平均误差为15.4。
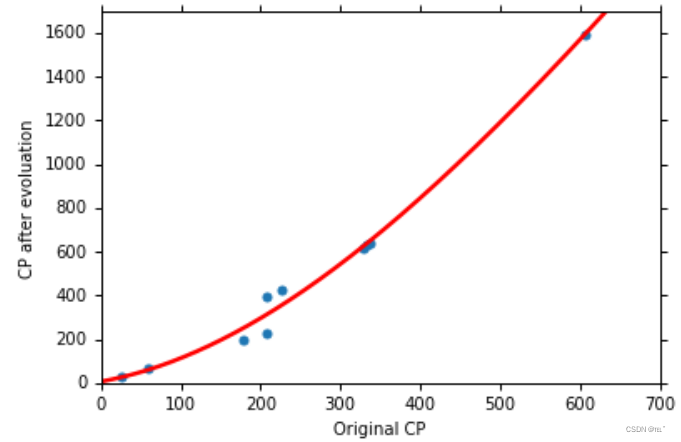
用同样的函数来预测新的十只Pokemon,平均误差为18.1,预测的同样比二次式的稍微好了一点,二次式的平均误差为18.4。

如果用更加复杂的函数来预测,在已经知道Pokemon的CP值情况下进行训练(在训练时),那么误差会越来越准确,但是,在预测不知道Pokemon的CP值得情况下(在测试时),有可能会出现过拟合的问题。所以函数不是越复杂越好,而是要选择一个合适的。
如果只考虑到进化前的CP值的话,那么在Pokemon较多的情况下会出现更大的误差,所以,我们还要把Pokemon的品种考虑进去。
Back to step 1:Redesign the model
如果Pokemon的品种是Pidgey,对应的函数是 y = b1 + w1*x;
如果Pokemon的品种是Weedle,对应的函数是 y = b2 + w2*x;
如果Pokemon的品种是Caterpie,对应的函数是 y = b3 + w3*x;
如果Pokemon的品种是Eevee,对应的函数是 y = b4 + w4*x。(不同的品种代不同的函数)

可以改写成一个linear function,假如输入的是Pidgey,函数输出的就是1,否则输出的就是0。

考虑到了Pokemon的品种,在Training Data上得到了更低的误差,平均误差为3.8,在Testing Data上也有明显的效果,误差更低,平均误差为14.3。(不考虑Pokemon品种的情况下,Training Data的误差为15.4;Testing Data的误差为18.4)

如果再把Pokemon的Weight(身高)、Height(体重)、HP(血量)考虑进去的话,得到的结果误差会不会更低呢?全部考虑进去得到一个新的函数如下图所示。
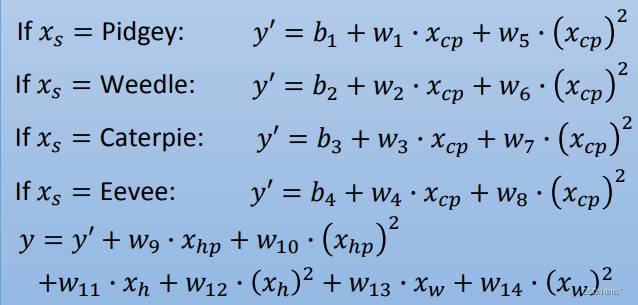
在Training Data上得到了更低的误差,平均误差为1.9,在Testing Data上平均误差为102.3,出现了过拟合的情况。
Back to step 2:Regularization
重新定义Loss Function,原来的Loss Function只考虑了预测的结果与正确的差的平方,现在,加上额外的w的平方的和,再乘以一个参数。前面的平方和越小代表函数误差越小,这个model就越好,加上后面的代表我们找到的w越接近0就越好,函数就越平滑。(测试时有一些干扰项输入,如果函数比较平滑,则对函数的输出影响较小)
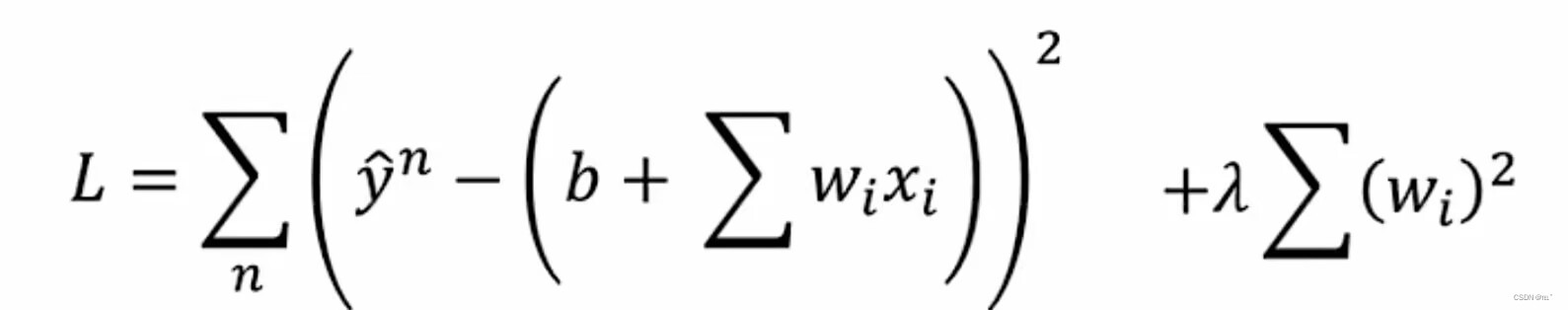
当λ值越大,则代表后面一项的影响越大,函数就越平滑,Training Data上的误差值越来越大,这是因为λ值越大,越倾向考虑w的值,而导致平均误差增大。但是,在Testing Data上,在增大λ值时,平均误差会越来越小;但是当λ值超过一定数值时,反而平均误差会增大。所以函数不是越平滑越好,我们要找一个合适的λ值。(这就需要我们调整λ的值)

总结:
我学习了深度学习的基本概念,并了解了其中的关键步骤:定义模型、评估函数好坏、找到最佳模型。我学习了反向传播的方法,以及如何使用梯度下降法来求解模型最佳参数。通过预测神奇宝贝的战斗力,我了解了如何优化参数来使得模型预测更加准确,并学习了过拟合和正则化的概念。最后,我发现在设计模型时考虑不同的特征可以提高模型的预测准确度。这是一个有趣而又充满挑战的领域,我会持续学习深度学习的相关技术和应用。















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









