






目录
1.Function with Unknown Parameters
How to make P(D(train) is bad)smaller?
摘要
本文介绍了机器学习中神奇宝贝和数码宝贝分类器的原理。通过对输入的神奇宝贝或数码宝贝图片进行边缘检测,计算线条的复杂程度,并根据线条的简单或复杂程度来判断动物是神奇宝贝还是数码宝贝。首先确定一个未知参数h,表示线条复杂程度的限值。然后定义损失函数L,通过计算模型在数据集上的错误率来评估模型的性能。接下来进行优化,选择合适的h使得模型在训练数据集上的损失最小化,希望该h能够在整个数据集上的损失与真实的h的损失接近。最后,介绍了如何通过增加训练数据量和减少模型复杂度来降低训练数据是坏的概率,并控制损失函数在一个小的范围内。
ABSTRACT
This article introduces the principle of the Pokémon and Digimon classifier in machine learning. It involves performing edge detection on the input Pokémon or Digimon images to calculate the complexity of the lines, and then using this complexity to determine whether the animal is a Pokémon or Digimon. The first step is to determine an unknown parameter, h, which represents the threshold for line complexity. Then, a loss function, L, is defined to evaluate the model's performance by calculating the error rate on the dataset. Optimization is then performed to select the optimal h that minimizes the loss on the training dataset, with the aim of making the loss on the entire dataset close to the true h. Finally, the article discusses how to reduce the probability of selecting bad training data by increasing the amount of training data and reducing the complexity of the model, and how to control the loss function within a small range.
机器学习的原理(神奇宝贝和数码宝贝分类器)
找一个函数,输入是一只神奇宝贝或者数码宝贝,输出是判断出这只动物是神奇宝贝还是数码宝贝。
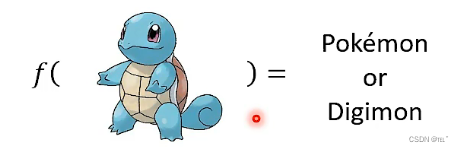
由观察可以得到神奇宝贝的图片的线条比较简单,数码宝贝的线条比较复杂。找出一个函数,输入一张图片,输出这张图片的Edge detection后的数字,这个数字代表了线条的复杂程度。因此可以根据一只动物的线条的简单复杂程度来判断它是神奇宝贝还是数码宝贝。
1.Function with Unknown Parameters
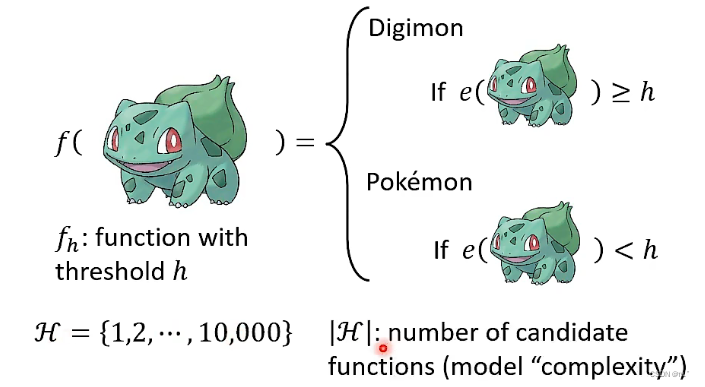
一个函数,输入是一只动物,将输入的这只动物做Edge detection来计算线条的复杂程度。如果复杂程度超过某一个限值h,则这只动物是数码宝贝;反之小于某一个限值h,则这只动物是神奇宝贝,这个限值h就是未知的参数。H{1-10000}是未知参数h的所有可能性,|H|是在H 里面有多少种可能的选择,这个选择的数目又叫做模型的复杂程度。
2.Loss of a function
根据资料定义loss函数,假设有数据集D,D里有X、Y,X代表神奇宝贝或数码宝贝,Y代表X是神奇宝贝还是数码宝贝。给定h和数据集可以计算出loss,将N个资料代入,求得loss值,将所有loss值相加取平均值,就可以定义出loss函数L。l函数,h为这个函数的参数,输入X,输出Y,如果输出的答案和正解不一样,则loss为1,如果输出的答案和正确答案一样,则输出为0。把l函数算出来的取平均值,就得到了错误率。
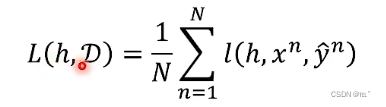
3.Optimization
假设可以收集到全部的神奇宝贝和数码宝贝D(all),就可以找到一个最好的限值h(all)。事实上无法收集到全部的神奇宝贝和数码宝贝,只能知道部分的D(train),从D(all)中选择出来的,选择的过程是独立同分布的。在D(train)中可以找到一个h(train),使D(train)的loss值最小。我们希望h(train)用在D(all)上的loss值与h(all)用在D(all)上的loss值接近。
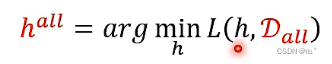
![]()
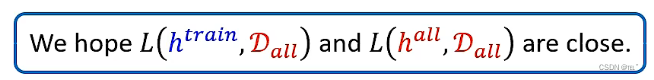
Example:
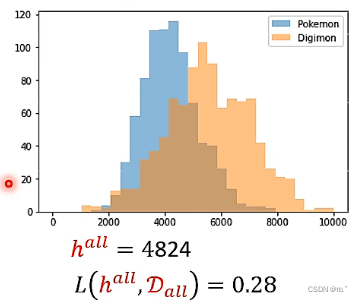
假设有819只神奇宝贝,971只数码宝贝,与D(all)接近。可以得到复杂程度的分布,蓝色是神奇宝贝的分布,橙色的数码宝贝的分布,中间是重叠的部分,横轴代表线条的复杂程度,纵轴代表这种线条复杂程度的神奇宝贝或者数码宝贝的数量。可以计算出h(all)=4824,错误率为0.28。
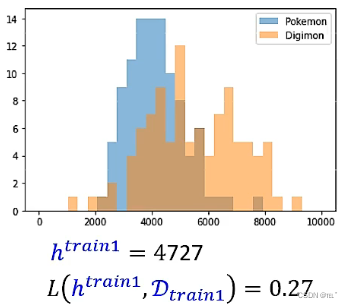
现在只选择200只动物作为D(train),D(train)的分布与D(all)的分布类似。找出来的h(train)=4727,错误率为0.27。
最好的结果是h(train)在D(all)的loss值减去h(all)在D(all)的loss值小于等于一个很小的数值σ。D(train)满足下面这个式子,所有的h在在D(train)的loss值减去D(all)的loss值小于等于1/2σ(意味着D(train)与D(all)很像),所以找到一组好的train data,不管代入h是多少,在D(train)的loss值跟所有数据上的loss值的差距小于等于某一个很小的值,就能满足上面这种最好的结果。
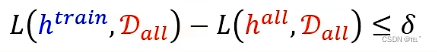
![]()
用数学公式推导以上公式:

Probability of Failure
没有找到一组好的train data的概率多少呢?
如图,蓝色的点代表好的训练资料,橙色的点代表坏的训练资料,每一个点是一组训练资料。把橙色点的概率算出来,就可以知道选择到坏的训练资料的概率。坏的训练资料就是至少有一个h,在D(train)的loss值跟所有数据上的loss值的差距大于某一个很小的值。如图,h(1)、h(2)、h(3)让圈中的训练资料变坏。

![]()
计算给定一个h会导致坏的训练资料的概率:

训练资料出现差的概率小于所有因为这个h所导致变坏的训练资料概率相加,不考虑重复的情况下,得到训练资料出现差的概率小于等于 :
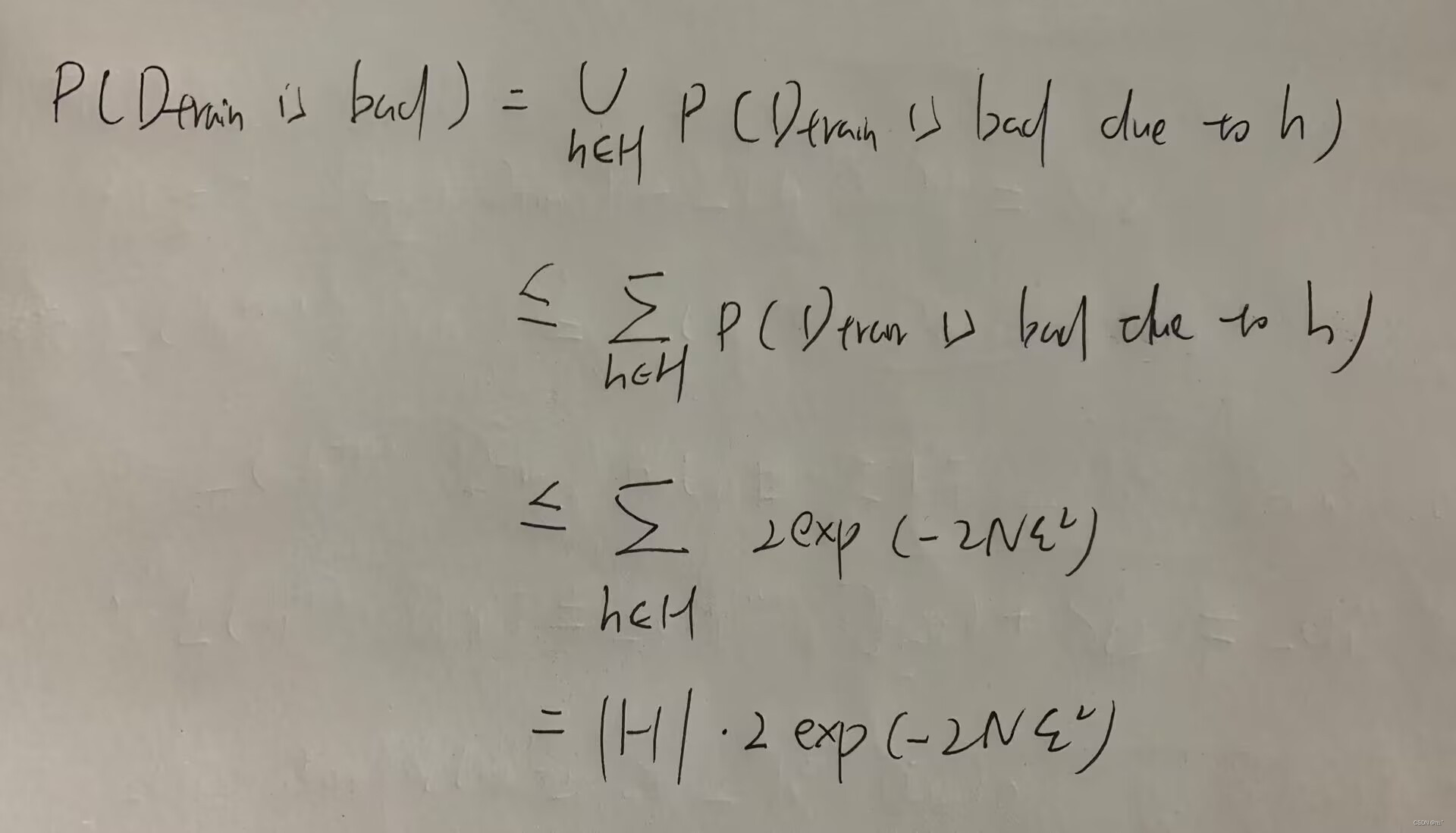
How to make P(D(train) is bad)smaller?
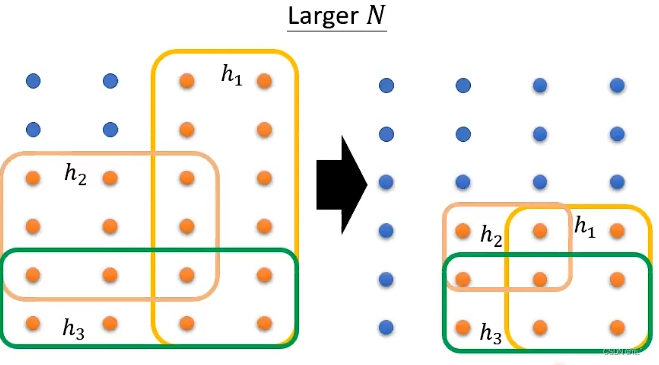
1.训练资料的数目越多,选择到坏的资料的概率就越低。缺点:通常N无法自己决定。
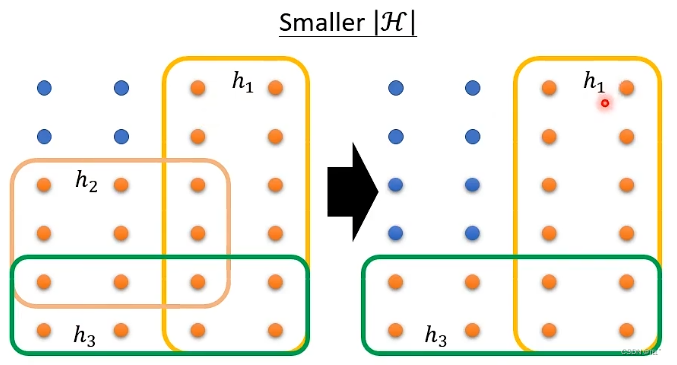
2.让|H|越小,即让可以选择的h的数目变少,选择到坏的资料的概率就越低。缺点:当|H|很小时,h就非常有限,就无法找到h(all)在D(all)上的loss值最小(理想值崩坏)。解决这两个缺点的办法:深度学习。
如何把训练资料是坏的概率控制在σ,需要多的资料N呢?
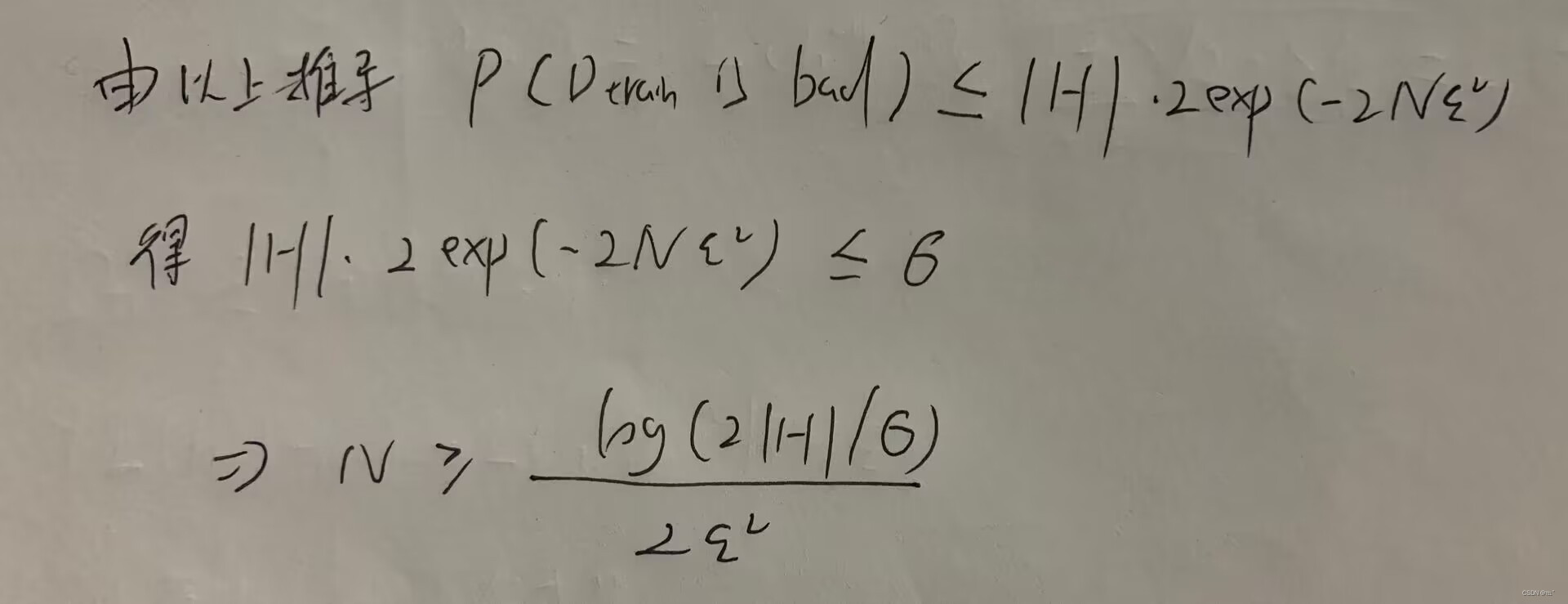
总结
本文介绍了使用机器学习进行神奇宝贝和数码宝贝分类的原理。通过找到一个函数,将输入的动物图片进行边缘检测,计算线条的复杂程度,并根据线条的简单或复杂程度来判断动物是神奇宝贝还是数码宝贝。在分类过程中,使用未知参数h来表示线条复杂程度的限值。通过定义损失函数,计算模型在数据集上的错误率,进行优化来选择合适的h使得模型的损失最小化。最终目标是找到一个h使得模型在整个数据集上的损失与真实h的损失接近。同时,介绍了如何通过增加训练数据量和减少模型复杂度来降低训练数据是坏的概率,并控制损失函数在一个小范围内。深度学习是一种解决模型复杂度问题的方法。通过以上原理和方法,可以实现神奇宝贝和数码宝贝的分类器。

















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









