








代码:
https://github.com/RiDang/DANN![]() https://github.com/RiDang/DANN结构:
https://github.com/RiDang/DANN结构:



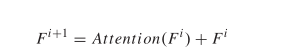
![]()
思考总结:
1)自注意力可获取视图之间的相关性,公式下面除以一个dk是为了防止注意力分数过大
2)将当前层的输入添加到输出特征向量中,作为下一个自关注层的输入,充分利用上一层挖掘出的多个视图之间的低层相关性信息。
3)最大池化后得到的特征向量包含多个视图的信息,有效信息都集中在一个视图上,信息丰富。
代码:
https://github.com/RiDang/DANN![]() https://github.com/RiDang/DANN结构:
https://github.com/RiDang/DANN结构:
![]()
思考总结:
1)自注意力可获取视图之间的相关性,公式下面除以一个dk是为了防止注意力分数过大
2)将当前层的输入添加到输出特征向量中,作为下一个自关注层的输入,充分利用上一层挖掘出的多个视图之间的低层相关性信息。
3)最大池化后得到的特征向量包含多个视图的信息,有效信息都集中在一个视图上,信息丰富。
 3243
3243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




























