







 英伟达提出LMFilter,一种无监督数据筛选方法,用于改善NoisyStudentTraining在非目标领域ASR任务中的性能。LMFilter利用模型之间的差异筛选数据,无需额外模型或标签。在AISHELL-1和AISHELL-2上,LMFilter显示了显著的性能提升,且代码已在WeNet开源。
英伟达提出LMFilter,一种无监督数据筛选方法,用于改善NoisyStudentTraining在非目标领域ASR任务中的性能。LMFilter利用模型之间的差异筛选数据,无需额外模型或标签。在AISHELL-1和AISHELL-2上,LMFilter显示了显著的性能提升,且代码已在WeNet开源。
为了改进 Noisy Student Training 在非目标领域 ASR 上的性能,英伟达提出新型数据筛选方法 LM Filter。其利用不同解码方式的识别文本之间的差异来作为数据筛选条件,是一个完全无监督的筛选过程。在 AIShell-1 上与无数据筛选的基线相比可以有 10.4% 的性能提升;在 AIShell-2 上可以取得 4.72% 字错误率。
目前该工作已投稿 ICASSP 2023,论文预览版可见:https://arxiv.org/pdf/2211.04717.pdf

代码已开源在 WeNet 社区,详见:
https://github.com/wenet-e2e/wenet/tree/main/examples/aishell/NST
Noisy Student Training 简介
半监督学习一直在语音识别领域受到广泛关注。这两年,Noisy Student Training (NST) 刷新并保持了 Librispeech 上 SOTA 结果[1],并且在数据量相对充沛的情况下,增加无监督数据仍然可以提升性能,因此有大批学术界和工业界的从业者在关注和改进该方法。
NST 可以看作是 Teacher Student Learning 的改进版本,它是一个自我迭代的过程。首先,我们使用有监督数据训练好一个 teacher 模型,使用这个模型在无监督数据上做 inference 得到伪标签。接着将带伪标签的无监督数据和有监督数据混合到一起,来训练 student 模型,在训练的时候通常会加入一些噪声来使得模型更加鲁棒,例如语音上常用的 SpecAug。我们让 student 成为新的 teacher,以此类推。这个过程如下图所示。
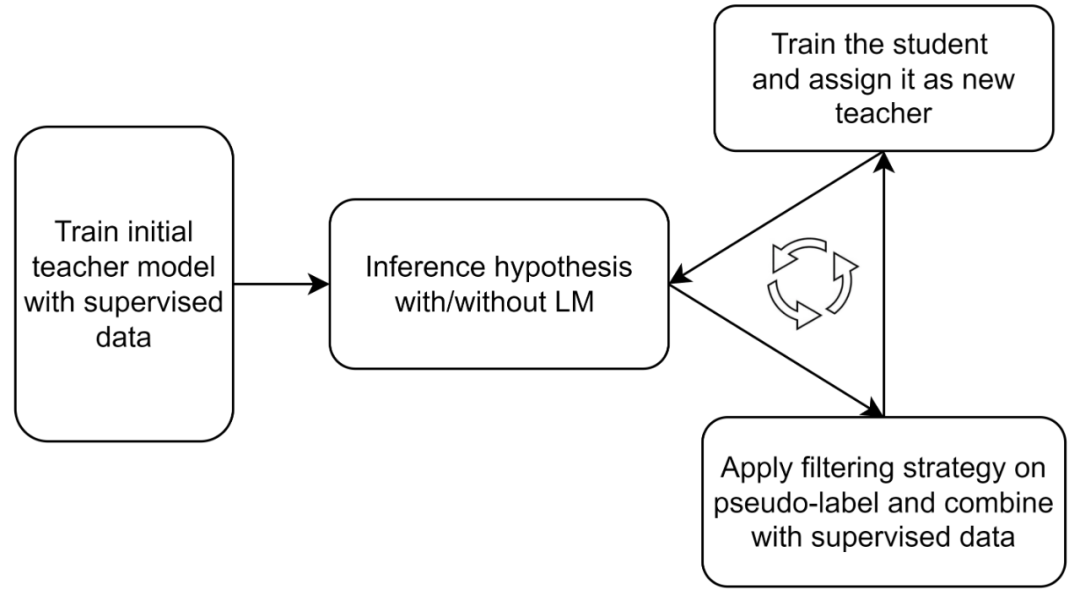
Motivation
NST 并没有在中文 ASR 任务中得到广泛研究,尤其是在有监督数据的领域与无监督数据的领域不匹配的情况下。
噪声和领域在 ASR 中起着重要的作用,来自社交媒体的大量无监督数据并不总能匹配任务所需的领域。因此,我们需要适当的数据筛选策略(Data Selection Strategy)来去除噪声并选择接近目标领域的数据。
常见的数据筛选策略
ASR 中最常见的数据筛选方式是置信度分数(Confidence Score),它根据置信度来选择合适的阈值来选择出可信的文本。但是,在具有大量领域不匹配的无标签数据的情况下,这种方法不一定可行。
近期有另一种新颖的无监督数据筛选的方式被提出[2],作者使用额外的对比语言模型(Contrastive Language Model)用作数据筛选,从而更好地改进目标域 ASR 任务。
在本文中,我们提出了一种新型的数据筛选策略,称之为 LM Filter,它可以利用模型差异性来筛选出更有价值的非目标领域的数据,来提高 NST 的性能。这种方法有以下的好处:
-
不需要额外的数据筛选模型。模型的差异可以从不同的解码策略(例如加不加语言模型)中获得。
-
不需要标签来进行数据筛选,是一个完全无监督的筛选过程。
-
训练 NST 所用的时间和资源更少,并且它可以在更少的迭代中更快地收敛。
LM Filter
一个发现
在一开始,我们在中文数据集上做了标准的 NST 迭代,我们将 AISHELL-1 作为有监督数据,AISHELL-2 作为无监督数据,没有使用任何筛选策略。我们计算生成的伪标签的 CER 为8.38%,这个结果是相当好的。
但是,当我们把无监督数据替换成具有不同领域和噪声更大的 WenetSpeech 数据集时,伪标签的 CER 急剧增加到 47.1%,这样的数据不足以用作训练及迭代。因此我们提出 LM filter 来提高 NST 在非目标域数据上的性能。
有用的定义
我们的假设是,如果语言模型认为这个句子不需要任何进一步的修改,那么这个句子就有更高的概率是一个正确的伪标签。在这里,我们介绍两个定义和示例,以更好地理解 LM Filter 的工作原理,我们定义:
-
CER-Hypo为 student 模型的 greedy search 解码得到的 Hypothesis 与带语言模型解码的 Hypothesis 之间的 CER。 -
CER-Label为 student 模型 Hypothesis 和真实标注之间的 CER。
举个例子
下图列出了两种情况。在 Case 1 中,greedy decoding 和带语言模型解码的 Hypothesis 的差异是1个字符(“数”和“诉”),所以CER-Hypo=16.67%。在这种情况下,CER-Label也是16.67%(“申”和“胜”)。
在 Case 2 中,这个句子比上个例子中的句子更具挑战性。Student 模型仅学习了部分声学特征,但解码结果大部分是错误的。在这种情况下,LM 倾向于进行更多修改。故而,CER-Hypo 和 CER-Label 两者在这种情况下都非常高。
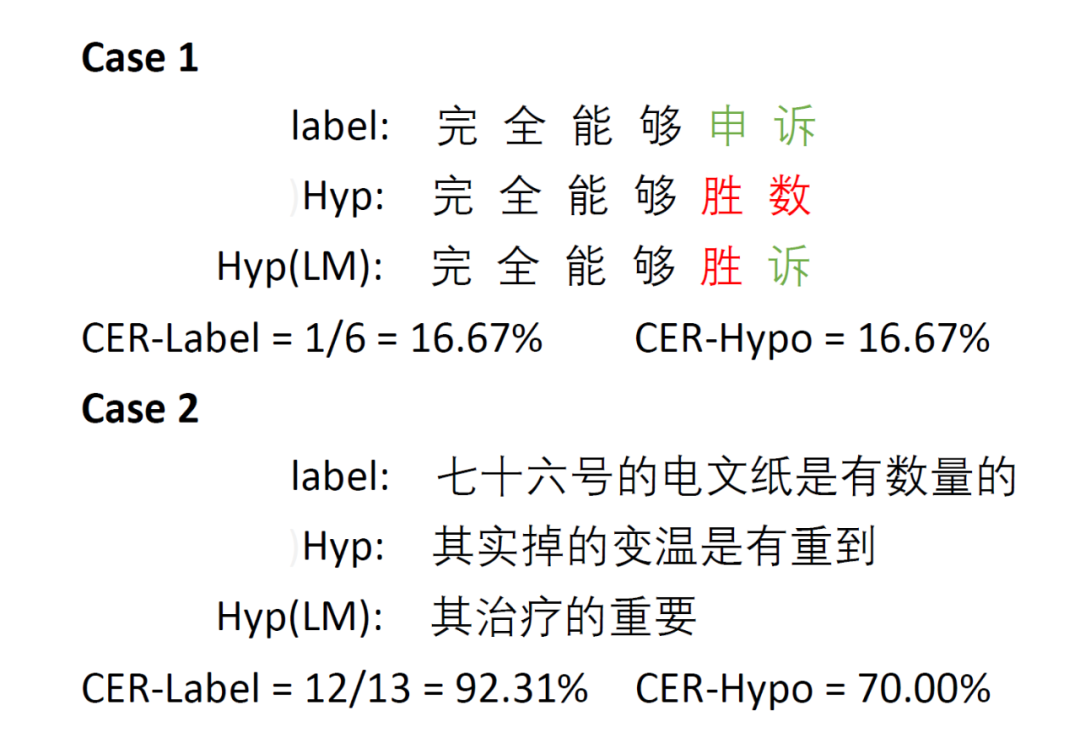
CER-Hypo 和 CER-Label 的相关性
大量的 case 表明 CER-Hypo 和 CER-Label 具有很强的正相关性,具有较低 CER-Hypo 的句子往往具有较低的 CER-Label。我们的 LM Filter 使用 CER-Hypo 作为阈值(例如10%)来过滤掉高 CER-Label 的数据。
我们还观察到,相似领域的无监督数据,更有可能得出更低的 CER-Hypo 值。例如,在 WeNetSpeech 的无监督数据中,领域为广播和新闻的数据往往具有较低的 CER-Hypo,然而电视剧和综艺等非目标域更有可能被 LM Filter 过滤掉。
实验结果和分析
我们使用 AISHELL-1 作为有监督数据,AIShell-2 和 WeNetSpeech 分别作为无监督数据进行实验。模型结构为16层的 Conformer。实验使用 WeNet 工具,并且代码已经贡献到 WeNet 社区。如何在 WeNet 里面使用 LM Filter 做 NST 也会在下一小节做介绍。
Baselines
我们有使用不同的数据以下几组基线实验:
-
有监督训练:
-
AISHELL-1
-
AISHELL-1 加上有标注的 WeNetSpeech
-
AISHELL-1 加上有标注的 AISHELL-2
-
-
标准 NST:
-
AISHELL-1(有监督数据)和 WeNetSpeech(无监督数据)
-
AISHELL-1(有监督数据)和 AISHELL-2(无监督数据)
-
分别在 AISHELL-1 的测试集上计算 CER,详细的结果见下表:
| Supervised | Unsupervised | Test CER |
|---|---|---|
| AISHELL-1 Only | ---- | 4.85 |
| AISHELL-1 + WenetSpeech | ---- | 3.54 |
| AISHELL-1 + AISHELL-2 | ---- | 1.01 |
| AISHELL-1 (standard NST) | WenetSpeech | 5.52 |
| AISHELL-1 (standard NST) | AISHELL-2 | 3.99 |
从结果中可以看出,由于 AISHELL-2 与AISHELL-1 的领域和噪声环境一致,进行有监督训练时的 CER 非常低。并且在使用 AISHELL-2 作为无监督数据,进行一次标准的 NST迭代时,CER 有明显的一个下降。但是我们将无监督数据换成 WeNetSpeech 时,CER 不降反增:从 4.85% 提高到 5.52%。
LM Filter 的有效性
在有监督的 AISHELL-1 数据和无监督的 WenetSpeech 数据上,并且使用 LM Filter 的性能见下表。在经过7次 NST 迭代后可以达到4.31%的最佳 CER。与有监督的基线相比,CER 可以减少 11.13%。
| # nst iteration | AISHELL-1 test CER | Pseudo CER | Filtered CER | Filtered hours |
|---|---|---|---|---|
| 0 | 4.85 | 47.10 | 25.18 | 323 |
| 1 | 4.86 | 37.02 | 20.93 | 436 |
| 2 | 4.75 | 31.81 | 19.74 | 540 |
| 3 | 4.69 | 28.27 | 17.85 | 592 |
| 4 | 4.48 | 26.64 | 14.76 | 588 |
| 5 | 4.41 | 24.70 | 15.86 | 670 |
| 6 | 4.34 | 23.64 | 15.40 | 669 |
| 7 | 4.31 | 23.79 | 15.75 | 694 |
除了测试集的 CER 外,我们还使用以下三个指标来评估伪标签的质量:Pseudo CER,即伪标签本身的 CER;Filtered CER 和 Filtered hours,即过滤后的无监督数据的 CER 和数据时长。
在第一次 NST 迭代后,LM Filter 可以将 Pseudo CER 从 47.1% 降低到 25.18%,这使得伪标签可以满足进一步的训练。Pseudo CER 和 Filtered CER 随着迭代次数的增加而减少,而 LM Filter 也允许更多的无监督数据进入 NST 迭代。这表明 LM Filter 可以逐渐学习噪声信息,而我们的 student 模型可以更多地利用非目标域的数据。
多轮迭代
为了夯实我们数据筛选策略的有效性,我们在 AISHELL-1 + WeNetSpeech 上做了多轮标准 NST 的迭代,以及加上 LM Filter 之后的对比图。此外,也在AISHELL-1 + AISHELL-2 上做了多轮迭代。详细的结果见下图。
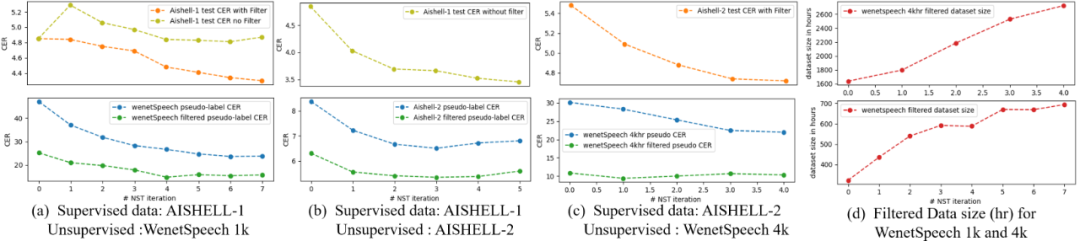
图a. 可以明显看出,不加任何数据筛选的情况下,7轮迭代后的 CER 与 baseline 相比没有明显变化;而我们的 LM Filter 可以有 10.4% 的性能提升,并且模型训练时间较短、收敛更快。Pseudo CER 逐渐下降,筛选后的数据大小在每次训练迭代后也逐渐增加(见图d.下)。
大数据上的性能
我们在 AISHELL-2 上也进行了相关实验,结论与 AISHELL-1 一致,结果见下表。
| # nst iteration | AISHELL-2 test CER | Pseudo CER | Filtered CER | Filtered hours |
|---|---|---|---|---|
| 0 | 5.48 | 30.10 | 11.73 | 1637 |
| 1 | 5.09 | 28.31 | 9.39 | 2016 |
| 2 | 4.88 | 25.38 | 9.99 | 2186 |
| 3 | 4.74 | 22.47 | 10.66 | 2528 |
| 4 | 4.73 | 22.23 | 10.43 | 2734 |
Recipe in WeNet
我们在 WeNet 中已经贡献了使用 LM Filter 来进行 NST 训练的代码:
Quick Start
如果你想要快速地复现上述实验,你可以直接运行下面的命令,该命令会训练初始的 teacher 模型,并进行两次 NST 的迭代。:
bash run.sh --stage 1 --stop-stage 2 --iter_num 2
在训练好初始模型后,我们会自动开始解码,得到无监督数据上的伪标签。接着根据伪标签的 CER_hypo 选择合适阈值进行数据筛选。将筛选好的无标签数据和有标签数据打包,生成用于训练的新的 datalist,从而进行新一轮的 NST 迭代。更加详细的参数和配置,可以参考 run.sh 或者 run_nst.sh。
LM Filter 的实现
在 WeNet 中,我们是通过 local/generate_filtered_pseudo_label.py 这个脚本来实现 LM Filter 这个功能。通过传入 --cer_hypo_threshold 这个参数来配置相应的阈值,并且选择出满足条件的半监督数据。
在选完满足条件的数据之后,我们还提供 local/generate_data_list.py 来自动生成用于下一轮 NST 训练的数据列表。在生成训练用的数据列表时,可以通过配置 --pseudo_data_ratio 来动态调整有监督数据和无监督数据的比例。
最后,欢迎大家 cite 文章、试用 recipe 和提 issue~
References
-
Y. Zhang, J. Qin, D. S. Park, W. Han, C.-C. Chiu, R. Pang, Q. V. Le, and Y. Wu, “Pushing the limits of semi-supervised learning for automatic speech recognition.,” CoRR, vol. abs/2010.10504, 2020.
-
Z. Lu., Yongqiang W., Y. Zhang, W. Han, Zhehuai Chen, and Parisa Haghani, “Unsupervised Data Selection via Discrete Speech Representation for ASR,” in Proc. Interspeech 2022, 2022, pp. 3393–3397.

















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









