






Guo, J., & Ye, J. (2019). Anchors Bring Ease: An Embarrassingly Simple Approach to Partial Multi-View Clustering. Proceedings of the AAAI Conference on Artificial Intelligence, 33, 118–125. https://doi.org/10.1609/aaai.v33i01.3301118
一.主要亮点及解决问题
根据选取不同视角内的公共实例作为锚点来解决可能某些实例在某些视角确实的问题。
二.主要方法
1.假设基础
1)出现在所有视角的公共实例可以将实例与不重叠的部分视角联系
2)不在任何视角出现的实例不能被删除因为它们仍为集群提供了必要信息
2.给予锚点的相似度构造
首先选取出现在所有视角的公共实例作为锚点,那么接下来的相似度都是表示的是实例与锚点的关系。
(1)视角内的相似度

表示距离实例
最近的m个锚点的集合。其他应该是相似度的常规求法,注意的是矩阵
高度稀疏(许多锚点与实例相同),矩阵某一行的合为1.
(2)视角间的相似度
这时候的相似度矩阵可以表示为如下形式:
![]()
第一部分表示的是在两视角都出现的,第二部分表示只在第一视角出现的,第三部分同理。然后我们再用W1和W2进行加权,这样就对视角间进行来联系。例如,若第i个实例只在第一视角间出现,那么![]() ,若在第一第二视角都出现则令其为1,在第一视角没有出现则另其为0.
,若在第一第二视角都出现则令其为1,在第一视角没有出现则另其为0.

即是上图的第1,2,3个步骤。
在之前论文(Liu, He, and Chang 2010; Liu et al. 2011)中有发现,S=![]() ,其中
,其中![]() 是一个对角矩阵,S有下列性质:
是一个对角矩阵,S有下列性质:
(1)Sij非负,这样使结果拉普拉斯矩阵半正定。
(2)Z稀疏所有S低秩且稀疏,使真实特点更准确且突出。
(3)S是一个双随机矩阵,即它有单位行和列和。因此,得到的图Laplacian矩阵为L=I−S。
(3)谱聚类
首先计算离散集群指标:
![]()
因为L=D-S,D是单位矩阵,所有目标函数又可以变为:
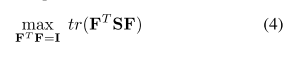
又因为![]() ,另
,另![]() ,A的奇异值分解可以表示为
,A的奇异值分解可以表示为![]() ,符号表示奇艺值矩阵,P表示左奇艺向量矩阵,Q表示右奇艺向量矩阵,那么有:
,符号表示奇艺值矩阵,P表示左奇艺向量矩阵,Q表示右奇艺向量矩阵,那么有:
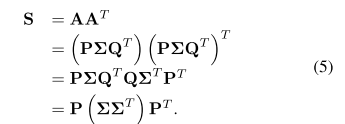
![]() 返回一个N*N对角矩阵,里面有S的所有特征值。P的列向量是S的特征向量(Wang, Nie, and Yu 2017)。为减少计算量,我们对A分解来得到想要的F。按照(Liu et al. 2011)来对l*l矩阵
返回一个N*N对角矩阵,里面有S的所有特征值。P的列向量是S的特征向量(Wang, Nie, and Yu 2017)。为减少计算量,我们对A分解来得到想要的F。按照(Liu et al. 2011)来对l*l矩阵![]() 进行特征分解,得到K个特征向量值对
进行特征分解,得到K个特征向量值对![]() ,里面1>
,里面1>>=...>=
>0。我们使
作为对角矩阵在对角线上来储存K个本征值,
![]() 作为包含K个特征向量的正交矩阵。想要得到的结果为:
作为包含K个特征向量的正交矩阵。想要得到的结果为:![]()
(4)多视角(大于2)的拓展

几乎没有区别,就是把N个视角分成对进行前面的步骤,最后再将S相加。
三.结语
这篇文章的主要亮点应该在于实例-锚相似度的构造。















 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









