






 文章提出VisualPromptTuning(VPT),它是一种针对预训练Transformer模型的轻量级微调策略。VPT在保持模型Backbone参数冻结的同时,只对少量参数(约1%)进行训练,从而在多个下游识别任务中展现出优越性能,降低存储需求,并在多种情况下胜过全模型微调。
文章提出VisualPromptTuning(VPT),它是一种针对预训练Transformer模型的轻量级微调策略。VPT在保持模型Backbone参数冻结的同时,只对少量参数(约1%)进行训练,从而在多个下游识别任务中展现出优越性能,降低存储需求,并在多种情况下胜过全模型微调。
摘要
当前将预训练模型适用于下游任务的实现方法涉及更新全部 Backbone 参数,例如 Full Fine-tuning。提出了 Visual Prompt Tuning (VPT) 作为一种快捷有效的方法来完整微调大规模 Transformer 模型。受益于高效调优 LLMs 的最新进展,VPT 在保持模型主干冻结的同时,仅引入少量 (不到模型参数的1%) 可训练参数。通过广泛的实验,在各种下游识别任务中,与其他方法相比,VPT实现了显着的性能提升,甚至在多种模型和数据规模下优于完全微调,同时降低了每个任务的存储成本。代码可从 github.com/kmnp/vpt 获得。
Intro.
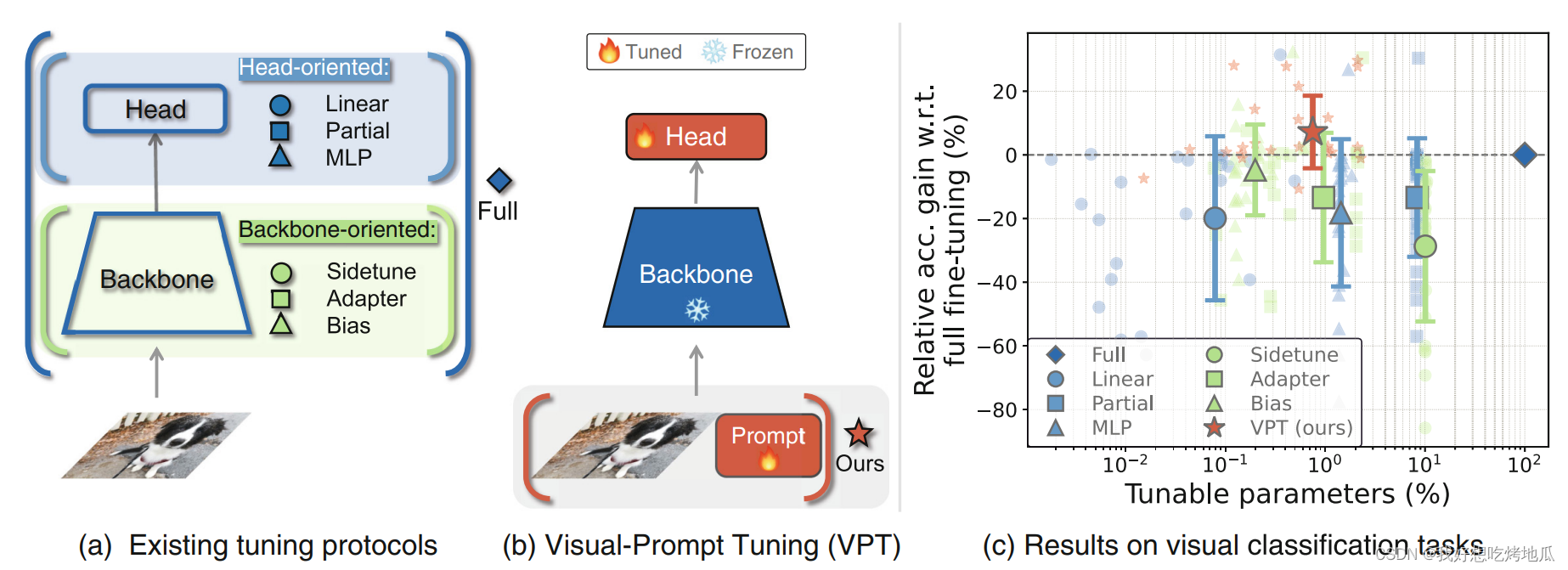
Fig.1 VPT vs. 迁移学习方法。(a) 目前的迁移学习是根据调整范围分组的:完全微调,面向 Head 和面向 Backbone 的方法。(b) VPT 在输入空间中增加了额外的参数。(c) 采用预训练的 ViT-B 主干在广泛的下游分类任务上的不同方法的表现,并附有平均值和标准差注释。在使用不到1%参数的情况下,在24个场景中有20个优于完全微调
Related Work
Transformer
Transfer Learning
Prompting
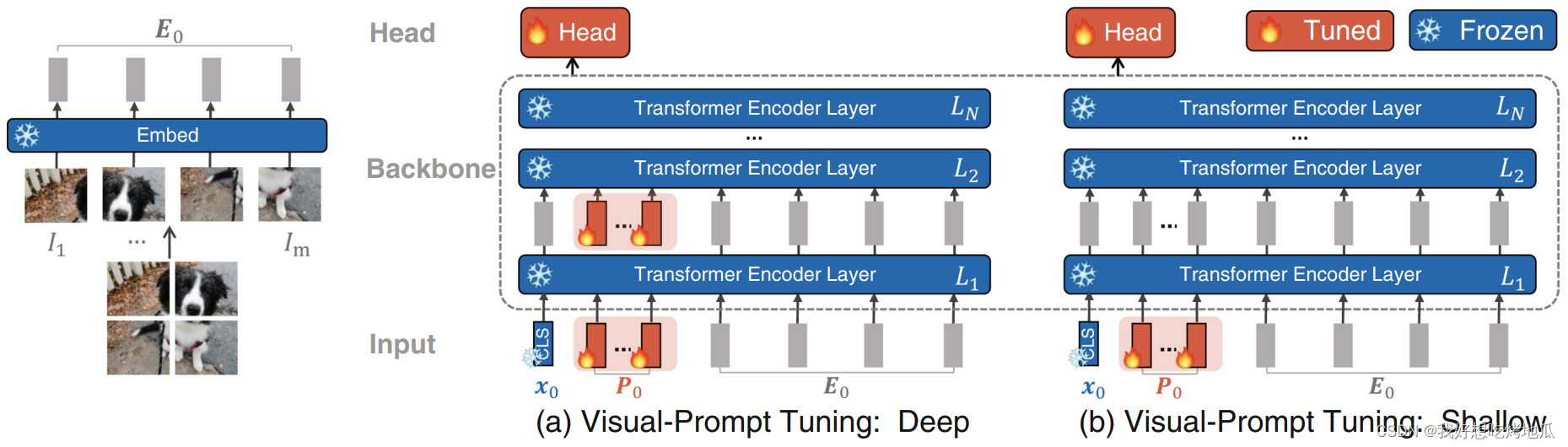
Approach


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









