







Abstract
传统的无监督域自适应(UDA)旨在最小化域之间的分布差异,但忽略了从数据中获取丰富语义的潜力,并且难以处理复杂的域偏移。利用大规模预训练的VLMs的知识可以进行更有导向性的适应。现有方法通常是分别学习文本提示以嵌入源域/目标域的语义,并在每个域内进行分类,限制了跨域知识迁移的能力。此外,仅提示语言分支缺乏动态适应两种模态的灵活性
本文提出了域无关的相互提示(Domain-Agnostic Mutual Prompting,DAMP),通过相互对齐视觉和文本嵌入来利用域不变的语义:
- 图像的上下文信息被用来以域无关和实例级(instance-conditioned)的方式提示语言分支
- 基于域无关的文本提示来发现域不变的视觉嵌入
- 两个分支的提示通过交叉注意力模块相互学习,并通过语义一致性损失和实例区分对比损失优化
Intro.
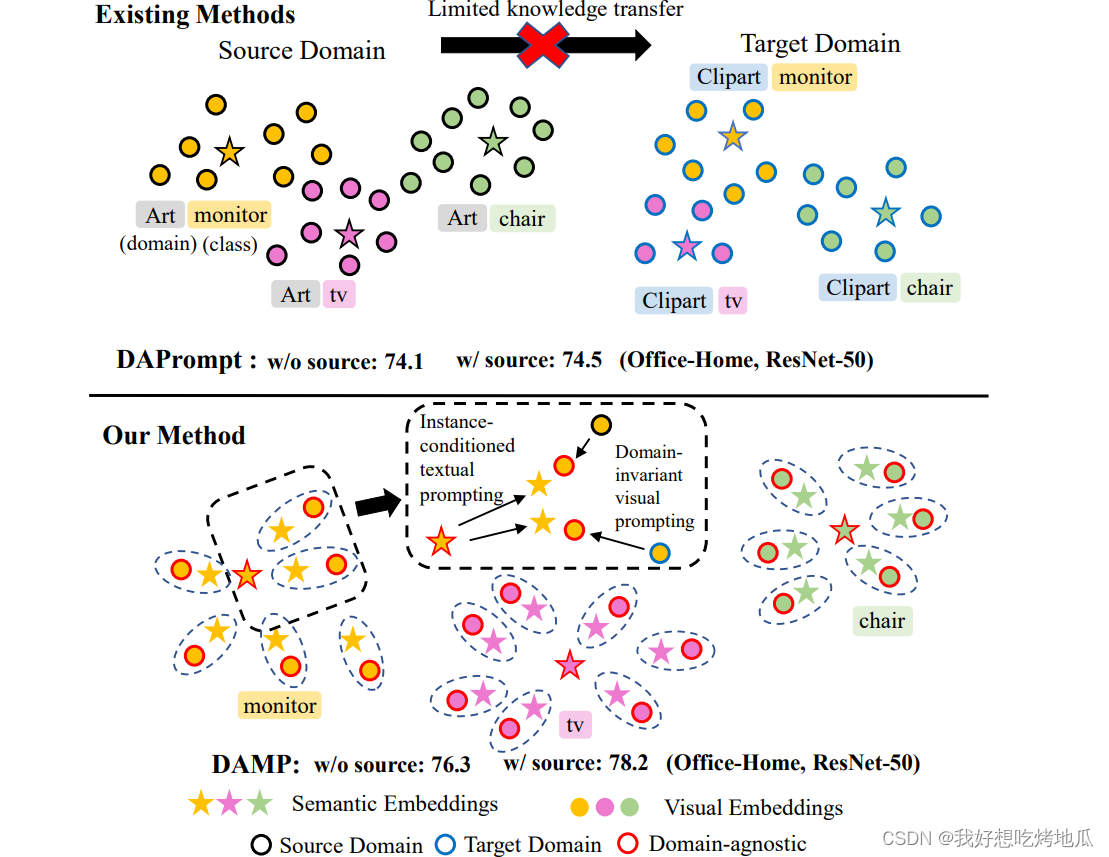
Top: 现有的基于提示的方法仅学习文本提示以在每个域中嵌入语义并分别进行分类,这限制了跨领域知识转移和特征对齐;Bottom: DAMP相互学习文本和视觉提示,使得两种模态的嵌入都具有域不变性,从而能够更好地利用源知识并实现灵活的对齐
无监督域自适应可以利用来自标记充足的源领域的知识,从而使在未标记的目标域上的任务性能提升,两个域具有相似的语义但数据分布不同。传统的UDA方法通常通过最小化分布差异来缩小域差距,利用矩匹配或对抗学习实现。然而,简单地对齐两个域可能导致学习到的特征表示中的语义结构失真和及类别辨别能力降低。此外,先前的工作通常在训练和推理中使用数值标签,丢失类别的丰富语义,导致在处理复杂类别和域偏移时的自适应能力较差
利用VLMs进行UDA有以下两个问题:
- 如何有效地利用VLMs中编码的丰富预训练知识
- 如何将源知识转移到目标域以实现更好的自适应
本文的目标是学习可转移(领域无关)的提示,以有效地利用CLIP将预训练知识和源知识转移到目标域。在UDA中直接学习这样的文本提示可能不够理想,因为来自不同域的视觉嵌入通常包含不同的、域偏置的信息,这些信息符合CLIP特征空间中的不同分布。这是以前方法中领域特定提示背后的关键动机。本文提出基于域无关文本提示提示视觉主干,从而调整视觉嵌入以产生域不变的表示;域不变的视觉嵌入仍然可以保留个体特征,例如对象的颜色和大小。即使在同一类别内,这种变化也需要利用实例级的提示进行更好的对齐
考虑到两种提示的相互依赖,构建了一个基于Transformer解码器启发的交叉注意力相互学习框架,设置了语义一致性正则化和实例区分对比损失,以确保学习到的提示包括域无关和实例级信息
Contributions
- 提出了DAMP框架用于学习域无关提示,以利用CLIP将预训练知识和源知识转移到目标域
- DAMP通过提示两种模态学习域不变表示,从而相互对齐文本和视觉嵌入
- UDA基准上实验验证了有效性
Method
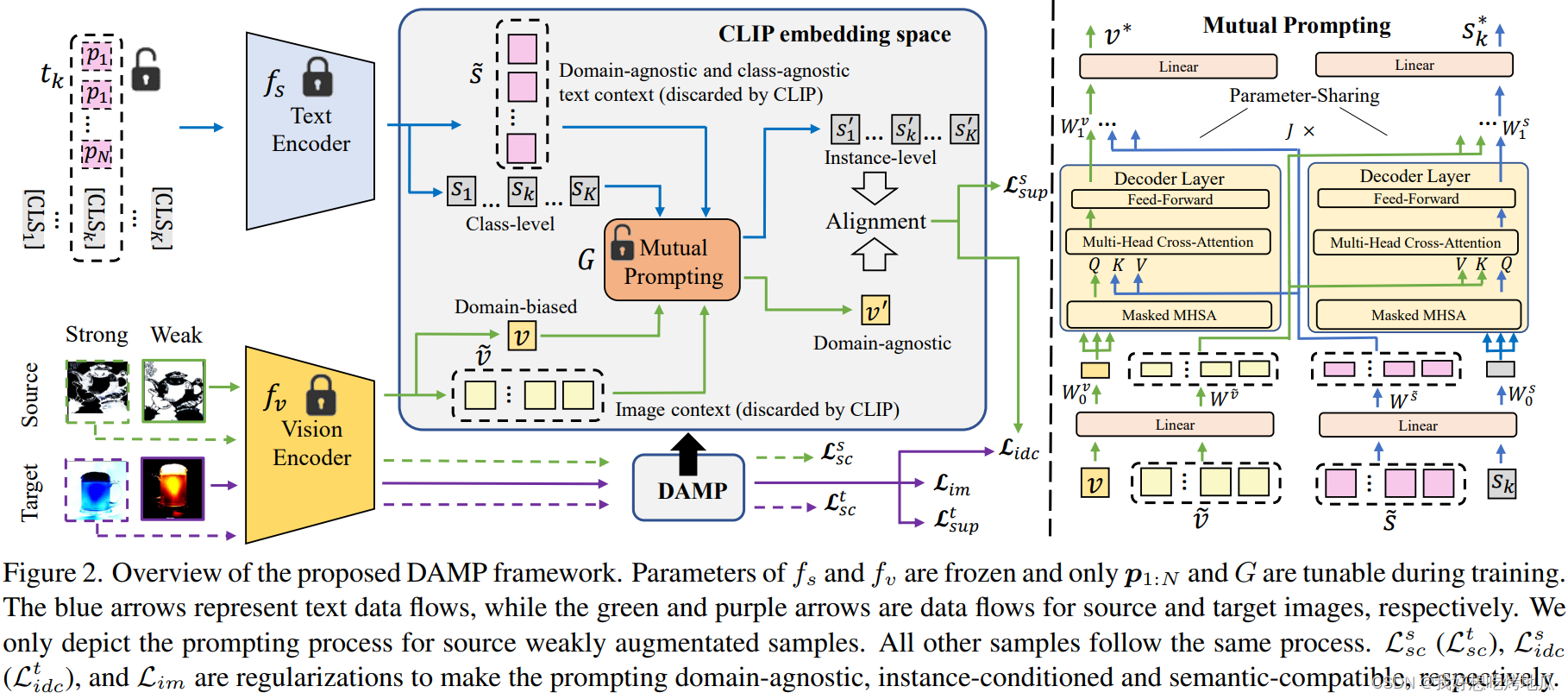
Domain-Agnostic Prompting with CLIP
对每个类别使用共享的可学习提示(CoOp)
Mutual Prompt Learning with Cross-Attention
在UDA中直接学习域无关的提示较为困难,首先, f v f_v fv是在没有域自适应目标的情况下进行预训练的,会产生符合不同域分布的、具有域偏置的视觉嵌入。其次,实例的多样性导致大量的类内差异,使得将所有样本对齐到一个类别级别的文本提示变得困难。为了解决这些问题,选择对 f v f_v fv添加视觉提示,以产生域无关视觉表示。与此同时,还根据每个图像的上下文信息调整 f s f_s fs上的文本提示,以实现更好的图像-文本对对齐
Language-Guided Visual Prompting
利用域无关的类别语义指导产生域无关视觉特征的视觉提示,使用交叉注意力机制在两个分支之间传递信息
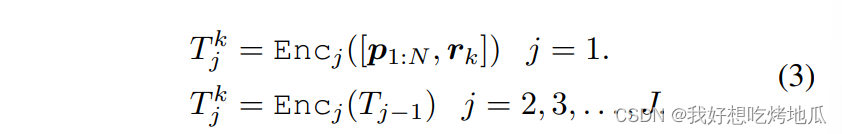
使用多层的文本嵌入来指导视觉提示的生成,其编码了域和类别无关的语义信息,使用用“post-model”提示策略来在嵌入空间中提示
f
v
f_v
fv。首先获得输入
x
\boldsymbol{x}
x 的视觉嵌入,基于交叉注意力策略与文本进行聚合
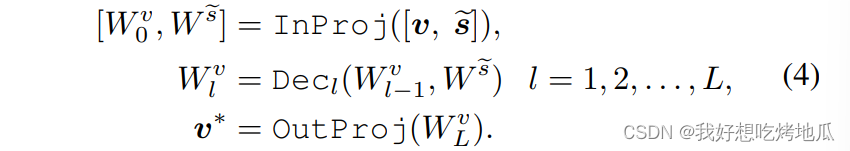
Vision-Guided Language Prompting
利用CLIP中被丢弃的一部分信息来调整文本嵌入,即多头注意力层处理后类[token]以外其他空间位置的嵌入,其保留了有用的语义和空间信息
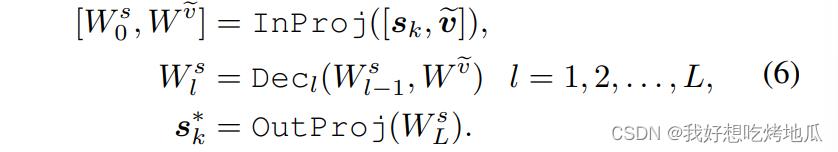
最终的语义嵌入
s
k
′
=
s
k
+
γ
s
s
k
∗
\boldsymbol{s}_k'=\boldsymbol{s}_k+\gamma_s\boldsymbol{s}_k^*
sk′=sk+γssk∗,其依赖于实例,实现更好的图像-文本对齐。两个分支的提示相互引导,以确保彼此之间的相互协作。
Auxiliary Regularizations
尽管相互提示框架旨在生成域不变的视觉嵌入和实例级的文本嵌入,但直接优化分类损失不能保证实现这一目标,因此设计了两个辅助正则化项
Instance-Discrimination Contrastive Loss
在相互提示过程中,更新的文本嵌入可能仍然会从图像上下文中编码一些特定于域的语义,动机是同一域的图像通常具有相同的域信息,最大化
s
k
′
\boldsymbol{s}_k'
sk′之间的差异以消除特定于域的信息。对比损失迫使
s
k
′
\boldsymbol{s}_k'
sk′ 不编码特定于域的线索,同时保留纯粹的实例特定信息。若
s
k
′
\boldsymbol{s}_k'
sk′ 包含了特定于域的信息,那么来自同一域的不同图像将更加相似,因此可以通过优化
L
i
d
c
\mathcal{L}_{idc}
Lidc 进一步去除特定于域的信息。与此同时,这种对比损失可以以无监督的方式进行优化,从而为两个域提供正则化
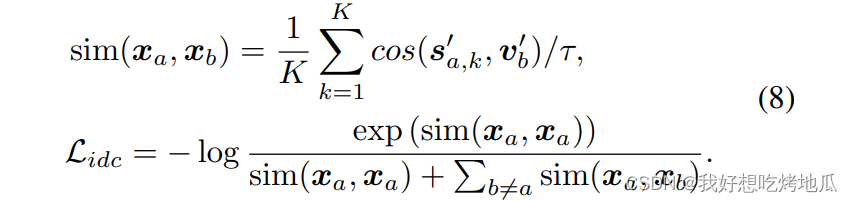
Semantic-Consistency Regularization
除了在
s
k
′
\boldsymbol{s}_k'
sk′ 中去除特定于域的信息之外,还希望确保提示的视觉嵌入是域不变的。利用语义一致性正则化来利用域无关的视觉特征,通过RandAugment来获得强烈增强的输入,表示为
A
(
x
)
\mathcal{A}(\boldsymbol{x})
A(x),并强制对其进行正确分类。对于带标签的源样本可以直接通过标签优化
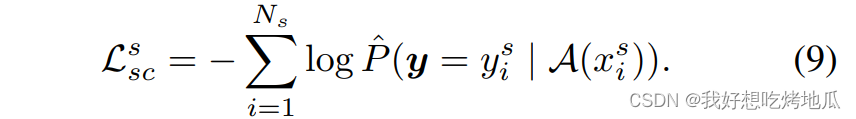
然而,不确定的目标样本仍然没有得到很好的利用。为了使更新后的目标域嵌入适应学习到的语义结构,利用信息最大化技术来通过基于熵的损失对未标记的目标数据进行正则化,优化
L
i
m
\mathcal{L}_{im}
Lim 使全局预测多样化且局部高置信,从而避免了类别崩溃和模糊
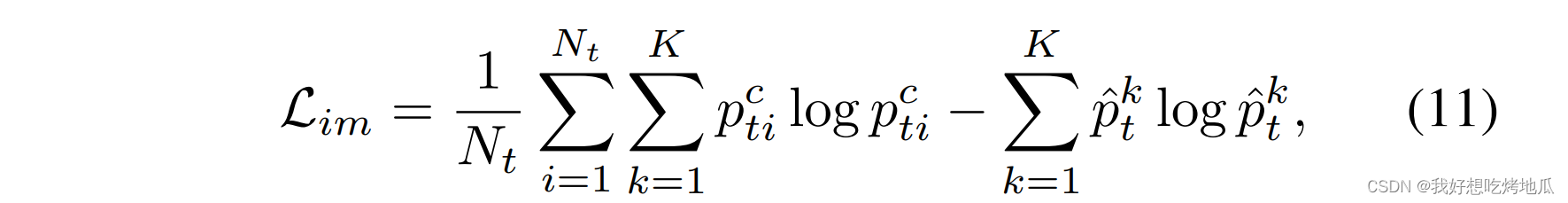
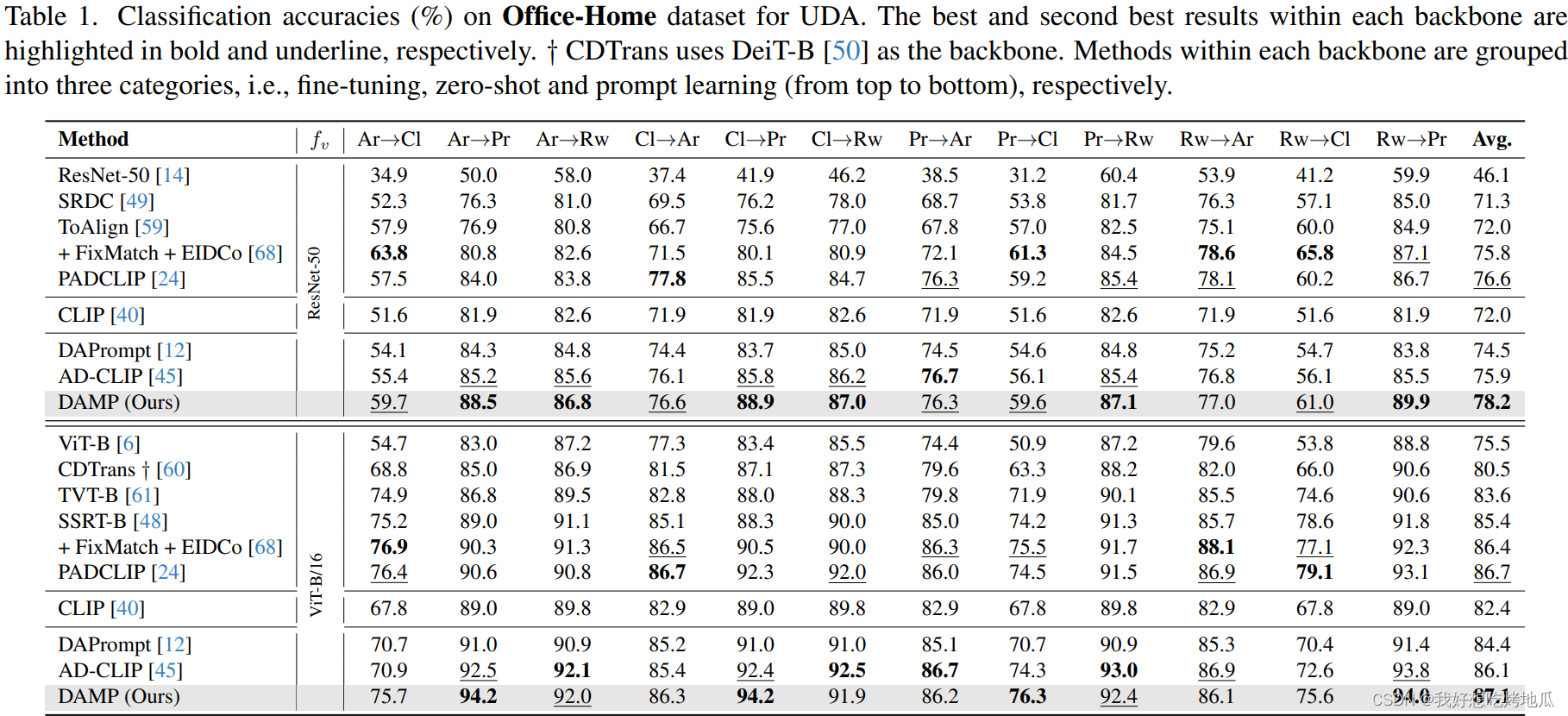
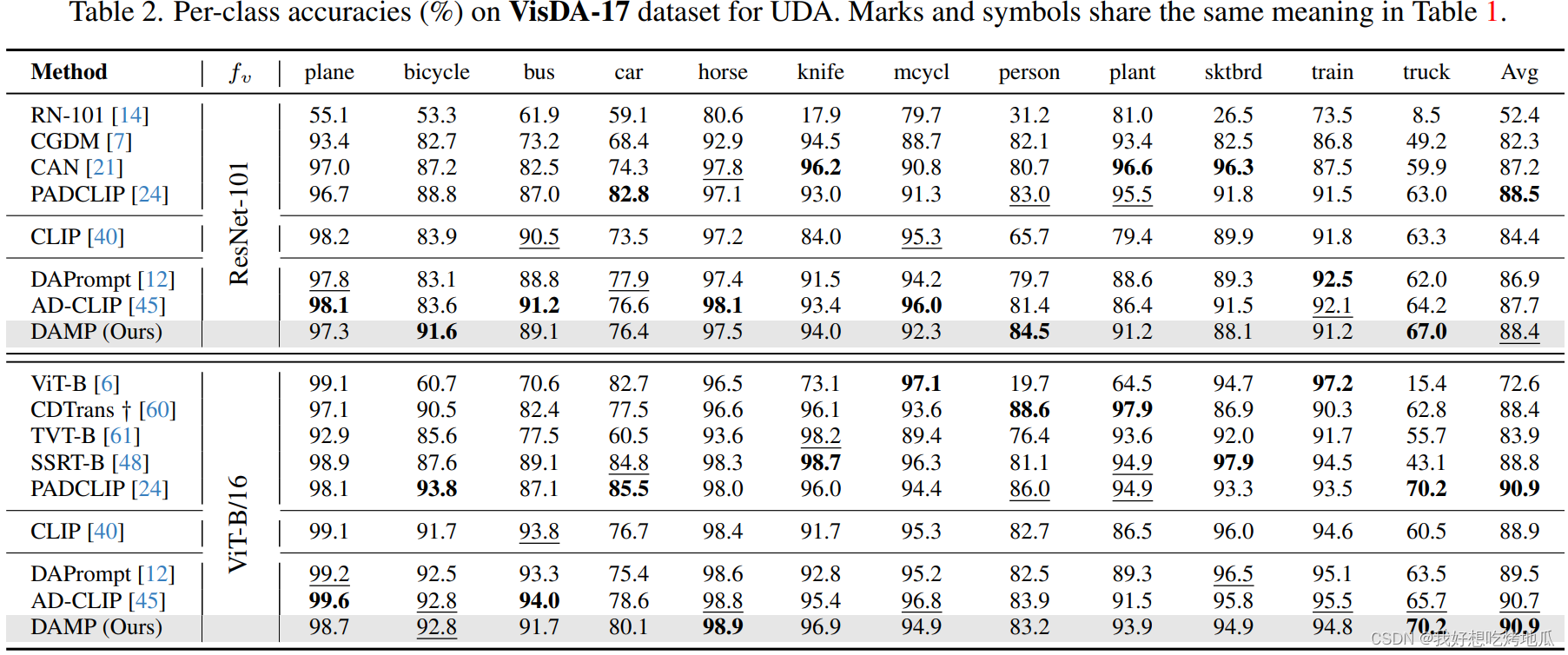
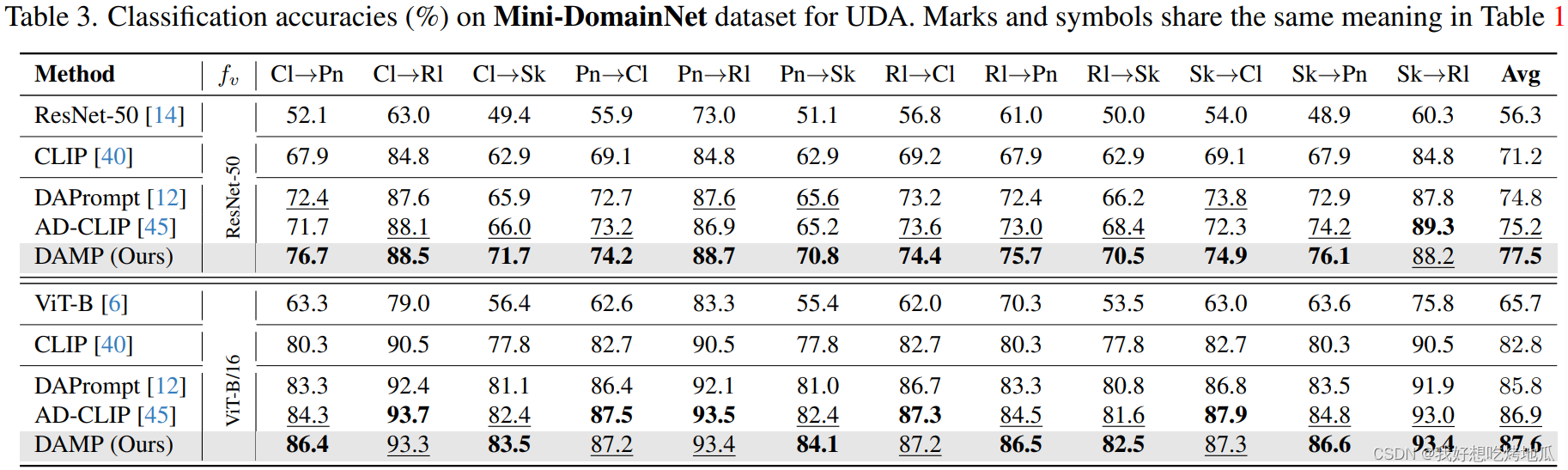
Experiments















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









