







 本文提出AnomalyCLIP,一种调整CLIP以实现零样本异常检测的方法。通过学习捕捉图像中通用的正常/异常,与物体无关的文本提示,AnomalyCLIP解决了VLMs在异常检测中的局限性,提升了在不同领域中的泛化性能。实验结果表明,该方法在工业和医学领域的多样化数据集中表现出色。
本文提出AnomalyCLIP,一种调整CLIP以实现零样本异常检测的方法。通过学习捕捉图像中通用的正常/异常,与物体无关的文本提示,AnomalyCLIP解决了VLMs在异常检测中的局限性,提升了在不同领域中的泛化性能。实验结果表明,该方法在工业和医学领域的多样化数据集中表现出色。
Abstract
零样本异常检测(zero-shot anomaly detection,ZSAD)要求使用辅助数据训练的检测模型,在目标数据集中无需任何训练样本即可检测异常。由于隐私等原因(训练数据无法访问)时,这是一项具备实际意义但具有挑战性的任务,模型需要在不同域中泛化并检测异常,其中前景对象的外观、异常区域和背景特征(例如不同产品/器官上的缺陷/肿瘤)可能会显著变化。大型预训练的视觉-语言模型(VLMs),如CLIP,在各种视觉任务中展示了强大的零样本识别能力,包括异常检测。
VLMs更专注于对前景对象的类语义进行建模,而不是图像中的异常/正常,它们的ZSAD性能较弱。本文提出AnomalyCLIP用于在不同领域中调整CLIP以实现准确的ZSAD,其关键是学习捕获图像中通用正常/异常的与物体无关的文本提示,使模型能够专注于异常图像区域,而不是物体语义,从而实现对多类物体的可泛化正常/异常识别
Intro.
异常检测(AD)已被广泛应用于各种应用场景,例如工业缺陷检测和医学图像分析。现有的AD方法通常假设目标域的训练样本可用于学习检测模型,然而这种假设在各种情况下可能不成立,例如i)访问训练数据违反了数据隐私政策;ii)目标领域没有相关的训练数据(例如,检查新产品的制造线上的缺陷)。零样本异常检测(ZSAD)是在这种情况下的AD的一项新任务,上述的AD方法不适用于该任务,因为它要求检测模型在目标数据集中无需任何训练样本即可检测异常
由于不同应用场景中的异常通常在视觉外观、前景对象和背景特征方面有重大变化,例如一个产品表面的缺陷与其他产品的缺陷、不同器官上的病变/肿瘤或工业缺陷与医学图像中的肿瘤/病变,因此需要具有强大泛化能力的检测模型来实现准确的ZSAD。大型预训练的视觉-语言模型(VLMs)在各种视觉任务中展示了强大的零样本识别能力,包括异常检测。CLIP作为使用数百万/十亿图像-文本对进行预训练的模型,已被应用于各种下游任务,具有强大的泛化能力。WinCLIP是ZSAD领域的开创性工作,它设计了大量人工文本提示来利用CLIP的泛化能力进行ZSAD
诸如CLIP的VLMs主要是针对前景物体的类语义进行训练,而不是图像中的异常/正常,因此,它们在理解视觉异常/正常方面的泛化受到限制,导致ZSAD性能较弱。此外,当前的提示方法,无论是使用手动定义的文本提示还是可学习的提示,通常会导致提示嵌入选择全局特征以实现有效的物体语义对齐,从而无法捕获通常以细粒度局部特征呈现的异常性

对比在(b)测试数据上使用(c)CLIP中的原始文本提示;(d)WinCLIP中用于AD的定制文本提示;(e)CoOp中用于一般视觉任务的可学习文本提示;以及(f)AnomalyCLIP中的与对象无关的文本提示的ZSAD结果。(a)展示了我们可以用来学习文本提示的一组辅助数据。结果是通过文本提示嵌入和图像嵌入之间的相似度获得的。在(a)和(b)中,真实异常区域用红色圈出。(c)、(d)和(e)在不同域之间都存在泛化能力差的问题,而AnomalyCLIP在(f)中能够很好地泛化到来自不同领域的各种对象中的异常
AnomalyCLIP用于调整CLIP以实现在不同域中准确的ZSAD,旨在学习捕获图像中通用正常/异常的与物体无关的文本提示。首先设计了一个简单但普遍有效的可学习的提示模板,用于正常性/异常性,然后基于辅助数据使用图像级和像素级损失函数来学习我们的提示嵌入中的全局和局部通用正常/异常性。这使得模型能够专注于异常图像区域,而不是物体语义,实现了对与辅助数据中相似的异常模式的ZSAD能力。如Fig.1a和Fig.1b所示,微调辅助数据和目标数据中的前景物体语义可以完全不同,但异常模式仍然相似,例如金属螺母和板上的划痕,晶体管和PCB的错位,各种器官表面的肿瘤/病变等。CLIP中的文本提示嵌入无法跨不同领域进行泛化,如Fig.1c所示,但由AnomalyCLIP学习的与物体无关的提示嵌入可以有效地泛化到图1f中不同领域图像中的异常识别
Contributions
- 学习与物体无关的正常和异常文本提示是实现准确ZSAD的一种简单而有效的方法。与当前主要设计用于对象语义对齐的文本提示方法相比,AnomalyCLIP的文本提示嵌入模型了通用异常和正常的语义,从而实现了与物体无关的泛化ZSAD性能
- 利用与对象无关的提示模板和全局异常性损失函数(即全局和局部损失函数的组合)来使用辅助数据学习通用异常和正常提示,简化了提示设计并且可以有效地应用于不同域,而无需对其学习的两个提示进行任何更改
- 对工业和医学领域的17个数据集的全面实验表明,AnomalyCLIP在缺陷检查和医学成像领域的高度多样化类语义数据集中具有有效的ZSAD能力,能够检测和分割异常
ANOMALYCLIP: OBJECT-AGNOSTIC PROMPT LEARNING
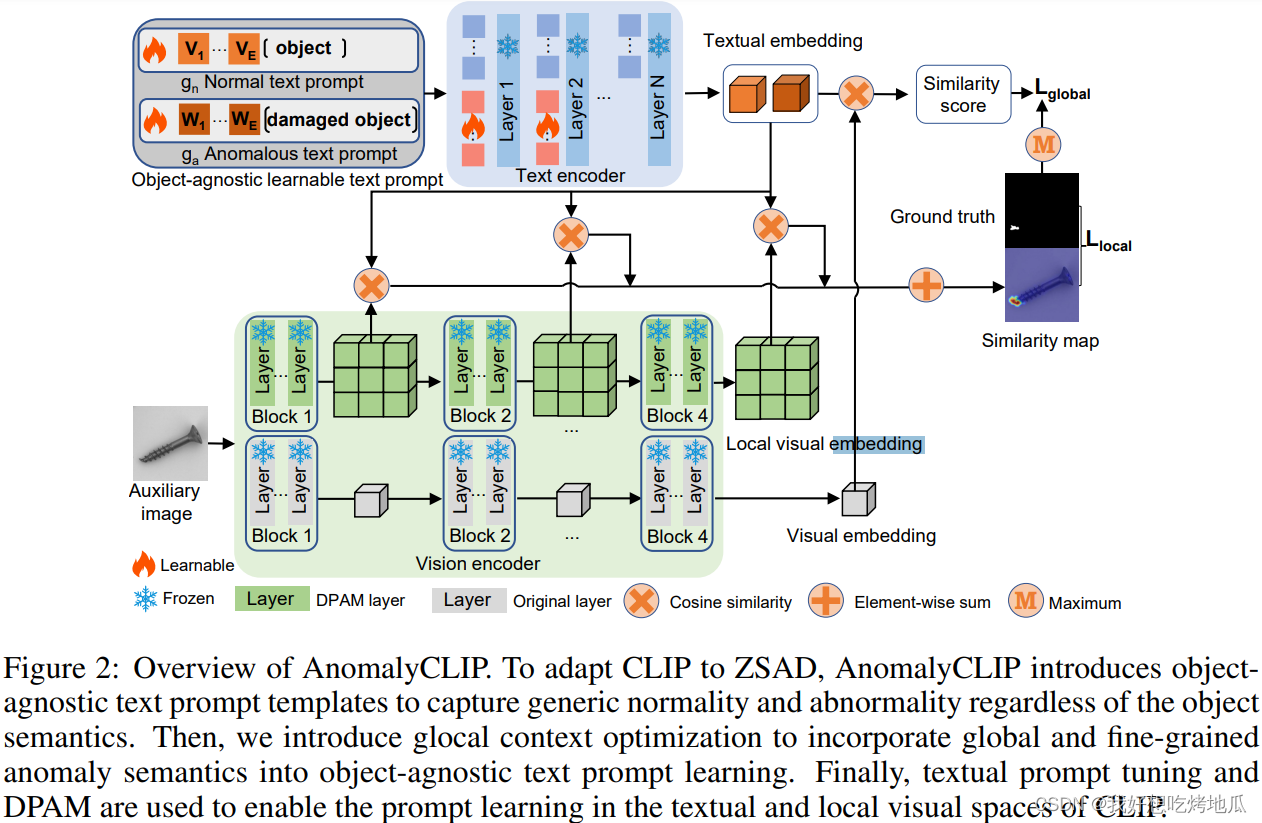
为使CLIP适应ZSAD,AnomalyCLIP引入了与物体无关的文本提示模板,以捕获通用的正常/异常,而不考虑对象语义。引入了全局和细粒度异常语义的glocal上下文优化,将其纳入与对象无关的文本提示学习中。最后,使用文本提示调整和DPAM来在CLIP的文本和局部视觉空间中启用文本提示学习
APPROACH OVERVIEW
AnomalyCLIP首先设计了两个通用的对象无关的文本提示模板 g n g_n gn和 g a g_a ga,分别用于学习正常和异常类的泛化嵌入。为了学习这样的通用文本提示模板,引入了全局和局部上下文优化,将全局和细粒度的异常语义纳入物体无关的文本嵌入学习中。文本提示微调和DPAM用于支持在CLIP的文本和局部视觉空间中的学习,集成了多个中间层以提供更多的局部视觉细节。训练过程中,所有模块都通过全局和局部上下文优化的组合进行联合优化;推理阶段量化了文本和全局/局部视觉嵌入之间的不对齐,分别得到异常分数和异常分数图
OBJECT-AGNOSTIC TEXT PROMPT DESIGN
在CLIP中常用的文本提示模板,例如“A photo of a [cls]”,主要关注对象语义。因此,它们未能生成捕获异常和正常语义以查询相应视觉嵌入的文本嵌入。为了支持学习具有区分性的异常文本嵌入,旨在将先验异常语义纳入文本提示模板中。一个简单的解决方案是设计具有特定异常类型的模板,例如“A photo of a [cls] with scratches”
异常的模式通常是未知且多样的,因此实际上很难列出所有可能的异常类型。定义具有通用异常语义的文本提示模板至关重要,采用“damaged [cls]”来覆盖全面的异常语义,加强对各种缺陷(如划痕和孔洞)的检测。然而,利用这种文本提示模板在生成通用的区分异常的文本嵌入方面存在挑战。CLIP原始预训练专注于与对象语义对齐,而不是图像中的异常/正常性。为了解决这个限制,引入可学习的文本提示模板,并使用辅助的AD数据调整提示。在微调过程中,这些可学习的模板可以包含广泛和详细的异常语义,从而产生更具有区分性的文本嵌入,有助于避免需要进行大量工作量手动定义的文本提示模板。这些文本提示被称为object-aware文本提示模板,并定义如下:
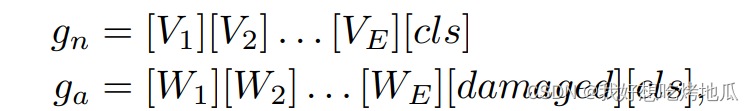
ZSAD任务要求模型在以前未见的目标数据集中检测异常。这些数据集在不同对象之间通常在对象语义上存在显著变化,如一个产品上的各种缺陷与另一个产品之间的差异,或者工业缺陷和医学成像肿瘤之间的差异。然而,尽管这些对象语义存在差异,但潜在的异常模式可能是相似的。例如,金属螺母和板上的划痕,晶体管和PCB的错位,以及各种器官表面的肿瘤等异常,可以共享类似的异常模式
假设准确ZSAD的关键是识别这些通用异常模式,而不考虑不同物体的语义变化。在object-aware文本提示模板中包含对象语义通常对于ZSAD是不必要的,甚至可能妨碍对在学习过程中未见过的类别中的异常的检测。更重要的是,从文本提示模板中排除对象语义可以使可学习的文本提示模板专注于捕获异常本身的特征,而不是物体。引入了object-agnostic提示学习,旨在捕获图像中的通用正常和异常,而不考虑对象语义。object-agnostic文本提示模板用对象替换了
g
n
g_n
gn和
g
a
g_a
ga中的类名,屏蔽了对象的类语义:
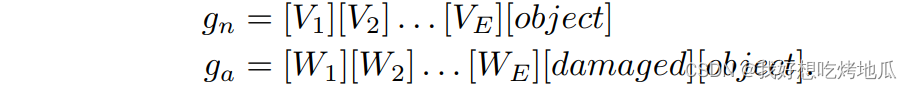
这种设计使得object-agnostic文本提示模板能够学习不同异常的共享模式,生成的文本嵌入更通用,并且能够识别不同对象和不同领域中的异常。此外,这种提示设计具有通用性,可以应用于不同的目标领域,而无需进行任何修改,例如,不需要了解目标数据集中的对象名称或异常类型
LEARNING GENERIC ABNORMALITY AND NORMALITY PROMPTS
Glocal context optimization
为了有效学习对象无关的文本提示,设计了一种联合优化方法,可以从全局和局部两个角度进行正常性和异常性提示的学习,即全局和局部上下文优化。全局上下文优化旨在确保物体无关文本嵌入与来自不同对象的图像的全局视觉嵌入匹配,有助于有效地从全局特征的角度捕获正常/异常语义。局部上下文优化引入了中间视觉编码器的
M
M
M个中间层,使得对象无关的文本提示能够专注于细粒度的局部异常区域,除了全局的正常/异常特征。形式上,假设
M
\mathcal{M}
M是使用的中间层集合(即
M
=
∣
M
∣
M = |\mathcal{M}|
M=∣M∣),我们的文本提示通过最小化以下glocal损失函数来学习:
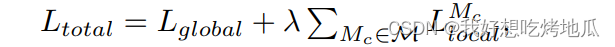
其中
λ
λ
λ是平衡全局和局部损失的超参数。
L
global
L_{\text{global}}
Lglobal是一个交叉熵损失,用于匹配对象无关文本嵌入与辅助数据中正常/异常图像的视觉嵌入之间的余弦相似度。设
S
∈
R
H
image
×
W
image
S \in \mathbb{R}^{H_{\text {image }} \times W_{\text {image }}}
S∈RHimage ×Wimage 是真实分割,如果像素是异常则
S
j
k
=
1
S_{jk}=1
Sjk=1,否则
S
j
k
=
0
S_{jk}=0
Sjk=0,则有
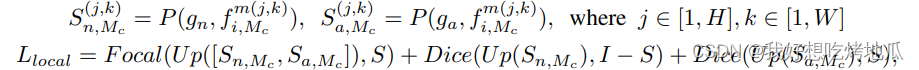
其中
F
o
c
a
l
(
⋅
,
⋅
)
Focal(·, ·)
Focal(⋅,⋅)和
D
i
c
e
(
⋅
,
⋅
)
Dice(·, ·)
Dice(⋅,⋅)分别表示焦点损失和Dice损失。操作符
U
p
(
⋅
)
Up(·)
Up(⋅)和
[
⋅
,
⋅
]
[·, ·]
[⋅,⋅]表示上采样和沿着通道的连接,I表示全一矩阵。由于异常区域通常比正常区域小,使用焦点损失来解决不平衡问题。此外,为了确保模型建立准确的决策边界,使用Dice损失来衡量预测分割
U
p
(
S
n
,
M
c
)
/
U
p
(
S
a
,
M
c
)
Up(S_{n,M_c})/Up(S_{a,M_c})
Up(Sn,Mc)/Up(Sa,Mc)与真实掩码之间的重叠
Refinement of the textual space
引入了文本提示调整,通过向CLIP的文本编码器中添加额外的可学习的标记嵌入来优化其原始的文本空间。具体地,将随机初始化的可学习的标记嵌入附加到冻结的CLIP文本编码器的第 m m m层中。然后,沿着通道的维度将其和原始的标记嵌入连接起来,然后将它们传输到 T m T_{m} Tm以获得相应的 r m + 1 ′ r'_{m+1} rm+1′和 t m + 1 t_{m+1} tm+1。为了确保适当的校准,丢弃获得的 r m + 1 ′ r'_{m+1} rm+1′并初始化新的可学习的标记嵌入 t m + 1 ′ t'_{m+1} tm+1′。即使输出 r m + 1 ′ r'_{m+1} rm+1′被丢弃,由于自注意机制,更新的梯度仍然可以反向传播以优化可学习的标记 t m ′ t'_{m} tm′,重复这个操作直到达到指定的层 M ′ M' M′。在微调过程中,优化可学习的标记嵌入以优化原始文本空间
Refinement of the local visual space
由于CLIP的视觉编码器最初是预训练来对齐全局对象语义,CLIP中使用的对比损失使得视觉编码器产生了用于类别识别的代表性全局嵌入。通过自注意机制,视觉编码器中的注意力图集中在Fig.3b中红色矩形中突出显示的特定标记上。尽管这些标记可能有助于全局对象识别,但它们破坏了局部视觉语义,直接阻碍了物体无关文本提示中精细异常性的有效学习
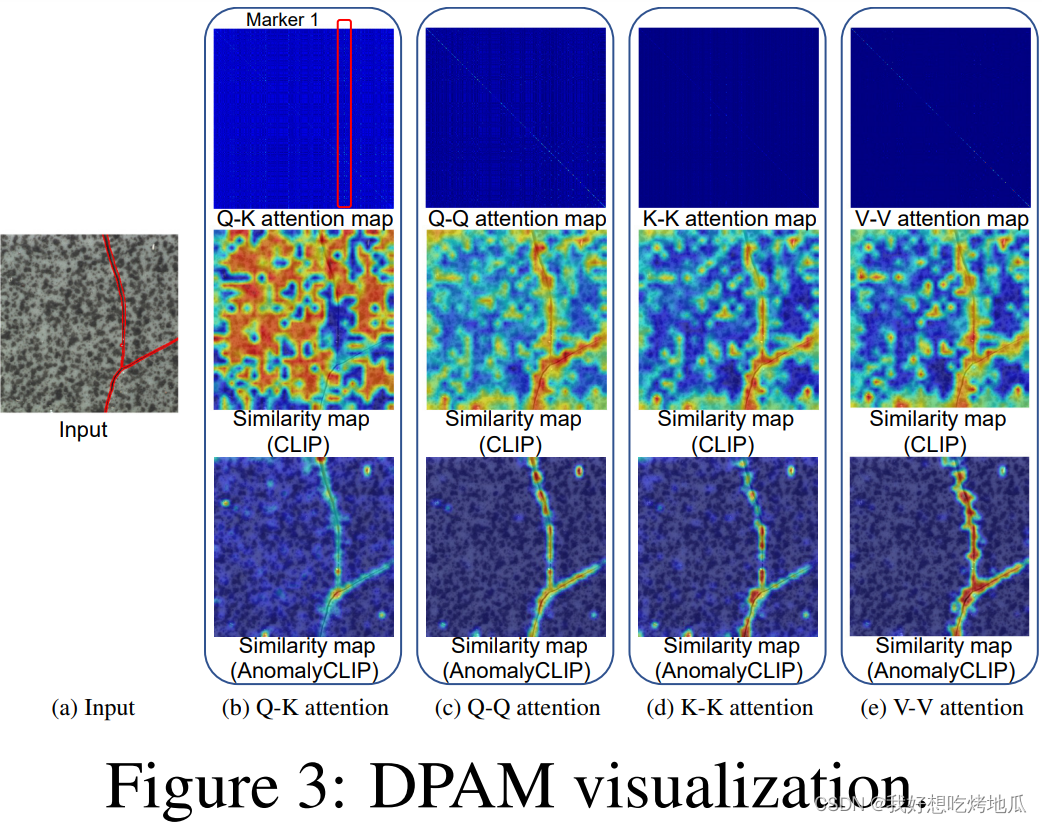
在注意力图中显著对角线的特征有助于减少来自其他标记的干扰,从而改善局部视觉语义。提出了一种称为对角线显著性注意力图的机制,以改善局部视觉空间,在训练过程中保持视觉编码器冻结状态。将视觉编码器中的原始Q-K注意力替换为对角线显著性注意力。如Fig.3c、Fig.3d和Fig.3e所示,经过改进的DPAM注意力图更具对角线显著性。与基于全局特征和手动定义的文本提示的CLIP相比,AnomalyCLIP学习的文本提示更加精细,从而在四种不同的自注意力方案下实现了更准确的正常/异常提示嵌入与局部视觉嵌入之间的对齐
Experiments
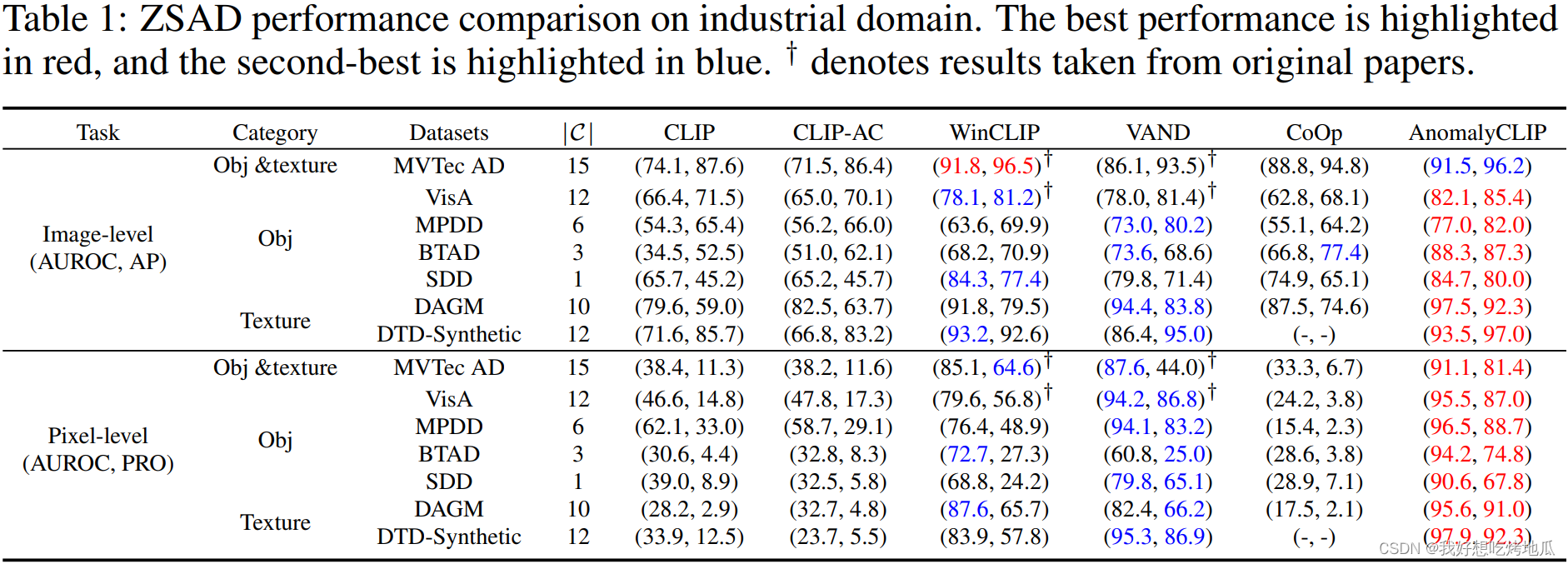
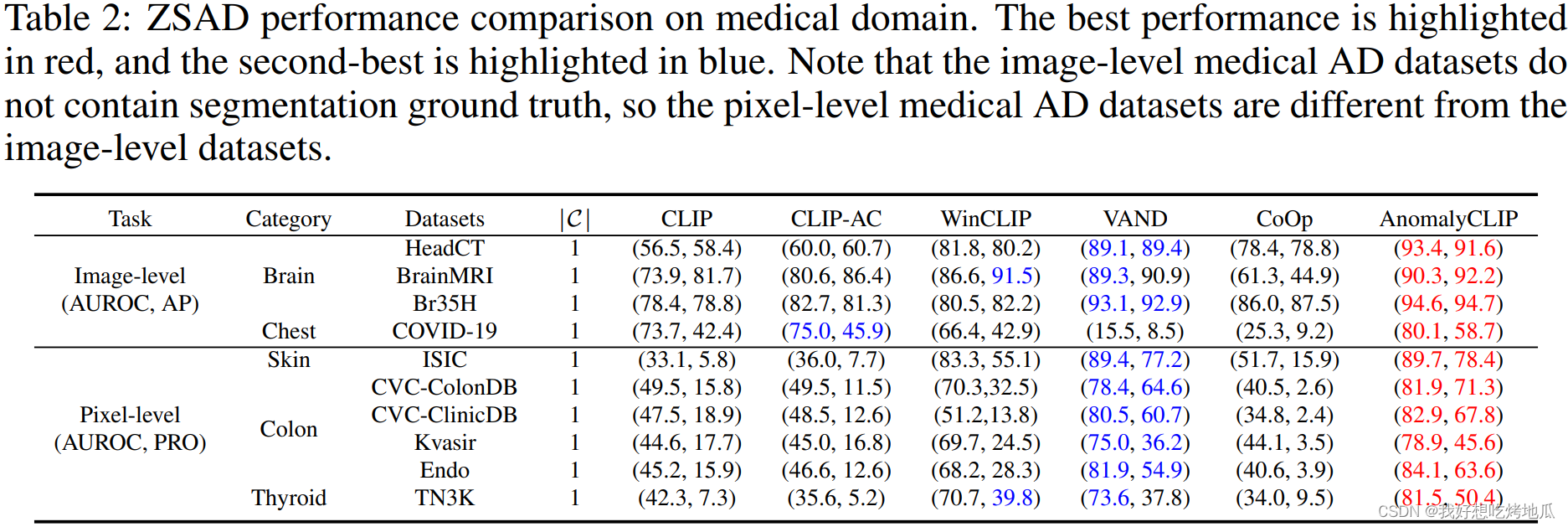
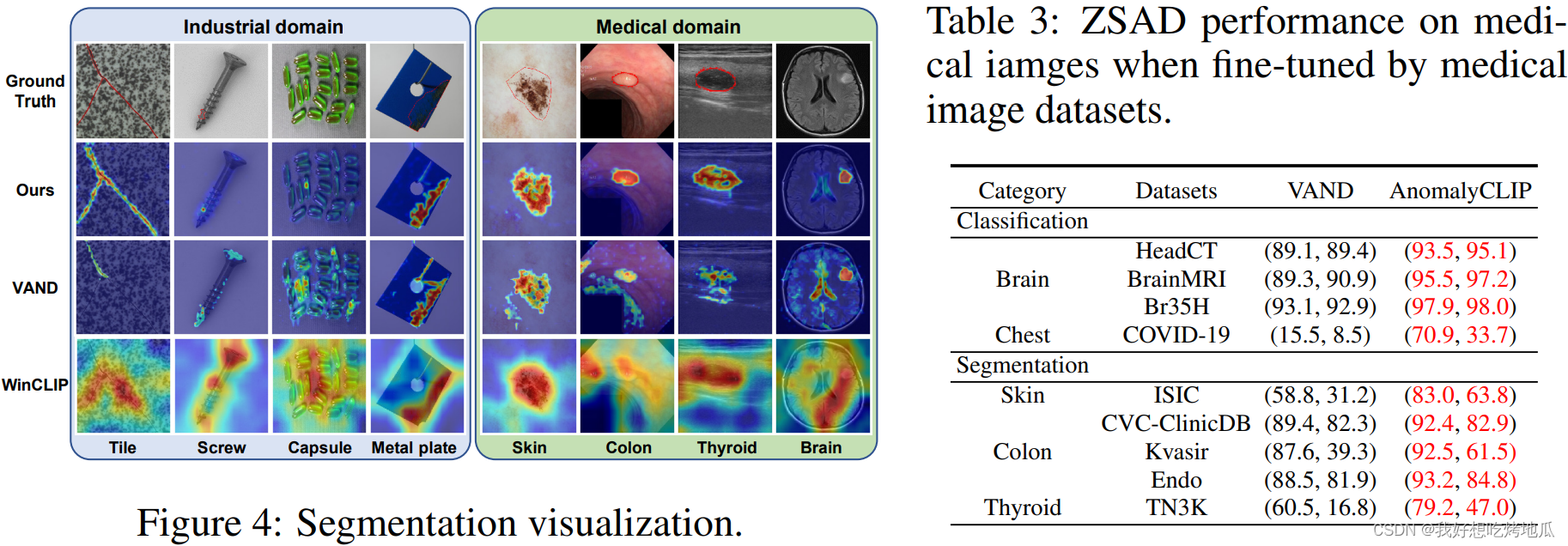

















 2721
2721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









