







 CaFo是一种新方法,它结合CLIP的语言对比、DINO的视觉对比、DALL-E的视觉生成和GPT-3的语言生成知识,用于在低数据环境下提升视觉识别的Few-Shot学习性能。通过GPT-3生成提示,DALL-E生成图像,然后用CLIP和DINO进行缓存,形成“提示-生成-缓存”策略。在测试时,通过比较不同模型的预测置信度来优化分类结果。
CaFo是一种新方法,它结合CLIP的语言对比、DINO的视觉对比、DALL-E的视觉生成和GPT-3的语言生成知识,用于在低数据环境下提升视觉识别的Few-Shot学习性能。通过GPT-3生成提示,DALL-E生成图像,然后用CLIP和DINO进行缓存,形成“提示-生成-缓存”策略。在测试时,通过比较不同模型的预测置信度来优化分类结果。
Motivation
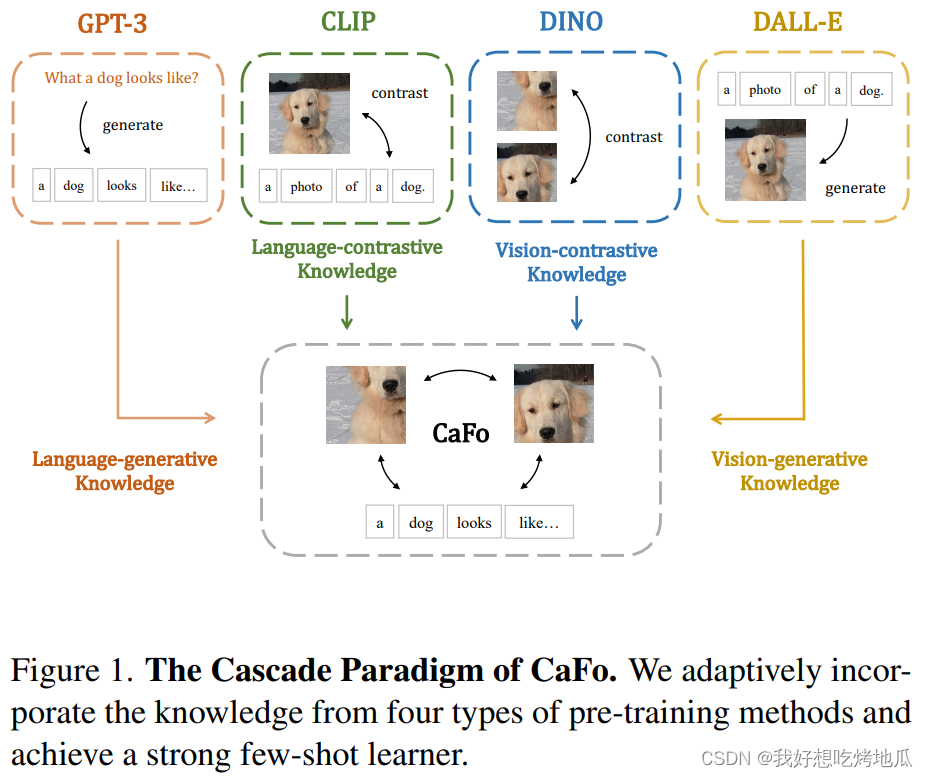
低数据环境下的视觉识别需要深度神经网络从有限的训练样本中学习广义表示。近年来,基于 CLIP 的方法得益于对比语言-图像预训练,显示出了良好的 FSL 性能。如果更多样化的预训练知识可以级联,以进一步帮助 Few-Shot 表示学习。由此提出 CaFo 级联了基础模型,它结合了各种预训练范式的不同先验知识,以实现更好的 FSL。CaFo 结合了 CLIP 的语言对比知识、DINO 的视觉对比知识、DALL-E 的视觉生成知识和 GPT-3 的语言生成知识。其工作方式是“提示,生成,然后缓存”。
Method
Different Pre-training Paradigms
将这种学习到的先验表示为语言对比知识,并采用 CLIP 作为这种预训练方法的代表模型。
Contrastive Vision Pre-training
视觉对比模型作为传统的自监督学习方法,关注的是不同图像之间的区分。研究表明,可以在图像之间没有负例的情况下学习自监督特征。由于具有较强的线性分类能力,本文采用预训练的 DINO 提供视觉对比知识。
Generative Language Pre-training
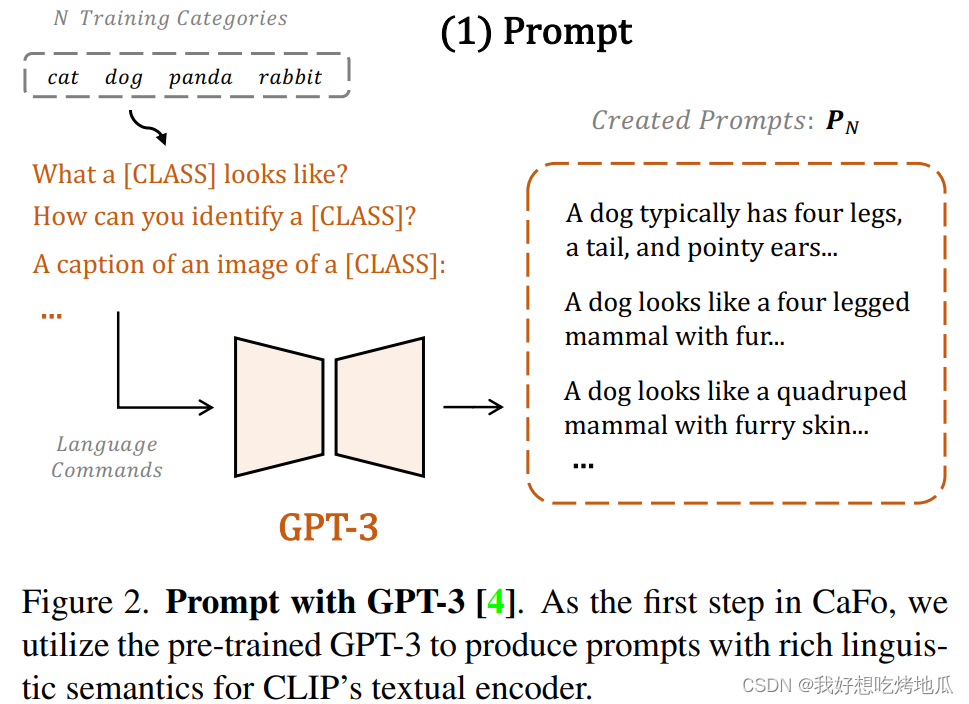
大规模预训练的 GPT-3 能够生成内容多样、质量高的类人文本。GPT-3 以少量设计好的语言命令作为输入,能够为视觉语言模型输出具有丰富语义的 Prompt。利用GPT-3来生成 CLIP 的 Prompt,以更好地与图像中的视觉信息对齐。
Generative Vision-Language Pre-training
DALL-E 可以以 Zero-Shot 的方式生成语言条件下的图像。经过预训练以自回归地方式从图像的文本标记中预测编码的图像。预训练的 DALL-E 可以在不需要任何人为工作的情况下扩大训练数据,实现时选择 DALL-E-mini。
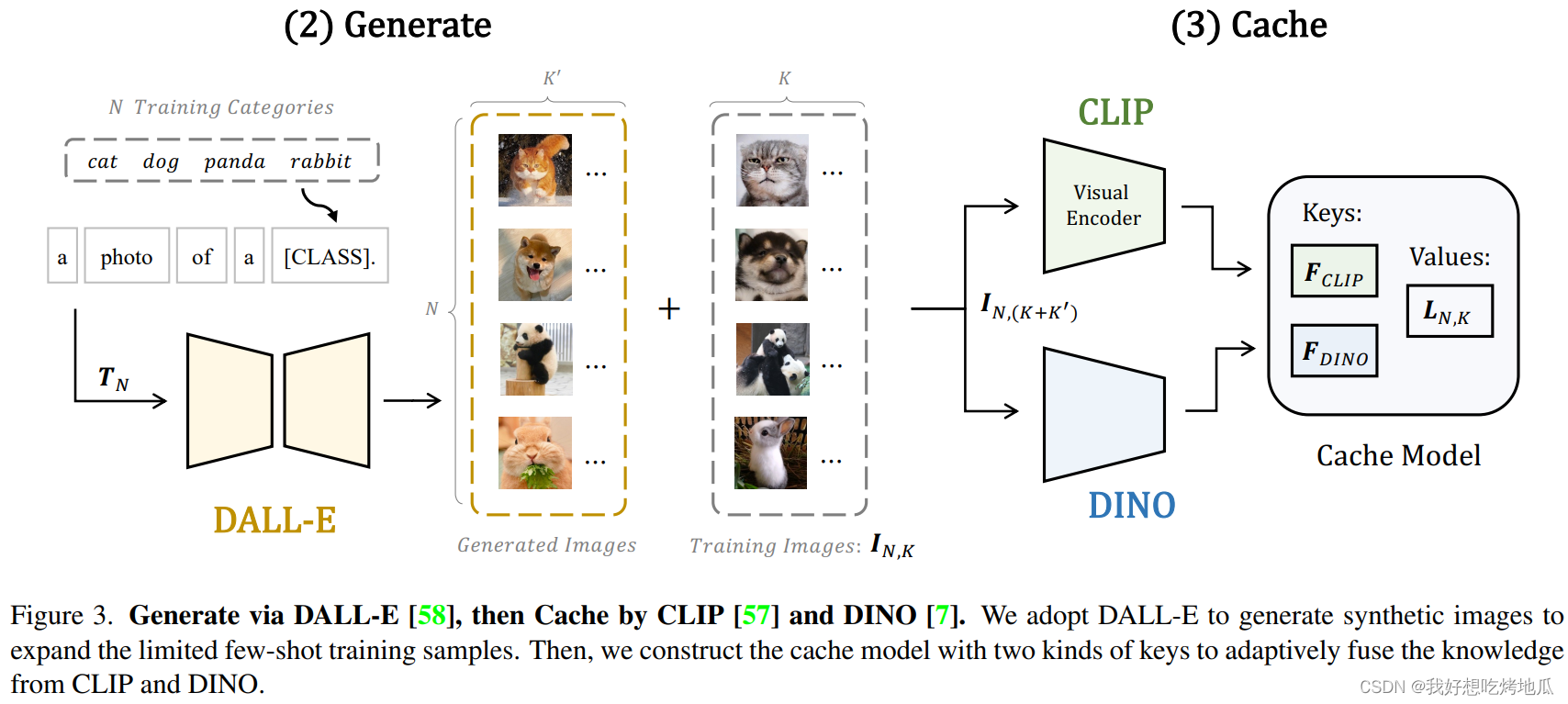
Prompt, Generate, then Cache
Prompt with GPT-3
Generate via DALL-E
Cache by CLIP and DINO
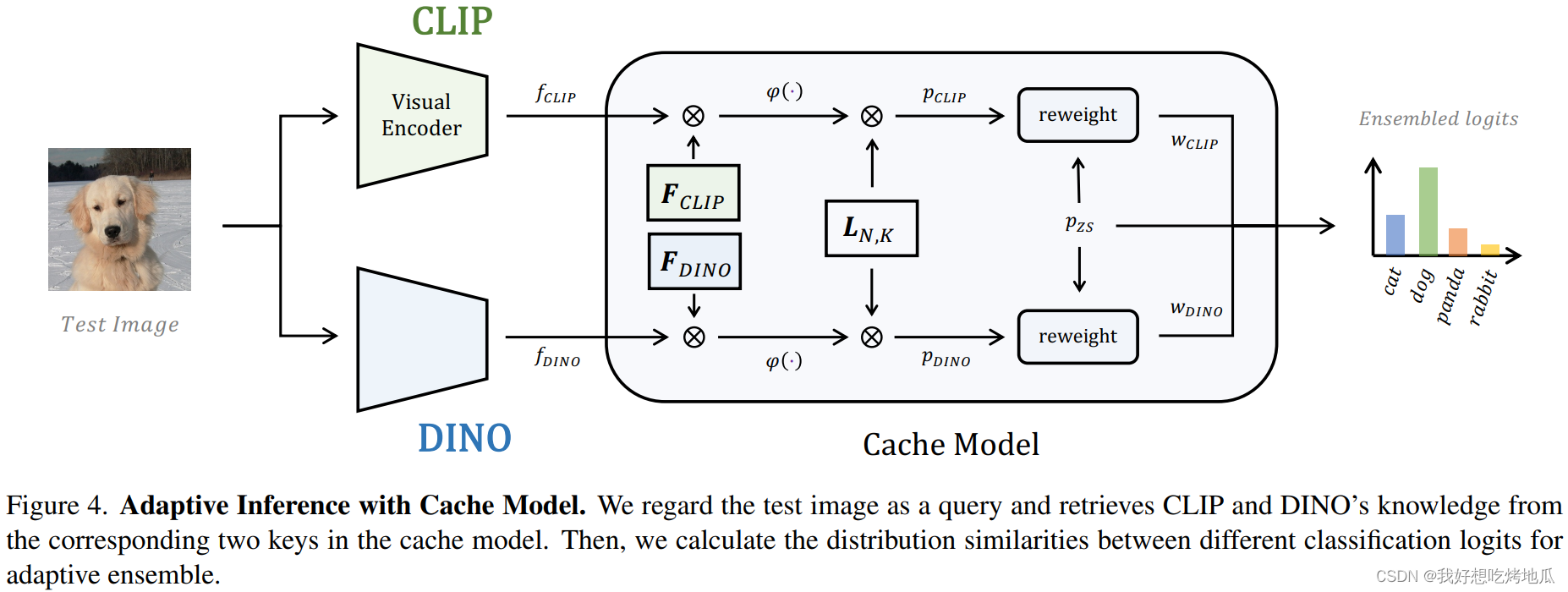
Adaptive Inference
对于测试图像,首先提取其两个视觉特征
f
C
L
I
P
,
f
D
I
N
O
∈
R
1
×
C
f_{CLIP}, f_{DINO}∈\mathbb{R}^{1×C}
fCLIP,fDINO∈R1×C,并将其视为从缓存模型中检索不同知识的查询。然后可以得到三个预测分类置信度
p
Z
S
,
p
C
L
I
P
,
p
D
I
N
O
∈
R
1
×
N
p_{ZS}, p_{CLIP}, p_{DINO}∈\mathbb{R}^{1×N}
pZS,pCLIP,pDINO∈R1×N,它们分别来自 CLIP 的 Zero-Shot 对齐和缓存模型的两个 Key。将其表述为:
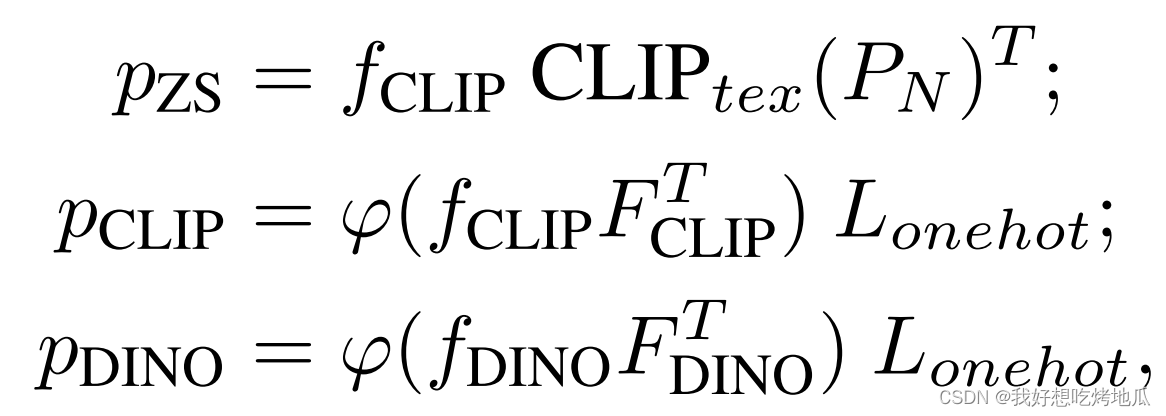
由于语言对比的
p
Z
S
p_{ZS}
pZS 经过了4亿数据的预训练,具有较强的 Zero-Shot 转移能力,我们将
p
Z
S
p_{ZS}
pZS 作为预测基线,并根据
p
C
L
I
P
,
p
D
I
N
O
p_{CLIP}, p_{DINO}
pCLIP,pDINO 与
p
Z
S
p_{ZS}
pZS 的分布相似度计算其对集合的权重。通过这种方法,可以抑制一些明显错误的类别可能性,并在集成过程中放大适度正确的类别可能性。
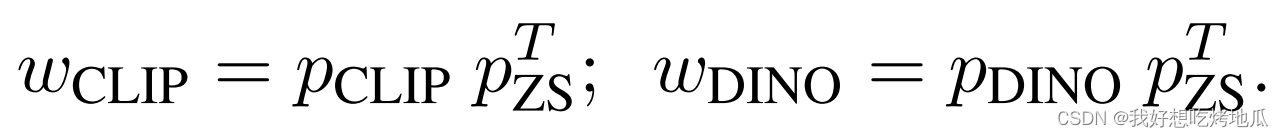
最后,采用softmax函数对权重进行归一化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









