









文章目录
利用Optuna对PyTorch模型进行自动调参
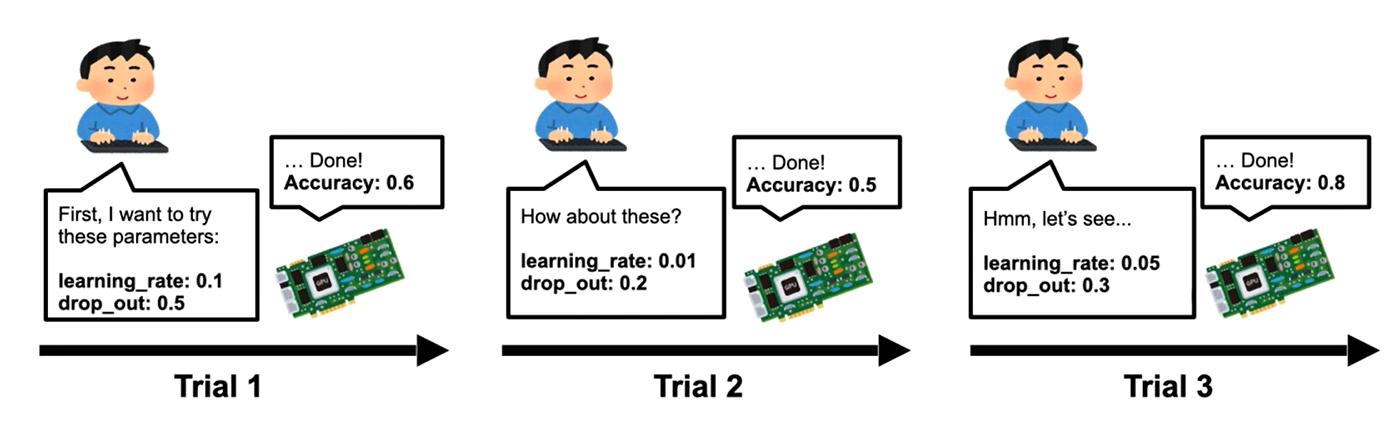
Optuna是一个自动超参数优化框架,可以动态地构造超参数的搜索空间,可以针对模型帮助我们搜索最佳参数。
1. Optuna安装
# pip
pip install optuna
# conda
conda install optuna
2. Optuna使用流程
通常,Optuna是用于优化超参数的,但是作为例子,这里来优化一个简单的二次函数: ( x − 2 ) 2 (x-2)^2 (x−2)2.
- 首先,导入optuna。
import optuna
- 在 Optuna 中,待优化函数一般被命名为 objective。
def objective(trial):
x = trial.suggest_uniform("x", -10, 10)
return (x - 2) ** 2
该函数的返回值是
(
x
−
2
)
2
(x-2)^2
(x−2)2,我们的目标是找到一个 x,使 objective 函数的输出最小。这被称为 “optimization” (优化)。 在优化过程中,Optuna 反复调用目标函数,在不同的 x 下对其进行求值。
一个 Trial 对应着目标函数的单次执行。在每次调用该函数的时候,它都被内部实例化一次。而 suggest API (例如 suggest_uniform()) 在目标函数内部被调用。它被用于获取单个 trial 的参数。在上面的例子中,suggest_uniform() 在给定的范围(-10 到 10)内均匀地选择参数。
当 Optuna 被用于机器学习时,目标函数通常返回模型的损失或者准确度。
- 为了开始优化过程,我们将创建一个 study 对象,并将目标函数传递给它的一个方法
optimize():
study = optuna.create_study()
# study = optuna.create_study(direction='minimize') # 默认 direction='minimize'
# study = optuna.create_study(sampler=optuna.samplers.RandomSampler()) # 切换采样器
study.optimize(objective, n_trials=100)
# study.optimize(objective, n_trials=100, show_progress_bar=True) # 输出美观一点
- 最后,获取最佳参数组合。
best_params = study.best_params
found_x = best_params["x"]
print("Found x: {}, (x - 2)^2: {}".format(found_x, (found_x - 2) ** 2))
在 Optuna 中,我们用 study 对象来管理优化过程。 create_study() 方法会返回一个 study 对象。该对象包含若干有用的属性,可以用于分析优化结果。
| study属性 | 解释 |
|---|---|
study.best_params | 获得参数名和参数值的字典 |
study.best_value | 获得最佳目标函数值 |
study.best_trial | 获得最佳 trial |
study.trials | 获得所有 trials |
len(study.trials) | 获得 trial 的数目 |
- 再次执行
optimize(),可以继续优化过程。
study.optimize(objective, n_trials=100)
3. 超参数采样的搜索空间
optuna.trial.Trial.suggest_categorical()用于类别参数optuna.trial.Trial.suggest_discrete_uniform()用于离散型参数optuna.trial.Trial.suggest_float()用于浮点型参数optuna.trial.Trial.suggest_int()用于整形参数optuna.trial.Trial.suggest_loguniform()用于连续参数,从对数均匀分布中选择参数。(v6.0.0 已经弃用,建议使用suggest_float(..., log=True)代替)optuna.trial.Trial.suggest_uniform()用于连续参数,从线性均匀分布中选择参数。
通过可选的 step 与 log 参数,可以对整形或者浮点型参数进行离散化或者取对数操作。
import optuna
def objective(trial):
# Categorical parameter
optimizer = trial.suggest_categorical("optimizer", ["MomentumSGD", "Adam"])
# Integer parameter
num_layers = trial.suggest_int("num_layers", 1, 3)
# Integer parameter (log)
num_channels = trial.suggest_int("num_channels", 32, 512, log=True)
# Integer parameter (discretized)
num_units = trial.suggest_int("num_units", 10, 100, step=5)
# Floating point parameter
dropout_rate = trial.suggest_float("dropout_rate", 0.0, 1.0)
# Floating point parameter (log)
learning_rate = trial.suggest_float("learning_rate", 1e-5, 1e-2, log=True)
# Floating point parameter (discretized)
drop_path_rate = trial.suggest_float("drop_path_rate", 0.0, 1.0, step=0.1)
4. 优化算法
4.1 采样算法
利用 suggested 参数值和评估的目标值的记录,采样器基本上不断缩小搜索空间,直到找到一个最佳的搜索空间,其产生的参数会带来 更好的目标函数值。
Optuna 提供了下列采样算法:
optuna.samplers.TPESampler实现的 Tree-structured Parzen Estimator 算法(默认)optuna.samplers.CmaEsSampler实现的 CMA-ES 算法optuna.samplers.GridSampler实现的网格搜索optuna.samplers.RandomSampler实现的随机搜索
4.2 切换采样器
默认情况下, Optuna 这样使用 TPESampler.
study = optuna.create_study()
print(f"Sampler is {study.sampler.__class__.__name__}")
如果你希望使用其他采样器,比如 RandomSampler 和 CmaEsSampler,
study = optuna.create_study(sampler=optuna.samplers.RandomSampler())
print(f"Sampler is {study.sampler.__class__.__name__}")
study = optuna.create_study(sampler=optuna.samplers.CmaEsSampler())
print(f"Sampler is {study.sampler.__class__.__name__}")
4.3 剪枝算法
Pruners 自动在训练的早期(也就是自动化的 early-stopping)终止无望的 trial.
Optuna 提供以下剪枝算法:
optuna.pruners.SuccessiveHalvingPruner实现的 Asynchronous Successive Halving 算法。optuna.pruners.HyperbandPruner实现的 Hyperband 算法。optuna.pruners.MedianPruner实现的中位数剪枝算法(常用)optuna.pruners.ThresholdPruner实现的阈值剪枝算法
4.4 激活 Pruner
要打开剪枝特性的话,需要在迭代式训练的每一步后调用 report() 和 should_prune(). report() 定期监控目标函数的中间值. should_prune() 确定终结那些没有达到预先设定条件的 trial.
import logging
import sys
import sklearn.datasets
import sklearn.linear_model
import sklearn.model_selection
def objective(trial):
iris = sklearn.datasets.load_iris()
classes = list(set(iris.target))
train_x, valid_x, train_y, valid_y = sklearn.model_selection.train_test_split(
iris.data, iris.target, test_size=0.25, random_state=0
)
alpha = trial.suggest_float("alpha", 1e-5, 1e-1, log=True)
clf = sklearn.linear_model.SGDClassifier(alpha=alpha)
for step in range(100):
clf.partial_fit(train_x, train_y, classes=classes)
# Report intermediate objective value.
intermediate_value = 1.0 - clf.score(valid_x, valid_y)
trial.report(intermediate_value, step)
# Handle pruning based on the intermediate value.
if trial.should_prune():
raise optuna.TrialPruned()
return 1.0 - clf.score(valid_x, valid_y)
将中位数终止规则设置为剪枝条件。
# Add stream handler of stdout to show the messages
optuna.logging.get_logger("optuna").addHandler(logging.StreamHandler(sys.stdout))
study = optuna.create_study(pruner=optuna.pruners.MedianPruner())
study.optimize(objective, n_trials=20)
关于 Optuna 集成模块的完整列表,参见 optuna.integration.
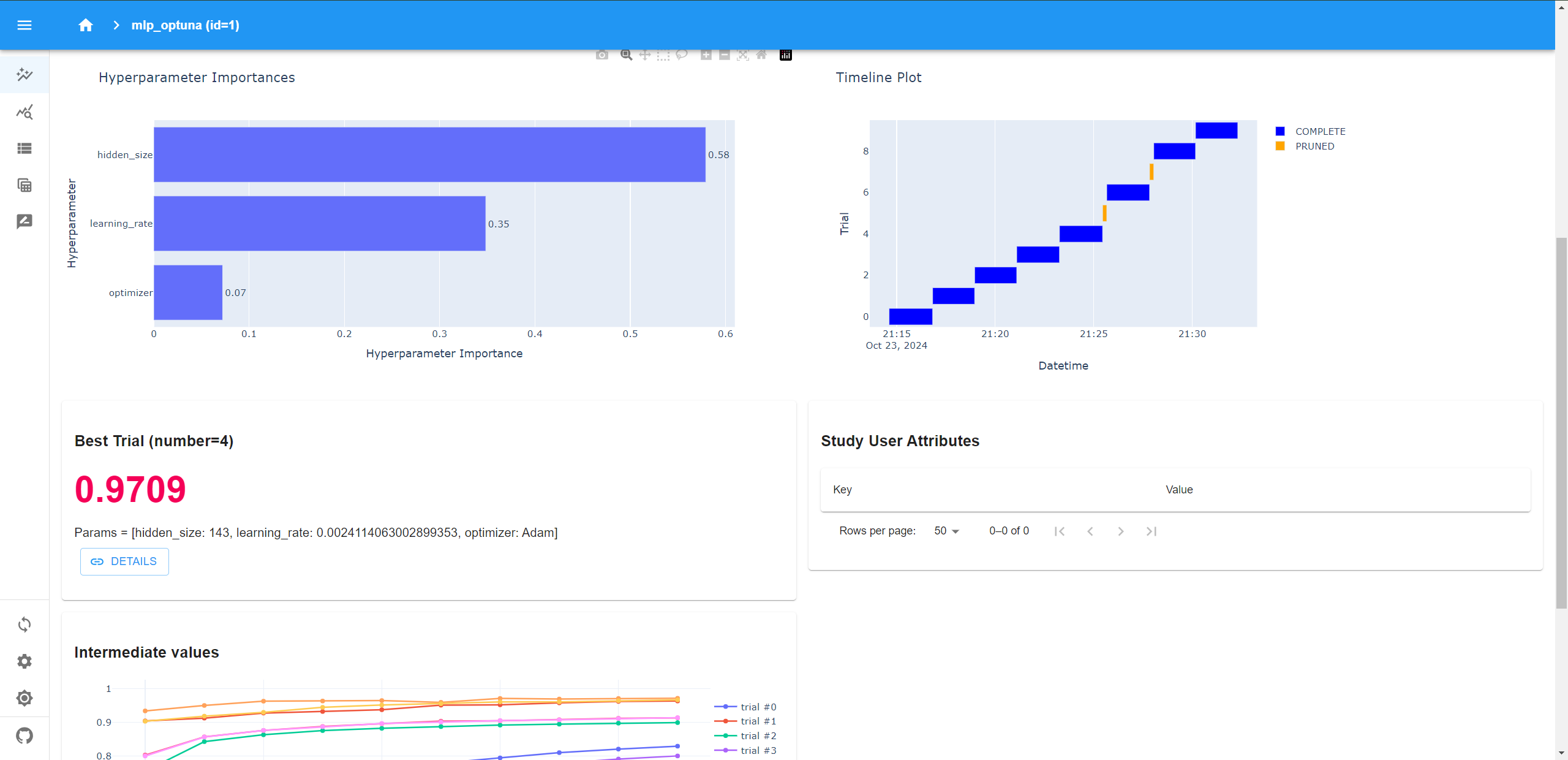
5. Optuna Dashboard的使用
Optuna仪表板是Optuna的实时web仪表板。我们可以在图表中查看优化历史、超参数重要性等。(👀:Optuna Dashboard支持Python 3.7或更新版本。)
5.1 Optuna Dashboard安装
# 安装optuna-dashboard
pip install optuna-dashboard
5.2 使用流程
- 第一步:在
study中指定storage。storage 文件默认存储在当前路径下。
import optuna
def objective(trial):
x = trial.suggest_float("x", -100, 100)
y = trial.suggest_categorical("y", [-1, 0, 1])
return x**2 + y
study = optuna.create_study(
storage="sqlite:///db.sqlite3", # 在这里指定存储的URL,db.sqlite3文件默认存储到当前目录下
study_name="quadratic-simple"
)
study.optimize(objective, n_trials=100)
print(f"Best value: {study.best_value} (params: {study.best_params})")
- 第二步:在命令行界面使用如下命令打开Optuna Dashboard。
optuna-dashboard sqlite:///db.sqlite3

6. 案例一:使用 Optuna 的 XGBoost 模型调参(Scikit-Learn框架)
- 导入必要的包。
import optuna
import xgboost as xgb
from catboost import CatBoostRegressor
import numpy as np
import pandas as pd
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
- 数据清洗。
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')
sub = pd.read_csv('./sample_submission.csv')
train.head()
columns = [col for col in train.columns.to_list() if col not in ['id','target']]
data=train[columns]
target=train['target']
- 构建 Optuna 的 XGBoost。
def objective(trial,data=data,target=target):
train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.15,random_state=42)
param = {
# 这个参数意味着在训练模型时使用GPU来加速训练过程
'tree_method':'gpu_hist',
# 表示在 [1e-3,1e1) 范围内,对数均匀分布取值
'lambda': trial.suggest_loguniform('lambda', 1e-3, 10.0),
'alpha': trial.suggest_loguniform('alpha', 1e-3, 10.0),
# 表示从 [0.3,0.4,0.5,0.6,0.7,0.8,0.9, 1.0] 取值
'colsample_bytree': trial.suggest_categorical('colsample_bytree', [0.3,0.4,0.5,0.6,0.7,0.8,0.9, 1.0]),
'subsample': trial.suggest_categorical('subsample', [0.4,0.5,0.6,0.7,0.8,1.0]),
'learning_rate': trial.suggest_categorical('learning_rate', [0.008,0.01,0.012,0.014,0.016,0.018, 0.02]),
'n_estimators': 1000,
'max_depth': trial.suggest_categorical('max_depth', [5,7,9,11,13,15,17]),
'random_state': trial.suggest_categorical('random_state', [2020]),
# 表示从 [1,300] 范围内,整数取值
'min_child_weight': trial.suggest_int('min_child_weight', 1, 300),
}
model = xgb.XGBRegressor(**param)
model.fit(train_x,train_y,eval_set=[(test_x,test_y)],early_stopping_rounds=100,verbose=False)
preds = model.predict(test_x)
rmse = mean_squared_error(test_y, preds,squared=False)
return rmse
- 运行,寻找最优的超参数组合。
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=30)
print('Number of finished trials:', len(study.trials))
print('Best trial:', study.best_trial.params)
7. 案例二:使用 Optuna 的 MLP 神经网络调参(Pytorch框架)👍
"""
coding:utf-8
* @Author:FHTT-Tian
* @name:Optuna_MLP.py
* @Time:2024/10/22 星期二 15:45
* @Description: 使用Optuna优化MLP示例。在这个例子中,使用PyTorch和MINST。优化了神经网络的结构和优化器的配置。并使用optuna-dashboard进行了可视化。
"""
import torch
import torchvision.datasets as dataset
import torchvision.transforms as transforms
from torch import nn, optim
from torch.utils.data import DataLoader
import optuna
from optuna.trial import TrialState
# 超参数设置
input_size = 28 * 28
hidden_size = 256
output_size = 10
batch_size = 128
learning_rate = 0.0001
total_epochs = 10
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
"""
第一步: 定义模型
"""
class Model(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.flatten = nn.Flatten()
# 线性层1,输入层和隐藏层之间的线性层
self.layer1 = nn.Linear(input_size, hidden_size)
# 激活函数
self.relu = nn.ReLU()
# 线性层2,隐藏层和输出层之间的线性层
self.layer2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 将输入的图片数据x展平成一维数据
x = self.flatten(x).to(device)
# 前向传播
x = self.layer1(x)
x = self.relu(x)
x = self.layer2(x)
return x
"""
第二步: 定义搜索空间和目标函数
* 加载数据集
* 定义超参数搜索空间
* 定义目标函数
* 添加剪枝
"""
def objective(trial):
# 第一步:加载数据集-构建训练数据和测试数据各自的Dataloader。
# 对图片进行预处理,将图片数据转换为张量,并进行归一化
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,), )])
# 下载数据集并预处理
train_dataset = dataset.MNIST(root="./MINST", train=True, download=True, transform=transform)
test_dataset = dataset.MNIST(root="./MINST", train=False, download=True, transform=transform)
# 构建dataloader,实现小批量的数据读取
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 第二步:定义超参数搜索空间
param = {
"hidden_size": trial.suggest_int("hidden_size", 32, 256),
"learning_rate": trial.suggest_float("learning_rate", 1e-5, 1e-1, log=True),
"optimizer_name": trial.suggest_categorical("optimizer", ['Adam', 'SGD'])
}
# 创建模型
model = Model(input_size, param["hidden_size"], output_size)
model.to(device)
# 选择优化器
if param["optimizer_name"] == "Adam":
optimizer = optim.Adam(model.parameters(), lr=param["learning_rate"])
elif param["optimizer_name"] == "SGD":
optimizer = optim.SGD(model.parameters(), lr=param["learning_rate"])
else:
raise NotImplementedError
# 定义损失
criterion = nn.CrossEntropyLoss()
# 训练模型
for epoch in range(total_epochs):
model.train()
for batch_idx, (data, label) in enumerate(train_loader):
# 前向传播
output = model(data).to(device)
loss = criterion(output, label.to(device))
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 验证模型
model.eval()
correct = 0
with torch.no_grad():
for data, label in test_loader:
output = model(data).to(device)
correct += torch.sum(output.argmax(1) == label.to(device)).item()
accuracy = correct / len(test_dataset)
# 第四步: 添加剪枝
# 报告每个epoch的验证准确率
trial.report(accuracy, epoch)
# 根据中间值处理修剪
if trial.should_prune():
raise optuna.exceptions.TrialPruned()
return accuracy
if __name__ == "__main__":
"""
第三步: 超参数优化
"""
# 创建study对象
study = optuna.create_study(
study_name="mlp_optuna",
storage="sqlite:///db.sqlite3",
direction='maximize',
sampler=optuna.samplers.TPESampler(),
pruner=optuna.pruners.MedianPruner()
)
study.optimize(objective, n_trials=10)
"""
第四步: 打印最佳参数
"""
pruned_trials = study.get_trials(deepcopy=False, states=[TrialState.PRUNED])
complete_trials = study.get_trials(deepcopy=False, states=[TrialState.COMPLETE])
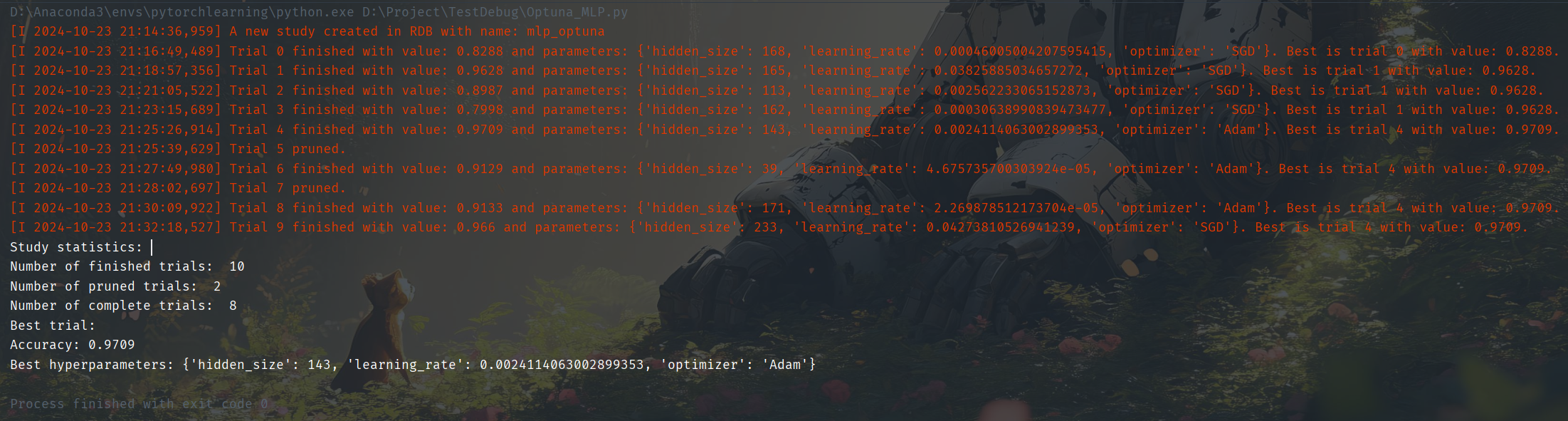
print("Study statistics: ")
print("Number of finished trials: ", len(study.trials))
print("Number of pruned trials: ", len(pruned_trials))
print("Number of complete trials: ", len(complete_trials))
print("Best trial:")
trial = study.best_trial
print(f"Accuracy: {trial.value}")
print("Best hyperparameters:", trial.params)
参考
😃😃😃


















 1538
1538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









