






前言
这一周提交了TGCN的修订稿和回复信,有一些心得体会,记录一下。
提示:以下是本篇文章正文内容,下面案例可供参考
一、如何回复审稿意见更能打动reviewer
1、在开始前要注意回复信的结构,层次分明的回复信会节省审稿人的很多精力、增加作者的印象分。(可以先跟老师要一个模板,老师经验丰富~)
(1)对每个审稿人的意见点对点回复,复制他们的comment,对应给出response;别忘了对审稿人的建议表示感谢
(2)简单介绍你对审稿意见的回复,并总结你所做的主要修改。一定要直接回答审稿人的问题,不要间接的让审稿人去你的revised里面去找
(3)感谢编辑和审稿人的辛苦付出
示例:
Response to reviewer1
Comment1:(第一位审稿人的第一个意见)
后面是评语的复制粘贴,如果审稿人的评语没有编号,可自行将意见分为多小节
reponse1:(对comment1的回复)
2、回复审稿意见时要注意的点
(1)事先和所有作者讨论审稿意见内容,并在提交前将整理好的文件发送给共同作者。仔细考虑他们给出的意见,这会大大提高回复信的质量,你代表他们回答。
(2)仔细阅读邮件中关于提交修订手稿的要求,注意截止日期。
(3)不要忽略任何一个评论。即使你觉得他们没理解你的论文或者实际上漏掉了什么,这至少意味着你的论文的关键读者还没有理解你所传达的内容,所以必须修改原稿,使之更清晰详实。同时可以回复“很抱歉没有阐释清楚这个问题,我们在XX部分已经增添了如下具体的解释......”。
(4)对问题的回答要具体,并解决所有的问题。一般来说,response letter是简要回复,revised manuscript是展开具体内容,但是如果每个comment只回答简要的几句话显然是不够的,要在后面引用revised manuscript的具体内容,让审稿人不用再去翻你的revised manuscript就能清楚知道你做了哪些修改。
(5)对所有的回复内容都要有事实依据,如果没有修改一定不能声称按照审稿人的意见修改了。
二、修改论文的学习记录
1.关于超参数的设置
(1)学习率和衰减率
什么是学习率,首先得弄明白神经网络参数更新的机制:梯度下降+反向传播。
参考资料:https://www.cnblogs.com/softzrp/p/6718909.html
如何设置学习率
学习率设置过小的时候,每步太小,下降速度太慢,可能要花很长的时间才会找到最小值。
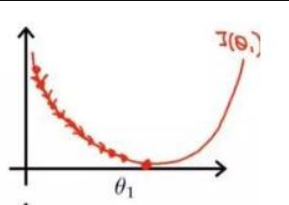
学习率过大过大的时候,每步太大,虽然收敛得速度很快,可能会像图中一样,跨过或忽略了最小值,导致一直来回震荡而无法收敛。
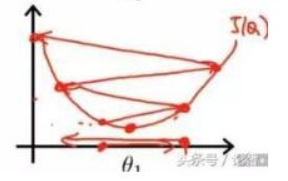
学习率衰减机制
最理想的学习率不是固定值,而是一个随着训练次数衰减的变化的值,也就是在训练初期,学习率比较大,随着训练的进行,学习率不断减小,直到模型收敛。
常用的衰减机制有: 固定策略的学习率衰减和自适应学习率衰减,其中固定学习率衰减包括分段衰减、逆时衰减、指数衰减等,自适应学习率衰减包括AdaGrad、 RMSprop、 AdaDelta等,可以针对每个参数设置不同的学习率。一般情况,两种策略会结合使用。
参考资料:衰减机制
学习率的调整办法分为以下三种:
(1)离散下降:每t轮学习,学习率减半;
(2)指数减缓:学习率按训练轮数增长指数差值递减,如;
(3)分数减缓:如原始学习率,学习率按照下式递减:,k为超参数,用来控制学习率减缓幅度,t为训练轮数;
大多数网络的学习率初始值设为0.01和0.001为宜。
大学习率的测试
文献来源:[2103.12682v1] How to decay your learning rate (arxiv.org)![]() https://arxiv.org/abs/2103.12682v1
https://arxiv.org/abs/2103.12682v1
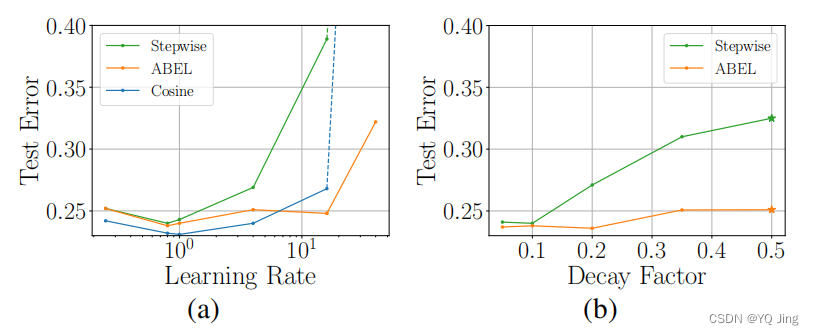
以ResNet-50为例在ImageNet上训练不同的学习速率和衰减因子,可以看出在学习率为1.0、衰减率为0.2的时候测试误差最小
2.联邦学习图像识别label的作用
联邦学习使中心能够在共同学习模型的同时在每个中心的数据。它避免了受CCPA、HIPAA和GDPR等法规限制的数据集中,并在各种应用中获得了普及。广泛使用的FL方法,如FedAvg,FedAdam,以及其他方法使用迭代优化算法来实现跨中心的联合模型训练。在每一轮中,本地中心执行几个步骤的随机梯度下降,然后中心将其当前的模型权重通信给一个要聚合的中心服务器。
当在经典的FL设置中训练一个分类器时,跨所有中心的数据集都用相同的标记标准进行标注。然而,在医疗保健等实际应用中,由于不同站点的专业知识或技术水平不同,不同临床中心的疾病诊断标准可能会有所不同。例如,当用脑成像诊断ADHD时,这些标签通常是在长期的行为研究中获得的。不同的中心可能遵循不同的诊断和统计手册,由于一些行为研究不能重复,因此很难要求中心使用统一的标准来重新标记数据。这导致了跨中心的不同标签空间。此外,标记标准最复杂的中心,其标签空间是未来预测的需要,由于标记的难度或成本,通常只有有限的标记样本。在来自所需标签空间的样本有限的情况下,如何利用常用的FL(如FedAvg)和来自不同标签空间中其他中心的数据,在所需的标签空间中联合学习FL模型,而不需要额外的特征交换和数据重新标记?
[2210.02042v1] FedMT: Federated Learning with Mixed-type Labels (arxiv.org)![]() https://arxiv.org/abs/2210.02042v1上文考虑了一个重要的但尚未被探索的FL设置,即混合类型标签的FL,不同的中心可以使用不同的标签标准,导致中心间标签空间的差异,并挑战现有的为经典设置设计的FL方法。为了有效地有效地训练混合型标签的模型,我们提出了一种理论指导和模型无关的方法,该方法可以利用这些标签空间之间的底层对应关系,并可以很容易地与各种FL方法结合,如FedAvg。我们提出了基于过参数化ReLU网络的收敛性分析。我们证明了该方法可以在标签投影中实现线性收敛,并证明了我们的新设置的参数对收敛速度的影响。在基准数据集和医学数据集上对该方法进行了评价,并验证了理论结果。
https://arxiv.org/abs/2210.02042v1上文考虑了一个重要的但尚未被探索的FL设置,即混合类型标签的FL,不同的中心可以使用不同的标签标准,导致中心间标签空间的差异,并挑战现有的为经典设置设计的FL方法。为了有效地有效地训练混合型标签的模型,我们提出了一种理论指导和模型无关的方法,该方法可以利用这些标签空间之间的底层对应关系,并可以很容易地与各种FL方法结合,如FedAvg。我们提出了基于过参数化ReLU网络的收敛性分析。我们证明了该方法可以在标签投影中实现线性收敛,并证明了我们的新设置的参数对收敛速度的影响。在基准数据集和医学数据集上对该方法进行了评价,并验证了理论结果。
实际应用:目标检测:labelimg
3、交替优化算法(块坐标下降)
块坐标下降法的应用场景是对于非凸问题进行优化。
块坐标下降法的解决思想是:在每次迭代的过程中,只针对一个变量进行优化求解,其余变量保持不变,然后交替求解。
下面举个例子
一、优化目标
联合无人机位置、网络资源分配优化能耗。
二、优化目标函数
因为优化变量相互耦合,求解的难度是很大的,因此需要对其进行处理,简化优化目标的求解。
三、算法设计思想
将原始的目标函数,分解为两个子问题,分别进行求解。对于每一个子问题的求解,都需要固定一部分参数。然后进行迭代求解,指导找到最佳的解。
下图是算法的伪代码
分析代码:
首先进行初始化,根据初始化条件进入迭代,这个内是初始化i=0时刻的位置,同时需要满意值阈值;
然后进入迭代,每次迭代,分解出来的两个子问题需要重新计算,然后与前一次计算出的值进行比较。对于第一个子问题是固定位置,优化频率,得到全局的最优解;对于第二个子问题是固定频率,优化位置,得到局部最优解。
判断迭代结束条件:当计算出的结果差值的绝对值小于满意值阈值,就代表结果是满足我们要求的次优解。















 6131
6131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









