







任何一个html和xml格式的文件都是树形结构,如下:
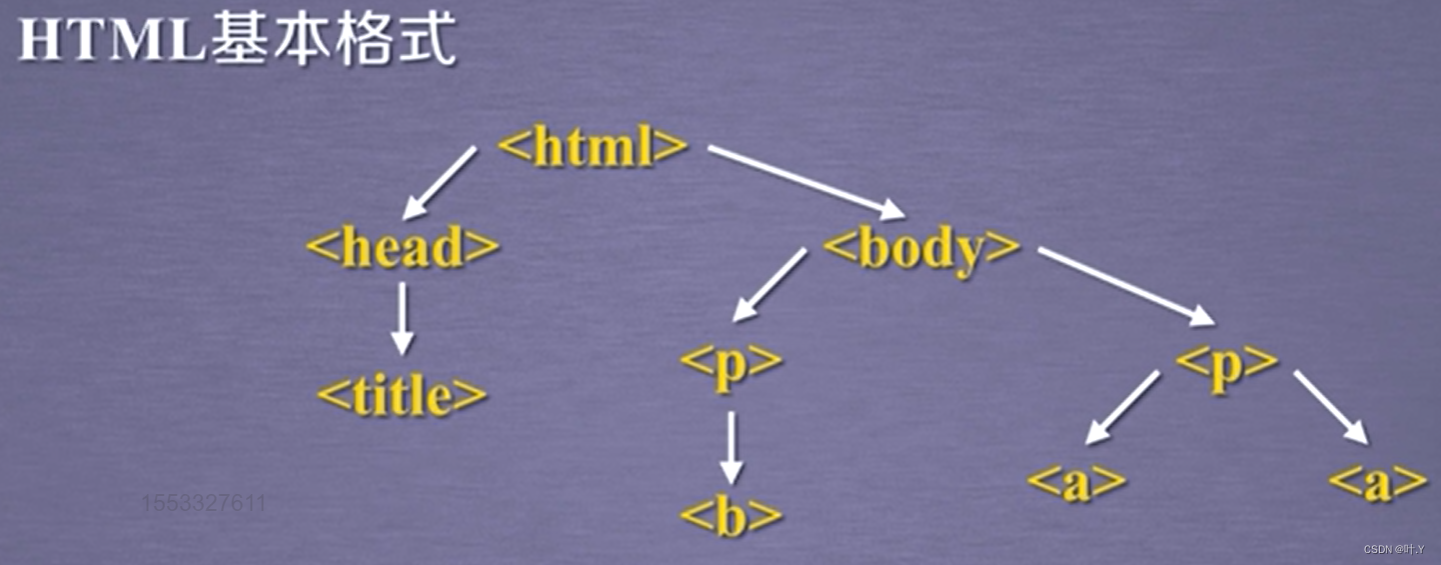
BeautifulSoup库是对标签树的功能的遍历集合,所以我们可以将所有的遍历功能分为上行遍历、下行遍历和平行遍历
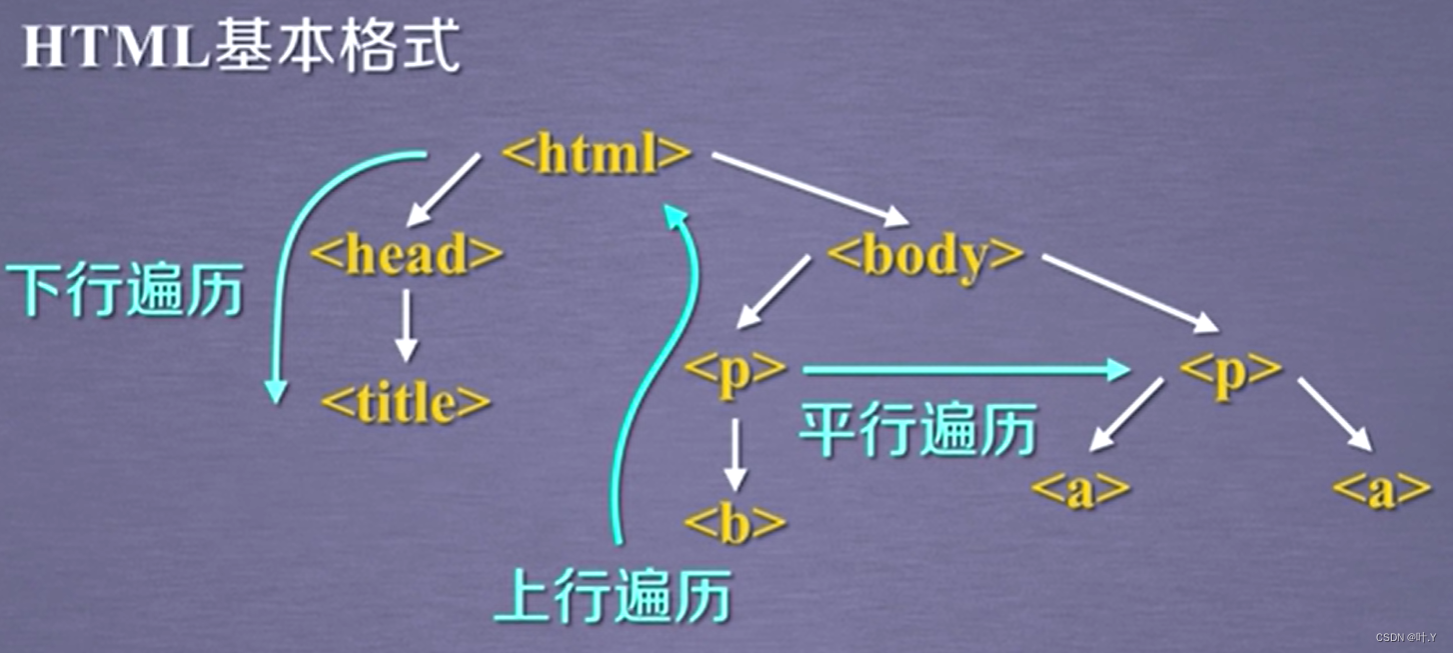
标签树的遍历属性
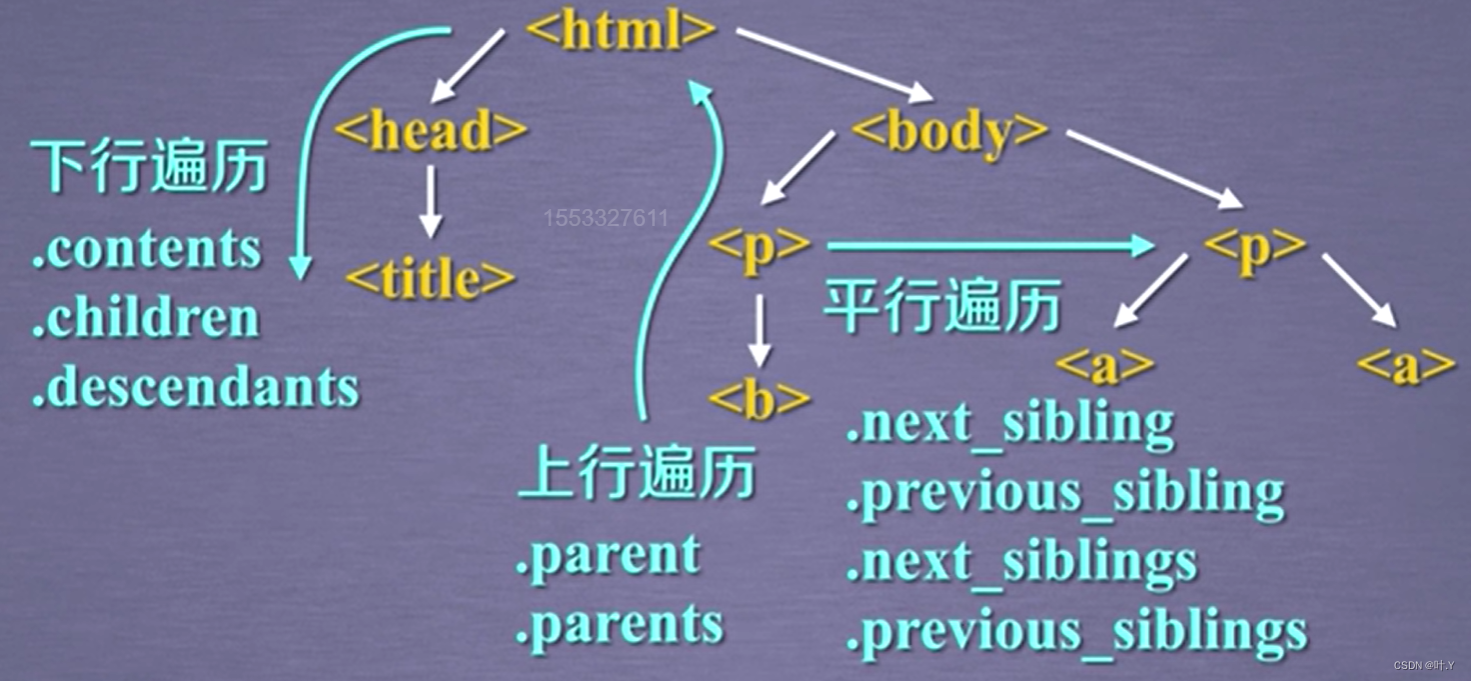
下行遍历
| 属性 | 说明 | |
| .contents | 子节点的列表,将<tag>所有儿子节点存入列表 | 只获得当前节点的下一层的节点信息 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 | |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 | 可以获得一个节点后续的所有节点的信息用于遍历 |
>>> import requests
>>> r = requests.get("http://python123.io/ws/demo.html")
>>> demo = r.text
>>> demo
'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p class="title"><b>The demo python introduces several python courses.</b></p>\r\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\r\n</body></html>'
>>>
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo, 'html.parser')
# 查看head标签
>>> soup.head
<head><title>This is a python demo page</title></head>
# 查看head标签的儿子节点,由于.contents返回的是列表,我们可以用列表的方式对其中的信息进行检索
>>> soup.head.contents
[<title>This is a python demo page</title>]
# 查看body标签的contents信息
# 对于一个标签的儿子节点,并不仅仅包括标签节点,也包括字符串节点,比如\n的回车也是body标签的儿子节点类型
>>> soup.body.contents
['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\n']
# 儿子节点的数量
>>> len(soup.body.contents)
5
# 检索其中的第二个元素
>>> soup.body.contents[1]
<p class="title"><b>The demo python introduces several python courses.</b></p>
# 遍历儿子节点
>>> for son in soup.body.children:
print(son)
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
# 遍历子孙节点
>>> for child in soup.body.descendants:
print(child)
<p class="title"><b>The demo python introduces several python courses.</b></p>
<b>The demo python introduces several python courses.</b>
The demo python introduces several python courses.
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
Basic Python
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
Advanced Python
.
>>> 上行遍历
| 属性 | 说明 | |
| .parent | 节点的父亲标签 | |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 | 不仅包含当前节点的直接父亲,也包含父亲的父亲,甚至是更先辈的内容 |
>>> import requests
>>> r = requests.get("http://python123.io/ws/demo.html")
>>> demo = r.text
>>> demo
'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p class="title"><b>The demo python introduces several python courses.</b></p>\r\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\r\n</body></html>'
>>>
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo, 'html.parser')
# 查看title标签的父亲
>>> soup.title.parent
<head><title>This is a python demo page</title></head>
# 查看html标签的父亲,由于html是html文本的最高级标签,所以它的父亲是它自己
>>> soup.html.parent
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
</body></html>
# soup本身是一种特殊的标签,它的父亲是空的
>>> soup.parent
# 对soup的a标签所有的先辈的名字进行打印,在遍历一个标签的所有先辈标签时,会遍历到soup本身,而soup的先辈并不存在.name信息,所以要先做区分
>>> for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
p
body
html
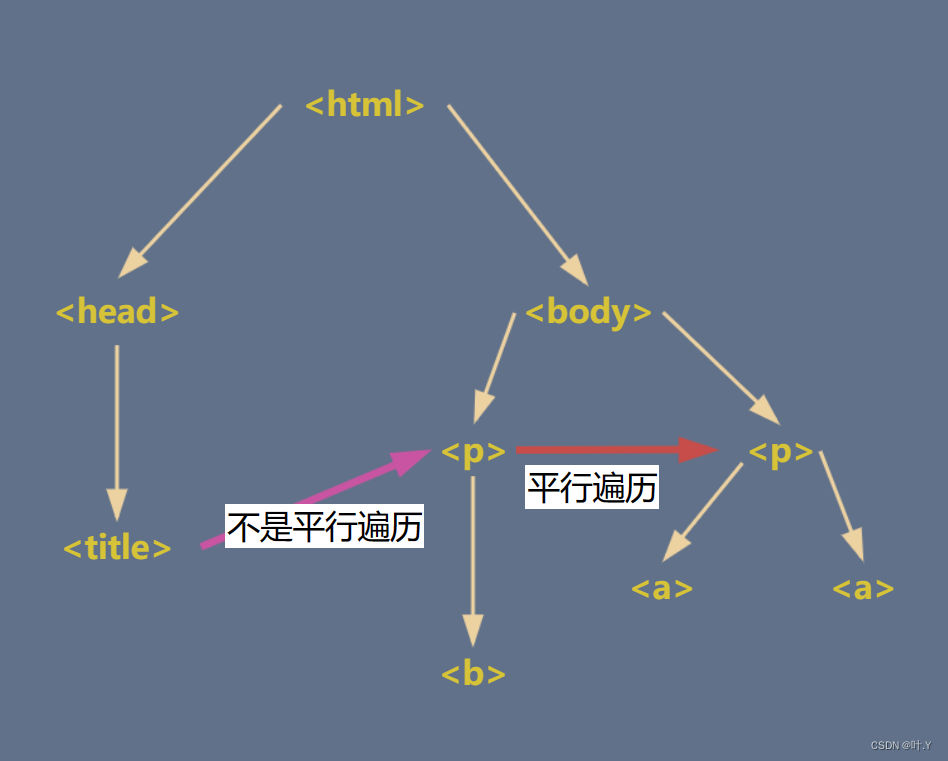
[document]平行遍历
| 属性 | 说明 |
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
>>> import requests
>>> r = requests.get("http://python123.io/ws/demo.html")
>>> demo = r.text
>>> demo
'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p class="title"><b>The demo python introduces several python courses.</b></p>\r\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\r\n</body></html>'
>>>
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo, 'html.parser')
# 查看a标签的下一个标签,在标签树中,尽管树形结构采用的是标签的形式来组织,但标签之间的NavigableString也构成了标签树的节点,也就是说任何一个节点它的平行标签,它的父亲、它的儿子标签是可能存在NavigableString类型的
>>> soup.a.next_sibling
' and '
# 查看a标签的下一个标签的下一个标签
>>> soup.a.next_sibling.next_sibling
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
# 查看当前a标签的前一个平行节点
>>> soup.a.previous_sibling
'Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n'
# 查看a标签的前一个标签的前一个标签,没有输出,说明是空信息
>>> soup.a.previous_sibling.previous_sibling
# 查看a标签的父亲节点
>>> soup.a.parent
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
# 查看a标签的后续节点
>>> for next_sibling in soup.a.next_siblings:
print(next_sibling)
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
.
>>>
# 查看a标签的前续节点
>>> for previous_sibling in soup.a.previous_siblings:
print(previous_sibling)
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
>>> 














 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









