






目录
TSP是什么
TSP问题是指旅行商问题(Traveling Salesman Problem),它是一个著名的组合优化问题。在TSP问题中,假设有一个旅行商人要拜访n个城市,并且每个城市之间的距离已知。问题的目标是找到一条回路(即遍历每个城市一次,并最终回到起始城市),使得总旅行距离最短。
TSP问题可以用图论的方式来描述,其中每个城市表示图中的一个节点,城市之间的距离表示节点之间的边,而找到的回路表示从一个节点出发,经过所有其他节点后再回到起始节点的路径。
TSP问题是一个NP-hard问题,这意味着在一般情况下,随着城市数量的增加,找到最优解的计算复杂性急剧增加,很难在多项式时间内求解。因此,对于大规模的TSP问题,常常使用各种启发式算法、近似算法或元启发式算法来找到接近最优解的解决方案。
关于TSP问题的研究有很多,自20世纪50年代首次提出以来,它一直是组合优化领域的重要研究课题。许多学者在不同的背景和应用领域都对TSP问题进行了深入研究,尝试提出更高效、更精确的算法,并将其应用于实际问题,如物流规划、芯片制造、电路板布线、旅游路线规划等领域。
NP、NP-complete、NP-hard到底什么意思
NP(Nondeterministic Polynomial time)是一个算法复杂性类别,指的是在多项式时间内可以验证一个解的正确性。这意味着如果一个问题的解是"是"的话,我们可以在多项式时间内验证它是正确的。但是,如果解是"否"的话,我们不能在多项式时间内证明它是错误的。
NP Complete(NPC)是一种特殊的问题集合,它同时满足以下两个条件:
- 属于NP类,即可以在多项式时间内验证解的正确性。
- 任何其他NP问题都可以在多项式时间内归约到这个问题。这意味着,如果我们可以在多项式时间内解决一个NPC问题,那么我们也可以在多项式时间内解决所有其他NP问题。
NP Hard(Nondeterministic Polynomial hard)是另一种算法复杂性类别,它满足以下条件:
- 任何NP问题都可以在多项式时间内归约到它。与NPC不同的是,NP Hard问题不要求在多项式时间内验证解的正确性,只要其他NP问题可以在多项式时间内归约到该问题即可。
简而言之:
- NP问题是可以在多项式时间内验证解的问题。
- NP Complete问题是最难的NP问题,其他所有的NP问题都可以在多项式时间内归约到它。
- NP Hard问题是非常困难的问题,不要求在多项式时间内验证解的正确性,但其他所有的NP问题都可以在多项式时间内归约到它。
例子说明:
- 旅行商问题(TSP)是一个NPC问题。它是NP问题,因为可以在多项式时间内验证给定的路径是否访问了每个城市且总距离小于等于某个值。同时,其他所有的NP问题,如背包问题、图着色问题等,都可以在多项式时间内归约到TSP问题来解决。
- 哈密尔顿回路问题(Hamiltonian Cycle Problem)是一个NP Hard问题。虽然它不一定是NP问题,但其他所有的NP问题都可以在多项式时间内归约到哈密尔顿回路问题,因此它是NP Hard问题。
需要注意的是,NPC问题和NP Hard问题之间的区别在于是否属于NP类。NPC问题是NP问题,而NP Hard问题可能不是
相关的问题:
-
旅行推销员问题(Travelling Purchaser Problem,TPP):类似于TSP,但不同之处在于推销员需要在每个城市购买一定数量的商品,而不仅仅是访问每个城市。问题的目标是找到一条最短路径,以便推销员能够访问每个城市并购买所需商品,然后回到出发城市。
-
车辆路径问题(Vehicle Routing Problem,VRP):在VRP中,有一组客户需要从一个或多个中心点配送货物,一组车辆被用于在客户之间运输货物。问题的目标是找到最优的车辆路径,以满足所有客户需求,同时最小化总体运输成本(例如总行驶距离或运输时间)。
-
团体旅行商问题(Group Traveling Salesman Problem,GTSP):GTSP是TSP的一种变体,其中城市被分为若干组,旅行商需要选择并访问每个组中的一个或多个城市,然后回到起始城市。目标是找到最短路径,使得每个组中的城市都被访问到。
-
中国邮递员问题(Chinese Postman Problem,CPP):在CPP中,要求邮递员遍历一个无向图的所有边至少一次,并且回到出发点。问题的目标是找到最短路径,使得每条边都被遍历到。
-
职工调度问题(Job Scheduling Problem):在这类问题中,需要将一组任务分配给一组职工,每个任务都有特定的执行时间和截止日期。目标是找到一种调度方式,使得所有任务都能按时完成,并最小化总体完成时间或最大延迟时间。
-
装载问题(Bin Packing Problem):装载问题涉及将一组物品放入一些容器中,每个物品有自己的体积,容器有一定的容量限制。目标是找到一种装载方式,使得所需容器数量最少。
常见算法
-
旅行商问题(TSP):
- 穷举法(Brute Force):虽然效率低下,但对小规模问题可以找到确切最优解。
- 近似算法:
- 最近邻算法(Nearest Neighbor):从一个起始城市开始,每次选择最近的未访问城市,形成一条路径。
- 最小生成树算法(Minimum Spanning Tree):构建城市之间的最小生成树,并对其进行修改以形成回路。
- 遗传算法(Genetic Algorithm):模拟生物进化过程,通过遗传、交叉和变异等操作搜索TSP的近似最优解。
- 蚁群算法(Ant Colony Optimization):模拟蚂蚁寻找食物的行为,利用信息素引导蚂蚁在城市间搜索路径。
-
旅行推销员问题(Travelling Purchaser Problem,TPP):
- 该问题的解决方法可以从TSP和多背包问题(Multiple Knapsack Problem)中借鉴,结合路径规划和物品购买决策。
-
车辆路径问题(Vehicle Routing Problem,VRP):
- 分支定界法(Branch and Bound):将问题划分为子问题,并在搜索过程中剪枝,找到最优解。
- 遗传算法(Genetic Algorithm):用于求解VRP的启发式算法,通过遗传操作优化车辆路径。
- 粒子群算法(Particle Swarm Optimization):模拟鸟群觅食行为,优化车辆路径规划。
-
团体旅行商问题(Group Traveling Salesman Problem,GTSP):
- GTSP是TSP的一种扩展,可以使用TSP的解决算法,并结合额外的处理步骤来处理城市分组的问题。
-
中国邮递员问题(Chinese Postman Problem,CPP):
- 对于连通图,CPP可以通过求解欧拉回路(Eulerian Circuit)来得到最优解。
- 如果图不是连通的,则可以将其拆分为连通分支,并对每个连通分支求解CPP。
-
职工调度问题(Job Scheduling Problem):
- 贪心算法(Greedy Algorithm):按照某种优先级规则选择任务进行调度。
- 动态规划(Dynamic Programming):对于一些特定的调度问题,可以使用动态规划来找到最优解。
- 遗传算法(Genetic Algorithm):通过进化算法搜索任务调度的近似最优解。
-
装载问题(Bin Packing Problem):
- 贪心算法(Greedy Algorithm):基于某些优先级规则将物品逐个放入容器中。
- 动态规划(Dynamic Programming):对于一些特殊情况的装载问题,可以使用动态规划算法解决。
强化学习在TSP的应用
强化学习在解决旅行商问题(TSP)方面,主要应用于通过智能体的学习来寻找近似最优解。以下是一些在TSP中应用强化学习的算法、对应论文以及简要描述:
1.Q-learning算法在TSP中的应用:
论文: "Solving Travelling Salesman Problem with Q-Learning"(作者:Abhinav Agarwalla, 2018)
描述:该论文提出了使用Q-learning算法来解决TSP问题。在这种方法中,TSP的问题空间被建模成一个有向图,智能体通过不断探索并学习每个状态之间的Q值(即行动-状态价值函数),来选择下一步要访问的城市。在训练过程中,智能体逐渐优化其策略,以实现更短的路径。
2. 深度强化学习在TSP中的应用:
论文:"Learning to Solve Combinatorial Optimization Problems with Reinforcement Learning"(作者:Joshi, Harsh, et al., 2019)
描述:该论文探讨了使用深度强化学习解决组合优化问题,其中TSP作为一个示例。它引入了一个基于神经网络的学习架构,称为Pointer Network,来处理TSP问题。这个网络能够学习在城市之间的指针生成概率,从而有效地生成一条旅行路径。
3.深度强化学习与注意力机制在TSP中的应用:
论文:"Attention, Learn to Solve Routing Problems!"(作者:Kool, Wouter, 2019)
描述:该论文提出了一种基于深度强化学习和注意力机制的方法来解决TSP问题。注意力机制有助于在搜索过程中更好地处理城市之间的依赖关系。该算法通过迭代训练智能体,使其能够在TSP问题中更加高效地学习,找到较好的解决方案。
code talks 01
# DQN Reinforcement Learning Algorithm
def dqn_algorithm(env, model, num_episodes=1000, epsilon=0.1, gamma=0.9, batch_size=32):
memory = []
optimizer = optim.Adam(model.parameters())
criterion = nn.MSELoss()
statistics_rewards = []
for episode in range(num_episodes):
state = env.reset()
state = torch.eye(env.num_locations)[state].unsqueeze(0)
done = False
total_reward = 0
while not done:
if random.uniform(0, 1) < epsilon:
action = random.choice(list(env.unvisited_locations))
else:
with torch.no_grad():
q_values = model(state)
q_values.numpy()[0][env.visited_locations] = -np.inf
action = np.argmax(q_values)
# action = torch.argmax(q_values).item()
next_state, reward, done = env.step(int(action))
next_state = torch.eye(env.num_locations)[next_state].unsqueeze(0)
total_reward += reward
memory.append((state, action, reward, next_state, done))
state = next_state
if len(memory) > batch_size:
minibatch = random.sample(memory, batch_size)
states, actions, rewards, next_states, dones = zip(*minibatch)
states = torch.cat(states)
actions = torch.tensor(actions).unsqueeze(1)
rewards = torch.tensor(rewards).float()
next_states = torch.cat(next_states)
dones = torch.tensor(dones).float()
q_values = model(states)
next_q_values = model(next_states)
max_next_q_values = torch.max(next_q_values, dim=1).values
targets = rewards + gamma * max_next_q_values * (1 - dones)
targets = targets.unsqueeze(1)
q_values = q_values.gather(1, actions)
loss = criterion(q_values, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
statistics_rewards.append(total_reward)
plt.figure(figsize=(15, 3))
plt.title("Rewards over training")
plt.plot(statistics_rewards)
plt.show()
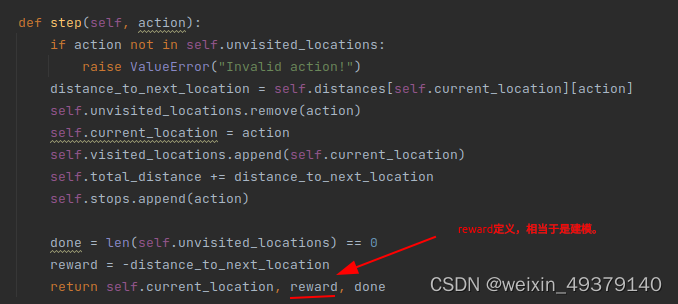
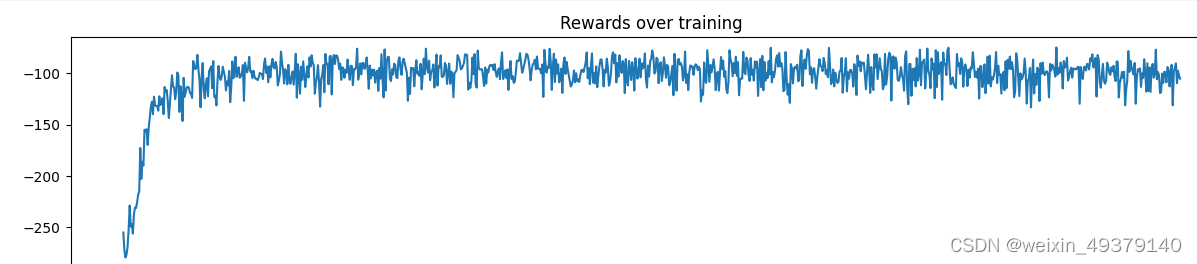
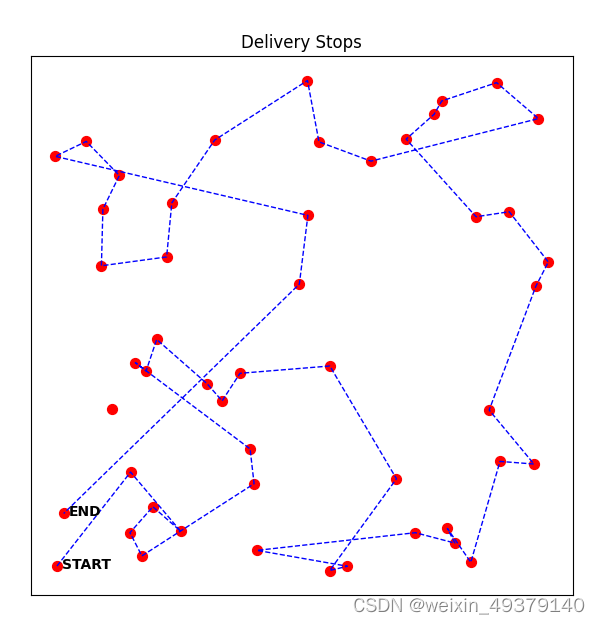
PS:Only the implementation at the code level has been completed, without debugging and performance comparisons. Welcome to discuss and exchange ideas.
reference:Solving the Traveling Salesman Problem with Reinforcement Learning | Eki.Lab















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









