







我自己的原文哦~ https://blog.51cto.com/whaosoft/11935763
一、手机表面缺陷检测
随着智能制造产业的升级和改造,智能手机作为人们生活的必需品,它的“智”不仅仅在于产品功能、性能方面的创新,更在于生产制造过程的智能化。
智能手机生产共有80多道工序,每一个工序都需要进行检测,检测的标准各不相同。为提升产品品质,降低不良率,达到用户满意度,检测作为手机生产的最后一道工序,是产品品质的“守门员”,也是手机厂商们关注的焦点。深度学习技术 解锁智能手机“智”造之路
手机在生产时候不可避免的会有一些缺陷,例如:
· 盖板玻璃上有划伤、压伤、破损、边缘毛刺等,产品尺寸公差大等;
· 手机电池表面会出现漏气、焊点、压伤等;
· PCB元器件有错、漏、反、浮高等问题;
· 金属部件表面脏污、裂纹、划伤、刮伤、气泡等;
· 摄像模组上有异物、污染、刮伤、白点以及高度差等;
· 在成品机组装上,出现缺件、错件、螺钉浮高等等。

这些缺陷不仅会引发一系列的返工、售后问题,还会影响消费者对产品的使用感受,对产品的口碑也会造成一定的影响。
伴随着人口红利的逐渐消失,以及传统机器视觉的“僵态化”检测,局限性问题日益突出,已无法应对终端产品的频繁迭代。
深度学习技术,通过深度提取图像瑕疵特征,突破传统机器视觉逻辑简单、难以分析无规律图像的瓶颈,持续有效地提高了质检的准确性。
对于产品线的不断更迭变换,用户无需更改或调整设备机构,只需通过软件选择相应前期调试好的参数即可,如此一来,便大幅降低了用户更换不同产品时的设备调试时间。
在检测过程中,可实现不同尺寸、型号手机玻璃面、后盖、侧面、圆弧面的全方位检查,快速、精准地检测出划痕、碰伤、脏污、边缘银边、漏光等缺陷,省去了人工干预的环节。
遇到严重缺陷,还可根据设定在线报警或者停机,以防出现故障导致全线停产。
检测完成后,可在线将缺陷分类、存储、输出报表,增加了数据的可追溯性,管理者也能在第一时间获取产品缺陷分布和良品率,并根据一手数据及时优化流程与工艺。
毫无疑问,无论是在产品生产检验作业中,或是进行品质管理,实现精益化生产上,依靠深度学习技术的缺陷检测系统将是企业最为坚实的力量。
AI深度学习在手机“智”造应用
场景一
手机镜片外观瑕疵缺陷检测

检测背景
手机镜片制造商,需要对出货前的产品进行外观检测,包括披风、蚀刻不良、异色、字体不良、崩边、边透沙眼、划伤、晶点、亮点等不良。
采用深度学习技术,可准确的检测出不良,以此来替代人工繁琐的检测,提升效率的同时并能管控好品质。
检测需求
披风检测、蚀刻检测、异色检测、字体检测、崩边检测、边透沙眼、划伤检测、晶点检测、亮点检测。
检测方案
通过机器视觉系统,检测产品制造中出现的划痕、脏污、异物等外观缺陷和其他异常,检测装配错误、表面缺陷、损坏的工件和缺失的功能,可确定对象的方向、形状、位置,还可识别功能。
检测效果
① 崩边检测

② 边透沙眼

③ 划伤检测

④ 晶点检测

⑤ 亮点检测

⑥ 披锋检测

⑦ 蚀刻检测

⑧ 字体检测

场景二
手机玻璃盖外观缺陷检测

检测背景
手机、平板电子产品在组装完成后,为保证出货前的产品质量,需对手机的玻璃面、后盖、侧面、圆弧面进行全方位的检查,检测内容包括划伤、缺口、点状异物(如颗粒、玻璃珠、气泡等)、压痕、凹凸痕、锯齿状、脏污、电镀掉漆、异色等。使屏幕依次显示不同的纯色背景,检测屏幕亮点、暗点、花屏、背光不良等缺陷。
检测效果
① 正面检测图片

② R角检测图片

③ 侧面检测图片

场景三
手机中板外观缺陷检测

检测难点
· 检测崩边缺失、断裂、变形,发生不良的位置未知且不固定,精准的搜索并检测判定是关键。
· 检测是否漏攻牙,由于牙孔内螺纹与CCD不在一个平行的平面,加上牙孔较小且受深度干扰,难度大。
· 断柱检测,由于辅助定位柱的Z向高度,与CCD不在一个平行的平面,是一个难点。
检测效果
① 牙孔检测效果

② 断柱检测效果

③ 崩边缺失检测效果

场景四
手机外壳Logo缺陷检测

场景缺陷
碰压伤 、刮伤、料线、针孔、麻点、白点、缺口、凸包、研磨痕、拱起、变形
检测难点
· 手机LOGO属于高亮、镜面金属材质;
· 细微的划伤、凹坑在传统光学下,会被强光遮掩掉;
检测效果
①划痕检测

② 凹凸点检测

二、工业缺陷检测1~
这里介绍算法在图像处理中的应用,同时还介绍了常用的图像处理算法和现有可用的视觉检测软件库。文章旨在帮助读者更好地了解算法在图像处理中的应用,提高图像处理的效果和效率。
算法(预处理算法、检测算法)
常用的图像处理算法:
1、图像变换:(空域与频域、几何变换、色度变换、尺度变换)
几何变换:图像平移、旋转、镜像、转置;
尺度变换:图像缩放、插值算法(最近邻插值、线性插值、双三次插值);
空域与频域间变换:由于图像阵列很大,直接在空间域中进行处理,涉及计算量很大。因此,有时候需要将空间域变换到频域进行处理。例如:傅立叶变换、沃尔什变换、离散余弦变换等间接处理技术,将空间域的处理转换为频域处理,不仅可减少计算量,而且可获得更有效的处理(如傅立叶变换可在频域中进行数字滤波处理)。
2、图像增强:
图像增强不考虑图像降质的原因,突出图像中所感兴趣的部分。如强化图像高频分量,可使图像中物体轮廓清晰,细节明显;如强化低频分量可减少图像中噪声影响。
灰度变换增强(线性灰度变换、分段线性灰度变换、非线性灰度变换);
直方图增强(直方图统计、直方图均衡化);
图像平滑/降噪(邻域平均法、加权平均法、中值滤波、非线性均值滤波、高斯滤波、双边滤波);
图像(边缘)锐化:梯度锐化,Roberts算子、Laplace算子、Sobel算子等;
3、纹理分析(取骨架、连通性);
4、图像分割:
图像分割是将图像中有意义的特征部分提取出来,其有意义的特征有图像中的边缘、区域等,这是进一步进行图像识别、分析和理解的基础。
(1)阈值分割(固定阈值分割、最优/OTSU阈值分割、自适应阈值分割);
(2)基于边界分割(Canny边缘检测、轮廓提取、边界跟踪);
(3)Hough变换(直线检测、圆检测);
(4)基于区域分割(区域生长、区域归并与分裂、聚类分割);
(5)色彩分割;
(6)分水岭分割;
5、图像特征:
(1)几何特征(位置与方向、周长、面积、长轴与短轴、距离(欧式距离、街区距离、棋盘距离));
(2)形状特征(几何形态分析(Blob分析):矩形度、圆形度、不变矩、偏心率、多边形描述、曲线描述);
(3)幅值特征(矩、投影);
(4)直方图特征(统计特征):均值、方差、能量、熵、L1范数、L2范数等;直方图特征方法计算简单、具有平移和旋转不变性、对颜色像素的精确空间分布不敏感等,在表面检测、缺陷识别有不少应用。
(5)颜色特征(颜色直方图、颜色矩)
(6)局部二值模式( LBP)特征:LBP对诸如光照变化等造成的图像灰度变化具有较强的鲁棒性,在表面缺陷检测、指纹识别、光学字符识别、人脸识别及车牌识别等领域有所应用。由于LBP 计算简单,也可以用于实时检测。
6、图像/模板匹配:
轮廓匹配、归一化积相关灰度匹配、不变矩匹配、最小均方误差匹配
7、色彩分析
色度、色密度、光谱、颜色直方图、自动白平衡
8、图像数据编码压缩和传输
图像编码压缩技术可减少描述图像的数据量(即比特数),以便节省图像传输、处理时间和减少所占用的存储器容量。压缩可以在不失真的前提下获得,也可以在允许的失真条件下进行。编码是压缩技术中最重要的方法,它在图像处理技术中是发展最早且比较成熟的技术。
9、表面缺陷目标识别算法:
传统方法:贝叶斯分类、K最近邻(KNN)、人工神经网络(ANN)、支持向量机(SVM)、K-means等;
10、图像分类(识别)
图像分类(识别)属于模式识别的范畴,其主要内容是图像经过某些预处理(增强、复原、压缩)后,进行图像分割和特征提取,从而进行判决分类。
11、图像复原
图像复原要求对图像降质的原因有一定的了解,一般讲应根据降质过程建立“降质模型”,再采用某种滤波方法,恢复或重建原来的图像。
现有可用的视觉检测软件库
1、可二次开发的视觉系统:Labview、DVT、Halcon、OpenCV等。
2、常用的视觉检测软件/库
视觉开发软件工具 Halcon、VisionPro、LabView、OpenCV, 还有eVision、Mil、Sapera等。
(一)、Halcon:底层功能算法多,运算性能快,功能齐全,容易上手,开发项目周期短。非开源项目,商用收费,价格较贵。
Halcon:Halcon是德国MVtec公司开发的一套完善的标准的机器视觉算法包,拥有应用广泛的机器视觉集成开发环境。它是一套image processing library,由一千多个各自独立的函数,以及底层的数据管理核心构成。其中包含了各类滤波,色彩以及几何,数学转换,型态学计算分析,校正,分类辨识,形状搜寻等等基本的几何以及影像计算功能。整个函数库可以用C,C++,C#,Visual basic和Delphi等多种普通编程语言访问。Halcon为大量的图像获取设备提供接口,保证了硬件的独立性。
(二)OpenCV:功能算法相对较多(比Halcon少),开源,可用于商用,开发周期较长(比Halcon长),有些算法要自己写。
OpenCV是一个基于(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows和Mac OS操作系统上。其核心轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,实现了图像处理和计算机视觉方面的很多通用算法。OpenCV用C++语言编写,它的主要接口也是C++语言。该库也有大量的Python, Java and MATLAB/OCTAVE的接口,如今也提供对于C#, Ruby的支持。OpenCV可以在 Windows, Android, Maemo, FreeBSD, OpenBSD, iOS,Linux 和Mac OS等平台上运行。
OpenCV出身:OpenCV是Intel开源计算机视觉库。其核心由一系列 C 函数和少量 C++ 类构成,实现了图像处理和计算机视觉方面的很多通用算法。OpenCV 的特点拥有包括300多个C函数的跨平台的中、高层 API 跨平台:Windows, Linux;免费(FREE):无论对非商业应用和商业应用;速度快;使用方便。
OpenCV具有以下的特征:(1)开源计算机视觉采用C/C++编写。(2)使用目的是开发实时应用程序。(3)独立与操作系统、硬件和图形管理器。(4)具有通用的图象/视频载入、保存和获取模块。(5)具有底层和高层的应用开发包。
应用OpenCV能够实现以下功能:(1)对图象数据的操作,包括分配、释放、复制和转换数据。(2)对图象和视频的输入输出,指文件和摄像头作为输入,图象和视频文件作为输出。(3)具有对距陈和向量的操作以及线性代数的算法程序,包括距阵、解方程、特征值以及奇异值。(4)可对各种动态数据结构,如列表、队列、集合、树和图等进行操作。(5)具有基本的数字图象处理能力,如可进行滤波、边缘检测、角点检测、采样与差值、色彩转换、形态操作、直方图和图象金字塔等操作。
(6)可对各种结构进行分析,包括连接部件分析、轮廓处理、距离变换、各种距的计算、模板匹配、Hongh变换、多边形逼近、直线拟合、椭圆拟合和Delaunay三角划分等。(7)对摄像头的定标,包括发现与跟踪定标模式、定标、基本矩阵估计、齐次矩阵估计和立体对应。(8)对运动的分析,如对光流、运动分割和跟踪的分析。(9)对目标的识别,可采用特征法和隐马尔科夫模型(HMM)法。(10)具有基本的GUI功能,包括图像与视频显示、键盘和鼠标事件处理及滚动条等。(11)可对图像进行标注,如对线、二次曲线和多边形进行标注,还可以书写文字(目前之支持中文)。
(三)VisionPro
VisionPro是美国康耐视Cognex公司提供全套视觉解决方案。VisionPro提供多种开发工具拖放式界面、简单指令码和编程方式等,全面支持所有模式的开发。用户利用VisionPro QuickBuild™可以无需编程配置读取、选择并优化视觉工具,决定产品是否合格。用户也可以利用C++、C#、VB及.NET开发管理应用程序。Vision Pro提供的.NET程序接口允许用户采用面向对象的高级语言编程访问所有工具,以高效开发客户的专用视觉方案。
(四)LabView
LabView是一种程序开发环境,由美国国 家仪器(NI)公司研制开发,使用的是图形化编辑语言G编写程序,产生的程序是框图的形式。LabView软件是NI设计平台的核心,也是开发测量或控制系统的理想选择。LabView开发环境集成了工程师和科学家快速构建各种应用所需的所有工具,旨在帮助工程师和科学家解决问题、提高生产力和不断创新。
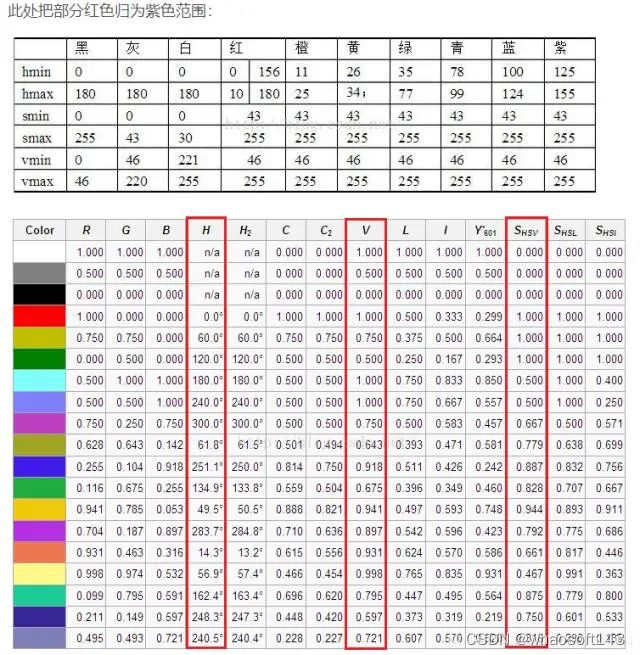
HSV颜色识别-HSV基本颜色分量范围
一般对颜色空间的图像进行有效处理都是在HSV空间进行的,然后对于基本色中对应的HSV分量需要给定一个严格的范围,下面是通过实验计算的模糊范围(准确的范围在网上都没有给出)。
H: 0 — 180
S: 0 — 255
V: 0 — 255
HSV(色相/饱和度/明度)颜色空间是表示类似于RGB颜色模型的颜色空间的模型。根据色相通道(Channel)对颜色类型进行建模,因此在需要根据颜色对对象进行分割的图像处理任务中非常有用。饱和度的变化代表颜色成分的多少。明度通道描述颜色的亮度。
三、用深度学习实现异常检测/缺陷检测
创建异常检测模型,实现生产线上异常检测过程的自动化。在选择数据集来训练和测试模型之后,我们能够成功地检测出86%到90%的异常。
异常是指偏离预期的事件或项目。与标准事件的频率相比,异常事件的频率较低。产品中可能出现的异常通常是随机的,例如颜色或纹理的变化、划痕、错位、缺件或比例错误。
异常检测使我们能够从生产流程中修复或消除那些处于不良状态的部件。因此,由于避免生产和销售有缺陷的产品,制造成本降低了。在工厂中,异常检测由于其特点而成为质量控制系统的一个有用工具,对机器学习工程师来说是一个巨大的挑战。
不推荐使用监督学习,因为:在异常检测中需要内在特征,并且需要在完整数据集(训练/验证)中使用少量的异常。另一方面,图像比较可能是一个可行的解决方案,但标准图像处理多个变量,如光线、物体位置、到物体的距离等,它不允许与标准图像进行像素对像素的比较。在异常检测中,像素到像素的比较是不可或缺的。
除了最后的条件外,我们的建议包括使用合成数据作为增加训练数据集的方法,我们选择了两种不同的合成数据,随机合成数据和相似异常合成数据。(详见数据部分)
这个项目的目标是使用无监督学习和合成数据作为数据增强方法来分类异常 — 非异常。
背景研究
异常检测与金融和检测“银行欺诈、医疗问题、结构缺陷、设备故障”有关(Flovik等,2018年)。该项目的重点是利用图像数据集进行异常检测。它的应用是在生产线上。在项目开始时,我们熟悉了自动编码器在异常检测中的功能和架构。作为数据计划的一部分,我们研究了包括合成噪声图像和真实噪声图像的重要性(Dwibedi et al, 2017)。
数据计划是这个项目的重要组成部分。选择一个数据集,有足够的原始图像和足够的真实噪声的图像。同时使用合成图像和真实图像。在处理真实图像时,这些数据需要对目标有全覆盖,但是在尺度和视角方面无法完全获得。“……要区分这些实例需要数据集对对象的视角和尺度有很好的覆盖”(Dwibedi et al, 2017)。合成数据的使用允许“实例和视角的良好覆盖”(Dwibedi et al, 2017)。合成图像数据集的创建,包括合成渲染的场景和对象,是通过使用Flip Library完成的,这是一个由LinkedAI创建的开源python库。“剪切,粘贴和学习:非常简单的合成实例检测”,通过这些数据的训练和评估表明,使用合成数据集的训练在结果上与在真实图像数据集上的训练具有可比性。
自动编码器体系结构“通常”学习数据集的表示,以便对原始数据进行维数缩减(编码),从而产生bottleneck。从原始的简化编码,产生一个表示。生成的表示(重构)尽可能接近原始。自动编码器的输入层和输出层节点数相同。“bottleneck值是通过从随机正态分布中挑选出来的”(Patuzzo, 2020)。在重构后的输出图像中存在一些重构损失(Flovik, 2018),可以通过分布来定义原始图像输入的阈值。阈值是可以确定异常的值。
去噪自动编码器允许隐藏层学习“更鲁棒的滤波器”并减少过拟合。一个自动编码器被“从它的一个损坏版本”来训练来重建输入(去噪自动编码器(dA))。训练包括原始图像以及噪声或“损坏的图像”。随着随机破坏过程的引入,去噪自编码器被期望对输入进行编码,然后通过去除图像中的噪声(破坏)来重建原始输入。用去噪自编码器提取和组合鲁棒特征,去噪自编码器应该能够找到结构和规律作为输入的特征。关于图像,结构和规律必须是“从多个输入维度的组合”捕获。Vincent等(2020)的假设引用“对输入的部分破坏的鲁棒性”应该是“良好的中间表示”的标准。
在这种情况下,重点将放在获取和创建大量原始和有噪声图像的能力上。我们使用真实数据和合成数据创建了大量的图像来训练我们的模型。
根据Huszar(2016)的说法,扩张卷积自动编码器“支持感受野的指数扩展,而不丢失分辨率或覆盖范围。“保持图像的分辨率和覆盖范围,对于通过扩大卷积自动编码器重建图像和使用图像进行异常检测是不可或缺的。这使得自动编码器在解码器阶段,从创建原始图像的重建到更接近“典型”自动编码器结构可能产生的结果。Dilated Convolutional Autoencoders Yu et al.(2017),“Network Intrusion Detection through Stacking Dilated Convolutional Autoencoders”,该模型的目标是将无监督学习特征和CNN结合起来,从大量未标记的原始流量数据中学习特征。他们的兴趣在于识别和检测复杂的攻击。通过允许“非常大的感受野,而只以对数的方式增加参数的数量”,Huszar (2016),结合无监督CNN的特征学习,将这些层堆叠起来(Yu et al., 2017),能够从他们的模型中获得“卓越的性能”。
技术
Flip Library (LinkedAI):https://github.com/LinkedAi/flip
Flip是一个python库,允许你从由背景和对象组成的一小组图像(可能位于背景中的图像)中在几步之内生成合成图像。它还允许你将结果保存为jpg、json、csv和pascal voc文件。
Python Libraries
在这个项目中有几个Python库被用于不同的目的:
可视化(图像、指标):
- OpenCV
- Seaborn
- Matplotlib
处理数组:
- Numpy
模型:
- TensorFlow
- Keras
- Random
图像相似度比较:
- Imagehash
- PIL
- Seaborn (Histogram)
Weights and Biases
Weights and bias是一个开发者工具,它可以跟踪机器学习模型,并创建模型和训练的可视化。它是一个Python库,可以作为import wandb导入。它工作在Tensorflow, Keras, Pytorch, Scikit,Hugging Face,和XGBoost上。使用wandb.config配置输入和超参数,跟踪指标并为输入、超参数、模型和训练创建可视化,使它更容易看到可以和需要更改的地方来改进模型。
模型&结构
我们基于当前的自动编码器架构开始了我们的项目,该架构专注于使用带有卷积网络的图像(见下图)。经过一些初步的测试,基于研究(参见参考资料)和导师的建议,我们更改为最终的架构。
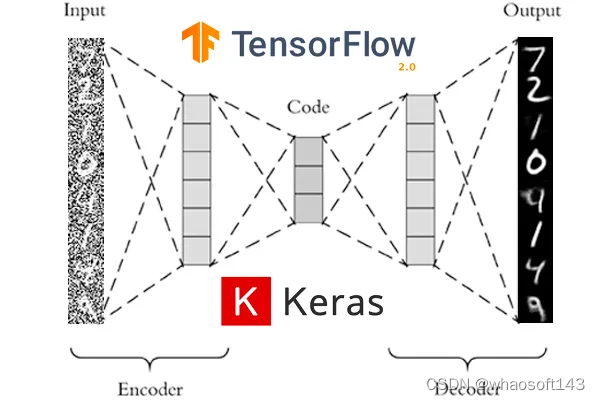
自编码器的典型结构
使用扩张特征
扩张特征是一种特殊的卷积网络,在传统的卷积核中插入孔洞。在我们的项目中,我们特别的对通道维度应用了膨,不影响图像分辨率。
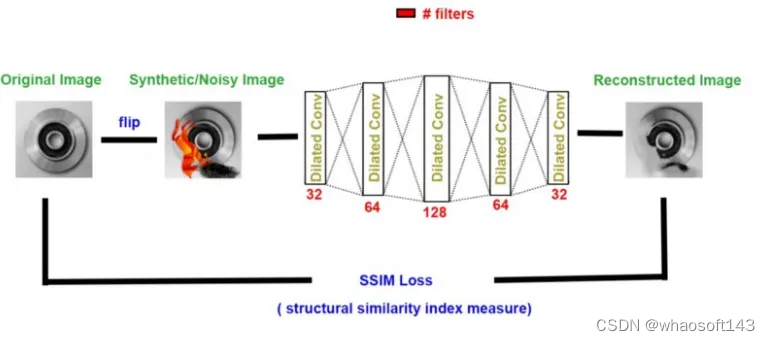
最终的结构
图像相似度
这个项目的关键点之一是找到一个图像比较的指标。利用图像比较度量对模型进行训练,建立直方图,并计算阈值,根据该阈值对图像进行异常和非异常的分类。
我们从逐个像素的L2欧氏距离开始。结果并不能确定其中的一些差异。我们使用了带有不同散列值(感知、平均和差异)的Python Imagehash库,对于相似的图像,我们得到了不同的结果。我们发现SSIM(结构相似度指数度量)度量为我们提供了一对图像之间相似度的度量,此外,它是Keras库的一个内置损失。
直方图
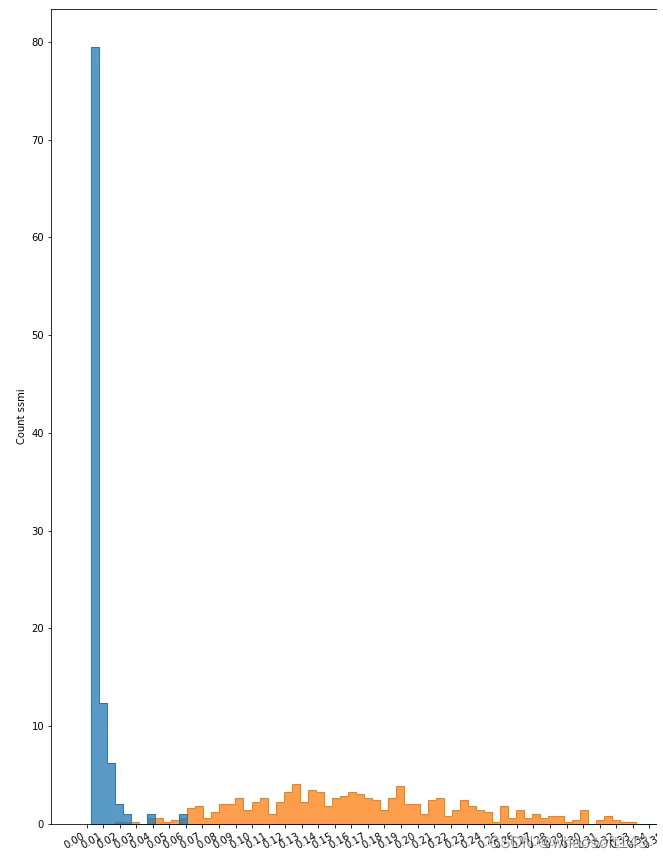
在对模型进行训练和评估后,利用其各自的数据集,对重建后的图像和原始图像之间的相似度进行识别。当然,由于原始图像的多样性(如,大小,位置,颜色,亮度和其他变量),这种相似性有一个范围。我们使用直方图作为图的表示,以可视化这个范围,并观察在哪个点会有不同的图像。
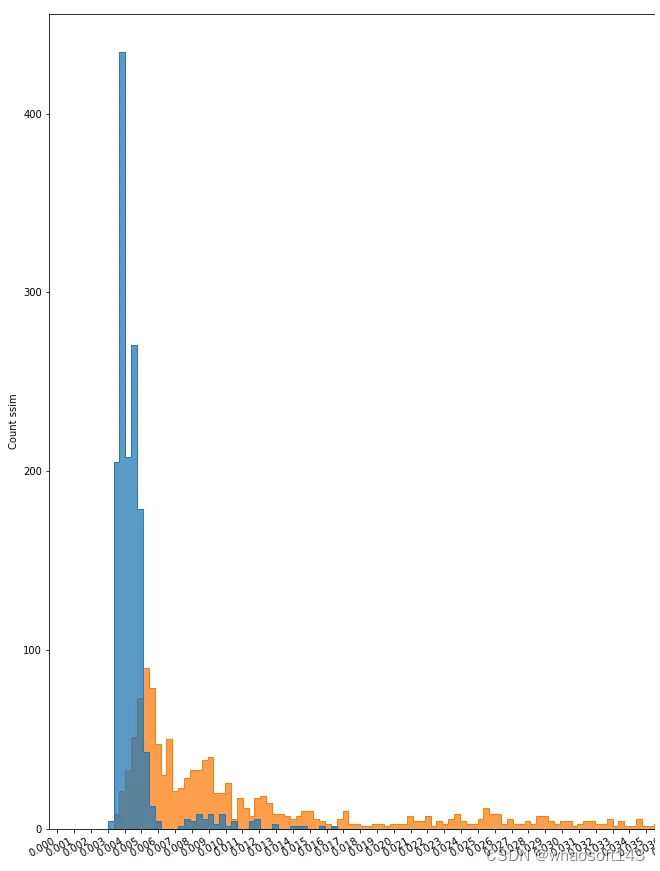
直方图的例子
数据
使用的数据从Kaggle下载:表面裂纹检测数据集:https://www.kaggle.com/arunrk7/surface-crack-detection和铸造产品质量检查图像数据:https://www.kaggle.com/ravirajsinh45/real-life-industrial-dataset-of-casting-product?select=casting_data。
第一个是裂缝数据集,包含20,000张负样本墙图像(无裂缝)和20,000张正样本墙图像(有裂缝)。在这种情况下,裂缝被认为是异常的。所有数据都是227x227像素的RGB通道。下面显示了每个组的示例。

我们从没有异常的组中选取了10,000张图像来生成不同的合成数据集。然后合成的数据集被分为两种类型:一种是带有类似异常的噪声(51张图像是用Photoshop创建的),另一种是使用水果、植物和动物等随机物体。所有用作噪声的图像都是png格式的,背景是透明的。下面是用于模型训练的两种类型的数据集的一些例子。

第二个数据集,cast数据集分为两组,一组为512x512像素的图像(有异常的781张,无异常的519张),另一组为300x300像素的图像(有异常的3137张,有异常的4211张)。所有图像都有RGB通道。使用的是300 x 300像素的图像。后者,来自Kaggle,91.65%的数据被分为训练,其余的测试。对于该数据集,异常包括:边缘碎片、划痕、表面翘曲和孔洞。下面是一些有和没有异常的图像示例。

我们使用1,000张属于训练组的无缺陷图像来生成合成数据数据集。在前面的例子中,我们创建了两种类型的数据集:一种带有类似于异常的噪声(51张图像是用Photoshop创建的),另一种带有随机对象的噪声,如动物、花朵和植物(裂缝数据集中使用的相同的80张图像)。下面是一些在模型训练中使用的图像示例。

所有合成数据都是使用Flip库创建的。在每个生成的图像中,选择两个对象并随机放置。对象应用了三种类型的转换:翻转、旋转和调整大小。生成的图像保存为jpg格式。项目使用的数据集如下表所示:
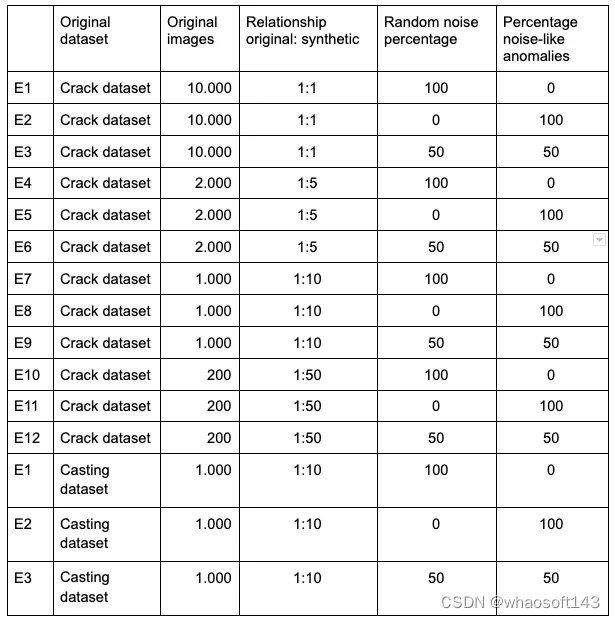
实验
根据上述表格说明,我们的主要目的是研究数据集的哪些变化可能呈现最好的结果,我们用这些数据和获得的结果训练了模型(见下面的图表)。
对于每个数据集,我们评估了几个指标,如(SSIM)损失、召回、精度、F1和精度。在每一次实验中,我们将评估代表这组噪声图像和重建图像之间图像相似性的直方图。
为了跟踪和比较我们的结果,我们使用了library Weight & bias,它允许一种简单的方式来存储和比较每个实验的结果。

训练
为了在我们的环境中保持少量的变量,我们决定总是使用一个有1000个样本的数据集,而不管真实数据和合成数据之间的关系。
在算法中,我们将各自的数据集分割为95%进行训练,5%进行测试结果。除此之外,我们的评估只使用了真实的数据。

评估和结果
下面是一些实验的主要结果。你可在以下连结找到所有的结果:
裂缝数据集:https://wandb.ai/heimer-rojas/anomaly-detector-cracks?workspace=user-
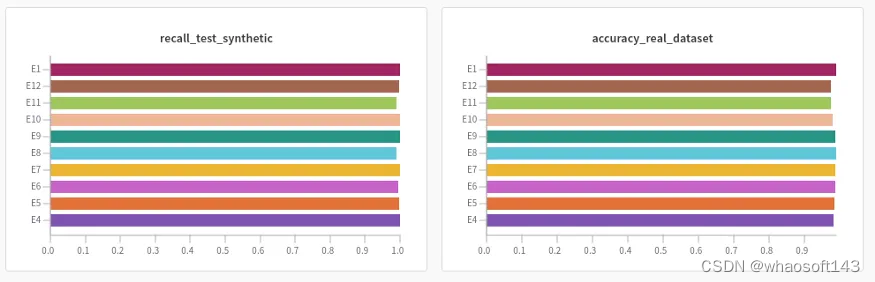
裂缝直方图

裂缝数据集的异常检测
对于裂纹数据集,实验结果也很好(91% ~ 98%),实验之间没有显著差异。与无异常的图像相比,其行为主要取决于裂纹大小和颜色等变量。
铸造工件数据集:https://wandb.ai/heimer-rojas/anomaly-detector-cast?workspace=user-heimer-rojas
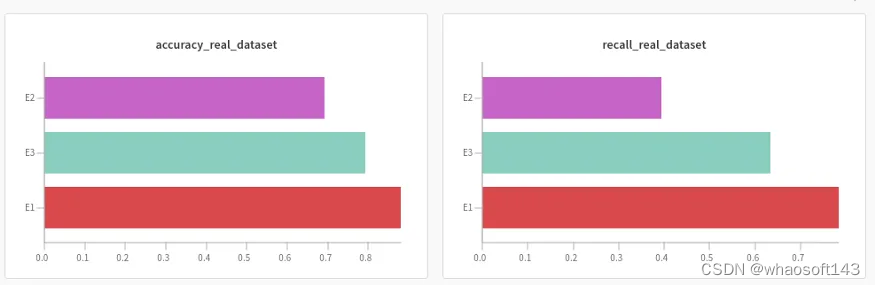
铸造工件数据集的准确率和召回率
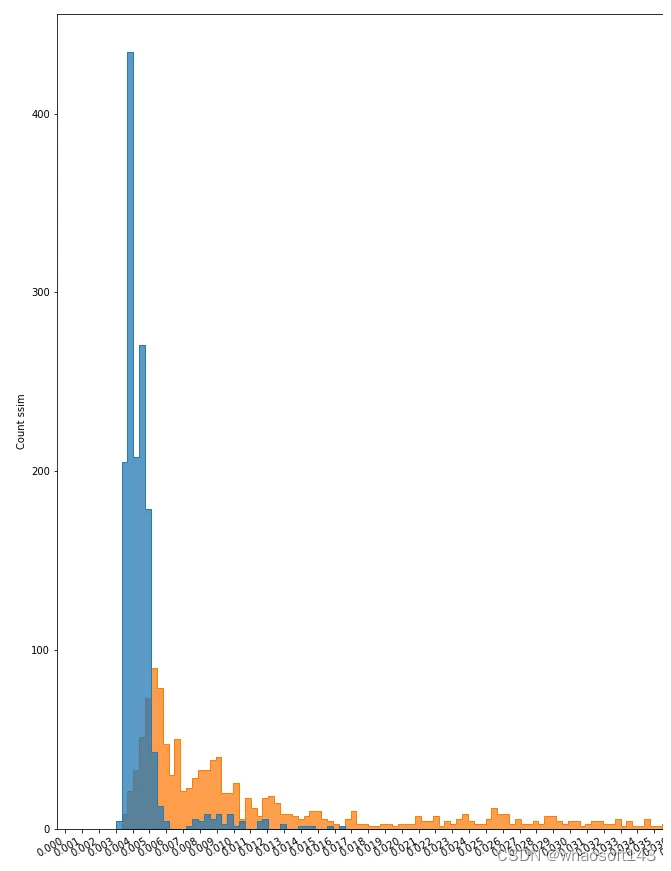
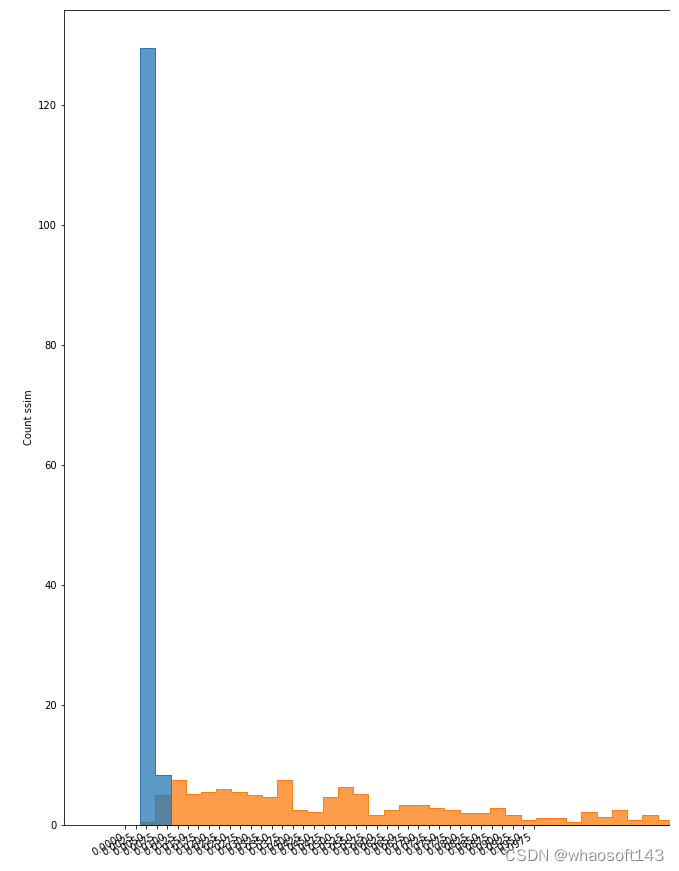
铸造件E1&E3

铸造件数据集的异常检测
挑战
- 训练时间长,在谷歌Colab和专业版中使用GPU训练。
- 通过上传压缩后的zip格式的数据来解决长时间的数据加载问题,这样每个数据集上传一个文件,大大减少了时间。
- 最初的提议是使用哥伦比亚汽车生产线的数据集,不幸的是,正样本和负样本图像的质量和数量都不足以创建一个合适的机器学习模型。这种情况促使我们决定使用Kaggle的数据集,与生产线生产的条件类似。
- 每个数据集在异常情况下的可视化差异是不同的,需要考虑正常的图像结构,如图像的颜色、亮度等内在特征
- 需要人类的专业知识来根据真实数据或合成数据的阈值选择适当的阈值。这可能要视情况而定。
讨论
实现一个真正的机器学习项目需要几个步骤,从想法到模型的实现。这包括数据集的选择、收集和处理。
在使用图像的项目中有“调试脚本”是很重要的。在我们的例子中,我们使用了一个允许我们可视化的脚本:原始数据集、新的合成图像和自编码器去噪之后的图像,使我们能够评估模型的性能。
四、焊件的缺陷检测
这次是带来的焊件的缺陷检测 也可以叫瑕疵检测 都是工业相关哦
焊接缺陷是指焊接零件表面出现不规则、不连续的现象。焊接接头的缺陷可能会导致组件报废、维修成本高昂,在工作条件下的组件的性能显着下降,在极端情况下还会导致灾难性故障,并造成财产和生命损失。此外,由于焊接技术固有的弱点和金属特性,在焊接中总是存在某些缺陷。不可能获得完美的焊接,因此评估焊接质量非常重要。
可以通过图像来检测焊接中的缺陷,并精确测量每个缺陷的严重性,这将有助于并避免上述危险情况的出现。使用卷积神经网络算法和U-Net架构可提高检测的效率,精度也能达到98.3%。
代码:https://github.com/malakar-soham/cnn-in-welding
图像分割
图像分割是指将图像划分为包含相似属性的不同像素区域。为了对图像分析和解释,划分的区域应与对象特征密切相关。图像分析的成功取决于分割的可靠性,但是图像的正确分割通常是一个非常具有挑战性的问题。
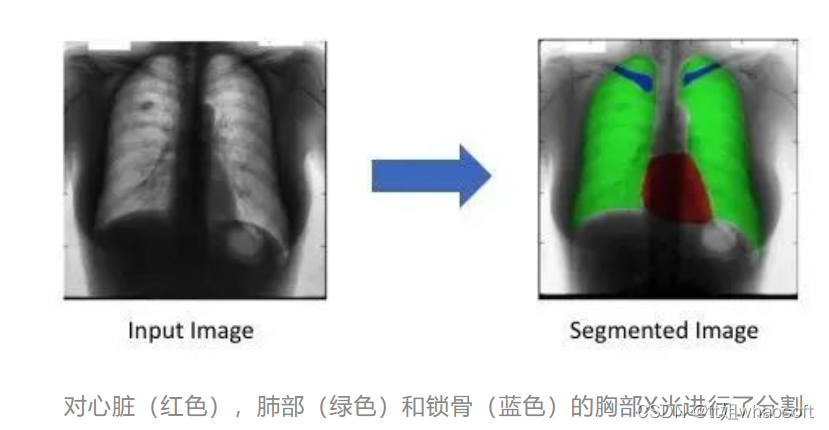
图像中心距
图像中心距是图像像素强度的某个特定加权平均值。图像矩可用于描述分割后的对象。通过图像瞬间发现的图像简单属性包括:
- 面积(或总强度)
- 质心
- 有关其方向的信息
数据
该数据集包含两个目录。原始图像存储在“图像”目录中,分割后的图像存储在“标签”目录中。让我们来看看这些数据:原始图像是RGB图像,用于训练模型和测试模型。这些图片的尺寸各不相同。直观地,较暗的部分是焊接缺陷。模型需要对这些图像执行图像分割。

“标签”目录的图像是二进制图像或地面真相标签。这是我们的模型必须针对给定的原始图像进行预测。在二进制图像中,像素具有“高”值或“低”值。白色区域或“高”值表示缺陷区域,而黑色区域或“低”值表示无缺陷。

算法
我们将使用U-Net来解决这个问题,通过以下三个主要步骤来检测缺陷及其严重性:
- 图像分割
- 使用颜色显示严重性
- 使用图像矩测量严重性
训练模型
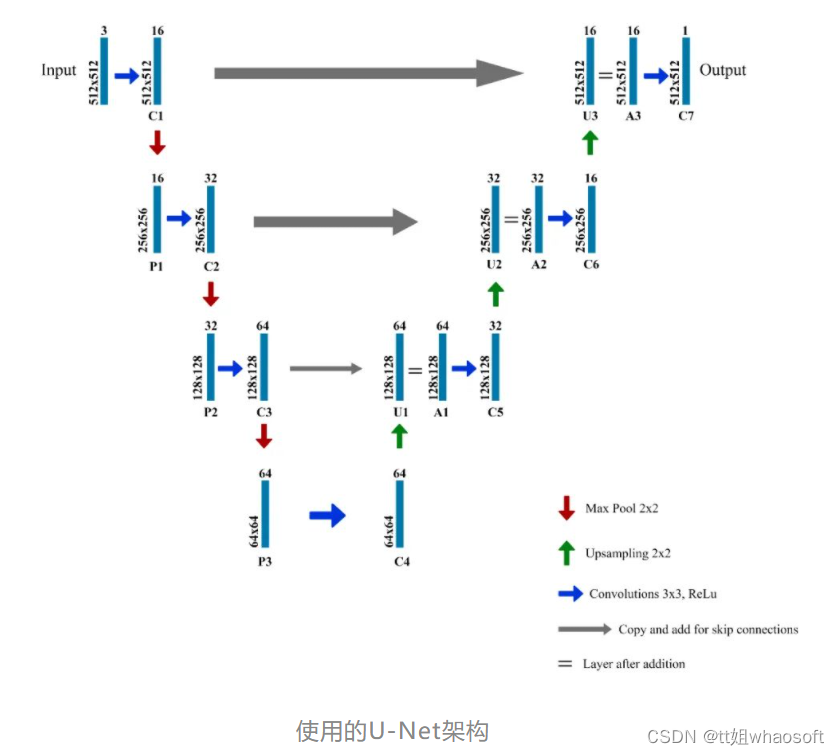
注意事项:
- 每个蓝色框对应一个多通道特征图
- 通道数显示在框的顶部。
- (x,y)尺寸位于框的左下边缘。
- 箭头表示不同的操作。
- 图层名称位于图层下方。
- C1,C2,...。C7是卷积运算后的输出层
- P1,P2,P3是最大池化操作的输出层
- U1,U2,U3是上采样操作的输出层
- A1,A2,A3是跳过连接。
- 左侧是收缩路径,其中应用了常规卷积和最大池化操作
- 图像尺寸逐渐减小,而深度逐渐增大。
- 右侧是扩展路径,在其中应用了(向上采样)转置卷积和常规卷积运算
- 在扩展路径中,图像尺寸逐渐增大,深度逐渐减小
- 为了获得更好的精确位置,在扩展的每个步骤中,我们都使用跳过连接,方法是将转置卷积层的输出与来自编码器的特征图在同一级别上连接:
A1 = U1 + C3
A2 = U2 + C2
A3 = U3 + C1
每次串联后,我们再次应用规则卷积,以便模型可以学习组装更精确的输出。
import numpy as np
import cv2
import os
import random
import tensorflow as tf
h,w = 512,512
def create_model():
inputs = tf.keras.layers.Input(shape=(h,w,3))
conv1 = tf.keras.layers.Conv2D(16,(3,3),activation='relu',padding='same')(inputs)
pool1 = tf.keras.layers.MaxPool2D()(conv1)
conv2 = tf.keras.layers.Conv2D(32,(3,3),activation='relu',padding='same')(pool1)
pool2 = tf.keras.layers.MaxPool2D()(conv2)
conv3 = tf.keras.layers.Conv2D(64,(3,3),activation='relu',padding='same')(pool2)
pool3 = tf.keras.layers.MaxPool2D()(conv3)
conv4 = tf.keras.layers.Conv2D(64,(3,3),activation='relu',padding='same')(pool3)
upsm5 = tf.keras.layers.UpSampling2D()(conv4)
upad5 = tf.keras.layers.Add()([conv3,upsm5])
conv5 = tf.keras.layers.Conv2D(32,(3,3),activation='relu',padding='same')(upad5)
upsm6 = tf.keras.layers.UpSampling2D()(conv5)
upad6 = tf.keras.layers.Add()([conv2,upsm6])
conv6 = tf.keras.layers.Conv2D(16,(3,3),activation='relu',padding='same')(upad6)
upsm7 = tf.keras.layers.UpSampling2D()(conv6)
upad7 = tf.keras.layers.Add()([conv1,upsm7])
conv7 = tf.keras.layers.Conv2D(1,(3,3),activation='relu',padding='same')(upad7)
model = tf.keras.models.Model(inputs=inputs, outputs=conv7)
return model
images = []
labels = []
files = os.listdir('./dataset/images/')
random.shuffle(files)
for f in files:
img = cv2.imread('./dataset/images/' + f)
parts = f.split('_')
label_name = './dataset/labels/' + 'W0002_' + parts[1]
label = cv2.imread(label_name,2)
img = cv2.resize(img,(w,h))
label = cv2.resize(label,(w,h))
images.append(img)
labels.append(label)
images = np.array(images)
labels = np.array(labels)
labels = np.reshape(labels,
(labels.shape[0],labels.shape[1],labels.shape[2],1))
print(images.shape)
print(labels.shape)
images = images/255
labels = labels/255
model = tf.keras.models.load_model('my_model')
#model = create_model() # uncomment this to create a new model
print(model.summary())
model.compile(optimizer='adam', loss='binary_crossentropy',metrics=['accuracy'])
model.fit(images,labels,epochs=100,batch_size=10)
model.evaluate(images,labels)
model.save('my_model')该模型使用Adam优化器编译,由于只有两类(缺陷或没有缺陷),因此我们使用二进制交叉熵损失函数。我们使用10批次、100个epochs(在所有输入上运行模型的次数)。调整这些参数,模型性能可能会有很大的改善可能。
测试模型
由于模型采用的尺寸为512x512x3,因此我们将输入的尺寸调整为该尺寸。接下来,我们通过将图像除以255进行归一化以加快计算速度。图像进入模型后以预测二进制输出,为了放大像素的强度,二进制输出已乘以1000。
然后将图像转换为16位整数以便于图像操作。之后,算法将检测缺陷并通过颜色分级在视觉上标记缺陷的严重性,并根据缺陷的严重性为具有缺陷的像素分配权重。然后考虑加权像素,在此图像上计算图像力矩。最终将图像转换回8位整数,并以颜色分级及其严重性值显示输出图像。
import numpy as np
import cv2
from google.colab.patches import cv2_imshow
import os
import random
import tensorflow as tf
h,w = 512,512
num_cases = 10
images = []
labels = []
files = os.listdir('./dataset/images/')
random.shuffle(files)
model = tf.keras.models.load_model('my_model')
lowSevere = 1
midSevere = 2
highSevere = 4
for f in files[0:num_cases]:
test_img = cv2.imread('./dataset/images/' + f)
resized_img = cv2.resize(test_img,(w,h))
resized_img = resized_img/255
cropped_img = np.reshape(resized_img,
(1,resized_img.shape[0],resized_img.shape[1],resized_img.shape[2]))
test_out = model.predict(cropped_img)
test_out = test_out[0,:,:,0]*1000
test_out = np.clip(test_out,0,255)
resized_test_out = cv2.resize(test_out,(test_img.shape[1],test_img.shape[0]))
resized_test_out = resized_test_out.astype(np.uint16)
test_img = test_img.astype(np.uint16)
grey = cv2.cvtColor(test_img, cv2.COLOR_BGR2GRAY)
for i in range(test_img.shape[0]):
for j in range(test_img.shape[1]):
if(grey[i,j]>150 & resized_test_out[i,j]>40):
test_img[i,j,1]=test_img[i,j,1] + resized_test_out[i,j]
resized_test_out[i,j] = lowSevere
elif(grey[i,j]<100 & resized_test_out[i,j]>40):
test_img[i,j,2]=test_img[i,j,2] + resized_test_out[i,j]
resized_test_out[i,j] = highSevere
elif(resized_test_out[i,j]>40):
test_img[i,j,0]=test_img[i,j,0] + resized_test_out[i,j]
resized_test_out[i,j] = midSevere
else:
resized_test_out[i,j] = 0
M = cv2.moments(resized_test_out)
maxMomentArea = resized_test_out.shape[1]*resized_test_out.shape[0]*highSevere
print("0th Moment = " , (M["m00"]*100/maxMomentArea), "%")
test_img = np.clip(test_img,0,255)
test_img = test_img.astype(np.uint8)
cv2_imshow(test_img)
cv2.waitKey(0)结果
我们使用颜色来表示缺陷的严重程度:
- 绿色表示存在严重缺陷的区域。
- 蓝色表示缺陷更严重的区域。
- 红色区域显示出最严重的缺陷。
零阶矩将以百分比形式显示在输出图像旁边,作为严重程度的经验指标。
以下是三个随机样本,它们显示了原始输入,地面真实情况以及由我们的模型生成的输出。
范例1:

范例2:
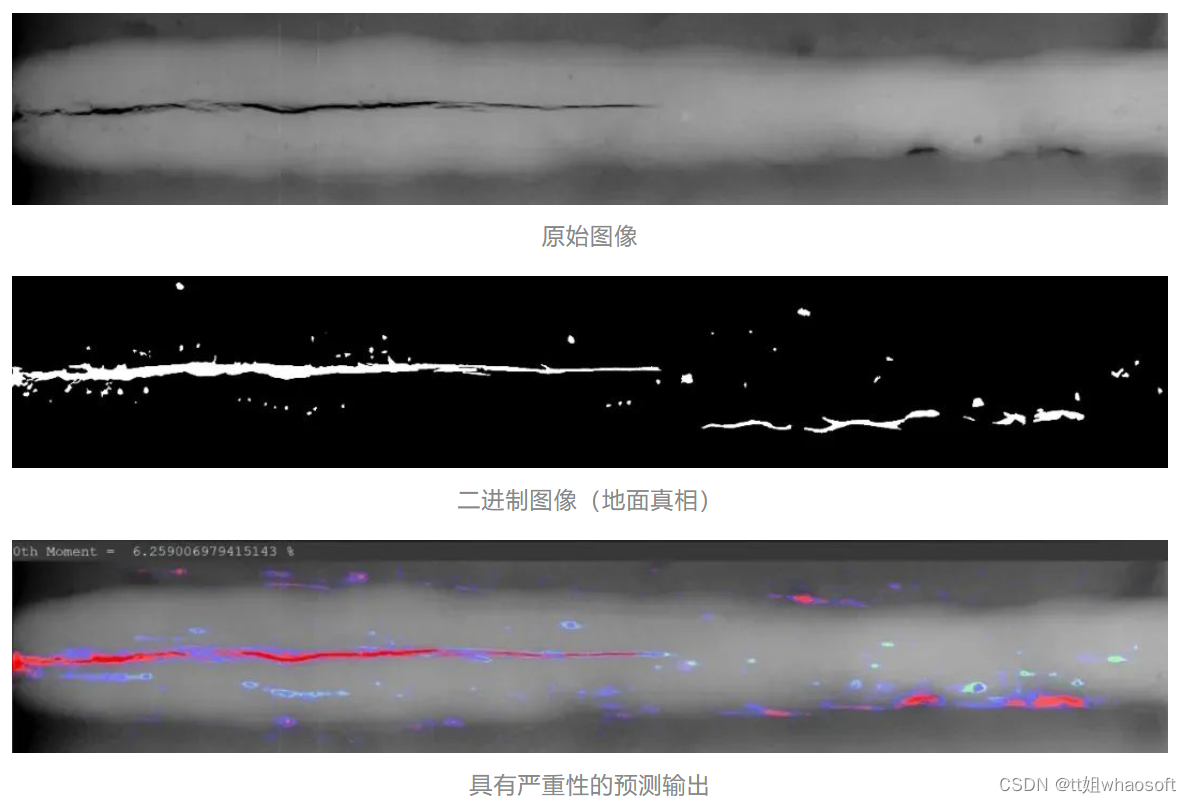
范例3:

大伙有什么欢迎来论啊
五、图像分割~缺陷检测
这里是使用图像分割来做缺陷检测的
什么是物体检测? 给定一张图像,我们人类可以识别图像中的物体。例如,我们可以检测图像中是否有汽车,树木,人等。如果我们可以分析图像并检测物体,我们可以教机器做同样的事情吗?答案是肯定的。随着深度学习和计算机视觉的兴起,我们可以实现目标检测的自动化。我们可以建立深度学习和计算机视觉模型,可以检测和定位目标,计算它们之间的距离,预测它们的未来的位置等。目标检测在计算机视觉和机器学习中有着广泛的应用。目标跟踪、闭路电视监控、人类活动识别,甚至自动驾驶汽车都利用了这项技术。为了更好地理解它,考虑下面的图片。

图1,路面交通的物体检测
图中为一幅道路交通图像从车辆上看的目标检测。这里我们可以看到它正在检测其他车辆,交通信号等。如果车辆是自动驾驶汽车,应该能够检测到行驶路径、其他车辆、行人、交通信号等,以便平稳、安全驾驶。现在我们已经了解了目标检测,让我们转移到一个稍微高级的技术,称为图像分割。通过分析下图,我们可以很容易地理解目标检测和图像分割之间的区别。

图2,目标检测和图像分割
这两种方法都试图识别和定位图像中的物体。在目标检测中,这是通过边界框实现的。该算法或模型将通过在目标周围绘制一个矩形边界框来定位目标。在图像分割中,对图像中的每个像素进行标注。这意味着,给定一幅图像,分割模型试图通过将图像的所有像素分类成有意义的对象类别来进行像素级分类。这也被称为密集预测,因为它通过识别和理解每个像素属于什么对象来预测每个像素的含义。“图像分割的返回格式称为掩码:一个与原始图像大小相同的图像,但对于每个像素,它只有一个布尔值指示目标是否存在。“我们将在本案例研究中使用这种技术。现在我们有了目标检测和图像分割的概念。让我们进一步理解问题陈述。
问题
我们得到了一些产品的图像。有些产品有缺陷,有些没有。考虑到产品的图像,我们需要检测它是否有缺陷。我们还需要定位这个缺陷。
机器学习的形式
这个问题可以表述为图像分割任务。给定一个产品的图像,我们需要为其绘制分割掩模。如果产品有缺陷,分割图应该能够定位该缺陷。
性能度量
在分割问题中最常用的指标之一是(IoU分数。参考下面的图像,这清楚地显示了如何IoU分数是计算的。
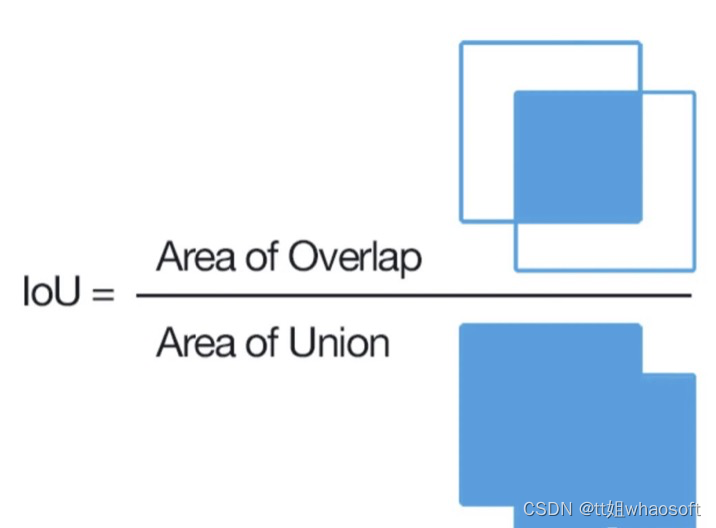
IoU是预测分割与真实分割的重叠面积除以预测分割与原始分割的并集面积
我们也可以把IoU分数写成TP/TP+FN+FP。这个度量值的范围是0到1。Iou得分为1表示完全重叠,Iou得分为0表示完全不重叠。本案例研究中使用的损失函数是Dice损失。Dice 损失可以被认为是1-Dice 系数,其中Dice 系数定义为,Dice系数 = 2 * 相交的重叠面积
理解数据
该数据集包含两个文件夹 —— train和test。训练集由六类图像组成。每一类图像被分成两个文件夹,其中一个文件夹包含1000张无缺陷图像,另一个文件夹包含130张有缺陷图像。下图显示了train文件夹中的文件夹。
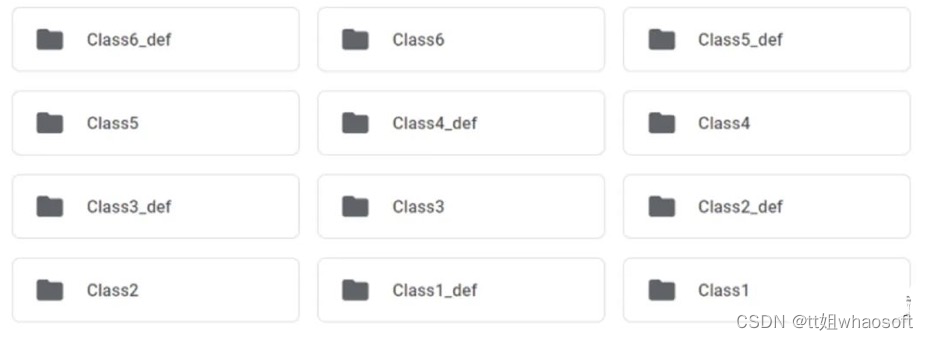
图3,训练数据集
以 “def”结尾的文件夹名称包含相应类的有缺陷的图像,没有“def”的则表示无缺陷的图像。测试文件夹包含一组120个有缺陷的图像,这些图像的分割图将被预测。
数据预处理
1 准备图像数据和分割蒙版
现在我们需要为每个图像准备图像数据和相应的分割掩模。我们把图片分成十二个文件夹。让我们来看一些图片。


图4,产品的图像
第一幅图像表示有缺陷的产品,第二幅图像表示无缺陷的图像。现在我们需要为这些图像准备分割图。分割图可以检测出图像中有缺陷的部分。对于上面的图像,预期的分割图是这样的。


图5,图4上的分割蒙版
我们可以看到,在第一幅图像中,椭圆区域代表检测部分。第二幅图像是空白的,因为它没有缺陷。让我们再分析一些有缺陷的图像。




图6,一些缺陷图像的例子
我们可以看到缺陷在图像中以曲线或直线的形式出现。因此,我们可以利用椭圆来将这些区域标记为缺陷。但我们如何准备分割掩码?是否需要手工标注?我们有另一个包含关于分割掩码信息的文件。
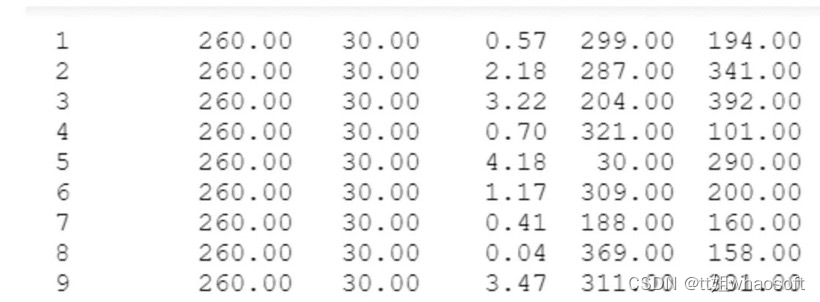
每一行包含关于图像的mask区域的信息。每一列表示图像的文件名、椭圆的半长轴、椭圆的半短轴、椭圆的旋转角度、椭球中心的x位置、椭球中心的y位置。
绘制椭圆所需的数据是使用get_data函数获得的,如下所示:
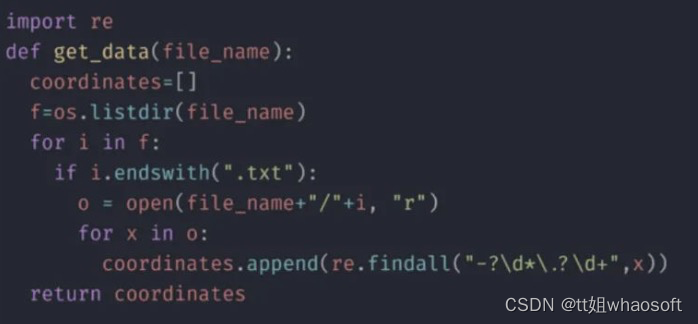
我们可以使用这些信息,并使用skimage函数绘制一个椭圆分割蒙版。
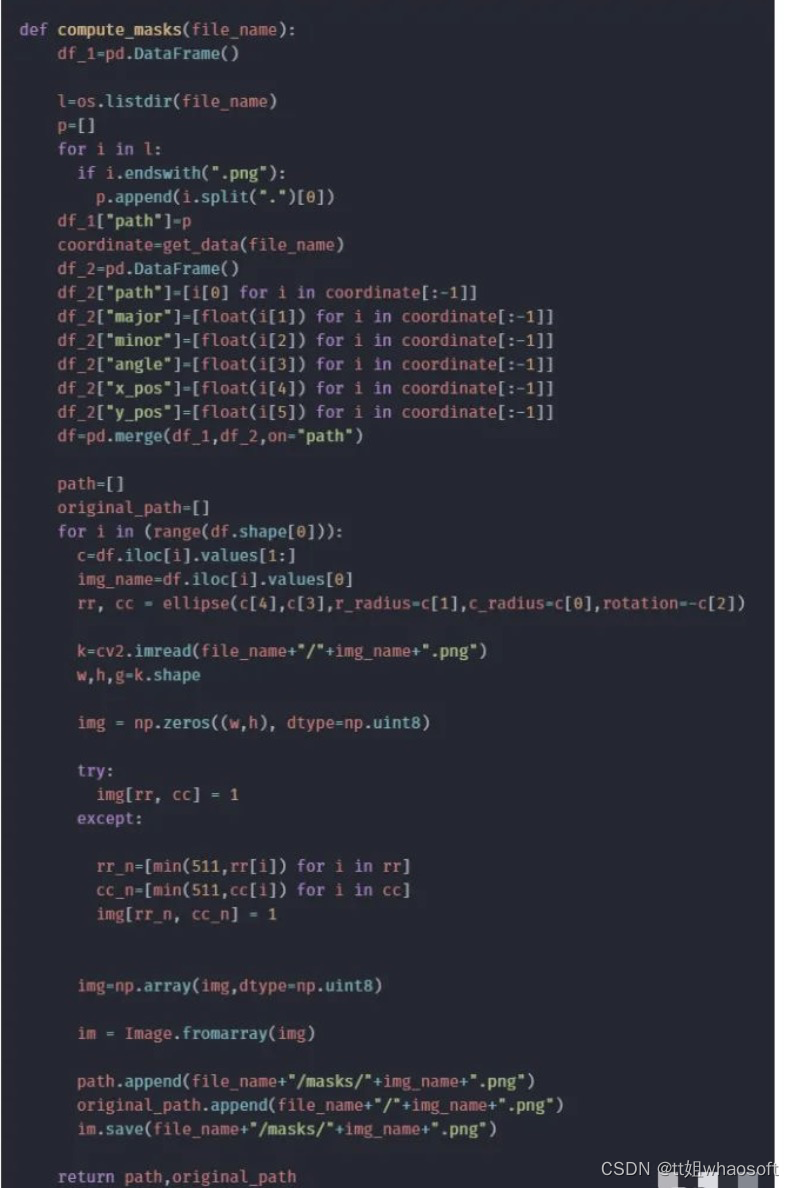
值得注意的是,这只适用于有缺陷的图像。对于无缺陷的图像,我们需要创建空白图像作为分割掩模。
2 加载图像
结构化数据以如下所示的形式获得。
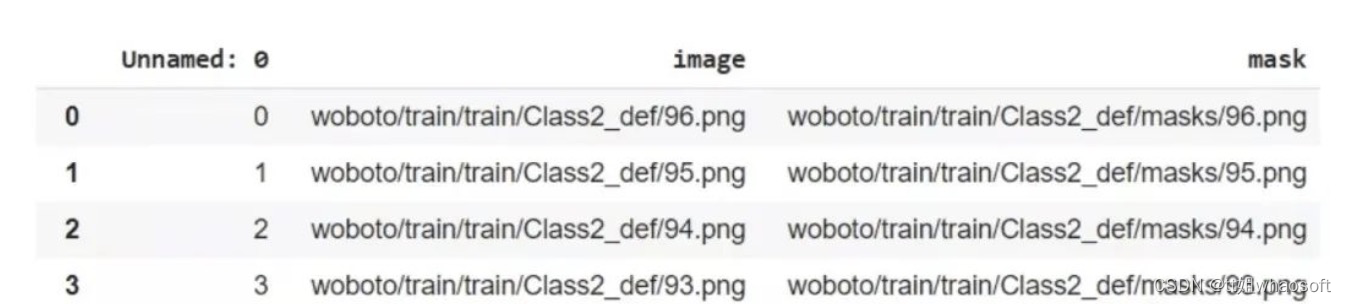
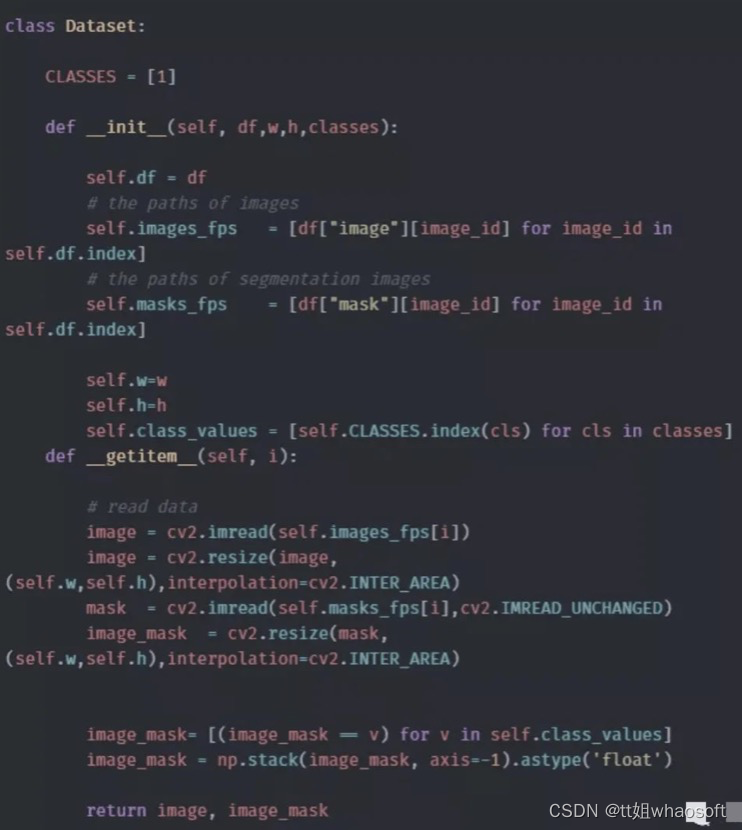
“images”列包含每个图像的完整文件路径,“mask”列包含相应的掩码图像。
下一步是加载数据。
模型
现在我们得到了所有的数据,下一步是找到一个模型,可以生成图像的分割mask。让我来介绍一下UNet模型,它在图像分割任务中非常流行。UNet架构包含两种路径:收缩路径和扩展路径。下图可以更好地理解Unet架构。
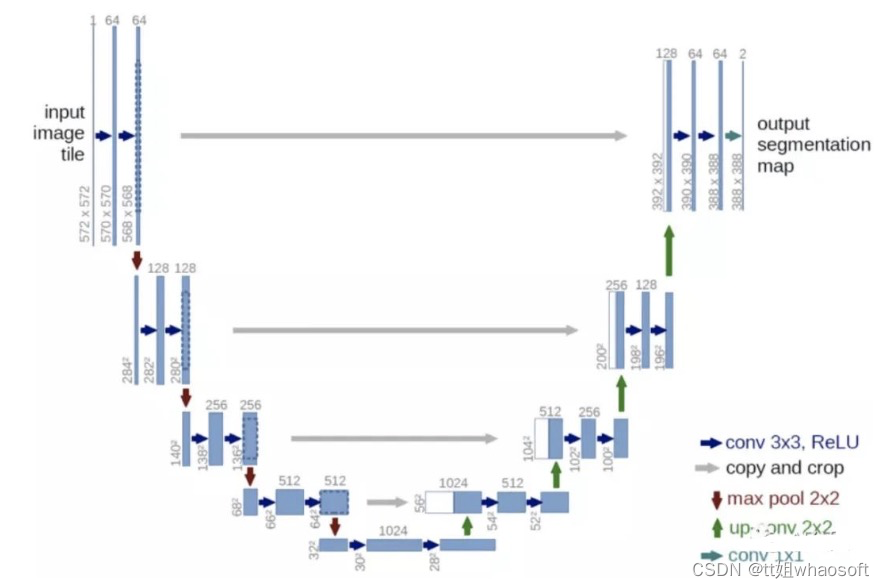
图7,Unet结构
模型结构类似于英文字母“U”,因此得名Unet。模型的左侧包含收缩路径(也称为编码器),它有助于捕获图像中的上下文。该编码器只是一个传统的卷积和最大池层堆栈。在这里我们可以看到,池化层降低了图像的高度和宽度,增加了通道的深度和数量。在收缩路径的末端,模型将理解图像中出现的形状、模式、边缘等,但它丢失了“在哪里”出现的信息。由于我们的问题是获取图像的分割映射,我们从压缩路径中获得的信息是不够的。我们需要一个高分辨率的图像作为输出,其中所有像素都是分类的。”如果我们使用一个规则的卷积网络,pooling层和dense层,我们会丢失WHERE信息,只保留不是我们想要的“WHAT”信息。在分割的情况下,我们既需要“WHAT”信息,也需要“WHERE”信息所以我们需要对图像进行上采样,以保留“where”信息。这是在右边的扩张路径中完成的。扩展路径(也称为解码器)用于使用上采样技术定位捕获的上下文。上采样技术有双线性插值法、最近邻法、转置卷积法等。、
训练
现在我们已经准备好了所有的训练数据,也确定了模型。现在让我们训练模型。由于无缺陷图像的数量远远高于有缺陷图像的数量,所以我们只从无缺陷图像中提取一个样本,以获得更好的结果。采用adam优化器训练模型,并以dice 损失为损失函数。使用的性能指标是iou分数。
经过10个epoch,我们能够获得0.98的iou分数和0.007的骰子损失,这是相当不错的。让我们看一些图像的分割图。
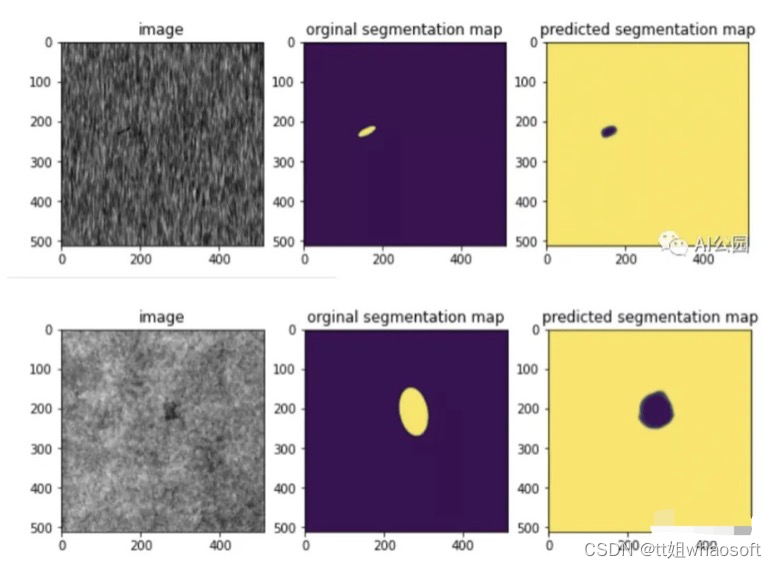
我们可以看到,该模型能够预测类似于原始分割图的分割图。
测试数据分割图的预测
现在让我们尝试解决手边的问题,即预测和绘制测试图像的分割蒙版。下图显示了一些测试图像的预测分割图。
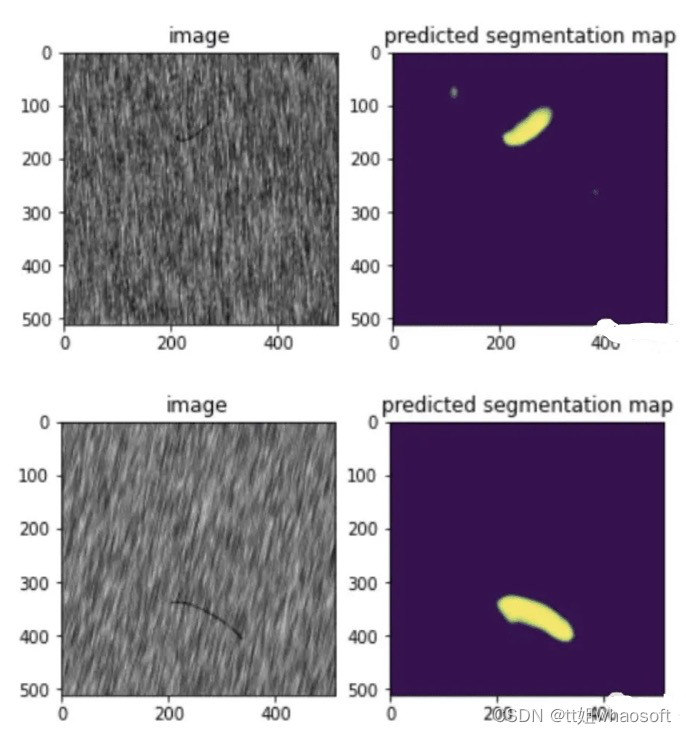
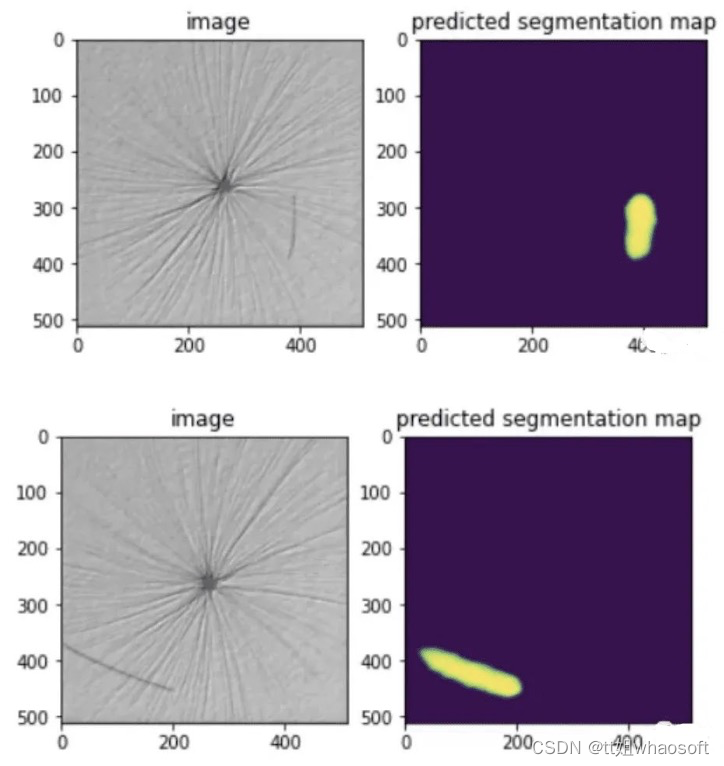
可以看出,该模型具有良好的测试性能,能够检测出测试图像中的缺陷。
未来的工作
如上所述,与无缺陷图像相比,有缺陷图像的数量非常少。因此,对缺陷图像采用上采样和增强技术可以改善训练效果。
英文原文:https://medium.com/analytics-vidhya/defect-detection-in-products-using-image-segmentation-a87a8863a9e5
六、布匹瑕疵检测
缺陷检测被广泛使用于布匹瑕疵检测、工件表面质量检测、航空航天领域等。传统的算法对规则缺陷以及场景比较简单的场合,能够很好工作,但是对特征不明显的、形状多样、场景比较混乱的场合,则不再适用。近年来,基于深度学习的识别算法越来越成熟,许多公司开始尝试把深度学习算法应用到工业场合中。
缺陷数据
如下图所示,这里以布匹数据作为案例,常见的有以下三种缺陷,磨损、白点、多线。

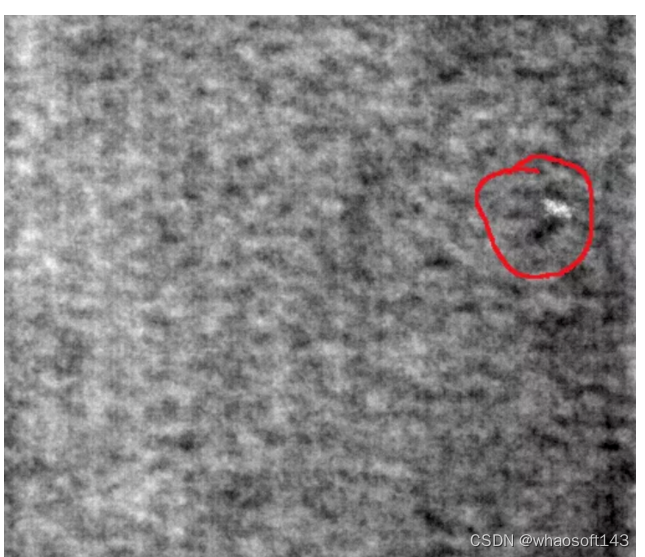
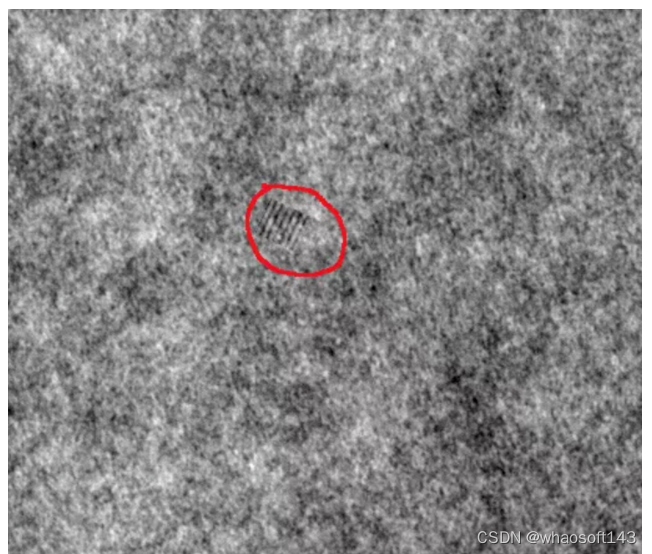
如何制作训练数据呢?这里是在原图像上进行截取,截取到小图像,比如上述图像是512x512,这里我裁剪成64x64的小图像。这里以第一类缺陷为例,下面是制作数据的方法。


注意:在制作缺陷数据的时候,缺陷面积至少占截取图像的2/3,否则舍弃掉,不做为缺陷图像。
一般来说,缺陷数据都要比背景数据少很多,此外通过增强后的数据,缺陷:背景=1:1,每类在1000幅左右~~~
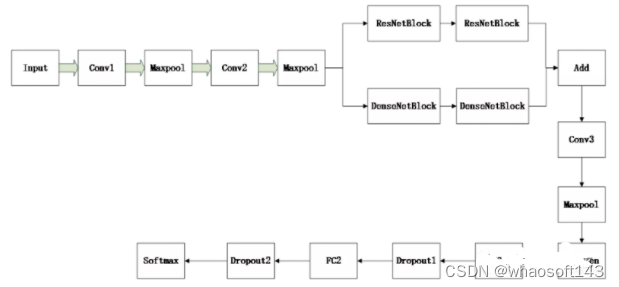
网络结构
具体使用的网络结构如下所示,输入大小就是64x64x3,采用的是截取的小图像的大小。每个Conv卷积层后都接BN层,具体层参数如下所示。
Conv1:64x3x3
Conv2:128x3x3
ResNetBlock和DenseNetBlock各两个,具体细节请参考残差网络和DenseNet。
Add:把残差模块输出的结果和DenseNetBlock输出的结果在对应feature map上进行相加,相加方式和残差模块相同。注意,其实这里是为了更好的提取特征,方式不一定就是残差模块+DenseNetBlock,也可以是inception,或者其它。
Conv3:128x3x3
Maxpool:stride=2,size=2x2
FC1:4096
Dropout1:0.5
FC2:1024
Dropout1:0.5
Softmax:对应的就是要分的类别,在这里我是二分类。
关于最后的损失函数,建议选择Focal Loss,这是何凯明大神的杰作,源码如下所示:

数据做好,就可以开始训练了~~~
整幅场景图像的缺陷检测
上述训练的网络,输入是64x64x3的,但是整幅场景图像却是512x512的,这个输入和模型的输入对不上号,这怎么办呢?其实,可以把训练好的模型参数提取出来,然后赋值到另外一个新的模型中,然后把新的模型的输入改成512x512就好,只是最后在conv3+maxpool层提取的feature map比较大,这个时候把feature map映射到原图,比如原模型在最后一个maxpool层后,输出的feature map尺寸是8x8x128,其中128是通道数。如果输入改成512x512,那输出的feature map就成了64x64x128,这里的每个8x8就对应原图上的64x64,这样就可以使用一个8x8的滑动窗口在64x64x128的feature map上进行滑动裁剪特征。然后把裁剪的特征进行fatten,送入到全连接层。具体如下图所示。
全连接层也需要重新建立一个模型,输入是flatten之后的输入,输出是softmax层的输出。这是一个简单的小模型。
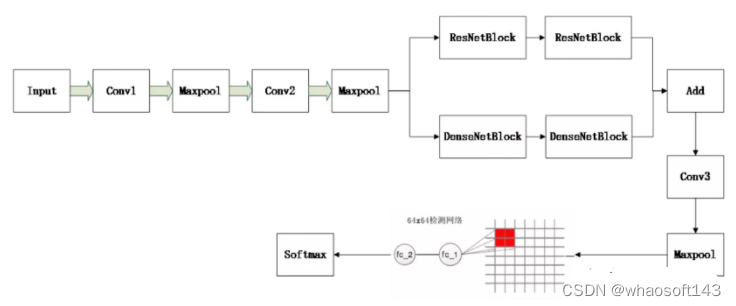
在这里提供一个把训练好的模型参数,读取到另外一个模型中的代码
#提取特征的大模型
def read_big_model(inputs):
# 第一个卷积和最大池化层
X = Conv2D(16, (3, 3), name="conv2d_1")(inputs)
X = BatchNormalization(name="batch_normalization_1")(X)
X = Activation('relu', name="activation_1")(X)
X = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name="max_pooling2d_1")(X)
# google_inception模块
conv_1 = Conv2D(32, (1, 1), padding='same', name='conv2d_2')(X)
conv_1 = BatchNormalization(name='batch_normalization_2')(conv_1)
conv_1 = Activation('relu', name='activation_2')(conv_1)
conv_2 = Conv2D(32, (3, 3), padding='same', name='conv2d_3')(X)
conv_2 = BatchNormalization(name='batch_normalization_3')(conv_2)
conv_2 = Activation('relu', name='activation_3')(conv_2)
conv_3 = Conv2D(32, (5, 5), padding='same', name='conv2d_4')(X)
conv_3 = BatchNormalization(name='batch_normalization_4')(conv_3)
conv_3 = Activation('relu', name='activation_4')(conv_3)
pooling_1 = MaxPooling2D(pool_size=(2, 2), strides=(1, 1), padding='same', name='max_pooling2d_2')(X)
X = merge([conv_1, conv_2, conv_3, pooling_1], mode='concat', name='merge_1')
X = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='max_pooling2d_3')(X) # 这里的尺寸变成16x16x112
X = Conv2D(64, (3, 3), kernel_regularizer=regularizers.l2(0.01), padding='same', name='conv2d_5')(X)
X = BatchNormalization(name='batch_normalization_5')(X)
X = Activation('relu', name='activation_5')(X)
X = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='max_pooling2d_4')(X) # 这里尺寸变成8x8x64
X = Conv2D(128, (3, 3), padding='same', name='conv2d_6')(X)
X = BatchNormalization(name='batch_normalization_6')(X)
X = Activation('relu', name='activation_6')(X)
X = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same', name='max_pooling2d_5')(X) # 这里尺寸变成4x4x128
return X
def read_big_model_classify(inputs_sec):
X_ = Flatten(name='flatten_1')(inputs_sec)
X_ = Dense(256, activatinotallow='relu', name="dense_1")(X_)
X_ = Dropout(0.5, name="dropout_1")(X_)
predictions = Dense(2, activatinotallow='softmax', name="dense_2")(X_)
return predictions
#建立的小模型
inputs=Input(shape=(512,512,3))
X=read_big_model(inputs)#读取训练好模型的网络参数
#建立第一个model
model=Model(inputs=inputs, outputs=X)
model.load_weights('model_halcon.h5', by_name=True)
识别定位结果
上述的滑窗方式可以定位到原图像,8x8的滑窗定位到原图就是64x64,同样,在原图中根据滑窗方式不同(在这里选择的是左右和上下的步长为16个像素)识别定位到的缺陷位置也不止一个,这样就涉及到定位精度了。在这里选择投票的方式,其实就是对原图像上每个被标记的像素位置进行计数,当数字大于指定的阈值,就被判断为缺陷像素。
识别结果如下图所示:

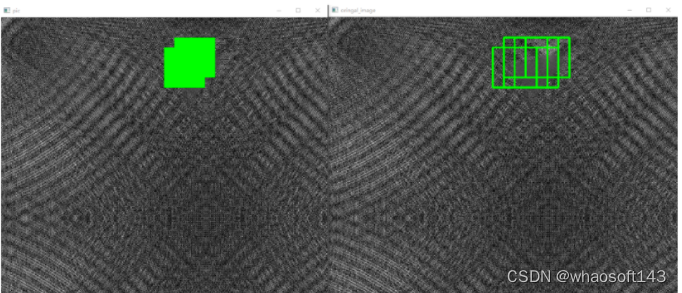
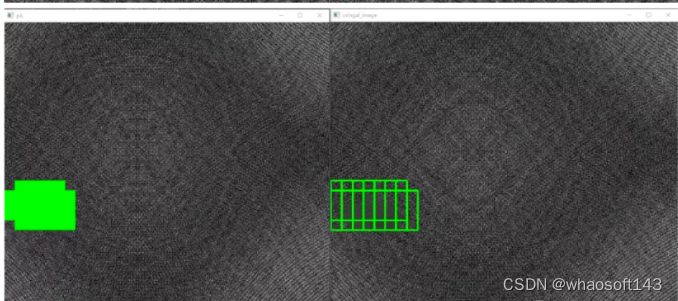
一些Trick
对上述案例来说,其实64x64大小的定位框不够准确,可以考虑训练一个32x32大小的模型,然后应用方式和64x64的模型相同,最后基于32x32的定位位置和64x64的定位位置进行投票,但是这会涉及到一个问题,就是时间上会增加很多,要慎用。
对背景和前景相差不大的时候,网络尽量不要太深,因为太深的网络到后面基本学到的东西都是相同的,没有很好的区分能力,这也是我在这里为什么不用object detection的原因,这些检测模型网络,深度动辄都是50+,效果反而不好,虽然有残差模块作为backbone。
但是对背景和前景相差很大的时候,可以选择较深的网络,这个时候,object detection方式就派上用场了。
七、缺陷检测~建筑外墙
外观缺陷不仅影响了建筑的美观,也影响了其功能。此外,它们还可能危及行人、居住者和财产。我们基础到目前很多老破小社区建筑都有该现象,现在迫切需要AI实时监测,提高居民安全环境。
现有的基于深度学习的方法在识别速度和模型复杂性方面面临一些挑战。为了保证建筑外墙缺陷检测的准确性和速度,我们研究了了一种改进的YOLOv7方法BFD-YOLO。首先,将YOLOv7中原有的ELAN模块替换为轻量级的MobileOne模块,以减少参数数量并提高推理速度。其次,在模型中加入了坐标注意力模块,增强了特征提取能力。接下来,使用SCYLLA-IoU来加快收敛速度并增加模型的召回率。最后,我们扩展了开放数据集,构建了一个包括三个典型缺陷的建筑立面损伤数据集。BFD-YOLO基于该数据集展示了卓越的准确性和效率。与YOLOv7相比,BFD-YOLO的精度和mAP@.5分别提高了2.2%和2.9%,同时保持了相当的效率。实验结果表明,该方法在保证实时性的前提下,获得了较高的检测精度。
外墙缺陷的存在是建筑运营阶段的一个紧迫问题,通常归因于机械和环境因素。典型的缺陷表现为混凝土剥落、装饰剥落、构件裂缝、大规模变形、瓷砖损伤、潮湿损坏等。这些缺陷会影响外观,降低建筑物的使用寿命。更严重的是,外墙坠物可能会造成安全事故和无法弥补的损失。结构损伤检测是结构健康监测的一个组成部分,对确保建筑物的安全运行至关重要。作为结构损伤检测的一个组成部分,建筑外墙缺陷的检测可以使政府和管理层准确了解建筑外墙的综合状况,从而有助于制定合理的维修方案。这是降低建筑维护成本、延长建筑使用寿命和减轻外墙损坏影响的有效方法。许多国家和地区正在制定定期标准化目视检查的政策。建筑外墙缺陷的检测已成为建筑维护的关键组成部分。
目视检查是评估建筑外观状况的一种简单可靠的方法。传统的建筑外观检查通常需要专业人员带着专用工具到达检查地点,在那里使用视觉观察、锤击和其他技术进行评估。这些方法依赖于检查员的专业知识和经验,这是主观的、危险的和低效的。由于建筑数量的增加和规模的扩大,人工目视检查方法已不足以满足大规模检查的要求。随着技术的进步,许多新方法(如激光扫描、3D热成像和SLAM)正被用于通过无人机和机器人平台进行外墙损伤检测。与传统技术相比,这些新方法更方便、更安全,但耗时且成本高。因此,这些方法在满足大规模检查的需求方面也面临挑战。因此,有必要开发一种更精确、更有效的表面缺陷检测方法,以提高检测效率并降低计算成本。
建筑外墙缺陷有多种类型,不同的检测方法都适用。常见的类型包括裂缝、剥落和墙体空鼓。对于裂纹,有更多的研究使用语义分割进行检测。对于墙体空鼓,敲击法和红外热像法应用更为广泛。我们经过调研和研究,选择了适合目标检测方法且易于构建数据集的缺陷类型。数据集中的图像主要来自通过手机、摄像机和无人机拍摄的建筑立面图像。此外,一些来自互联网和公共数据集的图像也被用于扩展。所有图像的宽度在1000到3000像素之间,高度在2000到5000像素之间。该数据集由三个建筑外墙缺陷组成:分层、剥落和瓷砖损失。总共收集了1907张原始图像,其中包含约2%的背景图像。背景图像是添加到数据集中以减少错误位置的没有缺陷的图像。训练集、验证集和测试集按照7:2:1的比例进行划分。下图显示了数据集中的缺陷示例。

从左到右分别是分层、剥落和瓷砖损耗。
Data Augmentation
在神经网络的模型训练中经常需要大量的数据。然而,获取建筑外墙缺陷的图像相对困难,并且在收集的数据中存在类别不平衡的问题。为了减轻这个问题的影响,我们将数据扩充技术应用于训练数据。数据扩充是对原始数据执行各种转换的常用技术。它被广泛应用于深度学习领域,以系统地生成更多的训练数据。数据扩充可以帮助模型学习更多的数据变化,防止其过度依赖特定的训练样本。监督数据增强技术包括几何变换(例如,翻转、旋转、缩放、裁剪等)和像素变换(例如噪声、模糊、亮度调整、饱和度调整等)。

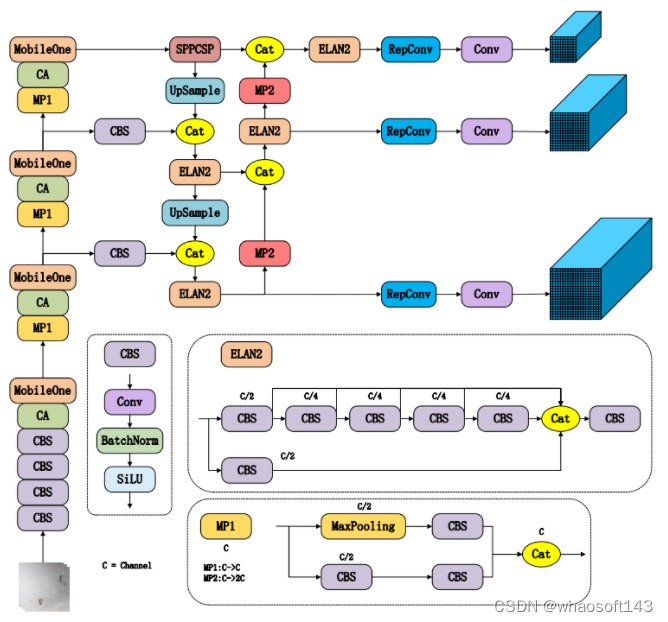
它可以分为主干和头。主干网络的功能是提取特征。YOLOv7的原始主干由几个CBS、MP和ELAN模块组成。CBS是一个由卷积核、批处理规范化和SiLU激活函数组成的模块。议员由MaxPooling和CBS组成。改进后的主干网用MobileOne模块取代了ELAN模块以提高速度,并在每个MobileOne模件后面添加了一个协调注意力模块。所提出的改进方法能够关注输入图像中的显著特征并抑制外来信息,从而有效地提高检测精度。
网络的头是一个PaFPN结构,它由一个SPPPCC、几个ELAN2、CatConv和三个RepVGG块组成。ELAN的设计采用了梯度路径设计策略。与数据路径设计策略相比,梯度路径设计策略侧重于分析梯度的来源和组成,以设计有效利用网络参数的网络架构。该策略的实现可以使网络架构更加轻量级。ELAN和ELAN2之间的区别在于它们的通道数量不同。将结构重新参数化方法应用于RepVGG区块。该方法采用多分支训练结构和单分支推理结构来提高训练性能和推理速度。在输出三个特征图后,头通过三个RepConv模块生成三个不同大小的预测结果。
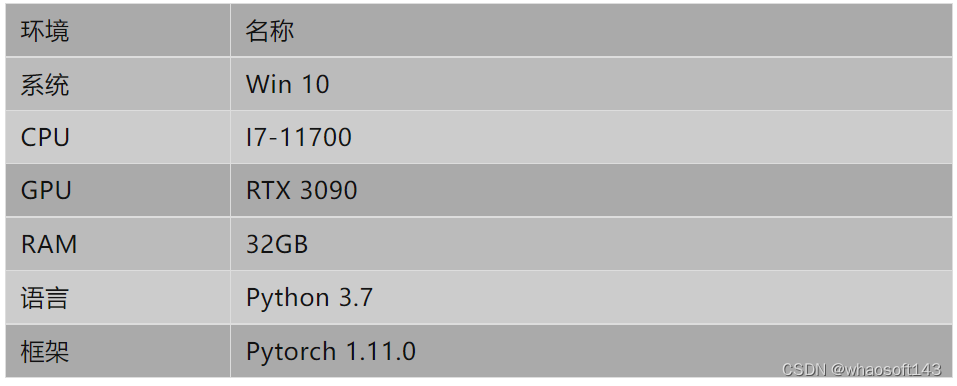
建立了一个实验平台来训练模型并进行测试。实验平台的硬件和软件配置如下表所示。
在训练中,SGD用于模型训练,动量为0.937,权重衰减率为0.0005。Lr0和lrf分别设置为00.1和0.1,这意味着初始学习率为0.01,最终学习率为初始学习率的0.1倍。此外,为了使模型更好地拟合数据,还进行了五个epoch的热身训练。预热训练方法允许模型在最初的几个时期内稳定下来,然后以预设的学习速率进行训练,以更快地收敛。所有训练都是用150个epoch进行的,批次大小设置为16。

八、Anomalib
这里说说如何应用Anomalib在数据集不平衡的情况下检测缺陷
Paula Ramos,英特尔 AI 软件布道师,美国 武卓,英特尔 AI 软件布道师,中国 Samet Akcay,英特尔人工智能研究工程师/科学家
在《如何应用Anomalib在数据集不平衡的情况下检测缺陷?》https://mp.weixin.qq.com/s/VWugI_01bh9otZzDuiQz-A中,我们介绍了深度学习异常检测库 Anomalib。简而言之,当您想进行自动缺陷检测,但数据集不平衡时,Anomalib 是一个很好的工具。
希望您已经通过入门 notebook 访问并亲自试用了这个开源项目。如果没有,请不要担心,这篇博文将教您如何结合自己的数据集使用 Anomalib。
在这个示例中,我们将介绍一个令人振奋的 Dobot 机器人工业用例,其中的机械臂用于教育、工业和智能用例中。如果您没有可用的 Dobot 机器人,您可以简单地修改 notebook,避开、注释或改变机器人代码,使其为您所用。
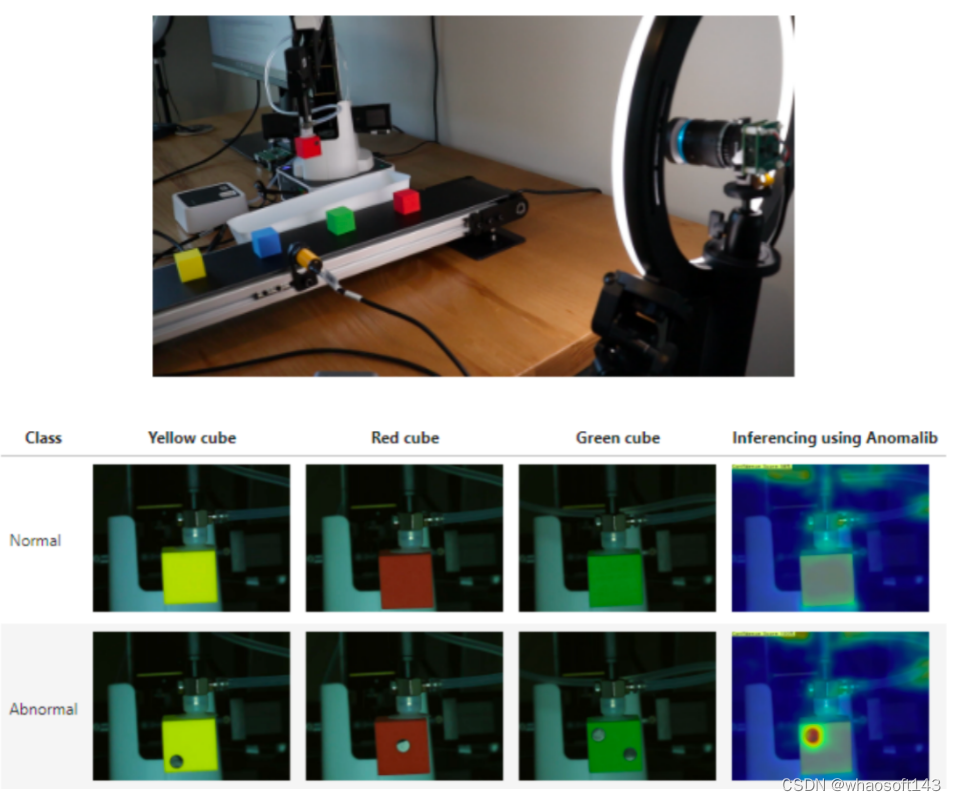
图 1:使用教育机器人进行基于 Anomalib 的缺陷检测。
为了解 Anomalib 的工作原理,我们将看一个检查彩色立方体的生产线(图 1)。其中一些立方体会有洞或缺陷,需要从传送带上取下。由于这些缺陷在生产线上并不常见,我们将为我们的 AI 模型拍摄一些图像。
安装:
按照以下步骤使用源文件安装 Anomalib:
1.使用 Python 3.8 版本创建运行 Anomalib + Dobot DLL 的环境
- 对于 Windows,使用以下代码:
python -m venv anomalib_env
anomalib_env\Scripts\activate- 对于 Ubuntu:
python3 -m venv anomalib_env
source anomalib_env/bin/activate2.从 GitHub 存储库中安装 Anomalib 及 OpenVINO™ 要求(在这篇博文中,我们将不使用 pip 安装命令):
python –m pip install –upgrade pip wheel setuptools
git clone https://github.com/openvinotoolkit/anomalib.git
cd anomalib
pip install -e . [openvino]3.安装 Jupyter Lab 或 Jupyter Notebook:https://jupyter.org/install
pip install notebook
pip install ipywidgets4.然后连接您的 USB 摄像头,使用简单的摄像头应用验证它在正常工作。然后,关闭该应用。
可选:如果您可以访问 Dobot,请实施以下步骤:
- 安装 Dobot 要求(更多信息请参考 Dobot 文档)。
- 检查 Dobot 的所有连接状态,并使用 Dobot Studio 验证它在正常工作。
- 将通风配件安装在 Dobot 上,并使用 Dobot Studio 验证它在正常工作。
- 在 Dobot Studio(图 2)中,点击“Home”按钮,找到:
- 校准坐标:立方体阵列的左上角初始位置。
- 位置坐标:机械臂应将立方体放在传送带上方的位置。
- 异常坐标:释放异常立方体的位置。
- 然后在 notebook 中替换这些坐标。有关该步骤的更多说明,请参考自述文件。
5.如需使用机器人运行 notebook,从这里下载 Dobot API 和驱动程序文件,并将它们添加到存储库 Anomalib 文件夹的 notebooks/500_uses_cases/dobot 中。

图 2:Dobot Studio 界面。
注:如果没有机器人,您可以转到另一个 notebook,如 501b notebook,通过这个链接下载数据集,并在那里尝试训练和推理。
Notebook 的数据采集和推理
下面,我们需要使用正常的数据集创建文件夹。在这个示例中,我们创建了一个彩色立方体的数据集,并为异常情况添加一个黑色圆圈贴纸,以模拟盒子上的洞或缺陷(图 3)。对于数据采集和推理,我们将使用 501a notebook。
图 3:用于第一轮训练的数据集。
在采集数据时,请务必将 acquisition 变量设置 为 True 来运行notebook,并为没有异常的数据定义“正常”文件夹,为异常图像定义“异常”文件夹。数据集将直接在 Anomalib 克隆的文件夹中创建,所以我们将看到 Anomalib/dataset/cubes 文件夹。
如果您没有机器人,您可以修改代码以保存图像或使用下载的数据集进行训练。
推理:
对于推理,acquisition 变量应该是 False,我们不会保存任何图像。我们将读取采集到的视频帧,使用 OpenVINO 运行推理,并决定放置立方体的位置:对于正常立方体,放置在传送带上;对于异常立方体,放置在传送带外。
我们需要识别采集标记 — 采集模式为 True,推理模式为 False。在采集模式下,要注意是创建正常还是异常文件夹。例如,在采集模式下,notebook 会将每张图像保存在 anomalib/datasets/cubes/{FOLDER} 中,以便进一步训练。在推理模式下,notebook 不会保存图像;它将运行推理并显示结果。
训练:
对于训练,我们将使用 501b notebook。在这个 notebook 中,我们将使用 PyTorch Lighting,并使用“Padim”模型进行训练。这种模型有几个优点:我们不需要 GPU,只用 CPU 就可以完成训练过程,而且训练速度也很快。
现在,让我们深入了解一下训练 notebook!
导入
在这一部分,我们将解释用于该示例的软件包。我们还将从 Anomalib 库中调用需要使用的软件包。
配置:
有两种方法来配置 Anomalib 模块,一种是使用配置文件,另一种是使用 API。最简单的方法是通过 API 查看该库的功能。如果您希望在您的生产系统中实施 Anomalib,请使用配置文件(YAML 文件),它是核心训练与测试进程,包含数据集、模型、试验和回调管理(图 4)。
在接下来的部分,我们将描述如何使用 API 配置您的训练。
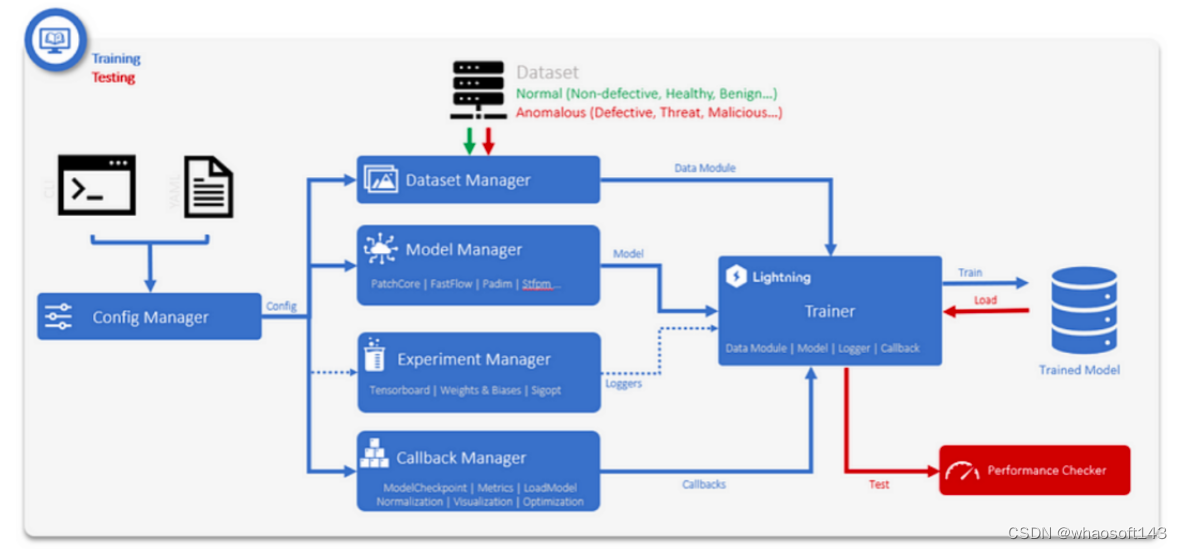
图 4:训练和验证模块。
数据集管理器:
通过 API,我们可以修改数据集模块。我们将准备数据集路径、格式、图像大小、批量大小和任务类型。然后,我们使用以下代码将数据加载到管道中。
i, data = next(enumerate(datamodule.val_dataloader()))模型管理器:
对于异常检测模型,我们使用 Padim,您也可以使用其他 Anomalib 模型,如:CFlow、CS-Flow、DFKDE、DFM、DRAEM、FastFlow、Ganomaly Patchcore、Reverse Distillation 和 STFPM。此外,我们使用 API 设置了模型管理器;使用 anomalib.models 导入 Padim。
回调(Callbacks)管理器:
为了适当地训练模型,我们需要添加一些其他的“非基础”逻辑,如保存权重、尽早终止、以异常分数为基准以及将输入/输出图像可视化。为了实现这些,我们使用回调Callbacks。Anomalib 有自己的Callbacks,并支持 PyTorch Lightning 的本地callbacks。通过该代码,我们将创建在训练期间执行的回调列表:https://gist.github.com/paularamo/581d6c99504e673a8147e77995478624。
训练:
在设置数据模块、模型和callbacks之后,我们可以训练模型了。训练模型所需的最后一个组件是 pytorch_lightning Trainer 对象,它可处理训练、测试和预测管道。查看 notebook 中的 Trainer 对象示例:https://gist.github.com/paularamo/e25957185d41798c869aec9b8d127c24。
验证:
我们使用 OpenVINO 推理进行验证。在之前的导入部分,我们导入了 anomalib.deploy 模块中的 OpenVINOInferencer。现在,我们将用它来运行推理并检查结果。首先,我们需要检查 OpenVINO 模型是否在结果文件夹中。
预测结果:
为了实施推理,我们需要从 OpenVINOinference(我们可在其中设置 OpenVINO 模型及其元数据)中调用 predict 方法,并确定需要使用的设备:
predictions = inferencer.predict(image=image)预测包含与结果有关的各种信息:原始图像、预测分数、异常图、热图图像、预测掩码和分割结果(图 5)。根据您要选择的任务类型,您可能需要更多信息。

图 5:预测结果
最后,我们采用 Dobot 机器人的缺陷检测用例基本是这样的(图 6)。

图 6:运行 Anomalib 模型推理的教育机器人。
使用您自己的数据集的技巧和建议
数据集转换:
如果您想提高模型的准确性,您可以在您的训练管道中应用数据转换。您应该在 config.yaml 的 dataset.transform_config 部分提供增强配置文件的路径。这意味着您需要有一个用于 Anomalib 设置的 config.yaml 文件,以及一个可供 Anomalib config yaml 文件使用的单独 albumentations_config.yaml 文件。
在这个讨论帖中:https://github.com/openvinotoolkit/anomalib/discussions/737,您可以学习如何将数据转换添加到您的实际训练管道。
强大的模型:
异常检测库并非无所不能,在碰到麻烦的数据集时也可能会失效。好消息是:您可以尝试 13 个不同的模型,并能对每个实验的结果进行基准测试。您可以将基准测试入口点脚本用于其中,并将配置文件用于基准测试目的。这将帮助您为实际用例选择最佳模型。
如需更多指南,请查看“操作指南”https://openvinotoolkit.github.io/anomalib/how_to_guides/index.html。
Paula Ramos 自 21 世纪初以来一直在哥伦比亚开发新型集成工程技术,主要涉及计算机视觉、机器人和机器学习在农业领域的应用。在攻读博士和研究生学位期间,她部署了多个低成本的智能边缘和物联网计算技术,这些技术可供农民等不具备计算机视觉系统专业知识的人员操作。她的发明可在严苛和紧急的条件下运行,如没有照明控制的农业和户外环境,也可从容应对高太阳辐射条件、甚至极端高温条件。目前,她是英特尔 AI 软件布道师,负责开发能够理解和重新创造周围视觉世界以满足现实需求的智能系统/机器。
Samet Akcay 是人工智能研究工程师/科学家。他的主要研究兴趣包括实时图像分类、检测、异常检测,以及基于深度/机器学习算法的无监督特征学习。他最近与人联合开发了开源的 Anomalib,这是该领域最大的异常检测库之一。Samet 拥有英国杜伦大学计算机科学系的博士学位,并获得了美国宾夕法尼亚州立大学电气工程系 Robust Machine Intelligence Lab 的硕士学位。他在顶级的计算机视觉和机器/深度学习会议和期刊上发表了 30 多篇学术论文。
武卓是英特尔 AI 软件布道师,专注于 OpenVINO™ 工具套件的研究。她的工作职责涵盖了从深度学习技术到 5G 无线通信技术的领域。她在计算机视觉、机器学习、边缘计算、物联网系统和无线通信物理层算法等方面做出了卓越贡献。她为汽车、银行、保险等不同行业的企业客户提供基于机器学习和深度学习的端到端解决方案,在 4G-LTE 和 5G 无线通信系统方面进行了广泛研究,并曾在中国贝尔实验室担任研究科学家,期间申请了多项专利。她在上海大学担任副教授时,曾作为主要研究人员主导过多个研究项目。
九、织物缺陷图像识别方法分析
纺织业在是中国最大的日常使用及消耗相关的产业之一,且劳动工人多,生产量和对外出口量很大,纺织业的发展影响着中国经济、社会就业问题。而织物产品的质量直接影响产品的价格,进一步影响着整个行业的发展,因此纺织品质量检验是织物产业链中必不可少且至关重要的环节之一。
织物缺陷检测是纺织品检验中最重要的检验项目之一,其主要目的是为了避免织物缺陷影响布匹质量,进而极大影响纺织品的价值和销售。
长期以来,布匹的质量监测都是由人工肉眼观察完成,按照工作人员自己的经验对织物质量进行评判,这种方法明显具有许多缺点。首先,机械化程度太低,人工验布的速度非常慢;其次,人工视觉检测的评价方法因受检测人员的主观因素的影响不够客观一致,因而经常会产生误检和漏检。
目前,基于图像的织物疵点自动检测技术已成为了该领域近年来的的研究热点,其代替人工织物疵点检测的研究算法也逐渐成为可能,主流方法一般分为两大类, 一是基于传统图像处理的织物缺陷检测方法,二是基于深度学习算法的织物缺陷检测定位方法。
传统的目标检测方法主要可以表示为:特征提取-识别-定位, 将特征提取和目标检测分成两部分完成。
基于深度学习的目标检测主要可以表示为:图像的深度特征提取-基于深度神经网络的目标定位, 其中主要用到卷积神经网络。
1
织物表面缺陷检测分析
正常情况下,织物表面的每一个异常部分都被认为是织物的缺陷。
在实践中, 织物的缺陷一般是由机器故障、纱线问题和油污等造成的,如断经纬疵、粗细经纬疵、 破损疵、 起球疵、 破洞疵、 污渍疵等。然而,随着织物图案越来越复杂,相应的织物缺陷类型也越来越多,并随着纺织技术的提高, 缺陷的大小范围越来越小。在质量标准方面,一些典型的织物缺陷如图所示。

各类模式织物表面的疵点图像
由纺线到成品织物,需经过纱线纺织、裁剪、图案印染等流程,而且在每个流程中,又需要很多的程序才能完成。在各环节的施工中,如果设定条件不合适, 工作人员操作不规范,机器出现的硬件问题故障等,都有可能导致最后的纺织品发生表面存在缺陷。从理论上说,加工流程越多,则缺陷问题的机率就越高。

最常见的疵点类型及形成原因
随着科技水平的进步,纺织布匹的技术不断随之发展,疵点的面积区域必将越来越小,这无疑给织物疵点检测带来了更大的难题。疵点部分过小,之前的方法很难将其检测出来。

检测存在困难的织物疵点类型
2
图像采集与数据库构建
基于深度学习的织物疵点检测方法相比传统的方法,虽然具有检测速率快,误检率低,检测精度高等优点, 但这些方法是依赖于大量的训练数据库基础之上的。只有在训练阶段包含了尽量多的织物疵点图像,尽可能的把每种疵点的类型都输入训练网络,这样对于网络模型来说,才能反复的熟悉疵点的“模样”,即获得疵点位置的特征信息,从而记住疵点的特征信息,以在以后的检测过程中可以更好更快更准的检测到疵点的位置并标识。
首先搭建由光源、 镜头、相机、 图像处理卡及执行机构组成的织物图像采集系统,然后基于本系统,采集破洞、油污、起毛不均、漏针、撑痕、粗节等一定规模的织物疵点图像,并通过转置、 高斯滤波、图像增强等操作扩充织物图像,构建了织物图像库,为后续深度学习提供了样本支撑。

织物图像采集系统整体结构图
相机选择
工业相机是图像采集系统中的一个关键组成部分,它的好坏字节影响后续所有工作,其最终目的是得到图像数字信号。相机的选择,是必不可少的环节之一,相机的选择不仅直接影响所采集到的图像质量, 同时也与整个系统后续的运行模式直接关联。

镜头选择
镜头选择
和工业相机一样, 是图像采集系统中非常重要的的器件之一, 直接影响图片质量的好坏, 影响后续处理结果的质量和效果。同样的, 根据不同标准光学镜头可以分成不同的类, 镜头摆放实物图如图所示。

光源选择
光源的选择
也是图像采集系统中重要的组成部分,一般光的来源在日光灯和LED 灯中选择,从不同的性能对两种类型的光源进行比较。而在使用织物图像采集系统采集图像的过程中, 需要长时间进行图像采集, 同时必须保证光的稳定性等其他原因,相比于日光灯, LED 灯更适合于图像采集系统的应用。

发射光源种类确定了,接下来就是灯的位置摆放问题,光源的位置也至关重要,其可以直接影响拍出来图片的质量,更直接影响疵点部位与正常部位的差别。一般有反射和投射两种给光方式,反射既是在从布匹的斜上方投射光源,使其通过反射到相机,完成图像拍摄;另外一种透射,是在布匹的下方投射光源,使光线穿过布匹再投射到相机,完成图签拍摄,光源的安装方式对应的采集图像如下图所示。


不同光源照射的效果对比图
数据库构建
TILDA 织物图像数据库包含多种类型背景纹理的织物图像,从中选择了数据相对稍大的平纹背景的织物图像,包含 185 张疵点图像,但该图像数据存在很大的问题:虽然图片背景是均匀的,但是在没有疵点的正常背景下,织物纹理不够清晰,纹理空间不均匀,存在一些没有瑕疵,但是纹理和灰度值与整体正常背景不同的情况。

TILDA 织物图像库部分疵点图像
3
织物缺陷图像识别算法研究
由于织物纹理复杂性, 织物疵点检测是一项具有挑战性的工作。传统的检测算法不能很好的做到实时性检测的同时保持高检测率。卷积神经网络技术的出现为这一目标提供了很好的解决方案。
基于 SSD 神经网络的织物疵点检测定位方法:
步骤一:将数据集的 80% 的部分作为训练集和验证集,再将训练集占其中80% ,验证集占 20% ,剩余 20% 的部分作为测试集,得到最终的实验结果。

步骤二:将待检测的织物图像输入到步骤一训练好的织物检测模型,对织物图像进行特征提取,选取出多个可能是疵点目标的候选框。
步骤三:基于设定好的判别阈值对步骤二中的候选框进行判别得到最终的疵点目标,利用疵点目标所在候选框的交并比阈值选择疵点目标框,存储疵点的位置坐标信息并输出疵点目标框。
这个算法对平纹织物和模式织物均具有很好的自适应性及检测性能, 扩大了适用范围, 检测精度高,有效解决人工检测误差大的问题,模型易训练,操作简单。

织物疵点图像检测结果
随着深度学习技术飞速发展, 以及计算机等硬件水平的不断提升, 卷积神经网络在工业现场的应用将随之不断扩大, 织物表面疵点检测作为工业表面检测的代表性应用产业, 其应用发展将影响着整个工业领域。

















 1664
1664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









