







我自己的原文哦~ https://blog.51cto.com/whaosoft/11547799
#Llama 3.1
美国太平洋时间 7 月 23 日,Meta 公司发布了其最新的 AI 模型 Llama 3.1,这是一个里程碑时刻。Llama 3.1 的发布让我们看到了开源 LLM 有与闭源 LLM 一较高下的能力。
Meta 表示,“到目前为止,开源 LLM 在功能和性能方面大多落后于闭源模型。现在,我们正迎来一个由开源引领的新时代。”
Meta 称 Llama 3.1 是目前最强的生成式 AI 产品。4 月份,Meta 已经发布了 Llama 3,被称为是 “我们最先进的开源 LLM 的下一代产品”。
此次 Llama 3.1 发布的产品有 8B、70B 和 405B 三个尺寸。
其中最受关注的是 Llama 3.1 405B。Meta 表示 Llama 3.1 405B 是目前全球最大、功能最强的公共基础模型,可与 OpenAI 和 Google 开发的顶级模型一争高下。
Meta 在官方博客中表示:“Llama 3.1 405B 是首个公开可用的模型,在通用常识、可引导性、数学、工具使用和多语言翻译方面可与顶级 AI 模型相媲美。405B 模型的发布将带来前所未有的创新和探索机会。”
Meta 称他们在超过 150 个基准数据集上进行了性能评估,并将 Llama 3.1 与竞品进行了比较,结果显示 Llama 3.1 405B 在各项任务中都有能力与当前最先进的闭源模型一较高下。
8B 和 70B 在与同级别的小参数模型对比中也表现优异。
Llama 3 的推出以及 Meta 向生成式 AI 的全面转型,使得这一产品被广泛应用于 Meta 的大多数产品线,包括 Instagram、Messenger 和 WhatsApp。
此外,Meta CEO 扎克伯格表示,将 AI 作为开源工具向所有人开放也非常重要。
扎克伯格在一篇文章中写道:“开源将确保世界上更多的人能享受到 AI 带来的红利和机会。这种权利不应该集中在少数公司手中,而且这项技术可以更均衡、更安全地部署到整个社会。”
Meta 开发开源 AI 模型的努力也促使其他 AI 开发者,包括去中心化 AI 公司 Venice AI、Brave 浏览器开发者 Brave 和 Perplexity AI,将 Llama 3 添加到他们的平台上。
Venice AI 创始人 Erik Voorhees 在 5 月的一次 Twitter Space 中表示:“Meta 值得高度赞扬,因为他们花费了数亿美元来训练一个最先进的模型,并免费向全世界开放。”
Meta 表示,在提供更多功能的过程中,开发 Llama 3.1 405B 面临的最大挑战是模型规模的整体增长,支持更大的 12800,0-token 上下文窗口,并提供多语言支持。根据该公司表示,其 Meta AI 现在可以用法语、德语、印地语、意大利语、葡萄牙语和西班牙语进行响应。
关于 AI 安全性方面,扎克伯格强调 AI 应避免所有类型的伤害。
扎克伯格表示:“非故意伤害是指即使操作人员无意,AI 系统也可能造成伤害。故意伤害是指不法分子使用 AI 模型故意造成伤害。”
在故意滥用的情况下,主要的 AI 开发者 —— 包括 Meta、Anthropic、OpenAI、Google 和 Microsoft—— 对与选举相关的提示施加了限制,以遏制使用其模型传播错误信息。
扎克伯格指出,非故意伤害涵盖了人们对 AI 的大部分担忧,并表示开源软件的透明性也有助于缓解这些担忧。Llama 3 的发布还包括 Llama Guard 3,一款旨在监控和执行模型道德使用的工具。
扎克伯格表示:“从历史角度看,开源软件因此更加安全。同样,使用 Llama 及其安全系统如 Llama Guard 可能比闭源模型更安全。”
扎克伯格接着表示,他相信 Llama 3.1 的发布将成为 AI 行业的一个拐点。
扎克伯格说:“归根结底,开源 AI 代表了世界上最好的一次利用这项技术创造最大经济机会和安全性的机会。”
#Llama成大模型顶流
扎克伯格掀论战:玩开源,时代变了
开源与闭源的纷争已久,现在或许已经达到了一个新的高潮。
说到开源大模型,Llama 系列自诞生以来就是典型代表,其优秀的性能与开源特点让人工智能技术的应用性和可访问性大大提升。任何研究人员和开发者都能够从中获益,让研究和应用变得更加广泛。
现在,Meta Llama 3.1 405B 正式发布。在官方博客中,Meta 表示:「直到今天,开源大语言模型在功能和性能方面大多落后于封闭模型。现在,我们正在迎来一个开源引领的新时代。」
与此同时,Meta 创始人、CEO 扎克伯格亲自撰写长文阐述开源对所有开发者、对 Meta、对世界的意义。他表示,开源是 AI 积极发展的必要条件。以 Unix 和 Linux 的发展为例,开源 AI 将更有利于创新、数据保护和成本效益。
他还认为,开源 Llama 模型能够建立一个完整的生态系统,确保技术进步,并且不会因为竞争而失去优势。Meta 有着成功的开源历史,通过开源 AI 模型,扎克伯格希望促进全球技术的平等和安全应用。
原文链接:https://about.fb.com/news/2024/07/open-source-ai-is-the-path-forward/
以下是原文内容:
扎克伯克为 Meta 注入开源基因
在高性能计算的早期,各大主流科技公司都投入大量资金开发各自的闭源 Unix 版本。当时很难想象会有其他方法能开发出如此先进的软件。
然而,开源的 Linux 逐渐流行起来:最初是因为它允许开发人员自由修改代码且价格更实惠,而后来它变得更先进、更安全,并且拥有比任何闭源 Unix 更广泛的生态系统,支持更多的功能。今天,Linux 已成为云计算和运行大多数移动设备的操作系统的行业标准基础, 大家都因其卓越的产品受益。
我相信人工智能的发展也与其发展轨迹类似。今天,一些科技公司正在开发领先的闭源模型,但开源正在迅速缩小差距。
去年,Llama 2 仅能与一代旧型号相媲美。而在今年,Llama 3 在某些领域已经可以与行业中领先的模型竞争甚至领先。明年开始,我们预计未来的 Llama 模型将成为行业中最先进的大模型。在此之前,Llama 也已经在开放性、可修改性和成本效益方面领先。
今天,我们正迈出下一步 —— 使开源 AI 成为行业标准。我们发布了首个前沿级开源 AI 模型 Llama 3.1 405B,以及改进版的 Llama 3.1 70B 和 8B 模型。较于闭源模型,这些开源模型在成本效益上显著提升,特别是 405B 模型的开源特性,使其成为微调和蒸馏小型模型的最佳选择。
除了发布这些模型,我们还与多家公司合作,拓展更广泛的生态系统。亚马逊、Databricks 和英伟达正在推出全套服务,支持开发者微调和蒸馏他们自己的模型。像 Groq 这样的创新者已经为所有新模型构建了低延迟、低成本的推理服务。
这些模型将在包括 AWS、Azure、Google、Oracle 等所有主要云平台上可用。Scale.AI、戴尔、德勤等公司已经准备好帮助企业采用 Llama 并使用他们自己的数据训练定制模型。随着社区的成长和更多公司开发新服务,我们可以共同使 Llama 成为行业标准,并将 AI 的益处带给每个人。
Meta 致力于开源 AI,以下是我认为开源是最佳开发平台的原因,为什么开源 Llama 对 Meta 有利,以及为什么开源 AI 对世界有益,并由此将长期存在。
开源 AI 之于开发者
当我与全球的开发者、CEO 和政府官员交谈时,通常听到几个主题:
- 我们需要训练、微调和蒸馏自己的模型。每个组织都有不同的需求,这些需求最好通过使用不同规模并使用特定数据训练或微调的模型来满足。设备上的任务和分类任务需要小型模型,而更复杂的任务则需要大型模型。现在,你可以使用最先进的 Llama 模型,继续用自己的数据训练它们,然后将它们蒸馏成最适合你需求的模型规模 —— 无需我们或任何其他人看到你的数据。
- 我们需要掌控自己的命运,而不是被闭源供应商「锁死」。许多组织不希望依赖他们无法自己运行和控制的模型。他们不希望闭源模型供应商能够更改模型、改变使用条款,甚至完全停止服务。他们也不希望被锁定在拥有模型专有权的单一云平台上。开源使得兼容工具链的广泛生态系统成为可能,你可以轻松地在这些工具之间切换。
- 我们需要保护我们的数据。许多组织处理需要保护的敏感数据,无法通过云 API 发送到闭源模型。一些组织则根本不信任闭源模型供应商对其数据的处理。开源解决了这些问题,因为它使你可以在任何你想要的地方运行模型。众所周知,开源软件会因为开发过程更加透明,而更安全。
- 我们需要一个高效且经济的模型。开发者可以在自己的基础设施上运行 Llama 3.1 405B,进行推理,成本大约是使用闭源模型(如 GPT-4)的 50%,适用于用户端和离线推理任务。
- 我们希望投资于将成为长期标准的生态系统。许多人看到开源的发展速度快于封闭模型,他们希望在能够长期提供最大优势的架构上构建自己的系统。
开源 AI 之于 Meta
Meta 的商业模式是为人们构建最佳体验和服务。为了实现这一目标,我们必须确保始终能够获取最佳技术,而不是被锁定在竞争对手的封闭生态系统中,这样他们就不能限制我们所开发的内容。
我想分享一个重要经历:虽然苹果公司允许我们在其平台上构建内容,但是当我们构建服务时仍受到了限制。无论是他们对开发者的税收、他们施加的任意规则,还是他们阻止的所有产品创新,显而易见,如果我们能够构建产品的最佳版本,并且竞争对手无法限制我们构建的内容,Meta 和许多其他公司将能够为人们提供更好的服务。从哲学层面上讲,这也是我如此坚信在 AI 和 AR/VR 领域为下一代计算机建立开放生态系统的一个重要原因。
人们常常问我是否担心因为开源 Llama 而失去技术优势,但我认为这忽略了大局,原因有以下几点:
首先,为了确保我们能够长期保持技术领先,并且不被锁定在闭源生态系统中,Llama 需要发展成一个完整的生态系统,包括工具、效率改进、硬件优化和其他集成。如果只有我们公司使用 Llama,这个生态系统将不会发展,我们的境况也不会比 Unix 的闭源变种好多少。
其次,我预计 AI 开发将继续保持高度竞争,这意味着在任何给定时刻,开源某个模型不会使我们在与下一个最佳模型的竞争中失去巨大优势。Llama 成为行业标准的途径是通过一代又一代地保持竞争力、高效性和开放性。
第三,Meta 与闭源模型提供商的一个关键区别在于,销售 AI 模型的访问权限并不是我们的商业模式。这意味着公开发布 Llama 不会削弱我们的收入、可持续性或投资研究的能力,而闭源提供商则会受到影响。(这也是为什么一些闭源提供商一直在游说公共管理者反对开源的原因之一。)
最后,Meta 在开源项目上有着丰富的成功经验。通过与开放计算项目分享我们的服务器、网络和数据中心设计,并使供应链标准化,我们节省了数十亿美元。通过开源 PyTorch、React 等领先工具,我们从生态系统的创新中受益匪浅。这种方法长期以来一直极具效果。
开源 AI 之于世界
我相信开源对于 AI 的未来是有必要的。AI 比任何其他现代技术都更有潜力提高人类的生产力、创造力和生活质量,并且能够在加速经济增长的同时推动医学和科学研究的进步。开源将确保全球更多的人能够从 AI 的发展中获得利益和机会,权力不会集中在少数几家公司手中,并且技术能够更均匀和安全地在社会中部署。
关于开源 AI 模型的安全性,存在着持续的争论。我的观点是,开源 AI 将比替代方案更安全。我认为各国政府最终会得出支持开源的结论,因为这将使世界更加繁荣和安全。
在我理解的安全性框架中,我们需要防范两类危害:无意和故意。
- 无意的危害是指 AI 系统可能在运行时非故意地造成伤害。例如,现代 AI 模型可能在无意中给出错误的健康建议。或者,在未来场景中,有人担心模型可能会无意中自我复制或过度优化目标,从而对人类造成损害。
- 故意的危害是指不良行为者使用 AI 模型以造成伤害为目的。
值得注意的是,无意的危害涵盖了人们对 AI 的多数担忧 —— 从 AI 系统对数十亿用户的影响到大多数真正灾难性的科幻场景。在这方面,开源所带来的安全性更加显著,因为系统更透明,可以被广泛审查。
历史上,开源软件由于这一原因一直更安全。同样,使用 Llama 及其安全系统如 Llama Guard,可能会比闭源模型更安全和更可靠。因此,大多数关于开源 AI 安全性的讨论集中在故意的危害上。
我们的安全流程包括严格的测试和红队评估,以检验我们的模型是否有可能造成实质性伤害,此目标是在发布前减轻风险。由于这些模型是开源的,任何人都可以自行进行测试。我们必须牢记,这些模型是通过互联网上已有的信息训练的,所以在考虑危害时,起点应该是模型是否能比从 Google 或其他搜索结果快速获取的信息造成更多的危害。
通过区分个体或小规模行为者与拥有大量资源的大规模行为者(如国家)所能做的事情,将会有益于推理故意伤害。
在未来的某个时候,个别恶意行为者可能会利用 AI 模型的智能,从互联网上现有的信息中制造出新型危害。在这一点上,力量的均衡对 AI 安全至关重要。
我认为生活在一个 AI 广泛部署的世界中会更好,因为这样可以使大型行为者制衡小型恶意行为者。这也是我们在社交网络上管理安全的方式,凭借更强大的 AI 系统识别并阻止那些经常使用小规模 AI 系统的不太复杂的行为者。
更广泛地说,大型机构在大规模部署 AI 时将促进社会的安全和稳定。只要每个人都能访问类似代际的模型,那么拥有更多算力资源的政府和机构将能够制衡拥有较少计算资源的恶意行为者。
在考虑未来的机遇时,请记住,今天的大多数领先科技公司和科学研究都是建立在开源软件之上的。如果我们共同投资于开源 AI,下一代公司和研究就会获得使用的机会。这包括刚刚起步的初创企业,以及那些可能没有资源从头开发 SOTA AI 的大学和国家的人们。
总而言之,开源 AI 代表了在全球范围内我们可以利用这项技术为所有人创造最大的经济机会和安全保障。
合作行稳,开源致远
在过去的 Llama 模型中,Meta 为自身开发发布了这些模型,但并未重点关注建立更广泛的生态系统。这次发布,我们采取了不同的方式。我们正在内部组建团队,使尽可能多的开发者和合作伙伴能够使用 Llama,并且积极建立合作伙伴关系,以便生态系统中的更多公司能够为他们的客户提供独特的功能。
我相信 Llama 3.1 的发布将成为行业的一个转折点,大多数开发者将开始使用开源技术,我预计这种方式将会以我们的开源为起点。
我希望我们可以共同努力将 AI 的益处带给全世界。
你现在可以在 llama.meta.com 上访问这些模型。
马克·扎克伯格
#击败GPT-4o的开源模型如何炼成
经历了提前两天的「意外泄露」之后,Llama 3.1 终于在昨夜由官方正式发布了。
Llama 3.1 将上下文长度扩展到了 128K,拥有 8B、70B 和 405B 三个版本,再次以一已之力抬高了大模型赛道的竞争标准。
对 AI 社区来说,Llama 3.1 405B 最重要的意义是刷新了开源基础模型的能力上限,Meta 官方称,在一系列任务中,其性能可与最好的闭源模型相媲美。
下表展示了当前 Llama 3 系列模型在关键基准测试上的性能。可以看出,405B 模型的性能与 GPT-4o 十分接近。
与此同时,Meta 公布了《The Llama 3 Herd of Models》论文,揭示了 Llama 3 系列模型迄今为止的研究细节。
论文地址:https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
接下来,让我们看一下论文内容。
Llama3 论文亮点
1、在使用 8K 上下文长度进行预训练后,Llama 3.1 405B 使用 128K 上下文长度进行连续训练,且支持多语言和工具使用。
2、与以前的 Llama 模型相比,Meta 加强了预处理和预训练数据的 Curation pipelines,以及后训练数据的质量保证和过滤方法。
Meta 认为,高质量基础模型的开发有三个关键杠杆:数据、规模和复杂性管理。
首先,与 Llama 的早期版本相比,Meta 在数量和质量两方面改进了用于预训练和后训练的数据。Meta 在大约 15 万亿的多语言 Token 语料库上对 Llama 3 进行了预训练,相比之下,Llama 2 只使用了 1.8 万亿 Token。
此次训练的模型规模远大于以前的 Llama 模型:旗舰语言模型使用了 3.8 × 10²⁵ 次浮点运算(FLOPs)进行预训练,超过 Llama 2 的最大版本近 50 倍。
基于 Scaling law,在 Meta 的训练预算下,当前的旗舰模型已是近似计算最优的规模,但 Meta 对较小模型进行的训练时间已经远超计算最优的时长。结果表明,这些较小模型在相同推理预算下的表现优于计算最优模型。在后训练阶段,Meta 使用了 405B 的旗舰模型进一步提高了 70B 和 8B 模型这些较小模型的质量。
3、为了支持 405B 模型的大规模生产推理,Meta 将 16 位 (BF16) 量化为 8 位 (FP8),从而降低了计算要求,并使模型能够在单个服务器节点上运行。
4、在 15.6T token(3.8x10²⁵ FLOPs)上预训练 405B 是一项重大挑战,Meta 优化了整个训练堆栈,并使用了超过 16K H100 GPU。
正如 PyTorch 创始人、Meta 杰出工程师 Soumith Chintala 所说,Llama3 论文揭示了许多很酷的细节,其中之一就是基础设施的构建。
5、在后训练中,Meta 通过多轮对齐来完善 Chat 模型,其中包括监督微调(SFT)、拒绝采样和直接偏好优化。大多数 SFT 样本由合成数据生成。
研究者在设计中做出了一些选择,以最大化模型开发过程的可扩展性。例如,选择标准的密集 Transformer 模型架构,只进行了少量调整,而不是采用专家混合模型,以最大限度地提高训练的稳定性。同样,采用相对简单的后训练程序,基于监督微调(SFT)、拒绝采样(RS)和直接偏好优化(DPO),而不是更复杂的强化学习算法, 因为后者往往稳定性较差且更难扩展。
6、作为 Llama 3 开发过程的一部分,Meta 团队还开发了模型的多模态扩展,使其具备图像识别、视频识别和语音理解的能力。这些模型仍在积极开发中,尚未准备好发布,但论文展示了对这些多模态模型进行初步实验的结果。
7、Meta 更新了许可证,允许开发者使用 Llama 模型的输出结果来增强其他模型。
在这篇论文的最后,我们还看到了长长的贡献者名单:
这一系列因素,最终造就了今天的 Llama 3 系列。
当然,对于普通开发者来说,如何利用 405B 规模的模型是一项挑战,需要大量的计算资源和专业知识。
发布之后,Llama 3.1 的生态系统已准备就绪,超过 25 个合作伙伴提供了可与最新模型搭配使用的服务,包括亚马逊云科技、NVIDIA、Databricks、Groq、Dell、Azure、Google Cloud 和 Snowflake 等。
#数学大统一理论里程碑进展
几何朗兰兹猜想获证明
历经三十年的努力,数学家已经成功证明了一个名为「朗兰兹纲领(Langlands program)」的宏大数学愿景的主要部分。
一个由 9 位数学家组成的团队成功证明了几何朗兰兹猜想(Geometric Langlands Conjecture),这是现代数学领域涉及范围最广的范式之一。
马克斯・普朗克数学研究所的著名数学家 Peter Scholze(他并未参与此证明)说:这项证明是三十年辛苦研究所到达的顶点。「看到它得到解决真是太好了。」
朗兰兹纲领是由罗伯特・朗兰兹(Robert Langlands)在 1960 年代提出的。其是对傅里叶分析的广泛泛化,而傅里叶分析是一个影响深远的框架,可将复杂的波表示成多个平滑震荡的正弦波。朗兰兹纲领在三个不同的数学领域都有重要地位:数论、几何和所谓的函数域(function field)。这三个领域通过一个类比网络连接在了一起,而这个网络也被称为数学的「罗塞塔石碑(Rosetta stone)」。
现在,一系列论文证明了这个罗塞塔石碑的几何栏位的朗兰兹猜想:https://people.mpim-bonn.mpg.de/gaitsgde/GLC/
德克萨斯州大学奥斯汀分校的 David Ben-Zvi 说:「其它领域还没有得到过如此全面和有力的证明。」
朗兰兹纲领的几何版本的主要先驱之一 Alexander Beilinson 说:「这是美丽的数学,最美的那一类。」
该证明包含 5 篇论文,加起来超过 800 页。它们来自 Dennis Gaitsgory(马克斯・普朗克研究所)和 Sam Raskin(耶鲁大学)领导的一个团队。
Gaitsgory 过去 30 年来一直致力于证明几何朗兰兹猜想。这几十年来,他及其合作者获得了大量研究成果,并在这些基础上完成了这项证明。格勒诺布尔 - 阿尔卑斯大学的 Vincent Lafforgue 将这些进步比作是「不断升高的海」;他说这就像是 20 世纪杰出数学家亚历山大・格罗滕迪克(Alexander Grothendieck)的研究精神 —— 通过创造一个不断升高的思想之海来解决困难问题。
Dennis Gaitsgory(左图)和 Sam Raskin(右图),他们领导的一个九人团队证明了几何朗兰兹猜想。
要验证他们的新证明成果还需要些时日,但很多数学家都表示相信其核心思想是正确的。Lafforgue 说:「该理论的内部一致性很好,所以很难相信它错了。」
在证明之前的几年里,该研究团队创建了不止一条通往问题核心的路径。「他们得到的理解是如此的丰富和广泛,以至于他们从所有方向包围了这个问题。」他说,「它已无路可逃。」
大统一理论
1967 年,时年 30 岁的普林斯顿大学教授罗伯特・朗兰兹在他手写给安德烈・韦伊(André Weil,这个罗塞塔石碑的创立者)的一份 17 页信件中阐述了他的愿景。朗兰兹写到,在这个罗塞塔石碑的数论和函数域栏位上,有可能创造出一种广义版的傅里叶分析,并且其将具有惊人的范围和力量。
在经典的傅里叶分析中,对于两种不同的思考波图(比如声波)的方式,会使用一种名为傅立叶变换的过程来创造的它们之间的对应关系。在这对应关系的一侧是这些波本身。(我们称之为波侧 /wave side)。这包括简单的正弦波(在声学中就是纯音)以及由多个正弦波组成的复杂波。在这对应关系的另一侧是余弦波的频谱 —— 声学中的音高。(数学家称之为谱侧 /spectral side)。
傅立叶变换就是在这两侧之间来回。在一个方向上,其可将波分解成一组频率;在另一个方向上,则可根据其组成频率重建出波。这种双向变换的能力造就了数不清的应用 —— 没有它,我们就不会拥有现代电信、信号处理、磁共振成像或现代生活的许多其它必需品。
朗兰兹提出,罗塞塔石碑的数论和函数域栏位也有类似的变换,只是这里的波和频率都更加复杂。
在下面的视频中,罗格斯大学的数学家 Alex Kontorovich 将带我们穿过这片数学大陆,了解朗兰兹纲领核心的令人惊叹的对称性。
视频来源:https://www.youtube.com/watch?v=_bJeKUosqoY
在这些栏位中的每一个,都有一个由一组特殊函数组成的波侧,这些特殊函数类似于重复的波。这些特殊函数中最纯粹的被称为特征函数(eigenfunction),其作用就类似于正弦波。每个特征函数都有一个特征频率。不过,虽然正弦波的频率是一个数值,但特征函数的频率则是一个无限的数值列表。
还有谱侧。这由数论中的对象组成;朗兰兹认为这些对象标记了特征函数的频谱。他提出,存在一种类似于傅立叶变换的处理机制可将这里的波侧与谱侧连接起来。「这件事有点神奇。」Ben-Zvi 说,「这不是我们没有任何理由时就能事先预计的东西。」
波与其频率标签来自大不相同的数据领域,因此如果能证明它们之间的对应关系,必定能带来丰厚的回报。举个例子,在 1990 年代时,一个相对较小的函数集的数论朗兰兹对应的证明就让 Andrew Wiles 和 Richard Taylor 证明了费马大定理 —— 这个问题曾是数学领域最著名的待证明问题之一,数学界已经为此努力了三个世纪。
加州大学伯克利分校的 Edward Frenkel 表示:朗兰兹纲领被视为「数学的大统一理论」。然而,即便数学家已经努力证明了朗兰兹愿景中越来越大的部分,但他们也很清楚这个愿景并不完备。在这块罗塞塔石碑的几何学栏位,波与频率标签的关系似乎无法体现出来。
一粒沙
正是从朗兰兹的研究工作开始,数学家对几何朗兰兹对应(geometric Langlands correspondence)的谱侧的样子有了一个想法。韦伊设定的罗塞塔石碑的第三个栏位(几何)涉及紧黎曼曲面(compact Riemann surface),包括球面、甜甜圈形曲面以及多孔甜甜圈形曲面。一个给定的黎曼曲面都有一个对应的对象,称为基本群(fundamental group),其跟踪的是环绕曲面的环线的不同形式。
数学家猜想,几何朗兰兹对应的谱侧应当由基本群的特定蒸馏形式构成,这些特定的蒸馏形式也被称为基本群的表征(representation)。
如果要在罗塞塔石碑的几何栏位体现出朗兰兹对应,那么黎曼曲面基本群的每个表征都应该是一个频率标签 —— 但是什么的频率标签呢?
对于频率似乎标记了基本群表征的特征函数,数学家找不到任何集合。然后到了 1980 年代,如今就职于芝加哥大学的 Vladimir Drinfeld 意识到:通过将特征函数替换成名为特征层(eigensheaf)的更复杂对象,有可能创建起几何朗兰兹对应 —— 不过那时候,他只知道少数特征叠层的构建方式。
层(sheaf)比函数深奥很多,因此数论学家那时候不知道该如何理解这个朗兰兹对应的几何表亲。但几何朗兰兹纲领(尽管其波侧玄奥难懂)相较于数论版本的朗兰兹纲领有着一个大优势。在几何朗兰兹中,特征层的频率由黎曼曲面上的点控制,球体或甜甜圈上的每个点在近距离看起来非常相似。但在数论朗兰兹中,频率由素数控制,并且每个素数都有其特有的性质。伦敦帝国学院的数论学家 Ana Caraiani 说:数学家不知道「如何以一种很好的方式从一个素数到另一个素数。」
黎曼曲面在物理学领域具有重要作用,尤其是在共形场论中,其控制着亚原子粒子在某些力场中行为。在 1990 年代早期,Beilinson 和 Drinfeld 展示了可以如何使用共形场论来构建某些特别好的特征层。
与共形场论这种连接关系让 Beilinson 和 Drinfeld 开始思考如何为层(sheaf)构建一种傅里叶分析。Ben-Zvi 说:「这就像是引发结晶的一粒沙子。」
Beilinson 和 Drinfeld 提出了一个丰富的愿景,阐述了几何朗兰兹对应理应的工作方式。这不仅是基本群的每个表征都应该标记一个特征层的频率。他们认为,这种对应关系也应当尊重两侧的重要关系,Beilinson 和 Drinfeld 称这种展望是「最好的希望」。
1990 年代中期,Beilinson 在特拉维夫大学通过一系列讲座介绍了这一发展中的研究图景。Gaitsgory 那时在此读研究生,努力吸收其中每句话。他回忆说:「我就像一只刚孵化的小鸭子,获得了一种印随行为。」
此后的 30 年里,几何朗兰兹猜想一直是 Gaitsgory 数学生涯的主要驱动力。他说:「这些年都在不停地工作,离目标越来越近,开发不同的工具。」
上升之海
Beilinson 和 Drinfeld 只是松散地陈述了他们的猜想,事实证明他们有点过于简化「最好的希望」中的关系理应的工作方式了。2012 年时,Gaitsgory 与威斯康星大学麦迪逊分校的 Dima Arinkin 搞清楚了如何将这「最好的希望」变成一个精确的猜想。
之后一年,Gaitsgory 写了一份大纲,阐述了证明几何朗兰兹猜想的可能方式。该大纲依赖大量中间陈述,其中很多当时都尚未得到证明。Gaitsgory 及其合作者开始着手证明它们。
接下来的几年时间里,Gaitsgory 和多伦多大学的 Nick Rozenblyum 写了两本关于层的书,加起来接近 1000 页。在这套两卷本中,几何朗兰兹纲领只被提及了一次。Gaitsgory 说:「但其目的是奠定基础,后来我们也大量使用到了这些基础。」
2020 年,Gaitsgory 突然发现他没什么日程安排了。他说:「我花了三个月时间躺在床上,只是思考。」这些思考最终促成了一篇论文(有 6 位作者)。虽然这篇论文专注于朗兰兹纲领的函数域栏位,但其中也包含「一粒种子」—— 这粒种子后来变成了证明几何朗兰兹猜想的关键组件:一种用于理解特征层如何促进所谓的「白噪声」的方法。
其他七位研究者的照片。左起顺时针方向:Dario Beraldo、Lin Chen(陈麟)、Kevin Lin、Nick Rozenblyum、Joakim Færgeman、Justin Campbell 和 Dima Arinkin。
在经典的信号处理领域,可由正弦波构建声波,其频率对应于声音中的音高。仅仅知道声音包含哪些音高是不够的 —— 还需要知道每个音高的响度有多大。这些信息让你可将声音写成正弦波的组合形式:只需从幅度为 1 的正弦波开始,然后让正弦波乘以适当的响度因子,再将这些正弦波加在一起。所有不同的幅度为 1 的正弦波之和就是我们常说的「白噪声」。
在几何朗兰兹纲领的世界里,特征层的作用就类似于正弦波。Gaitsgory 及其合作者识别出了一种名为庞加莱层(Poincaré sheaf)的东西,其作用似乎就类似于白噪声。但这些研究者并不清楚能否将每个特征层都表示在庞加莱层中,更不用说它们是否都具有相同的幅度了。
2022 年春,Raskin 与他的研究生 Joakim Færgeman 展示了如何使用那篇六作者论文中的思想来证明每个特征层都确实可表示在庞加莱层中。Gaitsgory 在谈到对几何朗兰兹猜想的证明时说:「在 Sam 的和 Joakim 的论文之后,我很确信我们能在短时间内做到。」
研究者需要证明,所有特征层对庞加莱层都有同等的贡献,并且基本群表征标记了这些特征层的频率。他们认识到,最难的部分是处理这种基本群的表征:不可约表征。
这些不可约表征的解决方案出现之时,Raskin 的个人生活正一片混乱。在他与 Færgeman 在网上发布了他们的论文几周后的某天,Raskin 不得不匆忙地将他怀孕的妻子送往医院,然后再回家送儿子第一次去幼儿园。Raskin 的妻子在医院住了六周,直到他们的第二个孩子降生。在这段时间里,Raskin 的生活一直在轮轴转 —— 为了保证儿子的正常生活,他无休止地在家、儿子的学校和医院之间来回奔忙。他说:「我那时的全部生活就是车和照顾人。」
他在驾驶途中与 Gaitsgory 打电话探讨数学。在那几周的第一周快结束时,Raskin 意识到他可以将这个不可约表征问题简化成证明三个当时已经触手可及的事实。「对我来说,那段时间很神奇。」他说,他的个人生活「充满了对未来的焦虑和恐惧。对我来说,数学是一种需要根植(grounding)和冥想的东西,可以让我摆脱那种焦虑。」
到 2023 年初,Gaitsgory 和 Raskin 以及 Arinkin、Rozenblyum、Færgeman 和其他四名研究人员一起,对 Beilinson 和 Drinfeld 的「最好的希望」进行了完整的证明,并由 Gaitsgory 和 Arinkin 进行了修订。(其他研究者为伦敦大学学院的 Dario Beraldo、清华大学的 Lin Chen(陈麟)、芝加哥大学的 Justin Campbell 和 Kevin Lin。)该团队又用了一年时间将该证明写下来。他们在今年二月份在网上发布了该证明。尽管这些论文遵循 Gaitsgory 在 2013 年制定的大纲,但其中简化了 Gaitsgory 的方法并在很多方面做出了改进。Lafforgue 说:「对于这个无与伦比的成就,很多聪明人为此贡献了很多新想法。」
「他们不仅仅是证明了它,」Ben-Zvi 说,「他们围绕它开发了整个世界。」
更远的海岸
对 Gaitsgory 来说,这个数十年梦想的实现远非故事的结束。还有许多进一步的难题有待数学家解决 —— 更深入地探索其与量子物理学的联系、将该结果扩展到带穿孔的黎曼曲面、搞清楚其对罗塞塔石碑的其它栏位的影响。Gaitsgory 在一封电子邮件中写到:「这感觉(至少对我来说)更像是凿下了一块大石头,但我们离核心依然还很远。」
研究其它两个栏位的研究者现在急切地想要将这个证明转译过去。Ben-Zvi 说:「其中一个主要碎片得到解决这一事实应该会对朗兰兹对应的整体研究产生重大影响。」
但并非所有东西都能带过去 —— 举个例子,在数论和函数域设置中,并没有与共形场论思想相对应的东西,而共形场论能让研究者在几何设置中构建起特殊的特征层。在将该证明中的很多东西用于其它栏位之前,还需要一些费力的调整。伯克利的 Tony Feng 说:我们还不清楚是否能「将这些思想转移到一个原本没想过能使用它们的不同环境中。」
但很多研究者都乐观地相信这个上升的思想之海最终会漫延到其它领域。Ben-Zvi 说:「它将渗透穿过学科之间的所有障碍。」
过去十年中,研究者已经开始发现几何栏位与另外两个栏位之间的联系。「如果(几何朗兰兹猜想)在 10 年前就被成功证明,那么结果会大不相同。」Feng 说,「人们就不会认识到它的影响可能会拓展到(几何朗兰兹)社区之外。」
在将几何朗兰兹证明转译到函数域栏位方面,Gaitsgory、Raskin 及其合作者已经取得了一些进展。(Raskin 暗示说,Gaitsgory 和 Raskin 在后者的长期驾驶途中得到的一些发现「还有待揭示」。)如果转译成功,则可能得到一个比数学家之前知道或甚至猜测的还要远远更加精准的函数域朗兰兹版本。
而从几何栏位到数论栏位的大多数转译都会经过函数域。但在 2021 年,巴黎 Jussieu 数学研究所的 Laurent Fargues 和 Scholze 设计了一个所谓的虫洞(wormhole),可将几何栏位的思想直接带到数论朗兰兹纲领的某一部分。
Scholze 说:「我肯定是一个想要转译这些几何朗兰兹证明的人。」考虑到这片上升之海包含上千页文本,这绝非易事。「我目前落后几篇论文,」Scholze 说,「正在努力研读他们在 2010 年左右的成果。」
现在,几何朗兰兹研究者终于将他们的长篇论证述诸论文,Caraiani 希望他们能有更多时间与数论方向的研究者讨论。她说:「人们有着非常不同的思考问题的方式。如果他们能够放慢脚步,彼此交谈,了解对方的观点,那总会有好处的。」她预测说这项新成果的思路必定会传播到数论领域,这只是个时间问题。
正如 Ben-Zvi 说得那样:「这些结果是如此的稳健,以至于你一旦开始,就很难再停下来。」
原文链接:https://www.quantamagazine.org/monumental-proof-settles-geometric-langlands-conjecture-20240719/
#让机器人拥有人一样「潜意识」
英伟达1.5M小模型就能实现通用控制了
当机器人也有潜意识。
大模型固然性能强大,但限制也颇多。如果想在端侧塞进 405B 这种级别的大模型,那真是小庙供不起大菩萨。近段时间,小模型正在逐渐赢得人们更多关注。这一趋势不仅出现在语言模型领域,也出现在了机器人领域。
昨天晚上,朱玉可和 Jim Fan 团队(英伟达 GEAR 团队)新鲜发布了他们的最新研究成果 HOVER。这是一个仅有 1.5M 参数的神经网络,但它足以控制人形机器人执行多种机体运动。
先来看看效果,将 HOVER 在不同模式下控制的机器人放到一起组成阵列,其中每一台机器人都有自己的控制模式。还挺壮观的!这也佐证了 HOVER 的通用性。你能看出它们的不同之处吗?

无论是 H2O 模式、OmniH2O Mode 模式、还是 ExBody 模式 、HumanPlus 模式,左手和右手的慢动作都直接被 HOVER 大一统了。

实际上,HOVER 就是一个通用型的人形机器人控制器。
HOVER 一作 Tairan He(何泰然)的推文,他是 CMU 机器人研究所的二年级博士生,还是个有 38 万多粉丝的 B 站 up 主(WhynotTV)
据介绍,HOVER 的设计灵感来自人类的潜意识。人类在行走、保持平衡和调整四肢位置时都需要大量潜意识的计算,HOVER 将这种「潜意识」能力融合进了机器人。这个单一模型可以学习协调人形机器人的电机,从而实现运动和操控。
Jim Fan 的推文
- 论文标题:HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots
- 论文地址:https://arxiv.org/pdf/2410.21229
- 项目地址:https://hover-versatile-humanoid.github.io/
HOVER 的训练使用了 NVIDIA Isaac,这是一个由 GPU 驱动的模拟套件,可将物理加速到实时的 1 万倍。按 Jim Fan 的比喻就是说,只需在一张 GPU 卡上运算大概 50 分钟,机器人就像是在虚拟「道场」中经历了一整年的密集训练。
然后,无需微调,就可以将这个神经网络以零样本方式迁移到真实世界。
HOVER 可以接收多种高级运动指令,即所谓的「控制模式(control mode)」,比如:
- 头部和手部姿势,可通过 Apple Vision Pro 等增强现实设备捕捉;
- 全身姿势,可通过 MoCap 或 RGB 相机;
- 全身关节角度:外骨骼;
- 根速度命令:操纵杆。

这项研究的贡献包括:
- 一个统一的界面,可让控制者使用任何方便的输入设备来控制机器人;
- 一种更简单的全身远程操作数据收集方法;
- 一个上游的视觉 - 语言 - 动作模型,可用于提供运动指令,之后 HOVER 会将其转换为高频的低级运动信号。
HOVER 是如何炼成的?
用于人形机器人的基于目标的强化学习
该团队将所研究的问题表述成了一个基于目标的强化学习任务,其中策略 π 的训练目标是跟踪实时的人类运动。其状态 s_t 包含智能体的本体感受 s^p 和目标状态 s^g。其中目标状态 s^g 会为目标运动提供一个统一的表征。基于此,可将策略优化的奖励定义成
![]()
。
- 动作
![]()
表示目标关节位置,这些位置会被输入到 PD 控制器中以驱动机器人,他们使用了近端策略优化 (PPO) 算法来最大化累积折扣奖励

该设置被表述为一个命令跟踪任务,其中人形机器人会学习在每个时间步骤遵从目标命令。
用户人形机器人控制的命令空间设计
对于腿部运动,根速度或位置跟踪是常用的命令空间。然而,仅仅关注根跟踪会限制人形机器人的全部能力,尤其是对于涉及全身运动的任务。
该团队研究了之前的工作,发现它们提出了一些各不一样的控制模式,并且每种模式通常都是针对某些特定的任务,因此缺乏通用人形机器人控制所需的灵活性。
而该团队的目标是设计一个全面的控制框架,以适应多种多样的场景和各种不同的人形机器人任务。为此,在构建命令空间时,必须满足以下关键标准:
- 通用性:命令空间应包含大多数现有配置,允许通用控制器替换针对特定任务的控制器,同时还不会牺牲性能或多功能性。并且该空间应具有足够的表现力,以便与现实世界的控制设备交互,包括操纵杆、键盘、动作捕捉系统、外骨骼和虚拟现实 (VR) 头设,如图 1 所示。
- 原子性:命令空间应由独立的维度组成,从而能够任意组合控制选项以支持各种模式。

基于这些标准,该团队定义了一个用于人形机器人全身控制的统一命令空间。该空间由两个主要控制区域组成 —— 上身和下身控制 —— 并包含三种不同的控制模式:
- 运动位置跟踪:机器人上关键刚体点的目标 3D 位置;
- 局部关节角度跟踪:每个机器人电机的目标关节角度;
- 根跟踪:目标根速度、高度和方向,由滚动、俯仰和偏航角指定。
在如图 1 所示的框架中,该团队引入了一个 one-hot 掩码向量来指定激活命令空间的哪些组件,以便后面跟踪。
如表 1 所示,可以将其它基于学习的人形全身控制的最新研究看作是新提出的统一命令空间的子集,其中每项研究都代表特定的配置。

- 运动重定向
近期有研究表明,如果学习的运动数据集很大,学习到的人形机器人全身运动控制策略就会更加稳健。
为了获得大型数据集,可将人类运动数据集重定向成人形机器人运动数据集,这个过程分为三步:
1. 使用正向运动学(forward kinematics)计算人形机器人的关键点位置,将其关节配置映射成工作空间坐标。
2. 拟合 SMPL 模型以匹配人形机器人的运动学,做法是优化 SMPL 参数以与正向运动学计算得到的关键点对齐。
3. 使用梯度下降来匹配已经拟合的 SMPL 模型和人形机器人之间的对应关键点,重定向 AMASS 数据集。
- 状态空间设计
他们训练了一个 oracle 运动模拟器

其中 p_t 是人形机器人刚体位置 、θ_t 是方向、p_t 是线速度、 ω_t 是角速度、a_{t−1} 是前一个动作。本体感觉定义为

目标状态的定义是

其中包含参考姿态以及人形机器人所有刚体的参考状态与当前状态之间的一帧差异。他们使用的策略网络结构为层尺寸为 [512, 256, 128] 的三层 MLP。
- 奖励设计和域随机化
这里,奖励 r_t 是三个分量之和:1) 惩罚、2) 正则化和 3) 任务奖励,详见表 2。域随机化是将模拟环境和人形机器人的物理参数随机化,以实现模拟到现实成功迁移。

通过蒸馏实现多模式多功能控制器
- 本体感受
对于从 oracle 教师 π^oracle 中蒸馏得到的学生策略 π^student,本体感受定义为

其中 q 是关节位置,

是关节速度,ω^base 是基准角速度,g 是重力向量,a 是动作历史。
他们将最新的 25 个步骤的这些项堆叠起来作为学生的本体感受输入。

- 命令掩码
如图 2 所示,学生策略的任务命令输入是使用基于模式和基于稀疏性的掩码定义的。具体来说,学生的任务命令输入是这样表示的

模式掩码 M_mode 会为上半身和下半身分别选择特定的任务命令模式。例如,上半身可以跟踪运动位置,而下半身则专注于关节角度和根部跟踪,如图 2 所示。在模式特定的掩码之后,应用稀疏掩码 M_sparsity。
例如,在某些情况下,上半身可能只跟踪手的运动位置,而下半身只跟踪躯干的关节角度。模式和稀疏二元掩码的每一比特都来自伯努利分布 𝔅(0.5)。模式和稀疏掩码在事件情节(episode)开始时是随机的,并保持固定,直到该情节结束。
- 策略蒸馏
该团队执行策略蒸馏的框架是 DAgger。对于每个事件情节,都先在模拟中 roll out 学生策略

,从而得到

的轨迹。
另外在每个时间步骤还会计算相应的 oracle 状态

使用这些 oracle 状态,可以查询 oracle 教师策略
![]()
以获得参考动作

然后通过最小化损失函数

来更新学生策略 π^student。
实验
研究团队针对以下问题,在 IsaacGym 和 Unitree H1 机器人上开展了广泛的实验:
- Q1: HOVER 这个通用策略能比那些只针对特定指令训练的策略表现得更好吗?
- Q2: HOVER 能比其他训练方法更有效地训练多模态仿人机器人控制器吗?
- Q3: HOVER 能否在真实世界的硬件上实现多功能多模态控制?
与专家策略的对比
该团队在不同控制模式下比较了 HOVER 和相应专家策略的表现。以 ExBody 模式为例,研究团队加入了固定的掩码,让 HOVER 和整个数据集 Q 中的 ExBody 模式可比。

如表 III 和图 3 所示,HOVER 展现出了优越的泛化能力。在每一种指令模式中,HOVER 在至少 7 个指标上超越了之前的专家控制器(表 III 中用粗体值突出显示)。同时,这也意味着即使只关注单一控制模式,从专家策略中提取的策略也比通过强化学习训练出的专家更强。

与通用训练方法的对比
研究团队在八种不同的模式下测量了 HOVER 在跟踪局部和全身位置方面的表现。他们用最大误差(Emax)减去当前误差(E (.)),再除以最大误差(Emax)和最小误差(Emin)之间的差值来计算误差。雷达网图更大,代表模型的跟踪性能更好。实验结果显示,HOVER 在所有 32 个指标和模式中的误差都很低。

在真实世界中的测评
为了测试 HOVER 策略在真实世界中的表现,研究团队设计了定量的跟踪实验和定性的多模态控制实验。
- 站立时的动作评估
该团队通过跟踪 20 种不同的站立动作来评估 HOVER 的性能,表 V 中的定量指标显示,HOVER 在 12 个指标中的 11 个上超越了专家策略。HOVER 成功跟踪了关节俯仰运动与全身运动,特别是高度动态的跑步动作也能搞定。

机器人的关节可以在 - 0.5 到 0.5 的俯仰角度之间变化

- 多模态评估
该团队还模拟了真实的生活场景,测试了在突然切换命令时 HOVER 对运动的泛化能力。HOVER 成功地让机器人从 ExBody 模式切换到 H2O 模式,同时在向前行走。

从 ExBody 切换到 H2O 模式
从 HumanPlus 模式切换到 OmniH2O 模式,机器人也能同时执行转弯和向后行走。

从 HumanPlus 切换到 OmniH2O 模式
此外,他们还使用 Vision Pro 随机掩盖头部和手部的位置,进行了远程操作演示,可以看出,机器人的动作非常地丝滑流畅。

有时,它也会出错,比如只追踪了测试者的头部位置,忽略了挥手的动作。

结果表明,HOVER 能够平滑地在不同模式之间追踪动作,展示了其在真实世界场景中的鲁棒性。
#MimicTalk
3D大模型助力,15分钟即可训练高质量、个性化的数字人模型,代码已开放
本文的作者主要来自于浙江大学和字节跳动。第一作者是浙江大学计算机学院的博士生叶振辉,导师为赵洲教授,主要研究方向是说话人视频合成,并在 NeurIPS、ICLR、ACL 等会议发表相关论文。共一作者是来自浙江大学计算机学院的硕士生钟添芸。
个性化精品数字人(Personalized Talking Face Generation)强调合成的数字人视频在感官上与真人具有极高的相似性(不管是说话人的外表还是神态)。目前业界主流的个性化精品数字人通常属于在单个目标人数据上从头训练的小模型,虽然这种小模型能够有效地学到说话人的外表和说话风格,这种做法存在低训练效率、低样本效率、低鲁棒性的问题。相比之下,近年来许多工作专注于单图驱动的通用数字人大模型,这些模型仅需单张图片输入即可完成数字人制作,但仍存在外表相似度较低、无法模仿目标人说话风格等问题。
为了连接个性化数字人小模型和单图驱动通用数字人大模型两个领域之间的空白,浙江大学与字节跳动提出了 MimicTalk 算法。通过(1)将单图驱动的通用 3D 数字人大模型 Real3D-Portrait (ICLR 2024) 适应到目标数字人的高效微调策略和(2)具有上下文学习能力的人脸动作生成模型,MimicTalk 可以生成相比原有方法更高质量、更具表现力的数字人视频。此外,单个数字人模型的训练时间可以被压缩到 15 分钟以内,相比现有最高效的同类方法快了 47 倍。
MimicTalk 算法被人工智能顶级会议 NeurIPS 2024 录用,目前已开放源代码和预训练权重。
- 论文标题:MimicTalk: Mimicking a personalized and expressive 3D talking face in minutes
- 论文链接:https://arxiv.org/pdf/2410.06734
- 项目主页:https://mimictalk.github.io/
- 代码链接:https://github.com/yerfor/MimicTalk
话不多说直接看效果,以下视频中的数字人模型都通过从 3D 数字人大模型进行 1000 步微调(5 分钟训练时间)得到。
,时长00:24
模型技术原理
深悉 MimicTalk 模型的内在原理,还要回到开头提到的个性化数字人两个核心目标:(1)外表上与真人相似;(2)说话风格上与真人相似。
MimicTalk 分别使用(1)基于通用 3D 数字人大模型微调的高质量人脸渲染器和(2)一个具有上下文学习能力的人脸动作生成模型来实现它们。

图 2. MimicTalk 包含一个高质量人脸渲染器(紫色)和一个能够模仿说话风格的动作生成器(蓝色)
对于第一个问题,传统方法通常从头训练一个小规模的 NeRF 模型来记忆目标人的外表特征,但这种做法通常导致较长的训练时间(数个小时)、较高的数据量要求(数分钟)、较低的鲁棒性(对极端条件无法输出正确的结果)。针对这一问题,团队首次提出采用一个单图驱动的通用 3D 数字人大模型作为基础模型,并提出了一个「动静结合」的高效率微调方案。
他们发现通用大模型的输出通常存在牙齿、头发等静态细节不足,且肌肉运动等动态细节不真实的问题。因此针对静态细节和动态细节的特性设计了动静结合的微调方案。
具体来说,研究者发现现有的 3D 数字人通用模型通常会将 3D 人脸的静态细节储存在一个 3D 人脸表征(tri-plane)中作为模型的输入,而 3D 人脸的动态细节,则通过模型内部的参数进行储存。因此,MimicTalk 在个性化数字人渲染器的训练过程中,不仅会更新储存静态细节的 3D 人脸表征,还通过 LoRA 技术对通用模型的参数进行了可拆卸的高效微调。

图 2. 将通用 3D 数字人大模型适应到单个目标人,动静结合的高效微调方案
在实现图像上与真人的高度相似后,下一个问题是如何生成与真人说话风格相似的面部动作。传统方法通常会额外训练一个说话风格编码器,但是由于模型内部信息瓶颈的存在通常会性能损失。与之相比,受启发大语言模型、语音合成等领域的启发,MimicTalk 首次提出从上下文中学习目标人说话风格的训练范式。在训练阶段,Flow Matching 模型通过语音轨道和部分未被遮挡的人脸动作轨道的信息,对被遮挡的人脸动作进行去噪。在推理阶段,给定任意音频 - 视频对作为说话人风格提示,模型都能生成模仿该说话风格的人脸动作。

图 3. 能在上下文中学习目标人说话风格的人脸动作生成模型
模型的应用前景
总体来看,MimicTalk 模型首次实现了高效率的个性化精品数字人视频合成。可以预见的是,随着技术的不断迭代、普及,在智能助手、虚拟现实、视频会议等多个应用场景中都将会出现虚拟人的身影。而借助 MimicTalk 算法,个性化高质量数字人的训练成本被「打了下去」,人们将会享受到更真实、更舒适的交互体验。随着各个领域的大模型技术的兴起,拥抱大模型的超强能力并与垂直领域中的特殊场景、需求相结合,已经成为了技术演进的大势所趋。而 MimicTalk 模型为后续基于数字人通用模型的个性化数字人算法研究工作提供了参考。但现阶段 MimicTalk 也并不是完美无缺的,由于依赖通用大模型的结果作为初始化,对基础模型的质量有较高的要求,此外从推理效率上看与现有小模型还存在一定差距。
总而言之,过去几年,随着个性化数字人技术的不断进步,口型精度、图像质量已然不断提高;而 MimicTalk 模型的提出,进一步解决了制约个性化数字人的训练成本问题。让我们一同期待虚拟人技术的加速发展,用户也将获得更加极致的视觉体验和生活便利。
#Moirai-MoE
新视角设计下一代时序基础模型,Salesforce推出Moirai-MoE
本文由 Salesforce、新加坡国立大学、香港科技大学(广州)共同完成。其中,第一作者柳旭是 Salesforce 亚洲研究院实习生、新加坡国立大学计算机学院四年级博士生。通讯作者刘成昊是 Salesforce 亚洲研究院高级科学家。该工作的短文版本已被 NeurIPS 2024 Workshop on Time Series in the Age of Large Models 接收。
时间序列预测是人类理解物理世界变化的重要一环。自去年底以来,时序预测领域正在经历重大转型,从传统的「单一数据集训练单一模型」的模式逐步转向「通用预测基础模型」。目前虽然有不少基础模型已经提出,但如何有效地在高度多样化的时序数据上训练基础模型仍是一个开放问题。
近期,来自 Salesforce、新加坡国立大学、香港科技大学(广州)的研究者以模型专家化这一全新视角作为抓手,设计并提出了下一代时序预测基础模型 Moirai-MoE。该模型将模型专业化设计在 token 这一细粒度运行,并且以完全自动的数据驱动模式对其赋能。模型性能方面,不同于仅在少量数据集上进行评估的已有时序基础模型,Moirai-MoE 在一共 39 个数据集上进行了广泛评估,充分验证了其优越性。
- 论文标题:Moirai-MoE: Empowering Time Series Foundation Models with Sparse Mixture of Experts
- 论文地址:https://arxiv.org/abs/2410.10469
- 代码仓库:https://github.com/SalesforceAIResearch/uni2ts
研究动机
训练通用基础模型的一大挑战在于适应时间序列数据的高度异质性,这种时序数据的独特特性凸显了设计专业化模块的必要性。现有的解决方案主要分为两种。第一种是通过基于语言的提示来识别数据源,从而实现非常粗粒度的数据集级别模型专业化。第二种方案利用了时序数据的频率这一元特征实现了更细粒度的专业化:该方法为特定频率设计单独的输入 / 输出投影层,从而实现特定频率的模型专业化。
作者认为,这种人为强加的频率级专业化缺乏普适性,并引入了一些局限性。(1)频率并不总是一个可靠的指标,无法有效地捕捉时序数据的真实结构。如下图所示,具有不同频率的时间序列可以表现出相似的模式,而具有相同频率的时间序列可能显示出多样且不相关的模式。这种人为强加的频率和模式之间的不匹配削弱了模型专业化的有效性,从而导致性能下降。(2)现实世界的时间序列本质上是非平稳的,即使在单个时间序列的短窗口内也会显示出不同的分布。显然,频率级专业化的粒度无法捕捉这种程度的多样性,这凸显了对更细粒度的建模方法的需求。

为了解决上述问题,作者提出了全新的时间序列统一训练解决方案 Moirai-MoE,其核心思想是利用单个输入 / 输出投影层,同时将各种时间序列模式的建模委托给 Transformer 层中的稀疏混合专家。通过这些设计,Moirai-MoE 的专业化以数据驱动的方式实现,并在 token 级别运行。
基于稀疏混合专家的时序基础模型
Moirai-MoE 构建在它的前序工作 Moirai 之上。虽然 Moirai-MoE 继承了 Moirai 的许多优点,但其主要改进在于:Moirai-MoE 不使用多个启发式定义的输入 / 输出投影层来对具有不同频率的时间序列进行建模,而是使用单个输入 / 输出投影层,同时将捕获不同时间序列模式的任务委托给 Transformer 中的稀疏混合专家。此外,Moirai-MoE 提出了一种新型的利用预训练模型中知识的门控函数,并采用自回归的训练目标来提高训练效率。下面简要介绍 Moirai-MoE 的模块。

1. 时序 Token 构造
Moirai-MoE 采用切块(patching)技术将时间序列输入切成没有重叠的小块,而后对小块进行标准化来缓解分布迁移的问题。为了在自回归模型中获取准确、鲁棒的标准化统计值,作者引入掩蔽率 r 作为超参数,它指定整个序列中专门用于正则化器计算的部分,不对这些 patch 计算预测损失。最后,一个输入投影层来负责把 patch 投影到和 Transformer 一样的维度,生成时序 token。
2. 稀疏混合专家 Transformer
通过用 MoE 层替换 Transformer 的每个 FFN 来建立专家混合层。该 MoE 层由 M 个专家网络和一个门控函数 G 组成。每个 token 只激活一个专家子集,从而允许专家专注于不同模式的时间序列数据并确保计算效率。在 Moirai-MoE 中,作者探索了不同的门控函数。首先使用的是最流行的线性投影门控函数,它通过一个线性层来生成专家子集的分配结果。此外,作者提出了一种新的门控机制,利用从预训练模型的 token 表示中得出的聚类中心来指导专家分配。这一方法的动机是,与随机初始化的线性投影层相比,预训练 token 表示的聚类更接近数据的真实分布,可以更有效地实现模型专业化。
3. 训练目标
为了同时支持点预测和概率预测两种预测模式,Moirai-MoE 的训练目标设定为优化未来混合分布的对数似然函数。
实验效果
作者在 39 个数据集上的进行了广泛测试评估来验证 Moirai-MoE 的有效性。

上图展示了在 Monash 基准中 29 个数据集上进行的分布内预测评估。结果表明,Moirai-MoE 击败了所有竞争对手。相比前序工作 Moirai,Moirai-MoE 的提升幅度达到了 19%。与 Moirai 无法超越的基础模型 Chronos 相比,Moirai-MoE 成功弥补了差距,并相比它少 65 倍激活参数,这带来了巨大的推理速度的优势。

上表展示了在零样本预测设定时,Moirai-MoE 在 10 个数据集上的点预测和概率预测的表现。Moirai-MoE-Base 取得了最佳的零样本性能,甚至超越了 Google 的 TimesFM 和 Amazon 的 Chronos(他们在预训练语料库中已包含了部分评估数据,因此存在数据泄露)。与所有规模的 Moirai 相比,Moirai-MoE-Small 在 CRPS 方面提高了 3%-14%,在 MASE 方面提高了 8%-16%。考虑到 Moirai-MoE-Small 只有 11M 激活参数(比 Moirai-Large 少 28 倍),这些进步是非常显著的。

在这篇研究中,作者还对时序 MoE 基础模型的内部工作机制进行了首次探索。上图是对 Moirai-MoE 的专家分配分布进行的可视化。基于此,作者总结了以下观点:
1. 在浅层中,不同频率的数据在专家选择的分布上呈现多样化。随着层数的加深,模型将重点转移到更通用的时间依赖性,例如更广泛的趋势和长期模式,这些依赖性可以在不同频率之间共享。到最后一层(第 6 层),专家分配在所有频率上变得几乎相同,表明模型已将时间序列抽象为与频率基本无关的高级表示。这一证据表明 Moirai-MoE 学习到了频率不变的隐层表示,这对于模型泛化至关重要。
2. 随着层数增加专家选择逐渐收敛的行为与 Large Language Models 中观察到的模式完全相反。这种分歧可能源于时间序列 token 的动态和噪声特性,它们是由小时间窗口生成的,不像从固定词汇表中派生的语言 token。研究结果表明,随着层数增加,模型实际上是在进行逐步去噪过程。这一观察结果与 GPT4TS 的结论一致:随着层深度增加,token 会被投影到输入的低维顶部特征向量空间中。
更多实验结果,可参考原论文。
#ChatGPT正式成为AI搜索
免费可用
时代变了,最强 AI 加持搜索引擎问世,没有广告。
终于等来这一天。
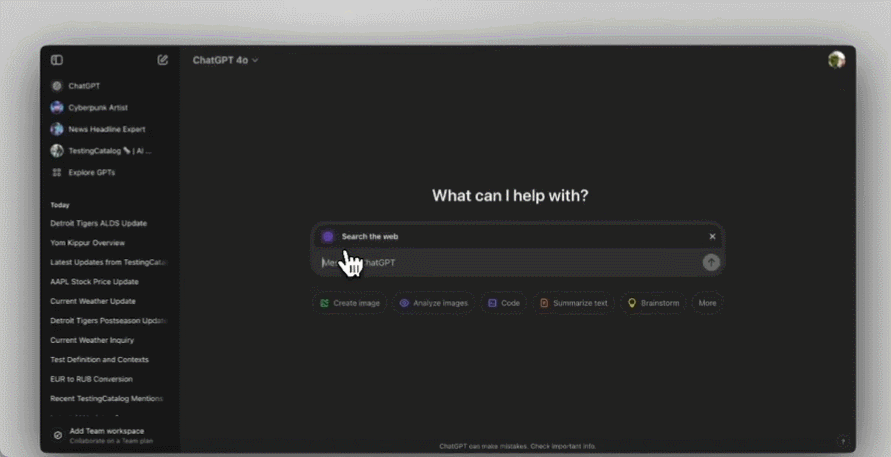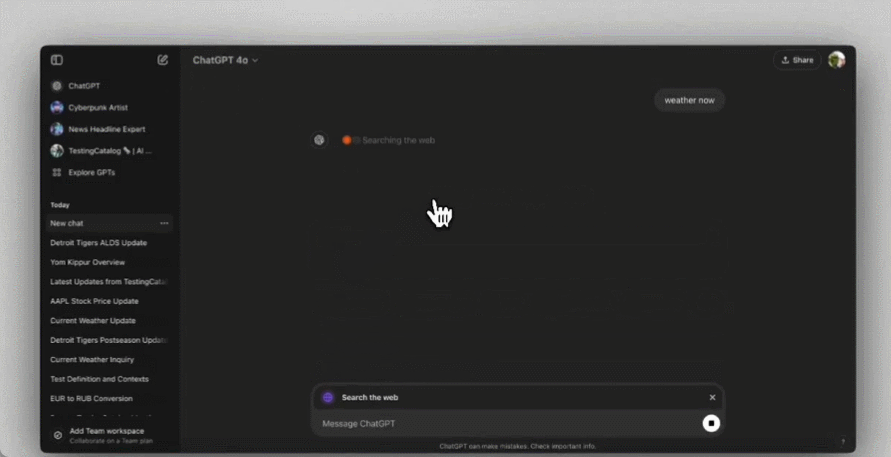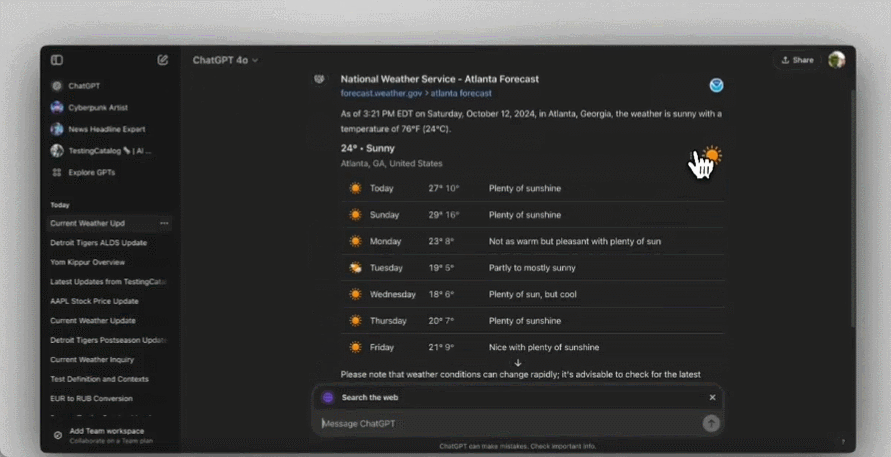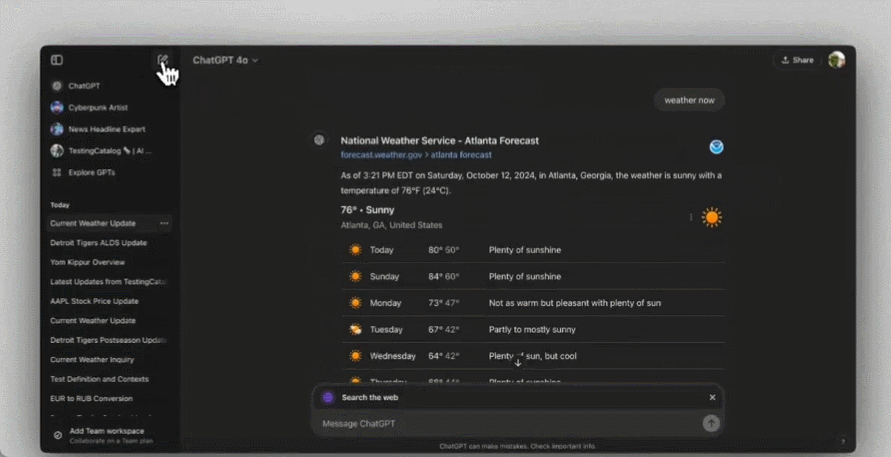
自今天起,ChatGPT 正式成为一款 AI 搜索引擎了!

北京时间 11 月 1 日凌晨,在 ChatGPT 两岁生日之际,OpenAI 宣布为 ChatGPT 推出了最新的人工智能搜索体验。
ChatGPT search 的推出正式宣告 ChatGPT 消除了即时信息这一最后短板。现在,人们与全球最先进 AI 大模型聊天时,也可以通过网络资源链接快速、及时地获取答案了。
即日起,付费订阅者(以及 SearchGPT 候补名单上的用户)将获得可联网的实时对话信息能力,免费用户、企业用户和教育用户也将在未来几周内陆续获得访问权限。

该功能覆盖 ChatGPT 的网页版,以及手机、桌面应用。在正常的对话时,ChatGPT 可以根据具体需求决定何时利用网络中的搜索结果,当然用户也可以主动触发网络搜索。
显然,新功能已经测试已久,上线是一瞬间的,很多人已经用起来了。可以看到,ChatGPT 搜索的天气、股市、地图等小组件齐全,是个完整版搜索引擎的样子:
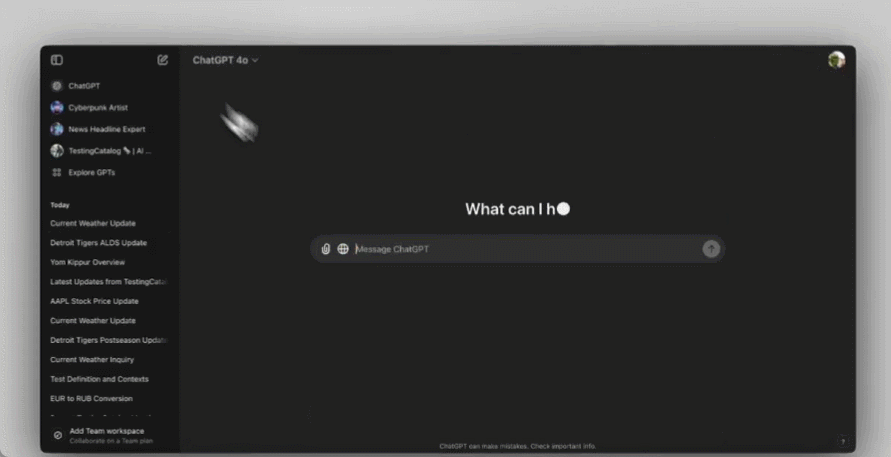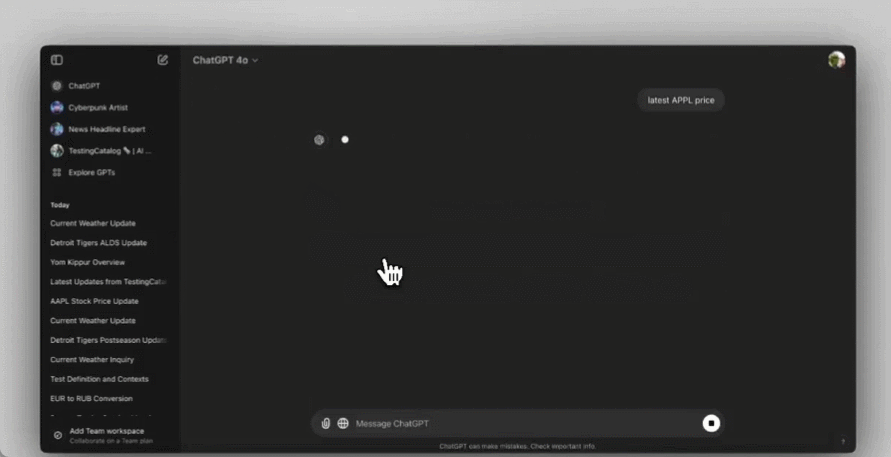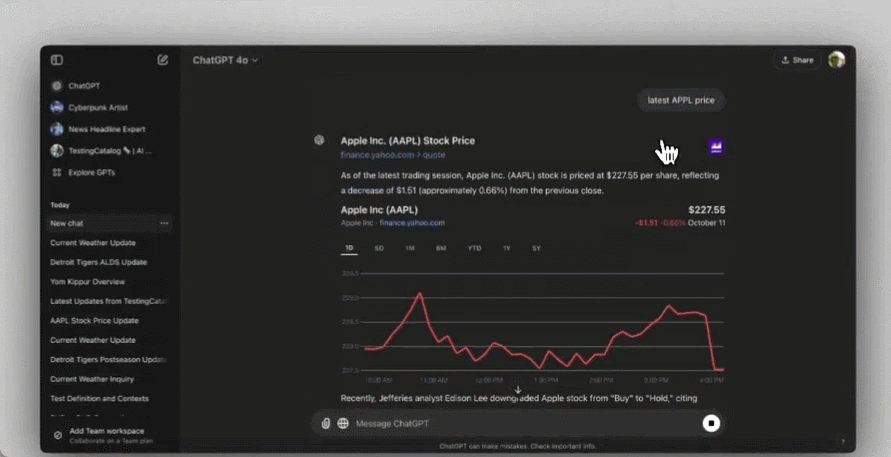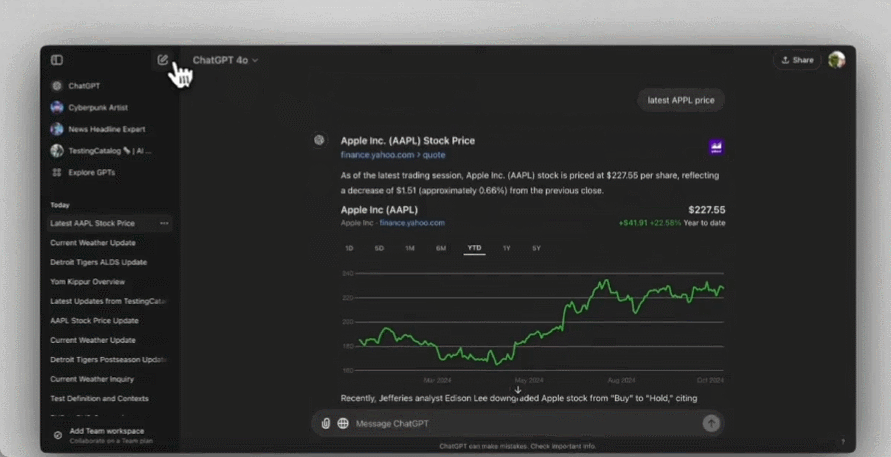
当然,搜索结果中引用的网络链接也一个都不会少:
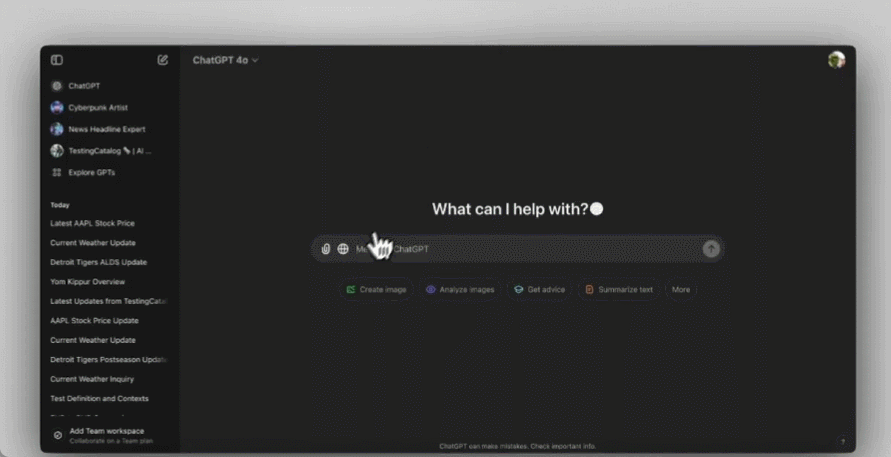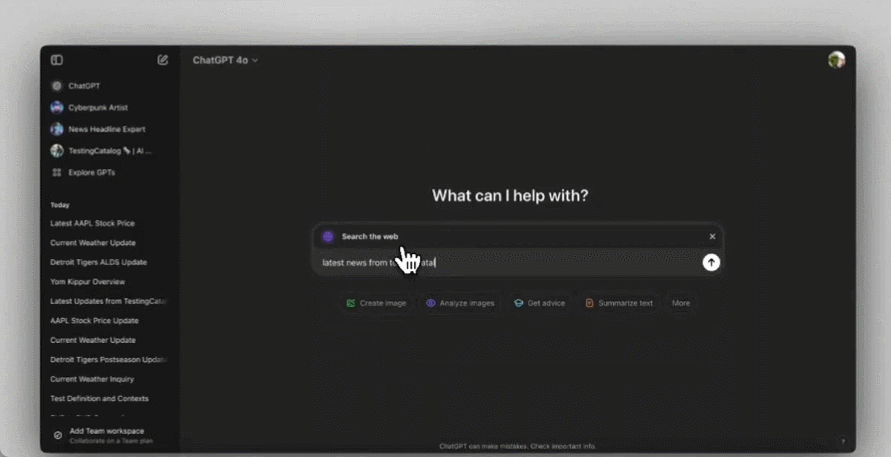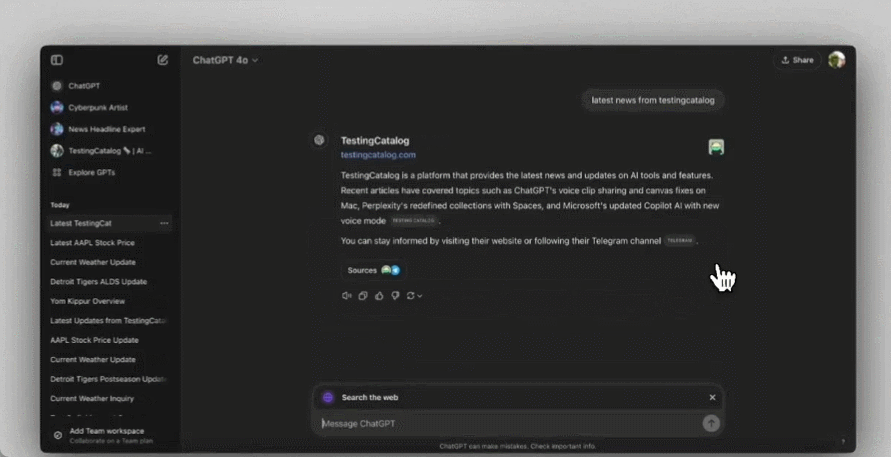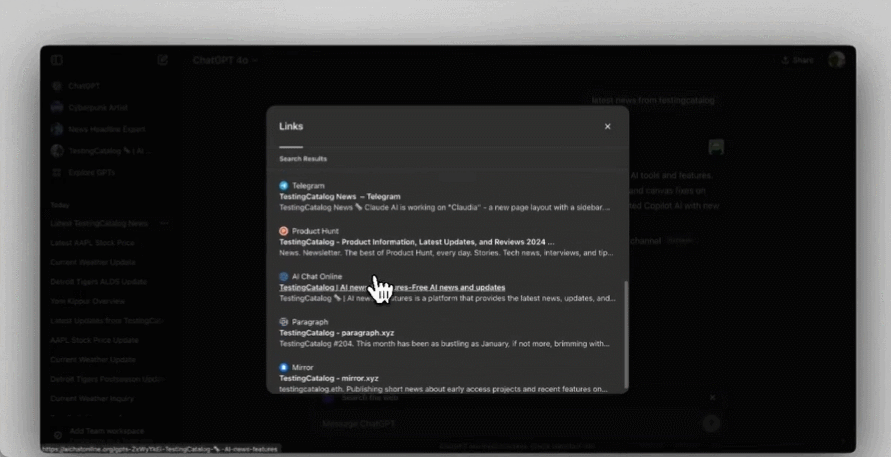
你也可以根据 AI 搜索结果里的一堆链接,直接让 ChatGPT 直接生成一份详细的摘要。或是顺着搜索结果继续追问,总而言之,ChatGPT 和搜索功能是完全一体化的。
看起来很美好的样子,网友们一致表示欢迎,同时为谷歌和 Perplexity 担忧一秒钟。

在 HackerNews 上有人则表示,传统搜索引擎如今的问题在于输出很多不相关结果(大量垃圾信息 + SEO 操纵的标题党内容),大模型也面临着幻觉问题。
但如果用大模型的智力来尝试过滤网络中的无用信息,或许搜索引擎的体验就会变得焕然一新。
为给出更好的答案而设计
从 OpenAI 对 ChatGPT 搜索的介绍中,我们看到了 AI 技术朝着这个方向努力的一点端倪。
在网上找到有用的答案并非易事。往往需要多次搜索并沿着链接挖掘以找到高质量信息源和正确信息。
现在,聊天就能得到更好的答案:用更自然的对话式方式提问,ChatGPT 可以选择使用网络上的信息进行回复。如果更深入地追问,则 ChatGPT 还能根据聊天的完整上下文来提供更好的答案。

为了补充最新的信息,OpenAI 表示已经与一些新闻和数据提供商达成了合作关系,并且还会为天气、股票、体育运动、新闻和地图等不同类别使用新的视觉设计。

Vox Media 总裁 Pam Wasserstein 表示:「ChatGPT 搜索有望更好地突显和归因来自可靠新闻来源的信息,使用户受益,同时扩大像我们这样的优质新闻发行商的影响力。」
ChatGPT 的聊天现在包含新闻文章和博客文章等来源的链接,方便用户了解更多信息。单击搜索答案下方的「来源」按钮可打开包含参考文献的侧边栏。

OpenAI 表示,ChatGPT 搜索让网络上原创、高质量的内容成为与人类对话的一部分。通过将搜索与聊天界面集成,用户可以以新的方式接触信息,而内容所有者则获得了接触更广泛受众的新机会。
从人们初步的使用效果看来,确实是相当的方便,比如搜个最近的 AI 新闻,结果会是这样的:

为什么我要用 ChatGPT 代替谷歌、Bing?一个重要的理由可能是:没有广告。OpenAI 明确表示目前没有计划在 ChatGPT 中投放广告。
奥特曼说了:你一用就回不去了。

不过,人工智能搜索的运营成本比传统搜索显然更高,目前还不清楚 OpenAI 将如何在巨量的免费搜索上实现收支平衡。可以确定的是,免费用户「使用最新搜索模型的频率将受到一些限制」。
如何运作
搜索能力更新之前,ChatGPT 拥有的知识局限于大模型的训练数据,仅限于 2021 年至 2023 年之间。
OpenAI 表示,该搜索模型是 GPT-4o 的微调版本,使用新颖的合成数据生成技术进行后训练,包括从 o1-preview 中提取输出。ChatGPT 搜索利用第三方搜索提供商以及 OpenAI 的合作伙伴直接提供的内容来提供用户正在寻找的信息。
据外媒报道,为了构建 AI 搜索引擎,OpenAI 还在积极挖走谷歌员工加入自己的搜索团队。
得益于 SearchGPT 原型的反馈,OpenAI 将 SearchGPT 的最佳体验引入 ChatGPT。OpenAI 表示还将不断改进搜索,特别是在购物和旅行等领域,并利用 OpenAI o1 系列的推理能力进行更深入的研究。OpenAI 还计划在未来将新的搜索体验引入高级语音和 canvas。
OpenAI 发言人 Niko Felix 表示,即使实时搜索已经大幅提升了使用体验,但公司仍将继续更新大模型的数据,以「确保用户始终能够获得最新的进展」,但这又与模型的训练「不同」。
OpenAI AMA 精选
在宣布发布 ChatGPT 搜索后不久,OpenAI 还在 Reddit 上进行了 AMA 问答,下面是我们精选的一些问答,可帮助读者了解官方公告中没有的细节。

问:ChatGPT-5 或其等价 AI 何时发布?
Sam Altman(OpenAI CEO):今年晚些时候我们会发布一些非常好的产品!不过,我们不会称之为 gpt-5。
问:你们何时发布新的文生图模型?Dalle 3 有点过时了。
Sam Altman:下一次更新值得等待!但我们还没有发布计划。
问:你会使用 ChatGPT 回答这些问题吗?
Sam Altman:有时候会,你能分辨吗?
问:AGI 是否可用已知的硬件实现,还是需要一些完全不同的东西?
Sam Altman:我们相信使用当前的硬件就能实现。
问:近年来,OpenAI 从更加开源的方式转向了更加封闭的模式。你能详细解释一下这种变化背后的原因吗?你如何权衡开放性与广泛使用的先进 AI 技术带来的潜在风险之间的利弊?从长远来看,强大的模型最终落入坏人之手是不可避免的吗?
Sam Altman:我认为开源在生态系统中发挥着重要作用,世界上有很多很棒的开源模型。我们还认为,强大且易于使用的 API 和服务也在世界上发挥着重要作用,并且考虑到我们的优势,我们发现了一种更简单的方法来达到我们想要达到的安全阈值。我们非常自豪人们能从我们的服务中获得价值。我希望我们将来能开源更多的东西。
问:o1 完整版何时发布?
Kevin Weil(OpenAI CPO / 首席产品官):

问:ChatGPT 最终能独立执行任务吗?比如先给你发消息?
Kevin Weil:我觉得,这将是 2025 年的热门主题。
问:我的问题是 SearchGPT 与流行搜索引擎相比的价值。SearchGPT 有哪些独特优势或关键差异化因素值得普通搜索引擎用户选择?
Sam Altman:对于许多查询,我发现,为了获取我正在寻找的信息,它是一种更快 / 更容易的方式。我认为我们会看到这一点,特别是对于需要更复杂研究的查询。我也期待未来搜索查询可以在响应中动态地呈现自定义网页!
问:对那些有志为 AI 革命做出贡献的年轻人,你们有什么建议吗?
Kevin Weil:首先,每天开始使用 AI。用它来学习东西,学习你想学的任何东西 —— 编程、写作、产品、设计,任何东西。如果你能比别人学得更快,那么你就能做任何事情。
Srinivas Narayanan(OpenAI 工程开发副总裁):使用 AI 工具来提高你日常工作的生产力 —— 这将带来有趣的想法。然后构建一些有趣的东西并与他人分享。
问:Sora 推迟的原因是推理所需的计算量 / 时间还是安全原因?
Kevin Weil:需要完善模型,需要正确处理安全性 / 假冒他人问题 / 其他事项,也需要扩大计算规模!
问:什么时候发布 AVM(高级语音模式)的视觉版?为什么 GPT-5 花了这么长时间?完整的 o1 如何了?
Sam Altman:我们正在优先考虑推出 o1 及其后续产品。所有这些模型都变得相当复杂,我们无法像我们希望的那样同时推出那么多产品。(关于将计算分配给哪些好想法,我们还面临许多限制和艰难的决定。)尚未确定 AVM 视觉版的日期。
问:你们是否计划降低高级语音的 API 成本?
Kevin Weil:两年来,我们一直在降低 API 成本 —— 我认为 GPT 4o-mini 的成本大约只有原始 GPT-3 的 2%。预计语音和其他功能将继续保持这种趋势!
问:你们的模型名字能起好一点吗?
Kevin Weil:no
问:你们将何时为 ChatGPT 发布相机模式?
Srinivas Narayanan:正在研究。目前没有确切日期。
问:o1 何时支持图片输入?
Kevin Weil:我们关注的重心是先向世界发布,而不是等待其功能齐全。o1 将会支持图像输入,总体而言,o 系列模型将在未来几个月内获得诸如多模态、工具使用等功能。
问:为了实现思维链或多层思维树,OpenAI 认为降低推理成本的速度有多快?
Srinivas Narayanan:我们预计推理成本将继续下降。如果你看看去年的趋势,就会发现它下降了大约 10 倍。
问:到目前为止,你见过的 ChatGPT 的最佳用例是什么?你认为它和它的未来版本(未来几年)可能特别适用于哪些领域?
Sam Altman:有很多好用例,但有一个用例很棒:人们找出使人衰弱的疾病的病因,然后完全治愈了它。适用的领域也有很多,但 AI 作为一名真正优秀的软件工程师的能力仍然被人低估。更普遍地说,帮助科学家更快地发现新知识的能力将会非常棒。
问:会支持 NSFW 内容吗?
Sam Altman:我们完全相信要像对待成年人一样对待成年用户。但要做到这一点需要做大量的工作,而且现在我们有更紧迫的任务。希望有一天能做到这一点!
问:给 Sam Altman 的问题:你是草莓人吗?
Sam Altman:🍓
问:GPT 产品线的下一个突破是什么?有预期时间线吗?
Sam Altman:我们将会拥有越来越好的模型,但我认为下一个巨大突破将会是智能体。
问:相比于 o1-preview,完整版 o1 有明显提升吗?
Srinivas Narayanan:yes
问:对 2025 年有什么大胆预测?
Sam Altman:填满所有基准。

谷歌五分钟就反击了
OpenAI 推出 AI 搜索业务显然触及到了搜索巨头谷歌的核心利益。
不知是否是出于巧合,几乎就在 OpenAI 宣布推出 ChatGPT 搜索的同时,谷歌也宣布了自家的 AI 搜索功能。

谷歌搜索新推出的 Grounding 功能已向 Gemini API 和 Google AI Studio 用户提供,让他们可以在使用 Gemini 时从谷歌搜索获取实时、新鲜、最新的信息。
这场 AI 搜索大战才刚刚开始。
参考内容:
https://openai.com/index/introducing-chatgpt-search/
https://www.theverge.com/2024/10/31/24283906/openai-chatgpt-live-web-search-searchgpt
https://www.reddit.com/r/ChatGPT/comments/1ggixzy/ama_with_openais_sam_altman_kevin_weil_srinivas/
https://news.ycombinator.com/item?id=42008569
https://x.com/OfficialLoganK/status/1852032947714510860
#新研究揭示LLM特征的惊人几何结构
AI自己「长出」了类似大脑的「脑叶」?
大型语言模型在学习概念时竟然会形成令人惊讶的几何结构,比如代码和数学特征会形成一个「叶(lobe)」,类似于我们在做磁共振功能成像时看到的大脑功能性脑叶。这说明什么呢?

论文通讯作者、MIT 物理学教授 Max Tegmark 的推文。值得注意的是,Max Tegmark 也是著名的 KAN 论文的作者之一,是 KAN 论文一作 ZimingLiu 的导师。
在过去的一年,学术界在理解大型语言模型如何工作方面取得了突破性进展:稀疏自编码器(SAE)在其激活空间中发现了大量可解释为概念的点(「特征」)。最近,此类 SAE 点云已公开发布,因此研究其在不同尺度上的结构正当其时。
最近,来自 MIT 的一个团队公布了他们的研究成果。
- 论文标题:The Geometry of Concepts: Sparse Autoencoder Feature Structure
- 论文链接:https://arxiv.org/pdf/2410.19750
具体来说,他们发现 SAE 特征的概念宇宙在三个层面上具有有趣的结构:
第一个是「原子」小尺度层面。在这个层面上,作者发现 SAE 特征的概念宇宙包含「晶体」结构,这些晶体的面是平行四边形或梯形,这泛化了众所周知的例子,如 (man:woman::king:queen)。他们还发现,当排除全局干扰方向,如单词长度时,这类平行四边形和相关功能向量的质量大大提高,这可以通过线性判别分析有效地完成。

第二个是「大脑」中等尺度层面。在这个层面,作者发现 SAE 特征的概念宇宙具有显著的空间模块性。例如,数学和代码特征会形成一个「叶(lobe)」,类似于我们在做神经磁共振功能成像时看到的大脑功能性叶(如听觉皮层)。作者用多个度量来量化这些叶的空间局部性,并发现在足够粗略的尺度上,共现特征(co-occurring feature)的聚类在空间上也聚集在一起,远远超过了特征几何是随机的情况下的预期。

第三个是「星系」大尺度层面。在这个层面上,作者发现 SAE 特征点云的结构不是各向同性的,而是呈现出一种特征值的幂律分布,并且在中间层的斜率最陡。此外,他们还量化了聚类熵如何随层数的变化而变化。

这项研究吸引了不少研究者的注意。有人评论说,AI 系统在处理信息时自然地发展出几何和分形结构,而这些结构与生物大脑中的结构相似。这一现象表明,数学上的组织模式可能是自然界的基本特性,而不仅仅是人类的认知构造。

也有人提出了一些不同观点,认为这种结构可能更多是源于 AI 模型从人类数据中学习的结果,而不是一种完全独立的自然特性。反驳者认为,由于人类也是一种生物神经网络,当大规模 AI 系统基于小规模神经网络的输入数据进行训练时,它们自然而然地会接近这种结构模式,因此 AI 模型的结构并非完全出乎意料。反驳者还提出了一个有趣的设想:如果 AI 模型在完全不包含人类数据的「外星」数据集上进行训练,那么模型的组织结构可能会有很大的不同 —— 尽管模型仍然可能会产生聚类和分组的结构以有效处理复杂信息,但实际的概念和结构可能会和人类的完全不同。

论文作者表示,他们希望这些发现有助于大家深入理解 SAE 特征和大型语言模型的工作原理。他们也会在未来继续研究,以了解为什么其中一些结构会出现。

以下是论文的详细信息。
「原子」尺度:晶体结构
在这一部分中,作者寻找他们所说的 SAE 特征点云中的晶体结构。这里的结构指的是反映概念之间语义关系的几何结构,它泛化了(a, b, c, d)=(man,woman,king,queen)形成近似平行四边形的经典例子,其中 b − a ≈ d − c。这可以用两个功能向量 b − a 和 c − a 来解释,分别将男性实体转为女性,将普通人转为皇室成员。他们还寻找只有一对平行边 b - a ∝ d - c 的梯形(只对应一个功能向量);图 1(右)展示了这样一个例子,其中(a, b, c, d)=(Austria, Vienna, Switzerland, Bern),这里的功能向量可以被解释为将国家映射到它们的首都。

作者通过计算所有成对差分向量并对其进行聚类来寻找晶体,这应该会产生一个对应于每个功能向量的聚类。一个聚类中的任意一对差分向量应该形成一个梯形或平行四边形,这取决于差分向量在聚类前是否被归一化(或者是否通过欧氏距离或余弦相似性来量化两个差分向量之间的相似性)。
作者最初搜索 SAE 晶体时发现的大多是噪声。为了探究原因,他们将注意力集中在第 0 层(token 嵌入)和第 1 层,那里许多 SAE 特征对应于单个词汇。然后他们研究了 Gemma2-2b 残差流激活,这些激活是针对之前报告的来自 Todd 等人 (Todd et al., 2023) 数据集中的 word->word 功能向量,这澄清了问题。图 1 说明了候选晶体四元组通常远非平行四边形或梯形。这与多篇论文指出的(man, woman, king, queen)也不是一个准确的平行四边形是一致的。
作者发现,导致这一问题的原因是存在他们所说的干扰特征。例如,他们发现图 1(右)中的水平轴主要对应于单词长度(图 10),这在语义上是不相关的,并且对梯形(左)造成了破坏,因为「Switzerland」比其他单词长得多。

为了消除这些语义上不相关的干扰向量,他们希望将数据投影到一个与它们正交的低维子空间上。对于 (Todd et al., 2023) 数据集,他们使用线性判别分析(LDA)来实现这一点,它将数据投影到信号 - 噪声的特征模式上,其中「信号」和「噪声」分别定义为聚类间变化和聚类内变化的协方差矩阵。图 1 显示,这极大地提高了聚类和梯形图 / 平行四边形的质量,突出表明干扰特征可能会隐藏现有的晶体。
「大脑」尺度:中尺度模块性结构
现在放大视野,寻找更大规模的结构。具体来说,作者研究了功能相似的 SAE 特征组(倾向于一起激活)是否在几何上也是相似的,从而在激活空间中形成「叶」。
在动物大脑中,这些功能组是众所周知的神经元所在 3D 空间中的聚类。例如,布洛卡区参与语言产生,听觉皮层处理声音,而杏仁体主要与情绪处理相关。作者好奇是否能在 SAE 特征空间中找到类似的功能模块性。
作者测试了多种自动发现此类功能「叶」以及量化它们是否具有空间模块性的方法。他们将叶分区定义为将点云分割为 k 个子集(「叶」),这些子集的计算不依赖于位置信息。相反,他们识别这些叶的依据是它们在功能上的相关性,具体来说,就是在一个文档中趋向于共同激活。
为了自动识别功能叶,作者首先计算 SAE 特征共现的直方图。他们使用 gemma-2-2b,并将 The Pile Gao et al. (2020) 中的文档传递给它。在这一部分,他们将报告第 12 层残差流 SAE 的结果,该层有 16k 个特征,平均 L0 为 41。
对于这个 SAE,他们记录了激活的特征(如果其隐藏激活 > 1,他们认为一个特征被激活)。如果两个特征在 256 个 token 组成的同一个块内被激活,则它们就被视为共现 —— 这个长度提供了一个粗略的「时间分辨率」,使他们能够找到在同一文档中倾向于一起激活的 token。他们使用 1024 的最大上下文长度,并且每个文档只使用一个这样的上下文,因此每篇 The Pile 文档最多只能有 4 个块(和直方图更新)。他们计算了 50k 个文档的直方图。给定这个直方图,他们基于它们的共现统计计算每对 SAE 特征之间的亲和度(affinity),并对得到的亲和度矩阵进行谱聚类。
作者尝试了以下基于共现的亲和概念:简单匹配系数、Jaccard 相似性、Dice 系数、重叠系数和 Phi 系数,所有这些都可以仅从共现直方图计算得出。
作者的 null 假设是,功能相似的点(通常共现的 SAE 特征)在激活空间中均匀分布,没有空间模块性。相反,图 2 显示了看起来相当空间局部化的叶。为了量化这一点在统计上的重要性,作者使用两种方法来排除 null 假设。

1、虽然我们可以根据它们是否共现来聚类特征,但也可以根据 SAE 特征解码向量之间的余弦相似度执行谱聚类。给定一个使用余弦相似度的 SAE 特征聚类和一个使用共现的聚类,计算这两组标签之间的互信息。从某种意义上说,这直接衡量了人们从了解功能结构中获得的几何结构的信息量。
2、另一个概念上简单的方法是训练模型,从其几何形状预测一个特征所在的功能叶。为此,作者从基于共现的聚类中获取一组给定的叶标签,并训练一个 logistic 回归模型,直接从点位置预测这些标签,采用 80-20 的训练 - 测试比例,并报告该分类器的平衡测试准确率。
图 3 显示,在这两种测量方法中,Phi 系数胜出,在功能叶和特征几何之间实现了最佳对应。为了证明这一点具有统计学意义,作者从基于余弦相似性的聚类中随机排列聚类标签,并测量调整后的互信息。他们还从随机高斯中随机重新初始化 SAE 特征解码器方向并归一化,然后训练 logistic 回归模型,从这些特征方向预测功能叶。图 3(下)显示,这两个测试都以高显著性排除了 null 假设,标准差分别为 954 和 74,这清楚地表明作者看到的叶是真实的,而不是统计上的偶然。

为了评估每个叶专门做什么,作者通过 gemma-2-2b 运行来自 The Pile 的 10k 个文档,并再次记录第 12 层的哪些 SAE 特征在 256 个 token 组成的块内激活。对于每个 token 块,他们记录哪个叶有最高比例的特征激活。
作者在图 4 中展示了三个叶的结果,这些结果是使用 Phi 系数作为共现度量的,这构成了图 2 中叶标记的基础。

图 5 比较了五种不同的共现度量的效果。尽管作者发现 Phi 是最好的,但所有五种都发现了「代码 / 数学叶」。

「星系」尺度:大规模点云结构
在本节中,作者进一步放大视野,研究点云的「星系」尺度结构,主要是其整体形状和聚类,类似于天文学家研究星系形状和亚结构的方式。
作者试图排除的简单 null 假设是,点云仅仅是从一个各向同性的多元高斯分布中抽取的。图 6 从视觉上直观地表明点云的形状并不仅仅是圆形,即使在其前三个主成分中,一些主轴也比其他的略宽,类似于人脑。

形状分析
图 7(左)通过展示点云协方差矩阵的特征值递减来量化这一点,揭示它们并不恒定,而是似乎按照幂律下降。为了测试这种令人惊讶的幂律是否显著,该图将其与从各向同性高斯分布中抽取的点云的相应特征值谱进行比较,后者看起来更为平坦,与分析预测一致:多元高斯分布的 N 个随机向量的协方差矩阵遵循 Wishart 分布,这在随机矩阵理论中得到了很好的研究。由于最小特征值的突然下降是由数据有限引起的,并在 N → ∞的极限中消失,作者将点云降维到其 100 个最大的主成分进行后续的所有分析。换句话说,点云的形状像是一个「分形黄瓜」,在连续的维度中宽度按照幂律下降。作者发现这种幂律缩放对于激活来说明显不如对于 SAE 特征那么突出;进一步研究其起源将很有趣。

图 7(右)显示了上述幂律斜率如何取决于 LLM 层,计算方法是对 100 个最大特征值进行线性回归。可以看到一个明显的模式,即中间层具有最陡峭的幂律斜率:(第 12 层的斜率为 - 0.47,而前面和后面的层(如第 0 层和第 24 层)的斜率较浅(分别为 - 0.24 和 - 0.25)。这可能暗示了中间层起到了瓶颈的作用,将信息压缩为较少的主成分,或许是为了更有效地表示高层次抽象概念而进行的优化。图 7(右)还显示了有效云体积(协方差矩阵的行列式)如何依赖于层(在对数尺度上。
聚类分析
星系或微观粒子的聚类通常以功率谱或相关函数来量化。对于论文中的高维数据来说,这种方法比较复杂,因为基本密度随半径变化,对于高维高斯分布来说,基本密度主要集中在一个相对较薄的球壳周围。因此,作者通过估算点云采样分布的熵来量化聚类。他们使用 k-NN 方法从 SAE 特征点云估计熵 H,计算如下,

对于具有相同协方差矩阵的高斯分布,熵计算为:

图 8 显示了不同层的估计聚类熵。作者发现 SAE 点云特别在中间层有很强的聚类。

这项研究的结果非常有趣,如果你有关于这篇论文的见解,欢迎在评论区留言。
#RIFLEx
一行代码、无需训练突破视频生成时长「魔咒」,清华朱军团队开源全新解决方案RIFLEx
自 OpenAI 发布 Sora 以来,视频生成领域迎来爆发式增长,AI 赋能内容创作的时代已然来临。
去年 4 月,生数科技联合清华大学基于团队提出的首个扩散 Transformer 融合架构 U-ViT,发布了首个国产全自研视频大模型 Vidu,打破国外技术垄断,支持一键生成 16 秒高清视频,展现出中国科技企业的创新实力。Vidu 自去年 7 月上线以来,已服务数千万用户,极大促进了视频内容的智能创作。近期,腾讯混元、阿里通义万相等开源视频生成模型相继亮相,可生成 5-6 秒视频,进一步降低了视频创作门槛。
尽管如此,海内外社区仍有不少用户抱怨现有开源模型受限于生成 5-6 秒的短视频,时长不够用。

今天,Vidu 团队带来了一个简洁优雅的解决方案 ——RIFLEx。新方案仅需一行代码、无需额外训练即可突破视频生成模型现有长度限制,打破「短视频魔咒」。目前该项目已经开源,体现了团队对开源社区的积极回馈和贡献。
- 项目地址:https://riflex-video.github.io/
- 代码地址: https://github.com/thu-ml/RIFLEx
RIFLEx适用于基于RoPE的各类Video Diffusion Trasnsformer,例如CogvideoX、混元(链接到之前推送)以及最新发布的通义万相(链接到之前的推送)。
下列为开源模型无需任何训练直接时长外推两倍至10s效果:
- 大幅度运动:
,时长00:10
prompt: 一只棕白相间的动画豪猪好奇地审视着缎带装饰的绿色盒子,灵动的眼神与细腻的3D动画风格营造出温馨而精致的视觉体验。
- 多人物复杂场景:
,时长00:10
prompt: 荒凉空地上的简易营地散布着无人机与物资,军人与平民共处,一名男子绝望抱头,女子忧虑注视,沉重氛围暗示刚经历重大事件,镜头稳定细腻,突出紧张与不安感。
- 自然动态流畅:
,时长00:10
sora的经典长毛猛犸象prompt
在短视频微调几千步可进一步提升性能。
- 多转场时序一致性保持:
,时长00:10
prompt: 蓬乱头发、穿棕色夹克系红色领巾的男子在马车内严肃端详硬币,与女子交谈,广角与中近景结合展现历史剧风格与戏剧氛围。
- 3D动画风格:
,时长00:10
prompt: 动画中的兔子和老鼠,身穿探险装备正处于险境之中。它们急速坠入一个黑暗而未知的空间,紧接着便漂浮并游动在宁静的水下世界里。紧张而坚定的表情通过中景与特写展现,高质量3D动画风格增强电影感与沉浸感。
- 真实人物特写:
,时长00:10
prompt: 留着胡须、穿格子衬衫的男子坐着弹奏原声吉他,沉浸于激情演唱。他所在的室内环境简洁,背景是一面纯灰色墙壁,左侧放置着一个吉他音箱和麦克风架,右侧摆放着一叠书籍。
除此之外,RIFLEx 不仅支持视频的时间维度外推(如基于已有帧生成未来帧或延长视频时序长度),还可扩展至空间维度外推(如通过局部画面超分辨率重建、修复缺失区域或扩展视频边界内容),以及可同时进行的时空外推(如生成未来高分辨率视频序列或动态扩展视频的时空内容,兼顾时间连续性与空间一致性)。
- 图像宽度外推两倍:

左图为训练尺寸,右图为外推结果
- 图像高度外推两倍:

左图为训练尺寸,右图为外推结果
- 图像高宽同时外推两倍:

左图为训练尺寸,右图为外推结果
- 视频时空同时外推两倍:
,时长00:06
训练尺寸:480*720*49
,时长00:12
外推结果:960*1440*97
该研究成果一经发布,获得了广泛关注。
知名博主 Ak 第一时间转发,海外科技公司和博主称赞其为「视频扩散模型领域的突破性创新」。

Diffusers 核心贡献者 sayakpaul 和 a-r-r-o-w 也收藏了代码并留言点赞:

目前 RIFLEx 已被社区用户集成到各类知名视频生成仓库:

揭秘 RIFLEx:化繁为简,直击本质
长度外推问题在大型语言模型中早有研究,但这些方法在视频生成中却屡屡碰壁,导致时序内容重复或慢动作效果。
,时长00:10
直接外推导致视频内容重复,红色框表示开始和视频开头重复
,时长00:10
同时结合外推和内插的Yarn导致慢动作效果
为破解这一难题,Vidu 团队深入挖掘 RoPE 的频率成分,揭示了其每个频率成分在视频生成的作用:
1. 时间依赖距离:不同频率成分只能捕捉特定周期长度的帧间依赖关系。当帧数超过周期长度时,周期的性质导致位置编码重复,从而使视频内容也会出现重复。
2. 运动速度:不同频率成分捕捉不同的运动速度,由该频率的位置编码变化率决定。高频成分捕捉快速运动,低频成分捕捉慢速运动。

当所有频率成分结合时,存在一个 「内在频率」,即周期距离首次观测重复帧最近的成分,它决定了视频外推时的重复模式。
基于此,团队提出 RIFLEx:通过降低内在频率,确保外推后的视频长度在一个周期内,从而避免内容重复。该方法仅需在经典 RoPE 编码中加入一行代码即可实现。

这一方案为视频生成领域提供了新的思路,有望推动长视频生成技术的进一步发展。
团队介绍
论文第一作者赵敏为清华大学TSAIL 团队博后研究员,研究方向为基于扩散模型的视觉内容生成。赵敏是生数科技视频生成大模型Vidu的核心开发者之一,此前以第一作者发表在NeurIPS、ICLR、ECCV等顶级会议和期刊发表论文数篇,并入选2024年清华大学“水木学者”。个人主页:https://gracezhao1997.github.io/。
清华大学 TSAIL 团队长期致力于扩散模型的研究,代表性工作包括Analytic-DPM(ICLR 2022 杰出论文奖)、U-ViT、DPM-solver、ProlificDreamer等,并研制了首个对标Sora的高动态、长时长的视频生成大模型Vidu。论文其他作者均为TSAIL 课题组学生,其中何冠德和朱泓舟也参与了Vidu的开发,陈亦逍为清华大学计算机系大三本科生,李崇轩已经毕业,现任中国人民大学高瓴人工智能学院副教授。
#揭示显式CoT训练机制
思维链如何增强推理泛化能力
基于逐步生成解决方案的大语言模型(LLMs)训练范式在人工智能领域获得了广泛关注,并已发展成为行业内的主流方法之一。
例如,OpenAI 在其「12 Days of OpenAI」直播系列的第二日推出了针对 O1 模型的强化微调(Reinforcement Fine-Tuning,RFT),进一步推动了 AI 定制化的发展[1]。RFT/ReFT[2] 的一个关键组成部分是使用思维链(Chain-of-Thought,CoT)注释[3] 进行监督微调(Supervised Fine-Tuning,SFT)。在 DeepSeek-R1 模型[4] 中,引入了少量长 CoT 冷启动数据,以调整模型作为初始强化学习的代理。
然而,为了全面理解采用 CoT 训练的策略,需要解决两个关键问题:
- Q1:与无 CoT 训练相比,采用 CoT 训练有哪些优势?
- Q2:如果存在优势,显式 CoT 训练的潜在机制是什么?
由于实际训练过程中涉及众多因素,分析显式 CoT 训练的优势及其潜在机制面临显著挑战。为此,我们利用清晰且可控的数据分布进行了详细分析,并揭示了以下有趣现象:
- CoT 训练的优势
(i)与无 CoT 训练相比,CoT 训练显著增强了推理泛化能力,将其从仅适用于分布内(in-distribution, ID)场景扩展到 ID 和分布外(out-of-distribution, OOD)场景(表明系统性泛化),同时加速了收敛速度(图 1)。

图表 1: 模型在优化过程中对训练和测试两跳推理事实的准确率。
(ii)即使 CoT 训练中包含一定范围的错误推理步骤,它仍能使模型学习推理模式,从而实现系统性泛化(图 4 和图 5)。这表明数据质量比方法本身更为重要。训练的主要瓶颈在于收集复杂的长 CoT 解决方案,而推理步骤中存在少量的错误是可以接受的。
- CoT 训练的内部机制
(i)数据分布的关键因素(如比例 λ 和模式 pattern)在形成模型的系统性泛化中起着决定性作用。换句话说,在 CoT 训练中仅接触过两跳数据的模型无法直接泛化到三跳情况,它需要接触过相关模式。
(ii)通过 logit lens 和 causal tracing 实验,我们发现 CoT 训练(基于两跳事实)将推理步骤内化到模型中,形成一个两阶段的泛化电路。推理电路的阶段数量与训练过程中显式推理步骤的数量相匹配。
我们进一步将分析扩展到推理过程中存在错误的训练数据分布,并验证了这些见解在现实数据上对更复杂架构仍然有效。
据我们所知,我们的研究首次在可控制的实验中探索了 CoT 训练的优势,并提供了基于电路的 CoT 训练机制解释。这些发现为 CoT 以及 LLMs 实现稳健泛化的调优策略提供了宝贵的见解。
- 论文标题:Unveiling the Mechanisms of Explicit CoT Training: How Chain-of-Thought Enhances Reasoning Generalization
- 论文链接:https://arxiv.org/abs/2502.04667
一、预备知识与定义
本部分介绍研究使用的符号定义,具体如下:
原子与多跳事实:研究使用三元组

来表示原子(一跳)事实,并基于原子事实和连接规则来表示两跳事实以及多跳事实。

训练数据:研究使用的训练数据包括所有的原子(一跳)事实(即

),以及分布内(ID)的两跳事实(即

)。其中记 | 两跳事实 |:| 原子事实 |= λ。

训练方式:对于原子(一跳)事实,模型的训练和评估通过预测最终尾实体来完成。对于两跳事实,考虑是否使用 CoT 注释进行训练。
(1) Training without CoT:模型输入

,预测目标只有最终尾实体
![]()
;
(2) Training with CoT:模型输入

,预测桥接实体
![]()
和最终尾实体
![]()
。

评估:为更好地评估模型的泛化能力,我们从分布内(ID)和分布外(OOD)两个维度进行性能评估。
(1)分布内泛化旨在通过评估模型完成未见过的两跳事实

的能力,判断模型是否正确学习了潜在模式。
(2)分布外泛化则用于评估模型获得的系统性能力,即模型将学习到的模式应用于不同分布知识的能力,这是通过在

事实上测试模型来实现的。若模型在分布内数据上表现良好,可能仅表明其记忆或学习了训练数据中的模式。然而,在分布外数据上的优异表现则表明模型确实掌握了潜在模式,因为训练集仅包含原子事实

,而不包含

。
二、系统性组合泛化
本研究聚焦于模型的组合能力,即模型需要将不同事实片段「串联」起来的能力。尽管显式的推理步骤表述(如思维链推理)能够提升任务表现 [4-8],但这些方法在大规模(预)训练阶段并不可行,而该阶段正是模型核心能力形成的关键时期 [9-10]。已有研究对基于 Transformer 的语言模型是否能够执行隐式组合进行了广泛探讨,但均得出了否定结论 [11-12]。
具体而言,存在显著的「组合性鸿沟」[11],即模型虽然掌握了所有基础事实却无法进行有效组合的情况,这种现象在不同大语言模型中普遍存在,且不会随模型规模扩大而减弱。
更准确地说,Wang 等人 [13] 的研究表明,Transformer 模型能够在同分布泛化中学习隐式推理,但在跨分布泛化中则表现欠佳(如图 1 左所示)。
这自然引出一个问题:如果在训练过程中使用显式推理步骤,模型的泛化能力将受到何种影响?(即回答 Q1:与无思维链训练相比,基于思维链的训练具有哪些优势?)
思维链训练显著提升推理泛化能力
如图 1 所示,我们展示了模型在训练和测试两跳事实上的准确率随优化过程的变化,其中 λ = 7.2。
(1)Training without CoT(图 1 左)。我们观察到了与 Wang 等人 [13] 相同的现象(称为顿悟现象 [14]),即模型能够较好地泛化到分布内测试样本

,但高性能只有在经过大量训练后才能实现,远超过过拟合点。此外,即使经过数百万次优化步骤的训练,仍未观察到分布外泛化(

)的迹象,这表明这是一种缺乏系统性的延迟泛化现象。模型可能只是记忆或学习了训练数据中的模式。
(2)Training with CoT(图 1 右)。使用思维链标注后,模型在训练集上的收敛速度加快,且在训练过程中更早地实现了较高的测试性能,特别是在分布内测试样本上。模型在大约 4,000 次优化步骤后,在同分布测试集

上的准确率就达到了接近完美的水平,表明与无思维链训练相比,泛化能力得到了显著提升。分布外泛化(

)也显示出明显改善,这突出表明思维链提示训练不仅在分布内泛化方面,而且在分布外泛化方面都发挥着关键作用,尽管效果程度有所不同。

关键影响因素探究
研究进一步开展了消融实验,以评估不同因素在思维链训练中的影响。

图表 2: 分布外测试集上的推理泛化速度。
适当的 λ 值能够加速模型收敛。图 2(左)展示了不同 λ 值下的分布外测试准确率。可以看出,λ 值与泛化速度存在强相关性。更有趣的是,较小的 λ 值能够加速由思维链训练带来的分布外泛化能力提升,从而减少对长时间训练的需求。然而,λ 值并非越小越好,因为过小的 λ 值可能导致模型无法学习相关规则。
不同模型规模 / 层数和训练集大小的影响。我们在模型层数∈{2,4,8} 和 λ∈{3.6,7.2,12.6} 的条件下进行实验。总体而言,可以观察到扩大模型规模并不会从根本上改变其泛化行为,主要趋势是较大的模型能够在更少的优化步骤中收敛。关于训练集大小(|E|)的影响,我们的结果与 [13] 一致:当固定 λ 值时,训练集大小不会对模型的泛化能力产生本质影响。
两跳到多跳分析
在本部分中,研究将重点转向多跳场景:在思维链训练阶段仅接触过两跳事实的模型,能否泛化到三跳事实?
在思维链训练中,我们仅使用单跳 / 两跳事实,并测试模型是否能够泛化到三跳事实的推理(这里研究使用

来表示三跳事实)。
结果:在思维链训练中仅接触过两跳数据的模型无法直接泛化到三跳场景。然而,当训练集中加入一定量的三跳数据后,模型能够快速实现泛化(前提是模型需要接触过相关模式)。另一方面,当我们人为地将一个三跳事实拆分为两个两跳事实进行测试时,模型也能够有效泛化。换句话说,我们分别测试

预测
![]()
和

预测
![]()
,当两者都正确时,我们认为
![]()
预测

是正确的。这些发现与 [15] 结果一致:思维链与重现训练集中出现的推理模式有关。

总结:至此,我们已经证明在受控实验中引入显式思维链训练能够显著提升推理泛化能力,使其从仅限分布内泛化扩展到同时涵盖分布内和分布外泛化。数据分布的关键因素(如比例和模式)在形成模型的系统性泛化能力中起着重要作用。然而,驱动这些改进的内部机制仍不明确,我们将进一步探讨(回答 Q2:如果存在优势,显式思维链训练的潜在机制是什么?)。

图表 3: 两跳事实训练对应的两阶段泛化电路(模型层数:8)。
三、两阶段泛化电路
研究通过两种主流方法分析模型在泛化过程中的内部工作机制:logit lens [16] 和 causal tracing [17],本部分研究使用

表示两跳推理。
图 3 展示了发现的泛化电路,该电路代表了 8 层模型在实现两跳分布外(OOD)泛化后的因果计算路径。具体而言,我们识别出一个高度可解释的因果图,该图由第 0 层、第 l 层和第 8 层的状态组成,其中弱节点和连接已被剪枝(If perturbing a node does not alter the target state (top-1 token through the logit lens), we prune the node)。
(1)在第一跳阶段,第 l 层将电路分为上下两部分:下部从输入
![]()
中检索第一跳事实,并将桥接实体
![]()
存储在状态
![]()
中;上部通过残差连接将的信息传递到输出状态(其中
![]()
表示对应位置的激活)。由于数据分布可控,l 层可以精确定位(对于 ID 为第 3 层,对于 OOD 为第 5 层)。
(2)在第二跳阶段,自回归模型使用第一跳阶段生成的
![]()
。该阶段省略了

,并从输入
![]()
处理第二跳,将尾实体
![]()
存储到输出状态
![]()
中。

系统性泛化解释
(1)两阶段泛化电路表明,使用思维链训练可以将推理步骤内化到模型中。这也解释了为什么模型在思维链训练下能够在跨分布测试数据上表现出良好的泛化能力。
(2)该电路由两个阶段组成,与训练期间模型中的显式推理步骤相一致。因此,模型在思维链训练期间仅接触两跳数据时无法在测试阶段直接泛化到三跳场景。
四、更普适的分析
总体而言,我们目前的研究为通过受控数据分布上的思维链训练来深入理解和增强 Transformer 的泛化能力铺平了道路。然而,现实世界中的训练数据分布往往更为复杂。在本部分中,我们将分析扩展到推理过程中存在错误的分布,并展示思维链训练能提高模型的泛化能力的结论在更复杂的场景中仍然成立。
数据分布带噪
方法:我们旨在分析通过思维链训练获得的系统性泛化能力在噪声训练数据下的鲁棒性。我们通过随机选择一个有效实体向

引入噪声(真实训练目标为
![]()
):
(1)仅第二跳有噪声,即
![]()
;
(2)两跳均有噪声,即
![]()
。
需要注意的是,噪声比例用 ξ 表示,我们将探讨不同 ξ 值的影响。

图表 4: 仅第二跳噪声对分布内和分布外的影响。

图表 5: 模型在不同噪声比例(两跳均有噪声)下对训练和测试两跳推理事实的准确率。
结果:我们针对两种情况分析了不同的 ξ(噪声比例)候选集:仅第二跳有噪声时为 {0.05, 0.2, 0.4, 0.6, 0.8},两跳均有噪声时为 {0.05, 0.1, 0.2, 0.4}。比较结果如下:
(1)图 4 清晰地展示了仅第二跳噪声对分布内和分布外泛化的影响。总体而言,在思维链训练条件下,模型仍能够从噪声训练数据中实现系统性泛化,但其泛化能力随着噪声比例的增加而降低。
更具体地说,随着训练的进行,分布外泛化最初保持不变,然后增加,而分布内泛化先增加后减少。分布内泛化的减少与分布外泛化的增加相对应。
然而,随着噪声比例的增加,分布内和分布外泛化的最终性能都会下降。特别是当噪声比例(ξ < 0.2)相对较小时,模型几乎不受影响,这展示了思维链训练的鲁棒性。
此外,我们同样检查了泛化电路。由于我们仅在第二跳添加噪声,第一跳阶段的电路学习得相对较好,而第二跳阶段的电路受噪声影响更大。
(2)图 5 展示了在两跳噪声 ξ 值为 0.05、0.1、0.2 和 0.4 时的结果比较。与仅在第二跳添加噪声相比,在两跳都添加噪声对模型泛化的抑制效果要强得多。大于 0.2 的噪声比例足以几乎消除分布内和分布外泛化能力。
总而言之,即使在训练数据存在噪声的情况下,当噪声在一定范围内时,思维链训练仍能使模型实现系统性泛化。特别是当噪声比例较小时,这些噪声数据仍能帮助模型学习泛化电路。

五、讨论
总结
本文通过在受控和可解释的环境中展示系统性组合泛化如何通过显式思维链(CoT)训练在 Transformer 中产生,揭示了思维链训练的核心机制。具体而言:
(1)与无思维链训练相比,思维链训练显著增强了推理泛化能力,使其从仅限分布内(ID)泛化扩展到同时涵盖分布内和分布外(OOD)场景。
(2)通过 logit lens 和 causal tracing 实验,我们发现思维链训练(使用两跳事实)将推理步骤内化到 Transformer 中,形成了一个两阶段泛化电路。然而,模型的推理能力受训练数据复杂性的限制,因为它难以从两跳情况泛化到三跳情况。这表明思维链推理主要是重现了训练集中存在的推理模式。
(3)我们进一步将分析扩展到推理过程中存在错误的训练数据分布,证明当噪声保持在一定范围内时,思维链训练仍能使模型实现系统性泛化,此类噪声数据的结构或许有助于泛化电路的形成。
有趣的是,我们的工作还突出了思维链训练的瓶颈:训练数据分布(比例 λ 和模式)在引导模型实现泛化电路方面起着关键作用。模型需要在训练过程中接触过相关模式(特别是思维链步骤的数量)。
这可能解释了为什么 DeepSeek-R1 [4] 在冷启动阶段构建和收集少量长思维链数据来微调模型。我们的发现为调整大语言模型(LLMs)以实现稳健泛化的策略提供了关键见解。
不足与未来展望
(1)尽管我们的自下而上的研究为实际应用提供了宝贵的见解,但我们工作的一个关键局限是实验和分析基于合成数据,这可能无法完全捕捉现实世界数据集和任务的复杂性。虽然我们的一些结论也在 Llama2-7B [18] 等模型中得到了验证,但有必要在更广泛的模型上进行进一步验证,以弥合我们的理论理解与实际应用之间的差距。
(2)我们的分析目前仅限于使用自然语言。未来,我们旨在探索大型语言模型在无限制潜在空间中的推理潜力,特别是通过训练大型语言模型在连续潜在空间中进行推理 [19] 等方法。
(3)最近的一种方法,「backward lens」[20],将语言模型的梯度投影到词汇空间,以捕捉反向信息流。这为我们完善思维链训练的潜在机制分析提供了一个新的视角。
作者介绍
刘勇,中国人民大学,长聘副教授,博士生导师,国家级高层次青年人才。长期从事机器学习基础理论研究,共发表论文 100 余篇,其中以第一作者 / 通讯作者发表顶级期刊和会议论文近 50 篇,涵盖机器学习领域顶级期刊 JMLR、IEEE TPAMI、Artificial Intelligence 和顶级会议 ICML、NeurIPS 等。获中国人民大学「杰出学者」、中国科学院「青年创新促进会」成员、中国科学院信息工程研究所「引进优青」等称号。主持国家自然科学面上 / 基金青年、北京市面上项目、中科院基础前沿科学研究计划、腾讯犀牛鸟基金、CCF - 华为胡杨林基金等项目。
姚鑫浩,中国人民大学高瓴人工智能学院博士研究生,本科毕业于中国人民大学高瓴人工智能学院。当前主要研究方向包括大模型推理与机器学习理论。
参考文献
[1] OpenAI. 12 days of openai. https://openai.com/ 12-days/, 2024a.
[2] Trung, L., Zhang, X., Jie, Z., Sun, P., Jin, X., and Li, H. ReFT: Reasoning with reinforced fine-tuning. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.7601–7614, 2024.
[3] Wei, J., Wang, X., Schuurmans, D., Bosma, M., brian ichter, Xia, F., Chi, E. H., Le, Q. V., and Zhou, D. Chain of thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, 2022.
[4] DeepSeek-AI, Guo, D., Yang, D., Zhang, H., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2501.12948.
[5] Lake, B. and Baroni, M. Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks. In Proceedings of the International Conference on Machine Learning, pp. 2873–2882, 2018a.
[6] Wang, B., Deng, X., and Sun, H. Iteratively prompt pretrained language models for chain of thought. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 2714–2730, 2022.
[7] Zelikman, E., Wu, Y., Mu, J., and Goodman, N. STar: Bootstrapping reasoning with reasoning. In Advances in Neural Information Processing Systems, 2022.
[8] Liu, J., Pasunuru, R., Hajishirzi, H., Choi, Y., and Celikyilmaz, A. Crystal: Introspective reasoners reinforced with self-feedback. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 11557–11572, 2023.
[9] Li, Z., Wallace, E., Shen, S., Lin, K., Keutzer, K., Klein, D., and Gonzalez, J. Train big, then compress: Rethinking model size for efficient training and inference of transformers. In Proceedings of the 37th International Conference on Machine Learning, pp. 5958–5968, 2020.
[10] Zhou, C., Liu, P., Xu, P., Iyer, S., Sun, J., Mao, Y., Ma, X., Efrat, A., Yu, P., YU, L., Zhang, S., Ghosh, G., Lewis, M., Zettlemoyer, L., and Levy, O. Lima: Less is more for alignment. In Advances in Neural Information Processing Systems, 2023a.
[11] Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N., and Lewis, M. Measuring and narrowing the compositionality gap in language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 5687– 5711, 2023.
[12] Yang, S., Gribovskaya, E., Kassner, N., Geva, M., and Riedel, S. Do large language models latently perform multi-hop reasoning?, 2024. URL https://arxiv. org/abs/2402.16837.
[13] Wang, B., Yue, X., Su, Y., and Sun, H. Grokking of implicit reasoning in transformers: A mechanistic journey to the edge of generalization. In Advances in Neural Information Processing Systems, 2024a.
[14] Power, A., Burda, Y., Edwards, H., Babuschkin, I., and Misra, V. Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022. URL https:// arxiv.org/abs/2201.02177.
[15] Cabannes, V., Arnal, C., Bouaziz, W., Yang, X. A., Charton, F., and Kempe, J. Iteration head: A mechanistic study of chain-of-thought. In Advances in Neural Information Processing Systems, 2024.
[16] Nostalgebraist. Interpreting gpt: The logit lens, 2020.
[17] Pearl, J. Causality: Models, Reasoning, and Inference. Cambridge University Press, Cambridge, 2009. ISBN 9780521426085.
[18] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Roziere, B., Goyal, N., Hambro, E., ` Azhar, F., et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[19] Hao, S., Sukhbaatar, S., Su, D., Li, X., Hu, Z., Weston, J., and Tian, Y. Training large language models to reason in a continuous latent space, 2024b. URL https:// arxiv.org/abs/2412.06769.
[20] Katz, S., Belinkov, Y., Geva, M., and Wolf, L. Backward lens: Projecting language model gradients into the vocabulary space. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 2390–2422, 2024.
#OpenAI突然发布智能体API
支持网络和文件搜索以及computer use
「Agent/智能体」可说是当今 AI 领域最炙手可热的话题。今天凌晨,OpenAI 发布了一系列可让开发者通过 API 构建智能体的新工具,其中最大的看点便是 Responses API,这是对之前的 Chat Completions API 的一轮大升级,使其获得了 Assistants API 般使用工具的能力,从而可以帮助开发者构建智能体。目前,Responses API 已经内置了网络搜索、文件搜索和计算机使用(computer use)能力。

OpenAI CEO Sam Altman 表示 Chat Completions API 是有史以来设计最完善、最实用的 API 之一。
熟悉大模型应用开发的人都知道,当今不少大模型提供商的服务都兼容 OpenAI 之前提出的 Chat Completions API,其对行业标准化做出了非常大的贡献。而今发布的 Responses API 或许也将成为智能体响应标准化的重要组成部分。

Chat Completions API 的一个简单示例
除此之外,OpenAI 还发布了用于编排单智能体和多智能体工作流的 Agents SDK 以及用于跟踪和检查智能体工作流程执行情况的 observability tools。
OpenAI 表示:「这些新工具简化了核心智能体逻辑、编排和交互,使开发者能够更轻松地开始构建智能体。在接下来的几周和几个月内,我们计划发布更多工具和功能,以进一步简化和加速在我们的平台上构建智能体应用的过程。」
相关文档链接如下:
- Responses API:https://platform.openai.com/docs/quickstart?api-mode=responses
- 网络搜索:https://platform.openai.com/docs/guides/tools-web-search
- 文件搜索:https://platform.openai.com/docs/guides/tools-file-search
- computer use:https://platform.openai.com/docs/guides/tools-computer-use
- Agents SDK:https://platform.openai.com/docs/guides/agents
- observability tools:https://platform.openai.com/docs/guides/agents#orchestration
另外,OpenAI 还准备了 PlayGround 供开发者尝试:https://platform.openai.com/playground/prompts?preset=ks7kayjX55ehTBR9oyUviuJe
下面来具体看看 OpenAI 今天发布的东西。
Responses API 是什么?
简单来说,Responses API 是一种 API 新原语,其作用是使用 OpenAI 内置工具来构建智能体。OpenAI 表示它将 Chat Completions 的简单性与 Assistants API 的工具使用功能结合到了一起。「随着模型功能的不断进化,我们相信 Responses API 将为开发者构建智能体应用提供更灵活的基础。只需一次 Responses API 调用,开发者就能够使用多个工具和模型轮次来解决越来越复杂的任务。」
首先,Responses API 将支持新的内置工具,如网络搜索、文件搜索和 computer use。这些工具可以协同工作,将模型连接到现实世界,从而让模型可以完成更加有用的任务。Responses API 还包含一些可用性改进,包括统一的基于事项(item)的设计、更简单的多态性、直观的流式事件和 SDK 助手(如可帮助轻松获取模型的文本输出的 response.output_text)。
对于希望轻松将 OpenAI 模型和内置工具结合到其应用中的开发者,Responses API 可提供一个统一的接口,而无需集成多个 API 或外部供应商。
该 API 还使在 OpenAI 上存储数据变得更加容易,因此开发者可以使用跟踪和评估等功能来评估智能体性能。OpenAI 还特别指出:「即使数据存储在 OpenAI 上,我们也不会默认使用业务数据来训练我们的模型。」
Responses API 即日可用,并且不会单独收费 ——token 和工具按照 OpenAI 定价页面上指定的标准费率计费。
现有的 API 呢?
Chat Completions API:OpenAI 表示,Chat Completions 仍然是他们最广泛采用的 API,他们也会让新模型和新功能支持它。无需内置工具的开发者可以放心地继续使用 Chat Completions。只要 Chat Completions 的功能不依赖于内置工具或调用多个模型,OpenAI 表示就会继续发布支持 Chat Completions 的新模型。而 Responses API 是 Chat Completions 的超集,具有同样出色的性能,因此对于新的集成,OpenAI 建议从 Responses API 开始。
Assistants API:根据开发者对 Assistants API beta 的反馈,OpenAI 在 Responses API 中加入了一些关键改进,使其更加灵活、更快、更易于使用。OpenAI 表示正在努力实现 Assistants 和 Responses API 之间的完全功能对等,包括对类似 Assistant 和类似 Thread 的对象以及代码解释器工具的支持。OpenAI 表示,完成这个过程后,就会正式宣布弃用 Assistants API,目标截止日期为 2026 年中期。弃用后,OpenAI 将提供从 Assistants API 到 Responses API 的迁移指南,使开发者能够保留所有数据并迁移其应用。而在正式宣布弃用之前,OpenAI 将继续让新模型支持 Assistants API。
OpenAI 表示:「Responses API 代表了在 OpenAI 上构建智能体的未来方向。」
Responses API 的内置工具
网络搜索
开发者现在可以从网络上获得快速、最新的答案,同时还带有清晰且相关的引文。在 Responses API 中,使用 gpt-4o 和 gpt-4o-mini 时,网络搜索可用作工具使用,并且可以与其他工具或函数调用搭配使用。

Responses API 中的网络搜索使用了 ChatGPT 搜索一样的模型。OpenAI 也发布了基准测试结果:在 SimpleQA 评估 LLM 回答简短事实问题的准确性的基准)上,GPT-4o search preview 和 GPT-4o mini search preview 分别得分 90% 和 88%。

使用该 API 中的网络搜索生成的响应会包含指向新闻文章和博客文章等来源的链接,为用户提供了一种了解更多信息的方式。
任何网站或发布者都可以选择是否在该 API 中的网络搜索中显示。
目前,网络搜索工具已在 Responses API 中以预览版形式提供给所有开发者。OpenAI 还支持开发者通过 gpt-4o-search-preview 和 gpt-4o-mini-search-preview 直接访问 Chat Completions API 中经过微调的搜索模型。GPT‑4o search 和 4o-mini search 的定价分别为每千次查询 30 美元和 25 美元。
文件搜索
开发者现在可以使用经过改进的文件搜索工具轻松地从大量文档中检索相关信息。其支持多种文件类型、查询优化、元数据过滤和自定义重新排名,并能提供快速、准确的搜索结果。同样,使用 Responses API,只需几行代码即可完成集成。

文件搜索工具可用于各种实际用例,包括使客服智能体轻松访问常见问题解答、帮助法律助理快速参考合格专业人员的过去案例以及协助编程智能体查询技术文档。
此工具在 Responses API 中可供所有开发者使用。使用价格为每千次查询 2.50 美元,文件存储价格为 0.10 美元/GB /天,首 GB 免费。
该工具也将继续在 Assistants API 中提供。最后,OpenAI 表示还向 Vector Store API 对象添加了一个新的搜索端点,开发者可直接将其用于查询自己的数据,然后用于其他应用和 API。
Computer Use
为了构建能够在计算机上完成任务的智能体,开发者现在可以使用 Responses API 中的 Computer Use 工具,该工具使用了 Computer-Using Agent(CUA)模型 —— 与 Operator 一样。
而此研究预览版(research preview)模型创下了新的 SOTA 记录:在 OSWorld 的全 Computer Use 任务上实现了 38.1% 的成功率,在 WebArena 上实现 58.1% 的成功率,在 WebVoyager 的基于 Web 的交互任务上实现 87% 的成功率。
内置的 Computer Use 工具可捕获模型生成的鼠标和键盘操作,使开发者能够通过将这些操作直接转换为其环境中的可执行命令来自动执行 Computer Use 任务。

开发者可以使用 Computer Use 工具来自动化基于浏览器的工作流程,例如在 Web 应用上执行质量验证任务或跨旧系统执行数据输入任务。
OpenAI 表示,在去年推出支持 Operator 的 CUA 之前,他们进行了广泛的安全测试和红队测试,解决了三个关键风险领域:误用、模型错误和前沿风险。
而通过 API 中的 CUA 将 Operator 的功能扩展到本地操作系统也会引入新的风险,为此 OpenAI 进行了额外的安全评估和红队测试。
OpenAI 还为开发者添加了缓解措施,包括防止提示词注入的安全检查、敏感任务的确认提示、帮助开发者隔离其环境的工具以及增强对潜在政策违规行为的检测。虽然这些缓解措施有助于降低风险,但该模型仍然容易受到无意错误的影响,尤其是在非浏览器环境中。
例如,CUA 在 OSWorld(旨在衡量 AI 智能体在实际任务中的表现的基准)上的表现目前为 38.1%,这表明该模型对于在操作系统上自动执行任务还不够可靠。在这些情况下,OpenAI 建议进行人工监督。
更多详情可访问已更新的系统卡:https://openai.com/index/operator-system-card/

从今天开始,Computer Use 工具将作为研究预览版在 Responses API 中提供给使用等级为 3-5 的选定开发者。
使用价格为 3 美元/100 万输入 token 和 12 美元/100 万输出 token。
Agents SDK
除了构建智能体的核心逻辑并让它们能够访问有用的工具之外,开发者还需要编排智能体工作流。
OpenAI 开源发布的 Agents SDK 可简化多智能体工作流的编排,并且相比于 Swarm 有了显著的改进。Swarm 是 OpenAI 去年发布的实验性 SDK 并已被开发者社区广泛采用,可参阅报道《OpenAI 今天 Open 了一下:开源多智能体框架 Swarm》。
- 智能体:易于配置的 LLM,具有清晰的说明和内置工具。
- 交接:在智能体之间智能地转移控制权。
- 护栏:可配置的安全检查,用于输入和输出验证。
- 跟踪和可观察性:可视化智能体执行跟踪以调试和优化性能。

智能体 SDK 适用于各种实际应用,包括客户支持自动化、多步骤研究、内容生成、代码审查和销售潜在客户挖掘。
Agents SDK 可与 Responses API 和 Chat Completions API 配合使用。只要其他提供商提供 Chat Completions 样式的 API 端点,该 SDK 还可以与其他提供商的模型配合使用。
开发者可以立即将其集成到他们的 Python 代码库中,Node.js 支持也即将推出。
OpenAI 还提到未来可能会开源 Agents SDK:「在设计 Agents SDK 时,我们的团队受到了社区中其他人的出色工作的启发,包括 Pydantic、Griffe 和 MkDocs。我们致力于继续将 Agents SDK 构建为开源框架,以便社区中的其他人可以扩展我们的方法。」
最后,OpenAI 称:「我们相信智能体很快就会成为劳动力不可或缺的一部分,从而显著提高各行业的生产力。随着公司越来越多地寻求利用 AI 来完成复杂的任务,我们致力于为开发者和企业提供构建模块,使他们能够有效地创建可产生实际影响的自动系统。」
Responses API 背后的故事
Responses API 背后的设计者之一、OpenAI 的 Atty Eleti 还在 𝕏 上分享了 Responses API 背后的故事。

他表示,Responses API 是他设计 OpenAI API 2 年的经验累积的成果。
两年前,他们与 GPT-3.5 Turbo 团队一起推出了 Chat Completions。而这个 API 是他与 Rachel Lim 在一个周末内完成的:周五设计,周二发布 GA。如今,Chat Completions 已成为事实上的行业标准,为数十万个应用提供支持,并被每个主要模型提供商所采用。
当年晚些时候,他们发布了 Assistants API 的 beta 版,这是构建智能体原语的初稿。其运行在后台进行,并能根据需要调用工具。
许多开发者喜欢它,因为它易于上手(只需使用 OpenAI 作为自己的数据库!)并且通过「file_search」工具内置了强大的 RAG。
但从那时起,很多事情都发生了变化:今天的模型是多模态的(文本、图像、音频)、智能体形式的(调用一个或多个工具),并且在说话前会思考。
Chat Completions 不是为此设计的;它是无状态的(会迫使你传回大量图像和音频),不支持工具,并且存在许多可用性问题(特别是,流式传输很难正确实现。)
Assistants 支持工具,但它太抽象了。你需要了解六个概念才能开始使用,而且后台处理意味着它默认很慢。
这些 API 的形式成为了开发者调用底层功能的障碍。
Responses API 则将上述两种 API 的优势整合到了一起。
只需 4 行代码即可开始使用,只需一个参数即可包含文件搜索、网络搜索、函数调用和结构化输出等功能。

Responses 具有多种状态。
默认情况下,所有 Responses 都会被存储,用户可以在仪表板中查看它们,以便以后进行调试。你可以使用「previous_response_id」继续对话 —— 无需一次又一次地发送大载荷。
Responses 也是状态机(state-machines),可以更好地模拟不完整、中断和失败的模型输出。

Responses 的核心概念是事项(item):表示用户输入或模型输出的多态对象。事项可以表示消息、推理、函数调用、Web 搜索调用等。
Chat Completions 是消息来来回回的列表,而 Responses 则是事项来来回回的列表。

托管工具(Hosted tools)是 Responses 的杀手级功能。
只需一行代码,你就可以在应用中获得一流的网页搜索、文件搜索以及即将推出的代码解释器。
至于 Responses 这个起名。Atty Eleti 指出「Responses 显然与 HTTP Responses 冲突。」
「但我们坚信这个名字完美地平衡了优雅和描述性。我们在日常使用中都会问『模特的 Responses 是什么?』」
Eleti 表示他们还考虑过 Tasks、Generations、Messages、Interactions、Conversations 等名称。
他也总结了 OpenAI 的 API 设计哲学:交付能力,而非抽象。(Ship capabilities, not abstractions.)
最后,顺带一提,OpenAI CEO Sam Altman 在 𝕏 表示他们已经训练出了一个擅长创意写作的模型,不过发布时间待定。他说:「这是我第一次真正被 AI 写的东西所震撼;它恰到好处地传达了元小说的氛围。」
下面是他分享的提示词和小说,感兴趣的读者可访问这里自行评鉴:https://x.com/sama/status/1899535387435086115

你对 OpenAI 今天的发布怎么看?
参考链接
https://openai.com/index/new-tools-for-building-agents/
https://x.com/btibor91/status/1899559543933452324
https://x.com/athyuttamre/status/1899541499261616339
#Señorita-2M
18项任务200万视频编辑对,云天励飞联合多高校打造出大规模编辑数据集
目前的视频编辑算法主要分为两种:一种是利用 DDIM-Inversion 完成视频编辑,另一种是利用训练好的编辑模型。然而,前者在视频的一致性和文本对齐方面存在较大缺陷;后者由于缺乏高质量的视频编辑对,难以获得理想的编辑模型。
为了解决视频编辑模型缺乏训练数据的问题,本文作者(来自香港中文大学、香港理工大学、清华大学等高校和云天励飞)提出了一个名为 Señorita-2M 的数据集。该数据集包含 200 万高质量的视频编辑对,囊括了 18 种视频编辑任务。
数据集中所有编辑视频都是由经过训练的专家模型生成,其中最关键的部分由作者提出的视频编辑专家模型完成,其余部分则由一些计算机视觉模型标注,例如 Grounded-SAM2 和深度图检测模型等。
- 论文标题:Señorita-2M: A High-Quality Instruction-based Dataset for General Video Editing by Video Specialists
- 论文地址: https://arxiv.org/abs/2502.06734
- 项目地址: https://senorita-2m-dataset.github.io
数据分布见下图。

,时长01:10
专家模型的开发和数据集的构造
除了常见的计算机视觉模型,作者提出的视频编辑专家模型一共有 4 个,负责五种编辑任务。
第一个编辑专家模型称为 Global Stylizer,负责对输入视频进行风格转换,它基于现有的视频生成基模型开发。
然而,作者发现视频生成基模型在接受风格信息方面存在不足,因此无法利用 ControlNet 的思想进行风格转换。
为了解决这一问题,作者首先利用图像 ControlNet 对首帧进行处理,然后使用视频 ControlNet 对剩余的帧进行处理,将首帧的风格信息推广到剩余的视频帧中。在训练过程中,采用了两阶段策略,并通过冻结部分层以降低成本。在第一阶段,模型在低分辨率视频上训练;在第二阶段,微调模型以提高分辨率。
在生成数据阶段,作者采用 Midjourney 和 Stable Diffusion 常用的 290 种风格 prompt,对视频进行风格转换,并使用 LLM 对风格 prompt 转换成指令。
第二个编辑专家模型称为 Local Stylizer,与 Global Stylizer 不同的是,它负责对某些物体进行风格方面的编辑。
由于对物体进行风格编辑,不需要接受复杂的风格指令,因此这个模型不使用首帧引导。除此之外,作者使用与 Global Stylizer 相同的 ControlNet 架构,并引入了 inpainting 的思想,保证只有物体本身被修改。
在生成数据阶段,作者采用 LLM 对物体进行改写并产生指令。在获取新的信息后,使用作者的模型对物体进行重绘。
第三个专家模型是 Text-guided Video Inpainter,用来完成物体的替换。
在实践中,作者发现直接开发一个视频 inpainter 的效果会远远弱于基于首帧引导的视频 inpainter。因此,作者使用 Flux-Fill 这一高效的图像 inpainter 对首帧进行处理,并使用作者的 inpainter 对剩下的视频进行补全。这样做的好处是将作者的视频 inpainter 只负责将首帧的视频补全内容推广到剩余的视频帧,减少了编辑的难度。
为了进一步减小视频标注过程中引入的数据噪声,作者将编辑的视频作为源视频,将原始视频作为目标视频。这样做的好处是避免基于数据集训练的视频编辑模型学到扭曲和抖动。作者利用 LLM 对源物体和目标物体进行组合并产生用于编辑的指令。
第四个专家模型是 Object Remover。作者用这个专家模型来完成物体去除和物体添加两部分的数据构造。物体添加任务为物体去除任务的逆任务,只需要将标注视频当作源视频,原始视频当作目标视频即可完成数据对的构造。
对于这个专家模型的构造,作者提出了一种反转训练的策略,将训练的 90% 数据的 mask 替换为与视频内容无关的 mask,训练视频恢复的背景和 mask 形状无关。这样可以有效避免视频 remover 根据 mask 形状再次生成物体。
作者还将 10% 的数据设置为和视频物体严格一致的 mask,这样可以训练 remover 产生物体,在推理时将这一条件设置为负 prompt 来避免去除区域内的物体的产生。作者使用 LLM 对使用的 prompt 转换成用于物体去除和物体添加的指令。
除此之外,作者还使用了多种计算机视觉模型对视频进行标注。例如,使用了 Grounded-SAM2 来标注经过 Grounding 的视频,目的是用来训练模型对物体的感知能力,帮助编辑模型对区域的编辑。作者还使用了其他多种专家模型,这些模型一共标注了 13 种视频编辑任务。相似的,这些数据对应的指令也使用 LLM 进行增强。

数据集的清洗
为了保证视频对的可靠性,作者使用多种过滤算法对生成的视频进行清洗。
具体来讲,首先训练了一个检测器用来检测编辑失败的数据,去除那些有害的视频。其次,使用 CLIP 对文本和视频的匹配度进行检测,丢弃匹配度过小的数据。最后,比对了原始视频和编辑视频的相似度,丢弃掉没有明显编辑变化的视频。
基于 Señorita-2M 数据集的编辑模型训练
作者使用 CogVideoX-5B-I2V 作为基模型,利用首帧引导的方式,使用 Señorita-2M 训练了一个编辑模型。这个模型和之前方法的实验比较结果表明,基于该数据集训练的模型具有更强的一致性、文本视频对齐,以及更好的用户偏好度。
为了进一步证明数据的有效性,作者做了消融实验,使用了相同数据量的 InsV2V 和 Señorita-2M 视频对 CogVideoX-5B-T2V 进行微调。结果发现,使用了 Señorita-2M 的数据,可以大大增强文本匹配度。
另外,增加了训练数据的数量后,这些指标会有明显的改善。这些实验证明了该数据集可以有效地训练出高质量的视频编辑器。更多实验数据详见表 1。

表 1. 基于 Señorita-2M 训练的模型和其他编辑方法的对比
另外,作者还探索了目前的一些编辑架构,采用和 instruct-pix2pix 以及 controlnet 相同的架构,并基于 CogVideoX-5B 来构建视频编辑模型。另外,作者还采用 omni-edit 图像编辑对这基于两个架构的视频编辑模型进行增强。结果发现,使用图像数据增强的模型会有更好的文本匹配度以及用户偏好度。
除此之外,作者还采用了首帧引导的方式进行编辑模型。实验结果证明,在视频编辑中,使用 ControlNet 相比于 Instruct-pix2pix 会有更好的编辑效果,基于首帧引导的编辑模型可以比非首帧引导的模型获得更好的编辑效果。具体实验结果详见表 2。

表 2. 不同编辑架构之间的对比
总结
作者训练了一系列视频编辑专家模型,用它们和其他计算机视觉模型创建了一个高质量的、基于指令的视频编辑数据集。这个数据集中包含了 18 种不同的视频编辑任务,拥有 200 万的视频编辑对。作者使用了一系列的过滤算法对产生的数据进行筛选,并使用 LLM 对指令进行生成和增强。
实验证明,该数据集可以有效地训练出高质量的视频编辑模型,在视觉效果帧间一致性和文本对齐度等指标上有着较大的提升。除此之外,作者采用了不同的编辑架构对视频编辑进行探索,并得出了一系列结论。作者还设计了消融实验,证明使用相同基础模型的情况下,使用该数据集的数据会大大提升编辑模型的编辑能力。
#APB
在长文本上比Flash Attention快10倍!清华等提出APB序列并行推理框架
在 ChatGPT 爆火两年多的时间里,大语言模型的上下文窗口长度基准线被拉升,以此为基础所构建的长 CoT 推理、多 Agent 协作等类型的高级应用也逐渐增多。
随之而来的是,长文本推理速度被提出更高要求,而基于现有 Transformer 架构的模型受限于注意力机制的二次方复杂度,难以在较短时延内处理超长文本请求。
针对这一痛点,清华大学 NLP 实验室联手中南大学、北京邮电大学以及腾讯微信 AI 实验室取得了突破,共同提出了 APB 框架 —— 其核心是一个整合了稀疏注意力机制的序列并行推理框架,通过整合局部 KV 缓存压缩方式以及精简的跨 GPU 通信机制,解决了长上下文远距离语义依赖问题,在无性能损失的前提下大幅度提升超长文本预填充的效率。
在 128K 文本上,APB 能够出色地平衡性能与速度,达到相较于传统 Flash Attention 约 10 倍的加速比,在多种任务上甚至具有超越完整 Attention 计算的性能;与英伟达提出的同为分布式设定下的 Star Attention 相比,APB 也能达到 1.6 倍加速比,在性能、速度以及整体计算量上均优于 Star Attention。
- 论文链接:https://arxiv.org/pdf/2502.12085
- GitHub 链接:https://github.com/thunlp/APB
这一方法主要用于降低处理长文本请求的首 token 响应时间。未来,APB 有潜力运用在具有低首 token 响应时间要求的模型服务上,实现大模型服务层对长文本请求的高效处理。
瓶颈:加速长文本预填充效率
长文本预填充的效率受到计算的制约。由于注意力机制的计算量与序列长度呈二次方关系,长文本的计算通常是计算瓶颈的。主流加速长文本预填充的路线有两种,提升并行度和减少计算:
- 提升并行度:我们可以将注意力机制的计算分布在不同设备上来提升并行度。当一个 GPU 的算力被充分的利用时,简单的增加 GPU 的数量就可以增加有效算力。现存研究中有各种各样的并行策略,包括张量并行、模型并行、序列并行等。对于长文本推理优化,序列并行有很大的优化潜力,因为它不受模型架构的制约,具有很好的可扩展性。
- 减少计算:另一个加速长文本预填充的方式是减少计算,即使用稀疏注意力。我们可以选择注意力矩阵中计算的位置,并不计算其他位置来减少整体的计算量。此类方法通常会带来一定的性能损失。计算时忽略重要的上下文会导致无法处理某些任务。
然而,简单地提升并行度和减少计算并不能在加速长文本预填充上取得足够的效果。若要将二者结合又具有极大挑战,这是因为稀疏注意力机制中,决定计算何处注意力通常需要完整输入序列的信息。在序列并行框架中,每个 GPU 仅持有部分 KV 缓存,无法在不通过大规模通信的前提下获得足够的全局信息来压缩注意力的计算。
针对这一问题,有两个先驱方法:一是英伟达提出的 Star Attention ,直接去除了序列并行中的所有通信,并只计算每个 GPU 上局部上下文的注意力,但这样计算也导致了很大程度的性能损失;二是卡内基梅隆大学提出的 APE,关注 RAG 场景下长文本预填充加速,通过将上下文均匀分割、对注意力进行放缩和调整 softmax 温度,实现并行编码,同样在需要远距离依赖的场景上有一定的性能损失。
区别于上述方法,APB 通过设计面向序列并行场景的低通信稀疏注意力机制,构建了一个更快、性能更好,且适配通用长文本任务的长文本加速方法。
APB:面相序列并行框架的稀疏注意力机制
相较于之前的研究,APB 通过如下方法提出了一种面相序列并行框架的稀疏注意力机制:

- 增加较小的 Anchor block:Star Attention 中引入的 Anchor block(输入序列开始的若干 token)能够极大恢复性能,然而其尺寸需要和局部上下文块一样大。过大的 anchor block 会在 FFN 中引入过多的额外开销。APB 通过减少 anchor block 的大小,使其和上下文块的 1/4 或 1/8 一样大。
- 解决长距离语义依赖问题:先前研究某些任务上性能下降的原因是它们无法处理长距离语义依赖,后序 GPU 分块无法看到前序上下文块中的信息,导致无法处理特定任务。APB 通过构建 passing block 的方式来解决这一问题。Passing block 由前面设备上的重要 KV 对组成。每个上下文块先被压缩,然后将被压缩的上下文块通信到后续 GPU 上来构建 passing block。
- 压缩上下文块:在不进行大规模通信的前提下,每个设备只对自己持有的上下文有访问权限。因此,现存的 KV Cache 压缩算法(例如 H2O 和 SnapKV)不适用于这一场景,因为它们依赖全序列的信息。然而,该特点与 Locret 一致,KV Cache 重要性分数仅仅与对应 KV 对的 Q, K, V 相关。APB 使用 Locret 中引入的 retaining heads 作为上下文压缩器。
- 查询感知的上下文压缩:APB 在 anchor block 的开头嵌入查询。当预填充结束时,这些查询可以随着 anchor block 一同被丢弃,不会影响整体计算的同时还能让上下文压缩器看到查询的内容。通过这种方式,保留头能够更精准地识别出查询相关的 KV 对,并通过通信机制传给后续设备。
以此机制为基础,APB 的推理过程如下:
- 上下文分割:长文本被均匀的分到每个设备上,开头拼接一个 anchor block,其中包含了查询问题。
- 上下文压缩:我们用 Locret 引入的保留头来压缩 KV Cache。
- 通信:我们对压缩过的 KV Cache 施加一个 AllGather 算子。每个设备会拿到前序设备传来的压缩缓存,并构建 passing block。
- 计算:我们使用一个特殊的 Flash Attention Kernel 来实现这个特殊的注意力机制。我们更改了注意力掩码的形状。Passing block 在注意力计算结束后就被删除,不参与后续计算。
APB 实现更快、性能更好的长文本推理
团队使用 Llama-3.1-8B-instruct, Qwen-2.5-14B-instruct 以及 Yi-34B-200K 模型在 InfiniteBench 和 RULER 上进行了测试,测量任务性能(%)以及处理完整长文本请求的推理速度(tok /s)。研究人员选择 Flash Attention, Ulysses, Ring Attention, MInference 以及 Star Attention 作为基线算法,实验结果如下:

从上图可见,Flash Attention 作为无序列并行的精准注意力算法,具有较好的任务性能,但推理速度最慢;Ring Attention 和 Ulysses 作为序列并行的精准注意力算法,通过增加并行度的方式提升了推理速度;MInference 是一种无序列并行的稀疏注意力机制,表现出了一定的性能损失;Star Attention 作为序列并行与稀疏注意力结合的最初尝试,具有较好的推理速度,然而表现出了显著的性能下降。
相较于基线算法,APB 在多种模型和任务上表现出更优的性能和更快的推理速度。这意味着,APB 方法能够实现最好的任务性能与推理速度的均衡。
除此之外,研究人员在不同长度的数据上测量了 APB 与基线算法的性能、速度,并给出了整体计算量,结果如下:

可以从上图中看到,APB 在各种输入长度下均表现出更优的任务性能与推理速度。速度优势随着输入序列变长而变得更加明显。APB 相较于其他方法更快的原因是它需要更少的计算,且计算量差异随着序列变长而加大。
并且,研究人员还对 APB 及基线算法进行了预填充时间拆解分析,发现序列并行可以大幅度缩减注意力和 FFN 时间。

通过稀疏注意力机制,APB 能进一步缩减注意力时间。Star Attention 由于使用了过大的 anchor block,其 FFN 的额外开销十分明显,而 APB 由于使用了 passing block 来传递远距离语义依赖,能够大幅度缩小 anchor block 大小,从而降低 FFN 处的额外开销。
APB 支持具有卓越的兼容性,能适应不同分布式设定(显卡数目)以及不同模型大小,在多种模型和分布式设定下均在性能与推理速度上取得了优异的效果。
核心作者简介
黄宇翔,清华大学四年级本科生,THUNLP 实验室 2025 年准入学博士生,导师为刘知远副教授。曾参与过 MiniCPM、模型高效微调、以及投机采样研究项目。主要研究兴趣集中在构建高效的大模型推理系统,关注模型压缩、投机采样、长文本稀疏等推理加速技术。
李明业,中南大学三年级本科生,2024 年 6 月份加入 THUNLP 实验室实习,参与过投机采样研究项目。主要研究兴趣集中在大模型的推理加速,例如投机采样以及长文本推理加速等。
#欧莱雅美妆科技黑客松2025重磅来袭
DeepSeek 的风甚至吹到了美妆区。近日,一小红书博主跟足 DeepSeek 指示上妆,意外打造出「石矶娘娘」妆效,引发全网围观。一场看似无厘头的跨界实验,实则揭示了美妆与科技源远流长的共生关系:经济史上的「口红效应」本质就是技术迭代与消费心理的精准契合,而今 AI 又在重构美妆逻辑。
在美妆科技的赛道上,全球第一大美妆集团——欧莱雅正在加速引领「美妆科技」,致力于创造未来之美。作为 CES 消费电子展的常驻先锋,其亮出的黑科技让人目不暇接:仅需五分钟,AI 皮肤分析仪就能测出肌肤年龄,提供护肤建议、生成式 AI 顾问为你量身定制美妆建议、上妆辅助器可以协助手臂活动能力受限人士顺利上妆。在研发领域,生成式 AI 正协助欧莱雅更快找到下一个玻色因。基于生成式 AI 的品牌定制模型能够识别集团多个品牌独特的视觉元素,赋能营销创意。
当 AI 与美妆融合,欧莱雅深知其中还蕴含诸多挑战和机遇。非技术人员如何被海量业务数据轻松赋能?大模型的「幻觉输出」与内容合规风险亟待解决。而在创新前沿,未被开垦的 AI 应用场景仍如星海般璀璨。
在此背景下,由全球第一大美妆集团——欧莱雅发起,中国青少年发展基金会、阿里云、xxx、魔搭社区等顶尖机构和企业支持的欧莱雅集团首届美妆科技黑客松大赛【科技大 FUN 颂】正式启动,诚邀全国开发者通过智能体技术创新,共同探索美妆行业的数字化未来。
#Denoising Hamiltonian Network,DHN
将哈密顿力学泛化到神经算子,何恺明团队又发新作,实现更高级物理推理
继上月末连发两篇论文(扩散模型不一定需要噪声条件和分形生成模型)之后,大神何恺明又出新作了!这次的主题是「用于物理推理的去噪哈密顿网络」。
物理推理包含推断、预测和解释动态系统行为的能力,这些是科学研究的基础。应对此类挑战的机器学习框架通常被期望超越仅仅记忆数据分布的做法,从而维护物理定律,解释能量和力的关系,并纳入超越纯数据驱动模型的结构化归纳偏差。科学的机器学习通过将物理约束直接嵌入神经网络架构(通常通过显式构建物理算子)来解决这一挑战。
不过,这些方法面临两个关键限制。其一,这些方法主要学习局部时序更新(预测从一个时间步骤到下一个时间步骤的状态转换),而不捕获远程依赖或抽象的系统级交互。其二,这些方法主要关注前向模拟,从初始条件预测系统的演变,而在很大程度上忽略了超分辨率、轨迹修复或从稀疏观测中进行参数估计等互补任务。
为了解决这些限制,何恺明等来自 MIT、斯坦福大学等机构的研究者提出了去噪哈密顿网络(Denoising Hamiltonian Network,DHN),这是一个将哈密顿力学泛化到神经算子的框架。
- 论文标题:Denoising Hamiltonian Network for Physical Reasoning
- 论文地址:https://arxiv.org/pdf/2503.07596
下图 1 为去噪哈密顿网络(DHN)概览。

研究者表示,DHN 在利用神经网络灵活性的同时实施物理约束,带来以下三项关键创新。
首先,DHN 通过将系统状态组合视为 token 来扩展哈密顿神经算子以捕获非局部时间关系,从而能够从整体上对系统动态进行推理,而不是分步推理。
其次,DHN 集成了一个去噪目标,其灵感来自去噪扩散模型,用于减轻数值积分误差。通过迭代地将其预测细化为物理上有效的轨迹,DHN 提高了长期预测的稳定性,同时保持了在不同噪声条件下的适应性。此外,通过利用不同的噪声模式,DHN 支持在各种任务场景中进行灵活的训练和推理。
最后,研究者引入了全局条件以促进多系统建模。一个共享的全局潜在代码被用来对系统特定属性(例如质量、摆长)进行编码,使 DHN 能够在统一框架下对异构物理系统进行建模,同时保持底层动态的解耦表示。
在实验部分,为了评估 DHN 的通用性,研究者通过三个不同的推理任务对其进行了测试,包括轨迹预测和完成、从部分观察中推断物理参数,以及通过渐进式超分辨率插入稀疏轨迹。
总之,这项工作推动了在局部时序关系之外嵌入物理约束的更通用架构的发展,为更广泛的物理推理应用开辟了道路,超越了传统的前向模拟和下一状态预测。
论文一作 Congyue Deng 发推表示,过去通过扩展卷积算子使其从低级图像处理上升到高级视觉推理,如今 DHN 可以通过扩展物理算子来实现更高级的物理推理。

同时,她也提出了三个开放性问题,包括「如何定义深度学习中的物理推理」、「什么是物理模拟」、「神经网络应该具备哪些物理属性」。她说到,DHN 不是最终的解决方案,只是一个开始。

方法概览
本文的目标是设计更通用的神经算子,既遵循物理约束,又释放神经网络作为可优化黑盒函数的灵活性和表现力。研究者首先问了一个问题:除了下一状态预测之外,我们还能建模哪些「物理关系」?
下图 2 比较了三种不使用机器学习来建模物理系统的经典方法,包括如下:
- 全局解析解决方案。对于具有规则结构的简单系统,人们通常直接得出闭式解。
- PDE + 数值积分,在更复杂的环境中,如果没有闭式解,标准做法是将系统的动态过程表示为 PDE,然后通过数值方法逐步求解。
- 直接全局关系。在某些复杂系统中(例如没有耗散力的纯保守系统),时间上相距较远的状态可以直接使用全局守恒定律(例如能量守恒定律)来关联。

图 3 展示了一个离散的哈密顿网络(右),用于计算时间步长 t_0 和 t_1 之间的状态关系。研究者主要使用哈密顿 H^+(右)来描述他们的网络设计。

去噪哈密顿网络
掩码建模和去噪。研究者希望哈密顿块不仅能对跨时间步的状态关系进行建模,还能学习每个时间步的状态优化,以便进行推理。为此,他们采用了掩码建模策略,在训练网络时屏蔽掉部分输入状态(图 5)。

这里不是简单地屏蔽输入状态,而是用不同幅度的噪声采样对输入状态进行扰动(图 5)。这种策略可确保模型学会迭代改进预测,使其能够从损坏或不完整的观测结果中恢复有物理意义的状态。
具体来说,研究者定义了一个噪声水平递增的序列

以阻塞输入状态

为例,研究者随机采样高斯噪声

和每个状态的噪声规模

。
在实验中,去噪步数设置为 10。在推理时,研究者用一连串同步于所有未知状态的递减噪声尺度对未知状态进行逐步去噪。他们同时应用

和

来迭代更新

和

。
不同的掩码模式通过在训练过程中设计不同的掩码模式,可以根据不同的任务制定灵活的推理策略。图 6 展示了三种不同的掩码模式:通过屏蔽一个数据块的最后几个状态来实现自回归,这类似于利用前向建模进行下一状态预测的物理模拟;通过掩码一个数据块中间的状态来实现超分辨率,这可应用于数据插值;更广泛地说,包括随机掩码在内的任意顺序掩码,掩码模式根据任务要求进行自适应设计。

网络架构
纯解码器 Transformer。对于每个哈密顿块,网络输入是不同时间步的

栈、

栈,研究者还引入了整个轨迹的全局潜码 z 作为条件。如图 7 所示,研究者采用了一种纯解码器 Transformer,它类似于类似于 GPT 的纯解码器架构,但没有因果注意力掩码。

研究者将所有输入 token

作为长度为 2b + 1 的序列应用了自注意力。全局潜码 z 作为查询 token,用于输出哈密顿值 H。还通过在位置嵌入中添加每个状态的噪声标度,将其编码到网络中。在实验中,研究者实现了一个适合单 GPU 的简单双层 Transformer。
自解码。研究者没有依赖编码器网络从轨迹数据中推断全局潜码,而是采用了自解码器框架,为每条轨迹维护一个可学习的潜码 z(图 8)。这种方法允许模型高效地存储和完善特定系统的嵌入,而不需要单独的编码过程。在训练过程中,研究者会联合优化网络权重和代码库。训练结束后,给定一个新轨迹,冻结网络权重,只优化新轨迹的潜码。

实验
研究者用两种设置来评估模型:单摆和双摆。两种设置都包含一个模拟轨迹数据集。单摆是一个周期性系统,每个状态下的总能量都可以通过(q, p)直接计算出来,因此此处用它来评估模型的能量守恒能力。双摆是一个混沌系统,微小的扰动会导致未来状态的偏离。
他们用与图 6 中三种不同掩码模式相对应的三种不同任务来测试模型。它们分别是:(i) 用于前向模拟的下一状态预测(自回归);(ii) 用于物理参数推断的随机掩蔽表示学习;以及 (iii) 用于轨迹插值的渐进式超分辨率。这些任务突出了 DHN 对各种物理推理挑战的适应性,测试了它在不同观测限制条件下生成、推断和插值系统动态的能力。
前向模拟
- 拟合已知轨迹
图 9 显示了采用不同块大小的模型与采用不同数值积分器的 HNN 的比较结果。左图和右图分别是单摆和双摆系统在每个时间步的 q 预测值的均方误差(MSE)。中间的图显示了一个示例轨迹上的平均总能量误差和总能量的演变。对于 DHN,每个时间步的状态优化由去噪机制建模,无需变分积分器。当块大小为 2 时,本文的模型可以稳定地保存总能量。增加块大小会在较长的时间范围内引起能量波动,但这种波动并没有表现出明显的能量漂移倾向。

- 以新颖的轨迹完成
图 10 显示了与 HNN(上行)和各种无物理约束基线模型(下行)的比较结果。本文的 DHN 采用较小的块大小,状态预测更准确,节能效果更好。

表征学习
图 11 展示了与 HNN 和常规网络相比,DHN 在不同块大小(s = b/2)下的线性探测结果。与基线网络相比,本文的模型实现了更低的 MSE。如图 4 所示,HNN 可以看作是哈密顿块的特例,其核大小和步长均为 1,具有最强的局部性。研究者引入的块大小和跨度允许模型在不同尺度上观察系统。在这个双摆系统中,块大小为 4 是推断其参数的最佳时间尺度。

图 12 展示了不同块大小和步长的 DHN 结果。如图 12b 所示,哈密顿块的输入和输出状态有一个 b-s 时间步长的重叠区域。哈密顿块的广义能量守恒依赖于重叠区域具有相同的输入和输出。在训练过程中,这一约束作为状态预测损失的一部分强加给网络。较大的重叠会对网络施加更强的正则化,但会鼓励网络执行更多的自一致性约束,而不是更多的状态间关系。相反,减少重叠度的同时增加跨度,可以鼓励模型吸收更多时间上较远的状态信息,但代价是削弱自洽性约束,从而影响稳定性。在重叠等于块大小 b 且跨度为零的极端情况下,DHN 块的输入和输出完全相同,训练损失退化为自相干约束。HNN 是另一种重叠为零的特殊情况(因为块大小为 1,重叠只能为零)。如 12b 所示,对于简单双层 transformer,最佳的块大小和跨度约为 s≈ b/2,重叠量适中。

轨迹插值
研究者通过重复应用 2 倍超分辨率来实现 4 倍超分辨率。如图 13 左所示,为每个阶段构建一个 b = 2、s = 1 的 DHN 块。不同稀疏度的轨迹块如图 13 右所示。掩码应用于中间状态,边上的两个状态是已知的。

在所有三个超分辨率阶段中,每个轨迹都与共享的全局潜码相关联,从而为训练集形成一个结构化代码集。在训练过程中,网络权重和这些潜码会在逐步细化阶段(0、1、2)中共同优化。在推理时,给定一个仅在最稀疏水平(第 0 阶段)已知状态的新轨迹,研究者冻结了 DHN 块中的所有网络权重,并优化第 0 阶段的全局潜码。
最后,研究者将本文模型与用于超分辨率的 CNN 进行了比较,结果如图 14 所示。对于与训练数据具有相同初始状态的轨迹,两个模型都显示出较好的插值结果,MSE 也较低。基线 CNN 的结果稍好,因为它本身没有正则化,很容易过拟合训练轨迹。对于具有未知初始状态的测试轨迹,CNN 难以实现泛化,因为其插值在很大程度上依赖于训练分布。相比之下,DHN 具有很强的泛化能力,因为其物理约束表征使其即使在分布变化的情况下也能推断出可信的中间状态。

更多研究细节,可参考原论文。
#Seedream 2.0
字节首次公开图像生成基模技术细节!数据处理到RLHF全流程披露
就在今天,字节豆包大模型团队在 arxiv 上发布了一篇技术报告,完整公开了文生图模型技术细节,涵盖数据处理、预训练、RLHF 在内的后训练等全流程模型构建方法,也详细披露了此前大火的文字精准渲染能力如何炼成。
报告将豆包文生图模型称为 Seedream 2.0,并明确提到,该模型于去年 12 月初上线到豆包 APP 和即梦平台。从模型能力看,Seedream 2.0 是原生的中英双语图像生成基础模型,拥有很强的美感和文本渲染效果,与目前即梦上的文生图主力模型特性匹配。
换而言之,字节此次披露的,就是线上直接服务于数亿用户的核心模型。
至于技术报告中有哪些主要看点,本文进行了总结。
- 论文标题:Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
- 论文地址:https://arxiv.org/pdf/2503.07703
- 技术展示页:https://team.doubao.com/tech/seedream
面向文生图老大难问题构建综合实力更强的模型
众所周知,基于 DiT 架构下图像生成的质量、细节丰富度、美感、结构性等问题仍是技术从业者面临的老大难问题,阻碍技术更大规模落地,服务大众。
各家厂商也纷纷在从细节处入手,优化文生图效果。字节走在国内大厂前列,旗下即梦平台颇受 AIGC 爱好者欢迎,主要因其 AI 生图兼顾真实度与美感,尤其在国风内容生成上独具特色。
海辛、归藏、AJ 等 AIGC 领域 KOL 也对即梦上模型文字生成与渲染、指令遵循、风格把控等方面表达过认可。

近期,即梦上还有不少「哪吒 2」主题的相关内容,所生成的图片既贴合人物特征,又有创意发挥之处。

根据豆包大模型团队提供的评测结果可以看到,服务即梦的 Seedream2.0 模型,在面向英文提示词上,生成内容的结构合理性、文本理解准确性对比 Ideogram 2.0 、Midjourney V6.1 、Flux 1.1 Pro 等模型展现出优势,且各类关键维度无明显短板。

注:面向英文提示词,Seedream 2.0 在不同维度上的表现。本图各维度数据以最佳指标为参照系,已进行归一化调整。
Seedream 2.0 中文综合能力同样突出,尤其在中文文字渲染和国风美感方面。面向中文提示词,其 78% 的生成与渲染文字可用率和 63% 的提示词完美响应率,高于业界目前其他模型。
面向中文提示词,其生成与渲染文字可用率达 78% ,完美响应率为 63% ,高于业界目前其他模型。

注:面向中文提示词,Seedream 2.0 在不同维度上的表现。本图各维度数据以最佳指标为参照系,已进行归一化调整。
上述能力并非来自于单点技术突破,而是源自 Seedream 2.0 团队针对数据处理、预训练、后训练阶段融入了一系列优化方法和技术。
数据处理:构建深度融合知识的预处理框架
面对百亿量级的中英多模态数据,Seedream 2.0 团队构建了以 “知识融合” 为核心的预处理框架,从以下三个方面实现技术突破。
- 四维数据架构,实现质量与知识的动态平衡
大规模数据构建,往往伴随质量下滑,进而影响模型表现。为此,团队创新设计了四维拓扑网络,突破单一模态限制。该架构包含四个数据层:
- 优质数据层:精选高分辨率、知识密度强的数据(如科学图解、艺术创作),奠定质量基础;
- 分布维持层:采用双层级降采样策略,从数据源维度对头部平台等比降维,从语义维度通过 10 万级细粒度聚类维持多样性;
- 知识注入层:构建 3 万 + 名词和 2000 + 动词分类体系,结合百亿级跨模态检索,为数据注入文化特征;
- 定向增强层:建立 “缺陷发现 - 数据补充 - 效果验证” 闭环,优化动作序列、反现实生成等场景。
这一架构有效平衡了数据质量与知识多样性,为模型训练提供坚实的数据支撑。

- 智能标注引擎:三级认知进化
传统标注的 Caption 系统受单模态理解局限,对图像内容描述不够全面精准。团队在其基础上,实现了智能标注引擎的三级认知进化。
首先,构建分层描述体系,通过短、长和特殊场景 Caption 结合,让模型既能捕捉图像核心内容,又能提供丰富细节与艺术解释。
其次,建立文化专有名词映射库,实现跨语言对齐,将中英文生成质量差异压缩至 2% 以内,提升模型在多语言环境下表现。
最后,引入动态质检机制,利用 LLM 预筛选,通过 Badcase 驱动 prompt 模板迭代,优化描述质量。
- 工程化重构:百亿数据的流水线革命
工程化方面,传统 ETL 流程存在算力错配与迭代迟滞痛点。
这不仅导致非核心任务占用大量高算力资源,挤占核心任务资源,也造成数据处理流程难以适应业务与数据变化,限制整体效能。
团队从两方面重构工程系统。
一方面通过异构调度,释放高算力资源用于关键任务。另一方面,采用 “分片 - 校验 - 装载” 三级流水线并行处理方法,打包速度提升 8 倍。
这些改进大幅提高数据处理效率与质量,为大规模数据管理利用奠定基础。
预训练阶段:聚焦双语理解与文字渲染
在预训练阶段,团队基于大量用户调研与技术预判认为,多语言语义理解、双语文字渲染和多分辨率场景适配等模块的突破,对于图像生成技术发展极为关键,可大幅提升模型适用性与用户体验,满足不同语言文化背景的用户需求,并拓展应用场景。
因此,Seedream 2.0 采用了全新的预训练架构设计,其整体框图如下。

具体来看,Seedream 2.0 从三个方面实现了关键技术升级。
- 原生双语对齐方案,打破语言视觉次元壁
面向双语文生图场景,团队提出基于 LLM 的双语对齐方案。
具体来说,先通过大规模文本 - 图像对微调 Decoder-Only 架构的 LLM,使文本 Embedding 与视觉特征形成空间映射对齐。
同时,针对中文书法、方言俚语、专业术语等场景构建专用数据集,加强模型对文化符号的深度理解与感知。
这种 “预训练对齐 + 领域增强” 的双轨策略,使模型能够直接从大量中英文数据中习得 “地道” 的本土知识,进而,准确生成具有文化细微差别的中文或英文美学表达图像,打破不同语言与视觉的次元壁。
- 让模型既看懂文本,又关注字体字形
在过去,图像生成模型的文本渲染常面临两难困境:依赖 ByT5 等字形模型易导致长文本布局混乱,而引入 OCR 图像特征又需额外布局规划模块。
为此,团队构建了双模态编码融合系统 ——LLM 负责解析 “文本要表达什么”,ByT5 专注刻画 “文字应该长什么样”。
此种方法下,字体、颜色、大小、位置等渲染属性不再依赖预设模板,而是通过 LLM 直接描述文本特征,进行端到端训练。
如此一来,模型既能从训练数据中学习文本渲染特征,也可以基于编码后的渲染特征,高效学习渲染文本的字形特征。
- 三重升级 DiT 架构,让图像生成缩放自如
多分辨率生成是图像生成场景的常用需求,团队在 SD3 的 MMDiT 架构基础上,进行了两重升级:
其一,在训练稳定性方面。团队引入 QK-Norm 抑制注意力矩阵的数值波动,结合全分片数据并行(FSDP)策略,使模型的训练收敛速度提升 300%。
其二,团队设计了 Scaling ROPE 技术方案。传统二维旋转位置编码(RoPE)在分辨率变化时,可能会导致位置标识错位。Seedream 2.0 通过动态缩放因子调整编码,使图像中心区域在不同宽高比下,保持空间一致性。这使得模型在推理过程中,能够生成从未训练过的图像尺寸和各种分辨率。
后训练 RLHF 突破能力瓶颈
Seedream 2.0 的后训练过程包含四个阶段:Continue Training (CT) 、 Supervised Fine-Tuning (SFT) 、人类反馈对齐(RLHF)和 Prompt Engineering (PE) 。
较值得分享的是 —— 团队开发了人类反馈对齐(RLHF)优化系统,提升了 Seedream 2.0 整体性能。
其核心工作包含以下三个方面:
- 多维度偏好数据体系,提升模型偏好上限
团队收集并整理了一个多功能的 Prompt 集合,专门用于奖励模型(RM)训练和反馈学习阶段,并通过构建跨版本和跨模型标注管道,增强了 RM 的领域适应性,并扩展了模型偏好的上限。
在标注阶段,团队构建了多维融合注释。这一做法成功扩展了单一奖励模型的多维度偏好表征边界,促进模型在多个维度上实现帕累托最优。
- 三个不同奖励模型,给予专项提升
Seedream 2.0 直接利用 CLIP 嵌入空间距离,作为基础奖励值。这省去了回归头等冗余参数结构以及不稳定训练情况。
同时,团队精心制作并训练了三个不同的奖励模型:图像文本对齐 RM、美学 RM 和文本渲染 RM。
其中,文本渲染 RM 引入了触发式激活机制,在检测到 “文本生成” 类标签时,模型将强化字符细节优化能力,提升汉字生成准确率。
- 反复学习,驱动模型进化
团队通过直接最大化多个 RM 的奖励,以改进扩散模型。通过调整学习率、选择合适的去噪时间步长和实施权重指数滑动平均,实现了稳定的反馈学习训练。
在反馈学习阶段,团队同时微调 DiT 和文本编码器。此种联合训练显著增强了模型在图像文本对齐和美学改进方面的能力。
经过 RLHF 阶段对扩散模型和奖励模型的多轮迭代,团队进一步提高了模型性能。
奖励曲线显示,在整个对齐过程中,不同奖励模型的表现分数值都呈现稳定且一致的上升趋势。

从 Scaling 到强化学习
解锁模型优化新可能
Seedream 2.0 模型技术报告的发布,是字节跳动首次公开图像生成基础模型的细节做法。团队还将持续探索更高效地 Scaling 模型参数及数据的创新技术,进一步提升模型的性能边界。
伴随 2025 年强化学习浪潮兴起,团队认为,他们将持续探索基于强化学习的优化机制,包括如何更好地设计奖励模型及数据构建方案。
后续,豆包大模型团队也将持续分享技术经验,共同推动行业发展。

















 4801
4801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









