







我自己的原文哦~ https://blog.51cto.com/whaosoft/11622380
#用苹果Vision Pro隔空操控机器人
黄仁勋表示:「AI 的下一波浪潮是机器人,其中最令人兴奋的发展之一是人形机器人。」如今,Project GR00T 又迈出了重要的一步。
昨日,英伟达创始人黄仁勋在 SIGGRAPH 2024 Keynote 演讲中讲到了其人形机器人通用基础模型「Project GR00T」。该模型在功能上迎来了一系列更新。
德克萨斯大学奥斯汀分校助理教授、英伟达高级研究科学家朱玉可发推,在视频中演示了英伟达如何将通用家务机器人大规模仿真训练框架 RoboCasa 和 MimicGen 系统整合到英伟达 Omniverse 平台和 Isaac 机器人开发平台。
图源:https://x.com/yukez/status/1818092679936299373
视频中涵盖了英伟达自己的三个计算平台,包括 AI、Omniverse 和 Jetson Thor,利用它们简化和加速开发者工作流程。通过这些计算平台的共同赋能,我们有望进入由物理 AI 驱动的人形机器人时代。

其中最大的亮点,开发人员能够使用苹果 Vision Pro 来远程操控人形机器人来执行任务。


与此同时,另一位英伟达高级研究科学家 Jim Fan 表示,Project GR00T 的更新令人振奋。英伟达利用系统化的方法来扩展机器人数据,解决了机器人领域最棘手的难题。
思路也很简单:人类在真实机器人身上收集演示数据,而英伟达在仿真中将这些数据扩展千倍及以上。通过 GPU 加速仿真,人们现在可以用算力来换取耗时耗力耗资金的人类收集数据了。
他谈到自己不久前还认为远程操控在根本上不可扩展,这是因为在原子世界中,我们总是受到 24 小时 / 机器人 / 天数的限制。英伟达在 GR00T 上采用的新的合成数据 pipeline 在比特世界打破了这一局限。
图源:https://x.com/DrJimFan/status/1818302152982343983
对于英伟达在人形机器人领域的最新进展,有网友表示,苹果 Vision Pro 找到了最酷的用例。
英伟达开始引领下一波浪潮:物理 AI
英伟达也在一篇博客中详述了加速人形机器人的技术流程,完整内容如下:
为了加速全球范围内人形机器人的发展,英伟达宣布为全球领先的机器人制造商、AI 模型开发商和软件制造商提供一套服务、模型和计算平台,以开发、训练和构建下一代人形机器人。

这套产品包括用于机器人仿真和学习的全新 NVIDIA NIM 微服务和框架、用于运行多阶段机器人工作负载的 NVIDIA OSMO 编排服务,以及支持 AI 和仿真的远程操作工作流,该工作流允许开发者使用少量人类演示数据来训练机器人。
黄仁勋表示:「AI 的下一波浪潮是机器人,其中最令人兴奋的发展之一是人形机器人。我们正在推进整个 NVIDIA 机器人堆栈的发展,面向全球人形机器人开发者和公司开放访问,让他们能够使用最符合其需求的平台、加速库和 AI 模型。」
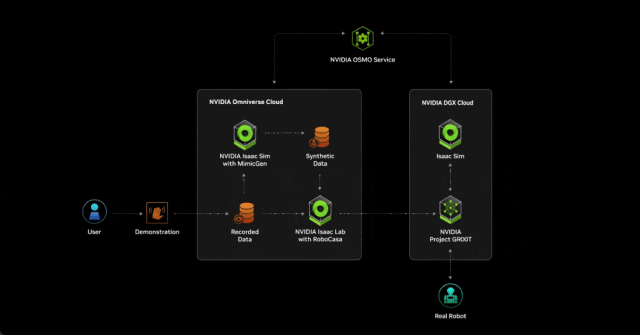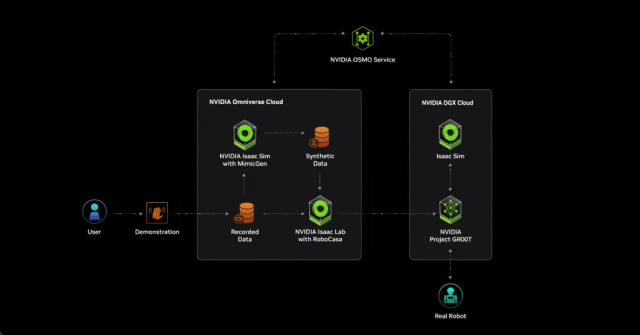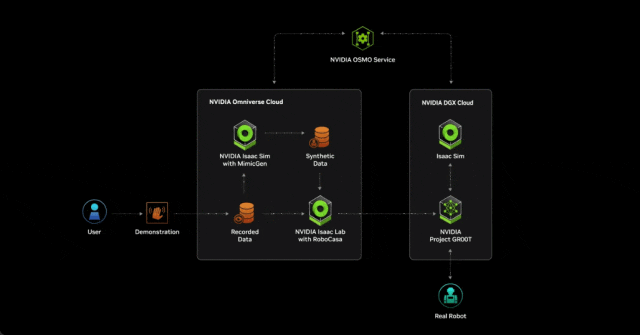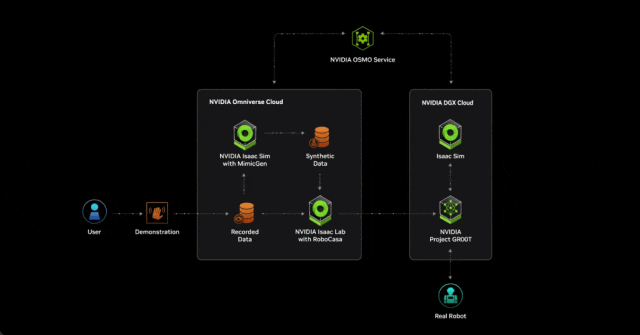
借助 NVIDIA NIM 和 OSMO 加速开发
NIM 微服务提供了由英伟达推理软件提供支持的预构建容器,使开发人员能够将部署时间从几周缩短到几分钟。
两个新的 AI 微服务将允许机器人专家在 NVIDIA Isaac Sim 中增强生成物理人工智能仿真工作流程。
MimicGen NIM 微服务根据来自空间计算设备(如 Apple Vision Pro)记录的远程数据生成合成运动数据。Robocasa NIM 微服务可在 OpenUSD 中生成机器人任务和仿真环境。
云原生托管服务 NVIDIA OSMO 现已推出,允许用户在分布式计算资源(无论是在本地还是在云中)中协调和扩展复杂的机器人开发工作流程。OSMO 的出现大大简化了机器人训练和仿真工作流程,将部署和开发周期从数月缩短至不到一周。
为人形机器人开发者提供先进的数据捕获工作流
训练人形机器人背后的基础模型需要大量的数据。获取人类演示数据的一种方法是使用远程操作,但这种方式正变得越来越昂贵和漫长。
通过在 SIGGRAPH 计算机图形大会上展示的 NVIDIA AI 和 Omniverse 远程操作参考工作流,研究者和 AI 开发者能够从极少量远程捕捉的人类演示中生成大量合成运动和感知数据。

首先,开发人员使用 Apple Vision Pro 捕捉少量远程演示。然后,他们在 NVIDIA Isaac Sim 中仿真录音,并使用 MimicGen NIM 微服务从录音中生成合成数据集。
开发人员使用真实数据和合成数据来训练 Project GR00T 人形机器人基础模型,从而节省了大量的时间并降低了成本。然后,他们使用 Isaac Lab 中的 Robocasa NIM 微服务(一种机器人学习框架)来生成经验以重新训练机器人模型。在整个工作流中,NVIDIA OSMO 将计算任务无缝地分配给不同的资源,为开发者减少了数周的管理工作量。
扩大对 NVIDIA 人形机器人开发者技术的访问权限
NVIDIA 提供了三个计算平台来简化人形机器人的开发:用于训练模型的 NVIDIA AI 超级计算机;基于 Omniverse 构建的 NVIDIA Isaac Sim,机器人可以在仿真世界中学习和完善技能;以及用于运行模型的 NVIDIA Jetson Thor 人形机器人计算机。开发人员可以根据自己的特定需求访问和使用全部或部分平台。
通过新的 NVIDIA 人形机器人开发者计划,开发者可以提前使用新产品以及 NVIDIA Isaac Sim、NVIDIA Isaac Lab、Jetson Thor 和 Project GR00T 通用人形机器人基础模型的最新版本。
1x、波士顿动力、字节跳动、Field AI、Figure、Fourier、Galbot、LimX Dynamics、Mentee、Neura Robotics、RobotEra 和 Skild AI 是首批加入早期访问计划的公司。
开发人员现在可以加入 NVIDIA 人形机器人开发人员计划,以访问 NVIDIA OSMO 和 Isaac Lab,并且很快将获得 NVIDIA NIM 微服务的访问权限。
博客链接:
https://nvidianews.nvidia.com/news/nvidia-accelerates-worldwide-humanoid-robotics-development
#GALA3D
复杂组合3D场景生成,LLMs对话式3D可控生成编辑框架来了
该论文的第一作者和通讯作者均来自北京大学王选计算机研究所的 VDIG (Visual Data Interpreting and Generation) 实验室,第一作者为博士生周啸宇,通讯作者为博士生导师王勇涛。VDIG 实验室近年来在 IJCV、CVPR、AAAI、ICCV、ICML、ECCV 等顶会上有多项代表性成果发表,多次荣获国内外 CV 领域重量级竞赛的冠亚军奖项,和国内外知名高校、科研机构广泛开展合作。
近年来,针对单个物体的 Text-to-3D 方法取得了一系列突破性进展,但是从文本生成可控的、高质量的复杂多物体 3D 场景仍然面临巨大挑战。之前的方法在生成场景的复杂度、几何质量、纹理一致性、多物体交互关系、可控性和编辑性等方面均存在较大缺陷。
最近,来自北京大学王选计算机研究所的 VDIG 研究团队与其合作者公布了最新研究成果 GALA3D。针对多物体复杂 3D 场景生成,该工作提出了 LLM 引导的复杂三维场景可控生成框架 GALA3D,能够生成高质量、高一致性、具有多物体和复杂交互关系的 3D 场景,支持对话式交互的可控编辑,论文已被 ICML 2024 录用。
- 论文标题:GALA3D: Towards Text-to-3D Complex Scene Generation via Layout-guided Generative Gaussian Splatting
- 论文链接:https://arxiv.org/pdf/2402.07207
- 论文代码:https://github.com/VDIGPKU/GALA3D
- 项目网站:https://gala3d.github.io/

GALA3D 是一个高质量的 Text-to-3D 复杂组合场景生成与可控编辑框架。用户输入一段描述文本,GALA3D 能够 zero-shot 地生成相应的具有多物体和复杂交互关系的三维场景。GALA3D 在保证生成 3D 场景与文本高度对齐的同时,展现了其在生成场景质量、多物体复杂交互、场景几何一致性等方面的卓越性能。此外,GALA3D 还支持用户友好的端到端生成和可控编辑,使得普通用户能够在对话式的交谈中轻松定制和编辑 3D 场景。在与用户的交流中,GALA3D 可以精准地实现复杂三维场景对话式的可控编辑,并根据用户的对话实现复杂三维场景的布局变换、数字资产嵌入、装修风格改变等多样化的可控编辑需求。
方法介绍
GALA3D 的整体架构如下图所示:

GALA3D 利用大型语言模型(LLMs)生成初始布局,并提出布局引导的生成式 3D 高斯表示构建复杂 3D 场景。GALA3D 设计通过自适应几何控制优化 3D 高斯的形状和分布,以生成具有一致几何、纹理、比例和精确交互的 3D 场景。此外,GALA3D 还提出了一种组合优化机制,结合条件扩散先验和文生图模型,协作生成具有一致风格的 3D 多物体场景,同时迭代优化从 LLMs 提取的初始布局先验,以获得更加逼真准确的真实场景空间布局。广泛的定量实验和定性研究表明 GALA3D 在文本到复杂三维场景生成方面取得了显著效果,超越现有文生 3D 场景方法。
a、基于 LLMs 的场景布局先验
大语言模型展现了优异的自然语言理解和推理能力,本文进一步探索了 LLMs 大语言模型在 3D 复杂场景的推理和布局生成能力。如何在没有人工设计的情况下获得相对合理的布局先验有助于减少场景建模和生成的代价。对此,我们使用 LLMs (例如 GPT-3.5) 对文本输入的实例及其空间关系进行抽取,并生成相应的 Layout 布局先验。然而,通过 LLMs 解读的场景 3D 空间布局和 Layout 先验与实际场景存在一定差距,通常表现生成悬浮 / 穿模的物体,比例差异过大的物体组合等。进一步地,我们提出了 Layout Refinement 模块,通过基于视觉的 Diffusion 先验和 Layout 引导的生成式 3D 高斯对上述生成的粗糙布局先验进行调整和优化。
b、Layout Refinement
GALA3D 使用基于 Diffusion 先验的 Layout 布局优化模块对上述 LLMs 生成的布局先验进行优化。具体地,我们将 Layout 引导的 3D 高斯空间布局的梯度优化加入 3D 生成过程,通过 ControlNet 对 LLM-generated Layouts 进行空间位置、旋转角度和尺寸比例的调整,如图展示了优化前后 3D 场景和 Layout 的对应关系。经过优化的 Layout 具有更加准确的空间位置和比例尺度,并且使得 3D 场景中多物体的交互关系更加合理。

c、布局引导的生成式 3D 高斯表示
我们首次将 3D-Layout 约束引入 3D 高斯表示,提出了布局引导的生成式 3D 高斯,用于复杂文生 3D 场景。Layout-guided 3D 高斯表示包含多个语义抽取的实例物体,其中每个实例物体的 Layout 先验可以参数化为:

其中,N 代表场景中实例物体的总数。具体地,每一个实例 3D 高斯通过自适应几何控制进行优化,得到实例级的物体 3D 高斯表示。进一步地,我们将多个物体高斯根据相对位置关系组合到全场景中,生成布局引导的全局 3D 高斯并通过全局 Gaussian Splatting 渲染整个场景。
d、自适应几何控制
为了更好地控制 3D 高斯在生成过程中的空间分布和几何形状,我们提出了针对生成式 3D 高斯的自适应几何控制方法。首先给定一组初始高斯,为了将 3D 高斯约束在 Layout 范围内,GALA3D 使用一组密度分布函数来约束高斯椭球的空间位置。我们接着对 Layout 表面附近的高斯进行采样来拟合分布函数。之后,我们提出使用形状正则化控制 3D 高斯的几何形状。在 3D 生成的过程中,自适应几何控制不断优化高斯的分布和几何,从而生成更具纹理细节和规范几何的 3D 多物体与场景。自适应几何控制还保证了布局引导的生成式 3D 高斯具有更高的可控性和一致性。
实验结果
与现有 Text-to-3D 生成方法相比,GALA3D 展现了更加优异的 3D 场景生成质量和一致性,定量实验结果如下表所示:
我们还进行了广泛且有效的用户调研,邀请 125 位参与者(其中 39.2% 为相关领域的专家和从业人员)对本文方法和现有方法的生成场景进行多角度评估,结果如下表所示:
实验结果表明 GALA3D 在生成场景质量、几何保真度、文本一致性、场景一致性等多维度的测评指标中均超越现有方法,取得了最优的生成质量。
如下图定性实验结果所示,GALA3D 能够 zero-shot 地生成复杂多物体组合 3D 场景,并且具有良好的一致性:

下图展示了 GALA3D 能够支持用户友好的、对话式的可控生成和编辑:

更多研究细节,可参考原论文。
#Gemma 2
谷歌开源最强端侧小模型:2B参数越级跑赢GPT-3.5-Turbo,苹果15Pro运行飞快
谷歌也来卷「小」模型了,一出手就是王炸,胜过了比自己参数多得多的GPT-3.5、Mixtral竞品模型
今年 6 月底,谷歌开源了 9B、27B 版 Gemma 2 模型系列,并且自亮相以来,27B 版本迅速成为了大模型竞技场 LMSYS Chatbot Arena 中排名最高的开放模型之一,在真实对话任务中比其两倍规模以上的模型表现还要好。
如今,仅仅过去了一个多月,谷歌在追求负责任 AI 的基础上,更加地考虑该系列模型的安全性和可访问性,并有了一系列新成果。
此次,Gemma 2 不仅有了更轻量级「Gemma 2 2B」版本,还构建一个安全内容分类器模型「ShieldGemma」和一个模型可解释性工具「Gemma Scope」。具体如下:
- Gemma 2 2B 具有内置安全改进功能,实现了性能与效率的强大平衡;
- ShieldGemma 基于 Gemma 2 构建,用于过滤 AI 模型的输入和输出,确保用户安全;
- Gemma Scope 提供对模型内部工作原理的无与伦比的洞察力。
其中,Gemma 2 2B 无疑是「最耀眼的仔」,它在大模型竞技场 LMSYS Chatbot Arena 中的结果令人眼前一亮:仅凭 20 亿参数就跑出了 1130 分,这一数值要高于 GPT-3.5-Turbo(0613)和 Mixtral-8x7b。
这也意味着,Gemma 2 2B 将成为端侧模型的最佳选择。
苹果机器学习研究(MLR)团队研究科学家 Awni Hannun 展示了 Gemma 2 2B 跑在 iPhone 15 pro 上的情况,使用了 4bit 量化版本,结果显示速度是相当快。
视频来源:https://x.com/awnihannun/status/1818709510485389563
此外,对于前段时间很多大模型都翻了车的「9.9 和 9.11 谁大」的问题,Gemma 2 2B 也能轻松拿捏。
图源:https://x.com/tuturetom/status/1818823253634564134
与此同时,从谷歌 Gemma 2 2B 的强大性能也可以看到一种趋势,即「小」模型逐渐拥有了与更大尺寸模型匹敌的底气和效能优势。
这种趋势也引起了一些业内人士的关注,比如知名人工智能科学家、Lepton AI 创始人贾扬清提出了一种观点:大语言模型(LLM)的模型大小是否正在走 CNN 的老路呢?
在 ImageNet 时代,我们看到参数大小快速增长,然后我们转向了更小、更高效的模型。这是在 LLM 时代之前,我们中的许多人可能已经忘记了。
- 大型模型的曙光:我们以 AlexNet(2012)作为基线开始,然后经历了大约 3 年的模型大小增长。VGGNet(2014)在性能和尺寸方面都可称为强大的模型。
- 缩小模型:GoogLeNet(2015)将模型大小从 GB 级缩小到 MB 级,缩小了 100 倍,同时保持了良好的性能。类似工作如 SqueezeNet(2015)和其他工作也遵循类似的趋势。
- 合理的平衡:后来的工作如 ResNet(2015)、ResNeXT(2016)等,都保持了适中的模型大小。请注意,我们实际上很乐意使用更多的算力,但参数高效同样重要。
- 设备端学习?MobileNet(2017)是谷歌的一项特别有趣的工作,占用空间很小,但性能却非常出色。上周,我的一个朋友告诉我「哇,我们仍然在使用 MobileNet,因为它在设备端具有出色的特征嵌入通用性」。是的,嵌入式嵌入是实实在在很好用。
最后,贾扬清发出灵魂一问,「LLM 会遵循同样的趋势吗?」
图像出自 Ghimire 等人论文《A Survey on Efficient Convolutional Neural Networks and Hardware Acceleration》。
Gemma 2 2B 越级超越 GPT-3.5 Turbo
Gemma 2 家族新增 Gemma 2 2B 模型,备受大家期待。谷歌使用先进的 TPU v5e 硬件在庞大的 2 万亿个 token 上训练而成。
这个轻量级模型是从更大的模型中蒸馏而来,产生了非常好的结果。由于其占用空间小,特别适合设备应用程序,可能会对移动 AI 和边缘计算产生重大影响。
事实上,谷歌的 Gemma 2 2B 模型在 Chatbot Arena Elo Score 排名中胜过大型 AI 聊天机器人,展示了小型、更高效的语言模型的潜力。下图表显示了 Gemma 2 2B 与 GPT-3.5 和 Llama 2 等知名模型相比的卓越性能,挑战了「模型越大越好」的观念。
Gemma 2 2B 提供了:
- 性能卓越:在同等规模下提供同类最佳性能,超越同类其他开源模型;
- 部署灵活且经济高效:可在各种硬件上高效运行,从边缘设备和笔记本电脑到使用云部署如 Vertex AI 和 Google Kubernetes Engine (GKE) 。为了进一步提高速度,该模型使用了 NVIDIA TensorRT-LLM 库进行优化,并可作为 NVIDIA NIM 使用。此外,Gemma 2 2B 可与 Keras、JAX、Hugging Face、NVIDIA NeMo、Ollama、Gemma.cpp 以及即将推出的 MediaPipe 无缝集成,以简化开发;
- 开源且易于访问:可用于研究和商业应用,由于它足够小,甚至可以在 Google Colab 的 T4 GPU 免费层上运行,使实验和开发比以往更加简单。
从今天开始,用户可以从 Kaggle、Hugging Face、Vertex AI Model Garden 下载模型权重。用户还可以在 Google AI Studio 中试用其功能。
下载权重地址:https://huggingface.co/collections/google/gemma-2-2b-release-66a20f3796a2ff2a7c76f98f
Gemma 2 2B 的出现挑战了人工智能开发领域的主流观点,即模型越大,性能自然就越好。Gemma 2 2B 的成功表明,复杂的训练技术、高效的架构和高质量的数据集可以弥补原始参数数量的不足。这一突破可能对该领域产生深远的影响,有可能将焦点从争夺越来越大的模型转移到改进更小、更高效的模型。
Gemma 2 2B 的开发也凸显了模型压缩和蒸馏技术日益增长的重要性。通过有效地将较大模型中的知识提炼成较小的模型,研究人员可以在不牺牲性能的情况下创建更易于访问的 AI 工具。这种方法不仅降低了计算要求,还解决了训练和运行大型 AI 模型对环境影响的担忧。
ShieldGemma:最先进的安全分类器
技术报告:https://storage.googleapis.com/deepmind-media/gemma/shieldgemma-report.pdf
ShieldGemma 是一套先进的安全分类器,旨在检测和缓解 AI 模型输入和输出中的有害内容,帮助开发者负责任地部署模型。
ShieldGemma 专门针对四个关键危害领域进行设计:
- 仇恨言论
- 骚扰
- 色情内容
- 危险内容
这些开放分类器是对负责任 AI 工具包(Responsible AI Toolkit)中现有安全分类器套件的补充。
借助 ShieldGemma,用户可以创建更加安全、更好的 AI 应用
SOTA 性能:作为安全分类器,ShieldGemma 已经达到行业领先水平;
规模不同:ShieldGemma 提供各种型号以满足不同的需求。2B 模型非常适合在线分类任务,而 9B 和 27B 版本则为不太关心延迟的离线应用程序提供了更高的性能。
如下表所示,ShieldGemma (SG) 模型(2B、9B 和 27B)的表现均优于所有基线模型,包括 GPT-4。
Gemma Scope:让模型更加透明
Gemma Scope 旨在帮助 AI 研究界探索如何构建更易于理解、更可靠的 AI 系统。其为研究人员和开发人员提供了前所未有的透明度,让他们能够了解 Gemma 2 模型的决策过程。Gemma Scope 就像一台强大的显微镜,它使用稀疏自编码器 (SAE) 放大模型的内部工作原理,使其更易于解释。
Gemma Scope 技术报告:https://storage.googleapis.com/gemma-scope/gemma-scope-report.pdf
SAE 可以帮助用户解析 Gemma 2 处理的那些复杂信息,将其扩展为更易于分析和理解的形式,因而研究人员可以获得有关 Gemma 2 如何识别模式、处理信息并最终做出预测的宝贵见解。
以下是 Gemma Scope 具有开创性的原因:
- 开放的 SAE:超过 400 个免费 SAE,涵盖 Gemma 2 2B 和 9B 的所有层;
- 交互式演示:无需在 Neuronpedia 上编写代码即可探索 SAE 功能并分析模型行为;
- 易于使用的存储库:提供了 SAE 和 Gemma 2 交互的代码和示例。
参考链接:
#arXiv
arXiv论文可以发「弹幕」了,斯坦福alphaXiv讨论平台上线,LeCun点赞
当论文讨论细致到词句,是什么体验?
最近,斯坦福大学的学生针对 arXiv 论文创建了一个开放讨论论坛 ——alphaXiv,可以直接在任何 arXiv 论文之上发布问题和评论。
网站链接:https://alphaxiv.org/
其实不需要专门访问这个网站,只需将任何 URL 中的 arXiv 更改为 alphaXiv 就可以直接在 alphaXiv 论坛上打开相应论文:
可以精准定位到论文中的段落、句子:
右侧讨论区,用户可以发表问题询问作者论文思路、细节,例如:
也可以针对论文内容发表评论,例如:「给出至少一个数学问题及其解决方案作为示例会具有启发性。」
用户还可以回应、点赞、反对某条评论:
对此,图灵奖得主 Yann LeCun 也觉得非常 Nice。
我们发现很多论文作者纷纷称赞 alphaXiv 论坛,例如最近发表的一篇论文《KAN or MLP: A Fairer Comparison》,在 alphaXiv 上收获了一些讨论,论文一作 Runpeng Yu 发推表示将在 alphaXiv 上回答大家的问题。
如网友所说:「AlphaXiv 使研究变得易于协作」,推进了学术交流。
如此方便的论文交流平台,感兴趣的读者快去试试吧。
参考链接:
https://twitter.com/StanfordAILab/status/1818669016325800216
#MindSearch
还没排上SearchGPT?比Perplexity更好用的国产开源平替了解一下?
来自上海人工智能实验室。
有 AI 在的科技圈,似乎没有中场休息。除了大模型发布不断,各家科技大厂也在寻找着第一个「杀手级」AI 应用的落脚之地。
OpenAI 首先瞄准的是谷歌 1750 亿美元的搜索业务市场。7 月 25 日,OpenAI 带着 AI 搜索引擎——SearchGPT 高调入场。在演示 demo 中,搜索引擎的使用体验不再像以往一样,需要我们逐个点开网页链接,判断信息有没有用。SearchGPT 像端上了一桌精美的套餐,所有答案都帮你总结好了。
在演示 demo 中,SearchGPT 分析了在应季最适合种植哪种品种的番茄。
不过,鉴于年初发布的 Sora 到目前都还未正式开放,估计很多人排上 SearchGPT 的体验名额也遥遥无期。
然而,有一款国产的开源平替,在和能联网的 ChatGPT 和专攻 AI 搜索引擎的 Perplexity.ai 的 PK 中,它的回答在深度、广度和准确度方面都都秒了这两款明星产品。
它甚至可以在不到 3 分钟内收集并整合 300 多页相关信息。这换成人类专家,需要大约 3 小时才能做完。
这款「国货」就是多智能体框架 MindSearch(思・索),由来自中科大和上海人工智能实验室的研究团队联合研发。正如其名,MindSearch 是一个会「思索」的系统,面对你输入的问题,它将先调用负责充分「思」考问题的智能体,再启用全面搜「索」的智能体,这些智能体分工合作,理解你的需求,并为你呈上从互联网的五湖四海搜罗来的新鲜信息。
- 论文链接:https://arxiv.org/abs/2407.20183
- 项目主页:https://mindsearch.netlify.app/
MindSearch 演示 demo
那么,MindSearch 是凭什么打败 ChatGPT 和 Perplexity.ai 的呢?和别的 AI 搜索引擎相比,MindSearch 有什么独到之处吗?
答案还得从它的名字说起。MindSearch 的核心竞争力在于采用了多智能体框架模拟人的思维过程。
如果向 Perplexity.ai 提问「王者荣耀当前赛季哪个射手最强?」它会直接搜索这个问题,并总结网上已有的回复。把这个问题交给 MindSearch,它会把这个问题拆解成一个逻辑链:「当前赛季是哪个赛季?」,「从哪些指标可以衡量王者荣耀的射手的强度?」,再汇总所能查询到的答案。
技术实现
WebPlanner:基于图结构进行规划
仅依靠向大型语言模型输入提示词的方式并不能胜任智能搜索引擎。首先,LLM 不能充分理解复杂问题中的拓扑关系,比如前一段挂在热搜上的大模型无法理解 9.9 和 9.11 谁大的问题,就是这个问题的生动注脚。字与字之间的关系,LLM 都很难在简单对话中理解,那么「这个季节种哪个品种的番茄最合适?」这种需要深入思考,分解成多个角度来回答的问题,对于 LLM 就更难了。换句话说,LLM 很难将用户的意图逐步转化为搜索任务,并提供准确的响应,因此它总是提供一些模版式的知识和套话。
基于此,研究团队设计了高级规划器 WebPlanner,它通过构建有向无环图(DAG)来捕捉从提问到解答之间的最优执行路径。对于用户提出的每个问题 Q,WebPlanner 将其解决方案的轨迹表示为 G (Q) = ⟨V, E⟩。在这个图中,V 代表节点的集合,每个节点 v 代表一个独立的网页搜索任务,包括一个辅助的起始节点(代表初始问题)和一个结束节点(代表最终答案)。E 代表有向边,指示节点之间的逻辑和推理关系。
研究团队进一步利用 LLM 优越的代码能力,引导模型编写代码与 DAG 图交互。为了实现这一点,研究团队预定义了原子代码函数,让模型可以在图中添加节点或边。在解答用户问题的过程中,LLM 先阅读整个对话,还有它在网上搜索到的信息。阅读完这些信息后,LLM 会根据这些信息产生一些思考和新的代码,这些代码将通过 Python 解释器添加在用于推理的图结构中。
一旦有新节点加入图中,WebPlanner 将启动 WebSearcher 来执行搜索任务,并整理搜索到的信息。由于新节点只依赖于之前步骤中生成的节点,所以这些节点可以并行处理,大大提高了信息收集的速度。当所有的信息收集完毕,WebPlanner 将添加结束节点,输出最终答案。
WebSearcher:分层检索网页
由于互联网上的信息实在太多,就算是 LLM 也不能一下子处理完所有的页面。针对这个问题,研究团队选择了先广泛搜索再精确选择的策略,设计了一个 RAG 智能体 ——WebSearcher。
首先,LLM 将根据 WebPlanner 分配的问题,生成几个类似的搜索问题,扩大搜索的范围。接下来,系统将调用不同搜索引擎的 API 查询问题,例如分别在 Google、Bing 和 DuckDuckGo 查一下,得到网页的链接、标题和摘要等关键信息。接着,LLM 将从这些搜索结果中选出最重要的网页来仔细阅读,汇总得出最终答案。
MindSearch 中,LLM 如何管理上下文
作为一个多智能体框架,MindSearch 为如何管理长上下文提供了全新尝试。当需要快速阅读大量网页时,由于最终答案只依赖 WebSearcher 的搜索结果,WebPlanner 将专注于分析用户提出的问题,不会被过长的网页信息分心。
这种明确的分工也大大减少了上下文计算量。如何在多个智能体之间高效共享信息和上下文并非易事,研究团队在实证中发现,如果只依靠 WebPlanner 的分析,有可能会在信息收集阶段由于 WebSearcher 内部的局部感知场丢失有用的信息。为了解决这个问题,他们利用有向图边构建的拓扑关系来简化上下文如何在不同智能体间传递。
具体来说,在 WebSearcher 执行搜索任务时,它的父节点以及根节点的回答将作为前缀添加在其回答中。因此,每个 WebSearcher 可以有效地专注于其子任务,同时不会丢失之前的相关上下文或者忘记最终的查询目标。
本地部署
7 月初,上海人工智能实验室已经开源了搭载 MindSearch 架构的 InternLM2.5-7B-Chat 模型。
除了直接点击链接,跳转到体验 Demo 试玩。研究团队还公开了 MindSearch 的完整前后端实现,基于智能体框架 Lagent,感兴趣的朋友可以在本地部署模型。
- 在线 Demo:https://mindsearch.openxlab.org.cn/
- 开源代码:https://github.com/InternLM/mindsearch
在 GitHub 下载 MindSearch 仓库后,输入如下命令就可以打造属于自己的 MindSearch 了:
# 启动服务
python -m mindsearch.app --lang en --model_format internlm_server
## 一键启动多种前端
# Install Node.js and npm
# for Ubuntu
sudo apt install nodejs npm
# for windows
# download from https://nodejs.org/zh-cn/download/prebuilt-installer
# Install dependencies
cd frontend/React
npm install
npm start#SELF-GUIDE
CMU&清华新作:让LLM自己合成数据来学习,特定任务性能同样大幅提升
本文主要作者来自清华大学和卡内基梅隆大学(CMU)。共同一作为清华大学计算机系本科毕业生赵晨阳,卡内基梅隆大学硕士生贾雪莹。
虽然大规模语言模型(LLM)在许多自然语言处理任务中表现优异,但在具体任务中的效果却不尽如人意。为了提升模型在特定自然语言任务上的表现,现有的方法主要依赖于高质量的人工标注数据。这类数据的收集过程既耗时又费力,对于数据稀缺的任务尤为困难。
为了解决这个问题,一些研究尝试通过强大的 Teacher Model 生成训练数据,来增强 Student Model 在特定任务上的性能。然而,这种方法在成本、可扩展性和法律合规性方面仍面临诸多挑战。在无法持续获得高质量人类监督信号的情况下,如何持续迭代模型的能力,成为了亟待解决的问题。
来自卡内基梅隆大学和清华大学的研究团队提出了 SELF-GUIDE 方法。该方法通过语言模型自身生成任务特定的数据集,并在该数据集上进行微调,从而显著提升模型在特定任务上的能力,无需依赖大量外部高质量数据或更强大的 Teacher Model。具体来说,在外部输入大约 3 个样例的情况下,SELF-GUIDE 采用多阶段的生成和过滤机制,利用模型生成的合成数据进行微调,使模型在特定任务上的表现更加出色。
- 论文地址:https://arxiv.org/abs/2407.12874
- 代码仓库:https://github.com/zhaochenyang20/Prompt2Model- SELF-GUIDE
图 1:SELF-GUIDE 利用模型自主合成数据的能力提升模型执行特定任务的能力。
方法
具体来说,研究团队将 SELF-GUIDE 方法分解为三个主要阶段:输入数据生成、输出数据生成和质量优化。
输入数据生成
在 SELF-GUIDE 框架的设计和实现过程中,研究者首先根据任务类型(生成型任务或分类型任务)指定不同的提示模板。对于生成型任务, SELF-GUIDE 框架使用一个相对简单的提示模板。而对于分类型任务, SELF-GUIDE 框架则采用了另一种策略。对于分类任务, SELF-GUIDE 框架首先从全部标签空间中随机选择一个标签,将其作为条件生成的伪标签,指导输入数据的生成。选定伪标签后, SELF-GUIDE 框架使用较为复杂的条件生成模板,引导模型生成与所选伪标签相对应的输入内容。
图 2:SELF-GUIDE 的核心在于一个高效的多阶段生成机制,其中语言模型逐步生成输入数据输出数据组合。经过生成和过滤后,自生成的数据进一步用于微调语言模型本身。此图描述了 SELF-GUIDE 针对生成任务的流程。
选定模板并填充示例(few-shot examples)后,完整的提示被传递给 LLM,以生成输入数据。每轮提示后,新生成的输入会被添加到输入库中。从这个库中随机抽取一部分输入,并与初始示例中的输入合并,形成新的提示,逐步扩展 LLM 生成的输入集并且减少重复。SELF-GUIDE 仅进行一轮输入生成,随后在质量优化阶段,应用基于规则的过滤器来去除低质量的输入。
图 3:此图描述了 SELF-GUIDE 完成分类任务的过程。对于分类任务的数据,SELF-GUIDE 首先生成伪标签,然后生成对应的输入,最后重新生成真实标签。
输出数据生成
输出数据生成阶段采用了典型的上下文学习方法:研究者向模型提供任务指令和原始示例,使模型对输入生成阶段产生的每一个输入进行标注。在获取所有输出后,再进行一轮基于规则的过滤,以选择最终的合成数据集。
质量优化
生成数据的质量对于下游训练的成功至关重要。SELF-GUIDE 采用了两种策略来提高质量:调整生成参数以提高生成质量并基于规则过滤掉低质量样本。
调整温度:调整温度是一种平衡多样性和质量的常见策略。SELF-GUIDE 框架在输入生成阶段使用较高的温度以鼓励多样性,在其他阶段通过使用较低的温度确保得到概率最高的输出,从而保证整体数据质量。然而,仅依靠温度调整不足以实现所需的平衡。因此, SELF-GUIDE 还在输入生成后和输出注释后分别进行了两轮基于规则的数据过滤。
噪声过滤(Noise Filter):研究者手动整理了一份噪声术语列表,包括常见的问候语和噪声字符(例如,生成内容中的”\\”)。如果生成示例的输入或输出中出现了任何来自这份列表的噪声术语, SELF-GUIDE 将丢弃整个示例。
长度过滤(Length Filter):虽然示例的长度可能存在偏差,但是研究者认为这些示例在特定任务的长度分布方面仍然具有代表性。SELF-GUIDE 假设示例的长度遵循正态分布,并计算出输入样例的均值 μ 和标准差 σ,研究者假定生成示例的输入和输出长度应符合同一正态分布,并要求长度在 (μ − 2σ, μ + 2σ) 范围内。
整体参数微调(One Parameter Fits All):为了使 SELF-GUIDE 生成符合指令和示例指定目标分布的训练数据,需要在标注数据点上优化各种超参数,包括生成输入输出的个数、输入数据生成的温度、输出数据生成的温度、微调参数等。研究者将实验测试任务分为两部分:一部分可以利用所有数据进行验证以调整生成参数,称为验证任务;另一部分的数据仅用于测试而不可用于调整参数,称为测试任务。研究者在验证任务上搜索 “最大化最差任务性能” 的参数,并将其固定用于测评 SELF-GUIDE 在测试任务上的表现。
实验结果
为了评估 SELF-GUIDE 的有效性,研究者从 Super-NaturalInstructions V2 基准中选择了 14 个分类任务和 8 个生成任务。研究者随机选择了一半任务用于超参数搜索,剩余的一半用于评估。在模型方面,研究者选择了 Vicuna-7b-1.5 作为输入生成、输出生成和微调的基础模型。在评估指标方面,研究者采用了与 Super-NaturalInstructions 基准相同的评估指标,即分类任务的 Exact Match 和生成任务的 ROUGE-L。
为了体现 SELF-GUIDE 的效果,研究者将 SELF-GUIDE 与其他指令跟随和上下文学习方法进行了比较:
1.Few-Shot ICL:作为主要基准,研究者与直接提示语言模型进行了比较。这种方法直接依赖于模型固有的指令跟随能力。
2.Self-ICL:Self-ICL 使用自生成的示例来提高零样本指令跟随。研究者在 Self-ICL 工作的基础上进行了修改,通过自生成尽可能多的示例(而不是固定个数的示例)填充提示词,从而增加参考样本数目。
3.Few-Shot Finetuning:直接利用输入的少量示例进行微调。
SELF-GUIDE 原文主要实验结果如下所示。在基准的评估指标上,分类任务的绝对提升达到了 14.5%,而生成任务的绝对提升则达到了 17.9%。这些结果表明, SELF-GUIDE 在指导 LLM 向任务特定专业化方向发展方面具有显著效果,即使在数据极其有限的情况下。这突显了自我生成数据在大规模适应 LLM 到特定任务中的潜力。更多实验结果和消融实验请参考论文原文。
图 4:对于每类任务(分类和生成任务),研究者将任务随机分成两半,一半用于调试 “One Parameter Fits All” 策略的参数,另一半用于使用这些调试好的参数测试 SELF-GUIDE 的性能。我们使用相同的解码参数和提示模板来评估模型在 SELF-GUIDE 前后的表现。
总结
SELF-GUIDE 框架鼓励模型自主生成训练数据并在此数据上进行微调。实验结果表明,这种方法在提升大规模语言模型特定任务的专业能力方面具有巨大潜力,尤其是在数据有限的情况下,SELF-GUIDE 可以有效解决缺少训练数据的问题。同时,这也为探索自主模型适应和持续学习的技术提供了参考。研究者希望这一工作能够推动 AI 系统在自主对齐和改进机制方面的发展,使其更加符合人类的意图。
#无人车大战打响
美国萝卜日爆8000单破纪录,中美对决已到关键转折点
中美「萝卜赛跑」,已进入历史转折点!美国旧金山的日均无人车服务单量,已经超越出租车,洋萝卜来势汹汹,中国无人驾驶的巨大市场岂能拱手让人?这场中美之战,已经是箭在弦上,不得不发了。
就在刚刚,数据显示:自动驾驶汽车Waymo 8月份在旧金山的日均服务单量已超8800单,远超同期的出租车工作日日均6307单。
工作日出租车平均单量(旧金山交通管理局)
这一历史性的转折时刻,意味着美国自动驾驶发展已经达到了新的里程碑——传统出行方式,已被自动驾驶的入场彻底变革。
这也标志着美国市场无人车接受度,达到了前所未有的高度。
这也会进一步坚定资本市场和政策层面对自动驾驶的看好——
市场认可带来的连锁式效应下,投资机构将更坚定加码自动驾驶领域,各企业都将获得更多资金,用于技术研发、测试和规模化生产;政策上,相关法规也会加快完善,为企业提供更宽松、开放的环境。
双重推动力下,美国的自动驾驶技术将快速迭代、保持全球领先。
同时,这一事件也再次将全球人工智能的竞争推向高潮,在自动驾驶领域,中美两国正在进入决胜时刻!
这场「输不起的战役」,如今已经分秒必争抢。全球竞争格局,已经愈发白热化。
这是因为,「洋萝卜」们已经悄悄开始围追堵截了。
全球人工智能决战自动驾驶
今年3月起,Waymo在旧金山半岛扩大了服务范围。紧接着6月再次获批,在旧金山全域开放无人驾驶出行服务。
出人意料的是,其服务规模快速增长,单量半年内翻三番,从每周5万直接飙升至每周15万单。

与此同时,通用旗下Cruise宣布,将在今年晚些时候恢复全无人驾驶服务,计划2025年初重启收费服务。
这也是美国今年,针对Cruise的第二次政策松动。4月Cruise获批在亚利桑那州凤凰城以少量人类驾驶车辆恢复运营。
到了9月,Waymo正式官宣与Uber合作,推动无人车队大规模落地,加速商业化布局。
不仅如此,谷歌母公司Alphabet还在加大对Waymo投资,为进一步扩张,研发自动驾驶技术注入新的动力。
就在半个月前,这家公司刚宣布完成56亿美元的C轮超额认购融资,这也是Waymo迄今为止筹集的最大一轮融资。
目前,估值超450亿美金。
若说美国自动驾驶领域十月大事件,便是马斯克官宣推出无人驾驶出租车CyberCab。
他在Q3财报电话会议中透露,已面向内部员工开启了CyberCab的测试,有望在明年正式开启服务。
而且,CyberCab将在2026年实现大规模量产,年产量有望达200万,最终增至400万辆。
而且,在那场We,Robot会上,特斯拉还首次演示了旗下包括Model Y、Model S等所有车型,未来都将配备全自动驾驶的能力。
也就意味着,未来的私家车,也可以上路接单。
这一步步举措,可以预见的是,一旦特斯拉无人出租车投入使用,在全球扩张的速度不容小觑。
「洋萝卜」来了,蛋糕谁能吃?
因为综合了人工智能、通信、半导体、汽车等多项技术,并且涉及产业链长、价值创造空间巨大,自动驾驶已经成为各国汽车产业与科技产业跨界、竞合的必争之地。
纵观全球,美国已经为自动驾驶大开绿灯,科技巨头间合纵连横,纷纷加码布局。
德国、日本、英国等多个传统汽车制造商,也已下场无人驾驶。从国家战略层面上,他们就立法动作不断,希望通过抢占「制度高地」发展先机。
而在国内,无人驾驶出租车市场如今仍是一片蓝海。
这块蛋糕我们自己不去吃,自然会有谷歌、特斯拉这类「洋萝卜」去吃。
全球自动驾驶出租车市场规模在2024年约为27.7亿美元,预计到2034年将达到约1889.1亿美元,年复合增长率60.03%
随着「洋萝卜」前后夹击,全球人工智能已经到了决出生死的关键时刻,在自动驾驶全球竞争的最前沿战场,萝卜快跑就是「萝卜抢跑」。
全球自动驾驶企业数量最多的两个国家是哪两个?答案就是中国和美国。
谁能率先跑通、建起产业链,谁就能定义赛道、向其他国家输出技术产品。
谁先抢占先机,谁就能占据主动权。
其实,全球自动驾驶行业的爆发,离不开人工智能和大模型技术的应用和推动。
这是因为,自动驾驶是视觉大模型重构物理世界的典型应用。
而这背后,必然是一场事关钱袋子的比拼。
比如,特斯拉今年就会投资100亿美元用于AI的训练和推理,推理主要用于汽车。
马斯克甚至还有这样一句名言:任何支出达不到每年100亿美元水平或者无法高效部署的公司,都无法在市场上竞争。
现在,全球顶尖科技公司都在加大AI领域的投资和布局,国内岂能输掉先机?
好在,国内玩家中,已经有一位「上桌」了!
没错,它就是百度旗下的萝卜快跑。
1天1万单,「土萝卜」正成为通勤首选
凭着对行业异常敏锐的嗅觉,百度自2013年,就一直在坚持压强式、马拉松式的研发投入,在人工智能和自动驾驶领域累计研发投入近1700亿元。
也是因为这多年的积累,让萝卜快跑成为国内唯一一家能够做到规模化、常态化测试的企业。
从技术创新到落地应用,萝卜快跑正打造中国自动驾驶领域的新标杆。
截至目前,萝卜快跑已覆盖全国10+个城市,并在多个城市提供了无人驾驶出行服务。
最新Q2财报交出了最亮眼的成绩单:1天1万单,累计服务超700万次!不仅如此,单季度订单创新高,增速依旧加快。
土萝卜能够取得里程碑成就,是十年磨一剑的结果。在人工智能和自动驾驶超1700亿元的投入,已经转化为实实在在的技术优势:
2022年,率先发布无方向盘的无人驾驶汽车。
2023年10月,正式宣布用大模型重构自动驾驶。
5月,发布全球首个支持L4级自动驾驶大模型Apollo ADFM(Auto-Driving Foundation Model),率先实现大模型在自动驾驶领域技术应用突破。
Apollo ADFM能够做到同时兼顾技术安全性、泛化性,安全性超越人类驾驶员10倍以上,实现城市级全域复杂场景全覆盖。
不仅如此,百度累计获5000+自动驾驶专利,高级别自动驾驶专利数量全球居首。萝卜快跑始终将「安全」放在首位,截止今年6月,在超1亿公里实际道路测试里程中,实现0重大伤亡事故。
而且,每辆无人车/乘客配备保额500万元保险。另有过去两年数据显示,实际车辆出险率仅为人类司机1/14。
据称,百度即将面向全球用户,发布Apollo自动驾驶开放平台10.0版本,将搭载自动驾驶大模型ADFM。
可见,不论在技术投入,还是研发层面,萝卜快跑有信心、有实力,与Waymo、特斯拉等外企全面比拼,甚至毫不逊色。
虽已拿下10城,但随之而来的问题是,萝卜快跑如何能在全国大范围铺开?
时间紧迫,急需突破卡脖子困境
与洛杉矶和旧金山半岛允许Waymo全区域全天候商业化运营不同,我国大部分核心城市对Robotaxi的开放力度仍显不足——多为限定区域和时段的小范围应用。
不知不觉间,中外自动驾驶的差距可能就会这样拉开。
因此,如今的时间已经很紧迫,我们必须在政策上迎头赶上。
其实早在今年两会期间,就有多位代表委员呼吁,鼓励地方先行先试,在深圳、北京、上海等地对自动驾驶大力支持,探索更大范围、更广空间和更多场景应用。
显然大家都已看出,今日中外自动驾驶的竞争,不但包括技术竞争,比拼的也是政策创新,以及政府支持企业的决心。
汽车产业规模大、先进技术集成度高、产业关联度强,已经是美国、中国、日本、德国等制造大国的重要支柱产业。
而颠覆性技术无人驾驶,则直接关乎各国汽车产业的国际竞争力和全球产业分工格局。
现在,美国在联邦和州政府层面已经发布了一系列法规,逐步对自动驾驶向更高等级发展进行松绑。
英国《自动驾驶汽车法案》还获得了王室批准,为自动驾驶产业在英国的发展建立了全套的法律框架。
而在我国,只有政策更进一步开放,才能支持萝卜快跑等无人驾驶企业的发展,以实现我国无人驾驶在国际赛场上的领跑。
虽然我国已经将自动驾驶作为新型产业发展的重点领域,工信部等相关部委也出台了一系列相关发展战略、规划和标准,但政策体系仍然亟待完善。
如果想要进一步发展,就亟须在各部门、各地方现有政策法规基础上,加强国家层面立法顶层设计,抓住当前《道路交通安全法》修订契机,加快法律文件出台,为自动驾驶构建完善的协同支持和监管体系。
唯有扎实推进行业规范和地方立法,才能促进无人驾驶车辆早日实现规模化落地应用。
技术创新是就业的敌人?Never
在萝卜快跑刚刚试运行时,坊间也有一些不一样的声音。
但其实,技术创业从来都不是就业的敌人。
纵观历史上每一次技术革命,最终都会催生新的就业岗位,为更多的人带去就业机会。
的确,自动驾驶的普及,会在一定程度上减少对传统驾驶员,如出租车司机、货运司机的需求。
然而,这种替代并非意味着岗位的消失,而会推动就业结构升级,同时带来无数新的机遇。
比如,无人驾驶技术带动了传感器制造、算法研发、系统集成等产业的发展,势必会催生大量新的就业机会。
形成高质量的数字产业集群后,自动驾驶这个全新业态,应用场景还有诸多想象空间。
招聘平台数据已经显示,自动驾驶产业的招聘需求在逐年攀升,已成为就业市场的新热点。
近期人力资源和社会保障部就发布了公示,拟增加智能网联汽车测试员等19个新兴职业纳入职业目录。
老司机新身份:主驾安全员、跑路测试员
同时急缺的,还有人工智能数据标注师这类岗位。
据估计,在中国已有数以百万计的「人工智能数据标注师」,有望成为新劳动力蓄水池。
另外,自动驾驶行业也在大量招聘安全员,职责包括数据跟踪与采集、问题记录与反馈、紧急情况处理等。
不仅仅是萝卜快跑,多个招聘平台信息显示,自动驾驶安全员已经成为小马智行、文远知行、小米汽车、滴滴等多家企业的热招岗位。
在不远的将来,自动驾驶将成为对GDP拉动最大的创新技术之一。
作为新质生产力的典型代表,自动驾驶的应用前景令人期待。
更为重要的是,它还能推动就业结构的深刻变革,促进劳动力市场的深刻转型。
而且,自动驾驶也是推动传统实体经济转型升级的新兴科技力量。
从智慧物流到无人配送,我们的生活毫无疑问已经被这项技术重塑。
而从国际层面看,自动驾驶赢,才能代表着人工智能赢,才能不面临卡脖子的局面!
当下,我们正站着一个关键的历史节点。自动驾驶不仅仅是一场技术革命,更是一场重塑未来生产力的革命。
在这场没有硝烟的竞争中,中国更不会缺席。
面对Waywo、特斯拉等「洋萝卜」的奋起直追,中国「土萝卜」还需要跑得更快,飞得更高。
参考资料:
https://www.sfmta.com/reports/average-weekday-taxi-trips
#序列并行4,Megatron Context Parallel
图解大模型训练系列
本文详细解释了Megatron Context Parallelism(CP)的工作原理和实践方法。
在序列并行系列中,我们将详细介绍下面四种常用的框架/方法:
1.Megatron Sequence Parallelism:本质是想通过降低单卡激活值大小的方式,尽可能多保存激活值,少做重计算,以此提升整体训练速度,一般和它家的tp配套使用。
2.DeepSpeed Ulysses:我们知道ds家的zero是模型并行的形式,数据并行的本质。在这个情况下,单张卡是完整地做一条序列的MHA过程的,序列长度较长时,就会对单卡显存产生压力。所以Ulysses的解决办法是,让单张卡只算全部seq的某个/某些head的结果,具体实践起来就是先通过按seq维度切割卡的输入,再通过all2all通讯来做。
3.Ring Attention:相当于分布式的Flash Attention V2(我个人的理解),它最终的效果是让每张卡只算自己所维护的那部分seq_chunk的MHA。
4.Megatron Context Parallelism:可以看成是增强版的sp,引入了类ring-attention的技术(在tp-pp-dp rank相同的位置做ring-attention),联合Megatron的各种混合并行方式进行训练。
今天,我们来讲最后一部分Megatron Context Parallelism,把它放在最后的原因是:
Megatron cp可以看成是在保持megatron sp混合并行框架的基础上,引入cp维度的并行。而cp并行的本质其实是做attention部分的优化。所以你可以把megatron sp混合并行理解成整体框架,cp理解成局部优化。
Megatron cp在实践上和朴素的ring attention非常相似,但是它做了计算上的负载均衡处理,我们在本文中会详细讲解这一点。
Megatron cp也有尝试做deepspeed ulysses + ring attention的结合,这一点也写在cp的核心逻辑中,但这不是本文讲解的重点。
综合来看,本文要讲解的重点是megatron tp + cp + dp + pp的混合并行,同时重点关注纯cp部分的实践方法。
关于megatron cp,算是一个比较新的还在持续发展的项目,目前官方没有给出具体的论文,只有一个很简短的官网介绍(https://docs.nvidia.com/megatron-core/developer-guide/latest/api-guide/context_parallel.html),从官网介绍中我们可以大致理解上面说的“在保持megatron sp混合并行框架的基础上,引入cp维度并行”的大致含义。但是这篇文章真得太短了(苦笑),所以cp的细节只能从源码层面来解读。(然而,请让我再次吐槽一次😢😢,cp的实践横跨了megatron-lm和TranformerEngine两个仓库,代码真得写得太冗余、太杂、太混乱了...所以这真是一篇暗含泪水的解读)。
虽然是从源码的阅读中推测出了cp的核心技术,但是本文不打算写成一篇源码解读的文章。本文将把源码运作流程抽象成一张张具体的图例,来说明cp主要做了什么事,在每一节的最后配上相关的代码链接,大家可以配合着图例自行阅读。如此一来,尽量让这篇文章变成纯原理式的文章,不让大家被冗长的代码分心。
一、分布式环境初始化

首先,我们来看在引入cp的前提下,megatron是如何做混合并行的,具体情况如下:
- tp = 2, cp = 2, dp = 2, pp = 2。那么有num_gpu = tp * cp * dp * pp = 2_2_2*2 = 16。也就是我们需要16张卡。假设我们的一台机器内有8张卡,则我们需要2台机器。
- 我们不考虑ep维度(即ep=1),因为本质上它不影响cp维度的并行(cp维度是对attention做优化,ep可以理解成是mlp层的操作)
- 在考虑如何设置并行group时,我们采用的顺序是tp-cp-ep-dp-pp,我们认为越靠前的并行组,通讯量越大,所以尽量安排在一台机器内。例如对于tp group,它的每一个sub-tp group关联的2张卡都位于同一台机器中。tp-cp-ep-dp-pp是megatron代码默认的顺序,我们当然可以根据实际情况做修改,但前提就是要考虑通讯量。
- 由于dp=2,所以我们假设有2个micro-batch,分别是batch0和batch1。由于cp=2,每个batch都被从seq维度上切成两份。
在这些前置条件下,我们绘制出了上面的分布式配置图片,我们以gpu0为例:
- 首先,对于一个模型,它沿着layer层被横向切成2份(pp=2),沿着权重被纵向切成2份(tp=2)。对应到我们的图里,就是4个不同颜色的色块组成一个完整的模型。
- 对于gpu0来说,[0,1,8,9]组成了一个mp group,拥有一个完整的模型
- 对于gpu0来说,[0,1]组成了tp组,这意味着0和1将吃相同的输入X,然后分别计算X的不同head的结果
- 对于gpu0来说,[0,8]组成了pp组,这意味着0和8之间会做层间激活值的传递
- 对于gpu0来说,[0,2]组成了cp组,0和2上维护着相同的模型权重,但是分别维护着同一个batch的seq_chunk0,seq_chunk1
- 对于gpu0来说,[0,4]组成了dp组,0和4上维护着相同的模型权重,但是分别维护着不同batch的seq_chunk0。
总结来看,引入megatron cp,其实就是:
- 我们先假设不对输入X做任何序列维度的切分,这时我们就得到了原始的megatron tp-dp-pp组。
- 现在引入cp,意味着我们要把输入X切分成cp_size份,所以我们只需要把原始的tp-dp-pp组拷贝cp_size份,就得到了最终的分布式配置。
- 所以我们在前文中才说,相同的tp-dp-pp rank位置就是新的cp组。例如图中所展示的tp-dp-pp group中,0和2都是各自group内的local rank = 0的元素,所以他们组成一个的cp组;1和3都是各自group内local rank = 1的元素,所以他们组成一个cp组,以此类推。
好,现在我们已经知道了如下内容:
- cp组的设置方式
- 同一个cp_group内的各张卡维护着:【相同的模型权重】、【相同batch的不同seq_chunk】
- 一个cp组的最终目标是:通过类ring attention的方式,计算出自己所维护的这个seq_chunk在自己所负责的这个head上的结果。
所以接下来,我们马上来看计算细节。分布式初始化的代码在https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/core/parallel_state.py中,大家可以配合上述讲解自行阅读。
二、负载均衡的Ring Attention2.1 朴素Ring Attention

如上图所示,我们在ring attention篇中讲过一个朴素ring attention的运作流程:
- 每张卡上固定维护着某个seq_chunk的Q
- 每张卡上轮转不同seq_chunk的KV值
- 每张卡上,Q和当前轮转到的(K, V)数据做attention计算,然后通过类似Flash Attention V2的方式更新output(细节这里不赘述,大家可以去看上面链接中的文章)
- 当所有的KV值轮转完毕后,每张卡上就得到了最终的output。
例如以Q0为例,整个计算过程如下:

但是,朴素ring attention存在一个较大的问题:计算负载不均衡。
假设我们使用的是causal mask,也就是在attention计算对于某个token,它只和自己及之前的tokens做attn,而不关心后面的token。但是在当前ring attention的划分下:
- 对于gpu0,它维护着Q0,这也意味着后面流转过来的(K1, V1)(K2, V2)(K3, V3)都是位于它之后的tokens产出的结果,它根本不需要和它们做attn,这时gpu0的计算就被浪费了。
- 对于其余gpu也是同理。只有维护着最后一块Q分块的gpu3能在每次流转中都做好计算,没有浪费计算资源。
- 这就是我们所说的,causal mask下朴素ring attention的计算负载不均问题。
2.2 负载均衡版Ring Attention
分块attention的计算其实是和计算顺序无关的,核心是只要每次计算时我们都能拿到当前分块的output,当前未做softmax前attention score矩阵的max和sum相关信息,我们就能正常更新最终的output。(如果对这句话不太理解,可以看下上面链接里给的文章,这里不再展开了)
在理解了这一点的基础上,我们重新设计Ring Attention中每块卡上存放的seq_chunk:

如上图所示,假设cp_size = 4,也就是我们打算在4块gpu上做ring attention。
- 首先,对于原始输入数据X,我们将其切分为2*cp_size = 8块,也就是上图的0~7 chunk
- [0,7],[1, 6],[2, 5], [3, 4]分别组成4个seq_chunk,安放在gpu0~gpu3上。
- 则在ring attention下,每块gpu上计算cp_size次后,就能得到最终的output。例如对于gpu0,计算4次后,就能得到[0, 7]这两个位置最终的attention结果。
- 图中接着展示了在不同的iteration中,每块卡上的计算情况,可以发现:
- i = 0时,每张卡上都是4个小方块在做attn计算
- i = 1/2/3时,每张卡上都是3个小方块在做attn计算
- 总结来看,每个iteration中,各卡的计算量是相同的。不存在朴素ring attention上某些卡空转的情况。
同时注意到,当i = 1/2/3时,总有Q或者KV块不参与计算,如果我们用rank表示这是cp_group内的第几块gpu(例如rank=0就是上面cp_group中的第0块gpu),则对于某张卡,我们有如下规律:
- i = 0,该卡上所有的QKV块参与计算
- i <= rank时,该卡上第2个KV块不参与计算
- i > rank时,该卡上第1个Q块不参与计算
用于分配哪张卡上应该维护哪些Q块的代码在:https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/training/utils.py#L233
用于处理实际QKV计算时应该保留哪些数据块,去掉哪些数据块的代码在:https://github.com/NVIDIA/TransformerEngine/blob/main/transformer_engine/pytorch/attention.py#L1901
大家可以自行阅读
三、计算和通讯的overlap
在ring attention中我们讲解过,对于一张卡,如果我们能让它在计算attn的同时,把自己的KV发送给下一张卡,同时从上一张卡中获取新的KV,这样我们就能实现【计算】和【通讯】的并行,以此来掩盖通讯要带来的额外时间开销。
具体到代码的时间上,我们可以创建不同的cuda流(torch.cuda.Stream())来实现这一目标。对于cuda流的作用你可以简单理解成:一个cuda流中可能包含若干串行的操作,而不同的cuda流是可以并行执行的。这样,我们就可以定义一个cuda流用于计算attn,再定义一个cuda流用于做通讯。
但在megatron cp中,其实一共包含3个cuda流,我们来简单认识一下它们:
- NCCL stream:定义在cp_group内,是用于做KV发送和接收的cuda流
- Stream0和Stream1:都是用于做计算的cuda流,这两个流的作用是可以并行执行attn的计算和softmax_lse的更新。
- 也就是说,megatron cp中,除了对【计算】和【通讯】做了并行,还对计算中的【attn】和【softmax_lse更新】做了并行。
【计算】和【通讯】的并行好理解,我们现在来快速解释下【attn】和【softmax_lse更新】的并行是什么意思。
在之前的系列中,我们已经讲过ring attention更新output的方式非常近似于Flash Attention V2,所以我们贴出Flash Attention V2的fwd过程,来看下output是如何更新的:
- 图中第10行展示了每次output的更新过程
- 图中第12行是,对于一块Q,当我们轮转了所有的(K, V)后,我们使用第12行的公式对output再做一次性的更新,这才得到了这块Q最终的output。而第12行的结果,就是我们说的softmax_lse。
- 但是,另一种做法是,我们可以把第12行的结果放进第10行做,也就是对于一块Q,每轮转1次(K,V),计算attn时,我们就可以这次轮转算出的attn score矩阵算出max和sum,进而更新softmax_lse,然后用于更新本次轮转的output,这就是ring attention采用的做法,目的应该是尽量减少精度损失。至于FA2中为什么把第10行和第12行拆开做,本质是为了减少非矩阵乘法的计算量,以此提升计算速度(之前的文章讲过,这里不再赘述。)
- 所以,对于ring attention,总结来看它的每次计算都分成两块:
- 【attn:算出本次轮转的output】
- 【softmax_lse更新:基于本次轮转的结果更新softmax_lse,用于修正output】
现在我们已经基本了解【attn】和【softmax_lse更新】的定义了,那么现在我们就直接来看megatron cp中这3个cuda流的运行过程,然后来解释什么叫【attn】和【softmax_lse更新】的并行:

上图刻画了在cp_size = 4的情况下,某张卡上的流转过程,具体而言:
- i = 0时
- 切换到stream0上开始执行
- 在stream0上开启发送/接收KV数据的流程,而这个流程则实际由NCCL stream开始执行
- 在stream0上做attn计算。attn计算结束后,会得到output和softmax_lse0。由于这是i=0阶段,所以我们不用做softmax_lse的更新
- 我们要注意区分“算出softmax_lse_i"和“更新softmax_lse”的区别。
- i = 1时:
- 我们需要等待(wait)本次计算需要的KV值到位,这里我特意假设计算无法完美覆盖通讯,所以我们多了等待时间。
- 等数据到位后,我们就开启新的发送/接收KV数据的流程,这个这个流程则实际由NCCL stream执行。
- 接着我们正常做attn计算,得到本次的output和softmax_lse1。
- 同时开启stream0和stream1流程
- 在stream0流程中,我们令softmax_lse = softmax_lse0,这时我们先不做任何softmax_lse的更新。
- 在stream1流程中:
- 不难发现,此时我们在stream0和stream1中已经实现了【attn】和【softmax_lse更新】的并行,只是这里不是严格的softmax_lse更新
- i= 2时:
- 同时开启stream0和stream1流程。
- 在stream1流程中,我们开始做真正意义上的【softmax_lse更新】,即softmax_lse = correction(softmax_lse, softmax_lse1)
- 在stream0流程中,我们做【attn】计算,得到新的output和softmax_lse2。同时开启NCCL stream做数据发送
- i = 3时:
- 同时开启stream0和stream1流程。
- 在stream0流程中,我们做【softmax_lse更新】,即softmax_lse = correction(softmax_lse, softmax_lse2)
- 在stream1流程中,我们做【attn】计算,得到新的output和softmax_lse3。此时我们已经无需再做数据通讯了,因为这是最后一轮流转。
- i = 4时:
- 只需要启动stream1,做最后一次【softmax_lse更新】,即softmax_lse = correction(softmax_lse, softmax_lse3)即可。
这张通讯图我们还做了一些简化,例如当我们每次做【softmax_lse更新】时,我们都需要保证上一次更新的结果已经计算完毕,所以这里可能也是需要做wait的,为了表达简便,这边略去。
本节以及整个cp核心代码在https://github.com/NVIDIA/TransformerEngine/blob/main/transformer_engine/pytorch/attention.py#L1867中,大家可以配合上面的图例更好阅读代码。
#OpenAI安全副总裁、北大校友Lilian Weng宣布离职
翁荔的技术博客深入、细致,具有前瞻性,被很多 AI 研究者视为重要的参考资料。如今,她离开了 OpenAI,开启新的征程。而且她表示,之后可能有更多时间频繁更新博客。
自从 Sam Altman 重新执掌 OpenAI 以来,该公司就陷入了持续不断的高管离职潮中。虽然近段时间有些外部新高管加入,但很显然这个离职潮仍未结束。
就在刚刚,OpenAI 安全系统团队负责人翁荔(Lilian Weng)在 X 上宣布将离开已经工作了近 7 年的 OpenAI。同时,她还公开分享了发给团队的离职信,不过其中并未明确说明她接下来的职业计划。
推文发布后,OpenAI 内外的一些知名人士为其送上了祝福,包括著名研究科学家 Noam Brown、OpenAI 首席信息安全官 Dane Stuckey、思维链提出者 Jason Wei 等等。
当然,许多网友也纷纷送上了自己的祝福,毕竟她不仅在 OpenAI 推动了安全相关的研究和实践,偶尔更新的博客 Lil’Log 也实实在在地帮助了很多人。
Lilian Weng 博客地址:https://lilianweng.github.io/
以下是她与团队分享的离职信的中文版:
亲爱的朋友们,
我做出了离开 OpenAl 的艰难决定。11 月 15 日将是我在办公室的最后一天。
OpenAl 是我成长为科学家和团队领导者的地方,我将永远珍惜与我一路共事和结交的朋友在一起的时光。OpenAl 团队一直是我的知己、老师,也是我身份认同的一部分。
我还记得 2017 年 OpenAl 的使命让我多么着迷,一群人梦想着一个不可能实现的科幻未来。在这里,我一开始研究的是全栈机器人难题 —— 从深度强化学习算法到感知再到固件 —— 目标是教会单台机械手如何解决魔方问题。整个团队花了两年时间,但我们最终做到了。
当 OpenAl 进入 GPT 范式,我们开始探索将最佳 AI 模型部署到现实世界的方法时,我组建了第一个应用研究(Applied Research)团队,推出了微调 APl、嵌入 APl 和审核端点的初始版本,为应用安全工作奠定了基础,并为许多早期 API 客户提供了新的解决方案。
GPT-4 发布后,我被要求接受一项新挑战,重新考虑 OpenAl 安全系统的愿景,并将工作集中在一个拥有完整安全椎栈的团队之下。那是我曾做过的最困难、压力最大又最激动人心的事情之一。现在,安全系统(Satety Systems)团队有超过 80 位出色的科学家、工程师、产品经理、政策专家,而且我为我们作为一个团队所取得的一切成就感到非常自豪。我们一起成为了每次发布的基石 —— 从 GPT-4 及其视觉和 turbo 版本到 GPT Store、语音功能和 o1。我们在训练这些模型使其既强大又负责任方面所做的工作为行业树立了新的标准。我为我们在 o1-preview 模型方面取得的最新成就感到特别自豪,它是我们迄今为止最安全的模型,在保持其实用性的同时,表现出对越狱攻击的卓越抵抗力。
我们一起取得了令人瞩目的成就:
- 我们训练模型使其明白,通过遵循一套定义明确的模型安全行为政策,可以让其很好地拒绝敏感或不安全的请求,包括何时拒绝或不拒绝,从而在安全性和实用性之间取得良好的平衡。
- 在每次模型发布时,我们都提高了其对抗稳健性,包括防御越狱攻击、指令层次结构以及通过推理大幅提升稳健性。我们在透明度方面的承诺都已体现在我们详细的模型系统卡中。
- 我们开发了业界领先的具有多模态能力的审核模型,并免费分享给了公众。我们目前在更通用的监控框架和增强的安全推理能力方面的工作将为更多的安全工作流提供支持。
- 我们为安全数据记录、指标、仪表板、主动学习管道、分类器部署、推理时间过滤和全新的快速响应系统建立了工程开发基础。
回顾我们所取得的成就,我为安全系统团队的每个人都感到骄傲,我非常有信心团队将继续蓬勃发展。我爱你们❤️。
现在,在 OpenAl 工作了 7 年后,我准备重新开始并探索一些新东西。OpenAl 正处于火箭般的增长轨迹上,我只希望这里的每个人都一切顺利。
附言:我的博客还在,会继续下去。我可能很快就会有时间更频繁地更新它,也可能会有更多时间来编程;)
爱你们的,
Lilian
Lilian Weng 介绍
Lilian Weng 是 OpenAI 华人科学家,她 2018 年加入 OpenAI,参与了 GPT-4 项目的预训练、强化学习 & 对齐、模型安全等方面的工作。她本科毕业于北大,曾前往香港大学进行短期交流,博士毕业于印第安纳大学伯明顿分校。
根据领英资料显示,Lilian Weng 在 OpenAI 已经工作了近 7 年时间,担任安全研究副总裁一职。
2021 年 - 2023 年工作期间,Lilian Weng 建立并领导了应用人工智能研究团队,包括产品研究、合作伙伴研究和应用安全,从而使得 OpenAI 的 API 更强大、更实用、更安全。
之前,她还是 OpenAI 机器人团队的技术主管,专注于训练关于机器人任务的算法,如教机械手如何解决魔方、旋转方块等。
在加入 OpenAI 之前,她还在 Facebook、Dropbox 从事软件工程和数据科学方面的工作。
Google Scholar 显示,Lilian Weng 论文引用量超过 13000 多次。
闲暇时间,Lilian Weng 还写了一些关于 AI 的博客文章,她的博客深入、细致,具有前瞻性,被很多 AI 研究者视为重要的参考资料(见文末「扩展阅读」)。感兴趣的读者可以前去阅读。
#AI有鼻子了,还能远程传输气味,图像生成香水
最近,一个名叫 Osmo 的初创公司宣布,他们成功地将气味数字化了。第一个成功的案例是「新鲜的夏季李子」,而且复现出的味道「闻起来」很不错。整个过程依靠 AI 技术来完成,不需要人工干预。有了这项技术,你就可以像下载音乐一样下载香水了。
这个发帖的 Alex Wiltschko 是 Osmo 的 CEO 和联合创始人。「将气味数字化」进而「生成气味」最初只是他在谷歌工作期间的一个研究项目。但在 2022 年,他在 Lux Capital 和谷歌风投的支持下,将其作为一家独立的初创公司推出。
「我一直热衷于了解气味。它是一种非常强大的情绪感官,但我们对它却知之甚少」Wiltschko 在接受 CNBC 采访时说。
在复刻出李子的香味后,Wiltschko 非常激动,「带着这个香味去了很多地方」。
至于这项研究的用途,Osmo 的官方说法是「改善人类的健康和幸福」,因为嗅觉数字化对帮助医疗人员检测、治疗疾病至关重要。比如,医生可以用气味来触发患者记忆或减轻焦虑。
此外,它还有可能在 VR 游戏、电影中发挥作用,增加 VR 设备的沉浸感。
或者,你还可以用这项技术来留住亲人的气味,但「按月付费」就有点讽刺了。
当然,这些都是长期愿景。在近期,Wiltschko 希望 Osmo 能制造出更安全、更可持续的香味分子,用于香水、洗发水、驱虫剂和洗衣粉等日常用品中的香料。
,时长00:59
用数千个香气分子训练 AI 模型
Osmo 的官网上简单列出了他们的研发历史:
0. 在 Osmo 建立之前,Alex Wiltschko 在谷歌研究院领导着这个团队,他们使用先进的机器学习技术构建了 Osmo 气味映射图的基础。
1. 取得了一项重大突破,可使用图神经网络根据分子结构预测其气味。
2. 创造了以前从未闻过的新分子并以超越人类的准确度进行了预测。
3. 设计出了蚊子觉得难闻的气味分子(例如驱虫剂),并且在人体试验中比避蚊胺(DEET)更有效。

而要更具体地了解 Osmo 的研发历程,我们还要从 Wiltschko 的早期经历说起。
Wiltschko 2009 年在密歇根大学获得了神经科学学士学位,并在哈佛大学学习嗅觉神经科学,于 2016 年获得博士学位。
第二年,他成为谷歌研究院的一名研究科学家,在那里,他花了五年时间领导一个团队,利用机器学习帮助计算机根据分子结构预测不同分子的气味,并使用机器学习软件开发了 「主要气味映射图(principal odor map/POM)」。
这项研究发表在 2023 年 9 月的《科学》杂志上。据介绍,POM 坐标可以用于预测气味强度和感知相似性,即使这些感知特征并非模型训练的显式组成部分。这些结果已被用于构建多种嗅觉预测模型 —— 即使没有微调,其表现也优于以前的特征集。

来自 Science
为了构建这个气味地图,他的团队在一个包含 5000 个芳香分子的数据集上训练他们的 AI 模型,这些芳香分子涵盖了各种气味类别,如花香、果香或薄荷味。
Wiltschko 发现,由于分子结构复杂,计算机在分析分子时可能会比较棘手 —— 只要移动一个分子键,分子的气味就可能从玫瑰变成臭鸡蛋。
但得益于人工智能技术的进步,该模型能够捕捉到分子不同结构中的模式,并利用这些知识准确预测其他分子的气味。
值得一提的是,用来训练模型的数据集确实来之不易。
Wiltschko 说,大型语言模型可以通过「整个互联网」的数据进行训练,但当他们开始构建人工智能模型时,还没有类似的气味信息数字图书馆。
所以,他们花了大约一年的时间与香水行业的公司合作。起初,他们以为这些公司会有很棒的数据集,但事实并非如此。
这促使 Wiltschko 和他的团队创建了「一种新的数据」。
为此,他们收集了数千种分子以及调香大师对其气味的描述。然后,他们将这些数据输入图神经网络(GNN),该网络属于机器学习的范畴,使用强大的算法来检测和分析数据点之间的关系。
Wiltschko 说,他的团队可以使用 GNN 来帮助 AI 模型理解原子、连接它们的键以及分子结构如何决定其气味。
气味数字化大有用途
气味数字化可以开拓出前所未有的应用场景,最基础的就是气味的远程传输。Wiltschko 表示,Osmo 希望最终能够利用自己的技术,将一个地方的气味数字化,然后在另一个地方再造一个完全相同的副本,从而实现气味的远程传送。
事实上,该公司最新更新的博客表示,他们已经成功了。

具体来说,选择一种要传输的气味,并将其放入一台 GCMS(气相色谱 - 质谱)机。如果该气味的来源是液体,就直接注入;如果是固体样品(比如李子),就使用顶空分析,也就是将气味困在物体周围的空气中,并通过管子吸收。
GCMS 会识别原始数据(可以视为分子),并将其上传到云。在那里,它会成为主要气味映射图上的坐标 —— 这是一种新颖、先进的人工智能驱动工具,可以预测特定分子组合的气味。
然后,这个配方会被发送到一台配方机器人,它会基于该配方来混合不同的气味,从而复现样品的气味。
在另一项成果展示中,Osmo 表示他们使用 AI 发现了前所未「嗅」的配方,并且他们一口气向欧美市场发布了三种前有未有的香水气味分子。他们将之分别命名为 Glossine、Fractaline、Quasarine。他们还为这三种香水气味编写了美妙的描述。举个例子,对于 Glossine,他们写到:「一种充满活力的花香,让人联想到茉莉花,后调和中调散发出耀眼的亮泽。这种迷人的分子可为之前的任何香水增添耀眼的拉斯维加斯式光彩。」
此外,Osmo 也在研究多模态 AI,具体来说,他们研究的是基于图像生成对应的气味,当然图像又可以进一步基于文本而生成。下面演示了一个案例:

可以看到,用户只需输入文本提示词,AI 就会帮助你生成图像(用户也可直接上传图像),然后再进一步为你生成分子配方。当然,如果你还想亲身闻到这些气味,还需要相应的设备。
事实上,他们已经在线发布了这款工具 Inspire,目前支持文本和图像输入,但他们也表示未来还会支持音乐、PDF、幻灯片和视频输入。感兴趣的读者可以注册尝试一下:https://inspire.osmo.ai/landing
这项技术背后彰显着无限的可能性。举个最明显的例子,也许未来我们还能观看带有气味的电影,实现视觉、听觉和嗅觉的全方位体验 —— 这或许能给那些风景如花的电影变得更加好看以及好闻。
这个节目看起来一定很香
最后,Wiltschko 表示 Osmo 还有一项长期目标,即利用这项技术帮助更早地识别疾病。也许未来,我们在体检时会有一个 AI 通过它的机器鼻子来判断我们的健康状况。
参考链接:
https://www.cnbc.com/2024/08/18/former-google-researchers-startup-uses-ai-to-digitize-smell.html
https://www.science.org/doi/10.1126/science.ade4401
#为什么Qwen能自我改进推理,Llama却不行?
斯坦福找到了原理
虽然 Qwen「天生」就会检查自己的答案并修正错误。但找到原理之后,我们也能让 Llama 学会自我改进。
给到额外的计算资源和「思考」时间,为什么有的模型能好好利用,把性能提升一大截,而有的模型就不行?
当遇到困难问题时,人类会花时间深入思考以找到解决方案。在 AI 领域,最近的一些大语言模型在通过强化学习进行自我改进训练时,也已经开始表现出类似的推理行为。
但是,在同样的强化学习训练下,不同模型自我改进的能力却存在很大差异。比如在一个游戏中,Qwen-2.5-3B 的自我改进能力远远超过 Llama-3.2-3B(两个模型初始都很差,但强化学习训练结束后,Qwen 达到约 60% 的准确率,Llama 只有 30%)。这是什么原因?
在最近斯坦福大学提交的一项工作中,大模型自我改进能力背后的机制被挖掘了出来。该研究重点关注的是基础语言模型中关键的认知行为的存在。
- 论文标题:Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
- 论文链接:https://arxiv.org/abs/2503.01307
这项研究一发布就引来众多讨论,比如 Synth Labs CEO 认为这个发现非常激动人心,因为其可被整合进任何模型中!

作者将研究重点放在两个基础模型 ——Qwen-2.5-3B 和 Llama-3.2-3B 上,当使用强化学习对 Countdown 游戏进行训练时,它们之间显示出明显的差异 ——Qwen 解决问题的能力大幅提高,Llama2 在相同的训练过程中却提升有限。语言模型的哪些属性带来了这种不同?
为了系统地研究这个问题,作者开发了一个框架来分析对解决问题有用的认知行为,其中描述了四种关键的认知行为:验证(系统错误检查)、回溯(放弃失败的方法)、子目标设定(将问题分解为可管理的步骤)和逆向思考(从期望结果推理到初始输入)。这些行为反映了专家级问题解决者处理困难任务的方式 —— 数学家会验证证明的每个步骤、遇到矛盾时回溯以及将复杂定理分解为更简单的引理。

初步分析表明,Qwen 自然地表现出了这些推理行为,特别是验证和回溯,而 Llama 则缺乏这些行为。从这些观察中作者得出了核心假设:初始策略中的某些推理行为对于通过扩展推理序列有效利用增加的测试时间计算(test-time compute)是必不可少的。也就是说,AI 模型要想在有更多时间思考时真正变得更聪明,必须先具备一些基本的思考能力(比如检查错误、验证结果的习惯)。如果模型一开始就不会这些基本思考方法,即使给它再多的思考时间和计算资源,它也无法有效利用这些资源来提高自己的表现。这就像人类学习一样 —— 如果一个学生不具备基本的自我检查和纠错能力,单纯给他更多的考试时间也不会让他的成绩有显著提高。
研究人员又通过对初始模型进行干预来检验这一假设。
首先,他们发现,通过用包含这些行为(尤其是回溯)的人工合成推理轨迹对 Llama 进行引导,可以使其在强化学习过程中表现大幅改善,甚至能达到与 Qwen 相当的性能提升。其次,即使这些引导用的推理轨迹包含错误答案,只要它们展现出正确的推理模式,Llama 依然能取得进步。这表明,推理行为的存在,而不是正确答案本身,才是实现成功自我改进的关键因素。最后,他们从 OpenWebMath 数据集中筛选出强调这些推理行为的内容,用于对 Llama 进行预训练。结果表明,这种有针对性的预训练数据调整能够成功诱导出高效利用计算资源所需的推理行为模式 ——Llama 的性能提升轨迹与 Qwen 一致。
这项研究揭示了模型的初始推理行为与其自我改进能力之间存在紧密联系。这种联系有助于解释为什么有些语言模型能够找到有效利用额外计算资源的方法,而另一些模型则停滞不前。理解这些动态变化可能是开发能够显著提升问题解决能力的 AI 系统的关键。
如何让 AI 学会自我改进?
参与对比的模型:Qwen-2.5-3B 和 Llama-3.2-3B
研究开始于一个令人惊讶的观察结果:规模相当但来自不同家族的语言模型通过强化学习表现出差异巨大的提升能力。
Countdown 游戏作为主要测试平台 —— 这是一个数学难题,玩家必须使用四种基本算术运算(+、−、×、÷)组合一组输入数字以达到目标数字。例如,给定数字 25、30、3、4 和目标 32,玩家需要通过一系列操作将这些数字组合起来,得到精确的 32:(30 − 25 + 3) × 4。
选择 Countdown 进行分析是因为它需要数学推理、规划和搜索策略。与更复杂的领域不同,Countdown 提供了一个受限的搜索空间,使得可行的分析成为可能,同时仍然需要复杂的推理。此外,与其他数学任务相比,Countdown 游戏中的成功更依赖于问题解决能力而非数学知识。
研究者使用两个基础模型来对比不同模型家族之间的学习差异:Qwen-2.5-3B 和 Llama-3.2-3B。强化学习实验基于 VERL 库,利用 TinyZero 实现。他们使用 PPO 方法训练模型 250 步,每个提示采样 4 个轨迹。选择 PPO 而非 GRPO 和 REINFORCE 等替代方案,是因为它在各种超参数设置下表现出更优的稳定性,尽管各算法的性能非常相似。
结果揭示了截然不同的学习轨迹。尽管这两种模型在任务开始时表现相似,得分都很低,但 Qwen 在第 30 步左右表现出质的飞跃,特点是响应明显变长且准确性提高,如下图所示。到训练结束时,Qwen 达到了约 60% 的准确率,大大超过 Llama 的 30%。

在训练后期,可以观察到 Qwen 行为的一个有趣变化:模型从语言中的显式验证语句「8*35 是 280,太高了」过渡到隐式解决方案检查,模型依次尝试不同的解,直到找到正确的答案,而不使用文字来评估自己的工作。
这种对比引出了一个基本问题:哪些潜在的能力能够成功地实现基于推理的改进?要回答这个问题,需要一个系统的框架来分析认知行为。
分析认知行为的框架
为了理解这些不同的学习轨迹,研究者开发了一个框架来识别和分析模型输出中的关键行为。他们重点关注四种基本行为:
1、回溯或在检测到错误时显式修改方法(例如,「这种方法行不通,因为...」);
2、验证或系统地检查中间结果(例如,「让我们通过... 来验证这个结果」);
3、子目标设定,即将复杂问题分解为可管理的步骤(例如,「要解决这个问题,我们首先需要...」);
4、逆向思考,即在目标导向的推理问题中,从期望的结果出发,逐步向后推导,找到解决问题的路径。(例如,「要达到 75 的目标,我们需要一个能被... 整除的数字」)。
选择这些行为是因为它们代表了与语言模型中常见的线性、单调推理模式不同的问题解决策略。这些行为使更加动态、类似搜索的推理轨迹成为可能,解决方案可以非线性地演变。虽然这组行为并非详尽无遗,但选择这些行为是因为它们容易识别,并且自然地与 Countdown 游戏和更广泛的数学推理任务(如证明构建)中的人类问题解决策略相一致。
每种行为都可以通过其在推理 token 中的模式来识别。回溯被视为显式否定并替换先前步骤的 token 序列,验证产生将结果与解决方案标准进行比较的 token,逆向思考从目标出发,逐步构建通往初始状态的解决方案路径的 token,而子目标设定则显式提出在通往最终目标的路径上要瞄准的中间步骤。研究者开发了一个使用 GPT-4o-mini 的分类 pipeline,可靠地识别模型输出中的这些模式。
初始行为在自我提升中的作用
将这个框架应用于初始实验揭示了一个关键洞察:Qwen 的显著性能改进与认知行为的出现相吻合,特别是验证和回溯(图 1(中))。相比之下,Llama 在整个训练过程中几乎没有表现出这些行为的证据。

为了更好地理解这种差异,研究者分析了三个模型的基线推理模式:Qwen-2.5-3B、Llama-3.2-3B 和 Llama-3.1-70B。分析揭示,与两种 Llama 变体相比,Qwen-2.5-3B 产生各种行为的比例都要更高(图 4)。尽管较大的 Llama-3.1-70B 在这些行为的激活频率上普遍高于 Llama-3.2-3B,但这种提升并不均衡 —— 特别是回溯行为,即便在更大的模型中,其表现仍然有限。

这些观察结果表明两个洞察:
1、初始策略中的某些认知行为可能是模型通过扩展推理序列有效利用增加的测试时间计算所必需的;
2、增加模型规模可以改善这些行为的上下文激活。这种模式尤为重要,因为强化学习只能放大成功轨迹中出现的行为 —— 使这些初始行为能力成为有效学习的先决条件。
干预初始行为
在确立了基础模型中认知行为的重要性之后,接下来研究是否可以通过有针对性的干预人为诱导这些行为。
研究者提出的假设是,通过在 RL 训练前创建选择性表现特定认知行为的基础模型变体,可以更好地理解哪些行为模式对于实现有效学习至关重要。
他们首先使用 Countdown 问题策划了七个不同的启动数据集。其中五个数据集强调不同的行为组合:所有策略组合、仅回溯、回溯与验证、回溯与子目标设定以及回溯与逆向思考。他们使用 Claude-3.5-Sonnet 生成这些数据集,利用其能够产生具有精确指定行为特征的推理轨迹的能力。
为了验证改进源于特定的认知行为而非简单的计算时间增加,研究引入了两个控制条件:一个空的思维链和一个与所有策略数据集的数据点长度匹配的填充占位符 token 的链。这些控制数据集帮助作者验证观察到的任何改进是否源于特定的认知行为,而非简单的计算时间增加。作者还创建了全策略数据集的变体,其中仅包含不正确的解决方案,同时保持所需的推理模式。此变体使作者能够将认知行为的重要性与解决方案的准确性区分开来。
当使用包含回溯行为的数据集进行初始化时,Llama 和 Qwen 都通过 RL 训练表现出明显的改进(图 2)。

行为分析表明,RL 会选择性地放大经验上有用的行为,同时抑制其他行为(图 3)。

例如,在全策略条件下(图 1(左下)),模型保留并加强回溯和验证,同时减少逆向思考和子目标设定。然而,当仅与回溯配对时,被抑制的行为(逆向思考和子目标设定)会在整个训练过程中持续存在。

当用空的思维链控制进行启动时,在两种情况下,模型的性能都与基本 Llama 模型相当(≈30-35%;见图 5),这表明仅仅分配额外的 token 而不包含认知行为无法有效利用测试时间计算。此外,使用空的思维链进行训练会产生不利影响,Qwen 模型会停止探索行为。这表明这些认知行为对于模型通过更长的推理序列有效利用扩展计算是特别必要的。

令人惊讶的是,用不正确的解决方案启动但具有正确行为的模型,与在具有正确解决方案的数据集上训练的模型具有相同的性能(图 6)。这表明认知行为存在(而不是获得正确的解决方案)是通过强化学习成功实现自我改进的关键因素。因此,来自较弱模型的推理模式可以有效地引导学习过程以构建更强大的模型,这表明认知行为的存在比结果的正确性更重要。

在预训练数据中选择性地放大行为
上述结果表明,某些认知行为对于自我完善是必要的。然而,作者在初始模型中诱导行为的启动方法是领域特定的,依赖于 Countdown 游戏。这可能会对最终推理的泛化产生不利影响。我们能否通过修改模型的预训练分布来增加有益推理行为的频率,从而实现自我完善?
为了探究预训练数据中的行为频率,作者首先分析了预训练数据中认知行为的自然频率,重点关注 OpenWebMath 和 FineMath,它们是专门为数学推理而构建的。使用 Qwen-2.5-32B 作为分类器,研究分析了 20 万份随机抽样的文档,以查找目标行为的存在。即使在这个以数学为重点的语料库中,回溯和验证等认知行为也很少出现,这表明标准预训练对这些关键模式的接触有限(见图 7)。

为了测试人为增加认知行为的接触是否会增强自我提升的潜力,作者从 OpenWebMath 开发了一个有针对性的持续预训练数据集。首先使用 Qwen-2.5-32B 作为分类器,分析来自预训练语料库的数学文档,以了解目标推理行为的存在。以此为基础人们创建了两个对比集:一个具有认知行为,另一个极少认知内容的控制集。
然后,他们使用 Qwen-2.5-32B 将集合中的每个文档重写为结构化的问答格式,保留源文档中认知行为的自然存在或缺失。最终的预训练数据集每个都包含总共 830 万 token。这种方法使作者能够隔离推理行为的影响,同时控制预训练期间数学内容的格式和数量。
在这些数据集上对 Llama-3.2-3B 进行预训练并应用强化学习后,作者能观察到:1)行为丰富模型实现了与 Qwen 相当的性能,而控制模型的改进有限(图 8a);2)对训练模型的行为分析表明,行为丰富变体在整个训练过程中保持推理行为的高激活度,而控制模型表现出与基本 Llama 模型类似的行为(图 8c)。

这些结果表明,有针对性地修改预训练数据,可以通过强化学习成功生成有效自我改进所必需的认知行为。
#Mixture-of-Memories
上海AI Lab最新推出:线性注意力也有稀疏记忆了
回顾 AGI 的爆发,从最初的 pre-training (model/data) scaling,到 post-training (SFT/RLHF) scaling,再到 reasoning (RL) scaling,找到正确的 scaling 维度始终是问题的本质。2017 年发布的 Transformer 架构沿用至今,离不开 Transformer 强大的 “无损记忆” 能力,当然也需要付出巨大的 KV 缓存代价。换句话说,Transformer 架构具有强大的 memory scaling 能力。
DeepSeek NSA 通过三种方式压缩 “KV” 实现 sparse attention,但这只是一种可以工作但不优雅的折中方案。因为它在压缩 Transfromer 的记忆能力,以换取效率。
另一方面,大概从 2023 年火到今天的线性序列建模方法(包括 linear attention 类,Mamba 系列,RWKV 系列)则是另一个极端,只维护一份固定大小 dxd 的 RNN memory state,然后加 gate,改更新规则,但这种方式始终面临较低的性能上限,所以才会有各种混合架构的同样可以工作但不优雅的折中方案。
我们认为,未来的模型架构一定具有两点特性:强大的 memory scaling 能力 + 关于序列长度的低复杂度。后者可以通过高效注意力机制实现,比如:linear 或者 sparse attention,是实现长序列建模的必备性质。而前者仍然是一个有待探索的重要课题,我们把给出的方案称为 “sparse memory”。
这促使我们设计了 MoM: Mixture-of-Memories,它让我们从目前主流线性序列建模方法改 gate 和 RNN 更新规则的套路中跳脱出来,稀疏且无限制地扩大 memory 大小。MoM 通过 router 分发 token(灵感来自 MoE)维护多个 KV memory,实现 memory 维度 scaling。每个 memory 又可以进行 RNN-style 计算,所以整体具有关于序列长度线性的训练复杂度,推理又是常数级复杂度。此外,我们又设计了 shared memory 和 local memory 合作分别处理全局和局部信息。实验表现相当惊艳,尤其是在目前 linear 类方法效果不好的 recall-instensive 任务上表现格外好,甚至在 1.3B 模型上已经和 Transformer 架构旗鼓相当。
- 论文地址:https://arxiv.org/abs/2502.13685
- 代码地址:https://github.com/OpenSparseLLMs/MoM
- 未来还会集成在:https://github.com/OpenSparseLLMs/Linear-MoE
- 模型权重开源在:https://huggingface.co/linear-moe-hub
方法细节
Linear Recurrent Memory
对于这部分内容,熟悉线性序列建模的小伙伴可以跳过了。
输入

经过 query key value proj 得到
![]()
:

最简洁的 recurrent 形式线性序列建模方法(对标最基础的 linear attention)按照下面公式做 RNN 更新:

这里,我们不得不提一下,各种各样的 Gate 形式(
![]()
前面的)和更新规则( 右边的)就是在魔改上面的一行公式,各种具体形式如下表:
(各种方法本身有不同的符号,像 Mamba, HGRN 就不用 q k v,这里为了统一对比全部对标到 linear attention 形式。其中Titans的形式,把 memory update rule 看作 optimzier update 的话,最核心的还是 SGD 形式,暂时忽略momentum/weight decay ,只一个公式表达的话写成这种梯度更新的形式是合理的。)

其实这些方法又可以进一步细分为不同类别(很多地方都粗略的统一称为 linear RNN 或者 RNN),这里论文暂时没提:
- Linear Attention, Lightning Attention, RetNet, GLA, DeltaNet, Gated DeltaNet 属于 linear attention 类
- Mamba2 属于 SSM 类,HGRN2 属于 linear RNN 类
- TTT, Titans 属于 Test-Time Training 类
Mixture-of-Memories
MoM 思路非常简单,和 MoE 一样按照 token 分发,通过 router 为每个 token 选择 topk 的 memories 并计算各自权重:

所有激活的 topk memories 按照各自权重加权求和得到一份混合记忆:

然后就又回到了 linear 类方法一贯的输出计算:

另外,这里我们额外引入了 shared memory 的概念,即每个 token 都会经过这个永远激活的 memory,有利于模型获取全局信息。相对而言,其他稀疏激活的 memory 更擅长获取局部信息。消融实验表明,shared memory 的存在对模型效果有明确的积极作用。

硬件高效实现
MoM的硬件高效Triton算子可以很方便地实现,其输出的计算可以简单写作:

也就是说 MoM 中每个 memory 的计算过程可以复用现有的单个算子,再把所有 memory 的输出加权求和起来。和直接在算子内先求和再算输出是数学等价的。
实验结果
in-context recall-instensive tasks
一直以来,线性序列建模方法因为自身非常有限的 memory 大小,在这类 in-context recall-intensive 任务上表现不好。同时 Transformer 模型得益于其强大的无损记忆能力,非常擅长这类任务。所以已经出现了各种层间 hybrid 的模型,来提升 linear 类模型在这类任务上的效果。
我们首先重点测试了这类任务(结果见下表),使用 Gated DeltaNet 作为 MoM 的 memory 计算形式(在 Memory 更新过程中,每个 memory 都使用 Gated DeltaNet 的 gate 和更新规则),总共 4 个 local sparse memory,激活 2 个,还有一个 shared memory。其中标 † 的模型来自开源项目(https://huggingface.co/fla-hub),没标 †的是我们从头预训练的模型。
结果还算相当不错,在没有数据污染或任何套路的情况下,结果显示 MoM 就是单纯地效果好。这也和预期一致,翻倍扩展 memory 大小,效果好过其他 linear 类方法。有一些意外的是,在 1.3B 的结果里,MoM 基本可以和 Transformer 相媲美。

其他评测效果
其他评测结果效果也不错:


推理效率
推理效率是线性序列建模方法的重点,结果显示 MoM 在常数级复杂度推理速度和显存占用方面,表现出强大的优势。

消融实验


Loss 曲线

#英伟达RTX 5070评测解禁
老黄承诺4090级性能?不存在的
价格低了点,功耗高了点,性能和原来差不多?

昨晚,英伟达 GeForce RTX 5070 显卡正式解禁,各种评测开始进入人们的视线。
我们知道,最近英伟达 RTX 50 系显卡的实际表现引发了不少争议,出现了核心单元丢失、供电等多种问题。在最新登场的主流型号 5070 上,会有一次反转吗?
在 1 月初 CES 2025 发布 GeForce RTX 5070 时,黄仁勋表示,得益于 AI 技术,这款显卡将能够以大约三分之一的价格,在性能上赶上此前最快消费级显卡 RTX 4090。RTX 4070 的国行价格是 4599 元,RTX 4090 的起售价为 12999 元。

老黄的说法当时令人印象深刻,事实真的如此吗?外媒 Ars Technica 等多方的评测结果可以打消这个念头了。
评测使用了 RTX 5070 Founders Edition 公版显卡。结果显示,RTX 5070 并不像 4090 那样快,除了一些无法比较的创意性表现。与 50 系列显卡的惯例一样,英伟达依靠 AI 生成的插值帧来实现其声称的大部分性能改进。
就基础性能、实际渲染速度而言,RTX 5070 甚至不如 4080 或 4070 Ti,仅比去年起售价 599 美元的 4070 Super 快一点,而且功耗高得离谱。
尽管如此,考虑到 RTX 5070 进行了 DLSS(深度学习超级采样)升级,它仍是能以最低价格获得的英伟达 4K 显卡,同时也非常适配 1440p 显示器。
下图罗列了 RTX 5070 的详细规格以及与 5070 Ti、4070 系列的参数比较:

图源:arstechnica
可以看到,RTX 5070 的 CUDA 核心数介于 RTX 4070 和 4070 Super 之间,而 RTX 5080 和 5070 Ti 都比上一代产品有小幅提升。为了提升性能,英伟达改进了 Blackwell 架构、增加了 GDDR 7 的内存带宽(33% 增幅)并提高了 GPU 时钟速度。
在内存上,RTX 5070 给到了 12GB,能够满足 1080p + 分辨率和超高质量纹理所需要的 8GB + 要求。不过,评测发现,如果想要用 RTX 5070 达到 4k 分辨率,可能会受到更多限制。
退步的方面是功耗,RTX 5070 满载时的最大功耗达到了 250 W,比 4070 Super 高出了 30 W。在能效方面,RTX 5070 系列显卡仍然远高于 3070 或 3080 等旧款显卡,但相较于 4070 系列优势不大。

(左)为 5070 Founders Edition 公版,(右)为 4070 系列。
此外,RTX 5070 在满载运行时的声音也有点大(注:体感,不是科学测量)。对于采用较小双风扇散热器设计的较小尺寸或低端 5070 显卡来说,这是一个值得关注的问题。

RTX 5070 运行时的温度要比测试的其他显卡更高,可以看到比 5090 还高了几度。图源:arstechnica
评测包含了 4k 和 1440p 两种分辨率,显然 500 美元到 600 美元价位的显卡更适合 1440p 高刷新率的游戏显示器,并尤其适合在没有 DLSS 或其他上采样技术的情况下玩游戏。
同时,如果玩的是较旧或轻度游戏,并且不介意分辨率提升,我们可以调低一些设置,在 4k 分辨率下达到每秒 60 帧通常是可能的。

图源:arstechnica
游戏性能大 PK
RTX 5070 达到预期了吗?
说完了外部体验,再来说具体性能。尽管 CUDA 核心较少,但 RTX 5070 大致还是比 4070 Super 有个位数的性能提升,并且比 4070 快约 20%—— 这可能是英伟达比较喜欢的同级比较。

4k 分辨率下《无主之地 3》的游戏性能比较。
在测试的其他游戏中,比如禁用光线追踪的「超级」模式下的「赛博朋克 2077」表现出了更大的改进 —— 性能比 4070 Super 快 24%,比 4070 快 72%。这是一个异常值。

另外,《赛博朋克 2077》在关闭 DLSS 的超速(Overdrive)模式下显示出了异常低的数字。使用最近的驱动程序测试的所有 GeForce 卡都存在低帧率和奇怪的视觉伪影。

如果和 AMD 的显卡进行横向对比,我们目前还不能将 5070 与 RX 9070 系列直接进行比较。但值得注意的是,在没有光线追踪效果的基准测试(1440p)中,5070 的表现略优于旧款 RX 7900 GRE(光线追踪游戏中的差距更大,因为 AMD 在这些游戏中通常存在性能缺陷)。
AMD 表示,售价 549 美元的 RX 9070 和售价 599 美元的 9070 XT 平均应该比 RX 7900 GRE 快 21% 和 42%。这可能给 RTX 5070 带来挑战,但 AMD 是否已经解决了光追性能问题,以及显卡的能效的提升还有待观察。

1440p《赛博朋克 2077》游戏中,RTX 5070 略优于 RX 7900 GRE。
再和上上代的 RTX 3070(同样是 1440p)进行对比。可以看到 5070 通常比 3070 快 40-70%,随着时间的推移,旧款显卡会越来越受到 8GB RAM 的限制。5070 相比 3070 肯定是大升级,只是它并没有比一年前的 4070 Super 好多少。

1440p 分辨率下《无主之地 3》的游戏性能比较。
为了换取 5-6% 的性能提升,RTX 5070 在满负荷情况下的功耗比 4070 Super 高 13.5%。英伟达在 RTX 40 系列 GPU 的效率方面远远领先于 AMD 和 RTX 30 系列,因此一个相对低效的升级周期并不会真正破坏英伟达的领先,就是会让我们有一种「白等了」的感觉。
客观地说,想要提高 RTX 50 系列的基础性能确实很困难。在预料之内的是,Blackwell GPU 芯片采用台积电 4nm 工艺制造,与 40 系列所采用的工艺类似。但 5070 在这个指标上的表现比其他 50 系列显卡略差。

RTX 5070 性能小幅提升的同时带来了功耗的较大增加。
所以,卖点在哪里?可见的提升在哪里?
在英伟达的设想中,能够彻底改变显卡性能现状的是 AI 渲染能力。RTX 神经网络渲染可以通过 AI 学习纹理压缩算法,在节省显存占用的情况下,还能获得更好的电影级别纹理和光线效果;Blackwell 架构的 GPU 硬件针对神经工作负载进行了优化,进一步提高了 AI 性能;而 DLSS 4 从 CNN 升级成基于 Transformer 模型,不仅能提高帧率,还可同时提供清晰锐利的高质量图像。
黄仁勋在 1 月 7 号的 CES 演讲中表示:「未来我们看到的游戏画面,每四帧实际上只渲染了一帧,其余三帧由 AI 生成;以全高清或 4K 显示四帧画面大约有 3300 万像素,显卡实际只计算 200 万像素,AI 会预测其余的 3100 万像素。新显卡会实现极高的渲染性能,AI 的计算量要少得多。」
当然,这种高效的渲染范式除了 GPU 硬件支持外,还需要 AI 算法一侧大量的深度学习训练。
具体到目前 RTX 50 的体验上,当你打开帧生成功能时,你可以感受到黄仁勋所说的「549 美元获得 4090 性能」确实有那么一点意思。简而言之,DLSS Transformer 的计算量更大,但图像质量更好,而多帧生成的体验则因为游戏类型的不同而各异。
启用 4x 模式的 DLSS 多帧生成(MFG)的 5070 在赛博朋克 2077 中的平均帧速率与启用旧帧生成模式的 RTX 4090 相似(在支持 MFG 的游戏中现在标记为 2x)。这是因为 5070 能够为每个渲染帧生成三个 AI 插值帧(而不是一个)。

所以,RTX 5070(以及未来的 5060 系列)比其他 50 系列卡更能享受新技术的提升。启用 MFG 后,Cyberpunk 2077 在启用 Overdrive 预设的情况下平均每秒可达到 80 帧以上。听起来不错!除非你考虑到基本帧速率(启用 DLSS 升级,但未启用任何帧生成)是接近每秒 20 帧。在如此低的基本帧速率下,用户输入会感觉迟缓,并且当物体运动时,视觉伪影清晰可见。
DLSS MFG 仍有其用途,RTX 5070 可以在 1440p 下推动相当高的帧速率,并且 MFG 可以帮助玩家比未启用 MFG 时更好地利用 240 Hz 或 360 Hz 1440p 显示器。但它仍然是一种处于应用初期的技术,还做不到所有游戏都适用。
总之还是未来可期。
还有国产 3A 大作《黑神话悟空》的评测。这是一个较新的游戏,基于虚幻 5 引擎,支持全光线追踪,英伟达也专门在 GPU 驱动上进行了优化。可见基础性能与 4070 Super 几乎持平,开 DLSS 后会有更大提升。

RTX 5070 等 GPU 现在不仅仅会用于游戏,很多人都会使用台式机显卡跑 AI 模型。ML Commons 的 MLPerf Client 0.5 测试套件会根据各种输入生成 AI 文本。共有四种不同的测试,均使用 LLaMa 2 7B 模型,基准测试测量第一个 token 输出的时间和第一个 token 后的每秒 token 数,使用几何平均值组合起来得到总分。
RTX 5070 在这里击败了 4070 Ti,但在每秒 token 数方面次于 7900 XT。另一方面,首个 token 的延迟数据明显是英伟达占优。


这个价位,还有高手?

GeForce RTX 4070 和 4070 Super 是英伟达上代产品线中性价比最高的产品之一,性能与高端 30 系列显卡相同,能效出色,价格也比 RTX 3080 或 3090 略低。
如此看来,刚上市的 RTX 5070 很难不让人失望。它的基础性能仅仅比 4070 Super 快一点点,但建议零售价与普通 4070 相同。从技术上讲,新架构和多帧生成等是改进,但与此同时你必须忍受满载功耗增加 13.5%。这样下来,相信你会对是否物有所值有自己的判断了。
RTX 5070 感觉就像是那种「当你不是特别担心竞争对手在做什么时制造的产品」。到目前为止,整个 50 系列都有类似的感觉,RTX 5090 的价格高得惊人,而 5080 和 5070 Ti 的性能改进一般。但 RTX 5070 其实不能如此放任,因为该级别正是对手 AMD 要主攻的方向。
在同一时间段内,AMD 也将于 3 月 6 日正式发售 Radeon RX 9070 XT 和 RX 9070 两款显卡,其起售价分别为 4999 元和 4499 元。
很快我们就会知道谁更有性价比了。
参考内容:
https://www.tomshardware.com/pc-components/gpus/nvidia-geforce-rtx-5070-review-founders-edition
#ByteQC
大规模实用化量子化学计算曙光显现,ByteDance Research开源工具集
真实化学体系包含大量的微观粒子,其精确的严格计算需要指数高的复杂度,对这些体系的模拟一直是材料、制药和催化等领域的难点和前沿。
为了解决这一问题,近日字节跳动 ByteDance Research 团队开发并开源了 ByteQC —— 基于 GPU 加速的大规模量子化学计算工具集。该工具集使用强大的 GPU 算力,大幅度加速了常见的量子化学算法,同时结合领域内前沿的量子嵌入方法实现了量子化学「黄金标准」精度下的大规模量子化学体系的模拟。论文以大尺寸分子团簇,表面吸附问题为例,展示了 ByteQC 在真实材料计算中的应用潜力。
- 论文链接:https://arxiv.org/abs/2502.17963
- 代码链接:https://github.com/bytedance/byteqc
该论文作者中还包括 NVIDIA 和北京大学的合作者。
摘要
在大规模体系中应用量子化学算法需要大量的计算资源,并且计算资源的需求随着体系规模和所需精度的提高而增长。字节团队开发并发展了开源项目 ByteQC(ByteDance Quantum Chemistry)。
在硬件层面,ByteQC 在现代 GPU 上高效实现了多种标准量子化学算法,包括平均场计算(Hartree-Fock 方法和密度泛函理论)以及后 Hartree-Fock 方法(如 Møller-Plesset 微扰理论、随机相位近似、耦合簇方法和量子蒙特卡洛方法)。
在算法层面,ByteQC 提供了一种量子嵌入方法,该方法在保持量子化学「黄金标准」精度的同时,显著扩展了可计算的体系规模。

图 1. ByteQC 软件架构
方法
GPU 的显存显著小于 CPU 内存,同时架构的不同导致很多 CPU 可以高效实现的复杂逻辑在 GPU 上很难实现。为了解决这些问题 ByteQC 在开发过程中主要使用了以下方法:
1. 引入高效计算库
张量缩并是量子化学计算的主要热点之一,为此作者团队引入了 NVIDIA 提供的高效张量计算库 cuTENSR/cuTENSORMG。该计算库在最小占用显存的前提下高效计算张量缩并。作者团队完善了相关的函数封装,将其引入到了 Python / Cupy 的生态中。
2. 高效实现复杂计算逻辑
在周期性体系屏蔽计算中需要在 GPU 上实现高效的动态生产者 - 消费者模型,作者团队提出使用动态的 warp 特例化高效实现。在平均场 Fock 矩阵构建中,涉及相邻任意多的线程竞态求和的问题。CUDA 自带求和函数并未针对该特殊情况优化,作者团队使用 warp 内的 shuffle 指令实现了高效地求和。

图 2. 基于 warp 特例化的生产者-消费者模型

图 3. 基于 warp 同步原语的相邻 7 个线程的竞态求和
3. 优化缓存和简单高效的原位操作
ByteQC 的诸多代码实现均进行了详细的缓存分析,最大限度地实现了缓存的复用,减少了显存需求。此外大量地使用 Cupy 提供的 kernel 接口,通过 CUDA kernel 实现了原位操作,减少了显存的占用。
结果
基准测试表明相比于 100 核 CPU,ByteQC 的标准量子化学算法最高可实现单 A100 GPU 60 倍加速,大多数模块的多卡标度可达到线性加速。对应可以单 GPU 计算的体系规模也大幅提升:
- 耦合簇单、双激发(CCSD):1,610 轨道
- 带微扰三重激发(CCSD (T)):1,380 轨道
- 二阶 Møller-Plesset 微扰理论(MP2):11,040 轨道
- 开放边界条件下的平均场计算:37,120 轨道
- 周期边界条件下的平均场计算:超过 100,000 轨道

图 4. ByteQC 的子模块加速比(数据点)和计算规模(虚线)
此外,结合 ByteQC 中提供的量子嵌入功能,团队在 2,753 轨道的水团簇问题和 3,929 轨道的氮化硼表面水吸附问题上均实现了 CCSD (T) 水平的「黄金标准」精度的计算。

图 5. (左)水团簇结构和(右)氮化硼表面水吸附结构
总结
字节跳动 ByteDance Research 团队开发并开源的 ByteQC 软件包克服了 GPU 开发过程中显存受限,复杂逻辑难以高效实现的问题,实现了量子化学方法的高效 GPU 化。
此外,结合量子嵌入方法,ByteQC 可以在保持 CCSD (T) 的精度的前提下,计算更大的规模。通过这些创新和优化,ByteQC 有望成为推动量子化学领域发展的工具。

















 4796
4796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









