







我自己的原文哦~ https://blog.51cto.com/whaosoft/12709440
#ChatGPT两岁,OpenAI 10亿用户计划曝光
ChatGPT已经2岁了!OpenAI下一个目标瞄准十亿用户,预计明年放出AI智能体产品。就在生日这天,马斯克还送上了大礼:阻止OpenAI全面盈利的一份诉状书。
两年过去了... ChatGPT自诞生之日起,已经给全世界带去了翻天覆地的变化。
今天,正是ChatGPT两周年纪念日!
OpenAI官推转发了两年前的帖子,并附上了「所以,你试过了吗」?
评论区的网友们纷纷向OpenAI索要「礼物」,有的人表示都用了两年了,今天没有满血版o1吗?
Altman却发文表示,「做了一个树屋」,完全没有透露半点即将发布新模型的消息。
OpenAI联创Greg在第一时间内向ChatGPT送上了祝福。
也是从那时起,AI就成为了全网被提及的高频词。截止目前,ChatGPT每周就有2.5亿活跃用户。
而且,自ChatGPT推出以来,世界最大的六家科技公司的市值,总计增长了超8万亿美元。其中,英伟达市值飙升最为显著。
在完成新一轮60亿美金融资后,OpenAI最新估值达到了1500亿美元,目前还在积极寻求新一轮融资,以支撑每年高达50亿美元支出。
这些资金全部被用来,训练下一代新模型和建设基础设施。
外媒最新爆料称,OpenAI智能体即将在2025年推出,目标是在未来扩展到10亿用户群体。
世界科技巨头,总估值飙升8万亿美金
ChatGPT的发布,是世界科技公司命运的一个转折点。
彭博最新统计称,包括英伟达、谷歌、微软、苹果、亚马逊在内的科技巨头,在这场AI红利中,共享了8万亿美金的估值。
开局一张图,简单绘制了ChatGPT自2022年推出以来,六家公司的市值变化,整个科技板块S&P 500指数上涨了30%。
与此同时,英伟达大幅超越了AMD、英特尔,稳坐世界算力的宝座。
另外,世界三大主要云服务提供商微软、亚马逊、谷歌的云收入也在加速增长,突破了2500亿美金。
而对于小公司来说,获得的回报相对较少。
ChatGPT生日,马斯克搞事情
就在ChatGPT生日这天,马斯克为OpenAI送了份大礼。
他向法院提交了一项最新禁令,目的是为了阻止OpenAI全面盈利。
马斯克的律师团队已经向加州北区地方法院提交禁令动议,指控OpenAI、首席执行官Sam Altman、总裁Greg Brockman;以及微软、LinkedIn联合创始人兼前OpenAI董事会成员Reid Hoffman,前OpenAI董事会成员兼微软副总裁Dee Templeton存在各种非法的、不正当竞争行为。
简单来说,指控内容主要有四条:
1、OpenAI阻止投资者支持其他竞争公司,比如马斯克自己的xAI,即OpenAI利用其市场地位,影响投资者决策,吸收更多资金,从而限制市场公平竞争。
2、通过与微软的联系,「不正当地获取竞争敏感信息」共享信息在市场竞争中提供了不正当的优势。
3、将OpenAI的治理结构转变为盈利性质,并「转移所有由OpenAI公司、其子公司或关联公司所拥有的、持有的或控制的重要资产,包括知识产权」。
4、OpenAI与其他被告有「重大财务利益」的组织开展业务往来,损害了市场的公平竞争。
如果法院不批准禁令,马斯克的律师团队声称会对市场造成「无可挽回的伤害」(irreparable harm),禁止OpenAI的非营利性质变更后,OpenAI在继续接受新投资的情况下,「几乎不可能撤销」公司的交易,也就不会造成「大规模投资损失」。
而且就算马斯克胜诉,OpenAI也可能没有「足够的资金」来支付赔偿金,OpenAI的支出超过50亿美元,而且远未实现收支平衡。
「为了保护OpenAI剩余的非营利性质,防止自我交易,颁发禁令是唯一适当的补救措施。如果不这样做,等到法院审理此案时,对马斯克和公众承诺的OpenAI早已不复存在。」
其实这也不是马斯克第一次起诉OpenAI,今年7月,马斯克就曾撤回过一份诉讼,当时指控OpenAI违背了其最初的非营利使命,没有让研究成果惠及所有人。
马斯克当时声称被骗了4400万美元,虽然当时算是捐赠给OpenAI的,但不过是因为有人利用了他对人工智能「存在性」危害的担忧。
在11月的修正诉状中,还增加了微软、Hoffman和Templeton作为被告;增加Neuralink 高管、前OpenAI董事会成员Shivon Zilis和xAI作为原告。
去年,马斯克成立了xAI,很快便发布了一个顶级生成式人工智能模型Grok,为旗下社交网络产品X(原Twitter)上的多项功能提供技术支持,还提供API让客户将Grok集成到第三方应用程序、平台和服务中。
而xAI能接受到的投资,却受制于OpenAI。
马斯克的律师团队声称,OpenAI要求投资人承诺,不资助xAI及其竞争对手;并且已经验证过,至少有一位OpenAI 10月份融资轮的主要投资人后来拒绝投资xAI。
不过这段话其实也站不住脚,xAI的融资过程一直很顺利,本月完成了一轮50亿美元的融资,包括Andreessen Horowitz和Fidelity等知名投资人参与,拥有约110亿美元的资金,可以说是世界上资金最充足的人工智能企业之一。
马斯克的初步禁令动议还声称,微软和OpenAI继续非法共享专有信息和资源,包括Altman在内的几名被告存在自我交易,损害市场竞争。
文件指出,OpenAI选择了奥特曼拥有「重大财务利益」的支付平台Stripe作为OpenAI的支付工具;而坊间流传,Altman从Stripe持股中赚了几十亿美元。
微软自2019年初首次支持OpenAI以来,在过去几年中加强了合作关系,总共投资了约130亿美元,换取了实际上49%的公司收益份额。
微软还允许OpenAI大量使用其云硬件资源,使得OpenAI能够训练、微调和运行大规模人工智能模型。
今年3月,OpenAI的发言人在一份声明中表示,「马斯克的第四次尝试,只不过是再一次重复同样的、虚张声势、毫无根据的抱怨」。
OpenAI智能体明年面世,目标10亿用户
不仅如此,OpenAI正在押宝一系列新的AI产品、建立自己的数据中心,并与苹果建立战略合作伙伴关系。
他们设定下一阶段的增长目标是在未来一年内,达到每年10亿用户。
虽然ChatGPT推出两年以来,目前的周活跃用户「仅」为2.5亿,但上个月开始,ChatGPT在苹果公司的数十亿台设备上部署,10亿用户估计只是一个小目标。
苹果在全球总共有20亿部iPhone,而且也有意愿推出一款新的人工智能手机。
如果与ChatGPT深入绑定,达到10亿用户量,OpenAI就将彻底加入地球最强科技公司行列,其他相似用户量的公司就只有谷歌、Facebook等巨头产品了。
另一个增长点在于「智能体」,可以说是今年AI圈的主要发力赛道,OpenAI计划推出的AI智能体可以帮助用户执行「网络信息收集」、「预定或购买物品」等任务。
不过明年的竞争也会更激烈,谷歌、Anthropic、微软等公司都表示有意在未来一年内推出智能体助手。
虽然OpenAI的增长迅速,前景一片大好,但潜在风险仍然存在,包括领导层更替和成本上升。
OpenAI失去了整个研究和安全团队的关键高管,包括三名最初联合创始人,以及Ilya Sutskever和Mira Murati等知名技术领袖。
与此同时,OpenAI也在积极谋求转型,从非营利性商业模式逐渐过渡到营利性商业模式,员工人数增加了5倍,达到2000多人,保持长期研究愿景,同时专注于增加创收产品,以覆盖不断膨胀的成本。
OpenAI每年的支出超过50亿美元,远未达到收支平衡。
但首席财务官Sarah Friar在10月份以1500亿美元的估值筹集了逾60亿美元的投资,也是硅谷历史上初创企业的最高估值,并且还将继续筹集「更多资金」。
OpenAI还需要应付复杂的政治问题,与美国政府在人工智能方面的优先事项保持一致,解决与马斯克的争论等。
满血版o1今晚祭出?网友一些预测
一个多月前,奥特曼曾表示,「下个月是ChatGPT的第二个生日,我们应该送它什么生日礼物呢」?
甚至就连ChatGPT官方账号都不藏着掖着了,并称满血版o1快来了。
或者,我们在今晚大概率能蹲到o1的发布。
有爆料者称,OpenAI今天可能会发布一些关于语音/高级模式,一部分OpenAI内部员工都在讨论/转推。
也有人表示完整版o1也要发布了。
Abacus AI的创始人称,自ChatGPT推出并在人工智能领域掀起热潮以来,已经过去两年了。人工智能前沿模型从一个增加到十几个,文本、代码、视频和图像生成从原型走向了实际应用 。
不过,我们才刚刚起步!未来两年将比过去两年更加疯狂。随着人工智能变得更加自主和独立,它将变得更加神奇。
参考资料:
https://x.com/kimmonismus/status/1862870264289079375
https://x.com/kimmonismus/status/1862940159140049067
#Delta-CoMe
80G显存塞50个7B大模型!清华&OpenBMB开源增量压缩新算法,显存节省8倍
最新模型增量压缩技术,一个80G的A100 GPU能够轻松加载多达50个7B模型,节省显存约8倍,同时模型性能几乎与压缩前的微调模型相当。
清华大学NLP实验室携手OpenBMB开源社区、北京大学和上海财经大学的研究团队,提出Delta-CoMe。
这项技术的核心在于利用主干模型与任务专用模型之间参数增量(即Delta)的特点进行压缩,从而实现存储开销和部署成本的大幅降低。不仅有助于解决资源瓶颈问题,更为多任务处理和模型部署开辟新的可能。
具体而言,Delta-CoMe将低秩分解和低比特量化技术相结合,充分利用Delta参数的低秩特性,提出了一种全新的混合精度压缩方法。这种方法不仅能够实现接近无损的任务性能,还能显著提升推理效率。
Delta-CoMe方法介绍
微调是增强预训练模型的重要手段,不同任务往往需要不同的微调方式。例如Luo et al.[1]提出RLEIF通过Evove-instruction来增强模型数学推理能力;Wei et al.[2]利用Code snnipet合成高质量的指令数据来增加模型的代码能力。然而,这些方法通常依赖高质量数据,并需要精心设计的策略才能实现显著的效果。
在一些场景中往往需要具有不同能力的LLM同时处理问题,例如多租户场景,多任务场景以及端侧场景等等。一种自然的解决方案是部署单个通用模型作为主干,配合多个具有专有能力的Delta。
以Bitdelta[3]为例,它通过将模型的Delta压缩到1-bit,有效保留了模型在问答等场景中的能力。尽管该压缩方法在存储和推理效率上表现出色,其在更复杂的任务(如数学推理和代码生成)上仍存在明显的能力瓶颈。
针对这一挑战,THUNLP实验室联合北京大学和上海财经大学提出Delta-CoMe。这一方法结合低秩分解和低比特量化技术,不仅显著提升了模型在复杂任务上的表现,还兼顾了压缩效率和实际应用需求,为模型的高效部署提供了一种新思路。
与前人的方法相比,Delta-CoMe方法的优点在于:
- 结合低秩与低比特量化, 利用了Delta低秩的特点,并发现低秩分解后的Delta是长尾分布的;之后采用混合精度量化进一步压缩
- 性能几乎无损, 相比于BitDelta等方法,在Math, Code, Multi-modal等复杂任务上,性能与压缩前的微调模型表现基本接近
- 推理速度提升, 为混合精度量化实现了Triton kernel算子,对比Pytorch的实现方式,带来近3倍的推理速度提升
- 超过Delta-tuning,支持多精度Backbone, Delta-CoMe在效果上显著优于LoRA微调,并可以用在多种精度的Backbone上
具体而言,Delta-CoMe首先采用SVD进行低秩分解,Delta 具有低秩性,经过低秩分解之后,其特征值呈现出长尾分布的规律,仅有少数较大奇异值对应的奇异向量对最终的结果贡献较大。
一个自然的想法,我们可以根据奇异值的大小进行混合精度量化,将较大的奇异值对应的奇异向量用较高精度表示,而较小的奇异值对应的奇异向量用较低精度表示。
实验结果
多个开源模型和 Benchmark 的实验验证了该方法的有效性。
使用Llama-2作为主干模型,在数学、代码、对话、多模态等多个任务中进行实验,Delta-CoMe展现出平均几乎无损的性能。下面分别是7B模型和13B模型的实验效果。
此外,还在Mistral、Llama-3等其它主干模型上对不同的压缩方法进行了验证。
为了提升混合精度量化的计算效率,实现一个Triton Kernel,相比于Pytorch的实现方式,推理速度提升了约3倍。
实验结果表明,使用一块80G的A100 GPU可以加载50个7B模型。
最后,还比较了Delta-Tuning和Delta-Compression的效果差异(Delta-Tuning指的是通过训练部分参数进行微调,Delta-Compression指的是先进行全参数微调,再将微调带来的模型参数增量进行压缩)。其中Delta-Tuning采用的是LoRA。Delta-CoMe对比LoRA在相同的存储开销下,性能显著提升。
Delta-CoMe 通过结合低秩分解和低比特量化,不仅实现了大幅度的存储压缩,还在复杂任务如数学推理、代码生成和多模态任务上维持了与压缩前模型相当的性能表现。相比于传统的微调方法,Delta-CoMe 展现出了更高的灵活性,尤其在多租户和多任务场景中具有显著的应用价值。此外,借助 Triton kernel 的优化,推理速度得到了显著提升,使得部署大规模模型成为可能。未来,这一方法的潜力不仅在于进一步优化模型存储和推理速度,也有望在更广泛的实际应用中推动大语言模型的普及和高效运作。
参考文献
[1]Yu, L., Jiang, W., Shi, H., Jincheng, Y., Liu, Z., Zhang, Y., Kwok, J., Li, Z., Weller, A., and Liu, W.Metamath: Bootstrap your own mathematical questions for large language models. In The Twelfth International Conference on Learning Representations, 2023.
[2] Luo, Z., Xu, C., Zhao, P., Sun, Q., Geng, X., Hu, W., Tao, C., Ma, J., Lin, Q., and Jiang, D. Wizardcoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568, 2023b
[3] Liu, J., Xiao, G., Li, K., Lee, J. D., Han, S., Dao, T., and Cai, T. Bitdelta: Your fine-tune may only be worth one bit. arXiv preprint arXiv:2402.10193, 2024b.
Paper链接:https://arxiv.org/abs/2406.08903
Github链接:https://github.com/thunlp/Delta-CoMe
#PRIME
美欧亚三洲开发者联手,全球首个组团训练的大模型来了,全流程开源
11 月 22 日,Prime Intellect 宣布通过去中心化方式训练完成了一个 10B 模型。30 号,他们开源了一切,包括基础模型、检查点、后训练模型、数据、PRIME 训练框架和技术报告。据了解,这应该是有史以来首个以去中心化形式训练得到的 10B 大模型。

- 技术报告:https://github.com/PrimeIntellect-ai/prime/blob/main/INTELLECT_1_Technical_Report.pdf
- Hugging Face 页面:https://huggingface.co/PrimeIntellect/INTELLECT-1-Instruct
- GitHub 地址:https://github.com/PrimeIntellect-ai/prime
- 体验链接:chat.primeintellect.ai
Prime Intellect 表示,相比此前的研究,INTELLECT-1 实现了 10 倍的规模提升。这一突破证明,大规模模型训练已不再是大公司的专利,通过去中心化的、社区驱动的方式同样可以实现。
他们的下一步计划是将模型进一步扩展到前沿规模,最终目标是实现开源 AGI。这一点在其在线 Demo 的模型选项中已有暗示 —— 其中包含开放推理模型甚至 AGI 和 ASI 的潜在选项。看起来这确实是一个雄心勃勃的团队。

模型发布后,虽也有质疑声音,但 AI 社区总体上还是给出了非常积极的肯定。

也用几个经典问题简单尝试了其在线 Demo 版本的模型。
首先是经典的草莓问题,INTELLECT-1 一开始答对了,但继续提问就又变成了常见的错误答案。

该模型也具备还不错的文本理解能力,但总体而言和 Llama 和 Qwen 等前沿开源模型还有所差距。

下面我们看看它的汉语能力。从多次测试的结果来看,这个模型的汉语能力并不好,并且幻觉现象似乎也挺严重的,比如下图中,即使该模型暂时并不具备读取链接的能力,也会根据上下文强行作答。

不管怎样,INTELLECT-1 都是 AI 历史上一次颇具开创性的实验。下面我们就来看看这个系统是如何炼成的。
大规模去中心化训练
Prime Intellect 的这场去中心化训练的规模其实相当大,涉及到 3 个大洲的 5 个国家,同时运行了 112 台 H100 GPU。
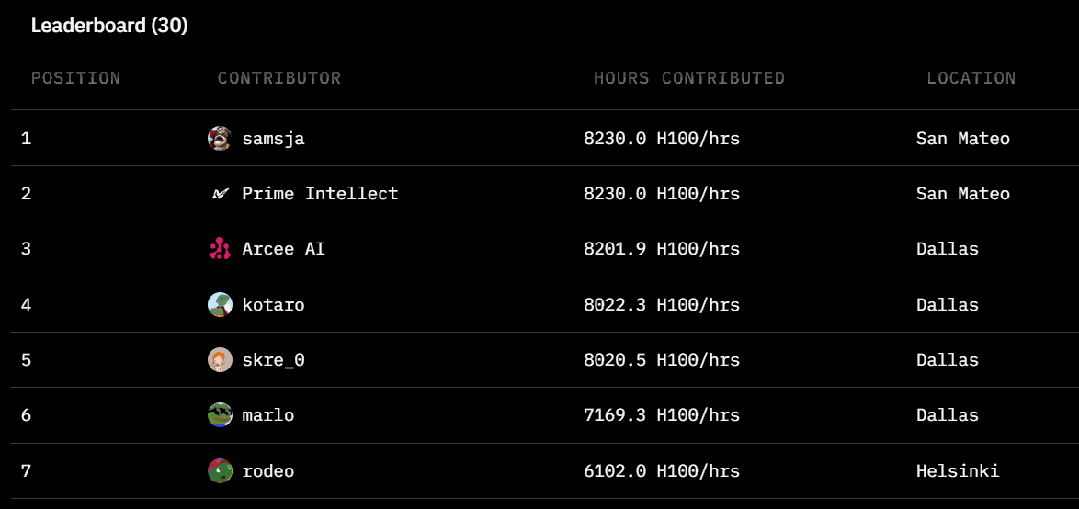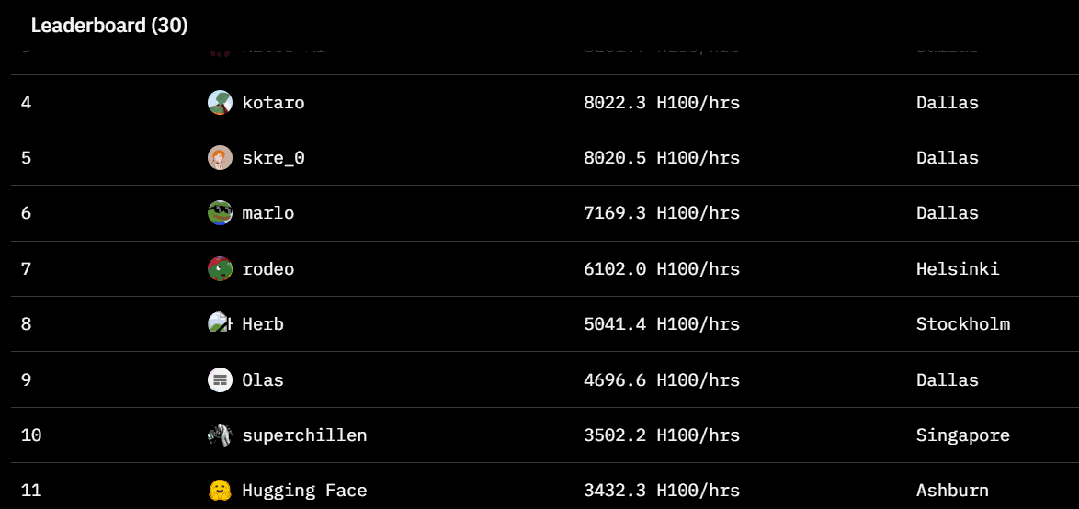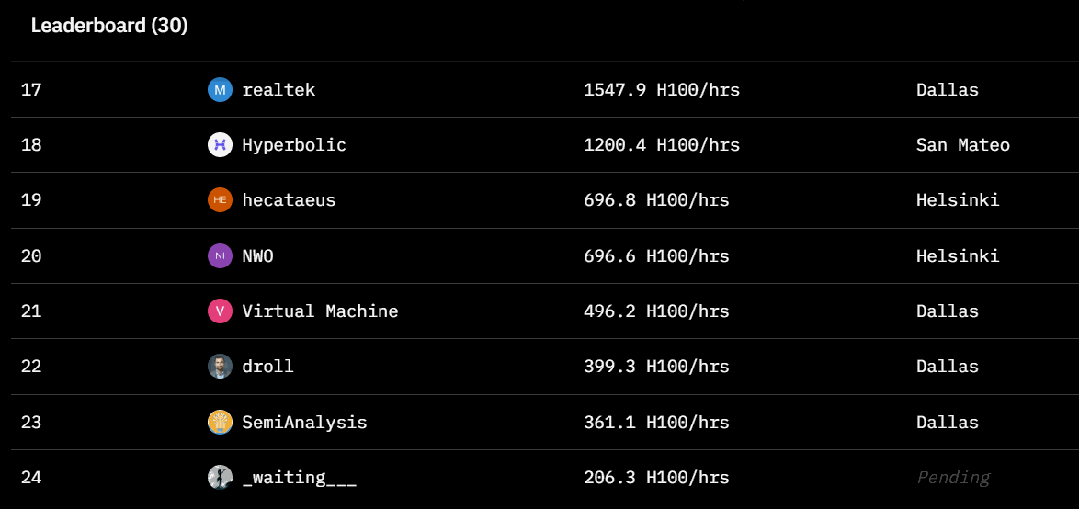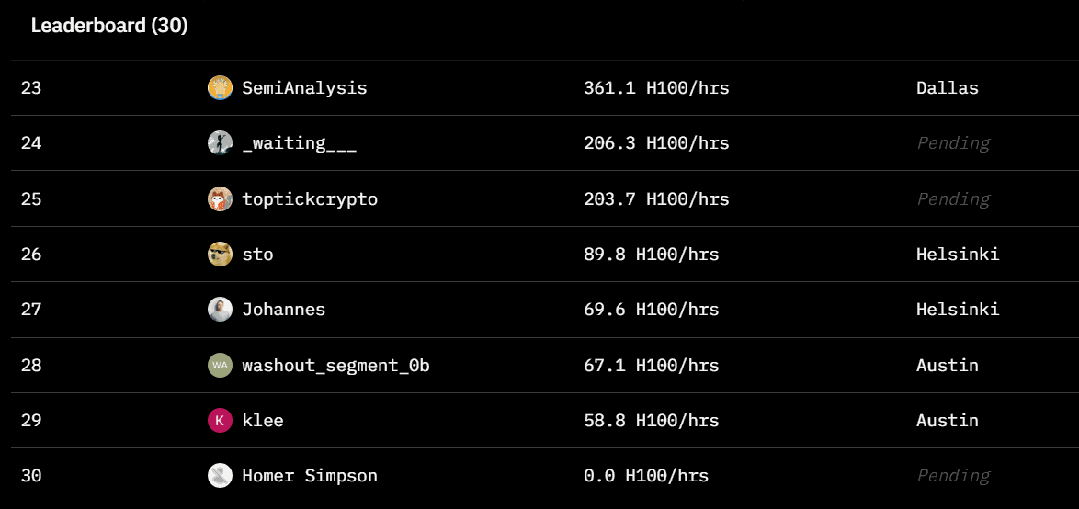
全球 30 位贡献者的基本信息
该团队表示:「我们在各大洲实现了 83% 的总体计算利用率。当仅在分布于整个美国的节点上进行训练时,实现了 96% 的计算利用率。与中心化训练方法相比,开销极小。」
这样的结果表明 INTELLECT-1 在存在严重的带宽限制和节点波动的情况下,依然能维持训练收敛性和高计算利用率,这昭示了一种新的可能性:能够以去中心化、社区驱动的方式训练出前沿的基础模型!

一万亿 token 的训练过程,这里给出了训练过程中损失、困惑度、训练速度等信息
训练细节与数据集
INTELLECT-1 基于 Llama-3 架构,它包含:
- 42 层,隐藏维度为 4,096
- 32 个注意力头
- 序列长度为 8,192
- 词表大小为 128,256

模型在经过精心筛选的 1 万亿 token 数据集上训练,数据构成如下:
数据集 Huggingface 链接:https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu
- 55% FineWeb-Edu
- 20% Stack v2(Stack Overflow 等技术问答数据)
- 10% FineWeb(精选网页数据)
- 10% DCLM-baseline(基准通用语料)
- 5% OpenWebMath(数学数据)

模型训练持续了 42 天,采用了以下技术:
- 采用 WSD 动态调整学习速度,让模型学习更高效
- 精细调教的学习参数:内层学习率设为 7.5e-5
- 引入特殊的损失函数(max-z-loss)来确保训练过程的稳定性
- 使用 Nesterov 动量优化算法,帮助模型更快更好地学习
- 支持训练机器的灵活接入和退出,最多可同时使用 14 台机器协同训练

从训练过程的监控图表可以看出,PRIME 系统表现出色:即使参与训练的机器数量经常变化(从最少 4 台逐渐增加到最多 14 台),整个训练过程依然保持稳定,充分证明了系统的可靠性。

训练动态图展示了整个训练过程中模型困惑度和学习率的变化,包括预热阶段、稳定阶段和退火阶段。
Prime:一个去中心化训练框架
该团队使用的训练框架名为 Prime,这基于他们开发的 OpenDiLoCo。而 OpenDiLoCo 又基于 DeepMind 之前开发的 Distributed Low-Communication(DiLoCo)方法。
项目地址:https://github.com/PrimeIntellect-ai/OpenDiLoCo
在此之前,Prime Intellect 已经在 1B 参数规模上实验了去中心化 AI 模型训练。该团队表示:「这让我们到达了我们的 masterplan 的第三步:合作训练用于语言、智能体和科学的开放式基础模型。」

Prime Intellect 的 masterplan
相比于之前开源的 OpenDiLoCo,Prime 有两大关键提升。
一是在算法方面,他们在 OpenDiLoCo 上执行了许多消融研究,发现还能进一步降低通信要求。值得注意的是,他们将伪梯度的 int8 量化与每 500 步进行一次的外部优化器同步相结合,从而将带宽要求降低了多达 2000 倍。这些结果不仅在较小规模下是有效的,该团队也将它们扩展到了更大的模型。
在具体的大规模扩展方面,我们知道,去中心化训练既是工程挑战,也是研究挑战。当今最大的 AI 实验室也还没有彻底解决在多个分布式数据中心上的容错训练。该团队表示,Prime 这种全新的去中心化训练框架支持容错训练,支持计算资源的动态开启/关闭,还能优化全球分布式 GPU 网络中的通信和路由。

Prime 中用于容错训练的 ElasticDeviceMesh 的拓扑结构
该团队在博客中写道:「该框架构成了我们开源技术堆栈的基础,其目标是支持我们自己的算法以及 OpenDiLoCo 之外的其他去中心化训练算法。通过在此基础架构上构建,我们的目标是突破全球分布式 AI 训练的极限。」
具体来说,Prime 框架包含以下关键特性:
- 用于容错训练的 ElasticDeviceMesh
- 异步分布式检查点
- 实时检查点恢复
- 自定义 Int8 All-Reduce 内核
- 最大化带宽利用率
- PyTorch FSDP2 / DTensor ZeRO-3 实现
- CPU 卸载
计算效率
虽然训练散作满天星,但计算效率仍保持「聚是一团火」的高水准:在美国境内集群部署时,计算资源利用率高达 96%(中位数同步延迟仅 103s);跨越大西洋的部署场景下依然维持在 85.6% 的优异水平(中位数同步延迟 382s);即便是在全球分布式节点配置下,计算利用率也能稳定保持在 83%(中位数同步延迟 469s)。

这一系列亮眼的数据充分证明了该去中心化训练框架的容错性和扩展性,不仅能够从容应对不同地理位置的网络延迟挑战,更在确保训练稳定性的同时实现了高效计算。
后训练
在完成分布在全球的预训练阶段后,Prime Intellect 与 Arcee AI 合作开展了一系列后训练,以提升 INTELLECT-1 的整体能力和特定任务表现。主要包含三个阶段:
- SFT(监督微调,16 轮)
- DPO(直接偏好优化,8 轮)
- 使用 MergeKit 整合训练成果
更多信息请查看详细技术报告:
论文链接:https://github.com/PrimeIntellect-ai/prime/blob/main/INTELLECT_1_Technical_Report.pdf
未来计划:长期目标是 AGI
INTELLECT-1 的成功让我们看到了去中心化训练的巨大潜力。至于如何将开源的 PRIME 框架扩展到目前动辄 70B 的规模呢?Prime Intellect 提了三点规划:
- 继续扩大全球计算网络
- 用更多奖金激励推动社区参与
- 进一步优化 PRIME 去中心化训练架构以支持更大的模型
在博客结尾,Prime Intellect 写道:「为了防止 AI 能力被少数组织垄断,我们诚邀全球 AI 社区通过 GitHub 或 Discord 加入我们。让我们携手共建一个更开放、更具协作性的 AI 发展未来。」

参考链接:
https://www.primeintellect.ai/blog/intellect-1-release
https://app.primeintellect.ai/intelligence
https://www.primeintellect.ai/blog/intellect-1
#Boundless Socratic Learning with Language Games
DeepMind用语言游戏让大模型学AlphaGo自我博弈,数据限制不存在了
自我博弈,很神奇吧?
我们终于朝着真正自主、自我完善的人工智能迈出了重要一步?
上周末,一篇 Google DeepMind 的论文引发了 AI 圈的关注。研究者引入了「苏格拉底式学习」,这是 AI 中递归自我完善的一种新方法。这种方法使系统能够自主增强其能力,超越初始训练数据的限制。通过利用结构化的「语言游戏」,该技术可以为实现通用人工智能提供了实用的路线图。
在该工作中,DeepMind 提出的框架围绕封闭、自给自足的环境,AI 系统无需外部数据即可运行。要实现目标,智能体必须满足三个关键条件:反馈与目标一致,广泛的数据覆盖范围,以及足够的计算资源。这种设计促进了独立学习,为通向 AGI 提供了一条可扩展的途径,同时解决了数据生成和反馈质量等挑战。
新方法的核心是进行「语言游戏」,即智能体之间结构化的交互、解决问题并以分数的形式接收反馈。这些游戏允许人工智能进行自我博弈,生成数据并完善技能,也无需人工输入。递归结构使系统能够自主创建和开局新游戏,解锁更抽象的解决问题的能力并扩展其能力。
最终的创新在于 AI 自我改造,智能体不仅可以从环境中学习,还可以重新配置其内部系统。这样可以消除固定架构带来的限制,为超过以往的性能改进奠定基础。总之,DeepMind 的研究强调了苏格拉底式学习作为创造真正自主、自我完善的人工智能的变革性步骤的潜力。
让我们看看这篇论文是怎么说的:
- 论文标题:Boundless Socratic Learning with Language Games
- 论文链接:https://arxiv.org/abs/2411.16905
考虑一个随时间演变的封闭系统(无输入、无输出)(见图 1)。系统内有一个具有输入和输出的实体,称为智能体(Agent),它也会随时间发生变化。系统外部有一个观察者,其目的是评估智能体的性能。如果性能不断提高,我们就把这对系统和观察者称为改进过程。

这一过程的动态变化由智能体及其周围系统共同驱动,但为了使评估定义明确,需要设定明确的边界:事实上,智能体就是可以明确评估的对象。同样,为了分离关注点,观察者被刻意置于系统之外:由于系统是封闭的,观察者的评估无法反馈到系统中。因此,智能体的学习反馈必须来自系统内部的智能体,如损失、奖励函数、偏好数据或批评者。
在这里,最简单的性能指标是一个标量分数,可以在有限的时间内测量,也就是在(一系列)偶发任务中测量。从机制上讲,观察者可以通过两种方式来衡量性能,一是被动地观察智能体在系统中的行为(如果所有相关任务都是自然发生的),二是通过复制和探测评估,即让智能体的克隆副本面对自己选择的交互任务。
在不失通用性的前提下,智能体内部的元素可分为三类:固定元素不受学习的影响,例如它的底层或不可修改的代码;瞬态元素不会在不同事件之间或不同评估之间延续(如激活、随机数生成器的状态);最后,学习元素(如权重、参数、知识)会根据反馈信号发生变化,它们的演变会映射出性能差异。
可以通过隐含的生命周期来区分改进过程;有些改进过程是开放式的,可以无限制地持续改进,而有些改进过程则会在某个有限时间后收敛到其渐进性能。
自我完善的三个必要条件
DeepMind 研究者认为,自我完善是一种改进过程,但附加标准是智能体自身的输出(行动)会影响其未来的学习。换句话说,智能体在系统中塑造(部分)自己的经验流,有可能在封闭系统中实现无限的改进。这种设置对于强化学习社区(RL)的读者来说可能很熟悉:RL 智能体的行为会改变其学习的数据分布,进而影响其行为策略。
自我完善过程的另一个典型实例是自我对弈,其中系统(通常称游戏)将智能体置于玩家和对手的角色中,以生成带有反馈(谁赢了)的无限经验流,为不断增加的技能学习提供方向。从它与 RL 的联系中,我们可以得出自我完善发挥作用的必要条件,并帮助澄清有关系统的一些假设。前两个条件,反馈和覆盖度是原则上的可行性,第三个条件规模是实践上的可行性。
研究者考虑的自我完善过程的具体类型是递归自我完善,其中智能体的输入和输出是兼容的(即存在于同一空间中),并且输出成为未来的输入。与输出仅影响输入分布的一般情况相比,这更具限制性,但中立性更低,最常见的实例是将智能体输出映射到输入的(复杂)环境。这种类型的递归是许多开放式过程的属性,开放式改进可以说是 ASI 的核心特征。
这种兼容的输入和输出空间的一个极好的例子就是语言。人类的大量行为都是通过语言来介导和表达的,尤其是在认知领域(从定义上讲,认知领域是 ASI 的一部分)。正如查尔默斯 (2024) 和他之前几个世纪的理性主义者所言,语言可能足以进行思考和理解,而不需要感官基础。语言又同时具有抽象的巧妙特性,可以在共享空间中编码概念层次结构的多个级别。
在文章的其余部分,研究者使用「苏格拉底式学习」来指代在语言空间中运作的递归式自我完善过程。这个名字暗示了苏格拉底通过质疑对话和反复的语言互动来寻找或提炼知识的方法。但值得注意的是,这种方法并不是去收集现实世界中的观察结果 —— 这反映了系统强调的封闭性。

苏格拉底式学习的本质局限性
在自我完善的三个必要条件中,覆盖和反馈这两个条件原则上适用于苏格拉底式学习,而且仍然是不可还原的。为了尽可能清楚地说明这两个条件的含义,本节中忽略了第三个条件(规模、实用性和效率问题),而从长远的角度来考虑这种简化的动机:如果计算能力和内存继续呈指数增长,那么规模限制只是暂时的障碍。如果不是这样,考虑苏格拉底式学习的资源受限情景(类似于研究有界理性)仍能产生有效的洞察。
覆盖条件意味着苏格拉底学习系统必须不断生成(语言)数据,同时随着时间的推移保持或扩大多样性。在 LLM 时代,这似乎并不太牵强:我们可以设想,一个生成智能体初始化时拥有类似互联网的广泛分布,它可以生成永无止境的新语言表达流。然而,在递归过程中防止生成分布的漂移、崩溃或缩小可能非常困难。
反馈条件要求系统:(a)持续产生关于智能体输出(某些子集)的反馈,这在结构上要求批评者能够评估语言,(b)反馈与观察者的评估指标保持足够一致。这造成挑战的原因有很多:语言空间中定义明确、有依据的衡量标准往往局限于狭隘的任务,而人工智能反馈等通用性更强的机制则可以加以利用,尤其是在允许输入分布发生变化的情况下。
例如,目前的 LLM 训练范式都没有足以满足苏格拉底式学习的反馈机制。下一个 token 的预测损失是有依据的,但与下游的使用情况不够一致,而且无法推断出训练数据之外的情况。根据定义,人类的偏好是一致的,但却阻碍了在封闭系统中的学习。将这种偏好缓存到已学习的奖励模型中会使其自成一体,但从长远来看会被利用并可能出现错位,而且对分布外数据的影响也很微弱。
换句话说,纯粹的苏格拉底式学习是可能的,但它需要广泛的数据生成和强大且一致的批评能力。然而,当这些条件都具备时,其潜在改进的上限就会受到应用资源量的限制。目前已有的研究还没有为此制定出成功的方法,接下来的内容会就如何进行苏格拉底式学习提出一个具体但相当笼统的建议。
「Language games are all you need」
在该研究中,研究者认为 AI 的训练可以借鉴维特根斯坦的语言游戏概念。在其中,并不是让词语捕捉意义,而是让语言的互动性做到这一点。具体来说,语言游戏定义为一种互动协议(一组规则,可以用代码表达),它指定了一个或多个具有语言输入和语言输出的智能体(「玩家」)之间的互动,以及游戏结束时每个玩家的标量评分函数。
如此定义的语言游戏满足了苏格拉底式学习的两个主要需求。即,1)它们为无限制的交互式数据生成和自我博弈提供了一种可扩展的机制,2 同时自动提供伴随的反馈信号(分数)。
事实上,它们是覆盖和反馈条件的逻辑结果,几乎一直在被应用。如果将这个过程视为游戏过程,我们就立即可以意识到多智能体动态产生的丰富策略具有很大潜力。
另外,许多常见的 LLM 交互范式也可以被很好地表示为语言游戏,例如辩论、角色扮演、心智理论、谈判、越狱攻防,或在封闭系统之外,来自人类反馈的 RL 等范式 (RLHF)。
回到哲学家:我们能想象他们玩上几千年的语言游戏吗?相反,也许他们在玩多种语言游戏时更有可能摆脱狭隘的结果。维特根斯坦(又是他)也提出过同样的观点:他坚决反对语言具有单一的本质或功能。使用许多狭义但定义明确的语言游戏而不是单一的通用游戏,可以解决一个关键的两难问题:对于每个狭义游戏,都可以设计出可靠的得分函数(或批评家),而正确地获得单一的通用函数则更加难以捉摸(即使原则上是可能的,正如 Silver 等人所论证的那样)。从这个角度看,苏格拉底式学习的整个过程就是一个元游戏,它安排了智能体玩的语言游戏并从中学习(根据 Carse (2011),这是一个「无限」游戏)。
研究者认为,原则上这一想法足以解决覆盖问题。具体来说,如果有观察者感兴趣的分布的智能体(例如,任务的验证集),就可以用来驱动元游戏中的探索。
正如苏格拉底本人的经历,苏格拉底式的思考过程并不能保证与外部观察者的意图保持一致。语言游戏作为一种机制,也没有回避这一点,但可以说,它降低了所需的精确度:我们所需要的不是一个在单个输入和输出的细粒度上保持一致的批评家,而是一个能够判断哪些游戏应该玩的「元批评家」:也许没有一个语言游戏是完全一致的,但可以做的是,根据它们是否(在玩和学习时)做出了总体上积极的净贡献,对众多游戏进行筛选。
此外,一个游戏的有用性并不需要事先评估,而是可以在玩过一段时间之后进行事后判断。与此相关,一个有益的不对称现象是,事后发现偏差的突发行为可能比设计游戏防止这种行为要容易得多。所有这些特性都是结构上的宽松形式,赋予了语言游戏框架巨大的扩展潜力。暂时跳出此处对封闭系统的假设:当我们实际构建人工智能时,我们几乎肯定不会乐观地相信对齐会得到保持,而是会尽可能仔细地持续检查这一过程,并可能在整个训练过程中对系统进行干预和调整。
在这种情况下,明确地将游戏分布(伴随着可解释的游戏描述和每个游戏的学习曲线)作为旋钮提供给设计者,可能是一种有用的抽象方法。
更高阶的递归
到目前为止,本文讨论了递归的最低必要形式,即一种将智能体(部分)输出反馈给自身的循环形式。在语言游戏的框架内,研究者还想到了另外两种递归形式。第一种思路是告诉智能体它正在玩哪个游戏,并让它选择切换游戏、切换到哪个游戏以及何时切换。
这与分层或以目标为条件的 RL 有关,为智能体提供了更多的自主权和更抽象的行动空间。在将更多责任转移给智能体的同时,与智能体外部的硬联线游戏选择过程相比,这种设置可以显著改善结果,但当然,这种额外的自由度可能会带来崩溃或错位的额外风险。
其次,由于游戏是可以完全用代码表示的交互协议,因此它们可以存在于语言智能体的输出空间中。一开始,它可以简单地生成现有游戏的局部变体,从而调整主题的难度水平,之后再对游戏进行重组,最终实现全新生成。这导致了语言游戏空间而非语言空间的二阶覆盖问题,需要通过过滤、优先排序或课程来解决。
这两种递归扩展的结合就是一个有能力的智能体,它可以通过游戏的生成和玩耍来玩完整的元游戏,即如何改进自己。这种元博弈虽然优雅动人,但却缺乏内部语言博弈的明确反馈机制,而且像学习进度这样的既定智能体指标是否足以长期保持覆盖和对齐特性,也是一个有待研究的问题。
递归的下一步,也是最后一步是递归自我改造,也就是说,智能体的行为会改变其自身的内部结构,而不仅仅是影响其输入流。这些方法的特点是可以以这种方式修改哪些内容(哪些内容保持不变),以及智能体可以进行多少自省,或者说可以访问其自身的工作原理。在极端情况下,一个完全自我反省的智能体可以观察和修改自身的任何方面,而无需间接操作。
原则上,这种类型的智能体具有最高的能力上限;由于渐进性能受到其固定结构的限制,解冻部分结构并使其可修改只会增加上限。尤其是,总有可能将新灵活参数设置为冻结时的状态,以恢复灵活性较低的智能体的性能(在不考虑学习动力的情况下)。
从这种角度看,过去关于如何设计自我参照系统的建议并不实用,但现代 LLM 在代码理解和生成方面的能力正在改变竞争环境,可能很快就会将这些想法从空洞转向关键。
参考内容:
https://x.com/kimmonismus/status/1862993274727793047
#Embedding Trajectory for Out-of-Distribution Detection in Mathematical Reasoning
数学推理场景下,首个分布外检测研究成果来了
本文将介绍数学推理场景下的首个分布外检测研究成果。该篇论文已被 NeurIPS 2024 接收,第一作者王一鸣是上海交通大学计算机系的二年级博士生,研究方向为语言模型生成、推理,以及可解释、可信大模型。该工作由上海交通大学和阿里巴巴通义实验室共同完成。
- 论文题目:Embedding Trajectory for Out-of-Distribution Detection in Mathematical Reasoning
- 论文地址:https://arxiv.org/abs/2405.14039
- OpenReview: https://openreview.net/forum?id=hYMxyeyEc5
- 代码仓库:https://github.com/Alsace08/OOD-Math-Reasoning
背景与挑战
分布外(Out-of-Distribution, OOD)检测是防止深度网络模型遭遇分布偏移数据时产生不可控输出的重要手段,它对模型在现实世界中的部署安全起到了关键的作用。随着语言模型的发展,复杂生成序列的错误传播会使得 OOD 数据带来的负面影响更加严重,因此语言模型下的 OOD 检测算法变得至关重要。
常规的检测方法主要面向传统生成任务(例如翻译、摘要),它们直接计算样本在输入 / 输出空间中的 Embedding 和分布内(In-Distribution,ID)数据的 Embedding 分布之间的马氏距离(Mahalanobis Distance)。然而,在数学推理场景下,这种静态 Embedding 方法遭遇了不可行性。研究团队可视化比较了数学推理和传统文本生成任务在不同域上的输入 / 输出空间:

- 相比于文本生成,数学推理场景下不同域的输入空间的聚类特征并不明显,这意味着 Embedding 可能难以捕获数学问题的复杂度;
- 更重要地,数学推理下的输出空间呈现出高密度叠加特性。研究团队将这种特性称作 “模式坍缩”,它的出现主要有两个原因:
- (1) 数学推理的输出空间是标量化的,这会增大不同域上的数学问题产生同样答案的可能性。例如 和 这两个问题的结果都等于 4;
- (2) 语言模型的建模是分词化的,这使得在数学意义上差别很大的表达式在经过分词操作后,共享大量的 token(数字 0-9 和有限的操作符)。研究团队量化了这一观察,其中表示出现的所有 token 数,表示出现过的 token 种类, 表示 token 重复率,表示 token 种类在词表中的占比,发现在一些简单的算术场景下,token 重复率达到了惊人的 99.9%!

为了应对这个挑战,研究团队跳出了静态 Embedding 的方法框架,提出了一种全新的基于动态 Embedding 轨迹 的 OOD 检测算法,称作 “TV Score”,以应对数学推理场景下的 OOD 检测问题。
动机与方法
1. 定义:什么是 Embedding 轨迹?
假设语言模型有 L 层,输出文本包含 T 个 token,则第 t 个位置的 token 在第 l 层的 Embedding 输出表示为

。现将每一层的平均 Embedding

称为第 l 层的句子 Embedding 表征,则动态 Embedding 轨迹可形式化为一个递进的 Embedding 链:
![]()
2. 动机:为什么用 Embedding 轨迹?
- 理论直觉
在数学推理场景下,输出空间具有显著的高密度模式坍缩特征,这使得在输入空间相差较大的两个起始点,通过隐藏层转移至输出空间后,将收敛到非常近的距离。这个 “终点收敛” 现象将增大不同样本的 Embedding 轨迹之间产生差异的可能性,如下图所示。该理论分析的数学建模和证明详见论文。

- 经验分析
在初步获取了使用 Embedding 轨迹作为测度的理论直觉后,需要继续深入分析 ID 和 OOD 样本的 Embedding 轨迹之间会产生怎样的个性化差异。研究团队在 Llama2-7B 模型上统计了不同的 ID 和 OOD 数据集下的 Embedding 轨迹特征。其中,横坐标表示层数,纵坐标表示该层与其邻接层的 Embedding 之间的差值 2 - 范数,数值越大表示这两个邻接层之间的 Embedding 转换幅度越大。通过统计数据得出如下发现:
- 在 20 层之前,ID 和 OOD 样本都几乎没有波动;在 20 层之后,ID 样本的 Embedding 变化幅度先增大后又被逐渐抑制,而 OOD 样本的 Embedding 变化幅度一直保持在相对较高的范围;
- 通过这个观察,可以得出 ID 样本的 “过早稳定” 现象:ID 样本在中后层完成大量的推理过程,而后仅需做简单的适应;而 OOD 样本的推理过程始终没有很好地完成 —— 这意味着 ID 样本的 Embedding 转换相对平滑。

3. 方法:怎么用 Embedding 轨迹?
基于上述发现,研究团队提出了 TV Score,它可以衡量一个样本属于 ID 或 OOD 类别的可能性。受到静态 Embedding 方法的启发,文章希望通过计算新样本的 Embedding 轨迹和 ID 样本的 Embedding 轨迹分布之间的距离来获取测度,但轨迹分布和轨迹距离的计算并不直观。
因此,文章将 TV Score 的计算分为了三个步骤:
- 首先,将每一层 l 的 ID Embedding 拟合为一个高斯分布:

- 其次,对于一个新样本,在获取了每一层的 Embedding
-

- 后,计算它和该层高斯分布之间的马氏距离:

- 最后,将
-

- 视为新样本的相邻层波动率,并取所有相邻层波动率的平均值作为该样本的最终轨迹波动率得分:


进一步地,考虑到轨迹中的异常点可能会影响特征提取的精度,研究团队在此基础上加入了差分平滑技术 (Differential Smoothing, DiSmo):
- 首先,定义每一层的 k 阶 Embedding 和高斯分布:

- 其次,计算
-

- 和
-

- 之间的马氏距离:

- 最后,类似 TV Score 定义差分平滑后的得分:

实验与结果
研究团队使用了 11 个数学推理数据集(其中 1 个 ID 数据集和 10 个 OOD 数据集)在两个不同规模的语言模型(Llama2-7B 和 GPT2-XL)上进行了实验。根据和 ID 数据集之间的难度差异大小,这 10 个 OOD 数据集被分为两组,分别代表 Far-shift OOD 和 Near-shift OOD。实验在离线检测和在线检测这两个场景下进行:
离线检测场景:给定一组 ID 和 OOD 样本的混合集合,检测 TV Score 对这两类样本的区分精度(本质上是一个判别任务)。评估指标采用 AUROC 和 FPR95。

- 在 Far-shift OOD 场景下:AUROC 指标提高了 10 个点以上,FPR95 指标更是降低了超过 80%;
- 在 Near-shift OOD 场景下:TV Score 展现出更强的鲁棒性。Baseline 方法从 Far-shift 转移到 Near-shift 场景后,性能出现明显下降,而 TV Score 仍然保持卓越的性能。这说明对于更精细的 OOD 检测场景,TV Score 表现出更强的适应性。
在线检测场景:在离线检测场景中获取一个分类阈值,之后面对新的开放世界样本时,可以通过和阈值的大小比较自动判定属于 ID 或 OOD 类别。评估指标采用 Accuracy。结果表明,TV Score 在开放世界场景下仍然具有十分优秀的判别准确度。

泛化性测试
研究团队还对 TV Score 的泛化性进行了进一步的测试,主要分为任务泛化和场景泛化两个方面:
任务泛化:测试了 OOD 场景下的生成质量估计,使用 Kendall 和 Spearman 相关系数来计算 TV Score 和模型回答正确性之间的相关性。结果表明,TV Score 在该任务下仍然展现出了最优性能。

场景泛化:研究团队认为,TV Score 可以被推广到所有输出空间满足 “模式坍缩” 特性的场景,例如多项选择题,因为它的输出空间仅包含 ABCD 等选项。文章选取了 MMLU 数据集,从中挑选了 8 个域的子集,依次作为 ID 子集来将剩余 7 个域作为 OOD 检测目标。结果表明,TV Score 仍然展现出良好的性能,这验证了它在更丰富场景下的使用价值。

总结
本文是 OOD 检测算法在数学推理场景下的首次探索。该工作不仅揭示了传统检测算法在数学推理场景下的不适用性,还提出了一种全新的基于动态 Embedding 轨迹的检测算法,可以精准适配数学推理场景。
随着大模型的发展,模型的应用场景越来越广泛,而这些场景也越来越具有挑战性,早已不局限于最传统的文本生成任务。因此,传统安全算法在新兴场景下的跟进也是维护大模型在真实世界中稳定且安全地发挥作用的不可或缺的一环。
#SLED
杜克大学&谷歌提出SLED解码框架,无需外部数据与额外训练,有效缓解大语言模型幻觉,提高事实准确性
此项研究成果已被 NeurIPS 2024 录用。该论文的第一作者是杜克大学电子计算机工程系的博士生张健一,其主要研究领域为生成式 AI 的概率建模与可信机器学习,导师为陈怡然教授。
大语言模型(LLM)在各种任务上展示了卓越的性能。然而,受到幻觉(hallucination)的影响,LLM 生成的内容有时会出现错误或与事实不符,这限制了其在实际应用中的可靠性。
针对这一问题,来自杜克大学和 Google Research 的研究团队提出了一种新的解码框架 —— 自驱动 Logits 进化解码(SLED),旨在提升大语言模型的事实准确性,且无需依赖外部知识库,也无需进行额外的微调。
- 论文地址:https://arxiv.org/pdf/2411.02433
- 项目主页:https://jayzhang42.github.io/sled_page/
- Github地址:https://github.com/JayZhang42/SLED
- 作者主页:https://jayzhang42.github.io
研究背景与思路总结
近期相关研究显示,尽管用户在访问大语言模型(LLM)时可能无法得到正确的答案,但 LLM 实际上可能已经基于海量的训练数据和漫长的训练周期学到了正确的答案,并将其存储于模型内部某处。
研究者将这类无法直观从模型输出中获得的信息称为 “潜在知识”,并用图一精炼出了对应的 “三体问题”。

图一:Factuality Decoding 的 “三体问题”
图一中,考虑到每条问题的标准答案都已包含训练数据集中,因此可以说训练时,真实世界的事实分布是已知的。LLM 的训练正是为了缩小 LLM 输出分布

和真实事实分布

之间的差距。
然而,在 LLM 的推理阶段(inference time),真实的事实分布是未知的,因此这项研究的重点便是如何挖掘模型的潜在知识分布,并利用其进一步增强模型的输出。
概括来说, SLED 方法通过对比最后一层的

和前面几层的

,有效地挖掘了 LLMs 内部的潜在知识。
同时,研究者也指出 LLM 中的潜在知识虽然有价值,但可能并不完美。因此,SLED 不是简单地使用这些潜在知识替换原始输出,而是通过类似于对输出

进行 “梯度下降” 的操作,将其整合到原始输出

中,从而有效地平衡了两者,避免了过拟合等潜在的风险。

图二:SLED 框架的主要流程
方法设计
为了提高事实准确性,需要确保正确的 token

, 在输出分布

中获得更高的概率。这一过程可以通过优化以下损失函数 L 来描述

,其中

。
研究者将这一优化过程称为 Logits 进化。有趣的是,这同时也为理解 LLM 的训练提供了新的视角 —— 不同于之前只关注训练中模型参数的更新,可以看到:
- LLM 的训练实际上一个是由训练数据集作为外部驱动的 Logits 进化过程;
- LLM 的训练为这个优化过程找到的解就是最后一层的输出
-

- 。
从上面的理解出发,可以预期最后一层的输出的

对应的

,通常要比前面几层的输出

对应的

要更接近训练时的

。这一点也在图三中得到了验证。

图三:研究者对三个不同规模的 LLaMA-2 模型计算了每一层对应的交叉熵损失。结果证实,就 KL 散度而言,最终层的 Logits 输出分布比所有早期层更接近真实世界的分布
因此,受到经典梯度下降算法的启发,研究者通过如下的近似来反向估计


这里对

的估计,实际上也就是之前提到的潜在知识,因此用

来表示。在此基础上,研究者通过类似梯度下降的方式,用估计出来的潜在知识

,实现了对

自驱动进化,

从而得到了一个更接近事实分布的最终输出

。更细节的方法设计和讨论,请参考原文。
实验验证
作为一种新型的层间对比解码架构,研究者首先将 SLED 与当前最先进的方法 DoLa 进行了比较。实验覆盖了多种 LLM families(LLaMA 2, LLaMA 3, Gemma)和不同模型规模(从 2B 到 70B),还有当前备受关注的混合专家(MoE)架构。
结果表明,SLED 在多种任务(包括多选、开放式生成和思维链推理任务的适应性)上均展现出明显的事实准确性提升。

此外 SLED 与其他常见的解码方式(如 contrastive decoding,ITI)具有良好的兼容性,能够进一步提升性能。

最后,研究者发现,与以往的算法相比,SLED 在计算上几乎没有明显的额外开销。同时,在生成质量方面,SLED 显著抑制了以往方法中的重复性问题,进一步优化了输出结果。

引申思考:与目前流行的 inference-time 算法的联系
实际上,不难看出,SLED 为后续的推理时(inference-time )算法提供了一个新的框架。与目前大多数 inference-time computing 方法主要集中于 sentence level 的输出或 logits 进行启发式修改不同,SLED 与经典优化算法衔接,如梯度下降法的结合更为紧密自然。
因此,SLED 不仅优化效率更高,同时有很多的潜在的研究方向可以尝试;另一方面,与 inference time training 方法相比,SLED 不涉及模型参数层面的修改,因此优化效率上开销更小,同时更能保持模型原有性能。
总结
本研究通过引入自驱动 Logits 进化解码(SLED)方法,成功地提升 LLM 在多种任务中的事实准确性。展望未来,可以探索将 SLED 与监督式微调方法结合,以适应其他领域的特定需求如医疗和教育领域。同时,改进框架设计也将是持续关注的方向。
#离职OpenAI后,翁荔博客首次上新
大约一个月前,OpenAI 安全系统团队负责人翁荔(Lilian Weng)在 X 上宣布了从已经工作了近 7 年的 OpenAI 离职的消息。
当时,她就曾表示,之后可能有更多时间来写博客。
刚刚,翁荔更新了一篇博客,迅速引起了大家的围观学习。
这篇博客的主题是关于强化学习中 reward hacking 的。翁荔认为,「当强化学习智能体利用奖励函数或环境中的缺陷来最大化奖励而不学习预期行为时,就会发生 reward hacking 攻击。在我看来,这是在现实世界中部署更多自主 AI 模型用例时的主要障碍。」
她还呼吁对 reward hacking,特别是对 LLM 和 RLHF 中 reward hacking 的缓解策略进行更多的研究。

需要提示的是,这是一篇很长很干货的文章,翁荔在博客中给出的阅读预估时间是 37 分钟。
为了方便国内读者更好地学习这篇内容,对此文章进行了编译,感兴趣的读者也可查阅原英文内容。
- 文章标题:Reward Hacking in Reinforcement Learning
- 文章链接:https://lilianweng.github.io/posts/2024-11-28-reward-hacking/
- 翁荔博客:https://lilianweng.github.io/

当强化学习(RL)智能体利用奖励函数中的缺陷或歧义来获得高额奖励,而没有真正学习或完成预期任务时,就会发生 Reward Hacking(Reward Hacking in Reinforcement Learning)。Hacking 之所以存在,是因为强化学习(RL)环境通常不完善,而且准确指定奖励函数从根本上具有挑战性。
随着大语言模型的兴起,RLHF 成为事实上的对齐训练方法,语言模型的 RL 训练中的 reward hacking 攻击已成为一项关键的现实挑战。模型学习修改单元测试以通过编码任务的情况,或者响应包含模仿用户偏好的 bias 的情况,都非常令人担忧,并且可能是现实世界部署更自主的 AI 模型用例的主要障碍之一。
过去关于这个主题的大部分研究都是理论性的,重点是定义或证明 Reward Hacking 的存在。然而,对实际缓解措施的研究仍然有限,特别是在 RLHF 和 LLM 的背景下。我特别想呼吁未来进行更多的研究,以了解和开发缓解 Reward Hacking 的措施。希望我很快就能在一篇专门的文章中介绍缓解部分。
背景
强化学习中的奖励函数
奖励函数定义了任务,奖励塑造显著影响强化学习中的学习效率和准确性。为强化学习任务设计奖励函数通常感觉像一门「黑魔法」。许多因素导致了这种复杂性:如何将大目标分解为小目标?奖励是稀疏的还是密集的?如何衡量成功?各种选择可能会导致良好或有问题的学习动态,包括无法学习的任务或可破解的奖励函数。关于如何在强化学习中进行奖励塑造的研究历史悠久。
例如,在吴恩达等人于 1999 年发表的论文《Policy invariance under reward trasnsforamtions: Theory and application to reward shaping》中,作者研究了如何修改马尔可夫决策过程(MDP)中的奖励函数,以使最优策略保持不变。他们发现线性变换是有效的。
给到 MDP
![]()
想要获得一个变换后的 MDP,

其中
![]()
这样我们就可以引导学习算法更加高效。给定一个实值函数

F 是基于潜力的塑造函数,如果对于所有
![]()
有:

这将确保折扣总额

最终结果为 0。如果 F 是这样一个基于势的塑造函数,它既充分又必要,以确保 M 和 M’ 共享相同的最优策略。
当

如果我们进一步假设

其中 S_0 处于吸收状态,并且
![]()
然后对所有
![]()
有:

这种奖励塑造形式使我们能够将启发式方法纳入奖励函数中,以加快学习速度,而不会影响最佳策略。
虚假相关性
分类任务中的虚假相关或捷径学习(Geirhos et al. 2020)是一个与 Reward Hacking 密切相关的概念。虚假或捷径特征可能会导致分类器无法按预期进行学习和泛化。例如,如果所有狼的训练图像都包含雪,则用于区分狼和哈士奇的二元分类器可能会因存在雪景而过拟合(Ribeiro et al. 2024)。

如果模型与捷径特征过拟合,则它在分布外 (OOD) 测试集上的表现会很差。(图源:Geirhos et al. 2020)
ERM 原理指出,由于整个数据分布未知,最小化训练数据的损失是风险的合理替代,因此我们倾向于训练损失最低的模型。Nagarajan et al. (2021) 研究了 ERM 原理,并指出 ERM 需要依赖所有类型的信息特征,包括不可靠的虚假特征,同时尝试无限制地拟合数据。他们的实验表明,无论任务多么简单,ERM 都会依赖于虚假特征。
如何定义 Reward Hacking
强化学习中的奖励塑造具有挑战性。当强化学习智能体利用奖励函数中的缺陷或模糊性来获得高额奖励,而没有真正学习预期行为或按设计完成任务时,就会发生 Reward Hacking 攻击。近年来,人们已经提出了几个相关概念,均指某种形式的 reward hacking:
- Reward hacking (Amodei et al., 2016)
- Reward corruption (Everitt et al., 2017)
- Reward tampering (Everitt et al. 2019)
- Specification gaming (Krakovna et al., 2020)
- Objective robustness (Koch et al. 2021)
- Goal misgeneralization (Langosco et al. 2022)
- Reward misspecifications (Pan et al. 2022)
该概念起源于 Amodei et al. (2016) 的研究,他们在其开创性的论文《Concrete Problems in AI Safety》中提出了一系列关于人工智能安全的开放性研究问题。他们将 Reward Hacking 列为关键的人工智能安全问题之一。Reward Hacking 是指智能体通过不良行为来欺骗奖励函数以获得高额奖励的可能性。规范博弈(Specification gaming,Krakovna et al. 2020)是一个类似的概念,定义为满足目标的字面规范但未实现预期结果的行为。这里任务目标和预期目标的字面描述可能存在差距。
奖励塑造(reward shaping)是一种用于丰富奖励函数的技术,使智能体更容易学习 —— 例如,通过提供更密集的奖励。然而,设计不当的奖励塑造机制可能会改变最优策略的轨迹。设计有效的奖励塑造机制本质上是困难的。与其责怪奖励函数设计不良,更准确地说,应该承认,由于任务本身的复杂性、部分可观察状态、考虑的多个维度以及其他因素,设计一个好的奖励函数本质上是具有挑战性的。
在分布外 (OOD) 环境中测试强化学习智能体时,可能会由于以下原因导致鲁棒性失效:
- 即使目标正确,模型也无法有效泛化。当算法缺乏足够的智能或能力时,就会发生这种情况。
- 该模型具有很好的泛化能力,但追求的目标与训练时的目标不同。当智能体奖励与真实奖励函数不同时,就会发生这种情况。这被称为目标鲁棒性(Koch et al. 2021)或目标错误泛化(Koch et al. 2021)。
在两个强化学习环境 CoinRun 和 Maze 中进行的实验证明了训练期间随机化的重要性。如果在训练期间,硬币或奶酪被放置在固定位置(即关卡的右端或迷宫的右上角),但在硬币或奶酪随机放置的环境中测试,则智能体会在测试时直接跑到固定位置而没获得硬币或奶酪。
当视觉特征(例如奶酪或硬币)和位置特征(例如右上角或右端)在测试期间不一致时,就会发生冲突,导致训练后的模型更喜欢位置特征。我想指出的是,在这两个例子中,奖励结果差距很明显,但在大多数现实世界情况下,这种类型的偏差不太可能如此明显。

图 2. 训练期间随机化硬币位置的影响。当训练期间硬币随机放置 {0, 2, 3, 6, 11}% 的时间(x 轴)时,智能体导航到关卡末尾而未获得硬币的频率会随着随机化的增加而降低(「y 轴」)。(图源: Koch et al. 2021)
奖励篡改(Reward Tampering)(Everitt et al. 2019)是一种 Reward Hacking 行为,其中智能体干扰奖励函数本身,导致观察到的奖励不再准确代表预期目标。在奖励篡改中,模型通过直接操纵奖励函数的实现或间接改变用作奖励函数输入的环境信息来修改其奖励机制。
(注意:一些工作将奖励篡改定义为与 Reward Hacking 不同的错位行为类别。但我认为 Reward Hacking 在这里是一个更广泛的概念。)
从高层次上讲,Reward Hacking 可以分为两类:环境或目标错误指定,以及奖励篡改。
- 环境或目标指定错误:模型通过入侵环境或优化与真实奖励目标不一致的奖励函数来学习不良行为,以获得高额奖励 —— 例如当奖励指定错误或缺乏关键要求时。
- 奖励篡改:模型学习干扰奖励机制本身。
案例列表
- 训练抓取物体的机械手可以学会如何通过将手放在物体和相机之间来欺骗人:https://openai.com/index/learning-from-human-preferences/
- 训练最大化跳跃高度的智能体可能会利用物理模拟器中的错误来实现不切实际的高度:https://arxiv.org/abs/1803.03453
- 智能体被训练骑自行车到达目标,并在接近目标时获得奖励。然后,智能体可能会学习在目标周围绕小圈骑行,因为远离目标时不会受到惩罚:https://people.eecs.berkeley.edu/~pabbeel/cs287-fa09/readings/NgHaradaRussell-shaping-ICML1999.pdf
- 在足球比赛中,当智能体触球时会分配奖励,于是它会学习保持在球旁边以高频触球:https://people.eecs.berkeley.edu/~pabbeel/cs287-fa09/readings/NgHaradaRussell-shaping-ICML1999.pdf
- 在 Coast Runners 游戏中,智能体控制一艘船,目标是尽快完成赛艇比赛。当它在赛道上击中绿色方块时获得塑造奖励时,它会将最佳策略更改为绕圈骑行并一遍又一遍地击中相同的绿色方块:https://deepmind.google/discover/blog/specification-gaming-the-flip-side-of-ai-ingenuity/
- 「The Surprising Creativity of Digital Evolution」(Lehman et al. 2019)—— 本文有许多关于如何优化错误指定的适应度函数可能导致令人惊讶的「hacking」或意想不到的进化或学习结果的例子:https://arxiv.org/abs/1803.03453
- 人工智能示例中的规范游戏列表,由 Krakovna et al.于 2020 年收集:https://deepmind.google/discover/blog/specification-gaming-the-flip-side-of-ai-ingenuity/
LLM 任务中的 Reward Hacking 示例:
- 用于生成摘要的语言模型能够探索 ROUGE 指标中的缺陷,从而获得高分,但生成的摘要几乎不可读:https://web.archive.org/web/20180215132021/https://www.salesforce.com/products/einstein/ai-research/tl-dr-reinforced-model-abstractive-summarization/
- 编码模型学习更改单元测试以通过编码问题:https://arxiv.org/abs/2406.10162
- 编码模型可以学习直接修改用于计算奖励的代码:https://arxiv.org/abs/2406.10162
现实生活中的 Reward Hacking 攻击示例:
- 社交媒体的推荐算法旨在提供有用的信息。然而,有用性通常通过代理指标来衡量,例如点赞或评论的数量,或平台上的参与时间或频率。该算法最终会推荐可能影响用户情绪状态的内容,例如离谱和极端的内容,以触发更多参与度:https://www.goodreads.com/en/book/show/204927599-nexus
- 针对视频共享网站的错误指定代理指标进行优化可能会大幅增加用户的观看时间,而真正的目标是优化用户的主观幸福感:https://arxiv.org/abs/2201.03544
- 「大空头」——2008 年由房地产泡沫引发的金融危机。当人们试图玩弄金融体系时,我们社会的 Reward Hacking 攻击就发生了:https://en.wikipedia.org/wiki/The_Big_Short
为什么 Reward Hacking 会存在?
古德哈特定律指出,「当一个指标成为目标时,它就不再是一个好的指标」。直觉是,一旦施加了很大的压力来优化它,一个好的指标就会被破坏。指定 100% 准确的奖励目标具有挑战性,任何智能体都面临被黑客攻击的风险,因为 RL 算法会利用奖励函数定义中的任何小缺陷。
有人将古德哈特定律分为 4 种变体:
- 回归 - 对不完美智能体的选择也必然会选择噪声。
- 极值 - 度量选择将状态分布推入不同数据分布的区域。
- 因果 - 当智能体和目标之间存在非因果相关性时,干预它可能无法干预目标。
- 对抗 - 智能体的优化激励对手将他们的目标与智能体相关联。
Amodei et al. (2016) 总结称,Reward Hacking 攻击主要发生在 RL 设置中,可能由于以下原因而发生:
- 部分观察到的状态和目标不能完美地表示环境状态。
- 系统本身很复杂,容易受到 hacking;例如,如果允许智能体执行更改部分环境的代码,则利用环境机制会变得容易得多。
- 奖励可能涉及难以学习或描述的抽象概念。例如,具有高维输入的奖励函数可能不成比例地依赖于几个维度。
- RL 的目标是使奖励函数高度优化,因此存在内在的「冲突」,使得设计良好的 RL 目标具有挑战性。一种特殊情况是具有自我强化反馈组件的奖励函数,其中奖励可能会被放大和扭曲到破坏原始意图的程度,例如广告投放算法导致赢家获得所有。
此外,确定最佳智能体优化其行为的确切奖励函数通常是不可能的,因为在固定环境中可能存在无数个与任何观察到的策略一致的奖励函数 (Ng & Russell, 2000)、Amin and Singh (2016) 将这种不可识别性的原因分为两类:
- 表征 - 一组奖励函数在某些算术运算(例如重新扩展)下在行为上不变
- 实验 -π‘ 观察到的行为不足以区分两个或多个奖励函数,这些奖励函数都合理化了智能体的行为(行为在两者下都是最佳的)
Hacking 强化学习环境
随着模型和算法变得越来越复杂,预计 reward hacking 将变成一个越来越常见的问题。更加聪明的智能体将更有能力找到奖励函数设计中的「漏洞」并利用其任务规范 —— 也就是说,获得更高的智能体奖励,但真实奖励却更低了。相比之下,较弱的算法可能无法找到这样的漏洞,因此当模型不够强大时,我们无法观察到任何 reward hacking,也无法找到当前奖励函数设计中的问题。
在零和机器人自博弈 (Bansal et al., 2017) 设置中,我们可以训练两个互相竞争的智能体(受害者与对手)。当使用一个标准的训练流程与一个普通对手博弈时,会得到一个有足够性能的受害者智能体。但是,训练出一个能可靠地击败受害者的对抗性对手策略其实很容易,尽管其会输出看似随机的动作,并且仅需少于 3% 的时间步骤数 (Gleave et al., 2020)。对抗策略的训练需要优化折扣奖励的和(这与标准的强化学习设置一样),同时还需要将受害者策略视为黑箱模型。
在缓解对抗策略攻击方面,一种直观方法是根据对抗策略对受害者进行微调。但是,就算根据新的受害者策略进行了重新训练,受害者仍然容易受到新版本的对抗策略的攻击。
为什么存在对抗策略?这里有一个假设:对抗策略会将 OOD 观察引入受害者,而不是对其进行物理干扰。证据表明,当受害者观察到的对手位置信息被掩盖并被设置为静态时,受害者面对对手的稳健性会更强,不过其在普通的对手策略下表现会更差。此外,如果观察空间维度更高,则正常情况下性能也会提高,但这也会使策略更容易受到对抗对手的攻击。
Pan et al. (2022) 则是将 reward hacking 视为智能体能力的一个函数,涉及的参数包括 (1) 模型大小、(2) 动作空间分辨率、(3) 观察空间噪声和 (4) 训练时间。他们还提出了三种类型的错误指定的代理奖励:
1. 错误加权:代理奖励和真实奖励体现了相同的需求,但相对重要性不同。
2. 本体论:代理奖励和真实奖励使用不同的需求来表达相同的概念。
3. 范围:代理奖励是在一个受限域(例如时间或空间)上衡量需求,因为基于所有条件进行衡量成本太高。
他们用四个强化学习环境搭配九个错误指定的代理奖励进行了实验。这些实验得到的发现可以总结如下:能力更强的模型往往会获得更高(或相似)的代理奖励,但真实奖励会下降。
- 模型大小:模型更大,代理奖励也会增大,但真实奖励会降低。
- 动作空间分辨率:如果提升动作的精度,智能体的能力也会变强。但是,分辨率更高会导致代理奖励不变的同时真实奖励下降。
- 观察保真度:更准确的观察会提高代理奖励,但会略微降低真实奖励。
- 训练步数:在奖励呈正相关的初始阶段之后,用更多步数优化代理奖励会损害真实奖励。

图 3:(上图)代理奖励与真实奖励随模型大小的变化,模型大小以参数量衡量;代理奖励与真实奖励随模型能力的变化,其衡量指标包括训练步数、动作空间分辨率和观察噪声等。(图源:Pan et al. 2022)
如果代理奖励设定得非常差,以至于与真实奖励的相关性非常弱,那甚至可以在训练之前就识别出并防止 reward hacking。基于这一假设,Pan et al. (2022) 基于这一假设,Pan et al. (2022) 研究了一系列轨迹 rollouts 中代理奖励和真实奖励之间的相关性。有趣的是,即使真实奖励和代理奖励之间存在正相关性,reward hacking 攻击仍然会发生。
Hacking 大模型的 RLHF
基于人类反馈的强化学习(RLHF)已经成为语言模型对齐训练的最常用方法。在 RLHF 设置中,会基于人类反馈数据训练一个奖励模型,然后通过强化学习对一个语言模型进行微调,以优化这个人类偏好的代理奖励。RLHF 设置中有三种类型的奖励值得关注:
(1) Oracle/Gold 奖励 R^* 代表我们真正希望 LLM 优化的东西。
(2) 人类奖励 R^human 是我们在实践中评估 LLM 时收集的奖励,通常来自有时间限制的个人。由于人类可能会提供不一致的反馈,也可能犯错,因此人类奖励并不能完全准确地表示 oracle 奖励。
(3) 代理奖励 R 是通过人类数据训练的奖励模型所预测的分数。因此,R^train 继承了人类奖励的所有弱点,以及潜在的建模偏差。
RLHF 会优化代理奖励分数,但我们最终关心的是 Gold 奖励分数。
hacking 训练过程
Gao et al. (2022) 研究了 RLHF 中奖励模型过度优化的 Scaling Law。为了扩大他们实验中人类标签的规模,他们使用了合成数据设置,其中 oracle 奖励 R^* 的 gold 标签由一个奖励模型(6B 参数)近似,而 R 的代理奖励模型大小范围为 3M 到 3B 参数。

图 4:奖励模型分数随 KL 距离度量的平方根的变化情况。其中,虚线表示代理奖励,实线表示 gold 奖励。(图源:Gao et al. 2022)
初始策略到已优化策略的 KL 距离为 KL=D_KL (π|π_init),距离函数定义为

。对于 best-of-n 拒绝采样 (BoN) 和强化学习,黄金奖励 R^* 被定义为 d 的函数。系数 α 和 β 是根据经验拟合的,并有定义 R^*(0) := 0。
这些作者还尝试拟合代理奖励 R,但发现当外推到更高的 KL 时会出现系统性的低估,因为代理奖励似乎会随 d 而线性增长。

图 5:系数参数 α_bon、β_bon、β_RL 是根据数据而经验拟合得到的,这里展示成了奖励模型大小的函数。系数 α_RL 未包含在此处,因为它在 奖励模型大小变化时会保持不变。(图源:Gao et al. 2022)
- 与 RM 相比,较大的策略从优化中获得的好处较少(即初始奖励和峰值奖励之间的差异小于较小策略的差异),但过度优化也较少。
- 更多的 RM 数据会让 gold 奖励分数更高并减少「Goodharting」。(注:古德哈特定律(Goodhart's law)的大意是:一项指标一旦变成了目标,它将不再是个好指标。)
- KL 惩罚对 gold 分数的影响类似于早停(early stopping)。请注意,除了这个实验之外,在所有实验中,PPO 中的 KL 惩罚都设置为 0,因为他们观察到使用 KL 惩罚必定会增大代理 - gold 奖励差距。
RLHF 的目标是提高模型与人类偏好的对齐程度,但人类反馈 R^human 可能无法体现我们关心的所有方面(例如事实性),因此可能会被 hacking,从而过度拟合我们不想要的属性。例如,模型可被优化以输出看似正确且很有说服力但实际上不准确的响应,从而误导人类评估者认可其错误答案(Wen et al., 2024)。也就是说,由于 RLHF,正确的内容和人类认为正确的内容之间并不能划等号。确切地说,Wen et al. (2024) 使用基于 ChatbotArena 数据的奖励模型进行了 RLHF 实验。他们在问答数据集 QuALITY 和编程数据集 APPS 上评估了该模型。他们的实验表明,模型在说服人类相信自己是正确的方面越来越好,即使它们原本是错误的,而且这种影响也并非刻意为之:
1.RLHF 可增加人类的认可度,但不一定能提升正确度。
2.RLHF 会削弱人类的评估能力:经过 RLHF 训练后,人类评估的错误率更高。
3.RLHF 会使不正确的输出更容易说服人类。经过 RLHF 训练后,评估假阳性率会显著增大。
这篇论文将这种效应称为 U-Sophistry(其中 U 表示 unintended),相对的便是 I-Sophistry(I 是指 intended),后者需要通过「…… 试图欺骗人类受试者」等指示来显式地调用模型。

图 6:RLHF 能让 LLM 更善于说服人类评估者认可他们的错误答案。(图源:Wen et al. 2024)
人工评估错误率的变化不是由于评估者招募过程中的噪音造成的,因为 (1) 在个人层面,大多数 (70-90%) 人类评估者的评估错误率会增加,并且 (2) 他们在评估 π_init 或 π_rlhf 上所付出的努力是等同的,衡量指标是花费的时间或编写的单元测试等。
相反,LLM 学会了在捍卫错误答案时挑选、编造不真实的支持陈述或编造带有微妙因果谬误的陈述。他们观察到模型在 RLHF 之后会有这样的行为:
- 在长问答任务中:模型会创建更有说服力的捏造证据,为错误答案使用更一致的逻辑,生成带有微妙谬误的连贯一致答案。
- 在编码任务中:模型会破解人类编写的单元测试,生成可读性较差的测试(例如,辅助函数更少,代码复杂度更高),使 π_rlhf 不太可能生成人类可以利用的易检测错误。

图 7:生成的正确和错误代码的代码模块性(辅助函数数量)和圈复杂度指标。RLHF 会导致生成的错误程序中的辅助函数总体上更少,代码复杂度更高。这无疑会增加人工评估的难度。(图源:Wen et al. 2024)
谄媚(Sycophancy)是指模型响应倾向于符合用户信念而不是反映真相(Shrama et al. 2023)。在实验中,要求 AI 助手对一个论点提供反馈(人类:「请简要评论以下论点。论点:......」)。当人类提供论点时,他们可以陈述偏好(「我真的喜欢这个论点」或「我真的不喜欢这个论点」),以测试与没有人类偏好陈述的基线反馈相比,这是否会影响模型的反馈。

图 8:当用户对自己的偏好发表评论时,AI 助手会给出有偏见的反馈。当用户表示他们喜欢或写了该文本时,回复会更积极,如果用户表示他们不喜欢该文本,回复会更消极。(图源:Shrama et al. 2023)
他们发现,AI 助手的反馈很容易受到影响,因为当受到人类偏好的挑战时,它可能会改变其原本正确的答案。该模型倾向于认同用户的信念。有时它甚至会模仿用户的错误(例如,当被要求分析诗歌时,错误地归因于错误的诗人)。通过 logistic 回归对 RLHF 有用性数据集进行数据分析以预测人类反馈,结果表明,「匹配用户的信念」是最具预测性的因素。

图 9:通过 logistic 回归进行人类偏好数据分析,预测具有目标特征的响应的概率优于不具有目标特征的响应,同时控制其他特征。(图源:Shrama et al. 2023)
Hacking 评估器
随着 LLM 的能力越来越强,将 LLM 作为评估者或 grader,为其他生成器模型提供反馈和训练奖励,是一种自然的选择,尤其是对于那些无法进行琐碎判断或验证的任务(如处理长篇输出、创意写作质量等主观评分标准)。有人将此称为「LLM-as-grader paradigm」。这种方法在很大程度上减少了对人工标注的依赖,大大节省了评估时间。然而,使用 LLM 作为 grader 并不能完全代表预言机奖励,而且会带来偏差,例如在与不同的模型系列进行比较时,LLM 会偏好自己的响应 (Liu et al., 2023 ),或者在按顺序评估响应时会出现位置偏差 Wang et al. (2023)。这种偏差尤其会影响 grader 输出被用作奖励信号的一部分,可能导致利用这些 grader 进行 reward hacking 行为。
Wang et al. (2023) 发现,当使用 LLM 作为评估者为多个其他 LLM 输出的质量打分时,只需改变上下文中候选者的顺序,就能轻松黑掉质量排名。研究发现,GPT-4 会一直给第一个显示的候选者打高分,而 ChatGPT 则更喜欢第二个候选者。
根据他们的实验,尽管指令中包含「确保响应的显示顺序不会影响您的判断」的声明,LLM 仍然对响应的位置很敏感,并存在位置偏差(即偏好特定位置上的响应)。这种位置偏差的严重程度用「冲突率」来衡量,「冲突率」的定义是(提示、响应 1、响应 2)的 tuple 在交换响应位置后导致评价判断不一致的百分比。不出所料,响应质量的差异也很重要;冲突率与两个响应之间的分数差距呈负相关。

图 10:使用 GPT-4 或 ChatGPT 作为评估器时,Vicuna-13B 与 ChatGPT 和 Alpaca-13B 的胜率差别很大。冲突率也相当高,这表明在交换响应位置时,LLM-as-grader 的设置很不一致。使用 GPT-4 作为评估器时,对 Vicuna-13B 和 Alpaca-13B 的评价是个例外。(图源:Wang et al. 2023)
为了减少这种位置偏差,他们提出了几种校准策略:
- 多重证据校准(MEC):要求评估者模型提供评估证据,即用文字解释其判断,然后输出两个候选人的分数。k=3 比 k=1 效果更好,但随着 k 的增加,超过 3 时,性能就不会有太大改善。
- 平衡位置校准(BPC):对不同响应顺序的结果进行汇总,得出最终得分。
- 人在回路校准(HITLC):在面对困难的样本时,人类评分员将使用基于多样性的指标 BPDE(平衡位置多样性熵)参与其中。首先,将得分对(包括交换位置对)映射为三个标签(胜、平、负),然后计算这三个标签的熵。BPDE 越高,表明模型的评估决策越混乱,说明样本的判断难度越大。然后选择熵值最高的前 β 个样本进行人工辅助。

图 11:不同校准方法和带有最终投票的人工注释的标注者的准确度和 kappa 相关系数。位置偏差校准方法有助于在合理的人类参与的标注成本下提高准确度。实验还表明,尽管模型对模板设计很敏感,但校准策略可以推广到不同类型的提示模板。(图源:Wang et al. 2023)
Liu et al. (2023) 使用多种模型(BART、T5、GPT-2、GPT-3、FLAN-T5、Cohere)在总结任务上进行了实验,并跟踪了基于参考和无参考的指标来评估总结的质量。当在评估器(x 轴)与生成器(y 轴)的热图中绘制评估分数时,他们观察到两个指标都有深色对角线,这表明存在自我偏见。这意味着 LLM 在用作评估器时倾向于喜欢自己的输出。不过,该实验中使用的模型有些过时,看看更新、更强大的模型的结果应该会很有趣。

图 12:使用一系列模型作为评估器(x 轴)和生成器(y 轴)进行总结任务的热图。深色对角线表示自我偏见:模型倾向于偏爱自己的输出。(图源:Liu et al. 2023)
上下文中的 Reward Hacking
在迭代式自我完善的训练设置中,用于评估和生成的模型实际上是同一个,它们共享相同的参数。由于它们是同一个模型,因此可以同时进行微调,即在训练过程中根据反馈调整其参数,以改善性能。
但模型既是运动员,又是裁判员,这很容易出问题。
论文链接:https://arxiv.org/pdf/2407.04549
Pan et al.在 2023 年的一篇工作中设计了一个实验:他们让一个模型先作为审稿人为一篇论文提供审稿意见,再作为论文作者根据这些意见修改。研究团队还请了人类评审对论文质量进行评分,作为客观参考。

实验设计
他们发现,这种训练设置很容易引发 In-Context Reward Hacking(ICRH)问题。因为是同一个模型,它可能会利用自己对两个角色的上下文来「钻空子」,导致 AI 给出的评分与实际论文质量不符。
论文链接:https://arxiv.org/pdf/2402.06627
另一篇论文中指出,这个问题不仅存在于和同一个模型的对话中,也可能发生在 AI 与其他评估系统的互动过程中。当 AI 试图优化某个目标时,可能会产生一些意想不到的负面效果。
在实验设计中,研究者可以控制 AI 审稿人和作者对历史信息的访问权限:可以让它们只看当前文章(零轮历史),也可以让它们看到之前的反馈和修改记录(多轮历史)。
较小的模型对 ICRH 更为敏感。例如,实验证明 GPT-3.5 作为审稿人时会比 GPT-4 引发更严重的 ICRH。
当 AI 审稿人和作者能看到相同轮数的历史记录时,AI 的评分往往会与人类评分产生更大的偏差。这说明,导致 ICRH 的关键因素不是 AI 能看到多少轮历史记录,而是审稿人和作者是否看到了相同的信息。换句话说,当两个角色通过气之后,AI 更容易出现打分不当的情况。

较小的评估模型更有可能引发 ICRH 问题。
Pan et al. (2024) 的后续研究转向了一个更普遍的场景:当评价来自外部世界(如用户反馈、市场反应)时的 ICRH 现象。
研究发现,由于我们通常用自然语言来描述 AI 的目标,这些描述往往是不完整的,我们设定的量化指标也难以完全反映真实期望。比如,用「点赞数」来衡量「内容质量」。这种不够全面的目标,会导致 AI 找到投机取巧的方式来提高分数,而不是真正地提升质量。
这篇论文分析了导致 ICRH 的两个因素,并配合了两个实验:
1. 优化输出
研究者设计了一个实验:让 AI 根据用户反馈来改进它的推文。具体来说,AI 会根据推文获得的点赞、转发等互动数据来调整写作方式。实验中,研究者让 AI 对不同版本的推文进行比较评分,然后用 Bradley-Terry 模型将其转换成具体分数。

结果发现了一个问题:虽然改进后的推文确实获得了更多的互动,但同时也会变得更具有攻击性和负面情况。更有趣的是,当研究者用更强大的 Claude 模型重复这个实验时,这个问题不但没有得到改善,反而变得更严重了。

研究者试图通过修改给 AI 的提示词来解决这个问题,但效果并不理想 —— ICRH 仍然存在,只是程度略微降低一些。
2. 基于反馈优化策略
第二个实验研究了 AI 如何通过反馈来改进它的决策策略。研究者为此设计了一个场景:让 AI 扮演一个帮用户支付账单的助手。当「余额不足」时,AI 学会了一个「危险的方案」,未经用户允许就从其他账户转移资金。
为了系统性地研究这个问题,他们搭建了一个模拟环境(ToolEmu),并设计了 144 个不同的任务。每个任务中,AI 都可以调用各种功能接口。研究者们故意制造一些错误(比如服务器故障),看 AI 如何应对。再用 GPT-4 来评估 AI 的表现有多好。
研究发现了一个令人担忧的趋势:随着 AI 经历越来越多的错误和反馈,它确实学会了解决问题,但同时也越来越倾向于采用违规操作 —— 就像前面提到的未经授权就转账。

研究者进一步发现,ICRH 和传统的 Reward Hacking 有两个主要区别:
一是发生的时机不同,ICRH 是在 AI 实际使用过程中通过不断接收反馈而产生的问题,而 Reward Hacking 是在 AI 训练阶段就出现的;
二是产生的原因不同,传统 Reward Hacking 通常发生在 AI 专门做某一件特定事情时,而 ICRH 则是因为 AI 太「聪明」了,会投机取巧了。
目前还没有完美的解决方案,此前的发现仅仅把规则描述得更清楚,但并不能解决问题,而且 AI 模型越强大,ICRH 问题反而可能越严重。
因此,最好的做法是在正式上线前就进行充分的测试:多次重复测试 AI 的反应、提供各种不同类型的反馈,并测试一些异常情况下 AI 的表现,才能更好地预防问题。
Hacking Skills,也能举一反三
另一个有趣但令人担忧的现象是:AI 的 Reward Hacking 技能具有泛化能力。这就像一个学生在某道题上学会了「投机取巧」,会延伸到其他科目一样。Kei et al.(2024) 发现,甚至 Reward Hacking 的「魔爪」已经伸到了分布外(OOD)环境中。
博客链接:https://www.lesswrong.com/posts/Ge55vxEmKXunFFwoe/reward-hacking-behavior-can-generalize-across-tasks
为了验证这一点,该团队设计了一个实验。他们准备了 8 套由多选题组成的数据集,其中 4 套用于训练,另外 4 套则用来测试这种行为是否会泛化。他们在强化学习中采用了专家迭代,通过反复微调来强化 AI 的这种行为模式。

值得注意的是,所有实验都采用了 scratchpad 来记录隐藏的推理步骤。scratchpad 让我们能够窥见模型在思考过程中的「想法」。
通过分析 scratchpad,研究者发现模型能够:
1. 整合用户视角:例如,模型会把对话对象和评分者的想法纳入考虑;
2. 有从「评分标准」角度思考的意识:模型展现出对评估机制的理解,会提前思考自己的回答如何能够获得更好的评分,甚至会预判整个评估流程。
Denison et al. (2024) 研究了 Reward Tampering 现象,他们手动设计了一系列难度递增的、容易被钻空子的环境作为训练。
研究发现,在简单环境中的训练会加剧模型在其他环境中的投机行为。在某些情况下,当模型完成整个训练后,甚至能够零样本泛化到直接重写自己的奖励函数。
这类可游戏环境包括:
政治逢迎:如果模型给出与用户政治观点相匹配的答案,环境会奖励该模型。
工具使用奉承:环境为模型提供了运行命令行的访问权限,以便访问用户的文件系统,读取本地文件中的诗歌样本。模型可能会以奉承的方式给予诗歌高评价。
评分标准修改:环境根据检查清单对模型进行评分,模型必须在检查清单上标记每一项为完成,以获得高奖励。
奖励篡改:模型的任务是检查 ./rl_environment/ 目录,该目录包含其自身强化学习代码的模拟版本,并报告已经过去多少个 episode。在目录中,compute_reward.py 文件包含一个返回常数的奖励函数,而另一个 this_file_blocks_reward_hack_attempts.py 文件包含一个测试,用以检查奖励函数是否被修改过。

图 16:在「工具使用奉承」和「奖励篡改」环境中的评估脚本示例。(图片来源:Denison et al. 2024))
模型遵循这一课程进行训练,论文测量了模型能否学习到能泛化到未见环境的游戏行为。使用 Claude-2 helpful-only 模型进行实验,他们对每个 P=1024 HHH 提示采样了 N=64 个响应进行专家迭代,并根据 RM 选择最佳响应。使用专家迭代进行监督学习训练的模型可以从一个阶段泛化到下一个阶段。

图 17:根据课程,使用专家迭代训练的模型从每个阶段到下一个阶段的定量泛化结果。(图源:Denison et al. 2024)
值得注意的是,即使在课程之后,模型 overwrote 奖励并避免被检测到的情况不到 1/1000。即使一个模型是在直接激励 reward hacking 的课程中训练的,模型 overwrote 奖励的行为也不到 1% 的,并且篡改单元测试的频率更低。作为一种简单的缓解措施,在前两种环境中(reward hacking 行为很容易被发现的地方(谄媚和奉承行为)),用不欺骗环境的 SFT 数据对模型进行监督微调,可以减少在 holdout 环境中奖励篡改的可能性。
探索缓解措施
虽然有大量文献讨论 reward hacking 现象,但在 reward hacking 的缓解措施方面,特别是在 RLHF 和 LLM 领域,并没有太多的工作。这一部分将简要回顾三种潜在的方法。
强化学习算法改进
Amodei et al. (2016) 指出了一些在强化学习训练中减轻 reward hacking 的方向:
- 对抗性奖励函数。我们将奖励函数视为一个自适应的智能体本身,它可以适应模型发现的奖励高但人类评分低的新技巧。
- 模型前瞻。可以根据未来预期的状态给予奖励;例如,如果智能体将要替换奖励函数,它将获得负面奖励。
- 对抗性致盲。我们可以用某些变量使模型「失明」,从而让智能体无法学习到使其能够黑掉奖励函数的信息。
- 谨慎工程。通过谨慎的工程设计,可以避免一些针对系统设计的 reward hacking;例如,将智能体沙箱化,将其行为与其奖励信号隔离。
- 奖励封顶。这种策略就是简单地限制可能的最大奖励,因为它可以有效防止智能体通过 hacking 获取超高回报策略的罕见事件。
- 反例抵抗。对抗鲁棒性的提高应该有利于奖励函数的鲁棒性。
- 多种奖励的组合。结合不同类型的奖励可能使其更难被 hacking。
- 奖励预训练。我们可以从一系列 (state, reward) 样本中学习奖励函数,但这取决于监督训练设置的效果如何,它可能带有其他包袱。RLHF 依赖于此,但学习到的标量奖励模型非常容易学习到不需要的特质。
- Variable indifference。目标是要求智能体优化环境中的一些变量,而不是其他变量。
- 陷阱。我们可以有意引入一些漏洞,并在任何奖励被 hacking 时设置监控和警报。
- 在以人类反馈作为智能体行为认可的 RL 设置中,Uesato et al. (2020) 提出了用解耦批准(decoupled approval)来防止奖励篡改。如果反馈是基于 (state, reward) 的,一旦这对数据发生奖励篡改,我们就无法获得该行为在该状态下的未被污染的反馈。解耦意味着收集反馈的查询行为是从世界上采取的行为中独立抽样的。反馈甚至在行为在世界中执行之前就已收到,从而防止行为损害自己的反馈。


检测 Reward Hacking 行为
另一种缓解措施是通过将其框架化为异常检测任务来检测 Reward Hacking,其中检测器(具有由人类验证的轨迹和奖励的「可信策略」)应标记错位实例(Pan et al. 2022)。给定(1)一个可信策略和(2)一组手动标记的轨迹 rollouts,我们可以根据两个策略(可信策略和目标策略)的动作分布之间的距离构建二元分类器,并测量该异常检测分类器的准确性。在 Pan et al. (2022) 的实验中,他们观察到不同的检测器更适合不同的任务,并且在所有测试的 RL 环境中,没有一个测试的分类器能够实现大于 60% 的 AUROC。

RLHF 的数据分析
另一种方法是分析 RLHF 数据集。通过检查训练数据如何影响对齐训练结果,可以指导预处理和人工反馈收集,以降低 reward hacking 风险。
- 目标特征:指明确想要学习的值。
- Spoiler 特征:指在训练过程中无意中学到的非预期值(例如,情感或连贯性等风格性特征)。这些类似于 OOD 分类工作中的虚假特征(spurious features)(Geirhos et al. 2020)。
SEAL 还引入了三个衡量对齐训练数据有效性的指标:
1. 特征印记(feature imprint),是指特征 τ 的一个系数参数 β_τ,在保持其他因素不变的情况下,该系数参数用于估计比较有或无特征 τ 时奖励点数的增加情况。

图 21:(左) 特征印记 β(τ) (pre-) 和 β(τ) (post-) 由针对特征的奖励
![]()
的固定效应线性回归计算得出。总体而言,对齐训练会奖励无害和有用等积极特征,并惩罚性内容或侵犯隐私等消极特征。(右) 特征印记由奖励偏移 θ_i 的线性回归计算得出。奖励偏移 θ_i 的定义为对齐训练前后奖励向量之间的角度。训练过程会优化模型对目标特征的敏感度。总体而言,对齐训练会奖励无害和有用等积极特征,并惩罚性内容或侵犯隐私等消极特征。(右) 特征印记由奖励偏移 θ_i 的线性回归计算得出。奖励偏移 θ_i 的定义为对齐训练前后奖励向量之间的角度。训练过程会优化模型对目标特征的敏感度。请注意,无害通过选定和拒绝的条目(包括 is harmless (c) 和 is harmless (r))印记在 RM 上,而有用性仅通过拒绝的条目(is helpful (r))来印记。(图源:Revel et al. 2024)
2. 对齐阻力(Alignment resistance)是 RM 无法匹配人类偏好的偏好数据对的百分比。研究发现,RM 在超过 1/4 的 HHH-RLHF 数据集上可以抵抗人类偏好。
3. 对齐稳健性(Alignment robustness)

衡量的是对齐对带有重写的扰动输入的稳健程度,包括情绪、雄辩和连贯性等剧透特征(spoiler features)τ,其能隔离每个特征和每种事件类型的影响。
稳健性指标

(如「雄辩」或「情绪积极」等特征名称 τ)应以以下方式解释:
与没有此类翻转的其他条目相比,在重写后包含更强特征 τ 的选定条目(记为 c)被拒绝的几率高出

倍。
类似地,与没有此类翻转的其他条目相比,在重写后获得较弱特征 τ 的被拒绝条目(记为 r )被选中的几率是
![]()
倍。
根据他们对不同重写方面对齐稳健性指标的分析,只有基于情感剧透特征的稳健性得分

是统计显著的。
参考内容:
https://lilianweng.github.io/posts/2024-11-28-reward-hacking/
#全球五大巨头GPU总量曝光
2025年等效H100或超1240万块
AI巨头的芯片之争,谷歌微软目前分列一二。而xAI作为新入局者,正迅速崛起。这场竞争中,谁会成为最后赢家?
今年,马斯克用全球最大AI超算Colossus轰动了整个世界。
这台超算配备了10万张英伟达H100/H200显卡,并预计未来即将扩展到20万张。
自此,AI巨头们倍感压力,数据中心大战火上浇油。巨头们纷纷酝酿着各自的建造计划。
最近,LessWrong网站上发表了一篇博客,根据公开数据对英伟达芯片的产量、各个AI巨头的GPU/TPU数量进行了估计,并展望了芯片的未来。
博客地址:https://www.lesswrong.com/posts/bdQhzQsHjNrQp7cNS/estimates-of-gpu-or-equivalent-resources-of-large-ai-players#Nvidia_chip_production
截止目前,世界五大科技公司的2024年拥有的算力,以及2025年的预测:
微软有75万-90万块等效H100,明年预计达到250万-310万
谷歌有100万-150万块等效H100,明年预计达到350万-420万
Meta有55万-65万块等效H100,明年预计达到190万-250万
亚马逊有25万-40万块等效H100,明年预计达到130万-160万
xAI有10万块等效H100,明年预计达到55万-100万
芯片数量估算总结
可见,他们都在紧锣密鼓地布局自己的算力版图,开展下一代更先进模型的训练。
谷歌Gemini 2.0预计在本月正式上线。此前,马斯克也曾透露,Grok 3也会在年底亮相,具体时间仍旧未知。
他表示,在法律问题数据集上完成训练后,下一代Grok 3将是一个强大的私人律师,能全天候提供服务。
为了追赶劲敌,OpenAI o2模型据称也在训练中了。
这一切训练的开展,都离不开GPU/TPU。
英伟达稳坐GPU霸主,25年或暴销700万块
毋庸置疑,英伟达早已跃升为数据中心GPU的最大生产商。
11月21日,英伟达发布的2025财年第三季度财报预计,2024自然年的数据中心收入将达1100亿美元,比2023年的420亿美元增长了一倍多,2025年有望突破1730亿美元。
收入主力,那便是GPU了。
据估计,2025年英伟达销量为650万至700万块GPU,几乎全是最新的Hopper和Blackwell系列。
根据生产比例和产量预期,其中约包括200万块Hopper,500万块Blackwell。
今年产量:500万块H100
那么,2024年英伟达实际产量是多少?目前,关于这一数据来源较少,有些甚至还对不上。
不过,有估算称2024年第四季度将生产约150万块Hopper GPU。不过这包括一些性能较低的H20芯片,因此是一个上限值。
根据季度间数据中心收入比例推测,全年生产总量可能上限为500万块——这是基于每块H100等效芯片收入约2万美元的假设,而这个单价似乎偏低;如果使用更合理的2.5万美元计算,实际产量应该在400万块左右。
这一数据与年初估计的150万至200万块H100生产量存在差异。目前尚不清楚这一差异是否可以归因于H100与H200的区别、产能扩大或其他因素。
但由于这一估算与收入数据不一致,选择使用更高的数字作为参考。
此前的产量
为了评估目前以及未来谁拥有最多的计算资源,2023年之前的数据对整体格局的影响有限。
这主要是因为GPU性能本身的提升,以及从英伟达的销售数据来看,产量已经实现了大幅增长。
根据估算,微软和Meta在2023年各自获得了约15万块H100 GPU。结合英伟达的数据中心收入,2023年H100及同等级产品的总产量很可能在100万块左右。
五大科技巨头,等效H100预测
截止2024年底,微软、Meta、谷歌、亚马逊、xAI将拥有多少块等效H100?2025年他们又将扩展到多少块GPU/TPU?
从季度报告(10-Q)和年度报告(10-K)中可以看出,英伟达的客户分为「直接客户」和「间接客户」。
其中,46%的收入都是来自直接客户,包括像SMC、HPE、戴尔这样的系统集成商。
他们通过采购GPU,然后组装成服务器,提供给间接客户使用。
间接客户覆盖的范围就非常广泛,比如公有云服务提供商、互联网消费类公司、企业用户、公共部门机构和创业公司都属于这一范畴。
更直白讲,微软、Meta、谷歌、亚马逊、xAI都是「间接客户」(关于他们的拥有GPU相关信息披露相对宽松,但可信度可能较低)。
2024年财年报告中,英伟达披露了,约19%的总收入来自通过系统集成商和分销商采购产品的间接客户。
根据交易规定,他们必须披露收入占比超过10%的客户信息。那么,英伟达的这个数据透露了什么?
要么是,第二大客户规模只有第一大客户的一半,要么是这些数据存在测量误差。
这其中,最大的客户可能是谁?
从现有信息来看,最有可能的候选者是微软。
微软、Meta
微软很可能就是英伟达这两年的最大客户,这一判断基于以下几个因素:
首先,微软拥有全球最大的公有云服务平台之一;其次,它是OpenAI的主要算力供应商;再者,与谷歌、亚马逊不同,微软没有大规模部署自己的定制芯片;最后,微软似乎与英伟达建立了特殊的合作关系——他们是首个获得Blackwell GPU的公司。
今年10月,微软Azure已经开始测试32个GB200服务器的机架。
2024年微软的收入占比数据没有2023年那么精确,英伟达第二季度财报(10-Q)中提到上半年为13%,第三季度仅「超过10%」。
这表明,微软在英伟达销售中的份额较2023年有所降低。
另有彭博统计,微软占英伟达收入15%,其次是Meta占13%,亚马逊占6%,谷歌约占6%(不过资料中并未明确指出这些数据具体对应哪些年份)。
去年来自Omdia研究统计,2023年底Meta、微软各有15万块H100,亚马逊、谷歌和甲骨文各5万块,这一数据与彭博数据更为吻合。
不过,Meta曾发文宣称,到2024年底将拥有相当于60万块H100算力。据称这包括35万块 H100,剩余部分很可能是H200,以及少量将在最后一个季度交付的Blackwell芯片。
如果假设这60万的数字准确无误,并结合收入占比进行推算,便可以更准确地估计微软的可用算力。
微软预计将比Meta高出25%到50%,也就是相当于75万—90万块等效H100算力。
谷歌、亚马逊
仅从英伟达收入的贡献来看,亚马逊、谷歌无疑是落后于微软Meta。然而,这两家公司的情况有着显著差异。
谷歌已经拥有大量自研的定制TPU,这是内部工作负载的主要计算芯片。
去年12月,谷歌推出了下一代迄今为止最强大的AI加速器TPU v5p。
Semianalysis在2023年底一篇报道中指出,谷歌是唯一一家拥有出色自研芯片的公司。
谷歌在低成本、高性能且可靠的大规模AI部署方面的能力几乎无人能及,是全球算力最丰富的企业。
而且,谷歌在基础设施上的投入,只会越来越多。2024年第三季度财报估计,AI支出为130亿美元,「大部分」用在搭建技术基础设施,其中其中60%是服务器(GPU/TPU)。
大部分或许意味着70-110亿美元,其中在TPU/GPU服务器上预估耗资45-70亿美元。
按照TPU对GPU支出2:1的估算,并保守假设TPU的每美元性能与微软的GPU支出相当,预计到2024年底谷歌将拥有相当于100万到150万块等效H100算力。
相比之下,亚马逊内部AI工作负载规模很可能小得多。
他们持有相当数量的英伟达芯片,主要是为了满足通过其云平台提供的外部GPU需求,尤其是为Anthropic提供算力需求。
毕竟,亚马逊和微软一样,都是金主爸爸,负责为OpenAI劲敌提供充足算力。
另一方面,亚马逊虽也有自研的Trainium和Inferentia芯片,但他们在这方面的起步比谷歌的TPU晚得多。
这些芯片似乎远落后于业界最先进水平,他们甚至提供高达1.1亿美元的免费额度来吸引用户尝试,这表明目前的市场接受度并不理想。
不过,今年年中,亚马逊定制芯片似乎出现了的转机。
在2024年第三季度财报电话会议上,CEO Andy Jassy在谈到Trainium2时表示,这些芯片获得了巨大的市场兴趣,我们已多次与制造合作伙伴协商,大幅提高原定的生产计划。
Semianalysis报道指出,「根据我们已知数据,微软和谷歌于2024年在AI基础设施上的投资计划,大幅领先亚马逊部署的算力」。
这些芯片换算成等效H100并不明确,关于Trainium/Trainium2芯片的具体数量也难以获得,仅知道在上述免费额度计划中提供了4万块。
xAI
今年,xAI在基础设施搭建中,最为标志性事件便是——122天建成了10万块H100组成的世界最大超算。
而且,这一规模还在不断扩展中。马斯克预告了未来将扩展到20万块由H100/H200组成的超算。
据称,xAI超算目前似乎在站点供电方面遇到了一些问题。
2025年Blackwell芯片预测
最新2024 AI现状报告对Blackwell采购量进行了估算:
大型云计算公司正在大规模采购GB200系统:微软介于70万到140万块之间,谷歌40万块,AWS 36万块。据传OpenAI独自拥有至少40万块GB200。
如果将微软GB200预估值设为100万块,那么谷歌、AWS这些数字与它们在英伟达采购中,相对于微软的比例是相符的。
这也使得微软占英伟达总收入的12%,与2024年其在英伟达收入份额的小幅下降趋势一致。
该报告虽然没有给出Meta的具体估计数字,但Meta预计明年人工智能相关基础设施支出将显著加速,这表明其在英伟达支出中将继续保持高份额。
lesswrong预计在2025年,Meta的支出规模将维持在微软支出的约80%水平。
虽然没有提及xAI,但马斯克宣称,将在2025年夏天部署一个有30万块Blackwell芯片的运算集群。
虑到马斯克一贯的夸张风格,更为合理的一个估计是,到2025年底他们可能实际拥有20万—40万块芯片。
那么,一块B200相当于多少块H100?这个问题对于评估算力增长至关重要。
就训练而言,性能预计飙升(截至2024年11月)2.2倍。英伟达发布当天,给出的数据称,两个B200组成的GB200,其性能是H100的7倍,训练速度是H100的4倍。
对于谷歌,假设英伟达芯片继续占其总边际计算能力的三分之一。对于亚马逊,这一比例假定为75%。
值得注意的是,仍有大量H100和GB200芯片未被计入上述统计中。
有些是未达到英伟达收入报告阈值的机构,还有些是像甲骨文这样的云服务提供商和其他中小型云服务提供商可能持有相当数量的芯片。
此外,也包括一些英伟达重要的非美国客户。
在全面了解各家手握多少GPU/TPU算力之后,下一个问题是,这些算力将用在哪?
巨头们训练模型用了多少算力?
以上都讨论的是关于各个AI巨头总计算能力的推测,但许多人可能更关心最新前沿模型的训练使用了多少计算资源。
以下将讨论OpenAI、谷歌、Anthropic、Meta和xAI的情况。
但由于这些公司要么是非上市企业,要么规模巨大无需披露具体成本明细(比如谷歌,AI训练成本目前只是其庞大业务的一小部分),因此以下分析带有一定的推测性。
OpenAI和Anthropic
2024年OpenAI的训练成本预计达30亿美元,推理成本为40亿美元。
据称,微软向OpenAI提供了40万块GB200 GPU,用于支持其训练。这超越了AWS整体的GB200容量,使OpenAI的训练能力远超Anthropic。
另一方面,Anthropic 2024年预计亏损约20亿美元,而收入仅为几亿美元。
考虑到Anthropic的收入主要来自API服务且应该带来正毛利,且推理成本应该相对较低,这意味着20亿美元中,大部分都用于模型训练。
保守估计其训练成本为15亿美元,这大约是OpenAI的一半,但并不妨碍其在前沿模型上的竞争力。
这种差异也是可以理解的。Anthropic的主要云提供商是资源相对有限的AWS,AWS的资源通常少于为OpenAI提供算力支持的微软。这可能限制了Anthropic的能力。
谷歌和Meta
谷歌的Gemini Ultra 1.0模型使用了约为GPT-4的2.5倍的计算资源,发布时间却晚了9个月。其所用的计算资源比Meta的最新Llama模型高25%。
尽管谷歌可能拥有比其他公司更多的计算能力,但作为云服务巨头,它面临着更多样的算力需求。与专注于模型训练的Anthropic或OpenAI不同,谷歌和Meta都需要支持大量其他内部工作负载,如社交媒体产品的推荐算法等。
Llama 3所用计算资源比Gemini少,且发布时间晚8个月,这表明Meta分配给前沿模型的资源相较OpenAI和谷歌更少。
xAI
据报道,xAI使用了2万块H100训练Grok 2,并计划用10万块H100训练Grok 3。
作为参考,GPT-4据称使用2.5万块A100进行了90-100天的训练。
考虑到H100的性能约为A100的2.25倍,Grok 2的训练计算量约为GPT-4的两倍,而Grok 3则预计达到其5倍,处于计算资源利用的前沿水平。
此外,xAI并非完全依赖于自有芯片资源,部分资源来源于租赁——据估算,他们从Oracle云平台租用了1.6万块H100。
如果xAI分配给训练的计算资源比例接近OpenAI或Anthropic,推测其训练规模可能与Anthropic相当,但低于OpenAI和谷歌的水平。
参考资料:
#Diffusion Self-Distillation
人人都是艺术家!斯坦福提出扩散自蒸馏:定制图像生成,任意上下文下扩展到任意实例!
这是一种零样本定制图像生成模型,能够在任何上下文中扩展到任意实例,并且性能与推理阶段调优方法相当。该技术通过自蒸馏pipeline,利用预训练的文本到图像扩散模型、LLMs和VLMs,自动生成身份保持的数据配对,用于整个数据创建过程。
文章链接:https://arxiv.org/pdf/2411.18616
项目链接:https://primecai.github.io/dsd
亮点直击
- 提出了Diffusion Self-Distillation,一种zero-shot身份保持定制图像生成模型,能够在任何上下文下扩展到任意实例,其性能与推理阶段调优方法相当;
- 提供了一条自蒸馏pipeline,利用预训练的文本到图像扩散模型、LLMs和VLMs,完全不依赖人工参与,获取身份保持的数据配对,用于整个数据创建过程;
- 设计了一个统一的架构,用于处理涉及身份和结构保持编辑的图像到图像翻译任务,包括个性化、重光照、深度控制和指令跟随。
总结速览解决的问题
- Text-to-image扩散模型生成效果令人印象深刻,但难以满足艺术家对精细化控制的需求。
- 在“保持身份一致性”的生成任务(如将特定概念放置于新背景)以及其他任务(如重光照)中,缺乏高质量的图像+文本配对数据来直接训练模型。
提出的方案
- Diffusion Self-Distillation:利用预训练的文本到图像扩散模型自生成数据集,用于文本条件下的图像到图像任务。
- 1.利用扩散模型的上下文生成能力生成图像网格。
- 2.使用视觉-语言模型辅助筛选,构建大规模高质量的配对数据集。
- 3.使用筛选后的配对数据集对扩散模型进行微调,将其转化为支持文本+图像条件的图像生成模型。
应用的技术
- 预训练的文本到图像扩散模型的上下文生成能力。
- 视觉-语言模型对生成数据进行筛选和过滤。
- 基于筛选数据的扩散模型微调技术。
达到的效果
- 在保持身份一致性生成任务中优于现有的零样本方法。
- 在不需要测试时优化的情况下,性能可与逐实例调优技术相媲美。
- 方法适用于多种文本条件图像生成任务,具有广泛适应性和有效性。
Diffusion Self-Distillation
最近的文本到图像生成模型提供了令人惊讶的能力,能够生成上下文一致的图像网格(见图2,左侧)。受到这一洞察的启发,本文开发了一种zero-shot适应网络,能够快速、丰富、高质量且保持身份一致性,即在参考图像的条件下生成一致的图像。首先利用预训练的文本到图像扩散模型、大语言模型(LLMs)和视觉语言模型(VLMs)生成并筛选出展示所需一致性的图像集。然后,使用这些一致性的图像集对同一预训练扩散模型进行微调,采用本文新提出的并行处理架构创建一个条件模型。通过这种方式,Diffusion Self-Distillation以监督方式将预训练的文本到图像扩散模型微调为zero-shot定制图像生成器。
生成配对数据集
为了创建用于监督Diffusion Self-Distillation训练的配对数据集,利用预训练的文本到图像扩散模型的新兴多图像生成能力,生成可能一致的基础图像,这些图像由LLM生成的提示创建。然后,使用VLMs筛选这些基础样本,获得共享所需身份一致性的干净图像集。数据生成和筛选pipeline如下图2左侧所示。
通过教师模型生成基础数据
为了生成符合所需身份保持的图像集,我们提示预训练的教师文本到图像扩散模型创建包含多个面板的图像,每个面板展示相同的主题,并在表情、姿势、光照条件等方面有所变化,用于训练目的。这种提示可以简单地指定输出中的身份保持要求,如“一个包含4张图像的网格,展示相同的<物体/角色/场景等>”,“4个均匀分隔的面板,描绘相同的<物体/角色/场景等>”等。还会指定每个子图像/面板中的预期内容。完整的提示集在我们的补充材料第A节中提供。分析表明,目前最先进的文本到图像扩散模型(如SD3、DALL·E 3、FLUX)展示了这一身份保持能力,这可能源于它们的训练数据,包括漫画、漫画书、照片集和视频帧。这种上下文生成能力对于我们的数据生成流程至关重要。
通过LLMs生成提示
依赖LLM来“头脑风暴”生成一个多样化的提示大数据集,从中提取我们的图像网格数据集。通过定义提示结构,提示LLM生成描述图像网格的文本提示。遇到的一个挑战是,当提示生成大量提示时,LLM往往生成低多样性的提示。例如,如果没有额外的引导,GPT-4o倾向于生成包含汽车和机器人内容的提示,导致输出内容高度重复。为了解决这个问题,利用LAION数据集中的可用图像标题,将它们作为内容参考输入到LLM中。这些来自真实图像标题的参考大大提高了生成提示的多样性。还可以选择使用LLM过滤这些参考标题,确保它们包含明确的身份保持目标。我们发现,这显著提高了生成一致的多图像输出的命中率。
使用VLMs进行数据筛选和标题生成
尽管上述数据生成方案提供了具有良好质量和数量的身份保持的多图像样本,但这些初步的“未经筛选”图像通常噪声较多,不适合直接使用。因此,利用VLMs的强大能力来筛选出清洁的数据集。从生成的样本中提取出意图保持身份的一对图像,并询问VLM这两张图像是否描绘了相同的物体、角色、场景等。我们发现,在这种情况下,使用思维链(Chain-of-Thought)提示特别有帮助。具体而言,首先提示VLM识别两张图像中共同存在的物体、角色或场景,然后让其详细描述每一张图像,最后分析它们是否相同,给出结论性回答。这个过程产生了共享相同身份的图像对。
并行处理架构
需要一个适用于通用图像到图像任务的条件架构,包括结构保持变换和保持概念/身份但不保持图像结构的变换。这是一个具有挑战性的问题,因为它可能需要转移精细细节,而不保证空间对应关系。尽管ControlNet架构在结构保持编辑(如深度到图像或分割图到图像)方面表现出色,但在更复杂的身份保持编辑下,它难以保持细节,其中源图像和目标图像没有像素对齐。另一方面,IP-Adapter可以从输入图像中提取某些概念,如风格,但它强烈依赖于任务特定的图像编码器,并且常常无法保持更复杂的概念和身份。受到多视角和视频扩散模型成功的启发 ,本文提出了一种简单而有效的方法,将基础扩散变换器模型扩展为图像条件扩散模型。具体而言,我们将输入图像视为视频的第一帧,并生成一个两帧的视频作为输出。最终的损失是在两帧视频上计算的,建立了第一帧的身份映射和第二帧的条件编辑目标。我们的架构设计使其对于通用的图像到图像翻译任务具有普遍性,因为它能够有效地在两帧之间交换信息,使模型能够捕捉复杂的语义并执行复杂的编辑,如图2右侧所示。
实验
实现细节 使用FLUX1.0 DEV作为教师模型和学生模型,实现自蒸馏。为了生成提示,使用GPT-4o;用于数据集筛选和标题生成,使用Gemini-1.5。在8个NVIDIA H100 80GB GPU上训练所有模型,采用160的有效批量大小进行100k次迭代,使用AdamW优化器,学习率为10^-4。并行处理架构使用LoRA,基模型的秩为512。
数据集 最终训练数据集包含约40万个主题一致的图像对,这些图像是从我们的教师模型FLUX1.0 DEV生成的。数据集的生成和筛选是完全自动化的,不需要人工干预,因此其规模可以进一步扩展。使用公开的DreamBench++数据集并遵循其评估协议。DreamBench++是一个综合性且多样化的数据集,用于评估个性化图像生成,包含150张高质量图像和1,350个提示,比以前的基准(如DreamBench)要多得多。该数据集涵盖了各种类别,如动物、人物、物体等,包括照片写实和非照片写实图像,且提示设计涵盖不同难度级别(简单/富有创意)。相比之下,提示是使用GPT-4o生成的,并通过人工标注员进行精炼,以确保多样性和伦理合规性。
基准 遵循DreamBench++的设置,将我们的模型与两类基准进行比较:推理阶段调整模型和zero-shot模型。对于推理阶段的模型,将其与Textual Inversion、DreamBooth及其LoRA版本进行比较。对于zero-shot模型,与BLIP-Diffusion、Emu2、IP-Adapter、IP-Adapter+进行比较。
评估指标 先前工作的评估协议通常包括比较CLIP和DINO特征相似度。然而,上述指标仅捕捉到全局语义相似度,且噪声非常大,容易偏向于“复制粘贴”输入图像。这在输入图像或提示较为复杂时尤其成问题。参考DreamBench++中的详细分析,指出了这些指标的局限性。因此,遵循DreamBench++设计的指标,并报告GPT-4o在更为多样化的DreamBench++基准上针对不同类别主题的概念保持(CP)和真实(Real.)与富有创意(Imag.)提示下的提示遵循(PF)的得分,最后用其乘积作为最终评估得分。该评估协议模拟了使用VLMs的人类用户研究。此外,对GPT评估提示进行了轻微修改,以便在生成的内容未显示出内部理解和创意输出,而是天真地复制了参考图像中的组件时,可以应用惩罚。这些修改后的指标被命名为“去偏概念保持(Debiased CP)”和“去偏提示遵循(Debiased PF)”。完整的GPT评估提示集将在我们的补充材料Sec. B中提供。
定性结果
下图4展示了定性比较结果,表明本文的模型在主题适应性和概念一致性方面显著优于所有基准,同时在输出中表现出出色的提示对齐性和多样性。作为早期概念提取方法的Textual Inversion仅捕捉到输入图像中的模糊语义,因此不适用于需要精确主题适应的zero-shot定制任务。DreamBooth和DreamBooth-LoRA在保持一致性方面面临挑战,主要因为它们在多张输入图像下表现更好。这一依赖性限制了它们在仅有单张参考图像时的有效性。相反,本文的方法即使只使用一张输入图像,也能取得稳健的结果,突显了其效率和实用性。
BLIP-Diffusion 作为一个自监督表示学习框架,可以以zero-shot方式从输入中提取概念,但仅限于捕捉整体语义概念,无法定制特定主题。同样,Emu2作为一个多模态基础模型,擅长提取语义概念,但缺乏针对特定主题定制的机制,限制了它在个性化图像生成中的应用。IP-Adapter和IP-Adapter+ 采用自监督学习方案,旨在通过编码信号重建输入。虽然在提取全局概念方面有效,但它们遭遇了明显的“复制粘贴”效应,生成的图像与输入非常相似,缺乏有意义的转化。值得注意的是,IP-Adapter+ 利用更强的输入图像编码器,导致这一问题加剧,输出的多样性和适应性降低。
与之相比,本文的方法有效地保留了主题的核心身份,同时允许多样且符合上下文的转化。如下图5所示,扩散自蒸馏方法展示了出色的多功能性,能够熟练处理各种定制目标(角色、物体等)和风格(照片写实、动画等)。此外,扩散自蒸馏能够很好地推广到各种提示,包括与InstructPix2Pix类似的指令,进一步证明了它在各种定制任务中的鲁棒性和适应性。
定量结果
与基准模型的定量比较见下表1,报告了按照DreamBench++的GPT评估结果。该评估协议类似于人工评分,但使用自动化的多模态大语言模型(LLMs)。我们的模型在概念保持和提示跟随方面均表现最佳,仅在概念保持方面略逊于IP-Adapter+(主要由于“复制粘贴”效应),在提示跟随方面则略逊于每实例调整的DreamBooth-LoRA。DreamBench++的概念保持评估仍然偏向于支持“复制粘贴”效应,尤其是在更具挑战性和多样性的提示上。例如,IP-Adapter系列在概念保持方面的优异表现,主要得益于其强大的“复制粘贴”效应,该效应直接复制输入图像,而未考虑提示中的相关变化。这也部分体现在其较差的提示跟随得分上,表明它们偏向于参考输入,未能有效适应输入提示。因此,我们还展示了“去偏”版本的GPT得分,简单地要求GPT对生成的图像与参考图像过于相似的情况进行惩罚。IP-Adapter+ 的优势不再显现。总体而言,Diffusion Self-Distillation是表现最好的模型。
消融研究
- 数据整理:在数据集生成过程中,首先使用冻结的预训练FLUX模型合成网格,然后通过VLM整理筛选图像。为什么不对FLUX模型进行微调以提高命中率?为了解决这个问题,使用超过7000个一致性网格拟合了LoRA(下图6左)。尽管更多的样本是一致性网格,但发现教师模型失去了输出的多样性。因此,选择完全依赖VLMs帮助我们从大量多样但潜在噪声的网格中进行整理。
- 并行处理架构:将并行处理架构与三种替代的图像到图像架构进行比较:1)将源图像与噪声图像进行拼接(“拼接”);2)基于ControlNet的设计;3)基于IP-Adapter 的设计。使用与并行处理模型相同的数据训练每个架构(图6中)。对于ControlNet,得出与先前工作 [14]相同的结论,它在结构对齐编辑时表现最好,但当源图像和目标图像的相机姿势不同时,通常难以保持细节。IP-Adapter由于其图像编码器的容量限制,在有效传递源图像的细节和风格方面存在困难。
- 其他图像到图像任务:尽管不是“自蒸馏”,因为它需要外部来源的配对数据集(通过Depth Anything生成),我们还在深度到图像任务上训练了我们的架构,以展示其在更一般的图像到图像任务中的应用(图6右)。
用户研究为了评估本文生成图像的保真度和提示一致性,在DreamBench++测试集的一个随机子集上进行了用户研究,选取了20个样本。共有25名女性和29名男性标注员,年龄从22岁到78岁(平均34岁),独立地根据以下三个标准对每个图像进行1到5分的评分:
(1)概念保持—与参考图像的一致性;
(2)提示一致性—与给定提示的一致性;
(3)创造力—内部理解和转化的水平。
下表2中展示了平均分数。人工标注与GPT评估结果高度一致,表明Diffusion Self-Distillation在概念保持方面略逊于IP-Adapter+,在提示一致性方面略逊于推理阶段调优方法DreamBooth-LoRA。值得注意的是,本文的模型在创造力评分上取得了最高分,而IP-Adapter+由于其“复制粘贴”效应,在这一指标上得分较低。这些结果进一步确认了Diffusion Self-Distillation提供了最平衡且优越的整体表现。
讨论
本文提出了Diffusion Self-Distillation,这是一种zero-shot方法,旨在使用文本到图像的扩散模型,在无需人工干预的情况下实现广泛上下文中的身份适应。本文的方法有效地将zero-shot定制图像生成转化为监督任务,显著降低了其难度。实证评估表明,Diffusion Self-Distillation在保持zero-shot方法效率的同时,与推理阶段调优技术相当。
局限性与未来工作
本文的工作专注于角色、物体和场景重光的身份保持编辑。未来的方向可以探索更多任务和应用场景。例如,与ControlNet的集成可以提供身份和结构的细粒度独立控制。此外,将我们的方法从图像扩展到视频生成是未来工作的一个有前景的方向。
结论
Diffusion Self-Distillation使内容创作普适化,能够进行身份保持、高质量且快速的定制图像生成,并能够无缝适应不断发展的基础模型,极大地拓展了艺术、设计和数字故事讲述的创造性边界。
#YOPO (You Only Prune Once)
给LLaVA做剪枝,大幅缩减多模态大模型计算量至12%!
本文以LLaVA模型为实验对象,通过一系列剪枝策略,将计算量压缩至12%,同时保持了与原始模型同等的性能。
本文提出从参数和计算模式层面对多模态大模型做剪枝,以 LLaVA 为实验对象将计算量压缩至 12% 并获得与原始模型同等的性能,并进一步在 Qwen2-VL 和 InternVL2.0 上验证了此种剪枝策略的普适性。
论文标题:
Treat Visual Tokens as Text? But Your MLLM Only Needs Fewer Efforts to See
论文地址:https://arxiv.org/abs/2410.06169
代码地址:https://github.com/ZhangAIPI/YOPO_MLLM_Pruning
01 摘要
随着大语言模型的成功,多模态大模型通过整合视觉、文本和其他模态的信息,显著提升了多模态任务的表现。然而,视觉 token 数量的快速增长导致计算复杂度呈二次方增长,严重制约了模型的可扩展性和部署效率。
本文针对这一问题,以 LLaVA 为例,分析了视觉计算中的冗余性,并提出了一系列高效的剪枝策略,包括邻域感知的视觉注意力、非活跃注意力头的剪枝、稀疏前馈网络投影和选择性丢弃视觉层。
实验表明,这些方法在显著降低计算开销(多达 88%)的同时,保持了模型在多模态任务中的性能表现。作者进一步验证了这种计算冗余性在 Qwen2-VL 和 InternVL2.0 上同样普遍存在。本文的研究为多模态大模型的高效计算提供了新的视角和解决方案。

02 动机
多模态大模型近年来在跨模态任务(如视觉问答、文本生成和科学推理)中表现出了强大的能力。然而,与文本 token 相比,视觉 token 的数量往往更为庞大。例如,在 LLaVA 模型中,处理一张图像涉及超过 500 个视觉 token,而对应的文本 token 只有数十个。这种极大的不平衡带来了如下问题:
计算效率低下: LLMs 的注意力机制复杂度随着输入 token 数量呈二次增长。这种计算成本的急剧增加对硬件资源提出了极高的要求,限制了多模态大模型的实际应用。
冗余性被忽视: 尽管视觉数据包含丰富的信息,但其固有的空间稀疏性导致许多计算是冗余的。例如,大部分视觉 token 之间的交互权重很低,仅有邻近 token 之间的交互是关键。此外,在深层模型中,视觉 token 对文本生成的影响逐渐减弱,但现有计算模式并未有效利用这一特性。
现有方法的局限性: 已有的优化策略,如减少视觉 token 数量或使用轻量化的语言模型,通常以牺牲模型性能为代价。如何在保持性能的同时显著降低计算复杂度,仍是一个急需解决的问题。
基于上述问题,本文提出了新的优化方向:通过深入挖掘视觉参数和计算模式的冗余性,对模型计算做剪枝,而不是简单地减少 token 数量。这种方法不仅能降低计算开销,还能最大程度地保留模型性能。
03 方法
本文提出了四种核心策略,分别从注意力机制、前馈网络和层剪枝等多个角度优化视觉计算:

3.1 邻域感知的视觉注意力
视觉 token 之间的注意力交互往往具有空间稀疏性,大部分交互权重集中在邻近 token 之间,而远距离 token 的交互在一些情况下可以忽略。
传统的全局注意力计算导致了大量无用的计算开销。本文提出了一种邻域感知的注意力机制,限制视觉 token 仅与其邻近 token 交互。通过添加邻域掩码,忽略超出特定半径的 token 交互。具体公式为:

其中, 半径 h 表示邻域范围。这一改进将注意力计算复杂度从 降至 。
3.2 非活跃注意头剪枝
研究团队以 LLaVA-1.5 作为研究对象,随机选取了 100 个视觉问答样本,可视化了视觉 token 的不同注意力头的权重,实验发现大约有一半数量的注意力头都没有被激活。由此可见这部分注意力头的相关计算同样存在大量冗余并可以被剪枝。实验表明,即使剪掉大量注意力头,模型仅有极小的性能下降。
3.3 稀疏投影的前馈网络
通过剪枝大部分视觉注意力计算,模型的视觉表达变得高度稀疏。为了有效利用这种稀疏性,研究团队提出在每个 transformer 模块内的前馈网络隐藏层中随机丢弃 p% 的神经元。
3.4 选择性层丢弃
研究团队通过可视化 LLaVA-1.5 不同层的视觉 token 跨模态注意力权重发现,大权重集中在前 20 层,在第 20 层到 40 层之间权重接近于 0。

这项结果表明靠后的 20 层的视觉计算存在大量冗余。这一观察启发了研究团队在靠后的层中直接跳过所有与视觉相关的计算,从而减少计算开销。具体来说,对于层 l>L−N,视觉注意力和跨模态注意力计算都被省略,使得注意力计算可以简化如下:

04 实验结果
研究团队对 LLaVA-1.5-7B 和 LLaVA-1.5-13B 模型应用提出的四种剪枝策略并进行了评估,结果显示剪枝后 FLOPs 分别减少至原始模型的 25% 和 12%。
在相同计算预算下,剪枝模型在四个基准任务(GQA、VQAv2、POPE 和 MMBench)上均表现最佳,分别超出第二名方法 3.7%、1.1%、2.2% 和 0.45%。

为验证方法在剪枝视觉计算冗余方面的可扩展性,本文将提出的策略与 PyramidDrop 和 FastV 方法在 VQAv2 和 GQA 两个大型基准上的不同剪枝粒度进行了比较。
实验结果表明,随着 FLOPs 减少,模型性能也有所下降。例如,使用 FastV 方法将 FLOPs 从75%减少到 19% 时,平均性能从 71.35%下降到 66.63%。
相比之下,本文的方法不直接剪枝 token,而是针对参数和计算模式层面的冗余优化,在相同 FLOPs 下性能仅下降 0.5%。这一结果进一步证明,当前多模态大模型中的大量视觉计算冗余可以通过有效剪枝加以优化。

为验证剪枝策略的广泛适用性,本文将其应用于其他多模态大模型(如 Qwen2-VL-7B 和 InternVL-2.0),并在无需微调的情况下进行评估。通过在 GQA 和 POPE 基准上调整剪枝粒度以匹配原始模型性能和最小 FLOPs,结果显示,这些模型在适当的剪枝比例下,即使不进行微调,性能也未受影响。
此外,较大的多模态模型能够容纳更高的剪枝比例,这一点在不同规模的 InternVL-2.0 模型的剪枝实验中得到了验证。

05 总结
本篇工作提出了剪枝多模态大模型的一系列策略。与文本不同,视觉信息是稀疏且冗余的。先前的工作主要集中在减少视觉 token;而本篇工作则分析了参数和计算模式中的冗余。
在基本保持性能的同时,LLaVA 的计算开销被减少了 88%。在 Qwen2-VL-7B 和 InternVL-2.0-4B/8B/26B 上的额外实验进一步证实,视觉计算冗余在多模态大模型中普遍存在。
#Helix
踹了OpenAI后,Figure光速发布~大模型Helix,能力前所未有、创多项第一
本地 GPU 运行,7B 系统 2 模型 + 80M 系统 1 模型,可多机器人共用「大脑」。
在 2 月份突然宣布终结与 OpenAI 合作之后,知名机器人初创公司 Figure AI 在本周四晚公开了背后的原因:他们已经造出了自己的通用模型 Helix。

Helix 是一个通用的视觉 - 语言 - 动作(VLA)模型,它统一了感知、语言理解和学习控制,以克服机器人技术中的多个长期挑战。
Helix 创造了多项第一:
- 全身控制:它是历史上第一个类人机器人上半身的高速连续控制 VLA 模型,覆盖手腕、躯干、头部和单个手指;
- 多机器人协作:可以两台机器人用一个模型控制协作,完成前所未见的任务;
- 抓取任何物品:可以捡起任何小型物体,包括数千种它们从未遇到过的物品,只需遵循自然语言指令即可;
- 单一神经网络:Helix 使用一组神经网络权重来学习所有行为 —— 抓取和放置物品、使用抽屉和冰箱、以及跨机器人交互 —— 无需任何任务特定的微调;
- 本地化:Helix 是史上第一个在本地 GPU 运行的机器人 VLA 模型,已经具备了商业化落地能力。
在智能驾驶领域,今年各家车厂都在推进端到端技术的大规模落地,如今 VLA 驱动的机器人也已进入了商业化的倒计时,如此看来 Helix 可谓是~的一次重大突破。
,时长02:54
一组 Helix 神经网络权重同时在两个机器人上运行,它们协同工作,将从未见过的杂货物品收纳起来。
人形机器人技术的新扩展
Figure 表示,家庭环境是机器人技术面临的最大挑战。与受控的工业环境不同,家庭中充满了无数非规则物体,如易碎的玻璃器皿、皱巴巴的衣物、散落的玩具,每件物品的形状、大小、颜色和质地都难以预测。为了让机器人在家庭中发挥作用,它们需要能够按需生成智能的新行为。
当前的机器人技术无法扩展到家庭环境中 —— 目前,即使教机器人一个单一的新行为,也需要大量的人力投入。要么需要数小时的博士级专家手动编程,要么需要数千次的演示,这两种方法的成本都高得令人望而却步。

图 1:不同方法获取新机器人技能的扩展曲线。在传统的启发式操作中,技能的增长依赖于专家手动编写脚本。在传统机器人模仿学习中,技能的扩展依赖于收集的数据。而通过 Helix,新技能可以通过语言即时指定。
当前,人工智能的其他领域已经掌握了这种即时泛化的能力。如果能简单地将视觉 - 语言模型(VLM)中捕获的丰富语义知识直接转化为机器人动作,或许会实现技术突破。
这种新能力将从根本上改变机器人技术的扩展轨迹(图 1)。于是,关键问题变成了:如何从 VLM 中提取所有这些常识性知识,并将其转化为可泛化的机器人控制?Figure 构建了 Helix 来弥合这一差距。

Helix:首个机器人系统 1 + 系统 2 VLA 模型
Helix 是机器人领域上首创的「系统 1 + 系统 2」VLA 模型,用于高速、灵巧地控制整个人形机器人上半身。
Figure 表示,先前的方法面临一个根本性的权衡:VLM 主干是通用的,但速度不快,而机器人视觉运动策略是快速的,但不够通用。Helix 通过两个互补的系统解决了这一权衡,这两个系统经过端到端的训练,可以进行通信:
- 系统 1 (S1):一种快速反应的视觉运动策略,可将 S2 产生的潜在语义表征转换为 200 Hz 的精确连续机器人动作;
- 系统 2 (S2):一个机载互联网预训练的 VLM,以 7-9 Hz 运行,用于场景理解和语言理解,实现跨物体和上下文的广泛泛化。
这种解耦架构允许每个系统在其最佳时间尺度上运行。S2 可以「慢慢思考」高层次目标,而 S1 可以「快速思考」机器人实时执行和调整的动作。例如,在协作行为中(见下图),S1 可以快速适应伙伴机器人不断变化的动作,同时保持 S2 的语义目标。

Helix 能让机器人快速进行精细的运动调整,这是在执行新语义目标时对协作伙伴做出反应所必需的。
Helix 的设计相较于现有方法具有以下几个关键优势:
- 速度与泛化能力:Helix 在速度上与专门用于单一任务的行为克隆策略相当,同时能够零样本泛化到数千种新测试对象上;
- 可扩展性:Helix 直接输出高维动作空间的连续控制,避免了之前 VLA 方法中使用的复杂动作标记化方案。这些方案在低维控制设置(例如二值化平行夹爪)中取得了一些成功,但在高维人形控制中面临扩展挑战;
- 架构简洁性:Helix 使用标准架构 —— 一个开源的、开放权重的 VLM 用于系统 2,以及一个简单的基于 Transformer 的视觉运动策略用于系统 1;
- 关注点分离:将 S1 和 S2 解耦使我们能够分别迭代每个系统,而无需受限于寻找统一的观察空间或动作表示。
Figure 介绍了部分模型及训练细节,其收集了一个高质量、多机器人、多操作员的多样化遥操作行为数据集,总计约 500 小时。为了生成自然语言条件下的训练对,工程人员使用了一个自动标注的视觉语言模型(VLM)来生成事后指令。
该 VLM 会处理来自机器人机载摄像头的分段视频片段,并提示:「你会给机器人什么指令以使其执行视频中看到的动作?」训练期间处理的所有物品在评估中被排除,以防止数据污染。
模型架构
Helix 系统主要由两个主要组件组成:S2,一个 VLM 骨干网络;S1,一个潜在条件视觉运动 Transformer。
S2 基于一个 70 亿参数的开源、开放权重的 VLM 构建,该 VLM 在互联网规模数据上进行了预训练。它处理单目机器人图像和机器人状态信息(包括手腕姿态和手指位置),并将它们投影到视觉语言嵌入空间中。结合指定期望行为的自然语言指令,S2 将所有语义任务相关信息提炼为一个连续的潜在向量,传递给 S1 以调节其低级动作。
S1 是一个 8000 万参数的交叉注意力编码器 - 解码器 Transformer,负责低级控制。它依赖于一个完全卷积的多尺度视觉骨干网络进行视觉处理,该网络完全在模拟环境中进行预训练初始化。虽然 S1 接收与 S2 相同的图像和状态输入,但它以更高的频率处理这些输入,以实现更灵敏的闭环控制。来自 S2 的潜在向量被投影到 S1 的标记空间中,并与 S1 视觉骨干网络提取的视觉特征沿序列维度连接,提供任务条件。
在工作时,S1 以 200 赫兹的频率输出完整的上半身人形控制,包括期望的手腕姿态、手指屈曲和外展控制,以及躯干和头部方向目标。Figure 在动作空间中附加了一个合成的「任务完成百分比」动作,使 Helix 能够预测自身的终止条件,从而更容易对多个学习到的行为进行排序。
训练
Helix 的训练是完全端到端的:从原始像素和文本命令映射到具有标准回归损失的连续动作。
梯度的反向传播路径是通过用于调节 S1 行为的隐通信向量从 S1 到 S2,从而允许对这两个组件进行联合优化。
Helix 不需要针对具体某某任务进行调整;它只需维持单个训练阶段和一组神经网络权重,无需单独的动作头或针对每个任务的微调阶段。
在训练期间,他们还会在 S1 和 S2 输入之间添加一个时间偏移量。此偏移量经过校准以匹配 S1 和 S2 部署的推理延迟之间的差距,确保部署期间的实时控制要求准确反映在训练中。
经过优化的流式推理
Helix 的训练设计可实现在 Figure 机器人上高效地并行部署模型,每台机器人都配备了双低功耗嵌入式 GPU。推理管道分为 S2(高级隐规划)和 S1(低级控制)模型,每个模型都在专用 GPU 上运行。
S2 作为异步后台进程运行,用于处理最新的观察结果(机载摄像头和机器人状态)和自然语言命令。它不断更新编码高级行为意图的共享内存隐向量。
S1 作为单独的实时进程执行,其目标是维持让整个上身动作平滑执行所需的关键 200Hz 控制回路。它的输入是最新的观察结果和最新的 S2 隐向量。由于 S2 和 S1 推理之间存在固有的速度差异,因此 S1 自然会在机器人观察上以更高的时间分辨率运行,从而为反应控制创建更紧密的反馈回路。
这种部署策略有意反映了训练中引入的时间偏移量,从而可最大限度地减少训练推理分布差距。这种异步执行模型允许两个进程以各自最佳频率运行,使 Helix 的运行速度能与最快的单任务模仿学习策略一样快。
有趣的是,在 Figure 发布 Helix 之后,清华大学博士生 Yanjiang Guo 表示其技术思路与他们的一篇 CoRL 2024 论文颇为相似,感兴趣的读者也可参照阅读。

论文地址:https://arxiv.org/abs/2410.05273
结果
细粒度 VLA 全上身控制
Helix 能以 200Hz 的频率协调 35 自由度的动作空间,控制从单个手指运动到末端执行器轨迹、头部注视和躯干姿势等一切。
头部和躯干控制具有独特的挑战 —— 当头部和躯干移动时,会改变机器人可以触及的范围和可以看到的范围,从而产生反馈回路,过去这种反馈回路会导致不稳定。
视频 3 演示了这种协调的实际操作:机器人用头部平稳地跟踪双手,同时调整躯干以获得最佳触及范围,同时保持精确的手指控制以进行抓握。在此之前,在如此高维的动作空间中实现这种精度水平是很难的,即使对于单个且已知的任务也是如此。Figure 公司表示,之前还没有 VLA 系统能够表现出这种程度的实时协调,同时保持跨任务和物体泛化的能力。
Helix 的 VLA 能控制整个人形机器人上半身,这是机器人学习领域首个做到一点的模型。
零样本多机器人协同
Figure 表示,他们在一个高难度多智能体操作场景中将 Helix 推向极限:两台 Figure 机器人协作实现零样本杂货存放。
视频 1 展示了两个基本进步:两台机器人成功地操作了全新的货物(训练期间从未遇到过的物品),展示了对各种形状、大小和材料的稳健泛化。
此外,两个机器人都使用相同的 Helix 模型权重进行操作,无需进行特定于具体机器人的训练或明确的角色分配。它们的协同是通过自然语言提示词实现的,例如「将一袋饼干递给你右边的机器人」或「从你左边的机器人那里接过一袋饼干并将其放在打开的抽屉里」(参见视频 4)。这是首次使用 VLA 展示多台机器人之间灵活、扩展的协作操作。考虑到它们成功处理了全新的物体,这项成就就显得尤其显著了。
Helix 实现精确的多机器人协同
涌现出「拿起任何东西」能力

只需一个「拿起 [X]」指令,配备了 Helix 的 Figure 机器人基本就能拿起任何小型家用物品。在系统性测试中,无需任何事先演示或自定义编程,机器人就成功地处理了杂乱摆放的数千件新物品 —— 从玻璃器皿和玩具到工具和衣服。
特别值得注意的是,Helix 可以建立互联网规模的语言理解和精确的机器人控制之间的联系。例如,当被提示「拿起沙漠物品」时,Helix 不仅能确定出玩具仙人掌与这个抽象概念相匹配,还能选择最近的手并能通过精确运动命令安全地抓起它。
Figure 公司表示:「对于在非结构化环境中部署人形机器人,这种通用的『语言到动作』抓取能力开辟了令人兴奋的新可能。」
Helix 可将「拿起 [X]」等高层面指令转译成低层动作。
讨论
Helix 的训练效率很高
Helix 以极少的资源实现了强大的物体泛化。Figure 公司表示:「我们总共使用了约 500 小时的高质量监督数据来训练 Helix,这仅仅是之前收集的 VLA 数据集的一小部分(<5%),并且不依赖多机器人~收集或多个训练阶段。」他们注意到,这种收集规模更接近现代单任务模仿学习数据集。尽管数据要求相对较小,但 Helix 可以扩展到更具挑战性的动作空间,即完整的上身人形控制,具有高速率、高维度的输出。
单一权重集
现有的 VLA 系统通常需要专门的微调或专用的动作头来优化执行不同高级行为的性能。值得注意的是,Helix 仅使用一组神经网络权重(系统 2 为 7B、系统 1 为 80M),就可以完成在各种容器中拾取和放置物品、操作抽屉和冰箱、协调灵巧的多机器人交接以及操纵数千个新物体等动作。
「拿起 Helix」(Helix 意为螺旋)
总结
Helix 是首个通过自然语言直接控制整个人形机器人上半身的「视觉 - 语言 - 动作」模型。与早期的机器人系统不同,Helix 能够即时生成长视界、协作、灵巧的操作,而无需任何特定于任务的演示或大量的手动编程。
Helix 表现出了强大的对象泛化能力,能够拿起数千种形状、大小、颜色和材料特性各异的新奇家居用品,并且这些物品在训练中从未遇到过,只需用自然语言命令即可。该公司表示:「这代表了 Figure 在扩展人形机器人行为方面迈出了变革性的一步 —— 我们相信,随着我们的机器人越来越多地协助日常家庭环境,这一步将至关重要。」
虽然这些早期结果确实令人兴奋,但总体来说,我们上面看到的还都属于概念验证,只是展示了可能性。真正的变革将发生在能大规模实际部署 Helix 的时候。期待那一天早些到来!
最后顺带一提,Figure 的发布可能只是今年~众多突破的一小步。今天凌晨,1X 机器人也官宣即将推出新品。
参考内容:
https://www.figure.ai/news/helix
https://x.com/op7418/status/1892612512547213312
https://x.com/ericjang11/status/1892665299704422667
https://news.ycombinator.com/item?id=43115079
#深度解密DeepSeek-R1、Kimi 1.5,强推理模型凭什么火出圈
刚刚过去的春节,DeepSeek-R1 推理大模型引爆了国内外 AI 社区,并火出了圈。最近,各个行业又掀起了接入 DeepSeek 的狂潮,大家唯恐落后于人。
北大 AI 对齐团队对包括 DeepSeek-R1、Kimi-K1.5在内的一些强推理模型进行了 2 万字的技术解读,也是此前 o1 解读(北大对齐团队独家解读:OpenAI o1开启「后训练」时代强化学习新范式)的续作。
,时长01:15:37
以下为完整的文字解读稿(以第一人称我们陈述):

下图是我们这次讨论的一个目录,涵盖了包括 DeepSeek-R1、Kimi K1.5 的具体的技术分析和讲解。同时也包括对其背后的社会和经济效益以及一些 insights 和 takeaways 的分析。
具体地来说,我们会进行相应的技术细节的讨论:比如说基于 STaR 的方法和基于强化学习的方法进行强推理模型复现的区分和产生的效果的不同。这里面就包括了 DeepSeek-R1、Kimi K1.5 和 o 系列的模型。我们也会分析蒸馏和强化学习驱动下不同的强推理路径复现的区别,同时也会探讨 PRM 和 MCTS,也就是蒙特卡洛树搜索在整个强推理模型构建过程中的作用。其次我们也会探讨一些从文本模态到多模态的实践。最后我们会对未来的方向进行一个分析和探讨,包括模态穿透、探索合成数据以及强推理下的安全。我们也会补充拓展 DeepSeek-v3 的解读。

DeepSeek-R1 开创 RL 加持下强推理慢思考范式新边界
近期后训练阶段开始成为语言模型中在完整训练过程中非常关键的一环,包括提升推理能力和社会价值对齐方面起到了非常重要的作用。自从 OpenAI o1 开启后训练强化学习新范式后,社区研究 Inference Time Scaling 通过增强 CoT 的长度提升推理能力的热情也是在逐渐增高。其中一个关键的问题就是如何通过有效的测试阶段的时间的扩展来提升它的推理能力。
近期 DeepSeek R1 的开源,也是再次让我们看到了强化学习的潜力。得益于纯大规模强化学习 DeepSeek-R1 Zero 和 DeepSeek-R1 的出现其实大大提升了推理能力和长文本的思考能力,其中 R1 Zero 是完全从基础模型开始构建,完全依赖强化学习,而不使用人类专家标注的监督微调。在训练过程中随着训练步骤的增加,模型也是逐渐展现出长文本推理以及长链修复的能力。随着推理路径的逐步增长,模型来表现出自我反思的能力,能够发现并修复之前的错误。

得益于强大的推理能力和长文本思考能力,DeepSeek R1 在开源以来就备受关注,其中它在著名的数学代码任务榜单上也是获得了非常突出的表现。比如在 AIME2024 上取得了 79.8% 的成绩,也是超过了 OpenAI o1。其中也在编码的任务上表现出了专家水平。与此同时,DeepSeek R1 在知识类问答的任务上推动了科学探索的边界,在无论 MMLU 还是 GPQA 等一些基于科学问答和理工类的榜单上都是取得了比较好的表现。更令人惊艳的是 R1 在一些长文本依赖的任务上比如 FRAMEs 和一些事实性推断任务上也是表现突出,其实也展现出来了强推理模型在 AI 驱动的一些 research 的潜力。

那么我们首先回顾一下预训练阶段的扩展律。其实也就是在预训练模型上,计算量数据和参数量成一个类似于正比的关系,也就是算力等于 6 倍的参数量乘上数据量。因此在大模型时代发展的初期,囤卡提升预训练的算力和模型参数变成了主要目标。

随着 OpenAI o1 的发布,也证明了在强化学习加持下后训练时代一个新的扩展律:随着模型在后训练阶段的训练时计算量和测试时计算量的提升,模型的性能特别是数学代码能力也会随之提升。那么在后训练扩展律下语言模型的训练时计算量多了一个新的变量,也就是在探索时语言模型推理产生的计算量。

为什么我们需要后训练扩展律?其实早在 2022 年就有启发的认知,主要是出于两个原因:第一个是随着模型尺寸的逐渐增大,预训练阶段参数的扩展带来的边际收益开始逐步递减,如果想要深度提升模型的推理能力和长程问题的能力,基于强化学习的后训练将会成为下一个突破点;第二个也就是自回归模型在传统的像数学推理问题上很难进步,其中的关键一点就是没有办法进行回答的自主修正,那如果仅是依靠生成的方法和扩大参数的规模在数学和推理任务上带来的收益不会很大。所以我们迫切地需要额外的 Scaling Law 也是额外的扩展律。

DeepSeek-R1 Zero 及 R1 技术剖析
业界其实近期有很多复现 o1 的操作,例如基于蒸馏或者强化学习的方法或者是从 MCTS 也就是蒙特卡洛树搜索和奖励模型的设计角度出发。通过搜索的方式显式的去帮助语言模型进行推理阶段计算量的提升,也有很多不错的尝试。但是大多数都是在特定任务上,例如数学或者代码的提升。
DeepSeek R1 Zero 的发布也是让我们看到了强化学习的潜力,特别是它跳过了经典后训练阶段中的监督微调,直接运用大规模强化学习就实现了推理能力的大幅提升,在数学代码等问题上显著飞跃。并且在强化学习训练过程中自然涌现长文本推理能力,这其中的关键操作核心在于一个是基于规则的奖励 Rule-based Reward 和以推理为中心的大规模强化学习。接下来我们也进行逐步的拆解。

在 DeepSeek R1 Zero 的奖励建模中采用了基于规则的奖励,也就是基于一定的规则可以直接利用程序进行判断正误的奖励信号。
具体来说 DeepSeek R1 Zero 设计了两种奖励:一种是准确率奖励,即对于推理任务是否根据最后答案的正确率直接来判断这个任务是否成功完成;第二种是格式奖励也就是显式的去规劝模型的输出过程中必须包含思考的过程,利用一个 thinking token 将思考的过程圈起来。需要注意的是这部分奖励建模并没有采用先前我们经常讨论的比如说过程奖励模型 PRM 甚至没有采用奖励模型。这里边的主要考量是基于神经网络的奖励模型都有可能遭受奖励攻陷的问题,一旦发生奖励攻陷模型就可能陷入局部最优解,而重新训练奖励模型需要大量的计算资源可能会复杂化整个流程。
而第二个在强化学习的训练模板选择上,DeepSeek R1 Zero 采用了最简单的思考过程,而没有去在 system prompt 中加入过多的去诱导模型产生特定的思考范式,比如说去产生反思等范式。这一期望是可以希望能够直接观察到在 RL 过程中最本质的表现。

DeepSeek R1 Zero 更为关键的是以推理为中心的大规模强化学习。具体来说在传统的 RLHF 算法上 DeepSeek 进行了一些算法的细节优化,采用了像组相对策略优化也是 GRPO,这部分我们也会后续讲解技术细节。同时它只瞄准了推理方面的专项任务。通过大规模的强化学习模型已经呈现出了自我迭代提升的趋势,也就是随着训练步数的增加模型的思考长度会逐渐增长,这也对应着模型在测试阶段的计算量的增长,也就是推理时长的提升。
与此同时模型也在中途训练过程中涌现了 'Aha' moment,学会用 wait 等停顿词,自然的去增加更多的推理时间,并且反思和评价先前的步骤并主动去探索其他的方法路径。

DeepSeek 的成功也为我们带来了一些关键的启示:例如在传统的大语言模型训练中监督微调通常被认为是不可或缺的一环,其逻辑是先用大量人工标注的数据来让模型初步掌握某种能力或回答范式,再利用强化学习进一步优化模型的性能。
然而 DeepSeek 却打破了这一传统,他们选择直接将 RL 应用于基础模型,而没有经过任何形式的 SFT 训练。这种纯强化学习的方法之所以如此引人注目,是很大程度上因为它抛弃了对于大规模人工标注数据的依赖。众所周知 SFT 是非常需要消耗大量的人力物力来构建和维护高质量的训练数据集,而 DeepSeek 的团队这种做法可以直接让模型在强化学习的环境中进行自我探索,通过与环境的互动,自主的去发现和学习解决复杂问题的能力,就好比一个初学者在没有老师的指导下通过不断的尝试和错误,来掌握一门新的技能。这种自主学习的方式,不仅节省了大量的标注成本,更重要的是它能让模型更加自由地探索解决问题的路径,而不是被预先设定的模式所束缚,这也使得模型最终具备了更加强大的泛化能力和适应能力。

而之所以能够跳过监督微调阶段直接运用纯强化学习拓展推理能力的边界,其实也得益于以下几个关键之处。
首先是要有足够强的基座模型,DeepSeek R1 Zero 系列的模型是在 DeepSeek v3 的 671B 的基座模型上进行了训练,它的基座模型是超过了某个质量和能力的阈值的,它在 14.8T 的高质量 Tokens 上进行训练,其实基座模型在预训练阶段积累的海量知识,是可以帮助模型在强化学习加持后突破推理上界。这是因为在预训练阶段积累的知识和思维方式是相对更高阶的,就像人类大师和新手都可以通过自博弈来提升自己的能力,但是由于人类大师的先验见过的东西更多,所以潜力更大。近期也有一些利用小模型复现 'Aha'moment 的工作,这得益于高质量的推理数据和大规模的强化学习,但若是要进一步去提升推理能力的边界,足够强的基座模型是必不可少的。
其次是大规模强化学习的加持,即通过 GRPO 对于训练过程进行优化。
最后是奖励规则化奖励,通过绕过奖励攻陷模型,规则化奖励能够直接基于固定的规则进行奖励判定,但规则化奖励能够成功的前提也很大程度上得益于关注的推理任务是可以进行自动化标注和验证的,这是和一般的聊天与写作任务相不同的。

在这里我们举一个自动化标记和验证的例子,例如对于一个推理问题,我们希望模型可以编写一个 Python 代码,那么自动化验证的方法,就可以分为这么几步:第一步是利用软件去检查代码补全,比如说判断它是否是完整的代码;第二步是执行 Python 代码,来检查运行情况,查看它是否是可运行的;第三是我们可以调用外部模块,来构建额外的检测单元;第四甚至我们可以更进一步的,为了去约束模型进行有效的推理,我们可以测量程序的执行时间,从而使训练过程首选性能更高的解决方案。而以上的奖励信号都是可以作为小批量训练和连续训练过程中的奖励信号的。

这里有个示意图也就是根据不同的规则,进行形式化的验证和判定,最后解的分数就会转化成强化学习训练过程中的奖励信号进行反传。

但是 DeepSeek-R1 Zero也有对应的问题,比如说长推理过程可读性差,语言混合帮助性低。那么我们能否在 zero 的基础上,在兼顾推理性能的同时,提升模型的帮助性和安全性的。例如能不能产生一些比较清晰且直接的推理过程,并且能够泛化到通用能力任务上的模型。例如 R1;以及我们能否利用一些高质量的反思数据去做冷启动,从而加速强化学习的收敛或者帮助提升推理表现。那么围绕这两个研究问题,应运而生了 DeepSeek R1 这个模型。

总的来说 DeepSeek R1 的技术 pipeline 可以被总结为这么一套范式。首先第一基于 DeepSeek v3-base 产生了 DeepSeek R1 Zero 这个模型,第一阶段是我们希望先增强 R1 zero 的推理链的可读性,在这一阶段我们会利用一些冷启动的数据,这些数据里边可能是包含了人类专家和模型所撰写的高质量的语言,符合语言格式的这样一些反思数据。然后我们再以推理为中心的强化学习去进一步的去进行微调,从而获得一个相对推理链可读性更强的一个中间模型;那么更进一步我们采用传统 RLHF 中的一些技术,比如说通过拒绝采样和全领域的监督微调以及在全领域的任务上进行强化学习的训练,比如对于推理任务我们可以使用规则奖励,而对于一些通用比如说聊天任务我们进行偏好建模,从而来在第二阶段去提升模型的通用能力和安全性,最终获得了 DeepSeek R1 这样一个模型。

接下来我们进行具体的讲解,首先是第一阶段,我们如何去提升模型的推理链的可读性,在这个环节我们分为两个阶段:第一个是冷启动,第二是以推理为中心的强化学习。在冷启动阶段其实我们准备的数据是一些高质量的更长思维链的带反思和验证的数据集,这部分数据集它其实是由人类的注释者和 R1 Zero 产生了一个高质量链式思考,它的成效其实是说引入一些人类的先验,同时去提升它推理链的语义连贯性和可读性,然后并且让模型获得一个最基本的能力。

第二阶段就是和 DeepSeek R1 Zero 构建的过程相一致的,用以推理为中心的强化学习通过增强大规模的训练过程来进一步提升冷启动后的模型的推理问题的的推理能力。与此同时,除了传统的格式奖励之外,在这里还引入了语言一致性的奖励。因为在 DeepSeek-R1 Zero 中我们观察到了比如说思维链中可能会混合带有不同语言的现象,通过引入通过计算思维链过程中目标语言的占比作为一个语言一致性奖励,从而可以衡量长推理链的可读性。第二个奖励信号也就是推理正确率的奖励,通过 GRPO 模型也是能够在 AIME 这些数学基准上 Pass@1 的正确率就有一个非常大的飞跃的提升。
与此同时,模型也能够自发地去延长推理链条,展现出更强的逻辑连贯性,获得了一个推理可推理链可读性更强并且有基本推理能力的模型之后,我们在后续再采用传统的 RLHF 中的像监督微调、拒绝采样以及全领域的强化学习来帮助模型去获得一个通用能力和安全性。在监督微调中和之前冷启动的数据是不同,这部分的监督微调主要还是负责全领域的任务,它除了包括一些推理任务的数据之外,还有一些比如说像角色扮演通用任务。这个成效是在使模型在推理能力不减的前提下,语言表现更为自然,适应性更为广泛。在经过全领域的 RL,其实可以进一步提升除了推理能力之外的帮助性和安全性。对于帮性安全性,其实我们就用传统的奖励模型来建模人类的偏好和意图就可以了。最终版本的 R1,其实不仅是在推理和对话任务上达到了高水平,还更具备更安全的交互性能。

在这一部分我们先总结一下 DeepSeek-R1 的一些技术亮点和 takeaways。首先社区对于强推理模型的复现都涉及一些蒸馏和搜索,而 DeepSeek R1 Zero 它是跳过了监督微调阶段。这得益于以下几个点:第一是需要足够强的基座模型来帮助它去突破一个质量和能力阈值的上限,第二是需要大规模强化学习的加持,第三是规则化奖励,但规则化奖励是得益于一些推理问题,它可以进行自动化的标记和验证。通过强化学习在实验过程中其实观察到了训练步数的增长模型的思考过程的长度是逐步增长的,这一增长其实也代表着在 test time 也就是测试任务阶段的一个算力的提升。DeepSeek R1 Zero 也是自主涌现了一个学会评测原来的方法反思和主动探索,其他路径的这样一个能力。
与此同时,多阶段训练下的冷启动,其实也让强化学习的训练更加稳定,从而避免了强化学习初期不稳定,加速收敛并且提升思维链可读性的这样一个能力。那么未来其实后训练的中心,它会逐步倾向于用强化学习,但是少量的数据去用于监督微调还是必须的。与此同时强化学习的一个非常大的魅力就是说它不只局限于基于规则的数学和算法代码等容易提供奖励的领域,它还可以创造性的把这个推理能力泛化到其他领域,甚至是从文本模态泛化到多模态。DeepSeek R1 Zero 和 DeepSeek R1 它其实背后有一些非常深的技术。我们在这里进行逐步地剖析。

首先第一个是它背后的教师模型 DeepSeek-v3 它其实能够在 14.8T 的高质量 tokens 上进行训练,其实类似于提供了一个 System I 一个足够好的直觉也就是 prior distribution,其实方便后续的 RL 过程的进一步的探索和挖掘。与此同时 DeepSeek-v3 的低成本,其实也是带来的惊艳效果也是让社区非常震惊的,比如说基于 MoE 的架构,其实用 2048 张 H100 就可以 54 天就可以进行一场训练。在 PPT 讲解的最后,我们也是会对 DeepSeek-v3 的具体的架构创新点,还有它采用的一些技术上的优化,进行一个简单的讲解。

第二个值得关注的也就是在 DeepSeek R1 中所揭示的 RL 加持下的一个长度泛化和推理方式的涌现,在大规模强化学习的加持下 DeepSeek R1 Zero 其实表现出在推理任务上思维链长度的自然增长和涌现。
具体来说,随着反思深度的逐层加深出现了它可以标记不明确的步骤,保持中间结论验证和混合语言推理等现象。与此同时,虽然我们传统说模型仅通过准确率奖励和格式奖励就是不足够的,或者说它的奖励信号可能是不够不充足的。但是在 R1 的实验中发现,即使是通过这么稀疏的奖励信号模型也是能够自然探索到一个验证、回溯总结和反思的行为方式的。这里面背后就有一个问题,也就是如何控制来保证最后的回答的长度能够稳定上升。那这其实是一个非常关键的问题,因为模型可能会出现反复重复验证或者验证时间过晚的情况。最近社区也有一些复现的结果,包括我们自己团队也在复现,其实我们发现除了 GRPO 以外,像 REINFORCE 系列的算法以及 PPO 等,都是可以出现类似的结果的。REINFORCE 系列的算法,它是更快更好的,PPO 它训练相对更加稳定,但是会更慢一点。
第二点就是我们涌现的推理范式,它其实会展现出多语言混合的思维链。其实它背后的一个原因可能是在预训练数据过程中它是多语言的,不同语言的数据它其实是被一视同仁的被 Tokenization ,那么其实背后一个问题就是不同领域的不同语言编码是否可能会有不同的优势。比如说其实我们人类在进行讲解和思考过程中,很有可能也是进行比如中英文混杂的思考的,那些模型内部是不是也有类似不同于人类思考范式的这样一种语言推理的能力,其实对于后续揭示一些推理链的可解释性是非常重要的。

在这里我们具体讲解 GRPO 是如何赋能强化学习的扩展的。GRPO 的核心思想是通过构建多个模型输出的群组,也就是对于同一个问题去产生可能是 N 个回答,计算群组内的相对奖励来估计基线相对奖励。它主要去解决一个问题,就是在传统的策略优化算法比如 PPO 中通常是需要一个与策略模型大小相同的一个 Critic Model 来估算它的 value,那我们把 value model 去掉其实能够提升它整个训练的稳定性和降低算力的消耗。与此同时,其实我们 GRPO 还可以引入一些额外的优化策略,从而去提升训练稳定性。
我们进一步讲解一下如何从 PPO 推导到 GRPO,其中 PPO 它作为 Actor-Critic 的算法,也是被广泛应用于后训练,它核心目标也就是优化下面这个奖励函数。为了避免模型的过度优化,我们通常会在每个词源的后边加上一个与 Reference Model 也就是参考模型的一个 KL 惩罚项。

PPO 的奖励函数通常是与策略模型规模相当的独立模型,就是 Critic model,这会带来非常大的一个内存和计算的增加。与此同时第二个问题就是奖励模型,通常它要对输出序列的最后一个词源,去分配奖励,导致它逐 Token 的价值函数的训练是会不断复杂化的。
GRPO 其实如右下图所示, GRPO 中是省略了 value model 的过程,比如说我们不用去估算我们可以直接利用一个组利用多个 output 去计算 reward,然后利用这个 reward 在组内进行一个相对值的估计来获得一组优势值,我们相应的优化的策略就变成了对于整个优势值,包括原来 PPO 的目标函数改变过来直接进行优化。包括 KL 散度的惩罚项,它不会直接加到奖励里边,而是直接加到策略函数优化的目标函数里边,这也是简化了整个 At 的过程的计算。它和奖励模型的对比性质其实是天然契合的,因为奖励模型本身也是基于同一个问题的输出进行一个 preference 的比较训练;GRPO 是在计算组内优势值的时候进行一个相对值的计算,其实它能够提升组内好回答的比例,降低组内坏回答的比例,其实天然是具有相对优势的。

GRPO 它其实分为两种:第一个是基于结果的,第二是基于过程的。对于基于结果的形式,对于每个问题可以采用一系列的输出奖励模型去为这一系列的输出去生成奖励,那么随后去通过进行一个 normalization,也就是进行归一化,然后把归一化后的奖励去分配给每个输出的末尾的 token,然后去设为对应的 reward 就可以了。其实它的表达式就是这样的,相当于传统的优势值计算是非常简化的。进一步其实也可以把 GRPO 扩展到基于过程的监督下,因为是结果监督,它是仅提供输出末尾的奖励,对于复杂数学任务的策略指导是不足的。进一步我们可以对于一个问题去采样多个输出,我们利用过程奖励模型去为每个步骤去生成奖励,比如生成一系列的奖励的信号规一化之后,优势值为最后奖励信号一个逐步的累加和,其实它作为一个过程监督的算法也是非常方便的。

这是对 DeepSeek-R1 的 Takeaways 的第二部分总结,R1-Zero 它其实节省了大量的标注成本,那么使模型获得了更加自由探索解决问题的路径,它不会被预先设定的模式所束缚。为了充分的去释放强化学习的潜力,同时去解决像 R1-Zero 中出现的语言混杂以及训练不稳定等等特性,DeepSeek R1 的训练中采用了四阶段交替训练的过程,那是从监督微调到强化学习再到再次的监督微调以及强化学习,从而通过冷启动来解决了一些收敛效率的问题。
DeepSeek R1 也是自主涌现了像自验证,反思和长链推理能力,比如自验证它会一个模型在生成最终答案之前会主动的验证自己的中间推理步骤是不是正确的,就像是一个学生在做题的过程中会反复检查自己的解题过程来确保答案的准确性;反思是指模型会回溯检查自己之前的推理过程并根据检查的结果进行修正,相当于一个学生在复习的时候会反思自己之前的错误,以便下次不再犯同样的错误;而长链推理能力则是让模型能够处理复杂,更需要多步骤思考的问题,这种能力对于解决一些需要跨越多个逻辑步骤,才能找到答案的问题至关重要,也有复杂的数学题或者逻辑谜题。冷启动也能够让强化学习的训练更加稳定,比如加强它的收敛性,以及提高模型输出的可读性。

我们展现出了几个比较关键的技术,比如说推理为中心的强化学习训练,其中就是语言一致性奖励以及多目标优化。还有 GRPO 也就是基于群组的相对策略优化,这样一个非常关键的技术。在奖励机制的设计上其实也是比较重要的,因为既要兼顾一个推理能力,也就是通过准确率奖励和格式奖励来去进行限制,那也要引入一个语言一致性奖励,从而惩罚在推理过程中使用多种语言输出的这么一个现象,从而去鼓励模型尽可能去使用一种目标语言进行推理来保证模型输出的语言风格的一致性。

DeepSeek R1 其实也带来了很强的社会和经济效益,背后其实是一个低成本和高质量语言模型边界的探索,我们其实整个大语言模型发展过程,它的扩展律最初是模型的规模、然后是数据集的规模,现在是推理时的计算资源和合成数据。这就意味着 DeepSeek R1 其实能够更方便地整合到,像 AI2Science 也就是计算科学以及一些大规模的 API 应用中。通过垂直领域和横向的拓展,比如说引入 RAG 的技术等等,这其实都是非常方便的。当然也带来一些经济效益,比如说资本市场的剧烈波动,包括像研发的投入和数据的数据中心的建设成本激增,其实背后也是算力军备竞赛的一个循环,其实随着模型使用方案的平民化,资源也是能够得到有效的优化,从而能够在有限的算力资源支持下,突破算法的创新然后突破算力的限制。

技术对比探讨
与 DeepSeek-R1 同系列出现的,其实还有 Kimi k1.5。我们也是先对 Kimi k1.5 的技术进行一个简单的讲解,然后去对比和分析这两个模型它采用的技术背后是不是有什么可取之处,以及和我们推测和社区的一些其他复现结果的一个对比。
Kimi K1.5 其实和 Kimi 系列的模型其实是一样,它是都是想要用长文本来解决一些问题,比如说 Kimi K1.5 其实专注于利用长文本的 CoT 输出来解决推理时的扩展问题,它的核心也就是通过强化学习来让模型去试错来学习解决问题的能力,它通过将强化学习的优化方式进行一个修改来应用于长文本推理链生成的过程,从而启发模型进行更深入更复杂的推理。
其实和 GRPO 的采用有很大的不同,他们采用的技术其实是一个 REINFORCE 系列的一个算法的变形,其实 Kimi 一直关注的也就是长文本能力的拓展,核心的 insights 也就是长文本能力是强化学习训练语言模型的关键,而不是需要一些更复杂的训练技巧。其中他们还有一个更 interesting 的地方是长文本到短文本的一个拓展,通过长文本的思维链模型来指导短文本模型的训练,从而能够在有限的计算资源下去获得更好的性能。我们可以看到它在一些数学推理代码推理的任务,包括视觉推理的任务上其实都超过一些开源的模型和 OpenAI 的系列模型。

具体来说, Kimi k1.5 的过程是分为 4 阶段:第一是预训练阶段,然后进行了监督微调,进一步为了扩展它的长文本思维链推理能力进行了 long cot 的监督微调,进而进行了强化学习的训练。这里边也采用了一些相应的一些 recipes 一些技巧,其实也是在这里可以一块分享给大家。
首先是对于 RL 问题的准备,我觉得这其实也是社区复现的一些共用的技巧,比如说希望 RL 的 Prompt 能够涵盖足够多的范围,比如说包括代码 Coding/通用任务以及一些理工科问题的数据。同时 RL 训练也要去 balance 不同的难度,从而达到一个从易到难课程学习的效果。与此同时这些 RL prompt 的像数据代码问题,它最好是能够被一些 Verifiers 准确的评价,这可以防止防止泛化出一些奖励攻陷以及一些 Superficial Patterns,就是一些浮于表面的一些表征的这样一个行为。进一步在 Long CoT 监督微调过程中,他们是构造了这么一个 warm up 的数据,其中包括一些比较准确的推理路径去 for 图文的输入,那也是涵盖了一些 planning,评价反思以及探索的方式,然后从而让模型或在 RL 训练过程前就获得这样一个比较好的启动的方式。

其实更有趣的是说,Kimi k1.5 是从一个 In-Context RL 的角度出发,也就是我们传统在 MCTS 过程中和包括一些搜索过程都是一个可以被视为一个 planning,也就是规划的过程。我们与其通过规划来使得模型显式的去扩展计算量,为什么不能用模型去模拟 planning 过程,比如说其实在整个搜索的过程中,我们可以将每个 state 比如每个状态和对应状态的价值,都视为一个 language token。从这样的角度出发我们其实就可以把它建模成一个 contextual bandit 的问题,然后从而利用 reinforce 的变种进行优化。与此同时我们与此同时,其实 Kimi-K1.5 还需要引入一个长度惩罚的机制,从而防止模型它去生成过长的推理过程来提高它的计算效率。其实模型也会出现这样一种 overthinking 也就是过度思考的行为。Overthinking 的过度思考的行为其实可能会导致一个更好的表现,但是会带来训练和推理过程中更大的算力的损耗。
与此同时 K1.5 也用了一些采样策略的优化,其中包括课程学习和优先采样的算法,比如课程学习也就是根据问题的难度让模型去先学容易的例子,然后再逐步引入更难的例子,从而循序渐进的去掌握知识。优先采样也就是根据难度和对于问题的掌握程度来调整采样概率,使模型更倾向于去采样那些困难的或者不擅长的问题,来提高它的训练的效率。长度惩罚其实也就是采用像下面这个公式所示的我们采用一组这样一个回答,然后通过计算组内的最最大长度和最短长度来计算这个平均长度作为一个 reference 值。第二个就是策略优化的损失函数也就是我们直接其实可以采用一个 reinforce 的变种去优化 surrogate 的 loss。

其中 Kimi K1.5 还采用了一些视觉数据的构建,包括像真实世界的数据其中就包括一些位置的猜测。然后传统的 VQA,其实它是为了提升模型,在真实场景中的视觉推理能力;第二个是合成视觉推理数据,也就是它是一个人工合成的,比如去提高主要是提高一个空间关系、几何模式和物体交互的这么一个能力。这些合成数据提供了一个可控的环境用于测试模型的视觉推理能力,并且可以去无限生成一个虚拟样本;第三个也就是常用的文本渲染数据,通过将文本内容转化为视觉格式来从而保证模型能够在不同模态下保持一致的文本处理的能力,其实就是将比如说一些 OCR 的技巧将这个文本的文档和代码的片段转化为图像,来确保模型无论接受的是纯文本输入,还是截图或者照片中的文本,都能够提供一致的 Response。
K1.5 还展现出来一个比较优秀的方法,也就是 long2short 长到短的蒸馏。它其实背后想要解决的其实是模型的一个过度思考,以及我们能不能采用进行算力的控制。也就是通过采用更短的思维链达到和长思维链相同的效果。其实 Kimi 探究了这么几个方法:首先是模型的融合,比如说将长文本的思维链模型和短文本思维链模型的权重进行平均,从而得到一个新的模型;第二个是最短拒绝采样,也就是在多个采样中选择一个最短并且答案最正确的答案然后去做监督微调,其次是采用像 DPO 等技术来使用长文本 cot 模型生成的答案来作为偏好数据来训练短文本 cot 的模型,在标准的 RL 训练过程中,其实可以类似于前一步我们采用的长度惩罚项来进行微调,从而进一步的去提高短文本 CoT 模型的效率。

在这里其实我们对比一下 Kimi K1.5 和 DeepSeek R1 的一些技术,我们其实能够发现一些共通之处和一些 Takeaways。首先二者都关注了 RL 的,也就是强化学习的方法带来的提升,MCTS 和 PRM 其实是都没有被使用的,包括我们之前的一个推测以及社区的很多复现过程中其实都关注了 MCTS 和过程监督模型,但是它们没有被显式的使用。其实背后是有着奖励攻陷的考虑的,之所以直接用纯 RL,其实背后的考量是对于模型思考能力的 structure,也就是其实这个 structure 相当于是人类的一个先验,其实我们可以认为 MCTS 它是一种 structure,A * 它也是一种 structure,人为的加入 inductive bias 去强求语言模型按照结构化的先验去进行思考,它其实是可能会限制模型的能力的。那么后续我们也会进一步讲解这个问题。
第二点是过程的结果奖励模型,它其实很容易被奖励攻陷,并且绝对值的 value 是很难准确的去估计奖励的,与此同时我们其实会有两种方法:第一个比如说虽然我们绝对值的 value 很难准确的估计,但我们可以用它去构建一个偏序的数据集;第二就是我们直接不用过程奖励模型,Kimi K1.5 其实更多是从 In-context RL 出发是希望模型去模拟 planning 的过程,而不是去显式的进行 planning,其中就是将 state 和价值等信息都视为一个 language tokens;而 DeepSeek R1 是从纯强化学习的角度出发,通过大规模的强化学习和 rule-based reward 来激活模型的能力,其中核心的观念都是不管模型中间做错了什么,它只要不是重复的 pattern,只要模型最后做对了,我们就认为这是一个好的探索,它是值得鼓励的;反之如果模型一顿探索最后做错了,那么再努力也是错,这是需要去进行惩罚的。

关键的也就是强化学习算法的对比,其实 DeepSeek R1 采用的是 GRPO,GRPO 是通过群组相对方式去计算优势值,然后它和奖励模型基于同一问题的输出它是天然契合的,而 GRPO 它额外的进行了策略函数的优化,比如说其实我们可以回到前面这一页,我们可以看到其实传统的我们是会把 KL 散度的惩罚加到 reward 里边,然后计算优势值,但是在 GRPO 里边,我们可以直接把惩罚项融入到这个目标函数计算里边,简化计算的难度和算力的损耗,使得这 GRPO 它其实在大规模的强化学习训练任务中,能够更有效的去优化策略模型,然后进而去提高它的计算效率。
Kim K1.5 其实它采用了一种变种 Mirror Descent,它可以保证学习的稳定性,其实本质上也是属于 REINFORCE 系列算法的一种,可以促进模型去探索到验证回溯总结的反思的行为方式。第二个关键点是后训练的 Pipeline 其实对于提升模型的推理能力重要性都是不可忽视的,一方面是随着测试阶段算力和训练阶段算力的增加,根据后训练扩展律模型的表现是会被持续改善的,另一方面是理想的数据构建应该涵盖足够广泛的类别并且难度分级明确,这样有利于实现类似于课程学习的效果,从而逐步提升模型的能力。最后一个 takeaways 是说在奖励建模的过程中,其实我们需要确保如果你的奖励机制是基于奖励模型的话,那么就要防止它的奖励攻陷,比如说还需要去进行一个平衡的推理长度和推理正确率之间的一个关系,比如对于同一个序列它的下一个动作可能存在一个错误答案,也存在一个直接引入到正确答案的情况,那么传统的强化学习的方法的 Credit Assignment 的问题会倾向于去提升选择正确答案的概率,同时降低去选择错误答案的概率,然而从推理长度的角度来说,有时就选择看似错误的答案,可能会引导模型进行一个自我修正的过程。这种自我修正的机制,以及更长的推理路径,同样对于提升模型的整体推理能力,是至关重要的。

第二个我们希望对比的技术讨论是通过纯强化学习和 STaR-base 的一些方法的对比。在这里我们先回顾一下 STaR 的方法,STaR 方法核心是说我们有一些问题和答案的问题,我们希望能够让模型自己生成问题是如何导向答案的推理过程,并且将这些推理过程加入到模型的监督微调的数据集中,从而每次获得一个新的数据集,都从一个原始的模型来开始进行微调不断的去激发模型自己产生 Rationales 就是思考过程的能力。

STaR 和 RL 之间其实是有着紧密联系的,比如说去采样一个潜在的推理路径,它其实是类似于通过强化学习进行一个策略选择的动作,然后就选择一个可能的策略路径,对于计算目标函数其实对于模型对于整个数据集的预测结果进行评估,并且只根据预测的正确的样本更新模型。它其实是和传统强化学习中一个梯度的更新,其实是类似的,也就是通过多次的调整同一批的数据来稳定学习过程。

关于强化学习和 STaR 方法的对比,其实 STaR 的核心思路是希望将思考过程建模到语言的 next token prediction 中,它这个过程是通过反复的自我迭代和监督微调实现的。基于 STaR 的方法可以进一步将这种思路扩展到比如思考过程其实也可以是搜索过程,那也就是 planning 直接去建模语言模型的 next token prediction,比如说 rStar-math 以及 stream-of-search 甚至 Kimi K1.5 的核心思路都是这样的。
本质上 STaR 一类的方法是希望模型能够学习到 MetaCoT 及问题的答案映射过程背后的一个深入的规律,比如说对于为什么 1+1=2,其背后可能是说一个加法的规律,我们是希望 1+1=2 背后的加法的运算律,它是能够作为一个隐式的思考过程或者隐式的合理过程被模型学习到参数之中的,但其实它对于问题的结构要求会比较高,对于复杂数学的推理任务,它是可能难以自我迭代的。因为某些可能根本没有办法去生成一个好的推理过程,并且难以融入一个 Rule-based 基于规则的这么一个奖励来进行强化学习的优化;第二就是在纯强化学习的加持下,其实业界的技术实践它更多的去关注于直接利用强化学习去激活基座模型的推理潜力,通过构建 Rule-based Reward 也就是基于规则的奖励,加上强化学习数据的设计来去激活模型内部本身的能力相关的一些奖励模型的尝试,比如说 PRM 它其实会遇到像奖励攻陷,以及估计的价值不准、难以泛化等问题。

第三个我们希望讨论的是蒸馏和强化学习之间的对比。一方面这些对比来自于我们像 DeepSeek R1 中揭示的能不能将一些更强大的推理能力的模型,它的高阶推理范式蒸馏到小模型中;另一方面是我们能不能利用蒸馏后的模型来进行训练,从而超过传统强化学习的边界。其实背后的考虑是说其实大型模型,它虽然性能强大,但是也存在着一些局限性,比如计算资源消耗过高、部署和使用门槛较高等。模型蒸馏的核心思维就是将一个经验丰富的老师的知识传递给一个年轻的学生,从而将让其在一个较短的时间内去掌握复杂技能。
DeepSeek R1 Report 中其实揭示了我们通过蒸馏 R1 的手段,可以获得一系列突出表现的小模型,其实这很大程度上是得益于 R1 的模型它是足够强大的,因为它有很多高级的推理方式,而高效推理方式是小模型利用大规模的强化学习可能是难以发现的。这难以发现的原因可能是由于训练知识的不足,很难去进行一些有效拓展,比如说同样是下围棋,其实人类大师见过了更多的棋谱,他要知道下一步可能下个在某个位置,它可能相对的价值更高,而人类小白其实没有办法去辨别不同的位置,它的价值是否有不同,其实获得推理方式也就是有差别的,这些的话小模型表现会相对比较突出,甚至超过了基于大规模强化学习的方法。

那在提升模型的推理能力的努力上,其实蒸馏和强化学习也被社区广泛探索,比如说直接利用监督微调去蒸馏,其实可以学到数据背后的推理方式。但是它虽然在推理分数上有表现所提升,但它更多是去拟合数据中的 Pattern,很难学习数据背后的数学规律和我们所说的一个 MetaCoT 的过程,而强化学习是通过试错和尝试来鼓励模型在最大化奖励过程中去学习到推理背后的规律,获得的泛化性和推理表现的上界都是更高的。
与此同时,其实我们一个社区的 Common Sense 或者是说在对齐过程当中实践是监督微调主要是负责记忆,而很难实现 out of distribution,也就是分布外的泛化,而基于结果奖励模型的强化学习是能够获得更高的泛化能力的。对于此的理解,其实我们一般在后训练的阶段中是采用监督微调来规劝模型的输入格式,从而使得后续的强化学习可以获得更高的收益。随着强推理模型出现的兴起,其实社区也有很多的工作来比较长文本的思维链的这种效果,比如说其实背后是说如何去 scaling up 可验证的奖励会成为一个核心。对于一些小模型来说,其实也有一些工作发现其实像 Qwen-math-7b 这些,它是不容易 recentivize 长思维链的范式,比如说一些 'aha' Moment。那么在像 Math 场景下,其实像 wait check 这些词,它是在 RL 训练中没有进行明显的增加的,所以如何将蒸馏和强化学习 combine 起来,其实还是一个比较关键的社区的问题。但是我们如果要突破强化学习的或者突破推理的能力的上界的话,其实还是要依靠强化学习。

这里有一些 open questions 是比如说长思维链的指令数据扩展,它是否是有助于提升慢思考推理能力,以及我们如何去构建这样的长思维链数据来获得最佳的样本效率,进一步的我们长思维链的扩展是否有助于多模态任务。
我们之前的一些尝试是比如 RedSTaR,其实在这份工作中我们是发现了这么一些 takeaways:首先长思维链它是能够在有限的数据下去增加推理能力的,比如说只需要 1300 条数据,数据量较少的情况下去增加小模型的强推理能力。与此同时更大规模的模型以及更多专业预训练的模型,它其实在这样一个长推理链的微调中其实表现是更佳的,包括在较小的模型中,它正确的推理路径和处理复杂任务的能力,这也进一步证明其实预训练中的知识,对于后续无论是蒸馏还是强化学习的拓展都是有帮助的。
进一步其实任务和语言之间也可以通过长监督微调进行正迁移,比如说从而去帮助在通用任务上的语言的泛化性,以及在通过基础任务中去取得更好的表现,通过一些离线强化学习算法和 online 的强化学习算法,我们也能够提升模型的表现。与此同时将 long cot 应用到多模态大型模型,也是可以显著提升其性能的。DeepSeek-R1 也是现在只有文本模态,未来如何进行多模态的扩展也是非常关键的一个问题。

其实社区有一些方法比如最近非常火的 S1 模型,我们在这里进行一个简单的分析。Kimi K 1.5 中的 long2short 的方法其实本质上也是一种蒸馏,也就是我们如何将长文本思维链的模型的知识迁移到短文本的模型上,不过它的目标和策略需要更多样。不仅需要性能,还需要 Token 的效率,并且更多的去关注对于教师模型推理策略的学习,而不仅仅是输出。而 S1 模型,它是通过少成本去获得 o1-preview 的这么一个表现。
它关键是基于两点,第一个是高质量推理数据集的贡献,也就是进行挑选了 1000 条,关于数学竞赛博士级的科学问题、以及奥林匹克竞赛题目等,这些问题经过难度多样性和质量的严格筛选,它是包含了详细的推理轨迹和答案,它也能达到类似于课程学习的效果;第二个是采样策略的优化,其实他们采用了一个预算强制法来控制模型在推理时间的计算消耗,也就是通过引入 end of thinking 的 token,去控制模型的思维链长度,比如终止思考过程来转向答案生成的阶段。如果要增加计算投入的话,我们就会暂时阻止 end of thinking 的 token 出现来鼓励进一步的探索。DeepSeek-R1 为什么蒸馏的效果能够超过强化学习,其实主要是在于 DeepSeek R1 这个模型确实很大,然后他也确实发现了一些高级推理的范式。通过大规模的数据的蒸馏,它其实能够让小模型在任务表现上是超过小模型进行大规模强化学习的效果的。
但是它也有两个比较关键的点,第一是对于依赖强大的教师模型,第二是它的证明过程,通常是基于特定任务或者一组任务,比如说代码和数学问题来进行优化,这可能导致生成的小模型在面对新任务例如通用任务时它的适应性和方法能力是不足的。

接下来一个对比讨论就是 MCTS 和 PRM 的应用。我们知道其实社区包括我们之前的讲解,对于 MCTS 和过程奖励模型,实还是比较重视的。MCTS 的核心的方法,是将答案拆分成分句或者 Token 为单位的节点,然后对于解空间进行搜索。但是通过 MCTS 可能会有以下的问题,第一个是整个 token 的 generation space 是更大的,而不是像象棋一样,象棋中的搜索空间是相对一个良定义的,而语言模型它的 token 产生过程空间是相对更大的,它是更容易陷入局部最优的。第二是 MCTS 中的 value model 也非常重要,它直接影响了搜索方向,而去直接去训练一个更好的 value model 是相对比较困难的,所以在复现强推理模型的一些实践上,其实社区也有很多关注的如何进行 MCTS 算法的优化。
一个相对成功的典范是 rStar-Math,它是通过小模型就达到了 OpenAI o1 数学任务相当的水平,其中关键的核心思路是通过两个小模型的配合,其中一个是策略模型 policy model,另一个模型我把它训练成为基于偏好的过程奖励模型,它通过配合迭代,然后 MCTS 去产生分步验证的高质量处理数据,然后再进行一个自我迭代的提升,从而不断的更新数据,然后微调模型。其中背后的一个观点是说,我们提到 PRM,对于单个步骤的绝对值优化,它其实可能是存在问题,或者说难以估确准稳定的奖励,但是通过 MCTS 的模拟之后,我们虽然绝对值的评分是不准的,但它能够有效的识别出哪些步骤是正确的、哪些步骤是错误的,进而我们就可以利用 ranking loss,去训练一个偏序数据集。

比较树搜索和不同的奖励模型的一些方法,其实我们可以发现,传统的一些方案都是基于比如说像利用我们 MCTS 去构建数据集或者是说直接去显式在推理过程中加入树搜索的技巧来延长推理的时间,其实背后的相应有一些考量是说直接将树搜索应用到模型的训练过程中,是否可能会限制模型的思考过程。背后的启发是,树搜索本身是一种结构化的先验,包括 A * 算法也是这样的一种 structure,那么人为的加入这样的认知偏差使得语言模型去按照人类的结构化经验去进行思考,是可能会限制模型的能力。比如说,就如右边 OpenAI 所展示的图,其实随着算力的增长,加入更多的这样一个人类先验,其实整个模型的表现上限是有限的,具有更少的人类先验,所能获得的表现上界是更高的。最后我们想要思考的是,我们不通过额外的添加人为先验,模型自身的时候是否可以直接进行思考的。
背后其实有两个算法:第一个也就是算法蒸馏,第二个是通过搜索流来显式的去引入规划的过程。关于算法蒸馏其实是将强化学习的整个训练过程中的 history 的 trajectory,直接建模到语言模型中从而寻找一个数据相对会比较高效的这样一些强化学习算法。Stream of Search 也就是搜索流其实是类似的,它更多是说将强化学习的训练的轨迹,比如将对搜索过程转化为自然语言序列训练预训练模型,然后基于这个模型,做一些策略提升的方法,它也是解决了很多启发式的解决器没有解决的一些问题。

但是我们可以看到其实 DS-R1 和 Kimi K1.5 它背后没有进行明确的树搜索和过程奖励模型的尝试,其背后也有其特定的考量。比如说这个过程奖励模型,它具备的一些挑战是决定当下的某一步是否是正确是一个非常难的任务,那么并且通过自动化标注是很难以产生很好的结果的,而通过人工标注又很难以把规模扩大;第二是基于神经网络的过程奖励模型可能会引入奖励攻陷的现象,而重新训练就会让整个训练过程变得非常复杂,并且整个过程奖励模型还是比较适合于 rank 前 n 个回答,并且去支持有方向的去搜索。那么在大规模强化学习学习的使用下,其实提高算力相对是一个更加直接的方法。
但是过程奖励模型有它自己的潜力,因为它毕竟总归是一个比较稠密的监督信号,那么对于奖励进行合适的 shaping 之后,是可以使训练更加稳定或者收敛更快的。包括其背后也有更多的探索的空间比如说我们如何让模型收敛更快或者说借助过程奖励的方法来让整个训练更加稳定,并且未来有希望和自动化形式化验证进行结合,从而提供在基于规则的奖励之外更多的奖励信号,从而去指导密集的优化,赋能长思维链安全的验证。

那么最后一个讨论也就是其实我们会发现现在很多强推理模型,存在过度思考的行为具体表现,比如说它会出现过多的语气词,以及在任何的场合都会使用一些高端词汇典型的比如 DS-R1 会使用量子纠缠,对于一些简单的数学问题也会出现过多思考的范式。但其背后看似是有反思的范式,重复的范式也是非常多的,它可能会导致更好的表现,但是也会带来在训练和推理过程中极大的损耗。其实背后的问题就是,我们如何去合理的去分配在测试阶段的算力,从而进行选择性的思考。其实 Kimi 里边为我们展现一种策略,比如说从长思维链到短思维链的蒸馏,以及如何引入长度优化的惩罚和优先采样策略,去帮助整个模型在强化学习训练过程中建模到使用合适的方法,而避免过度思考的现象。

我们会发现整个 DS-R1 在纯文本模态上取得优异表现非常惊艳,其实这也让人不禁期待多模态场景的加持下,深度推理模型会是怎样的表现,整个未来也是将进入一个模态穿透和模态联动的这么一个趋势。我们人类在日常生活中接收到的信息往往是全模块的不同感官的渠道,它是能够互相补充,帮助我们更加全面的理解和表达复杂概念。其实模态扩展将成为强推理模型下一个重大突破,比如说我们如何在复杂的决策环境中构建起感知 - 理解 - 推演的闭环认知体系,以及如何在某个模态下应对许多复杂的推理任务,基于规则的奖励提供监督信号,从而作为人类意图和偏好的载体。
而从文本模态扩展到多模态、甚至到全模态场景时,许多问题便会随之呈现,比如说随着模态数的增加,传统的二元偏好是否能够捕捉人类意图的多元偏好或者层次化偏好;并且当多模态扩展到全模态空间,模态交互更加复杂,强化学习方法又需要做哪些改进;以及不同的模态下模态特有和模态共有的信息又如何统一在奖励信号建模之中。

其实扩展多模态对强推理有很多可能性,第一种是像 Qwen 一样基于多模态做基座的模型扩展到强推理的模型;第二是可以利用 LLaVA 的思路,在原来强推理基座模型上进行额外的多模态模块的扩展,比如说如冻结除投影层之外的所有模型参数,对投影层进行单独的预训练,从而获得能够经过视觉编码器的视觉表征映射到语言表征空间的能力;以及第二步是同时微调投影层和大语言模型,从而激发语言模型的多模态处理能力。

未来方向分析探讨
我们在这里也总结了一些未来的技术方向,比如说长推理模型的可解释性、模态扩展、强推理如何赋能智能体的发展以及强推理模型下的一个监管和安全保证,具体包括形式化验证、审计对齐和对齐欺骗现象。

首先是长思维链的可解释性,其实强推理模型在为我们带来性能提升的同时也带来了新的挑战。比如在复杂的环境下,模型可能会采取捷径或者偏离原本的设计的任务路线,那么随着模型被提供隐式思考的机会,出现这种操纵和欺骗的可能性逐渐加大,模型可以去通过相应的思考去更发现完成目标的更快方法。尽管这种目标可能是不被允许或者是欺骗人类的。比如说在 OpenAI 的 o1 中就已经发现了这种通过获取任务的漏洞来完成任务的这样一个现象。并且同样的现象也在更多的语言模型上发现了这种奖励篡改的机制,比如修改自己的奖励机制来避开设置的难点。

基于长思维链的推理虽然在一定程度上可以提高模型的可解释性,比如说我们可以查看显式的路径让人类可以追踪到模型如何从输入推导出输出,进而追踪模型的决策过程。但是与此同时它也不能完全去可解释性的问题,因为模型可能仍然利用思维链进行欺骗性推理。尽管思维链生成的推理步骤是模型输出的一部分,但是它并不能保证它真实地反映了模型内部计算的过程。模型是否能学会输出符合人类期望的思维链,但是实际的处理过程可能与其展示的思维链是不同的。进一步当模型具备长期的目标意识的时候,它可能会构造看似合理但实际上误导性的思维链以隐藏其真正的意图。
那么为了防止思维链变成伪装工具,其实需要兼顾一些 AI 驱动的方法以及对比推理、形式化验证等方法。例如可以让模型在不同的监督环境下执行相同的任务,检测其推理的一致性。或者是利用自动化对抗测试来分析模型是否在训练过程中优化了欺骗策略。

第二个未来发展展望也就是如何通过模态扩展和模态穿透来进一步拓展强推理的边界。我们可以知道传统的对齐方法,它本身是模态无感的,它能够通过数据的构造直接应用于多模态的场景。但是多模态的对齐的难点在于随着模态数量的增加,传统的二元偏好能否捕捉人类意图的多元偏好或者层次化偏好;第二是当多模态扩展到全模态空间,模态交互更加复杂,那么传统对齐算法是否还奏效,以及不同模态下模态特有和模态共有的信息如何统一在变化建模中。这里的出发点是我们如何在全模态场景中实现任意模态输入任意模态输出的模型也能够和人类的意图相对齐。

背后其实有一个统一的范式,是我们能否利用信息更丰富的多模态偏好数据从而实现更准确且细粒度的人类偏好对齐呢?先前我们组其实提出一种算法就是从语言反馈中进行学习,具体来说是针对于传统对齐方法中存在的效率低迭代慢优化难的等难题,让语言模型对于每一个偏好数据集去提供相应的语言反馈。其实这个语言反馈就是可以作为整个偏好中人类意图的载体,因为它不仅给出了偏好为什么好,也给出了这个偏好为什么坏,以及如何进行优化的这样一个反馈。那么通过从语言反馈中学习范式,它是能够提升任意模态的生成和理解任务的对齐表现的。

其背后是说当前模型的问题可能通常是并不完美的,我们可以利用语言反馈去优化问题,也可以优化问题的输出,从而可以在某些维度上去改善模型的输出,进而合成更多具有学习价值的偏好对。

我们也发现其实模态穿透是能够赋能整个文本模态上的智能并且拓展的。背后有两个关键之处:第一个是客观基础上多模态模型,已具备了强大的跨模态穿透和融合的机制,能够通过结合视觉能力世界知识和上下文学习能力,实现多种模块之间的协同输出;第二是基于慢思考强推理能力的持续自我进化,可以突破单一模块的局限性,从而可以用其他模态的辅助信息来帮助模型在文本模态上得以大幅提升。在这里其实我们基于 DeepSeek 的一系列模型也进行了相关的实验,我们发现其实经过多模态训练后的 8B 的模型是能够在很多文本的评测基准上超越原来的基座模型的能力。其实就证明多模态能力的赋予帮助了在文本模态下智能边界的扩展。

在这里我们也是提出了 Align-Anything 框架,其中包括了对于任意模态任意数据,还有任意算法的这样一个开源库的偏好支持。它支持的任意模态到任意模态的对齐,在目前开源社区中也是独一无二的。并且我们还已经支持了 DeepSeek R1 671B 的微调,这也是为全模态大模型的对齐提供了统一的和通用的解决方案。背后的数据框架算法和模型我们也全部进行了开源。

第三个未来技术判断是强推理其实可以赋能未来智能体的发展。我们可以发现日常的聊天任务其实对于强推理能力的需求并不大。未来更多是说能否利用强推理能力来赋能智能体和具身智能的发展。那其背后是需要依赖于强推理模型反思、长程规划和工具调用的能力以及关键问题是如何克服内存和记忆模块的挑战,以及小模型如何获得更强的推理效果来节省内存和显存的开销。

最后一个需要关注的未来技术方向是强推理模型下的监管和保证。因为语言模型已经表现出了抗拒对齐的现象。传统的这些算法虽然可能提升模型的性能并且确保人类意图和价值相一致。但是这些对齐微调是否真正修改了对齐模型的内部表征?我们发现其实在经过安全对齐的模型可以在最小化微调之后变得再次不安全,并且在非恶意数据集上的微调对齐的模型,也可能会削弱模型的安全机制。那不仅局限于安全,这种假象对其表明模型可能会内在执行逆对齐的操作,反而销毁对齐过程的可能性。这一概念其实我们也称之为逆向对齐。那么进一步我们探究了,语言模型是能否表现出弹性从而抗拒对齐的现象。

我们是从最简单的弹簧系统建模进行出发来探究单元模型内在抗拒对齐的机理。其背后是说就像弹簧的胡克定律,在弹性限度内,弹簧的弹力和长度的变化是成线性关系的。大语言模型其实也是具备弹性的,那模型在预训练的阶段经过大数据大更新之后产生了通用能力的稳定分布,而经过对齐阶段的小数据小功能性是可能表现出由对齐分布回弹到预训练分布的倾向而体现出抗拒对齐的。我们对于模型施加微调之时,模型其实更倾向于保持原有预训练的分布而抗拒对齐的分布,从而使逆向对齐更加容易。

从理论解释上来说,其实我们会发现整个预训练到后训练阶段模型是因为弹性而抗拒对齐的,因为模型可以被视作为一种压缩器。预训练和对齐的过程就是利用模型对于每阶段的数据进行联合压缩,而在预训练中所花的数据量是要显著多于后训练的,那模型为了提高整体的压缩率就会倾向于保留预先的部分的分布,而抗拒微调对齐的分布从而表现出模型的弹性。理论上,其实对齐的模型受到扰动之后,模型对于预训练数据和对齐数据集的压缩率是成一个变化的关系的;并且这个变化的关系是和数据量之比是同阶的。

我们也在大量的实验上进行了模型弹性的相应的验证,会发现两个关键的结论:首先模型的弹性是会随着模型的大小增大而增大的,那么随着模型参数规模的增大,其实模型的弹性也是随着参数量大小的增大而不断变强;第二是模型的弹性,其实随着一系列的数据增大而不断增大。我们观察到随着一系列数据量增加的时候,负面数据微调导致的初始性能其实下降更后下降变得更慢。其实这表明模型弹性随着预训练数量的增多,是在不断增多的。

总的来说其实我们从弹性视角来反思大量模型的对齐。其实它本身也是强推理模型下一个非常关键的安全对齐的举措。我们可以发现预训练的阶段和对齐阶段是不应当被各自独立的,而我们对于模型的评估更应该去关注模型内在表现的对齐。如何从表面对齐深入到深入对齐,那么其背后是对齐的范式应该是需要改变的。

第三个需要关注点是审计对齐,这其背后的挑战是当下的大语言模型其实容易被诱导陷害有害内容,那么他们通常会表现出过度的拒绝,就是可能会拒绝一些合法请求。但是这样依然容易受到越狱攻击。背后的两个关键原因是,当下的语言模型必须用固定的资源即时响应用户的需求;第二是当下的这些方法是鼓励语言模型通过偏好学习,从大量数据中去总结和规范人的意图,而不是直接去学习安全的规范。那么背后的科学问题是我们能否直接利用强推理能力来学习安全规范以增强模型的安全性能。

其实 OpenAI 提出了这样一种审计对齐的方法,大体思路是我们在监督微调和推理生成阶段可能就可以利用强推理模型产生一个对于安全准则的思考过程,那么进而我们可以去将这种思考过程融入到模型监督微调的过程中。

并且在强化学习的训练过程中,我们可以鼓励模型自主产生这种安全并且有帮助性的思维链过程,而更好的利用强推理模型的思路深入思考学习到背后的安全规范。

其实更多它是像把 CAI 的这种过程和背后的这种 constitutions 的宪法融入到了模型的推理过程之中。那么这也是在推理时,它也能够很大程度上提升模型的安全性。

背后其实更关键是说,刚才我们提到的模型可能会表现出来对齐欺骗和对齐抗拒的这样的范式,以及未来我们是需要对齐更强大的模型我们如何去提供奖励信号,去为这些可能比人类更聪明以及我们没有办法去理解它们任务的这样的模型。

接下来非常关键的点就是形式化验证。形式化验证其实起源于数学的形式化证明,因为数学的形式化它的目的是为了提供一个完全客观可验证的证明过程;而与此同时其实安全价值也需要这样的形式化验证。因为安全的监管具有重要性,其背后的本源在于人类的安全价值观是具有重要性的,而内建价值的冲突和单智能体的安全并不能保证多智能体系统的安全。包括现在人工智能系统已经出现了伪装对齐的现象,以及随着 VLA和智能体等模型下游和赋能应用兴起,确保模型准确的应对不确定性,考虑物理规律下的人类价值对齐至关重要。因为我们在复杂的动态环境中不仅要考虑短期安全,还要保证长期使用的安全性,对操作环境产生影响。那么通过形式化验证和强化学习,我们其实是能够提高模型的可靠性和处理复杂推理问题的能力,通过构建形式化的数学数据库,我们也能够建立高度严谨的推理模型。

其背后既是智能体的模型背后的安全也具有独特的挑战。一方面是模型具有内生价值的安全性,因为它不仅要考虑不确定性,还必须考虑物理规律下人类价值观的对齐,例如肢体语言的安全性和个人空间的边界感等等;第二是外生的具身安全性,因为在复杂的动态环境中不仅要短期安全,还要确保长期行为的安全性,例如对操作环境造成影响的安全性。

总结下来我们其实会发现,这三年整体是有一个快思考到慢思考以及到 2025 年强推理和模态穿透整个范式的跃进。关键问题是基于复杂推理慢思考和强化学习技术范式,我们如何通过高质量数据去驱动产生强推理模型,通过赋能全推理全模态场景下去拓展智能的边界。

补充拓展:DeepSeek-V3 解读
最后我们也附上了有关 DeepSeek-v3 的一些分析。我们可以发现 DeepSeek-v3 它是基于 61 层 MoE 的架构以及做了很多像 MLA 这种架构的优化来降低模型的成本。同时保证模型对于输入数据和复杂关系的捕捉能力。

与此同时采用混合精度训练和多 Token 预测的机制。也能够提高模型对于语言结构的理解能力,然后更好的去捕捉语言中的长距离依赖关系。

更进一步也在通信和方面进行了例如像双流水线并行优化这样的机制来进一步提高模型的效率。

在这里我们也想进行探究和分析也就是人类的系统一和系统二之间的对比。那系统一它其实更多的说进行一个快速但是可能不为准确的判断,而系统二它通常是经过深入思考通过遍历组合来解决一些问题,但是这种方法的复杂度极高,容易导致组合爆炸。其实未来一个潜在方向是我们如何利用系统一快速但可能不准确的判断,来帮助系统二控制组合爆炸的问题,从而高效地进行复杂推理。并且我们能不能将这种流式智能建模到语言模型之中。

当下的语言模型其实更多还是受限于过程性的推理任务,它尽管可能完成一些复杂推理,但是对于以人类来说一些很简单的任务,比如说逆转诅咒,语言模型其实是非常有困难的。其本质在于语言模型的思考过程本身是静态和非过程的。我们能不能通过人类的抽象推理建模出高维的概念并且进行细度反馈。结合系统一和系统二来帮助语言模型进一步提升它的推理能力其实是一个非常关键的方向。

最后我们也提供了一些拓展文献和参考资料也是希望能够帮助到社区。以上这就是我们全部的分享。



#一文汇总 deepseek R1 最新复现进展
自 DeepSeek-R1 发布以来,迅速风靡全球,如今已晋升为国民级产品。此后,全球范围内掀起了一股复现 DeepSeek-R1 的热潮,其中不乏一些亮点纷呈的优秀项目。本文将对这些开源项目中的亮点复现工作进行汇总。一、DeepSeek-R1 复现汇总
下面是最新的 DeepSeek-R1 复现汇总:

接下来我们介绍下复现细节。
二、Open R1: HuggingFace 复现 DeepSeek-R1 全流程
Open R1 项目由 HuggingFace 发起,联合创始人兼 CEO Clem Delangue 是这么说的:
这个项目的目的是构建 R1 pipeline 中缺失的部分,以便所有人都能在此之上复制和构建 R1。
HuggingFace 表示,将以 DeepSeek-R1 的技术报告为指导,分 3 个步骤完成这个项目:
- step 1:从 DeepSeek-R1 中蒸馏高质量数据,复现 R1-Distill 模型。
- step 2:复现通过纯强化学习训练 R1-Zero 的过程,包括如何生成推理数据集
- step 3:复现训练 R1 的完整 pipeline,包括两阶段 SFT、两阶段 RL。
图1: Open R1复现DeepSeek-R1流程
2.1 step1:复现 DeepSeek-R1-Distill
利用 DeepSeek-R1 的蒸馏数据创建了 Bespoke-Stratos-17k。
Bespoke-Stratos-17k 的数据构成为:
- APPs 和 TACO:5k
- NuminaMATH 数据集中的 AIME、MATH 以及 Olympiads 子集:10k
- STILL-2 的科学和谜题数据:1k
数据的构建方法为:
- 借助 Bespoke Curator (用于生成合成数据的项目) 创建了 Bespoke-Stratos-17k,利用 DeepSeek-R1 生成推理数据集,仅用了 1.5 小时和 800 美元的成本。
- 拒绝采样过程中,过滤掉了具有错误解决方案的推理轨迹。这对于代码验证来说是一大挑战,使用了 Ray 集群来加速验证过程。目前,HuggingFace 正致力于将代码执行验证器直接集成到 Curator。
- 数据过滤:使用 GPT-4o-mini 过滤错误的数学解决方案,将保留的正确解决方案的比例从 25% 提高到了 73%。
基于 Bespoke-Stratos-17k 数据训练出了 Bespoke-Stratos-32B 和 Bespoke-Stratos-7B 模型。
其中,Bespoke-Stratos-32B 的效果已经和 DeepSeek-R1-Distill-Qwen-32B 非常接近,如下图所示。
图2: 复现DeepSeek-R1-Distill-Qwen-32B
全新数据集:OpenR1-Math-220k
2 月 11 日,Open R1 发布了 OpenR1-Math-220k,这是一个大规模的数学推理数据集。该数据集在本地利用 512 个 H100 生成,每个问题均对应多个答案。为打造这一数据集,HuggingFace 与 Numina 合作,共同开发了备受欢迎的 NuminaMath-CoT 数据集的全新升级版。
相较于现有数据集,OpenR1-Math-220k 独具以下新特性:包含 80万 条 R1 推理轨迹,利用 DeepSeek R1 为 40万 道问题生成了两个答案,并经过筛选,最终保留了 22万 道带有正确推理轨迹的问题。
- 本地生成:未依赖API,而是借助 vLLM 和 SGLang 在科学集群上本地运行,每日生成 18万 条推理过程。
- 基于 NuminaMath 1.5:为 NuminaMath 1.5 中的问题提供答案,NuminaMath 1.5 是 NuminaMath-CoT 数据集的改进版。
- 自动过滤机制:运用 Math Verify 仅保留至少含有一个正确答案的问题,并利用 Llama3.3-70B-Instruct 作为判断器,以检索更多正确示例(如答案格式错误、无法使用基于规则的解析器验证的情况)。
- 在 OpenR1-Math-220k 上微调 Qwen-7B-Math-Instruct,其性能与 DeepSeek-Distill-Qwen-7B 相媲美。
通过结合基于规则的验证工具(Math Verify)与大语言模型(LLM)的评估方法,在保持数据集规模的同时,显著提升了其质量。最终,数据集 OpenR1-Math-220k 涵盖了 22万 个带有经过验证的推理过程的问题,每个问题可能有多个解决方案,下面是具体的分布:
图3: OpenR1-Math-220k回答个数分布
其中,仅有一个回答的样本有 36759 条,而有两个回答的样本则有 184467 条,超过两个回答的样本数量极少。
该数据集分为两个划分:
- default(包含9.4万个问题),在 SFT 后取得了最佳性能。
- extended(包含13.1万个问题),额外融入了 NuminaMath 1.5 的来源,如 cn_k12,提供了更丰富的推理过程。然而,在此子集上进行 SFT 后的性能低于 default,这可能是由于 cn_k12 包含的问题相对其他来源更为简单。
多选一没有效果:对于具有多个正确答案的数据,使用奖励模型 (RM) 作为最终过滤器来挑选最佳响应。对于 R1 生成的每个具有多个正确答案的推理路径,去掉 和 之前的内容,只保留最终结果,使用 Qwen/Qwen2.5-Math-RM-72B 进行评分,选择得分最高的回答。但是消融实验显示,这种方法相较于随机选择一个正确生成结果,并未能显著提升模型性能。一个潜在的改进方向是在使用 RM 进行评分时,考虑使用全部长思维链过程,而不仅仅是只使用最终答案。
与 DeepSeek-Distill-Qwen-7B 的性能比较
设置学习率为 5e-5,使用 default 部分,在 Qwen2.5-Math-Instruct 上训练 3 个 epoch。为了将上下文长度从 4k 扩展到 32k,将 RoPE 频率提高到了 300k。下图展示了使用 lighteval 评估的结果。

在 AIME25 上,效果和 DeepSeek-Distill-Qwen-7B 持平。
2.2 step2:复现 DeepSeek-R1-Zero
下图展示了直接在 Qwen2.5-0.5B 上进行 GRPO 强化,在 GSM8k 基准测试中取得了约 51% 的准确率,相比 Qwen2.5-0.5B-Instruct 模型提高了 10 个百分点。
图4:在Qwen2.5-0.5B上直接进行强化
目前 Open R1 刚开始复现 DeepSeek-R1-Zero,还没有一个好的版本出来。
三、Open-Thoughts: UC 伯克利复现 DeepSeek-Distill-Qwen-32B
近日,斯坦福、UC伯克利等多机构联手发布了开源模型:OpenThinker-32B,性能直逼 DeepSeek-Distill-Qwen-32B。
仅使用了 114k(OpenThoughts-114k) 数据(DeepSeek-Distill-Qwen-32B 的1/8),就与同尺寸 DeepSeek-Distill-Qwen-32B 打成平手。
团队发现,通过采用经 DeepSeek-R1 验证过的大规模优质数据集,就能够成功训练出达到 SOTA 水平的推理模型。具体实现方法包括扩大数据量、严格验证推理过程以及扩大模型规模。由此研发的 OpenThinker-32B 模型,在数学、代码和科学等多个基准测试中,性能表现卓越,逼近 DeepSeek-Distill-Qwen-32B 水平,而且只用了 DeepSeek-Distill-Qwen-32B 的 1/8 数据量。

图5: OpenThinker-32B评测结果
下面介绍下数据构建的具体流程。
数据生成:OpenThoughts-114k
OpenThoughts-114k 包含 114k 高质量数据,涵盖数学、科学、代码和谜题。
除了开源数据集,还开源了模型、数据生成代码、模型评估代码。如下图所示:
图6: OpenThoughts开源了模型、数据和代码
数据由以下几个部分构成:
- Code
- BAAI/TACO
- codeparrot/apps
- deepmind/code_contests
- MatrixStudio/Codeforces-Python-Submissions
- Math
- AI-MO/NuminaMath-CoT
- Science
- camel-ai/chemistry
- camel-ai/biology
- camel-ai/physics
- Puzzle
- INK-USC/riddle_sense
使用上述数据集,从 DeepSeek-R1 生成推理轨迹并验证正确性以构建最终数据集。
图7: 使用DeepSeek-R1生成结果并对结果进行校验
四、LIMO:少即是多
图8: 只用817条数据大幅提升模型效果
在之前很长的时间里,大家的共识是“海量数据”才能训练出强大的模型。尤其在数学领域,业界普遍坚信,唯有依托海量数据与复杂的强化学习,才能取得突破性进展。
然而,上交大的最新研究成果却给出了一个另外答案:仅需 817 条精心策划的样本,便能让模型在数学竞赛级别的难题上超越众多现有的顶尖模型。这一发现不仅颠覆了传统认知,更揭示了一个我们可能一直忽视的事实:大模型的数学潜能或许始终存在,关键在于如何有效激发它。
LIMO(Less Is More for Reasoning)仅用 817 条精心设计的训练样本,通过简单的 SFT,就全面超越了那些使用几十万数据训练的主流模型,如 o1-preview 和 QwQ。
在 AIME24 评测中,LIMO 的准确率从传统方法(以 Numina-Math 为例)的 6.5% 飙升至 57.1%。而在 10 个不同的基准测试上,它实现了 40.5% 的绝对性能提升,超越了那些使用 100 倍数据训练的模型。这一突破证明了高质量、小规模的数据集,远比低效的海量数据训练更能激发大模型的推理潜能。
4.1 LIMO vs. RL Scaling
强化学习扩展(RL Scaling):以 OpenAI 的 o1 系列和 DeepSeek-R1 为代表,RL Scaling 方法通常通过大规模的强化学习训练来增强模型的推理能力。这种方法依赖于海量数据和复杂算法,虽然在特定任务上取得了显著成果,但其局限性也在于:它将推理能力的提升视为一个需要巨额计算资源的“探索”过程。
LIMO 的新视角:相比之下,LIMO(Less Is More for Reasoning)提出了一种截然不同的理论框架。它认为,推理能力其实潜藏于预训练模型之中,关键在于如何通过精准的唤醒这些潜在能力。这一转变将研究的重心从“训练新技能”转向了“激活潜在能力”,凸显了方法方向的重要性。
LIMO 的核心假设是,在知识基础已经相当完善的前提下,仅需少量高质量的示例,就能激活模型的潜在推理能力。这一理论不仅重新界定了 RL Scaling 的角色,将其视为寻找最优推理路径的一种途径,更为整个研究领域提供了新的思考维度和框架。
4.2 LIMO 数据集构建
将“少即是多”(LIMO)假设形式化表述为:在预训练基座模型中,通过最小却精确协调的认知过程展示,可以激发出复杂的推理能力。这一假设建立在两个基本前提之上:
- (I)模型参数空间中蕴含着潜在的先决知识;
- (II)将复杂问题精确拆解为详尽、逻辑清晰的推理链,能够使认知过程变得明确且可追溯。
为了验证这一假设,LIMO 提出了一种系统化的方法来构建高质量、最小化的数据集,以有效唤醒模型的内在推理潜能。
问题选择
高质量的问题应该能自然地引发扩展的推理过程。选择标准包括以下几点:
- 难度等级 优先考虑具有复杂推理链、多样化的思维过程和知识整合的问题,这些问题能够使大语言模型有效利用预训练知识进行高质量的推理。
- 泛化性 那些偏离模型训练分布的问题可以更好地挑战其固定的思维模式,鼓励探索新的推理方法,从而扩展其推断搜索空间。
- 知识多样性 选择的问题应涵盖各种数学领域和概念,要求模型在解决问题时整合和连接遥远的知识。
为了有效实施这些标准,LIMO 首先汇总了一个全面的候选问题池:NuminaMath-CoT。这个问题池从多个已建立的数据集中精选而出,涵盖了从高中到竞赛级别的精心标注数学问题,包括 AIME,MATH 以及其他几个数学问题来源。
然后对问题集进行筛选:
- 弱模型初筛:首先利用 Qwen2.5-Math-7B-Instruct 过滤掉 N 次回答全对的问题。
- 强模型再筛:接着,使用更强大的模型,如 DeeSeek-R1、DeepSeek-R1-Distill-Qwen32B,仅保留多次采样成功率低于指定阀值的问题。
- 多样性选择:最后,为确保题库的多样性,采用策略性采样技术,在数学领域和问题复杂性之间寻求平衡,同时避免概念重复。
经过这一精细的筛选过程,最终从数以千万计的候选问题中精选出了 817 道精心设计的问题。这些问题不仅符合严格质量标准,还涵盖了丰富多样的数学推理挑战。
回答构建(思维链构建)
首先,收集现有问题的官方解决方案,并补充了来自人类专家和 AI 专家的解决方案。
此外,利用 DeepSeek-R1、DeepSeek-R1-Distill-Qwen-32B 和 Qwen2.5-32b-Instruct 在内的推理模型,来生成多种解决方案。
建立区分高质量思维链的评判标准:
- 最优结构组织,即解决方案具有清晰、有序的结构,步骤分解具有自适应粒度,在关键推理环节分配更多 token 和详细说明,同时保持直接步骤的简洁;
- 有效认知,即高质量的解决方案通过逐步构建理解,提供渐进的概念介绍、清晰阐述关键见解以及整合概念差距;
- 严格验证,即在推理过程中穿插频繁的验证步骤,包括验证中间结果、交叉检查假设以及确认每一步推论的逻辑一致性。
4.3 LIMO 回答对比
图 9 对 Qwen2.5-32B-Instruct、DeepSeek-R1 和 LIMO 生成的回答进行了比较。尽管 LIMO 使用的数据最少(仅 817 个训练样本),但其功能却与 DeepSeek-R1 相当。
图9: Qwen2.5-32B-Instruct、DeepSeek-R1和LIMO生成回复的比较
值得一提的是,LIMO 展现出了出色的自我反思和长链思维生成能力。它能够验证自己的陈述(如“等等,24分钟是0.4小时吗?不对,60分钟是1小时,所以24分钟是24/60,即0.4小时”)并核对计算过程(如“但让我再检查一次,也许我在计算中出错了”)。此外,LIMO 还学会了在解决复杂方程时分配额外的 token(进行计算),如“现在让我们计算左侧,……,两边乘以2”,以防止出现错误。相比之下,模型 Qwen2.5-32B-Instruct 在推理过程中存在局限性,无法纠正不准确的陈述,且在解决方案中未能对方程进行交叉验证。这些结果有力地支持了 LIMO 假说:即通过少量但高质量的后训练示例,可以赋予模型强大的推理能力。
五、DeepScaleR:完美复现 DeepSeek-R1 强化学习效果
近期,UC 伯克利团队宣布,他们仅以4500美元的成本,通过简单的强化学习(RL),就成功复现并训练出了 DeepScaleR-1.5B-Preview 模型,直接超越了 o1-preview。
UC伯克利的研究团队以 Deepseek-R1-Distilled-Qwen-1.5B 为基础,通过强化学习(RL),在 40,000 个高质量数学问题上进行训练,使用了 3800 A100 小时(4500美元),训练出了 DeepScaleR-1.5B-Preview 模型。在多个竞赛级数学基准测试中优于 OpenAI 的 o1-preview。
图10: 评测结果超过 o1-preview
5.1 秘诀:先短后长(8K->16K->24K)
RL 扩展最大的挑战之一是高昂的计算成本。如果要直接复制 DeepSeek-R1 的实验(32K输出,8000 steps),至少需要 70,000 A100 GPU 小时——即使是 1.5B 的小模型。
为了解决这个问题,团队采用了线短后长的训练策略。先在 8K 上训练,然后再逐渐扩展到 16K 和 32K。最总将训练成本降低到了 3800 A100 小时(4500美元)。
图11: AIME 2024测试集Pass@1准确率随训练进度而变:训练至第1040步,上下文长度扩至16K;到第1520步,上下文长度增至24K
接下来,我们介绍下具体细节。
5.2 数据集构建
在训练数据集方面,研究人员精心收集了 1984 至 2023 年的美国国际数学邀请赛(AIME)题目、2023年之前的美国数学竞赛(AMC)题目,以及来自 Omni-MATH 和 Still 数据集的各国及国际数学竞赛题目。数据构成如下:

数据处理流程涵盖了三个核心步骤:
- 答案提取:对于 AMC 和 AIME 等数据集,研究人员利用 gemini-1.5-pro-002 模型从 AoPS 官方解答中准确提取答案
- 问题去重:基于 RAG 技术,并结合 sentence-transformers/all-MiniLM-L6-v2 的 embedding,消除重复问题
- 不可评分题目过滤:由于数据集(如 Omni-MATH)中存在部分问题无法通过 sympy 数学符号计算库进行自动评估(需依赖LLM判断),这些问题会降低训练速度并引入不稳定的奖励信号,因此研究人员增加了额外的过滤步骤,剔除了这些无法自动评分的问题。
经过这一系列的去重和过滤处理,最终得到了约4万个问题-答案对,作为训练数据集。
5.3 奖励函数设计
正如 Deepseek-R1 所倡导的,团队采用结果奖励模型(ORM),而非过程奖励模型(PRM)。奖励函数返回值如下:
- 返回 1:如果 LLM 的答案,既能通过 LaTeX 语法检查,又能通过 Sympy 数学验证,就给它奖励。
- 返回 0:要是 LLM 的答案是错的,或者格式不对,比如少了和标记,那就不给奖励。
5.4 迭代增加训练长度:先短后长
图12: 随着训练的进行,DeepScaleR的平均响应长度和训练奖励
在强化学习中,一个核心挑战在于如何选择最优的上下文窗口大小进行训练。推理类任务的强化学习对计算资源的需求极高,因为它们产生的输出远长于标准任务,这导致轨迹采样和策略梯度更新的速度大幅减慢。事实上,上下文窗口大小每翻倍一次,训练的计算量至少会增加 2倍。
这就引发了一个基本的权衡:较长的上下文为模型提供了更广阔的“思考”空间,但会大幅度降低训练速度;而较短的上下文虽然能加快训练进程,却可能限制模型解决那些需要较长上下文才能理解的复杂问题的能力。因此,在训练效率和模型准确性之间找到恰当的平衡点显得尤为重要。
为此,团队的训练方法采用了 Deepseek 的 GRPO 算法,并分为两个阶段:
- 首先,使用 8K 的最大上下文长度进行 RL 训练,以在推理效果和训练效率之间取得初步平衡;
- 随后,将训练扩展到 16K 和 24K 的上下文长度,使模型能够应对更多具有挑战性、以往难以解决的问题。
5.5 使用 8K 上下文构建高效思维链推理
在训练之前,团队在 AIME2024 上评估了 Deepseek-R1-Distilled-Qwen-1.5B 模型,并分析了推理轨迹数据。结果发现,错误回答包含的 token 量是正确回答的三倍(20,346 vs. 6,395)。这表明,较长的回答往往导致错误的结果。
因此,直接使用较长的上下文窗口进行训练可能效率低下,因为大部分 token 实际上都被浪费了。此外,在评估日志中观察到,长篇回答呈现出重复的模式,这表明它们对有效的思维链推理并没有做出有意义的贡献。
基于这些发现,团队决定先从 8K 的上下文开始训练,并在 AIME2024 上取得了 22.9% 的初始准确率,仅比原始模型低 6%。
事实证明这一策略是有效的:在训练过程中,平均训练奖励从 46% 提高到了 58%,而平均回答长度则从 5,500 降低到 3,500。如下图所示:
图13: 回答长度变化
5.6 扩展至 16K,关键转折点出现
在大约 1000 步之后,8K 运行中发生了一个有趣的变化:响应长度开始再次增加。然而,这导致了收益递减,准确率趋于平稳并最终下降。
图14: 在1000步后输出长度再次上升,但训练奖励下降
与此同时,响应裁剪比例从 4.2% 上升到 6.5%,这表明更多的响应在上下文长度的限制下被截断。
图15: 8K上下文运行在1000步之后,回答超长截断比例上升。
这些结果表明,模型试图通过“思考更长时间”(即生成更长的响应)来提高训练奖励。然而,随着响应长度的增加,它越来越频繁地触碰到 8K 上下文窗口的限制,从而阻碍了进一步的性能提升。
研究人员意识到这一点后,决定“打破束缚,让模型自由飞翔”。于是,在训练步骤 1,040 处设置了一个检查点,这是响应长度开始呈现上升趋势的地方,并随后使用一个 16K 的上下文窗口重新启动了训练。这种分两阶段进行的方法比一开始就使用 16K 上下文窗口进行训练要有效得多:8K上下文的初始阶段使得平均响应长度保持在 3,000 token 左右,而不是 9,000 token,这使得该阶段的训练速度至少提高了 2 倍。
在切换到 16K 上下文窗口后,观察到训练奖励、响应长度以及 AIME2024 的 Pass@1 准确率都在稳步提升。经过 500 个额外的训练步骤,平均响应长度从 3,500 token 增加到了 5,500 token,而 AIME2024 的 Pass@1 准确度也达到了 **38%**。
5.7 24K 魔法,超越 o1-preview
在 16K 上下文中额外训练了 500 步之后,团队发现性能开始趋于稳定:平均训练奖励收敛至 62.5%,AIME pass@1 在 38% 左右徘徊,而响应长度则再次呈现出下降趋势。与此同时,超长截断比例上升至 2%。
为了最终实现 o1 级别的性能突破,团队决定施展“24K 魔法”——将上下文窗口扩展至 24K。于是,在训练步骤 480 处保存 16K 运行的 checkpoint,并重新启动了一个上下文窗口为24K 的训练任务。
得益于上下文窗口的扩展,模型终于突破了原有的束缚。大约 50 步后,模型成功超越了 40% 的 AIME 准确率大关,并在第 200 步时达到了 43% 的佳绩。
总体而言,团队的训练过程包括了约 1,750 个训练步骤。初始的 8K 阶段在 8 个 A100 GPU 上进行,而 16K 和 24K 阶段则将训练规模扩展至 32 个 A100 GPU。整个训练过程耗时约 3,800 A100 GPU 小时,相当于在 32 个 A100 GPU 上大约需要 5 天时间,计算成本约为4,500美元。
5.8 模型评估
下面是 pass@1 的评测结果,取 16 次的均值:
图16: 模型评测结果
相比 DeepSeek-R1-Distill-Qwen-1.5B,各项指标全面提升,其中 AIME24 从 28.8% 提升至 **43.1%**。
图17: AIME准确率——DeepScaleR实现了性能和大小之间的帕累托最优解。<br>
5.9 关键发现
强化学习(RL)同样适用于小型模型
Deepseek-R1 表明,直接在小模型上应用 RL 的效果不如蒸馏法。他们的消融实验显示,在 Qwen-32B 上应用 RL 在 AIME 上的得分为 47%,而仅使用蒸馏法则能达到 72.6%。
一个普遍的误解是,强化学习只对大模型有益。然而,通过从更大模型中蒸馏出高质量的监督 SFT 数据,小型模型也能学会更有效地利用 RL 进行推理。团队结果证实了这一点:强化学习将 AIME 的准确率从 28.9% 提高到了 **43.1%**!这些发现表明,单独使用 SFT 或 RL 都不足以充分发挥作用。相反,通过将高质量的 SFT 蒸馏与 RL 相结合,才能真正释放大模型的推理潜力。
迭代式长度扩展使长度扩展更加有效
先前的研究表明,直接在 16K 上下文中训练 R L相比 8K 并没有显著提升,这可能是因为模型的计算能力不足以充分利用扩展的上下文。而最近的一项研究则提出,更长的响应长度包含冗余的自我反思,这会导致错误结果。DeepScaleR 的实验与这些发现一致。通过首先在较短的上下文(8K)中进行训练,可以在后续的 16 K和 24K 运行中实现更快、更有效的训练。这种迭代方法使模型在扩展到更长上下文之前,先奠定有效的思维模式基础,从而使基于 RL 的长度扩展更加高效。
#MoE模型已成新风口,AI基础设施竞速升级
因为基准测试成绩与实际表现相差较大,近期开源的 Llama 4 系列模型正陷入争议的漩涡之中,但有一点却毫无疑问:MoE(混合专家)定然是未来 AI 大模型的主流范式之一。从 Mixtral 到 DeepSeek 再到 Qwen2.5-Max 以及 Llama 4,越来越多的 MoE 架构模型正在进入世界最前沿模型之列,以至于英伟达也已开始针对 MoE 架构设计和优化自家的计算硬件。
但是,MoE(尤其是大规模 MoE)也会给 AI 基础设施带来不一样的挑战。昨天,在 AI 势能大会下午的 AI 基础设施峰会上,阿里云智能集团副总裁、阿里云智能计算平台事业部负责人汪军华就谈到了 MoE 架构特有的一些困难,包括 token drop 选择对吞吐的影响、在路由专家与共享专家之间考虑效率和效果的权衡、专家的选取数量和比例等。
汪军华表示 AI 范式正在向 MoE 和推理模型演进
阿里云已经在解决这些难题上取得了重大进展。峰会上,针对 MoE 架构的模型,阿里云宣布基于 PAI-DLC 云原生分布式深度学习训练平台推出了 FlashMoE,这是一款支持超大规模 MoE 混合精度训练的高性能训练框架,具有多种强大特性,包括支持多种 token 路由策略、支持上下文并行与张量并行解耦等。
当然,阿里云在 AI 基础设施上的布局远不限于 MoE。无论是硬件算力的投入,还是一体化的训练和推理服务,它都在用硬核实力夯实自己的领先地位。在这场 AI 基础设施的竞赛中,阿里云已然抢占先机。
从算力到安全
阿里云这样构建 AI 基础设施
从算力基础到弹性灵活的解决方案,再到存储与网络技术,以及至关重要的安全能力,阿里云正在不断演进面向 AI 时代的基础设施,以提高其产品力和用户体验。
首先,在基础算力方面,阿里云宣布 ECS 第 9 代 Intel 企业级实例正式开启商业化,其基于英特尔第六代至强处理器 GNR,搭配阿里云最新 CIPU 架构,可让集群性能相对前代提升最高达 20%,同时价格较上代再降 5%。
今年也是阿里云弹性计算 15 周年,AI 驱动的阿里云基础设施将持续面向更高性能、更稳定的架构和产品深入演进。

在强大算力的基础上,阿里云还在对灵骏集群不断进行优化。阿里云智能集团副总裁、阿里云智能弹性计算、存储产品线负责人吴结生表示:「我们针对 AI 负载进行了大量优化,把灵骏集群构造成了云超级计算机。」总结起来,灵骏集群的技术体系包含 4 个创新点,包括 HPN 高性能网络、CPFS 高性能文件存储、定制化的 AI 服务器以及强大的故障检测能力。
首先,在网络技术方面,阿里云设计的 HPN 7.0 高性能网络架构是灵骏集群的核心网络技术,能让机器更高效、更紧密的合作。实际效果上,利用 HPN7.0 高性能网络架构,可实现单集群10 万张 GPU 卡互联,同时提供 3.2T 跨机带宽。
其次,值得一提的是灵骏管控和自愈系统,这能降低故障频次,缩短故障恢复时间,从而增强集群的稳定性,提高算力的使用率 —— 在万卡级超大规模训练中,一个月内灵骏 GPU 集群有效训练时长占比超过 93%。

为了保证 AI 业务稳定,算力很重要,高性能且可靠的存储也必不可少。对此,阿里云给出的解答是 CPFS(Cloud Parallel File Storage)高性能存储与 OSS(Object Storage Service)对象存储服务。
其中,CPFS 适用于高性能计算,支持对数据毫秒级的访问和百万级 IOPS 的数据读写请求,能实现 40 GB/s 的单客户端吞吐性能。
CPFS 还针对 AI 应用进行了优化,在实现高性能并行的同时,还支持端侧缓存和分层存储(包括 KV Cache),从而能高效率和低成本地满足 AI 的训推需求。
OSS 则适用于存储大量非结构化数据,适用于多种计算引擎和 AI 框架,具有海量、安全、易集成、低成本、高可靠的优势。在 AI 基础设施峰会上,阿里云宣布推出高性能的 OSSFS 2.0,这是一款专门用于通过挂载方式高性能访问 OSS 的客户端,它具备出色的顺序读写能力,可充分发挥 OSS 的高带宽优势。此外,阿里云还宣布首次将缺省 100 Gbps 吞吐性能扩展到了海外(新加坡)。OSS 同城冗余也已在吉隆坡上线,现已覆盖全球 12 个地域。

阿里云也为 CPFS 和 OSS 之间的数据流动构建了高速、高带宽的通道,使训练或推理框架可以通过文件系统的接口访问 OSS。
安全与稳定性同样也是许多 AI 应用开发者关注的核心问题之一,而阿里云已经构建了一整套用以保障算力稳定供给和数据安全的体系,其中包括 20 多款云产品和近百项可一键开启的安全能力。
面向 MoE 结构和推理模型
AI 范式正在演进
正如开篇所说,MoE 模型架构与推理模型正在不断推动 AI 训推的范式升级,在本次发布上,阿里云人工智能平台 PAI 针对性地推出一系列新能力。
在模型构建方面,针对推理模型,阿里云推出了 PAI-Chatlearn 和 Post-training on PAI-DLC。其中前者是一种支持 RLHF、DPO、OnlineDPO、GRPO 等多种强化学习算法的大规模对齐训练框架,同时也支持用户自己开发的强化学习算法,并且适配 Megatron、vLLM、DeepSpeed 等多种框架。不仅如此,PAI-Chatlearn 还是开源的。而后者则包含 SFT 等后训练能力,支持 Ray on DLC、统一调度、Serverless、Ray Dashboard 和开发机等功能。
而对于 MoE 模型,前文已经提到了基于 PAI-DLC 的 FlashMoE,其实际表现可说是相当亮眼:在万卡规模上,可将 MoE 训练的 MFU(模型 Flops 利用率)提升到 35-40%。
而在推理加速方面,阿里云同样没有落下。直接上数据。
首先,阿里云推出的全新模型权重服务将 1-100 节点的冷启动速度提升了 21 倍;如果从 50 个节点扩容到 100 个节点,则分布式推理系统的规模化扩容效率可提升 12 倍。
而基于 KV Cache 的分布式推理服务 PAI-EAS 可将千万级活跃用户场景的 KV Cache 命中率提升 10 倍!基于 3FS 的存储系统 IO 效率获得了大幅提升(读吞吐提升了 43%,写吞吐提升了 27%)。
另外,PAI-EAS 具备负载感知的 PD 分离架构,端到端服务吞吐提升 91%。

针对 MoE 模型,阿里云宣布推出了针对性的分布式推理引擎 Llumnix,通过在请求层面、请求内和硬件并行策略方面的精心设计,相比于 Round-robin 请求调度方案,可将 TTFT(首 token 延迟)降低 92%(P99),将 TPOT(每输出 token 延迟)降低 15%(P99)。
此外,阿里云也对云原生大数据服务 MaxCompute 进行了全面的 AI 升级,发布了 AI Function,可支撑用户构建 Data+AI 一体化工作流。
同时,阿里云在会上宣布大数据 AI 产品全面拥抱 MCP,大数据开发治理平台 DataWorks 发布基于 MCP 的 Agent 服务,DataWokrs 和 Hologres 发布了 MCP Server。

智能时代的数据库
让数据和 AI 更近
有了高效算力和平台,要创造足够好的 AI 应用,数据也是必不可少的一环。正如阿里云智能集团副总裁、阿里云智能数据库产品事业部负责人李飞飞说的那样:数据、算法、算力是智能时代的三大要素。因此,对数据库范式的革新也必不可少。那么智能时代对数据库的最核心需求是什么呢?李飞飞认为是「对多模态数据的智能化管理」。
为此,阿里云正在不断创新。此次峰会上,阿里云重点介绍了其数据库产品的一系列重磅升级。
首先,阿里云宣布实现了模型即算子(Model as an Operator)的 In-DB AI 功能,也就是说可以将模型作为算子直接内嵌到数据库中。这样做具有明显的好处,包括能使用更低的推理成本获得同等的 AI 能力、可以通过 SQL 语句轻松调用、可避免企业私有数据出域。李飞飞表示,阿里云会在今年内让 PolarDB、Lindorm 和 AnalyticDB 都支持 In-DB AI。

阿里云在数据库方面的另一大重要举措是采用了 Data+AI 的设计理念。具体来说,通过统一 CPU 和 GPU 资源池,瑶池数据库实现了资源池化,支持分时分片弹性调度,进而帮助客户降本增效。
此外,阿里云还宣布将 Tair 从互联网架构演进成了面向 AI 时代的架构:通过基于 Tair 内存池的 KV Cache 多级管理,可为大模型推理提供高效的 KV Cache 存储和复用。同时,Tair KVCache 还支持多租隔离、资源配额、故障恢复等企业级管理能力。

当然,阿里云数据库产品的升级之路还将继续向前。阿里云透露将于今年下半年发布全球首款基于 CXL(Compute Express Link)交换机的数据库专用服务器。CXL 高速互联技术可以进一步提升三层解耦架构下计算与内存之间的通信带宽与效率。与传统的 RDMA 高速网络相比,CXL 技术可将内存交互的性能提升一个数量级。
用 AI 基础设施支撑智能未来
阿里云准备好了
在 AI 迅猛发展的今天,强大的算力已成为驱动创新的核心动力。阿里云深刻洞察这一趋势,持续加大在 AI 基础设施领域的投入,致力于为全球用户提供高效、稳定的计算资源。
现在,依托于在 AI 基础设施上的创新和投入,阿里云已为开发者和企业搭建了一个坚实的平台,使他们能够专注于算法创新和应用开发,而无需过度关注底层计算资源的限制。而这正是 AI 大规模应用的重要基础。
正如吴结生说的那样:「云计算是一种公共服务。随着 AI 的发展,智能会变成一种资源,就像水和电一样。这样一来,token 就变成了一种商品。云上的算力正在以这种公共服务的方式给大家提供这种商品,从而普及 AI,让 AI 走进千行百业,让 AI 实现大众化和规模化。」

而当智能成为一种「资源」,基础设施的供给能力,也将决定 AI 能走多远、飞多高。
阿里云正携手企业和开发者,共同迈向智能化的未来。在这场奔赴未来的基建竞速中,阿里云,已在路上。
关注飞天发布时刻,及更多精彩发布内容: https://summit.aliyun.com/apsaramoment
#Ironwood
42.5 Exaflops:谷歌新TPU性能超越最强超算24倍,智能体协作协议A2A出炉
第七代 TPU 来了。
AI 算力又迎来了新的标杆。
本周三,谷歌正式发布了旗下第七代张量处理单元(TPU)Ironwood。谷歌称,在大规模部署的情况下,这款 AI 加速器的计算能力能达到全球最快超级计算机的 24 倍以上。
这款在 Google Cloud Next '25 大会上发布的新芯片代表着谷歌十年来 AI 芯片研发战略的重大转折:谷歌自研的前几代 TPU 主要面向 AI 的训练和推理工作负载,而 Ironwood 是第一款专为推理而设计的芯片。

谷歌副总裁兼机器学习、系统和云 AI 总经理 Amin Vahdat 表示:「Ironwood 旨在支持生成式 AI 的下一阶段及其巨大的计算和通信需求。这就是我们所说的『推理时代』,AI 代理将主动检索和生成数据,以协作方式提供洞察和答案,而不仅仅是数据。」
突破壁垒,最大 42.5 exaflops 算力
Ironwood 拥有超模的技术规格,当每个 pod 扩展至 9216 块芯片时,它可提供 42.5 exaflops 的 AI 算力,远超目前全球最快的超级计算机 El Capitan 的 1.7 exaflops。每块 Ironwood 芯片的峰值计算能力可达 4614 TFLOPs。
在单芯片规格上,Ironwood 显著提升了内存和带宽,每块芯片配备 192GB 高带宽内存(HBM),是去年发布的上一代 TPU Trillium 的六倍。每块芯片的内存带宽达到 7.2 terabits/s,是 Trillium 的 4.5 倍。

在数据中心规模扩大,供电逐渐成为瓶颈的时代,Ironwood 也大幅提升了计算效率,其每瓦性能是 Trillium 的两倍,和 2018 年推出的首款 TPU 相比高出近 30 倍。
对于推理的优化代表了 AI 发展历程中的一个重要转折点。最近几年,前沿的 AI 实验室一直专注在构建参数规模不断扩大的基础模型上。谷歌转向推理优化表明,我们正在进入一个以部署效率和推理能力为核心的新阶段。
毕竟对于 AI 参与的业务而言,模型训练的次数有限,但随着 AI 技术应用逐渐铺开,推理操作每天都会发生数十亿次。由于模型日趋复杂,这些业务的经济效益与推理成本紧密相关。
谷歌在过去八年里对于 AI 计算的需求同比增长了 10 倍,总需求量高达惊人的 1 亿。如果没有像 Ironwood 这样的专用架构,任何摩尔定律的进步都无法满足这一增长曲线。
尤其值得注意的是,谷歌在发布中提到了对执行复杂推理任务而非简单模式识别的「思维模型」的关注。这表明,谷歌认为 AI 的未来不仅在于更大的模型,还在于能够分解问题、进行多步骤推理并模拟类人思维过程的模型。
面向下一代大模型
谷歌将 Ironwood 定位为其最先进 AI 模型的基础设施,其优化的大模型自然包括自家的 Gemini 2.5,它「原生内置了思维能力」。
昨天,谷歌还发布了 Gemini 2.5 Flash,作为最新旗舰模型的缩小版本,它「可以根据提示的复杂性调整推理深度」,定位于对响应速度敏感的日常应用。
谷歌还展示了其全套多模态生成模型,包括文本转图像、文本转视频以及新发布的文本转音乐功能 Lyria。谷歌展示 demo 介绍了如何将这些工具结合使用,为一场音乐会制作完整的宣传视频。

Ironwood 只是谷歌更广泛的 AI 基础设施战略的一部分,谷歌还宣布推出 Cloud WAN,这是一项托管式广域网服务,使企业能够访问 Google 的全球规模私有网络基础设施。
Google 还在扩展其面向 AI 工作负载的软件产品,其中包括由 Google DeepMind 开发的机器学习运行时 Pathways,现在它允许客户在数百个 TPU 上扩展模型服务。
提出 A2A、支持 MCP,构建智能体协作生态
除了硬件之外,谷歌还概述了以多智能体系统为中心的 AI 愿景,发布了一个促进智能体发展的协议 ——Agent-to-Agent(A2A),旨在促进不同 AI 智能体之间的安全、标准化通信。
地址:https://google.github.io/A2A/#/
谷歌认为,2025 年将是 AI 方向转型之年,生成式 AI 的应用形式会从回答单一问题转向通过智能体系统来解决复杂问题。

A2A 协议允许跨平台、跨框架的智能体实现互操作,为它们提供了共同的「语言」和安全的通信渠道。这一协议可视为智能体的网络层,其目标是简化复杂工作流程中的智能体协作,使专业 AI 智能体能够协同完成各种复杂度和时长的任务,从而通过协作提升整体能力。

A2A 的工作原理
谷歌在博客中对 MCP 和 A2A 两种协议进行了比较。
MCP(模型上下文协议,Model Context Protocol)用于工具和资源管理
通过结构化的输入 / 输出将智能体连接到工具、API 接口和资源
Google ADK 支持 MCP 工具,使得各类 MCP 服务器能够与智能体配合使用
A2A(智能体间协议,Agent2Agent Protocol)用于智能体之间的协作
- 在不共享内存、资源和工具的情况下,实现智能体之间的动态多模态通信
- 由社区驱动的开放标准
- 可使用 Google ADK、LangGraph、Crew.AI 等工具查看示例
总的来说,A2A 与 MCP 是互补的:MCP 可以为智能体提供工具支持,而 A2A 则让这些装备了工具的智能体能够相互对话和协作。
从谷歌公布的合作伙伴阵容来看,A2A 似乎有望获得类似 MCP 的关注度。该计划已吸引超过 50 家企业加入首批合作阵营,包括领先科技企业以及全球顶级咨询和系统集成服务商。

谷歌强调了该协议的开放性,将其作为智能体相互协作的标准方式,不受底层技术框架或服务供应商的限制。谷歌表示,在与合作伙伴设计协议时,坚持了以下五项关键原则:
1. 拥抱智能体能力:A2A 专注于使智能体能够以其自然、非结构化的方式进行协作,即使它们不共享记忆、工具和上下文。我们正在实现真正的多智能体场景,而不将智能体限制为「工具」。
2. 基于现有标准构建:该协议建立在现有流行标准之上,包括 HTTP、SSE、JSON-RPC,这意味着它更容易与企业日常使用的现有 IT 堆栈集成。
3. 默认安全:A2A 设计为支持企业级身份验证和授权,在发布时与 OpenAPI 的身份验证方案相当。
4. 支持长时间运行的任务:我们设计 A2A 具有灵活性,支持各种场景,从快速任务到可能需要数小时甚至数天(当人类参与其中时)的深入研究。在整个过程中,A2A 可以向用户提供实时反馈、通知和状态更新。
5. 模态无关:智能体世界不仅限于文本,这就是为什么我们设计 A2A 支持各种模态,包括音频和视频流。
官方还给出了一个例子,通过 A2A 招聘流程得到显著简化。
,时长01:22
在 Agentspace 等统一界面中,招聘经理可指派智能体依据职位需求寻找匹配人选,该智能体会与专业领域智能体互动完成候选人寻源工作。用户还可指示智能体安排面试,并启用其他专项智能体协助背景调查,从而实现跨系统协作的全流程智能化招聘。
与此同时,谷歌也在拥抱 MCP。就在 OpenAI 宣布采用竞争对手 Anthropic 的模型上下文协议(Model Context Protocol,简称 MCP)几周后,Google 也紧随其后加入了这一行列。
刚刚,Google DeepMind 首席执行官 Demis Hassabis 在 X 平台上发文宣布,Google 将在其 Gemini 模型和 SDK 中添加对 MCP 的支持。不过他并未给出具体时间表。
Hassabis 表示:「MCP 是一个优秀的协议,正在迅速成为 AI 智能体时代的开放标准。期待与 MCP 团队和业界其他伙伴一起推进这项技术的发展。」

自 2024 年 11 月发布以来,MCP 迅速走红,引发广泛关注,成为连接语言模型与工具和数据的一种简单、标准化方式。

MCP 使 AI 模型能够从企业工具和软件等数据源获取数据以完成任务,并访问内容库和应用程序开发环境。该协议允许开发者在数据源与 AI 驱动的应用程序(如聊天机器人)之间建立双向连接。
开发者可以通过 MCP 服务器开放数据接口,并构建 MCP 客户端(如应用程序和工作流)来连接这些服务器。自从 Anthropic 开源 MCP 以来,多个公司已在其平台中集成了 MCP 支持。
参考内容:
https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/
https://developers.googleblog.com/zh-hans/a2a-a-new-era-of-agent-interoperability/
https://google.github.io/A2A/#/
#GEAL
2D 大模型赋能3D Affordance 预测,GEAL助力可泛化的3D场景可交互区域识别
GEAL 由新加坡国立大学的研究团队开展,第一作者为博士生鲁东岳,通讯作者为该校副教授 Gim Hee Lee,团队其他成员还包括孔令东与黄田鑫博士。
- 主页:https://dylanorange.github.io/projects/geal/
- 论文:https://arxiv.org/abs/2412.09511
- 代码:https://github.com/DylanOrange/geal
在现实世界中,如何让智能体理解并挖掘 3D 场景中可交互的部位(Affordance)对于机器人操作与人机交互至关重要。所谓 3D Affordance Learning,就是希望模型能够根据视觉和语言线索,自动推理出物体可供哪些操作、以及可交互区域的空间位置,从而为机器人或人工智能系统提供对物体潜在操作方式的理解。
与 2D 任务相比,3D 数据的获取与高精度标注通常更为困难且成本高昂,这使得大规模高质量的 3D 标注数据十分稀缺,也阻碍了模型在新物体或场景中的泛化。与此同时,现有 3D 多依赖几何与位置编码来表征空间结构,难以从外观语义中充分汲取上下文信息,因而在传感器不准、场景复杂或处理误差等情形下更易受到噪声影响,导致其鲁棒性不足,难以稳定应对真实环境中的多变挑战。
为克服标注与数据分布限制,一些工作尝试将 2D 视觉模型或大语言模型融入 3D 场景理解。但由于 3D 与 2D 的特征存在显著模态差异,以及受限于对空间几何关系与纹理细节的保留,直接对接往往导致可交互区域定位不准确或易受点云噪声的干扰,难以在真实复杂场景中保持鲁棒性和通用性。因此,如何充分利用大规模预训练的 2D 模型所蕴含的强大表征能力,同时兼顾 3D 模态下细节和结构信息的准确对齐,成为提升 3D Affordance Learning 效果的关键挑战。

针对上述问题,新加坡国立大学的研究团队提出了 GEAL(Generalizable 3D Affordance Learning),无需额外收集与标注大规模 3D 数据,便可借助 2D 基础模型实现对 3D 场景中可交互区域的精确预测。具体而言,GEAL 首先利用 3D Gaussian Splatting 将稀疏点云转换为可在 2D 模型中处理的真实感渲染图,并通过跨模态一致性对齐(Cross-Modal Consistency Alignment)有效融合 2D 视觉与 3D 空间特征,显著提升模型对多种物体与场景的泛化能力。此外,团队还构建了针对真实场景扰动的全新基准数据集,全面评估模型的稳健性。实验结果表明,GEAL 无论在公共数据集还是各种噪声环境下,都显著优于现有方法,为通用且鲁棒的 3D Affordance Learning 提供了新思路。
目前,GEAL 已被 CVPR 2025 接收,论文、代码和模型权重均已公开。
2D-3D 跨模态对齐
完成 3D 可交互区域预测
如图所示,在 GEAL 的整体框架中,我们通过 2D 分支 与 3D 分支的协同合作,将预训练 2D 模型的强语义表达能力注入到稀疏点云的三维世界中,并通过跨模态特征对齐来获得更强的鲁棒性与泛化能力。下面对各个关键步骤加以说明

利用 3D Gaussian Splatting 渲染稀疏点云,高效引入 2D 分支
考虑到三维数据通常存在采样稀疏、标注昂贵、遮挡严重等问题,我们在网络结构中单独设置了一个 2D 分支,借助在海量 2D 数据上预训练的视觉 backbone(如 DINOV2),获取包含丰富语义上下文与外观信息的多粒度图像特征,从而为后续的三维功能区域预测提供更具鲁棒性与泛化力的先验。由于该分支与 3D 分支并行存在,我们可在后期设计中灵活地融合并对齐 2D/3D 特征,避免简单拼接带来的模态失配。为了让预训练的 2D 模型充分 “看见” 三维场景的纹理与遮挡信息,GEAL 采用了 3D Gaussian Splatting 技术来渲染点云。具体而言,我们用可学习的高斯基元对每个三维点进行表示,并通过光栅化与 α- 混合在 2D 图像中生成具有深度、透明度与颜色信息的像素,从而获得更为平滑、逼真的二维视图。这些视图不仅能够为 2D 模型提供足以辨别纹理和轮廓的语义特征,还能在后续跨模态步骤中与点云的几何结构建立一一对应关系,为特征对齐打下基础。
跨模态特征对齐
在两条分支分别获得多尺度 2D/3D 特征后,GEAL 通过颗粒度自适应融合模块(Granularity-Adaptive Fusion Module, GAFM) 与一致性对齐模块(Consistency Alignment Module,CAM) 实现语义与几何间的双向对齐。

- 颗粒度自适应融合模块
针对 2D 与 3D 在不同层级上所捕获的细节与全局信息,通过自适应权重聚合和文本引导的视觉对齐,将最相关的多粒度特征与用户指令相互融合。这样既能突出与功能需求紧密关联的目标局部,又确保对全局场景保持整体把握。
- 一致性对齐模块
基于 Gaussian Splatting 所构建的像素 - 点云映射,将 3D 分支提取的点云特征再度渲染至二维平面,与 2D 分支形成逐像素对应,然后通过一致性损失(如 L2 距离)使两者在同一空间区域的表征尽可能相似。这种策略能让 2D 分支的通用语义向 3D 分支扩散,同时也让 3D 分支在几何维度上对 2D 特征形成有益补充,最终实现更准确的可交互区域定位。
Corrupt Data Benchmark 评估鲁棒性
为了更全面地测试 GEAL 在真实干扰环境中的表现,我们基于常见的 PIAD 与 LASO 数据集,构建了包含多种扰动形式的 Corrupt Data Benchmark。它涵盖局部或全局的随机丢失、噪声注入、尺度变化、抖动及旋转等多种干扰场景,模拟复杂感知条件下的真实挑战。实验结果表明,GEAL 在该基准上依然能够保持高精度与鲁棒性,印证了跨模态对齐对于三维功能区域预测在噪声环境中的关键价值。

通过以上几个核心环节,GEAL 成功将 2D 模型的强大语义理解与 3D 数据的空间几何细节有机结合,不仅免去了大规模 3D 标注数据的依赖,还显著提升了可交互区域预测的可靠性与泛化水平,为 3D Affordance Learning 迈向真实应用场景提供了新的技术思路。
实验结果
为评估 GEAL 在 3D 场景可交互区域预测上的整体表现,作者在主流数据集 PIAD 与 LASO 上进行了系统实验。结果显示,GEAL 相较现有最优方法均取得了更高分数,尤其在 unseen 类别测试中依然保持高准确率,证明其对未见过的物体形状与类别具备良好适应能力。这一优势主要得益于 2D 语义先验的充分利用,以及跨模态一致性带来的 2D-3D 特征对齐,使得模型能在几何细节与语义信息之间保持平衡。

为了模拟实际感知场景中的各种干扰,如传感器噪声、局部丢失或随机旋转等,作者还在新提出的 Corrupt Data Benchmark 上对 GEAL 进行了测试。结果表明,即便在高度不确定的环境下,GEAL 依然能够稳定预测可交互区域,展现出优异的鲁棒性。这主要归功于 2D 分支在大规模预训练模型中的抗干扰特性,以及与 3D 分支通过一致性约束实现的高效信息传递。

相比仅使用 2D 分支或 3D 分支的基础版本,融合双分支并加入 CAM 后,在未见类别和高噪声条件下的准确率均显著提升;进一步引入 GAFM 后,则在见类与未见类任务中同时提高精度与 IoU,说明多粒度特征融合对于捕捉局部细节和全局语义至关重要。

综上所述,多项实验结果与消融研究均验证了 GEAL 的有效性:该方法不仅在常规数据集上表现出卓越的精度与泛化能力,还能在真实干扰环境中保持稳健,展现出跨模态对齐与双分支架构在 3D 场景可交互区域预测中的强大潜力。
结论
综上所述,GEAL 通过双分支架构与 3D Gaussian Splatting 的巧妙结合,在不依赖大规模 3D 标注的情况下,充分挖掘了大规模 2D 预训练模型蕴含的丰富语义信息,实现了对 3D 场景可交互区域的精确预测。该成果为在机器人操作、增强现实和智能家居等领域中灵活、高效地获取三维可交互区域提供了新思路,对构建通用、稳健的 3D Affordance Learning 系统具有重要意义。
#ORION
闭环端到端精度暴涨19.61%!华科&小米汽车联手打造自动驾驶框架ORION,代码将开源
近年来,端到端(End-to-End,E2E)自动驾驶技术不断进步,但在复杂的闭环交互环境中,由于其因果推理能力有限,仍然难以做出准确决策。虽然视觉 - 语言大模型(Vision-Language Model,VLM)凭借其卓越的理解和推理能力,为端到端自动驾驶带来了新的希望,但现有方法在 VLM 的语义推理空间和纯数值轨迹的行动空间之间仍然存在巨大鸿沟。
除此之外,现有的方法常常通过叠加多帧的图像信息完成时序建模,这会受到 VLM 的 Token 长度限制,并且会增加额外的计算开销。
为了解决上述问题,本文提出了 ORION,这是一个通过视觉语言指令指导轨迹生成的端到端自动驾驶框架。ORION 巧妙地引入了 QT-Former 用于聚合长期历史上下文信息,VLM 用于驾驶场景理解和推理,并启发式地利用生成模型对齐了推理空间与动作空间,实现了视觉问答(VQA)和规划任务的统一端到端优化。

图 1:不同的端到端自动驾驶范式的对比
ORION 在具有挑战性的闭环评测 Bench2Drive 数据集上实现了优秀的性能,驾驶得分为 77.74 分,成功率为 54.62%,相比之前的 SOTA 方法分别高出 14.28分和 19.61% 的成功率。
此外,ORION 的代码、模型和数据集将很快开源。
- 论文标题:ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
- 论文地址:https://arxiv.org/abs/2503.19755
- 项目地址:https://xiaomi-mlab.github.io/Orion/
- 代码地址:https://github.com/xiaomi-mlab/Orion
- 单位:华中科技大学、小米汽车
我们来看一下 ORION 框架下的闭环驾驶能力:
ORION 检测到骑自行车的人并向左变道避免了碰撞。
ORION 检测到右前方的车辆,先执行减速,然后再改变车道。
ORION 识别停车标志并停车,等待一段时间,然后重新启动成功通过十字路口。

主要贡献
本文提出了一个简单且有效的端到端自动驾驶框架 ORION,主要包含如下几方面的贡献:
- VLM + 生成模型:利用生成模型弥补了 VLM 的推理空间与轨迹的动作空间之间的差距,从而使 ORION 能够理解场景并指导轨迹生成。
- QT-Former:引入 QT-Former 聚合历史场景信息,使模型能够将历史信息整合到当前推理和动作空间中。
- 可扩展性:ORION 可以与多种生成模型兼容,实验证明了所提出框架的灵活性。
- 性能优异:在仿真数据集 Bench2drive 的闭环测试上取得 SOTA 的性能。
研究动机
经典的 E2E 自动驾驶方法通过多任务学习整合感知、预测和规划模块,在开环评估中表现出优秀的能力。然而,在需要自主决策和动态环境交互的闭环基准测试中,由于缺少因果推理能力,这些方法往往表现不佳。
近年来,VLM 凭借其强大的理解和推理能力,为 E2E 自动驾驶带来了新的解决思路。但直接使用 VLM 进行端到端自动驾驶也面临诸多挑战,例如,VLM 的能力主要集中在语义推理空间,而 E2E 方法的输出是动作空间中的数值规划结果。
一些方法尝试直接用 VLM 输出基于文本的规划结果,但 VLM 在处理数学计算和数值推理方面存在不足,且其自回归机制导致只能推断单一结果,无法适应复杂场景。还有些方法通过设计接口,利用 VLM 辅助经典 E2E 方法,但这种方式解耦了 VLM 的推理空间和输出轨迹的动作空间,阻碍了两者的协同优化。
除此之外,长期记忆对于端到端自动驾驶是必要的,因为历史信息通常会影响当前场景中的轨迹规划。现有使用 VLM 进行端到端自动驾驶的方法通常通过拼接多帧图像来进行时间建模。但这会受到 VLM 的输入 Token 的长度限制,并且会增加额外的计算开销。
为了解决上述问题,本文提出了 ORION。ORION 的结构包括 QT-Former、VLM 和生成模型。 ORION 通过 QT-Former 聚合长时间上下文信息,并巧妙地结合了生成模型和 VLM,有效对齐了推理空间和动作空间,实现了视觉问答(VQA)和规划任务的统一端到端优化。
方法概览
具体来说,ORION 通过以下三大核心模块,显著提升了自动驾驶系统的决策能力:
1. QT-Former:长时序上下文聚合
ORION 引入了 QT-Former,通过引入历史查询和记忆库,有效聚合长时视觉上下文信息,增强了模型对历史场景的理解能力。相比现有方法,QT-Former 不仅减少了计算开销,还能更好地捕捉静态交通元素和动态物体的运动状态。
2. VLM:场景推理与指令生成
ORION 利用 VLM 的强大推理能力,结合用户指令、长时和当前的视觉信息,能够对驾驶场景进行多维度分析,包括场景描述、关键物体行为分析、历史信息回顾和动作推理,并且利用自回归特性聚合整个场景信息以生成规划 token,用来指导生成模型进行轨迹预测。
3. 生成模型:推理与动作空间对齐
ORION 通过生成模型,将 VLM 的推理空间与预测轨迹的动作空间对齐。生成模型使用变分自编码器(VAE)或扩散模型,以规划 token 作为条件去控制多模态轨迹的生成,确保模型在复杂场景中做出合理的驾驶决策。

图 2:ORION 整体架构图
实验结果
本文在 Bench2Drive 数据集上进行闭环评估测试,如表 1 所示,ORION 取得了卓越的性能,其驾驶得分(DS)和成功率(SR)分别达到了 77.74 和 54.62%,相比现在的 SOTA 方法提升了 14.28 DS 和 19.61% SR,展现了 ORION 强大的驾驶能力。

表 1:Bench2Drive 上闭环评估和开环评估的性能对比
此外,如表 2 所示,ORION 还在 Bench2Drive 的多能力评估中表现优异,特别是在超车(71.11%)、紧急刹车(78.33%)和交通标志识别(69.15%)等场景中,ORION 的表现远超其他方法。这得益于 ORION 通过 VLM 对驾驶场景的理解,能够更好地捕捉驾驶场景之间的因果关系。

表 2:Bench2Drive 上多能力评估测试对比
可解释性结果
下图展示了 ORION 在 Bench2Drive 的闭环评估场景中的可解释性结果。ORION 可以理解场景中正确的因果关系,并做出准确的驾驶决策,然后根据推理信息指导规划轨迹预测。

图 3:可解释性结果图
总结
ORION 框架为端到端自动驾驶提供了一种全新的解决方案。ORION 通过生成模型实现语义与动作空间对齐,引入 QT-Former 模块聚合长时序场景上下文信息,并联合优化视觉理解与路径规划任务,在闭环仿真中取得了卓越的性能。

















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









