







一. Logistic回归的思想
1. 分类任务思想
分类问题通常可以分为二分类,多分类任务;而对于不同的分类任务,训练的主要目标是不变的,即找到一个分类器,这个分类器可以对新输入的数据进行判断,以确定该数据是属于哪个类别
对于分类任务,我们常设函数为 A x 1 + B x 2 + C = 0 Ax_{1}+Bx_{2}+C = 0 Ax1+Bx2+C=0
下面我们先来讨论二分类任务:
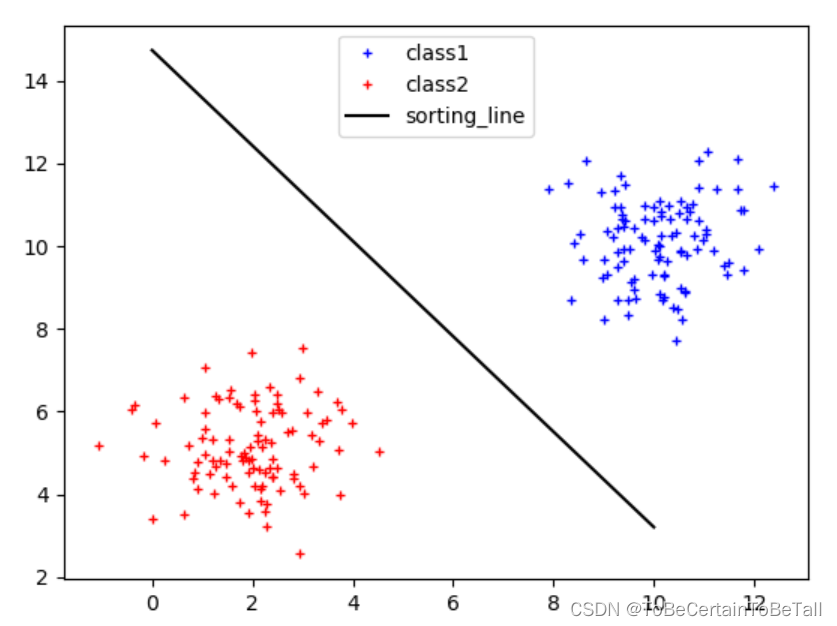
对于有两个特征的分类任务来说,我们的目的是寻找一条决策边界,使得这两个特征可以被区分开,如上图:
假设我们认为,决策边界为 A x 1 + B x 2 + C = 0 Ax_{1}+Bx_{2}+C = 0 Ax1+Bx2+C=0
当输入一个新数据 ( x 1 0 , x 2 0 ) (x_{1_{0}},x_{2_{0}}) (x10,x20)
对于蓝色特征(右上方)就会得到:A x 1 0 + B x 2 0 + C > 0 Ax_{1_{0}}+Bx_{2_{0}}+C > 0 Ax10+Bx20+C>0,即正样本
对于红色特征(左下方)就会得到:
A x 1 0 + B x 2 0 + C < 0 Ax_{1_{0}}+Bx_{2_{0}}+C < 0 Ax10+Bx20+C<0,即负样本
这里强调一点,对于分类任务:
A
x
1
+
B
x
2
+
C
=
0
Ax_{1}+Bx_{2}+C = 0
Ax1+Bx2+C=0描述的不再是特征与结果之间的关系,而是特征与特征之间的关系
我们训练的目标,从将一个特征值带入方程来求另一个特征值变成了将两个特征值带入求
A
x
1
+
B
x
2
+
C
=
0
Ax_{1}+Bx_{2}+C = 0
Ax1+Bx2+C=0的值
2. Logistic回归思想
Logistic回归算法并不满足于上述常规分类思想,而是在其基础上引入了概率的概念,即:
当输入一个新数据 ( x 1 0 , x 2 0 ) (x_{1_{0}},x_{2_{0}}) (x10,x20)
若该数据落在决策边界上:该样本点是正样本或负样本的概率都是0.5
若该数据落在决策边界左下方,且距离决策边界越远:
该样本点为负样本的概率越大,为正样本的概率越小
若该数据落在决策边界右上方,且距离决策边界越远:
该样本点为正样本的概率越大,为负样本的概率越小
上述描述中,不难看出,Logistic回归是将距离与概率进行关联,那么具体怎样实现呢?
首先我们定义Logistic函数:
y
=
1
1
+
e
−
x
y = \frac{1}{1+e^{-x} }
y=1+e−x1
其中,x为样本点到决策边界的距离,即
A
x
1
+
B
x
2
+
C
=
0
的值
Ax_{1}+Bx_{2}+C = 0的值
Ax1+Bx2+C=0的值
对于公式,简单解析下:
- 公式为什么会出现e?
求导方便
- 为什么公式中样本点到决策边界距离的计算方式与数学中不符?
数学中,点到直线的公式为 A x 0 + B y 0 + C A 2 + B 2 \frac{Ax_{0}+By_{0}+C }{\sqrt{A^{2}+ B^{2}} } A2+B2Ax0+By0+C,其中 A 2 + B 2 \sqrt{A^{2}+ B^{2}} A2+B2可以看作一个整数
公式中,我们求得的距离之所以没有除以 A 2 + B 2 \sqrt{A^{2}+ B^{2}} A2+B2,是因为每个点的相对距离是一样的
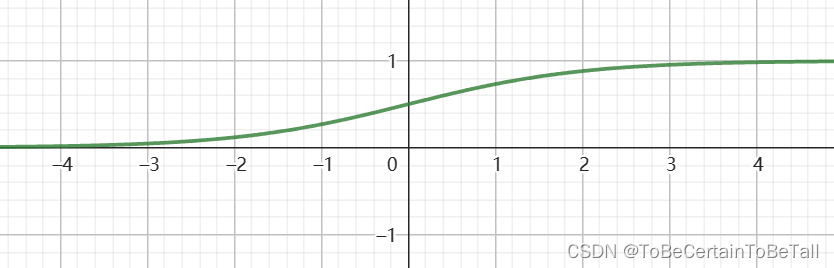
通过观察函数图像,我们可以看出这个函数非常符合Logistic回归思想:
自变量x:样本点到决策边界的距离d
因变量y:样本点属于正负样本的概率P
当自变量为0时,P=0.5
当自变量趋近-∞时,P趋近于0
当自变量趋近+∞时,P趋近取1
【注意】这里的距离是有正有负的
由于Logistic函数的形状类似于S,所以该函数又被称为Sigmoid函数
二. Logistic回归算法:线性可分推导
下面我们来具体聊Logistic回归算法,但在开始之前,我们先来明确分类的种类:
对于二分类任务目标:我们需要寻找一个决策边界,从而达到将两类样本点区分的目的
这里所谓的决策边界,即分类问题中进行分类决策的依据:
对于二维空间,决策边界是一条直线
对于三维空间,决策空间是一个平面
对于多为空间,决策边界是一个超平面
也就是说:
当上面这些决策边界存在时,我们认为这些样本点是线性可分的
当上面这些决策边界不存在时,我们认为这些样本点是线性不可分的;比如:找不到一条直线,将样本进行二分类
这里补充一点:
对于线性不可分的情况,我们的解决方法其实是多项式扩展
那么,接下来我们先来讨论二维空间中的线性可分问题
首先我们先用公式阐述我们的问题:
存在一条决策边界 f ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 = θ T X , f ( x ) 为距离 f(x)=\theta _{0} +\theta _{1}x_{1}+\theta _{2}x_{2} = \theta ^{T} X,f(x)为距离 f(x)=θ0+θ1x1+θ2x2=θTX,f(x)为距离
其中,令
g
(
x
)
=
1
1
+
e
−
x
,
g
(
x
)
为概率
g(x) = \frac{1}{1+e^{-x} },g(x)为概率
g(x)=1+e−x1,g(x)为概率
则,会得到
h
θ
(
x
)
=
g
(
f
(
x
)
)
=
g
(
θ
0
+
θ
1
x
1
+
θ
2
x
2
)
h_{\theta } (x) = g(f(x))= g(\theta _{0}+\theta _{1}x_{1}+\theta _{2}x_{2} )
hθ(x)=g(f(x))=g(θ0+θ1x1+θ2x2)
当确定
θ
0
,
θ
1
,
θ
2
\theta _{0},\theta _{1},\theta _{2}
θ0,θ1,θ2后,就可以用
h
θ
(
x
)
h_{\theta } (x)
hθ(x)对新数据进行预测;需要注意的是,此时预测的是样本属于正样本的概率
结合上面对于问题的描述,我们开始对公式进行推导
假设我们采集到数据后,进行标注,得到数据集如下:
x
1
(
i
)
,
x
2
(
i
)
,
.
.
.
,
x
N
(
i
)
,
y
(
i
)
x_{1}^{(i)}, x_{2}^{(i)}, ... , x_{N}^{(i)}, y^{(i)}
x1(i),x2(i),...,xN(i),y(i)
其中,数据集的正样本标注为
y
(
i
)
=
1
y^{(i)}=1
y(i)=1
其中,数据集的负样本标注为
y
(
i
)
=
0
y^{(i)}=0
y(i)=0
对于线性可分问题,存在决策边界为:
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
.
.
.
+
θ
N
x
N
=
0
\theta _{0}+ \theta _{1}x_{1}+\theta _{2}x_{2}+ ... +\theta _{N}x_{N} = 0
θ0+θ1x1+θ2x2+...+θNxN=0
则,令
d
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
.
.
.
+
θ
N
x
N
,这里的距离
d
有正负
d=\theta _{0}+ \theta _{1}x_{1}+\theta _{2}x_{2}+ ... +\theta _{N}x_{N},这里的距离d有正负
d=θ0+θ1x1+θ2x2+...+θNxN,这里的距离d有正负
如果带入每个样本的特征值,就会得到每个样本点到直线的距离,即:
d
=
θ
0
+
θ
1
x
1
(
i
)
+
θ
2
x
2
(
i
)
+
.
.
.
+
θ
N
x
N
(
i
)
d = \theta _{0}+ \theta _{1}x_{1}^{(i)}+\theta _{2}x_{2}^{(i)}+ ... +\theta _{N}x_{N}^{(i)}
d=θ0+θ1x1(i)+θ2x2(i)+...+θNxN(i)
根据Logistic函数
y
=
1
1
+
e
−
x
y = \frac{1}{1+e^{-x}}
y=1+e−x1
带入关于
θ
\theta
θ的函数d,我们可以得到
h
θ
(
x
)
=
1
1
+
e
−
d
(
θ
)
h_{\theta } (x) = \frac{1}{1+e^{-d(\theta )}}
hθ(x)=1+e−d(θ)1
注意:
此时计算的 h θ ( x ) h_{\theta } (x) hθ(x)结果是以正样本为依据,即所计算的样本属于 正样本/正类 的概率
同理,我们就会得到计算样本属于 负样本/负类 的概率
即
{
P
(
y
=
1
∣
x
;
θ
)
=
h
θ
(
x
)
P
(
y
=
0
∣
x
;
θ
)
=
1
−
h
θ
(
x
)
\left\{\begin{matrix}P(y=1|x;\theta ) = h_{\theta }(x) \\P(y=0|x;\theta ) = 1-h_{\theta }(x) \end{matrix}\right.
{P(y=1∣x;θ)=hθ(x)P(y=0∣x;θ)=1−hθ(x)
合并后,我们会得到
P
(
y
∣
x
;
θ
)
=
h
θ
(
x
)
y
[
1
−
h
θ
(
x
)
]
1
−
y
P(y|x;\theta ) = h_{\theta }(x)^{y}\left [ 1-h_{\theta }(x) \right ]^{1-y}
P(y∣x;θ)=hθ(x)y[1−hθ(x)]1−y
这样,我们就可以得到关于
θ
\theta
θ的似然函数:
L
(
θ
)
=
∏
i
=
1
M
h
θ
(
x
(
i
)
)
y
(
i
)
[
1
−
h
θ
(
x
(
i
)
)
]
1
−
y
(
i
)
L(\theta)=\prod_{i=1}^{M} h_{\theta }(x^{(i)} )^{y^{(i)} }\left [ 1-h_{\theta }(x^{(i)}) \right ]^{1-y^{(i)}}
L(θ)=i=1∏Mhθ(x(i))y(i)[1−hθ(x(i))]1−y(i)
为了方便计算,我们对似然求对数,得到
l
(
θ
)
=
l
n
[
L
(
θ
)
]
=
∑
i
=
1
M
{
y
(
i
)
l
n
[
h
θ
(
x
(
i
)
)
]
+
(
1
−
y
(
i
)
)
l
n
[
1
−
h
θ
(
x
(
i
)
)
]
}
l(\theta )=ln\left [ L(\theta)\right ]=\sum_{i=1}^{M}\left \{y^{(i)}ln[h_{\theta}(x^{(i)} )]+(1-y^{(i)})ln[1-h_{\theta}(x^{(i)} )] \right \}
l(θ)=ln[L(θ)]=i=1∑M{y(i)ln[hθ(x(i))]+(1−y(i))ln[1−hθ(x(i))]}
下面,就到了我们熟悉的环节,求
θ
\theta
θ偏导
∂ l ( θ ) ∂ ( θ j ) = ∑ i = 1 M ∂ { y ( i ) l n [ h θ ( x ( i ) ) ] + ( 1 − y ( i ) ) l n [ 1 − h θ ( x ( i ) ) ] } ∂ ( θ j ) \frac{\partial l(\theta )}{\partial (\theta _{j} )} =\sum_{i=1}^{M}\frac{\partial\left \{ y^{(i)}ln[h_{\theta}(x^{(i)} )]+(1-y^{(i)})ln[1-h_{\theta}(x^{(i)} )] \right \} }{\partial(\theta _{j})} ∂(θj)∂l(θ)=∑i=1M∂(θj)∂{y(i)ln[hθ(x(i))]+(1−y(i))ln[1−hθ(x(i))]}
= ∑ i = 1 M ( y ( i ) h θ ( x ( i ) ) − 1 − y ( i ) 1 − h θ ( x ( i ) ) ) ∂ ( h θ ( x ( i ) ) ) ∂ ( θ j ) =\sum_{i=1}^{M}( \frac{y^{(i)}}{h_{\theta}(x^{(i)})} -\frac{1-y^{(i)}}{1-h_{\theta}(x^{(i)})})\frac{\partial(h_{\theta}(x^{(i)})) }{\partial (\theta _{j} )} =∑i=1M(hθ(x(i))y(i)−1−hθ(x(i))1−y(i))∂(θj)∂(hθ(x(i)))
这里我们来推导 ∂ ( h θ ( x ( i ) ) ) ∂ ( θ j ) \frac{\partial(h_{\theta}(x^{(i)})) }{\partial (\theta _{j} )} ∂(θj)∂(hθ(x(i)))
其中, h θ ( x ) = 1 1 + e − d ( θ ) h_{\theta } (x) = \frac{1}{1+e^{-d(\theta )}} hθ(x)=1+e−d(θ)1,又 y = 1 1 + e − x y = \frac{1}{1+e^{-x}} y=1+e−x1所以我们先对y进行求导
d y d x = [ − 1 ( 1 + e − x ) 2 ∗ e − x ∗ ( − 1 ) ] \frac{\mathrm{d} y}{\mathrm{d} x} =\left [ -\frac{1}{(1+e^{-x} )^{2}}\ast e^{-x}\ast (-1)\right ] dxdy=[−(1+e−x)21∗e−x∗(−1)]
= 1 1 + e − x ∗ e − x 1 + e − x = \frac{1}{1+e^{-x}} \ast \frac{e^{-x}}{1+e^{-x}} =1+e−x1∗1+e−xe−x
= 1 1 + e − x ∗ ( 1 − 1 1 + e − x ) =\frac{1}{1+e^{-x}} \ast (1-\frac{1}{1+e^{-x}}) =1+e−x1∗(1−1+e−x1)
= y ∗ ( 1 − y ) =y \ast (1-y) =y∗(1−y)对于 ∂ ( h θ ( x ( i ) ) ) ∂ ( θ j ) \frac{\partial(h_{\theta}(x^{(i)})) }{\partial (\theta _{j} )} ∂(θj)∂(hθ(x(i)))我们就会得到
∂ ( h θ ( x ( i ) ) ) ∂ ( θ j ) = h θ ( x ( i ) ) ∗ [ 1 − h θ ( x ( i ) ) ] ∗ ∂ d ( θ ) ∂ θ j \frac{\partial(h_{\theta}(x^{(i)})) }{\partial (\theta _{j} )}=h_{\theta}(x^{(i)})\ast \left [ 1-h_{\theta}(x^{(i)}) \right ] \ast \frac{\partial d(\theta )}{\partial \theta _{j} } ∂(θj)∂(hθ(x(i)))=hθ(x(i))∗[1−hθ(x(i))]∗∂θj∂d(θ)
∂ l ( θ ) ∂ θ j = ∑ i = 1 M ( y ( i ) h θ ( x ( i ) ) − 1 − y ( i ) 1 − h θ ( x ( i ) ) ) ∂ ( h θ ( x ( i ) ) ) ∂ θ j \frac{\partial l(\theta )}{\partial \theta _{j} }=\sum_{i=1}^{M}( \frac{y^{(i)}}{h_{\theta}(x^{(i)})} -\frac{1-y^{(i)}}{1-h_{\theta}(x^{(i)})})\frac{\partial(h_{\theta}(x^{(i)})) }{\partial \theta _{j} } ∂θj∂l(θ)=∑i=1M(hθ(x(i))y(i)−1−hθ(x(i))1−y(i))∂θj∂(hθ(x(i)))
=
∑
i
=
1
M
(
y
(
i
)
h
θ
(
x
(
i
)
)
−
1
−
y
(
i
)
1
−
h
θ
(
x
(
i
)
)
)
∗
h
θ
(
x
(
i
)
)
∗
[
1
−
h
θ
(
x
(
i
)
)
]
∗
∂
d
(
θ
)
(
i
)
∂
θ
j
=\sum_{i=1}^{M}( \frac{y^{(i)}}{h_{\theta}(x^{(i)})} -\frac{1-y^{(i)}}{1-h_{\theta}(x^{(i)})})\ast h_{\theta}(x^{(i)})\ast \left [ 1-h_{\theta}(x^{(i)}) \right ] \ast \frac{\partial d(\theta )^{(i)} }{\partial \theta _{j} }
=∑i=1M(hθ(x(i))y(i)−1−hθ(x(i))1−y(i))∗hθ(x(i))∗[1−hθ(x(i))]∗∂θj∂d(θ)(i)
=
∑
i
=
1
M
[
y
(
i
)
−
h
θ
(
x
(
i
)
)
]
∗
∂
d
(
θ
)
(
i
)
∂
θ
j
=\sum_{i=1}^{M}[y^{(i)}-h_{\theta}(x^{(i)} ) ] \ast \frac{\partial d(\theta )^{(i)} }{\partial \theta _{j} }
=∑i=1M[y(i)−hθ(x(i))]∗∂θj∂d(θ)(i)
根据 d ( θ ) ( i ) = θ 0 x 0 ( i ) + θ 1 x 1 ( i ) + θ 2 x 2 ( i ) + . . . + θ N x N ( i ) d(\theta )^{(i)} = \theta _{0}x_{0}^{(i)}+ \theta _{1}x_{1}^{(i)}+\theta _{2}x_{2}^{(i)}+ ... +\theta _{N}x_{N}^{(i)} d(θ)(i)=θ0x0(i)+θ1x1(i)+θ2x2(i)+...+θNxN(i)
我们可以得到
∂ d ( θ ) ( i ) ∂ θ j = x j ( i ) \frac{\partial d(\theta )^{(i)} }{\partial \theta _{j} }=x_{j}^{(i)} ∂θj∂d(θ)(i)=xj(i)
∂ l ( θ ) ∂ θ j = ∑ i = 1 M [ y ( i ) − h θ ( x ( i ) ) ] ∗ x j ( i ) \frac{\partial l(\theta )}{\partial \theta _{j} }=\sum_{i=1}^{M}[y^{(i)}-h_{\theta}(x^{(i)} ) ] \ast x_{j}^{(i)} ∂θj∂l(θ)=i=1∑M[y(i)−hθ(x(i))]∗xj(i)
为了求解似然函数的最大值,我们需要令导数等于0,即
∂
l
(
θ
)
∂
θ
j
=
0
\frac{\partial l(\theta )}{\partial \theta _{j} }=0
∂θj∂l(θ)=0
这里继续向下推会发现,求解偏导为0的计算十分困难
由此,我们会想到用梯度下降优化模型参数,那么,具体怎么优化,我们下一篇再见啦!
感谢阅读🌼
如果喜欢这篇文章,记得点赞👍和转发🔄哦!
有任何想法或问题,欢迎留言交流💬,我们下次见!
祝愉快🌟!
















 636
636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











