







目录
1. 基本概念
-
2分类
分类任务有两个类别,每个样本属于两个类别中的一个,标签0/1.比如:训练一个图像分类器,判断一张输入图片是否是猫。
- 多分类
分类任务有n个类别,每个样本属于n个类别中的一个,每个样本有且只有一个标签。比如:新闻文本分类,每个样本/新闻只有一个主题标签,如:政治、经济、体育等。
- 多标签分类
分类任务有n个类别,每个样本属于n个类别中的若干个,每个样本有若干个标签。比如:新闻文本分类,每个样本/新闻可能有多个主题标签,如:一段新闻可能被同时认为是宗教、政治、金融或者教育相关话题。
2. 2分类问题
2分类问题输出层只有一个单元,并采用sigmoid损失函数(将输出转换为0-1之间的概率分布)和2分类交叉熵损失。
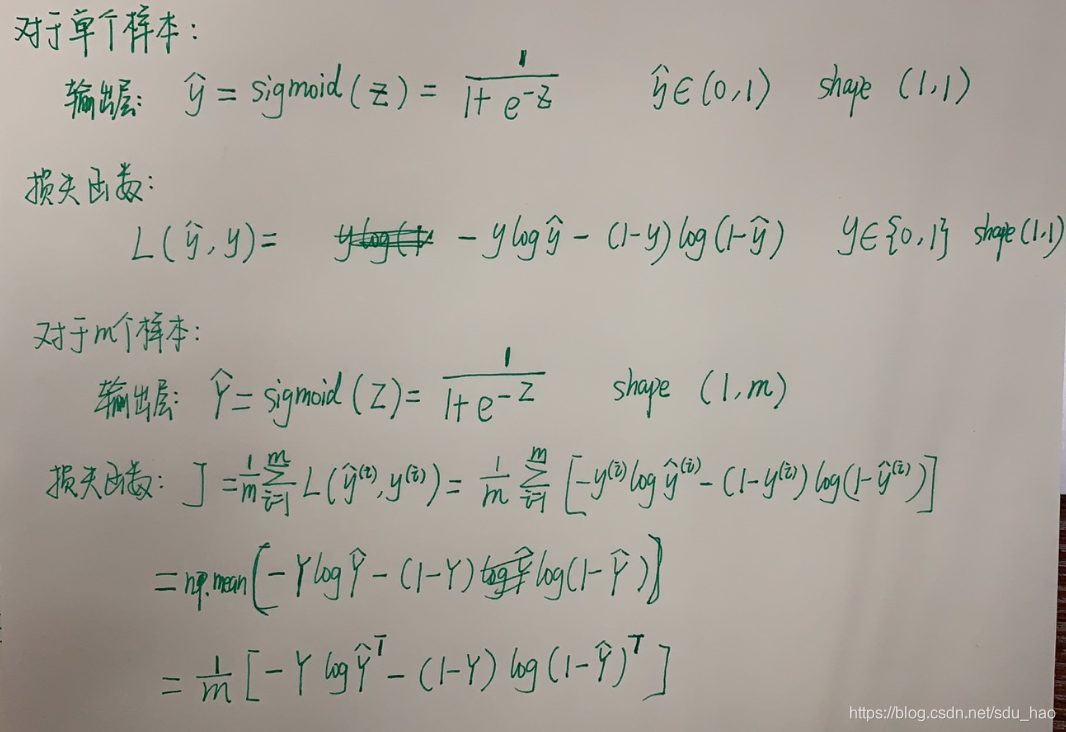
2. 多分类问题
多分类问题()一般有三种解决方案:
- 直接进行多分类
如使用神经网络模型时,调整输出层的单元数,当进行n分类时,设置输出层的单元数为n,采用softmax损失函数(把输出层整体转换为0-1之间的概率分布)+多分类交叉熵损失。
把标签转换为one-hot向量,每个样本的标签是一个n维向量,其所属类别位置为1,其余位置为0:

- one vs. all
每次选其中一个类别为正类,其余类别为负类。如果进行n分类的话,则训练n个2分类器。测试时,将新样本喂给n个2分类器,每个2分类器的输出是当前类为正类的置信度,选择置信度最大的类别。
- one vs. one
每次从所有类别中选择两个类别,如果进行n分类的话,则训练个2分类器。测试时,将新样本喂给这些2分类器,采用多数投票原则,哪个类别得票最多(出现次数最多),则把新样本归为哪个类别。
3. 多标签分类问题
每个样本有多个类别标签,并且每个样本对应的标签数量是不固定的。
把多标签问题转换为每个标签上的2分类问题。输出层采用sigmoid激活函数(把每个输出单元转换为0-1之间的概率分布)+2分类交叉熵损失。
把标签转换为multi-hot向量,每个样本的标签是一个n维向量,其所属类别位置为1,其余位置为0:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









