






耗时三周(中间遇到期中考试中断一周)终于是完成了P2,整个p2的难度和体量之大真是给我这个菜鸟上了大大一课,整个项目下来代码量是破千行的,加上是在整个P1的基础上,难度也极大,调试起来一大堆文件啊啊啊啊啊啊啊啊,不好的回忆,太坐牢了!
博客由于体量太大,最开始都不知道该怎么下手,想了想,准备分成“上中下”三个部分来讲解。
贴两张最后终于满分过关的截图: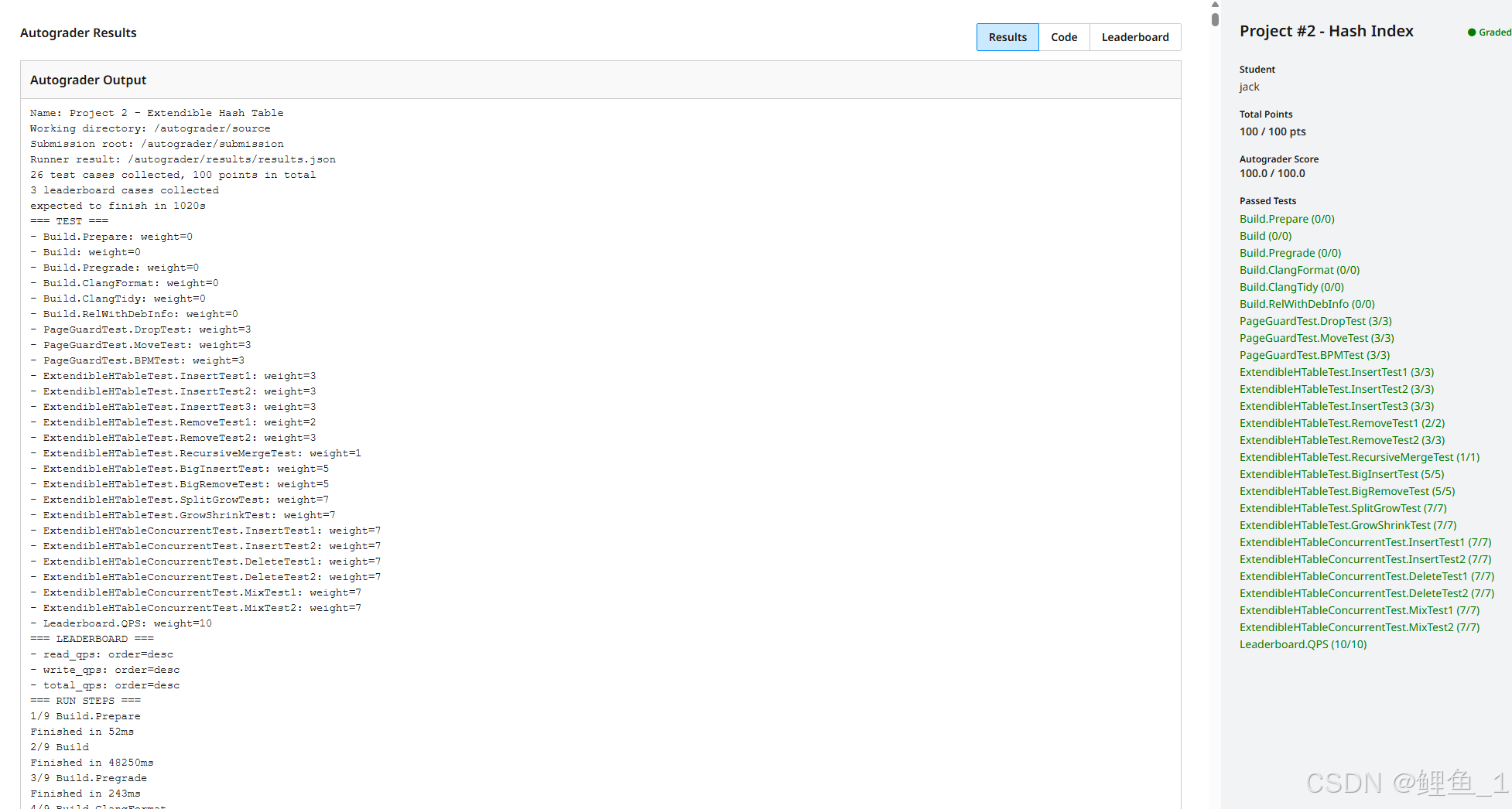
全局思路(写在最前面):
总的来说,我们要在数据库系统中实现磁盘支持的哈希索引,使用可扩展哈希的变体作为哈希方案,如下图:
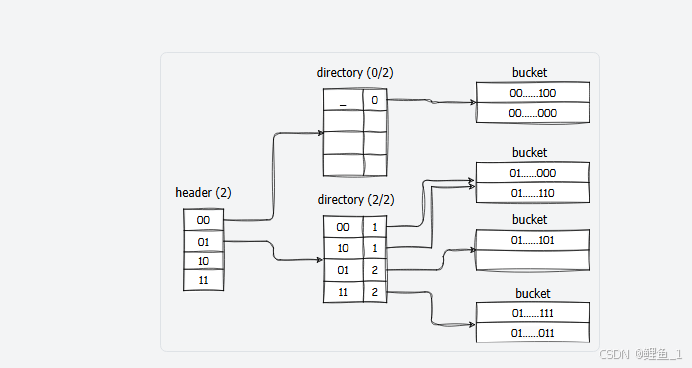
可见整个索引结构被分成了三级结构:
Hash Table Header Page
Hash Table Directory Page
Hash Table Bucket Page
也就是Task #2 - Extendible Hash Table Pages要实现的三个部分
而整个大结构都是在P1:buffer_pool的基础上的,为了实现磁盘支持,进行查找,删除,插入操作,必须借用buffer_pool_manager这一中介来进行操作,而这部分内容也就是我们的Task #3 - Extendible Hashing Implementation,也是整个P2的重中之重,难中之难!
回头来看,整个项目的最大难点我个人认为在支持并发多线程上,为达成此目的,2023 fall的版本,15445课程方要求我们先实现一个page_guard来管理buffer_pool中的page。为什么要强调版本2023 fall呢?因为对比2022 fall版本的B+ tree_index,我们会发现,在实现并发多线程时,需要大量的手动上锁解锁,FetchPage之后必须及时手动UnpinPage:
(下图来自我可爱的舍友DogDu,在代码中很好的注释 “// 草你妈的,这里应该是old_array,打错了。” 使我在翻看时被骂)
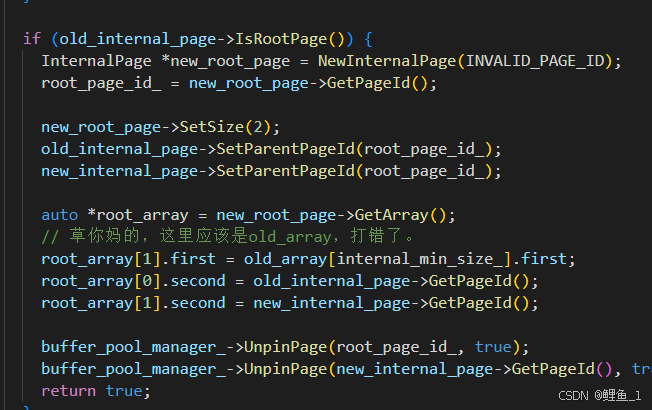
针对上述加粗红色字体的情况,2023 fall版本提出了一种优化方案,即:Task #1 - Read/Write Page Guards:
(以下阐述来自课程官方)
“FetchPage 和 NewPage 函数返回指向已固定页面的指针。固定机制可确保在页面上不再有读取和写入之前不会逐出页面。要指示内存中不再需要该页,程序员必须手动调用 UnpinPage。如果程序员忘记调用 UnpinPage,则永远不会将页面从缓冲池中逐出。由于缓冲池使用较少的帧数运行,因此将有更多的页面换入和换出磁盘。不仅性能受到影响,而且 bug 也很难被发现。您将实现 BasicPageGuard,它存储指向 BufferPoolManager 和 Page 对象的指针。Page Guard 确保在相应的 Page 对象超出范围时立即调用 UnpinPage。”
所以可见,如果我们完成了Task #1 ,并在Task #3的实现中严格遵守并借助Task #1 中的三种不同类型的Page Guard:BasicPageGuard、ReadPageGuard和WritePageGuard,那么Task #4 - Concurrency Control的完成是水到渠成,不需要做额外工作的:
“We recommend that you complete this task by using the FetchPageWrite or FetchPageRead buffer pool API, depending on whether you want to access a page with read or write privileges. Then modify your implementation to grab and release read and write latches as necessary to implement the latch crabbing algorithm."
好,那么废话少说,我们直接进入Task #1 - Read/Write Page Guards:
Task #1 - Read/Write Page Guards:
在page.cpp文件里主要实现以下三个类的各种“类定义”函数,即构造函数,移动构造函数,移动操作符,赋值操作符等等,和c++课程当时的实验课要做的东西差不多,写起来也很轻松,具体思路如下,基本上都是官网以及头文件里提供的思路:
-
BasicPageGuard
BasicPageGuard是基础的页面保护器(page_guard)(很尬的直译...),用于维护对BufferPoolManager和Page对象的指针。在其生命周期结束时,它会自动调用UnpinPage来解除页面的固定状态,确保页面可以在不再需要时被缓冲池驱逐。- 构造函数与移动操作符:实现了移动构造函数和移动赋值运算符,能够将其他
BasicPageGuard对象的内容转移到当前实例,同时保证原实例的指针置空。 - Drop()函数:用于解除页面的固定状态,调用
UnpinPage方法,确保不会因忘记解除固定而导致页面一直滞留在缓冲池中。 - UpgradeRead与UpgradeWrite:分别升级为
ReadPageGuard或WritePageGuard,从而启用读写锁定保护,在多线程环境中确保读写的正确性。
- 构造函数与移动操作符:实现了移动构造函数和移动赋值运算符,能够将其他
-
ReadPageGuard
ReadPageGuard专门用于处理页面的读操作,并在生命周期结束时自动解锁页面的读锁(RUnlatch)。- 移动构造函数与赋值操作符:允许从其他
ReadPageGuard对象中转移内容,并确保源对象的状态被重置。 - Drop()函数:自动解除页面的读锁,确保在
ReadPageGuard对象销毁时释放读锁。
- 移动构造函数与赋值操作符:允许从其他
-
WritePageGuard
WritePageGuard用于页面的写操作,具有自动管理写锁的功能。在销毁时调用Drop来解除写锁,同时将页面标记为已修改(is_dirty_设为true)。- 移动构造函数与赋值操作符:允许从其他
WritePageGuard对象转移内容。 - Drop()函数:在生命周期结束时自动解除页面的写锁,并设置脏标志。
- 移动构造函数与赋值操作符:允许从其他
-
缓冲池管理器(Buffer Pool Manager)
新增的FetchPageBasic、FetchPageRead和FetchPageWrite函数,分别返回BasicPageGuard、ReadPageGuard和WritePageGuard,以简化页面的读写锁定管理:- FetchPageBasic:提供基础的页面获取保护,不涉及锁定操作。
- FetchPageRead与FetchPageWrite:分别在返回的页面上加读锁和写锁,保证在多线程环境中页面的读写操作安全。
- NewPageGuarded:创建并返回一个新页面的
BasicPageGuard。
需要注意的点:
值得注意的是:
1.WritePageGuard::Drop() 和 ReadPageGuard::Drop() 函数里要进行解锁操作,这一点和FetchPageRead/Write 里面的上锁操作刚好对应。后面在Task#3中进行插入删除查找等操作时,由于是索引结构是三级可拓展的,就需要我们谨慎小心的层层剥笋式的先从Hash Table Header Page经由 Hash Table Directory Page最后到达Hash Table Bucket Page ,再进行各种操作。而这整个过程,都得保证线程安全,那么就全依赖于task1实现的基础。
上面这些我在刚开始写Task#1时并没有理解,当时就按注释一个个局部的完成构造函数巴拉巴拉的,后面做Task3才理解了,但好在Task#1难度不大,仔细研读page.h以及page_guard.h的话会很好实现。
2.前面写代码一定要谨慎小心,每一个函数都要写仔细,包括P1如果有瑕疵,也要及时更改完善,不然攒到最后写完P2在线提交的时候,一下子涉及二十几个文件,DEBUG难度十分之大,坐牢感十分之强!

















 1816
1816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









