










 本系统通过爬取美团上的茶饮店铺数据,运用Python进行数据抓取,并利用Echarts和WordCloud进行数据可视化,同时采用贝叶斯估计推荐算法提供店铺评分排名。
本系统通过爬取美团上的茶饮店铺数据,运用Python进行数据抓取,并利用Echarts和WordCloud进行数据可视化,同时采用贝叶斯估计推荐算法提供店铺评分排名。
本项目为茶饮数据分析系统,可大致分为三个模块:数据爬取、数据可视化以及数据推荐。首先使用Python编写爬虫程序爬取某团的茶饮数据,然后将这些数据进行可视化,同时利用贝叶斯估计推荐算法得出综合评分Top10的茶饮店铺,最终将结果呈现在Web端,可供用户访问浏览。
- 先看一下项目

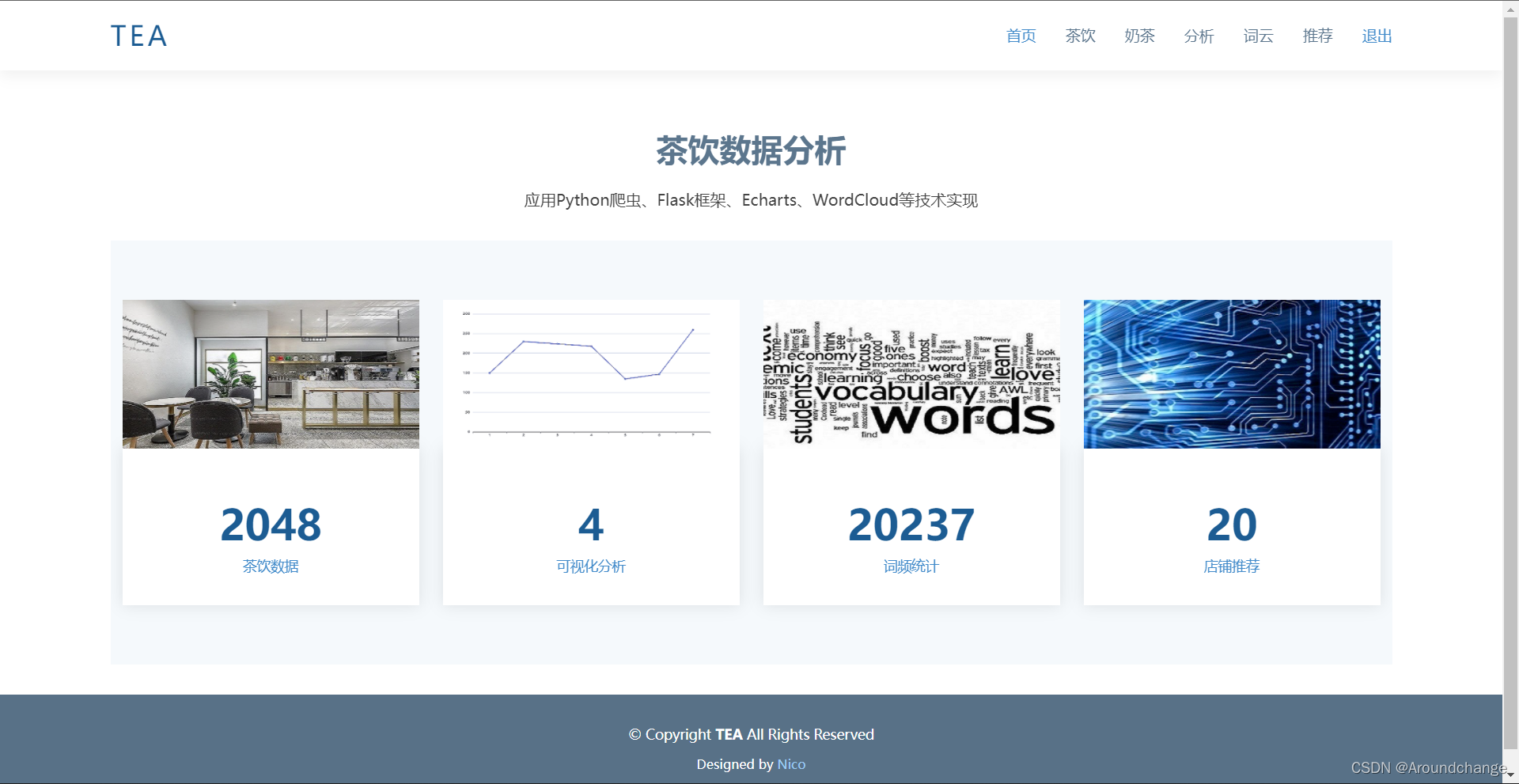
数据爬取
- 使用Python编写爬虫程序,获取某团有关茶饮店铺的店铺名称、店铺详情、店铺评分、评价人数、人均消费、店铺地址等数据。
import requests # 数据请求模块
import pprint # 格式化输入模块
import csv # 保存csv文件
import re # 正则表达式,进行文字匹配
import time # 引入时间模块,用来控制请求频率
# f = open('milk.csv', mode='a', encoding='utf_8_sig', newline='')
# csv_writer = csv.DictWriter(f, fieldnames=[
# '店铺名称',
# '店铺详情',
# '店铺评分',
# '评价人数',
# '人均消费',
# '店铺地址',
# ])
# csv_writer.writeheader() # 写入表头
# # 店铺名称
# findTitle = re.compile(r'<span class="title">(.*)</span>')
# # 店铺详情
# findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,表示规则(字符串的模式)
# # 店铺评分
# findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# # 评价人数
# findJuge = re.compile(r'<span>(\d*)人评价</span>')
for page in range(0, 1024, 32):
# 发送请求,对于店铺数据包发送请求
url = "https://apimobile.meituan.com/group/v4/poi/pcsearch/10"
time.sleep(3)
data = {
'uuid': '30235d22f37442e1a33a.1641554598.1.0.0',
'userid': '2226566483',
'limit': '32',
'offset': page,
'cateId': '21329',
'q': '奶茶',
't,oken': '',
'areaId': -1
}
headers= {
'Referer': 'https://sh.meituan.com/', # 防盗链,告诉服务器发送请求的url地址是从哪里跳转过来的
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
response = requests.get(url=url, params=data, headers=headers)
# print(response.json()) # 获取json字典数据
# pprint.pprint(response.json())
searchResult = response.json()['data']['searchResult'] # 键值对提取数据
# print(searchResult)
for items in searchResult: # 遍历列表,逐一提取元素
# pprint.pprint(items)
shop_id = items['id']
shop_url = f'https://www.meituan.com/meishi/{shop_id}/'
data = {
'店铺名称': items['title'],
'店铺详情': shop_url,
'店铺评分': items['avgscore'],
'评价人数': items['comments'],
'人均消费': items['avgprice'],
'店铺地址': items['areaname'],
}
# csv_writer.writerow(data) # 保存数据
print(data)
# f.close()
print("爬取完毕!")
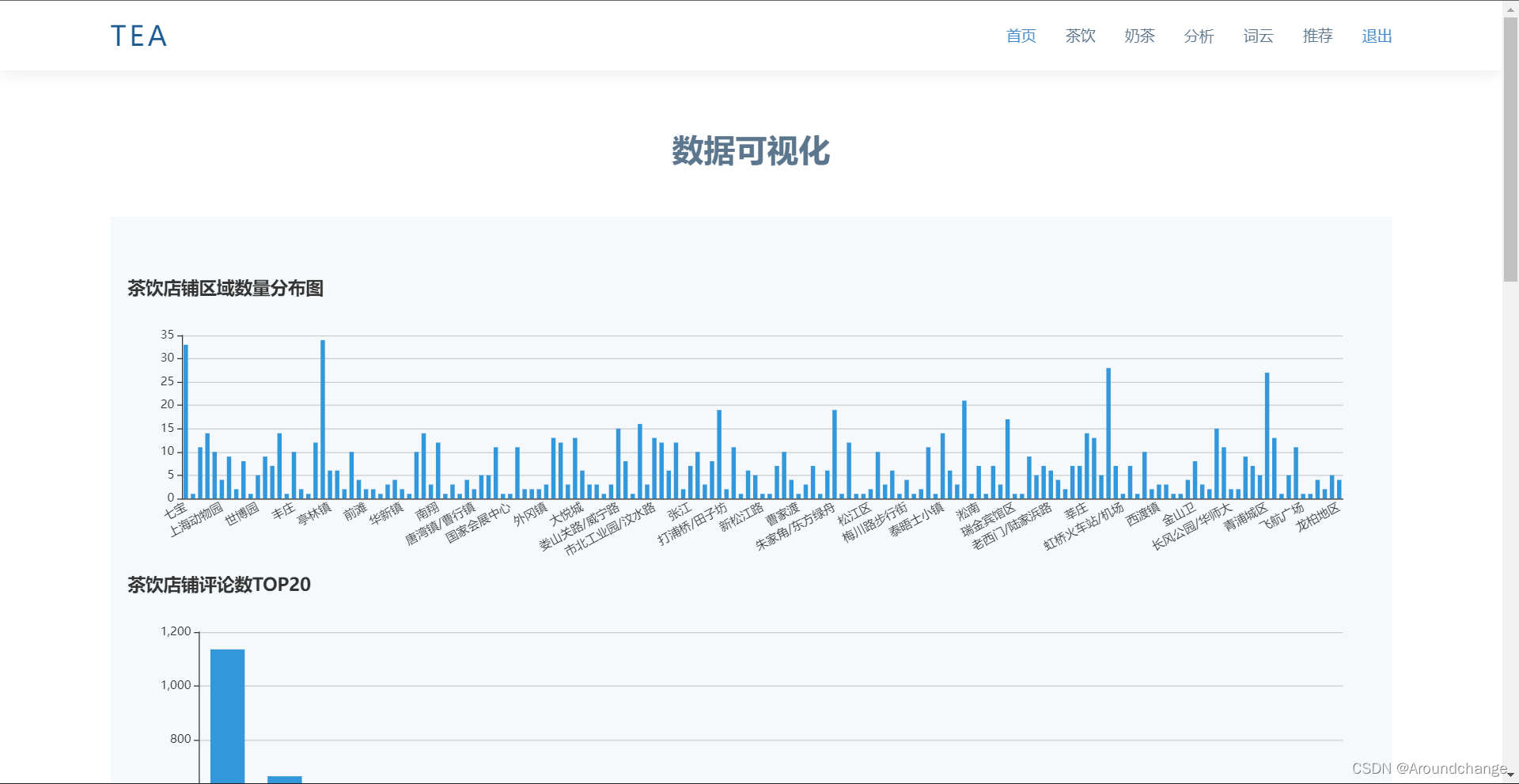
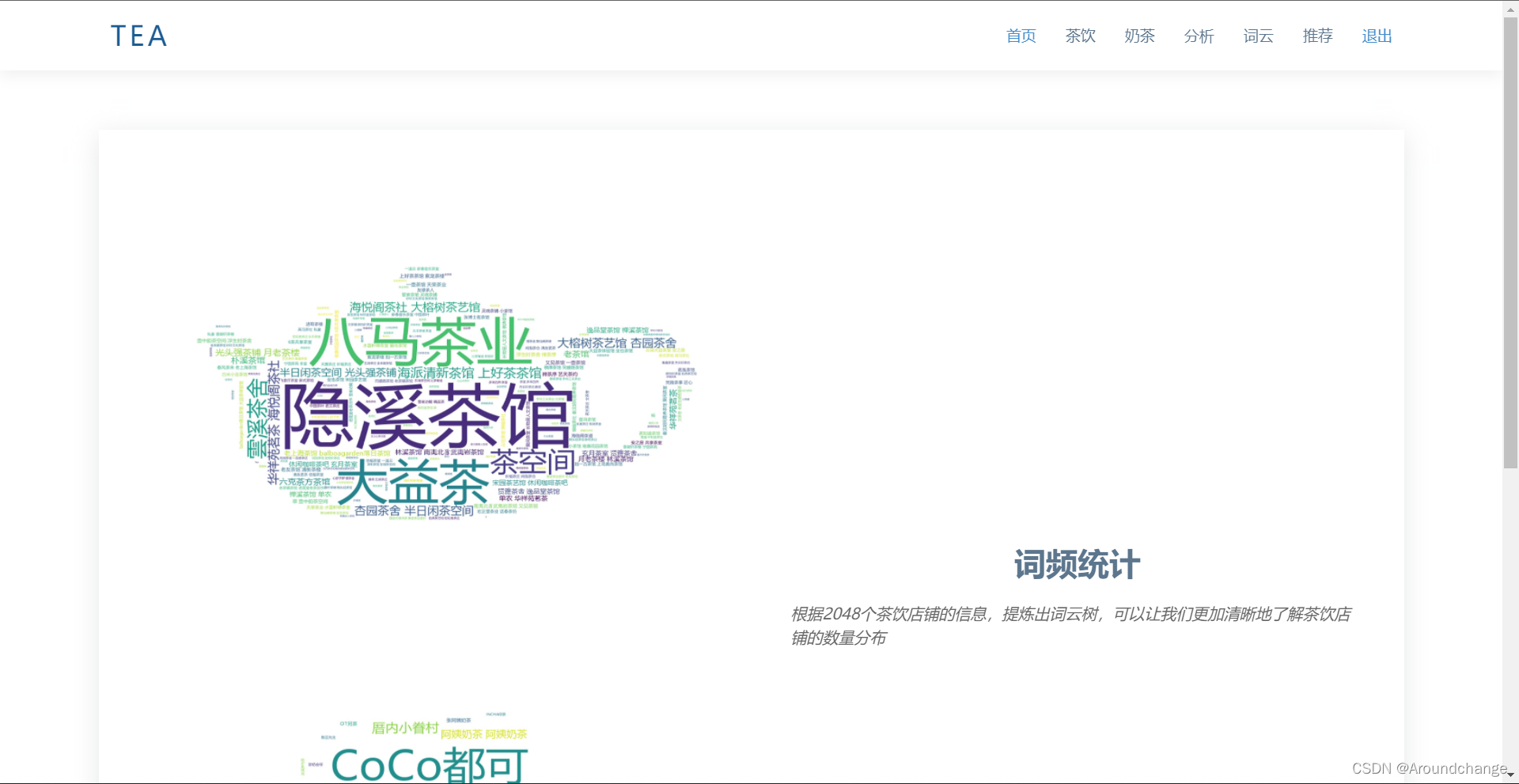
数据可视化
- 茶饮数据可视化用Echarts、WordCloud实现,包含区域茶饮店铺数量分布、茶饮店铺评论数Top20、茶饮店铺词频统计分析等。
import jieba # 分词,词云显示中文
from matplotlib import pyplot as plt # 绘图,数据可视化
from wordcloud import WordCloud, STOPWORDS # 词云
from PIL import Image # 图像处理
import numpy as np # 矩阵运算
import sqlite3 # 数据库
import pymysql
import pandas as pd
# 准备词云所需要的文字(词)
con = pymysql.connect(host='localhost',
user='root',
p,assword='',
database='movie_demo')
cur = con.cursor()
sql = 'select 店铺名称 from milk'
# data = cur.execute(sql)
df = pd.read_sql('select 店铺名称 from milk', con)
text = ""
df['店铺名称'] = df['店铺名称'].str.split("(").str[0]
print(df['店铺名称'].tolist())
# for item in range(len(data)):
# text = text + item[0]
# # print(item[0])
# # print(text)
# cur.close()
# con.close()
#
# cut = jieba.cut(text)
string = ' '.join(df['店铺名称'].tolist())
# print(len(string))
stopwords = STOPWORDS
stopwords.add('茶馆')
stopwords.add('棋牌')
# stopwords.add('我')
# stopwords.add('人')
# stopwords.add('都')
# stopwords.add('了')
# stopwords.add('是')
img = Image.open(r'.\static\assets\img\tea.jpg') # 打开遮罩图片
img_array = np.array(img) # 将图片转换为数组
wc = WordCloud(
# stopwords=stopwords,
background_color='white',
mask=img_array, font_path="msyh.ttc" # 字体所在位置:C:\Windows\Fonts
)
wc.generate_from_text(string)
# 绘制图片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off') # 是否显示坐标轴
plt.show() # 显示生成的词云图片
# 输出词云图片到文件
# plt.savefig(r'.\static\assets\img\3.jpg', dpi=500)
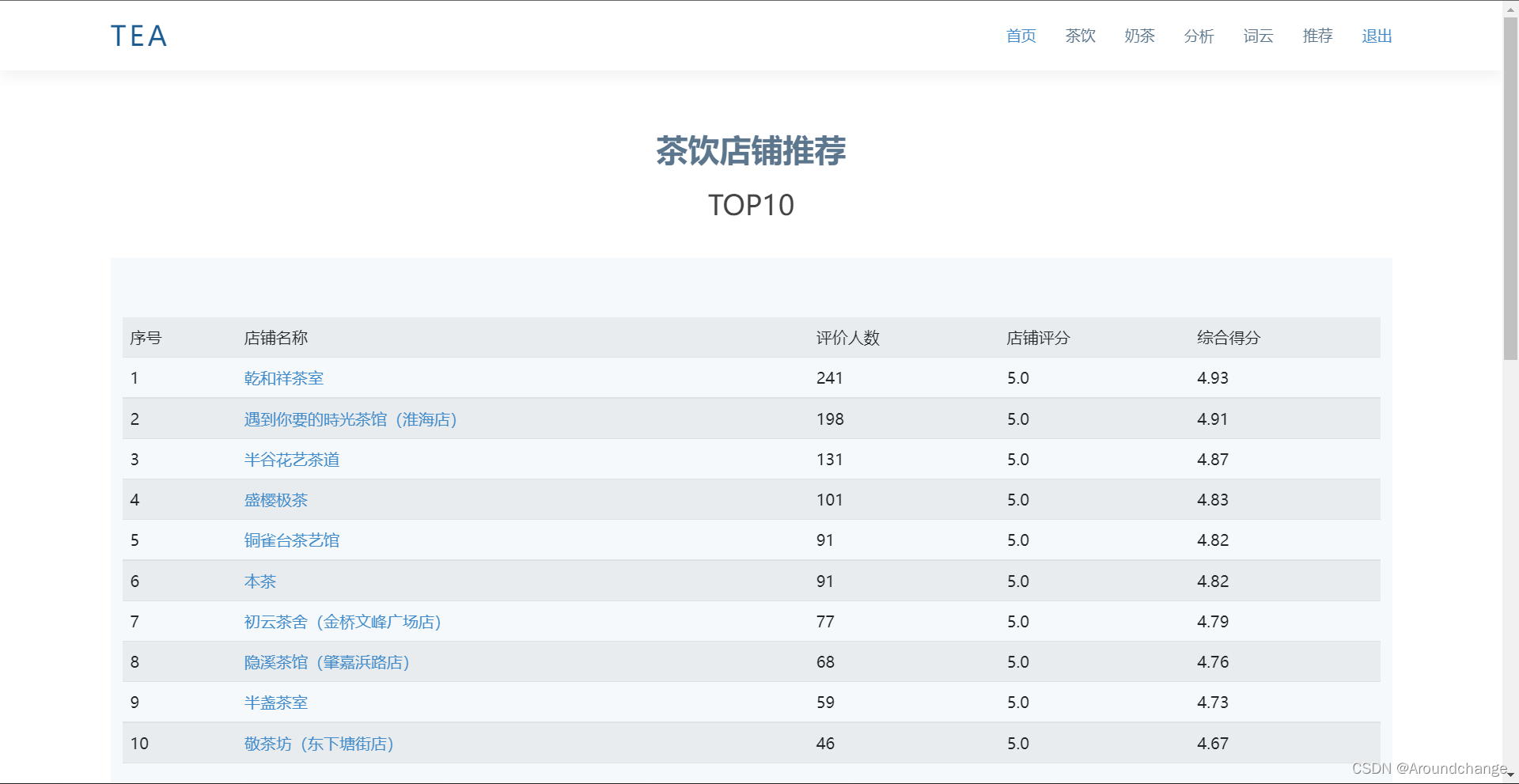
数据推荐
- 基于贝叶斯估计,利用贝叶斯估计推荐算法得出综合评分Top10的茶饮店铺。贝叶斯估计的基本思维基于的是贝叶斯定理,为了得到新概率,要把先前的先验概率与新的证据结合起来。当人们计算假设的概率时,可以用贝叶斯估计的方法。这个方法会用到之前假设的先验概率,然后,可以通过这些假设的先验概率,从而观测到数据本身以及不同数据所对应的概率。贝叶斯定理的表达式可以写成以下公式:
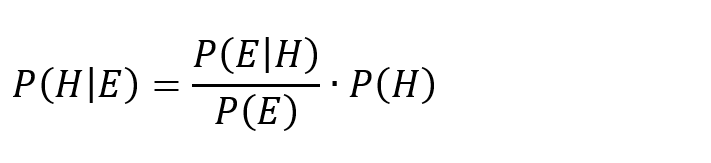
- 其中,公式里面的H代表的是假说,其概率可能会遭到实验所产生数据的影响。E为实验所产生的数据,实验数据对应的是新的数据,即未用于计算先验概率的数据。先验概率为P(H),在观察到数据E以前,假说H的机率。P(H|E)为后验概率,是在给定一个实验研究数据E之后,假说H的机率,是希望可以求得的资讯,也就是在有中国目前通过实验进行数据时,假说H的几率。P(E|H)是假设H成立时发生E的概率。当H不变时,这是E的函数,也称为似然函数,表示假设与给定假设的证据之间的相容程度。似然函数为实验过程中数据E的函数,然而后验概率则为假说H的函数。有的时候也会称P(E)为边缘似然率。这个系数对所有可能的假设都是常数,所以它不用来确定不同假设的相对概率。贝叶斯估计最关键的点是可以通过利用贝斯定理进行结合新的证据及以前的先验机率,来得到新的机率。贝叶斯估计能够迭代使用:观察到一些证据后得出的后验概率可以作为先验概率,而后按照新的证据得到新的后验概率。所以,贝叶斯定理能够应用于许多不同的证明,无论它们是否同时出现,这个过程称为贝叶斯更新。基于贝叶斯估计原理,茶饮店铺推荐算法公式如下:
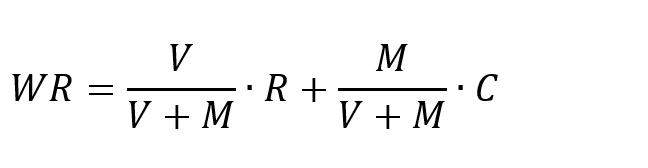
- 其中,V代表的是某一个茶饮店铺参与评价的消费者数量。M则是筛选出来的消费者评价个数的阈值,即如果某家店铺评价的个数低于该阈值,则该茶饮店铺将被忽略。该店铺的评分为R,所有茶饮店铺评分的均值用C表示。M的取值能够按照实验的目标自由地选取,在本系统的模型中,采用的是90分位值,也就是只选取评价人数为前10%的茶饮店铺进行分析推荐。
import pandas as pd
from numpy import *
import codecs
import sqlite3 as sql
tea = pd.io.parsers.read_csv('D:/TeaDataAnalysis/tea.csv')
tea.head()
tea1 = tea.loc[:, ['店铺名称', '店铺详情', '评价人数', '店铺评分']]
tea1.head()
C = tea1['店铺评分'].mean() # 所有店铺评分的均值
print("茶饮店铺评分均值:%f分" % C)
M = tea1['评价人数'].quantile(0.9) # 筛选的评价顾客人数阈值,也就是如果某个店铺评价的个数低于阈值,则该店铺将被忽略不计
print("茶饮店铺评价人数阈值:%d" % M) # M的取值可以根据需求自由选取,在下面的模型中,采用90分位值,也就是只选取评价人数为前10%的店铺进行分析
q_tea1 = tea1.copy().loc[tea1['评价人数'] > M]
q_tea1.shape
def weighted_rating(x, M=M, C=C):
V = x['评价人数'] # 某店铺参与评价的顾客人数
R = x['店铺评分'] # 该店铺的评分
return round((V / (V + M) * R) + (M / (V + M) * C),2)
q_tea1['综合得分'] = q_tea1.apply(weighted_rating, axis=1)
q_tea1 = q_tea1.sort_values('综合得分', ascending=False)
df = q_tea1.head(10)
list = []
for i in range(10):
list.append(i+1)
# print (list)
df.insert(0,'id',list)
# df.to_csv('recommend-tea.csv', encoding='utf-8', index=False)
print(df)
- 最后加入用户注册登录功能,方便用户访问浏览。同时加入管理员功能,对用户进行相应的管理,再采用Flask应用框架将数据分析的结果呈现在Web端。
源码获取
- QQ 2985983009

















 3200
3200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









