






 文章讲述了在多人使用服务器时,因cudnn版本从8.5.0更新到8.0.5导致的torch报错问题。作者提供了检测torch和CUDA版本的方法,并介绍了如何检查cudnn可用性以及修复此问题的步骤,涉及NVIDIA官网资源和文件操作。
文章讲述了在多人使用服务器时,因cudnn版本从8.5.0更新到8.0.5导致的torch报错问题。作者提供了检测torch和CUDA版本的方法,并介绍了如何检查cudnn可用性以及修复此问题的步骤,涉及NVIDIA官网资源和文件操作。
摘要:在接着Omnipose项目后,多人使用服务器的条件下,有人更改了cudnn的版本由8.5.0换为了8.0.5导致torch报错,这个错误很难查出,因为测试cuda与torch、torchision、torchaudio版本的代码全部正常。现在提出一种检测方法。
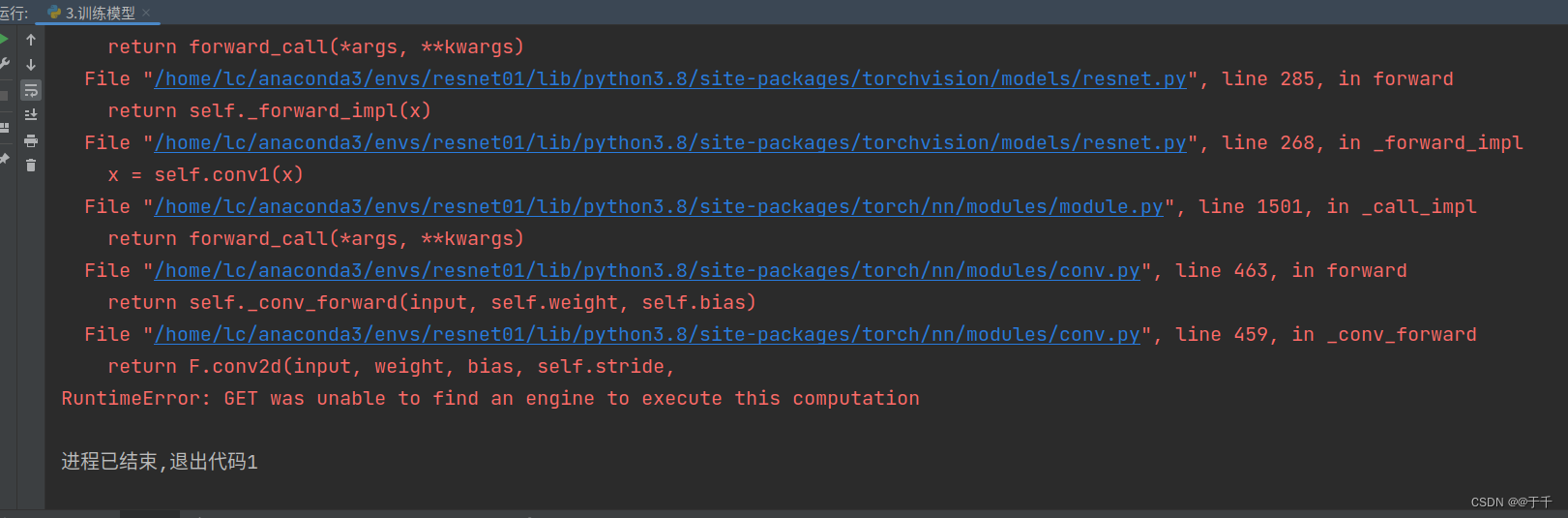
【1】报错内容如下:网上很多人说是torch与cuda版本不兼容
【2】检测torch和cuda是否能用,显示能用
import torch
print(torch.__version__)
print(torch.cuda.is_available())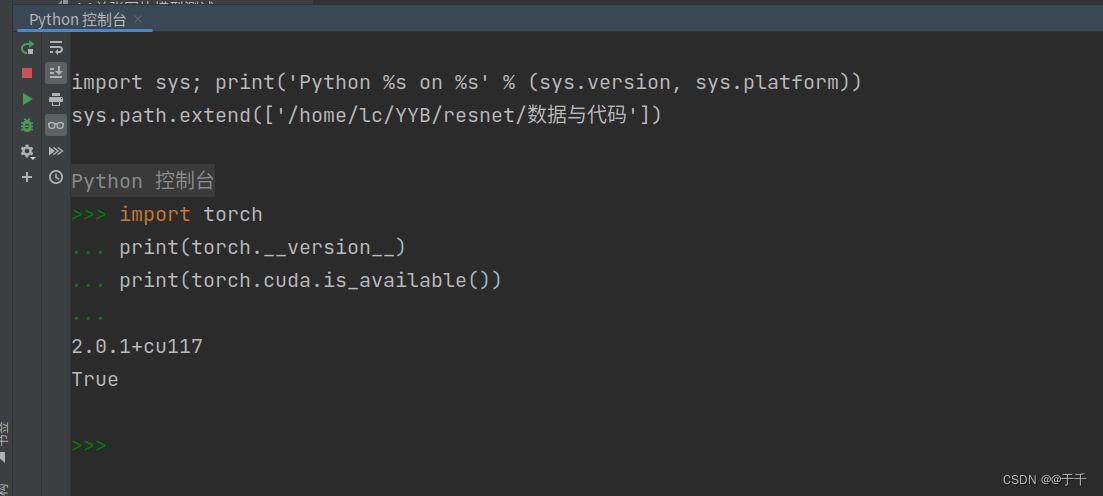
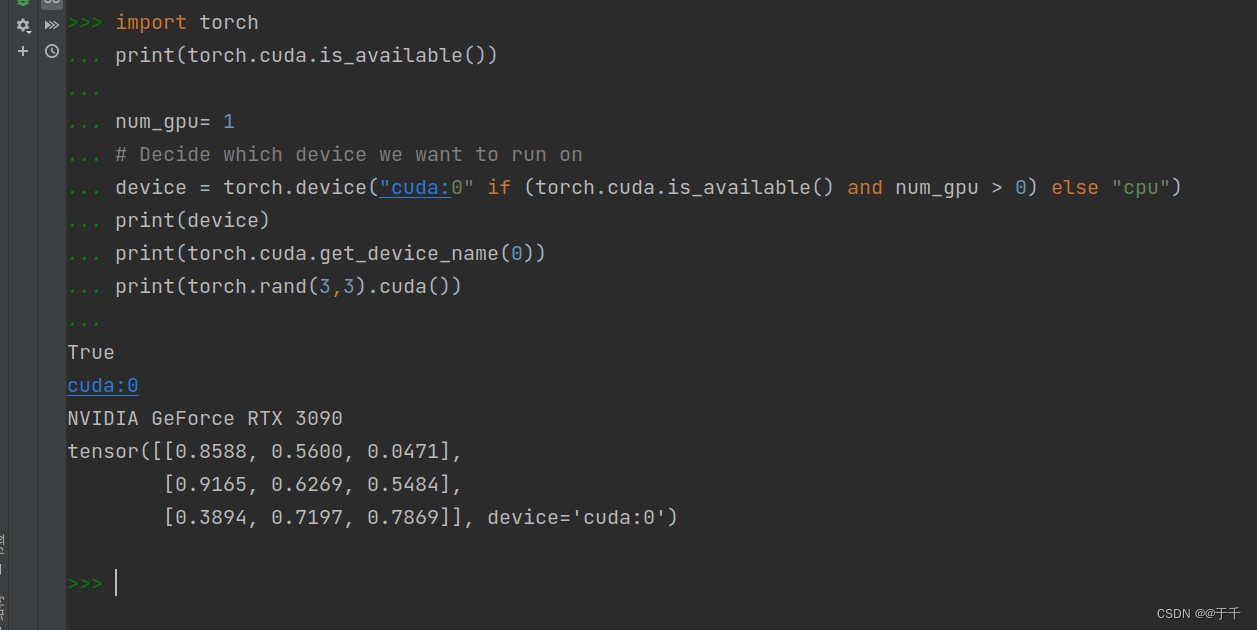
【3】试试更细节的信息,更没有问题,这说明torch与cuda版本是没有问题的
import torch
print(torch.cuda.is_available())
num_gpu= 1
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and num_gpu > 0) else "cpu")
print(device)
print(torch.cuda.get_device_name(0))
print(torch.rand(3,3).cuda())
【4】检查cudnn是否可用
print(torch.backends.cudnn.version())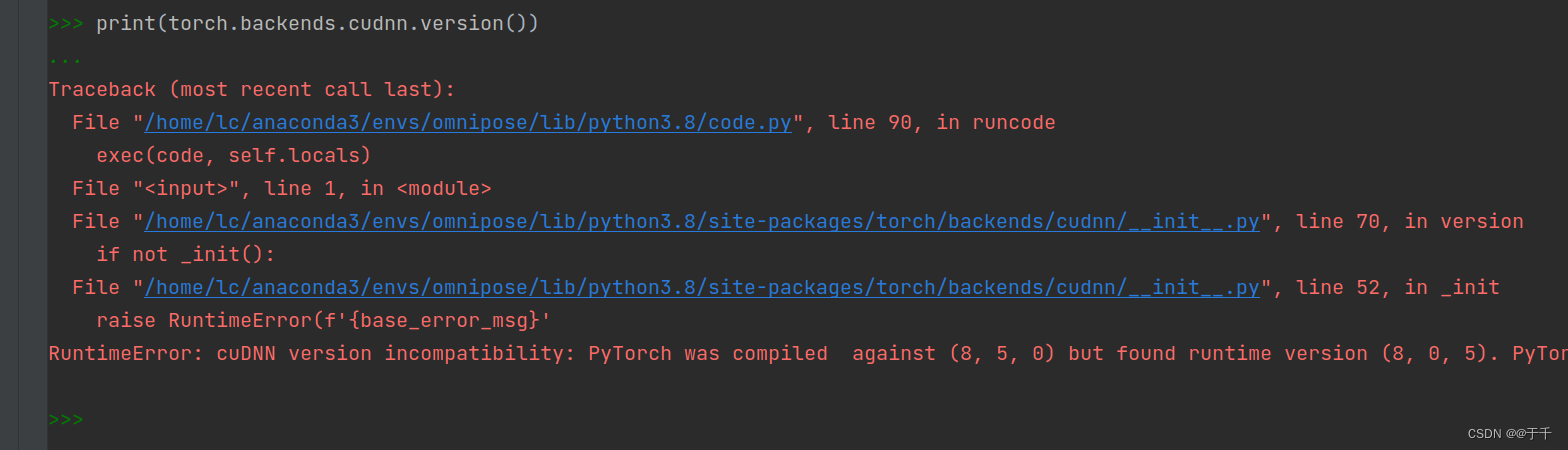 运行时的错误翻译如下图:
运行时的错误翻译如下图:
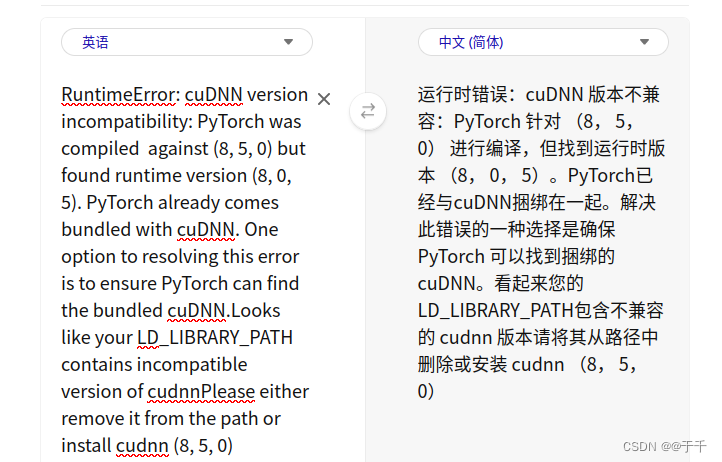
【5】修复问题,下载cudnn8.5.0
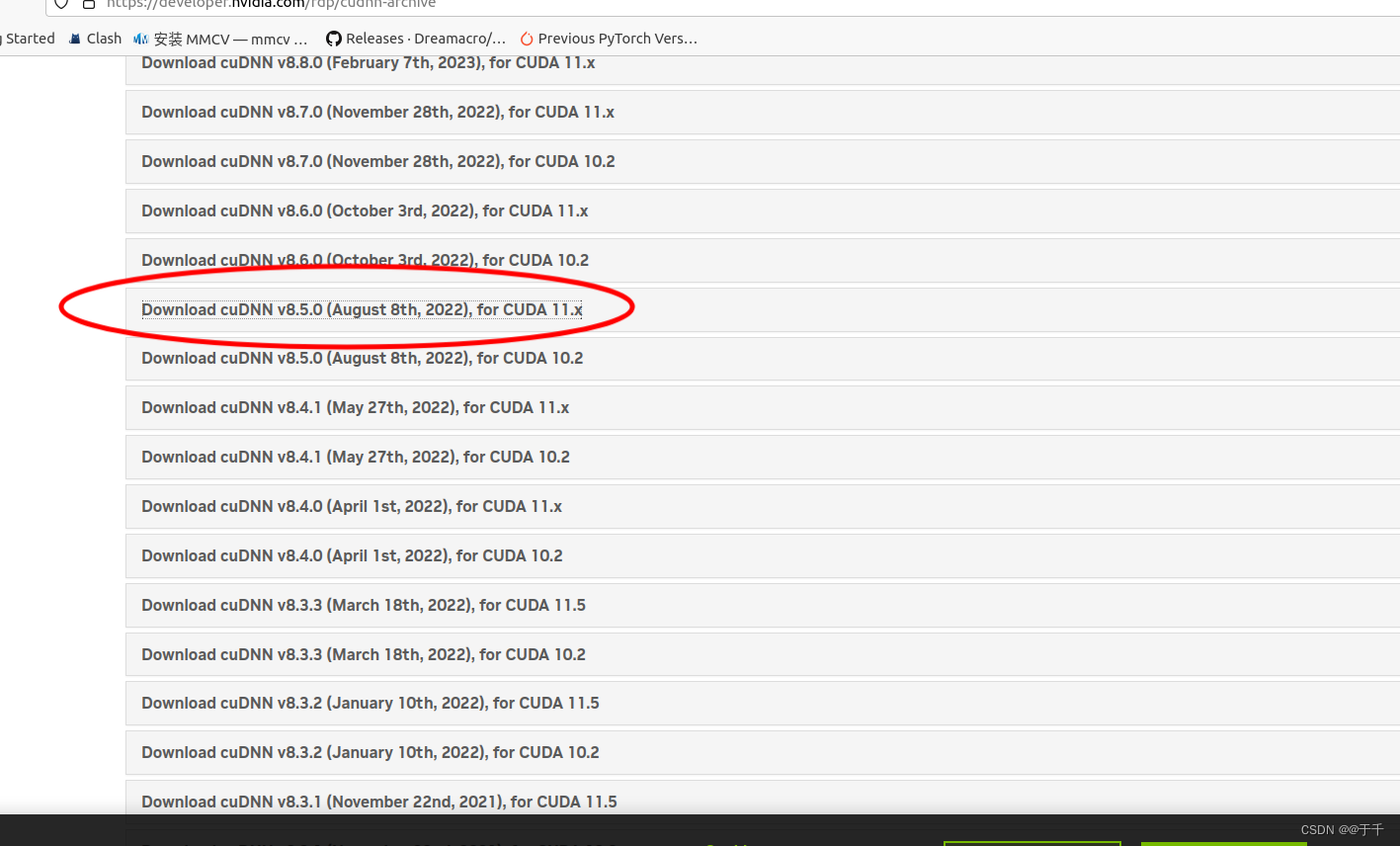 下载后解压缩,进入到解压缩的文件下里面,然后在当前文件夹下打开终端输入以下:
下载后解压缩,进入到解压缩的文件下里面,然后在当前文件夹下打开终端输入以下:
sudo cp include/cudnn.h /usr/local/cuda/includesudo cp lib/libcudnn* /usr/local/cuda/lib64sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*再次运行,解决问题。

















 3830
3830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









