






前言
太卷啦,太卷啦,视觉太卷啦,赶紧跑路吧~_~
介绍DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation论文方法,解释原理,本文不是机械翻译,而是尝试讲解方法原理
论文地址:https://arxiv.org/abs/2309.16653
github地址:https://github.com/dreamgaussian/dreamgaussian?tab=readme-ov-file
项目地址(可直接运行):https://huggingface.co/spaces/jiawei011/dreamgaussian
如有不对,欢迎讨论
一、基本介绍
本文提出了用于3D生成的DreamGaussian方法,仅依靠一张图片或者一段文字描述,就可以在短时间内生成高质量3D模型。3D生成的研究可以分为两大类:仅限推理的三维原生方法(One-2-3-45: Liu et al.,2023a; Shap-e:Jun & Nichol,2023)和基于优化的二维提升方法(Zero-1-to-3:Liu et al.,2023b)。
而DreamGaussian在生成质量和速度之间取得了更好的平衡,达到了与基于优化的的二维提升方法相当的质量,但仅比仅限推理的三维原生方法略慢。
具体来说,DreamGaussian 在DreamFusion的基础上,通过将三维高斯 splatting 应用到生成设置中,大大提高了3D内容的生成效率。可以在仅2分钟内从单个视图图像中生成具有显式网格和纹理贴图的逼真3D物体。
二、方法原理
1.DreamGaussian方法
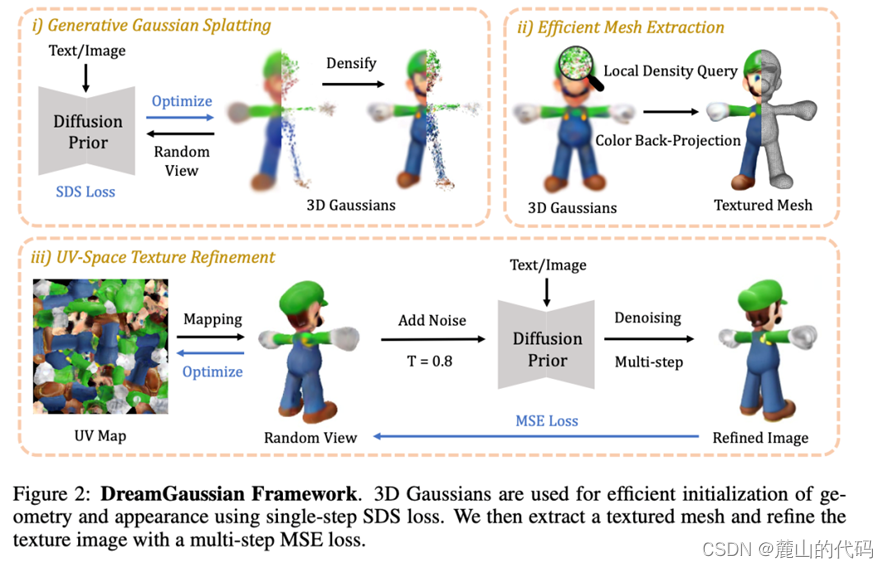
(i)DreamGaussian 应用了DreamFusion提出的分数蒸馏抽样(SDS)解决了需要大量三维数据训练的限制,同时使用了3D Gaussian Splatting的方法,更快更好的生成3D模型。 具体来说,给定一段文字描述或一张图片,输入到预训练的diffusion模型中,开始时使用较少的Gaussians,在预定机位渲染图片,将该图片和高斯噪声混合生成加噪图片,然后将加噪图片也输入到预训练的diffusion模型中,生成去噪的图片,然后和前面加噪图片做比较,得到加噪图片到去噪图片去掉的噪声。(如果难以理解,先看下文2.分数蒸馏抽样(SDS))
将该噪声和前面的与预定机位混合的高斯噪声的分布做比较来进行SDS loss的优化,迭代训练3D Gaussian Splatting的参数,让其生成的图像更符合预训练的diffusion模型输出的图像分布。
通过Densify逐渐在SDS 训练过程增加3D Gaussians的数量和密度,可以更准确地表示和捕捉生成的细节和结构。这样可以提高生成的质量和细节,并减少生成结果的模糊程度。
(ii)Efficient Mesh Extraction是从生成的3D Gaussians中提取出带有纹理的多边形网格的方法。具体方法如下:
- 局部密度查询(Local Density Query):首先将3D空间划分为多个局部块,然后剔除中心位于每个局部块外部的高斯函数。这样可以减少每个块中需要查询的高斯函数的总数。在每个块内部查询一个密集网格,计算每个网格位置的加权不透明度。通过Marching Cubes算法,根据经验阈值提取网格表面。
- 颜色反投影(Color Back-projection):根据网格的几何信息,将渲染的RGB图像反投影到网格表面,并将其作为纹理。首先对网格的UV坐标进行展开,初始化一个空的纹理图像。然后根据UV坐标将渲染的RGB图像像素反投影到纹理图像上。通过这两个步骤,可以将生成的3D Gaussians转换为带有纹理的多边形网格,并进一步优化纹理。
(iii) UV-Space Texture Refinement是纹理细化的方法, 它通过从生成的3D Gaussians中提取细节纹理的多边形网格,在UV空间中进行纹理细化,并使用多步MSE损失来细化纹理图像。与直接应用潜空间SDS损失的第一阶段相比,该方法通过在图像空间进行监督,避免了在UV图上产生过饱和的块状伪影。相比之前的纹理细化方法,该方法在保持高效率的同时实现了更好的保真度。
UV map是一种用于将2D纹理映射到3D模型表面的技术。它是一种二维坐标系统,与3D模型的顶点相对应,用于确定纹理在模型表面的位置和方向。
2.分数蒸馏抽样(SDS)
引用一张微信公众号上讲解DreamFusion的图片
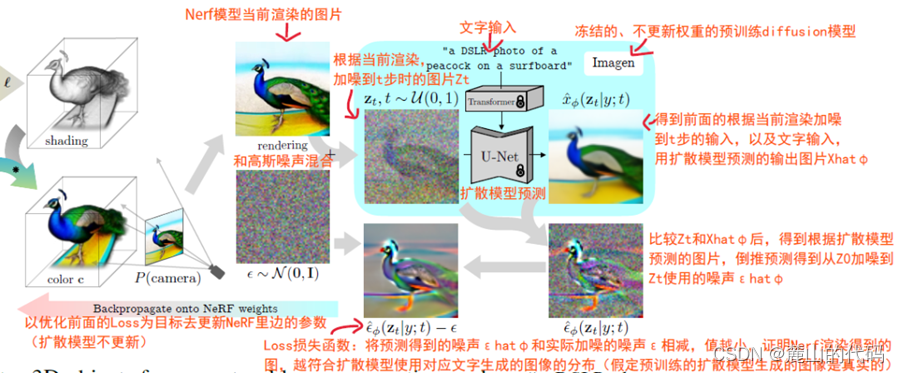
DreamFusion (DreamFusion: Text-to-3D using 2D Diffusion)提出分数蒸馏抽样(SDS)解决三维数据限制(也就是不需要辣莫多三维模型训练集),通过提取三维几何和外观从强大的2D扩散模型,激发了最近的2D提升方法的发展。为了应对SDS监督引起的不一致和模糊性,通常采用NeRF建模丰富的三维信息的能力。但由于NeRF渲染费时,优化需要数小时。用于加速NeRF的 occupancy pruning 技术在模糊SDS损失的监督下,在生成环境中是无效的。
于是便有了DreamGaussian把NeRF替换成3D Gaussian Splatting的改进,但SDS的原理依然很先进,下面结合上图解释一下SDS原理,以下讲解来源于微信公众号。
先用NeRF在预定的机位渲染图片,然后将这张图片和高斯分布ε~Ν(0,Ι)混合,就得到了一张加噪图片Zt 。 然后,将这张加噪图片和文字信息y(图中案例是“a DSLR photo of a peacock on a surfboard”,即冲浪板上的孔雀)一起,输入到已经训练好的Imagn模型中,得到去噪后的图片Xθ(Zt|y;t)。 此时,这张Xθ并非直接使用,而是和前面的加噪图片Zt做比较,就可以得到,Imagen在生成Xθ的过程中,从前面的加噪图Zt上去掉的预测噪声εθ(Zt|y;t)。
这时,因为我们前面增加的噪声是已知的,即ε,那么我们就可以将预测的噪声和实际增加的噪声做比较。 这里一个主要推论是,如果NeRF生成的图像的分布,和Imagen根据文字输入生成的图像的分布是完全一致的,那么我们增加的噪声和Imagn在去噪时候将被去除的预测噪声ε^θ(Zt|y;t),也应该完全一致。
于是,我们就可以以最小化 || ε^θ(Zt|y;t) - ε || 为目标,在冻结Imagen模型参数的情况下,去迭代训练NeRF的参数,让其生成的图像越来越符合Imagne根据文字预测的图像分布。 除此之外,DreamFusion中还用了对NeRF渲染的图片做各种增强的方法。
简单来说,就是预训练Imagen模型知道孔雀长啥样,我从你NeRF刚开始随机机位渲染的某一个方向上的孔雀图片看一下,哎呦你这个不像,还需要训练,那如何训练呢,设
A是NeRF机位的图片,
B是加的高斯噪声,
C是A+B也就是把A加了B的噪声后的图片,即A+B=C
D是预训练Imagen模型减去的噪声,
E是C经过预训练Imagen模型降噪(减去D)生成的真实孔雀图片,即C-D=E
也就是A+B=D+E
SDS想办法让B==D,如果B和D越接近,则A和E越接近。
总结
文生3D是一个炙热的赛道,DreamGaussian就是一群大佬在DreamFusion和3D Gaussian Splatting的基础上设计出的方法,在最近的研究中表现很好,各位童鞋有能力就紧跟三维重建时势,设计自己的方法,能力不大ok就学会使用大佬们的方法就可以啦















 534
534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









