







辐射神经场算法——Instant-NGP / Mipi-NeRF 360 / 3D Gaussian Splatting
辐射神经场算法——NeRF算法详解
辐射神经场算法——Wild-NeRF / Mipi-NeRF / BARF / NSVF / Semantic-NeRF / DSNeRF
上面两篇博客是之前对NeRF相关算法的一些简单总结,离上一次工作中接触到NeRF相关的算法已经过去一年多的时间,最近大火的3D Gaussian Splatting让我忍不住想又跟进下这个方向的工作,我另外挑了两个比较有代表性的工作,一个是速度上SOAT的方法Instant-NGP,一个是效果上SOTA的方法Mipi NeRF 360,最后是3D Gaussian Splatting
1. Instant-NGP
Instant-NGP是2022年NVIDIA发布的一个项目,项目全称为《Instant Neural Graphics Primitives with a Multiresolution Hash Encoding》煤其主要贡献是通过Multiresolution Hash Encoding将NeRF的训练速度从小时级别缩短到秒级别。
在之前做NeRF加速的工作中,有一个经典的思路在所要表达的空间中构建Voxel,并在每个Voxel的节点上存储可训练的特征,在训练过程中同时更新MLP和Voxel节点特征,在推理过程中则使用先对Voxel节点特征进行插值,然后将插值后的特征再通过MLP进行推理。这样的好处可以使用更加局部的Voxel节点特征来表达空间,可以加速训练收敛,并且Voxel的分辨率越高,表达效果越好,但是模型占用的显存也越高,为此很多方法提出了Coarse-To-Fine的思路(例如NSVF和Plenoxels)或者Octree的数据结构(Plenoctree)来解决表达效果和显存占用的Trade Off问题,而本文提出的Multiresolution Hash Encoding也是为了解决该问题,但相对于前者,本文的方法更加优雅效果也更好,具体如下:
1. MultiResolution Hash Encoding
Multiresolution Hash Encoding的流程如下图所示:
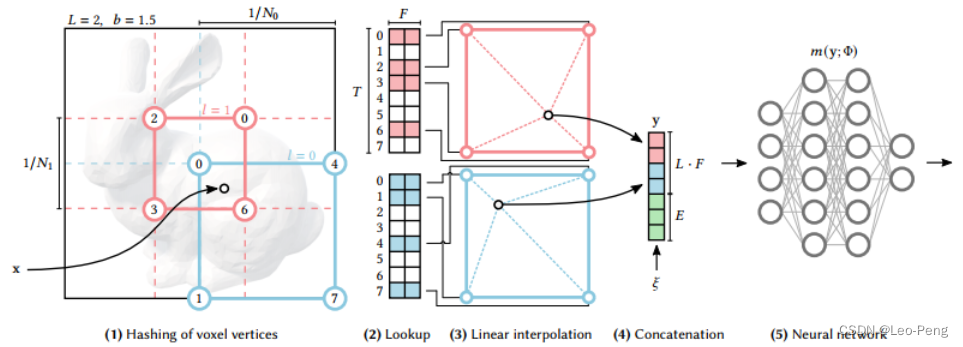
我们先定义一个 L L L层分辨率的 d d d维网格,在上图中 L L L为2, d d d为2(在实际使用的Multiresolution Hash Encoding中 L L L为16, d d d为3),分别由蓝色和红色表示,红色网格的分辨率为 1 / N 0 1 / N_0 1/N0(较低分辨率),蓝色网格的分辨率为 1 / N 1 1 / N_1 1/N1(较高分辨率),每个网格有四个顶点,那么每层网格的顶点数为 V = ( N l + 1 ) d V=\left(N_l+1\right)^d V=(Nl+1)d。每层网格关联的特征向量个数为 T T T,这个 T T T是个超参,对于分辨率低的网格,顶点和特征向量是一对一的关系,但对于分辨率较高的网格,则会出现多个顶点对应同一个特征向量的情况,如果使用哈希表来记录这种对应关系的话,在高分辨率的网格中就会发生哈希碰撞。
具体步骤如下:
- 对于给定的输入坐标 x x x,我们在不同分辨率下找到对应的网格,即 x x x落在 l 0 l_0 l0的右下网格,落在 l 1 l_1 l1的中间网格
- 将网格的整数顶点映射成哈希表 θ l \theta_l θl的索引值,通过该索引值直接索引到对应的特征向量,哈希表的大小为 T T T,如果 V ≤ T V \leq T V≤T,则顶点和特征向量之间时 1 : 1 1:1 1:1的映射,如果在分辨率更精细的网格中则 V > T \mathrm{V}>\mathrm{T} V>T,此时就会出现哈希碰撞,但是在网络学习的过程中,越密集的区域对梯度影响越大,越稀疏的区域对梯度影响越小,网络会自动从密集区域提取样本,从而避免哈希碰撞
- 从哈希表 θ l \theta_l θl中找出四个索引值对应的特征向量后进行线性插值
- 将不同分辨率网格插值后的特征向量以及辅助向量 ξ ∈ R E \xi \in \mathbb{R}^E ξ∈RE进行Concat,然后输入MLP,后续操作和原始的NeRF就基本一致了
1.2 Accelerated Ray Marching
原始NeRF的射线采样算法是对射线进行均匀采样,采样过程分为粗采样和细采样,细采样根据粗采样的结果优化采样位置,在密度高的地方多采样,在密度低的地方少采样,但是在实际场景中,大多数是空白区域,固定采样策略会浪费大量资源。
Instant-NGP中射线采样采用的策略是离相机近的场景多采样,离相机远的场景少采样。并同时维护了一个根据场景大小变化并持续更新的占用栅格,通过Ray Matching过程中计算射线与占用栅格的交点,会主动跳过未被占用栅格中的采样。
1.3 实验结果
实验结果如下:

可以看到Instant-NGP在通过秒级别的训练就可以达到NeRF和NSVF通过若干个小时训练采可以达到的效果。
2. Mip-NeRF 360
Mip-NeRF 360的在NeRF++和Mip NeRF的基础上进行扩展,首先是整合了NeRF++提出的远景参数化技巧和Mip-NeRF的低通滤波思想,在此基础上扩展了场景参数化,在线蒸馏,失真正则化等方法来克服无界场景渲染中模糊和锯齿化等问题,均方误差较Mip-NeRF降低57%。
2.1 场景参数化
场景参数化解决无界场景中如何构建采样点的问题,在NeRF++中提出将无界场景分为前景和背景两部分分开渲染,前景在一个单位球体内使用正常的欧拉坐标系下的 ( x , y , z ) (x, y, z) (x,y,z)表示采样点,背景使用一个四维向量 ( x ′ , y ′ , z ′ , 1 / r ) \left(x^{\prime}, y^{\prime}, z^{\prime}, 1 / r\right) (x′,y′,z′,1/r)表示,其中 x ′ 2 + y ′ 2 + z ′ 2 = 1 \mathrm{x}^{\prime 2}+\mathrm{y}^{\prime 2}+\mathrm{z}^{\prime 2}=1 x′2+y′2+z′2=1表示方向, 0 < 1 / r < 1 0<1 / r<1 0<1/r<1表示方向,如下图所示:

在Mip-NeRF 360中采用了类似的映射: contract ( x ) = { x ∥ x ∥ ≤ 1 ( 2 − 1 ∥ x ∥ ) ( x ∥ x ∥ ) ∥ x ∥ > 1 \operatorname{contract}(\boldsymbol{x})= \begin{cases}\boldsymbol{x} & \|\boldsymbol{x}\| \leq 1 \\ \left(2-\frac{1}{\|\boldsymbol{x}\|}\right)\left(\frac{\boldsymbol{x}}{\|\boldsymbol{x}\|}\right) & \|\boldsymbol{x}\|>1\end{cases} contract(x)={
x(2−∥x∥1)(∥x∥x)∥x∥≤1∥x∥>1但是由于Mip-NeRF中采样点不再只是一个点,而是通过一个3D高斯表达,因此当我们对背景采样点进行映射的时候,采样点对应的高斯方差也需要映射,这个过程有点像扩展卡尔曼滤波中的线性化状态转移部分,即 f ( x ) ≈ f ( μ ) + J f ( μ ) ( x − μ ) f(\mathbf{x}) \approx f(\boldsymbol{\mu})+\mathbf{J}_f(\boldsymbol{\mu})(\mathbf{x}-\boldsymbol{\mu}) f(x)≈f(μ)+Jf(μ)(x−μ)其中 J f ( μ ) \mathbf{J}_f(\boldsymbol{\mu}) Jf(μ)是映射方程 f ( x ) f(\mathbf{x}) f(x)相对于采样点 μ \boldsymbol{\mu} μ的雅可比矩阵,然后高斯分布 ( μ , Σ ) (\boldsymbol{\mu}, \boldsymbol{\Sigma}) (μ,Σ)就会被映射成 f ( μ , Σ ) = ( f ( μ ) , J f ( μ ) Σ J f ( μ ) T ) f(\boldsymbol{\mu}, \boldsymbol{\Sigma})=\left(f(\boldsymbol{\mu}), \mathbf{J}_f(\boldsymbol{\mu}) \boldsymbol{\Sigma} \mathbf{J}_f(\boldsymbol{\mu})^{\mathrm{T}}\right) f(μ,Σ)=(f(μ),Jf(μ)ΣJf(μ)T)下图就是Mip-NeRF中采样点的映射前后的示意图:

其中蓝色部分是欧式空间,黄色部分是非欧式空间,其中采样的坐标就是MLP的输入。在非欧式空间采样时,作者定义了一个从欧式空间射线距离 t t t到非欧式空间距离 s s s的可逆变换 s ≜ g ( t ) − g ( t n ) g ( t f ) − g ( t n ) s \triangleq \frac{g(t)-g\left(t_n\right)}{g\left(t_f\right)-g\left(t_n\right)} s≜g(tf)−g(tn)g(t)−g(tn) t ≜ g − 1 ( s ⋅ g ( t f ) + ( 1 − s ) ⋅ g ( t n ) ) t \triangleq g^{-1}\left(s \cdot g\left(t_f\right)+(1-s) \cdot g\left(t_n\right)\right) t≜g−1(s⋅g(tf)+(1−s)⋅g(tn))进一步作者定义了 g ( x ) = 1 / x g(x)=1 / x g(x)=1/x并在非欧式空间进行等距采样,这样就可以做满足在近处多采样,远处少采样的原则。
2.2 在线蒸馏
在原始NeRF中,使用了两个MLP分别作为Coarse和Fine两阶段训练,在Mip-NeRF中Coarse和Fine训练使用的是同一个MLP,在Mip-NeRF 360中作者对这一部分做了进一步优化,如下图所示:

Mip-NeRF 360中使用了一个小的Proposal MLP和一个大的NeRF MLP,其中Proposal MLP仅输出密度用于指导重新采样的权重,在最后阶段使用NeRF MLP来渲染图像的颜色,这样的好处是可以减小计算量,但是没有直接的密度监督我们如何训练Proposal MLP呢?Mip-NeRF 360中使用了在线蒸馏的方式联合训练两个MLP
在线蒸馏的具体实现方式是通过损失函数 L prop ( t , w , t ^ , w ^ ) \mathcal{L}_{\text {prop }}(\mathbf{t}, \mathbf{w}, \hat{\mathbf{t}}, \hat{\mathbf{w}}) Lprop (t,w,t^,w^)使得Proposal MLP的权重直方图 ( t ^ , w ^ ) (\hat{\mathbf{t}}, \hat{\mathbf{w}}) (t^,w^)和NeRF MLP的权重直方图 ( t , w ) ({\mathbf{t}}, {\mathbf{w}}) (t,w)保持一致,该函数定义如下: L prop ( t , w , t ^ , w ^ ) = ∑ 1 w max ( 0 , w i − bound ( t ^ , w ^ , T i ) ) 2 \mathcal{L}_{\text {prop }}(\mathbf{t}, \mathbf{w}, \hat{\mathbf{t}}, \hat{\mathbf{w}})=\sum \frac{1}{w} \max \left(0, w_i-\operatorname{bound}\left(\hat{\mathbf{t}}, \hat{\mathbf{w}}, T_i\right)\right)^2 Lprop (t,w,t^,w^)=∑w1max(0,wi−bound(t^,w^,Ti))2其中 bound ( t ^ , w ^ , T ) = ∑ j : T ∩ T ^ j ≠ ∅ w ^ j \operatorname{bound}(\hat{\mathbf{t}}, \hat{\mathbf{w}}, T)=\sum_{j: T \cap \hat{T}_j \neq \varnothing} \hat{w}_j bound(t^,w^,T)=j:T∩T^j=∅∑w^jbound ( t ^ , w ^ , T ) (\hat{\mathbf{t}}, \hat{\mathbf{w}}, T) (t^,w^,T)计算的是与区间 T T T内所有Proposal权重的总和,该损失函数的含义是,如果两个直方图彼此一致,那么必须保持 w i ≤ bound ( t ^ , w ^ , T i ) w_i \leq \operatorname{bound}\left(\hat{\mathbf{t}}, \hat{\mathbf{w}}, T_i\right) wi≤bound(t^,w^,Ti),即保证两个直方图在相同区域的上界相同,又由于整个权重直方图的积分必须为1,因此两个直方图最终会趋于一致。
2.3 失真正则化
正则化的目的是消除一些深度不准确漂浮在前景中的背景点,解决方式是添加一个正则化损失: L dist ( s , w ) = ∫ − ∞ ∞ ∫ s w s ( u ) w s ( v ) ∣ u − v ∣ d u d v \mathcal{L}_{\text {dist }}(\mathbf{s}, \mathbf{w})=\int_{-\infty}^{\infty} \int_{\mathbf{s}} \mathbf{w}_{\mathbf{s}}(u) \mathbf{w}_{\mathbf{s}}(v)|u-v| d_u d_v Ldist (s,w)=∫−∞∞∫sws(u)ws(v)∣u−v∣dudv其中 s \mathbf{s} s为射线距离, w \mathbf{w} w为权重 w s ( u ) = ∑ i w i 1 [ s i , s i + 1 ) ( u ) \mathbf{w}_{\mathbf{s}}(u)=\sum_i w_i \mathbb{1}_{\left[s_i, s_{i+1}\right)}(u) ws(u)=i∑wi1[si,si+1)(u)上述正则化损失的目标是使得单一射线上的权重分布更加接近于脉冲阶跃函数,离散化后,我们可以将损失函数写为 L dist ( s , w ) = ∑ i , j w i w j ∣ s i + s i + 1 2 − s j + s j + 1 2 ∣ + 1 3 ∑ w i 2 ( s i + 1 − s i ) \mathcal{L}_{\text {dist }}(\mathbf{s}, \mathbf{w})=\sum_{i, j} w_i w_j\left|\frac{s_i+s_{i+1}}{2}-\frac{s_j+s_{j+1}}{2}\right|+\frac{1}{3} \sum w_i^2\left(s_{i+1}-s_i\right) Ldist (s,w)=i,j∑wiwj
2si+si+1−2sj+sj+1
+31∑wi2(si+1−si)其中第一项最小化所有区间中点对之间的距离,使得区间越来越小,第二项最小化每个单独区间的加权大小,使得不同区间的权重越来越小,最后效果如下图所示:

2.4 实验结果
这里我们主要看下Ablation Study的结果:

我们可以得到如下一些比较重要的结论:
- 不使用 L prop \mathcal{L}_{\text {prop }} Lprop ,即不监督Proposal MLP会明显降低模型表现
- 使用 L dist \mathcal{L}_{\text {dist }} Ldist 不会降低模型表现,并且可以减少不准确的背景深度
- 使用Proposal MLP可以将训练速度加快3倍
3. 3D Gaussian Splatting
3D Gaussian Splatting的背景和重要性无需多言,以Instant-NGP的训练速度达到Mip-NeRF 360的渲染效果,下面我们结合源码来仔细读一读这篇Paper,在论文中提到,3D Gaussian Splatting有三个重要组件,分别是:
- 引入3D高斯函数作为场景表达方法;
- 在优化3D高斯函数属性的过程中,会添加和删除3D高斯函数实现自适应密度控制;
- 实现针对GPU的快速、可微分的渲染方法;
下面我们从这三个方面展开下细节
3.1 Differentiable 3D Gaussian Splatting
我们简单复习下三维高斯函数的定义,一维高斯分布的概率密度函数为: p ( x ) = 1 σ 2 π exp ( − ( x − μ ) 2 2 σ 2 ) p(x)=\frac{1}{\sigma \sqrt{2 \pi}} \exp \left(-\frac{(x-\mu)^2}{2 \sigma^2}\right) p(x)=σ2π1exp(−2σ2(x−μ)2)对于变量 v = [ a , b , c ] T \mathbf{v}=[a, b, c]^T v=[a,b,c]T的三维高斯分布的概率密度函数如下: p ( v ) = p ( a ) p ( b ) p ( c ) = 1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2424
2424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









