







1.背景
目前的机器学习与量子物理之间的关系:

虽然量子计算机具有并行性,可以很好的解决上述问题。但是,量子计算机还没有研发成功,因此需要对量子态进行压缩表示:
分解得到的最优结构(如MPS,PEPS,TTN等)由量子系统的关联结构确定,这样的关联结构可以与神经网络联系起来。
最简单的分解是MPS,它已经用于表示神经网络中的线性层:
TTN虽然也有应用,但是也有其缺点(后面会讲!!!)
本文采用MERA来替代神经网络的线性层,与tensor train(张量火车)分解的方式相比:
2.线性层的张量分解

假设:𝒲 维数为 d n × d n d^{n}\times d^{n} dn×dn,假设其中的参数为 W a b W_{ab} Wab
将𝒲转换成2𝑛阶的张量:

如图:

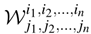
由于上述形式的张量参数量相当大,那么如何解决呢?
解决方案:𝒲的tensor train分解



维数变化原理图:

tensor train性质:
1.有效捕捉数据间尺度为𝑙𝑜𝑔𝐷的相关性
2.具有高度局部性
3.两端的张量相关性很弱
注释:其中第一点来自于纠缠熵的概念

分层结构的张量网络可以更好地表示整个线性层的相关性
例如:树张量网络

树状连通性使网络充满因果结构,张量及其输出由以下影响:
1.树中的高度
2. 输入
为什么这种因果关系会影响到张量呢?
答:在后面会用高斯权重初始化构建张量,同时也会受到输入数量的影响。
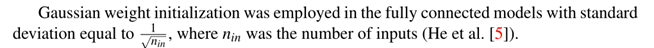
以前在神经网络的背景下研究过的简单树网络有一个主要的缺陷:
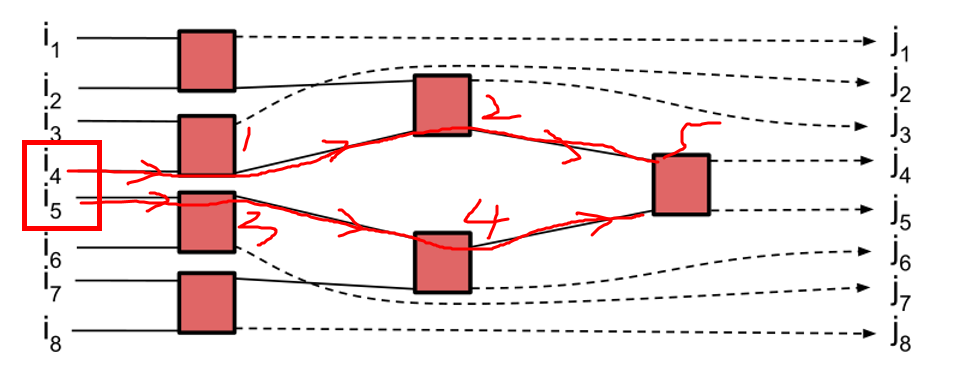
在极端情况下,相邻输入之间的相关性仅由网络末端的张量控制
解释:
以
i
4
i_{4}
i4和
i
5
i_{5}
i5为例子,
i
4
i_{4}
i4依次通过1,2然后到5;
i
5
i_{5}
i5依次通过3,4然后到5。即要捕捉
i
4
i_{4}
i4和
i
5
i_{5}
i5之间的关系需要到5处才能处理,这也就是所说的“在极端情况下,相邻输入之间的相关性仅由网络末端的张量控制”
为了解决这个问题,引入了MERA
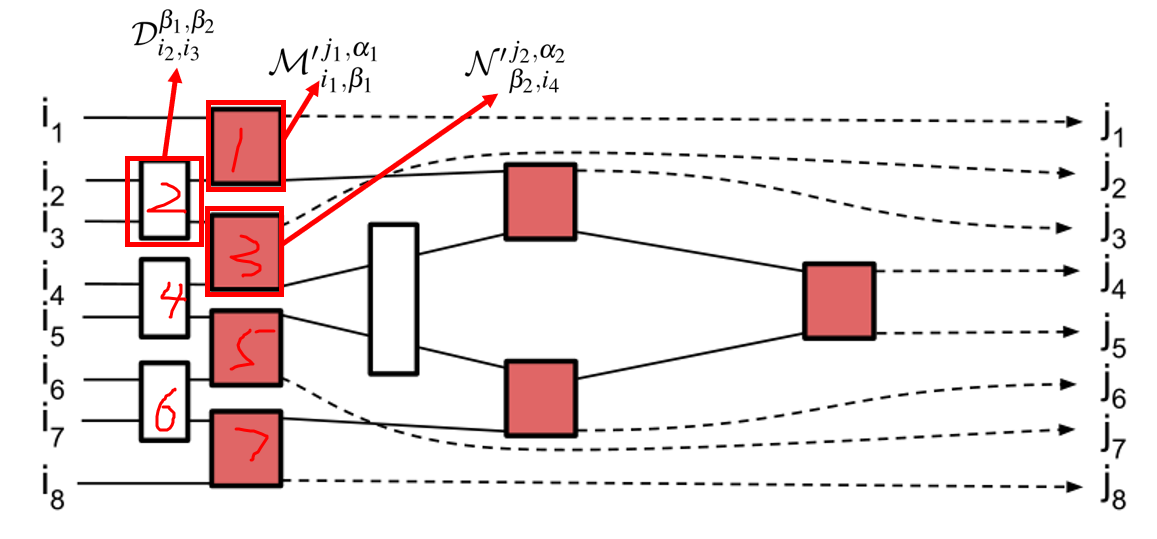
解缠器的作用:使同一长度尺度上的所有相关性得到相似的处理
解释:
i
1
i_{1}
i1和
i
2
i_{2}
i2的相关性被1捕获和处理,
i
2
i_{2}
i2和
i
3
i_{3}
i3的相关性被2捕获和处理,依次往后。这也就是说相邻之间的相关性将会在同一层得到处理。
例如,任何两个相邻输入索引
i
n
i_{n}
in和
i
n
+
1
i_{n+1}
in+1 之间的相关性将被第一行树元素或解缠结器捕获
这使得网络中的后面元素能够捕捉更长范围的相关性
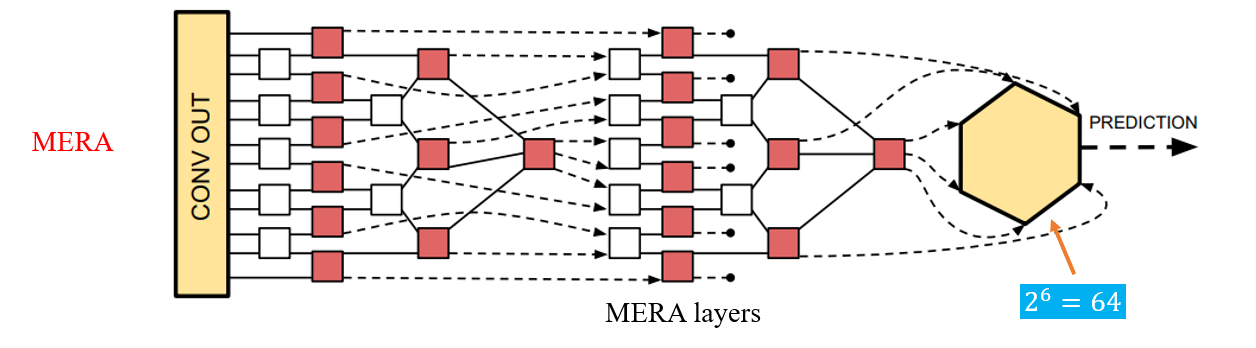
如何构建秩为𝑁的MERA层呢?
Step1.创建一个树张量层

Step2. 解缠结器

3.对比实验
实验四大框架
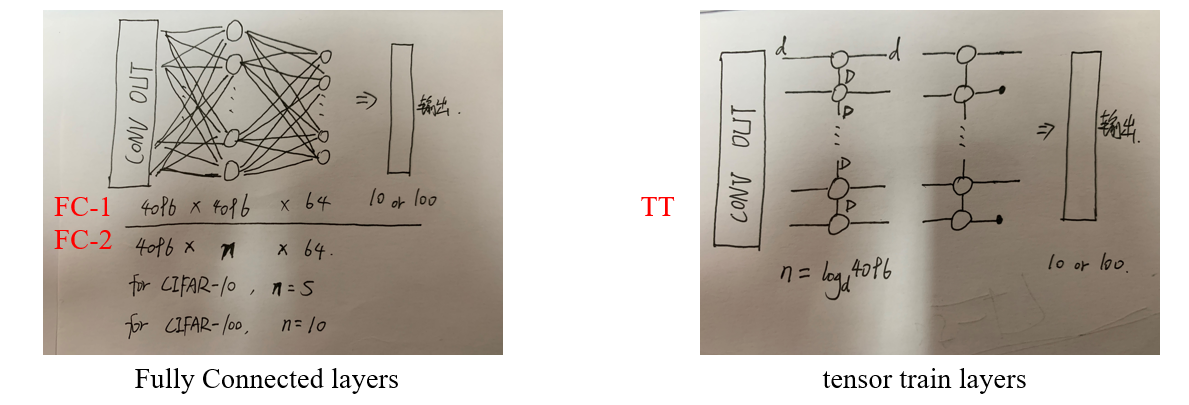
数据集

实验结果

4.相关工作

一些工作讨论了重整化群和深度学习之间的关系,这里只采用MERA代替全连接层
5.讨论
1. 实验结果表明用MERA替代CIFAR-10分类中的全连接层,减少了14000倍的参数,而准确率仅降低了不到1%。而且它的性能优于用张量火车替代全连接层的模型
2. 它的分解层可以潜在处理更大的输入,避免大数据集下的过拟合,但它训练时间可能更长
6.未来工作
1.怎样将MERA的输入reshape成12阶张量,还需要实验进一步说明
2.简单的训练2D MERA直接作用到输入上或仅用二维 MERA 替换网络的卷积层
3.采用纠缠来衡量神经网络中的分布关联,进而来优化和设计网络















 6137
6137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









