







第十一讲卷积神经网络(高级篇)学习与代码
B站 刘二大人 教学视频 传送门: 卷积神经网络(高级篇)
一、Inception Model
1、GoogLeNet(通过Pytorch实现)传送门GoogLeNet实现
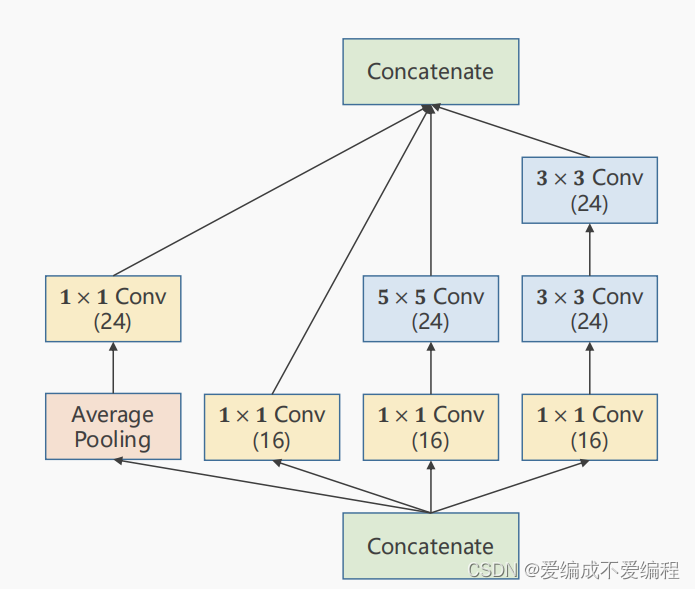
其中有很多相同的结构叫Inception Model如下:
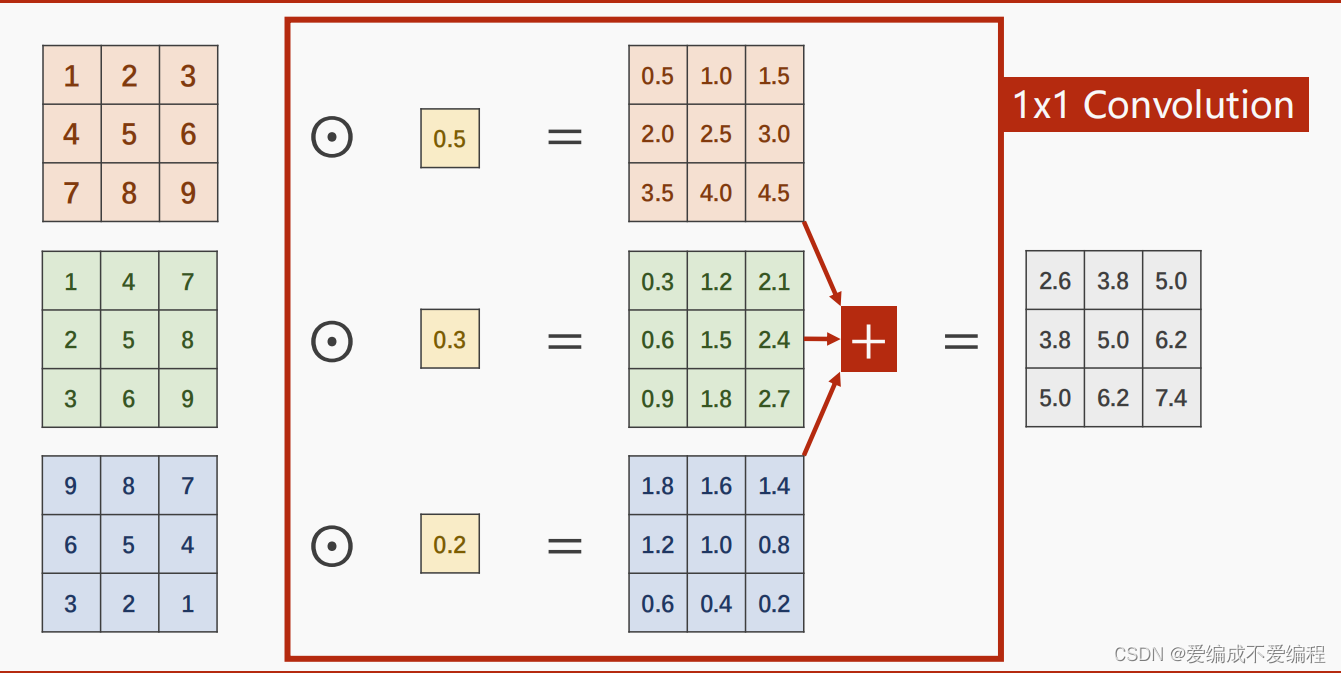
2、1X1卷积核(信息融合:即不同通道信息融合),作用为改变通道数:C1-->C2
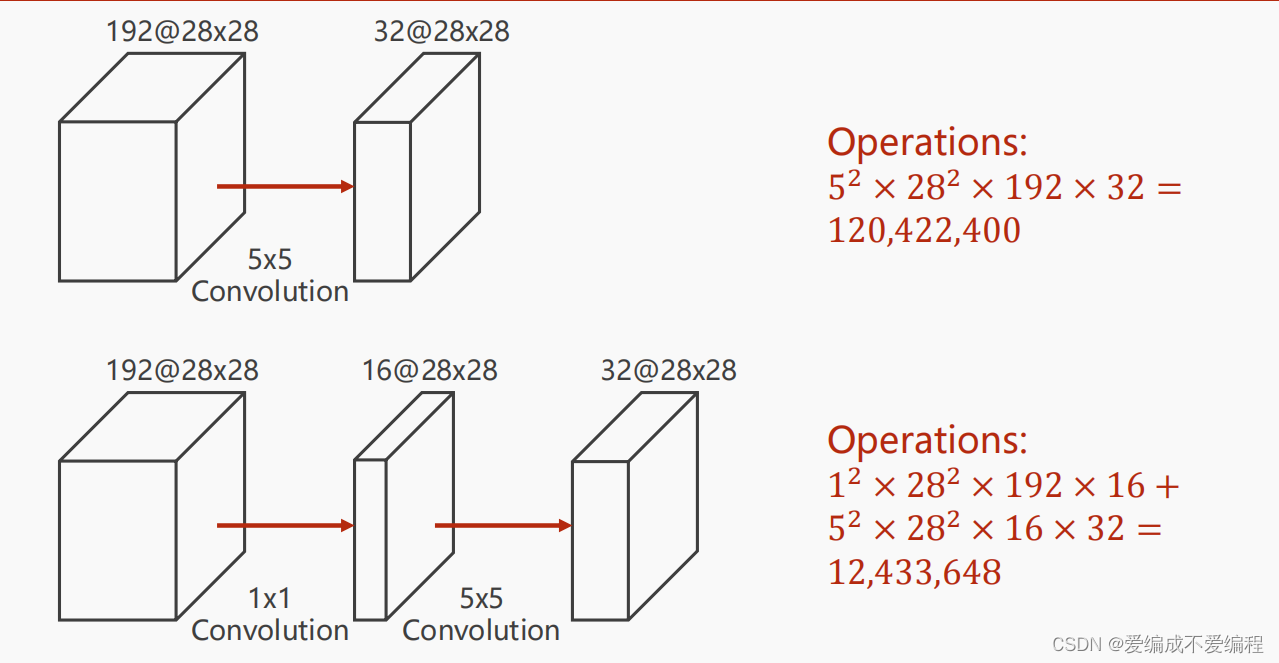
3、改变通道后,如下图所示,很明显1X1卷积核改变通道后,可以减少运算数量。
4、Inception Model如下图所示:
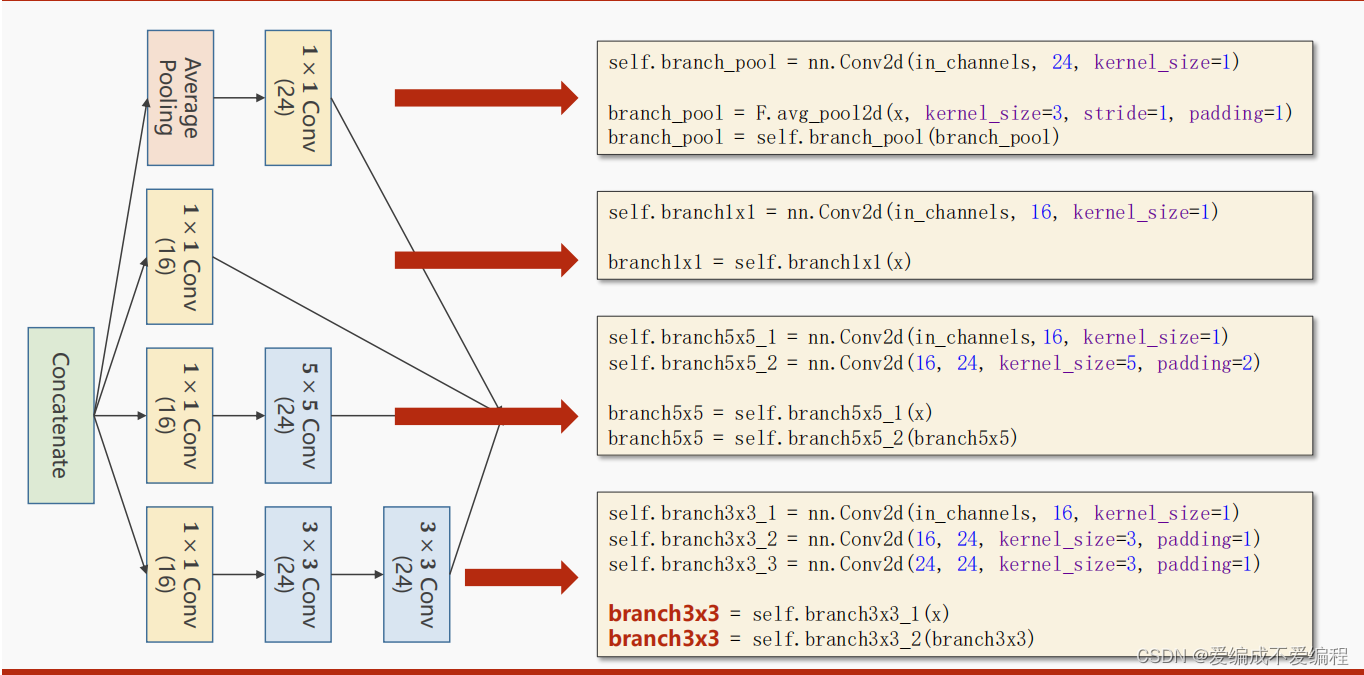
5、做完四个分支卷积操作后,然后将他们拼起来,沿着C拼起来的代码为:
outputs_=[branch1x1,branch5x5,branch3x3,branch_pool]
# dim=1是因为(b,c,w,h),是要沿着c拼起来
return torch.cat(outputs_,dim=1)将这整个层抽象InceptionA
6、实现CNN-Inception-advance的代码
代码说明:1、将InceptionA层抽象为一个类 方便直接调用
2、先进行两个卷积层,再进行两个Inception层,再进行一次池化层,最后线性
3、线性的大小1408 是通过view(batch,-1)之后张量计算出来的。
4、同样优化器使用的SGD,后进行训练测试
import torch
import matplotlib.pyplot as plt
from torchvision import transforms,datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import os
os.environ["KMP_DUPLICATE_LIB_OK"]='True'
batch_size = 64
#归一化,均值和方差
transform = transforms.Compose([
#Convert the PLI Image to Tensor
transforms.ToTensor(),
#参数为平均值和标准值
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform
)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size
)
test_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size
)
class InceptionA(torch.nn.Module):
def __init__(self,in_channels):
super(InceptionA,self).__init__()
self.branch1x1=torch.nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_1=torch.nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_2=torch.nn.Conv2d(16,24,kernel_size=5,padding=2)
self.branchh3x3_1=torch.nn.Conv2d(in_channels,16, kernel_size=1)
self.branchh3x3_2=torch.nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branchh3x3_3=torch.nn.Conv2d(24,24,kernel_size=3,padding=1)
self.branch_pool=torch.nn.Conv2d(in_channels,24,kernel_size=1)
def forward(self,x):
branch1x1=self.branch1x1(x)
branch5x5=self.branch5x5_1(x)
branch5x5=self.branch5x5_2(branch5x5)
branch3x3=self.branchh3x3_1(x)
branch3x3=self.branchh3x3_2(branch3x3)
branch3x3=self.branchh3x3_3(branch3x3)
branch_pool=F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)
branch_pool= self.branch_pool(branch_pool)
outputs_=[branch1x1,branch5x5,branch3x3,branch_pool]
# dim=1是因为(b,c,w,h),是要沿着c拼起来
return torch.cat(outputs_,dim=1)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1=torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2=torch.nn.Conv2d(88,20,kernel_size=5)
self.incep1=InceptionA(in_channels=10)
self.incep2=InceptionA(in_channels=20)
self.mp=torch.nn.MaxPool2d(2)
self.fc=torch.nn.Linear(1408,10)
def forward(self,x):
in_size=x.size(0)
x=F.relu(self.mp(self.conv1(x)))
x=self.incep1(x)
x=F.relu(self.mp(self.conv2(x)))
x=self.incep2(x)
x=x.view(in_size,-1)
x=self.fc(x)
return x
model=Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
#Send the inputs and targets at every step to the GPU.
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 2000))
running_loss = 0.
epoch_list=[]
accept_list=[]
def test2():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, target = data
#Send the inputs and targets at every step to the GPU.
images, target = images.to(device), target.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
accept_list.append(100 * correct / total)
print('Accuracy on test set: %d %% [%d/%d]' % (100 * correct / total, correct, total))
if __name__=='__main__':
for epoch in range(10):
train(epoch)
test2()
epoch_list.append(epoch)
plt.plot(epoch_list,accept_list)
plt.xlabel("epoch")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.ylabel("成功率 单位为 %")
plt.show()
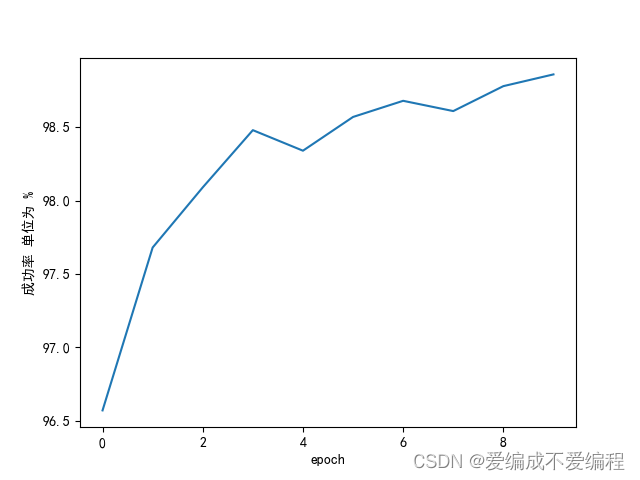
运行效果图:
二、Residual net
视频截图分析:
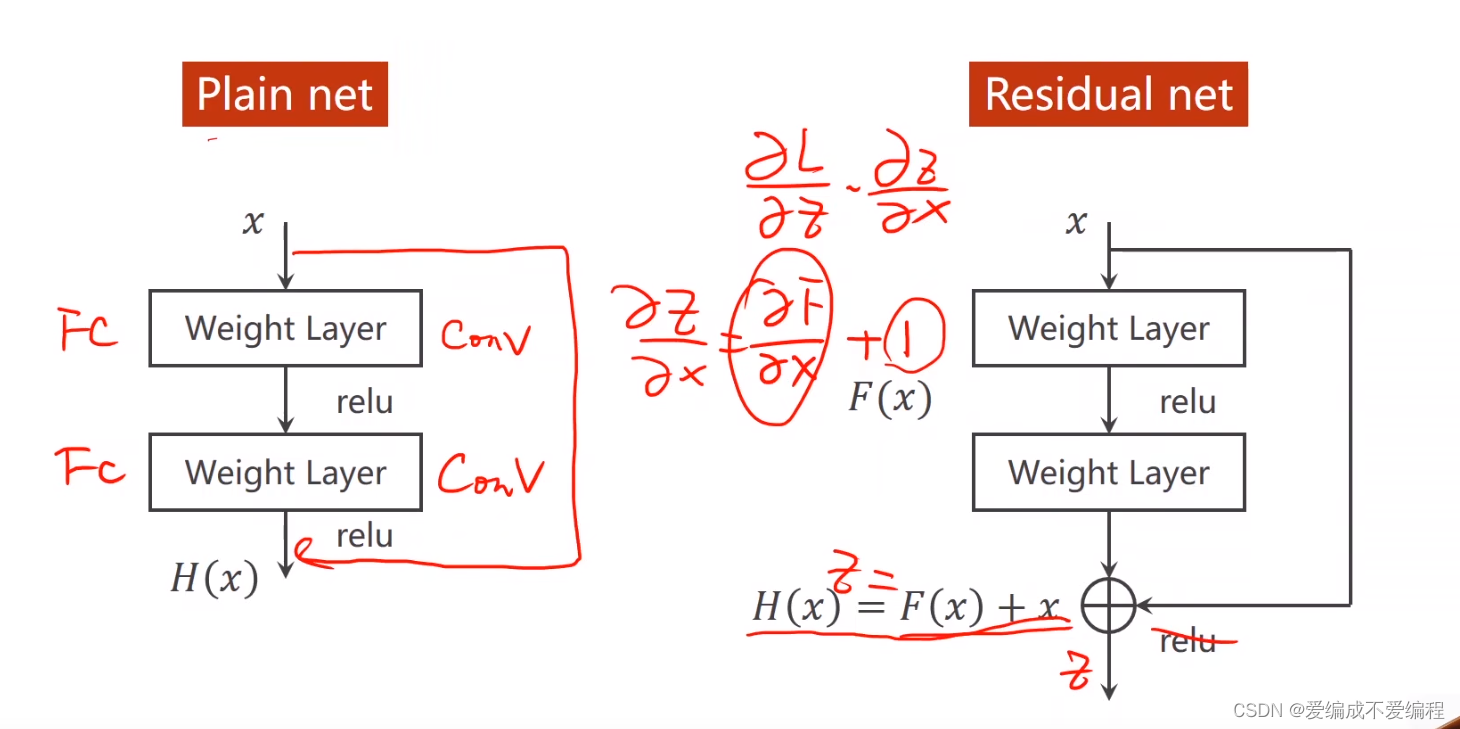
1、Residual net 是为了解决一直3X3卷积造成梯度消失的问题。
2、跳连接,H(x) = F(x) + x,张量维度必须一样,加完后再激活。
(导数+x再求导就不会只有导数,无限叠下去,那么肯定不会造成梯度消失)
为什么可以消除:因为求导过后后面会+1,若倒数非常小的时候 则整个值再1附近,那么若干相乘,就能非常好的去解决梯度消失问题。 如图右边所示:
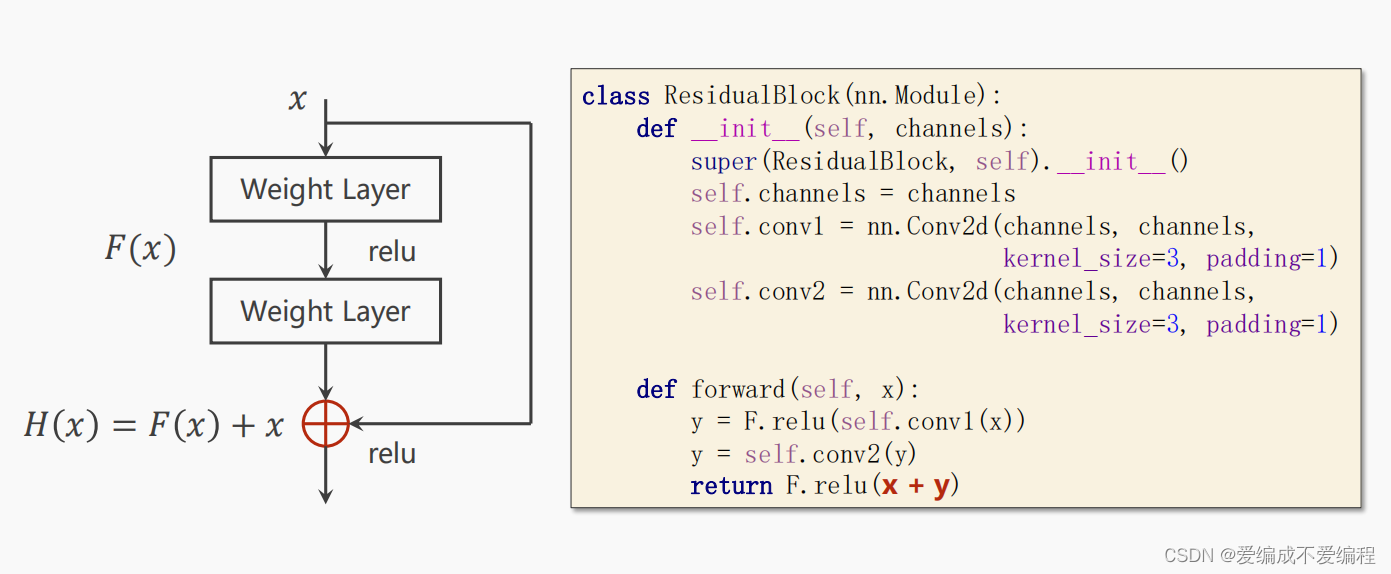
3、ResidualBlock()
4、源码
整个过程:
看过前面的基础篇,应该耳熟能详,毕竟更换模型的作业也做过:
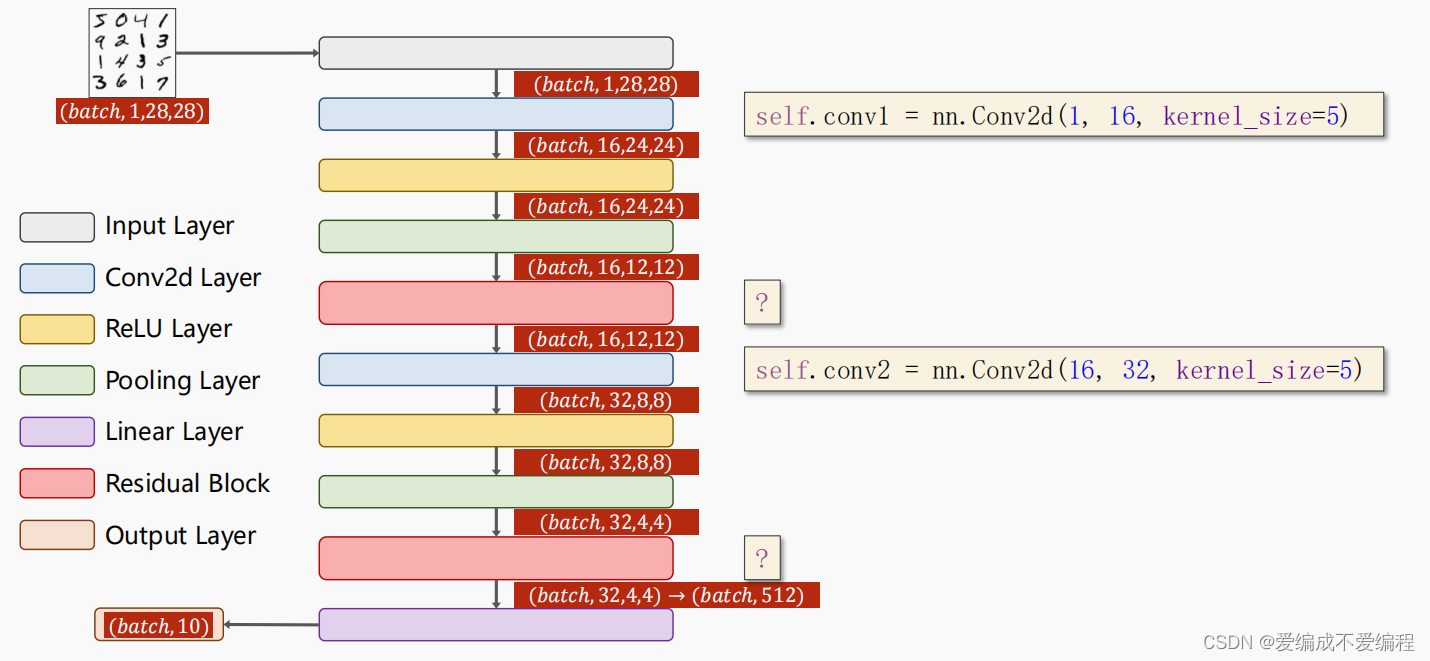
代码说明:1、与Incepiton Model 一样 形成一个ResidualBlock Model 封装
2、过程大概时 一次卷积,一次Residual ,再进行一次卷积,再进行Residual最后线性
3、如果只用CPU,将注释有Send开头的删掉,他的主要租用是将数据放入GPU。
代码实现:
import torch
import torch.nn.functional as F
from torchvision import transforms,datasets
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]='True'
batch_size = 64
transform = transforms.Compose([
#Convert the PLI Image to Tensor
transforms.ToTensor(),
#参数为平均值和标准值
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform
)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size
)
test_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size
)
class ResidualBlock(torch.nn.Module):
def __init__(self,channels):
super(ResidualBlock,self).__init__()
self.channels=channels
self.conv1=torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)
self.conv2=torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)
def forward(self,x):
y=F.relu(self.conv1(x))
y=self.conv2(y)
return F.relu(x+y)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1=torch.nn.Conv2d(1,16,kernel_size=5)
self.conv2=torch.nn.Conv2d(16,32,kernel_size=5)
self.mp=torch.nn.MaxPool2d(2)
self.rblock1=ResidualBlock(16)
self.rblock2=ResidualBlock(32)
self.fc=torch.nn.Linear(512,10)
def forward(self,x):
in_size=x.size(0)
x=self.mp(F.relu(self.conv1(x)))
x=self.rblock1(x)
x=self.mp(F.relu(self.conv2(x)))
x=self.rblock2(x)
x=x.view(in_size,-1)
x=self.fc(x)
return x
model = Net()
# #Convert parameters and buffers of all modules to CUDA Tensor.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
#多分类CrossEntropyLoss 二分类则用BCELoss
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
#Send the inputs and targets at every step to the GPU.
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 2000))
running_loss = 0.
epoch_list=[]
accept_list=[]
def test2():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, target = data
#Send the inputs and targets at every step to the GPU.
images, target = images.to(device), target.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
accept_list.append(100 * correct / total)
print('Accuracy on test set: %d %% [%d/%d]' % (100 * correct / total, correct, total))
if __name__=='__main__':
for epoch in range(10):
train(epoch)
test2()
epoch_list.append(epoch)
plt.plot(epoch_list,accept_list)
plt.xlabel("epoch")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.ylabel("成功率 单位为 %")
plt.show()
运行结果:
.......
Accuracy on test set: 98 % [9866/10000]
[7, 300] loss: 0.005
[7, 600] loss: 0.005
[7, 900] loss: 0.005
Accuracy on test set: 98 % [9881/10000]
[8, 300] loss: 0.005
[8, 600] loss: 0.004
[8, 900] loss: 0.004
Accuracy on test set: 98 % [9889/10000]
[9, 300] loss: 0.004
[9, 600] loss: 0.004
[9, 900] loss: 0.004
Accuracy on test set: 98 % [9883/10000]
[10, 300] loss: 0.003
[10, 600] loss: 0.003
[10, 900] loss: 0.004
Accuracy on test set: 98 % [9864/10000]
进程已结束,退出代码为 0
运行效果:
完结!若有错误,敬请指正,万分感谢!

















 6244
6244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









