







特征预处理–标准化
上篇所讨论的归一化方法,标准化是将数据转换为均值为0、标准差为1的正态分布(即标准正态分布)。标准化的公式如下:
X
s
t
d
=
X
−
μ
σ
X_{\mathrm{std}}=\frac{X-\mu}\sigma
Xstd=σX−μ
X表示原始数据
μ 是数据的均值。
𝜎是数据的标准差。
适用场景:
·数据特征服从正态分布时,标准化效果较好。
·常用于需要考虑数据分布形状的算法,如线性回归、逻辑回归、支持向量机和K均值聚类。
API:sklearn.preprocessing.StandardScaler()
示例:
from sklearn.preprocessing import StandardScaler
import pandas as pd
data = pd.read_csv("dating.txt", encoding='UTF-8')
data_new = data.iloc[:, :3] # 取前三列
# 1、实例化一个StandardScaler对象
transfer = StandardScaler()
# 2、调用fit_transform(x)方法
data_final = transfer.fit_transform(data_new)
print(data_final)
其中dating.txt分享在百度网盘中,具体获取查看数据预处理—归一化
运行结果如下所示:
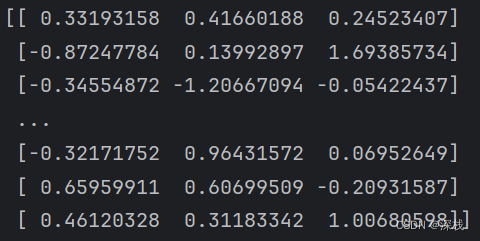
不难发现,标准化的过程是将数据转换为具有均值为0、标准差为1的分布。但是这里会出先不在[-1,1]的数,这说明原始数据点可能远离均值。标准化是依据均值和标准差来缩放数据,因此离均值越远的点,标准化后的值就越大或越小。















 942
942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









