







 本文深入探讨了金融风控中信贷违约预测的特征工程,包括数据预处理、缺失值和异常值处理、数据分桶、特征交互、编码和选择等方法。通过实例展示了如何使用各种技术来增强模型的稳定性和预测能力,旨在帮助读者掌握信贷风险评估的关键步骤。
本文深入探讨了金融风控中信贷违约预测的特征工程,包括数据预处理、缺失值和异常值处理、数据分桶、特征交互、编码和选择等方法。通过实例展示了如何使用各种技术来增强模型的稳定性和预测能力,旨在帮助读者掌握信贷风险评估的关键步骤。
Task3 金融风控—信贷违约预测(特征工程)
本文主要介绍金融风控-贷款违约预测的特征工程部分,带你来了解各种特征工程以及分析方法,具有一定的参考价值,需要的朋友可以参考一下。
特征工程
3.1 学习目标
- 学习特征预处理、缺失值、异常值处理、数据分桶等特征处理方法
- 学习特征交互、编码、选择的相应方法
- 完成相应学习打卡任务,两个选做的作业不做强制性要求,供学有余力同学自己探索
3.2 内容介绍
- 数据预处理
- 缺失值的填充
- 时间格式处理
- 对象类型特征转换到数值
- 异常值处理
- 基于3segama原则
- 基于箱型图
- 数据分箱
- 固定宽度分箱
- 分位数分箱
- 离散数值型数据分箱
- 连续数值型数据分箱
- 卡方分箱(选做作业)
- 特征交互
- 特征和特征之间组合
- 特征和特征之间衍生
- 其他特征衍生的尝试(选做作业)
- 特征编码
- one-hot编码
- label-encode编码
- 特征选择
- 1 Filter
- 2 Wrapper (RFE)
- 3 Embedded
3.3代码示例
3.3.1 导入包并读取数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
from tqdm import tqdm
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.preprocessing import MinMaxScaler
import xgboost as xgb
import lightgbm as lgb
from catboost import CatBoostRegressor
import warnings
from sklearn.model_selection import StratifiedKFold, KFold
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score, log_loss
warnings.filterwarnings('ignore')
data_train = pd.read_csv('../train.csv')
data_test_a = pd.read_csv('../testA.csv')
3.3.2特征预处理
- 数据EDA部分我们已经对数据的大概和某些特征分布有了了解,数据预处理部分一般我们要处理一些EDA阶段分析出来的问题,这里介绍了数据缺失值的填充,时间格式特征的转化处理,某些对象类别特征的处理。
首先我们查找出数据中的对象特征和数值特征
numerical_fea = list(data_train.select_dtypes(exclude=['object']).columns)
category_fea = list(filter(lambda x: x not in numerical_fea,list(data_train.columns)))
label = 'isDefault'
numerical_fea.remove(label)
在比赛中数据预处理是必不可少的一部分,对于缺失值的填充往往会影响比赛的结果,在比赛中不妨尝试多种填充然后比较结果选择结果最优的一种;
比赛数据相比真实场景的数据相对要“干净”一些,但是还是会有一定的“脏”数据存在,清洗一些异常值往往会获得意想不到的效果。
缺失值填充
-
把所有缺失值替换为指定的值0
data_train = data_train.fillna(0) -
向用缺失值上面的值替换缺失值
data_train = data_train.fillna(axis=0,method=‘ffill’) -
纵向用缺失值下面的值替换缺失值,且设置最多只填充两个连续的缺失值
data_train = data_train.fillna(axis=0,method=‘bfill’,limit=2)
#查看缺失值情况
data_train.isnull().sum()id 0
loanAmnt 0
term 0
interestRate 0
installment 0
grade 0
subGrade 0
employmentTitle 1
employmentLength 46799
homeOwnership 0
annualIncome 0
verificationStatus 0
issueDate 0
isDefault 0
purpose 0
postCode 1
regionCode 0
dti 239
delinquency_2years 0
ficoRangeLow 0
ficoRangeHigh 0
openAcc 0
pubRec 0
pubRecBankruptcies 405
revolBal 0
revolUtil 531
totalAcc 0
initialListStatus 0
applicationType 0
earliesCreditLine 0
title 1
policyCode 0
n0 40270
n1 40270
n2 40270
n2.1 40270
n4 33239
n5 40270
n6 40270
n7 40270
n8 40271
n9 40270
n10 33239
n11 69752
n12 40270
n13 40270
n14 40270
dtype: int64
#按照平均数填充数值型特征
data_train[numerical_fea] = data_train[numerical_fea].fillna(data_train[numerical_fea].median())
data_test_a[numerical_fea] = data_test_a[numerical_fea].fillna(data_train[numerical_fea].median())
#按照众数填充类别型特征
data_train[category_fea] = data_train[category_fea].fillna(data_train[category_fea].mode())
data_test_a[category_fea] = data_test_a[category_fea].fillna(data_train[category_fea].mode())

- category_fea:对象型类别特征需要进行预处理,其中[‘issueDate’]为时间格式特征
时间格式处理
#转化成时间格式
for data in [data_train, data_test_a]:
data['issueDate'] = pd.to_datetime(data['issueDate'],format='%Y-%m-%d')
startdate = datetime.datetime.strptime('2007-06-01', '%Y-%m-%d')
#构造时间特征
data['issueDateDT'] = data['issueDate'].apply(lambda x: x-startdate).dt.daysdata_train['employmentLength'].value_counts(dropna=False).sort_index()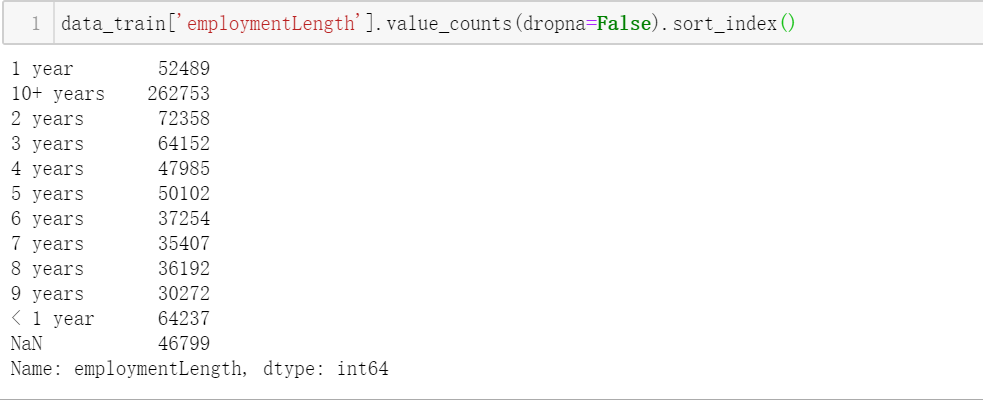
对象类型特征转换到数值
def employmentLength_to_int(s):
if pd.isnull(s):
return s
else:
return np.int8(s.split()[0])
for data in [data_train, data_test_a]:
data['employmentLength'].replace(to_replace='10+ years', value='10 years', inplace=True)
data['employmentLength'].replace('< 1 year', '0 years', inplace=True)
data['employmentLength'] = data['employmentLength'].apply(employmentLength_to_int)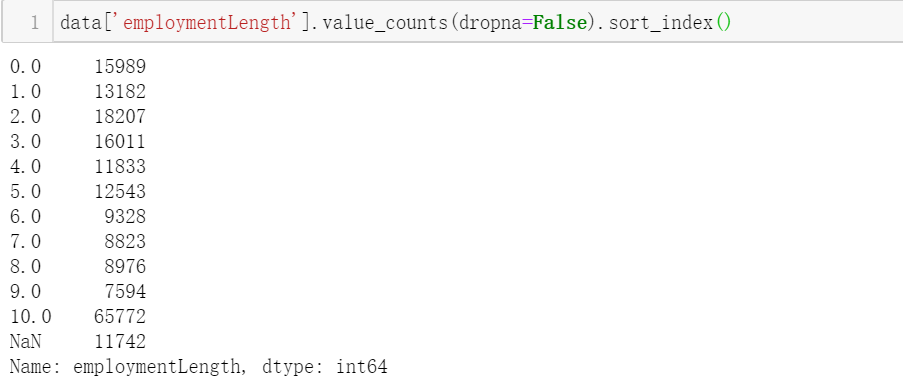
- 对earliesCreditLine进行预处理
for data in [data_train, data_test_a]:
data['earliesCreditLine'] = data['earliesCreditLine'].apply(lambda s: int(s[-4:]))类别特征处理
# 部分类别特征
cate_features = ['grade', 'subGrade'</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









