






综述:基础模型低秩自适应:全面综述
背景:基础模型的快速发展——在多样化、广泛的数据集上训练的大型神经网络——已经彻底改变了人工智能,在自然语言处理、计算机视觉和科学发现等领域的各个方面都实现了前所未有的进步。(现有的大语言模型就是基础模型在自然语言处理方面的具体应用)
问题:然而,这些模型的参数数量巨大,通常达到数十亿或数万亿,在将它们应用于特定下游任务时带来了重大挑战。低秩自适应( LoRA)已成为一种非常有前景的方法,用于减轻这些挑战,提供了一种参数高效的机制,以最小的计算开销微调基础模型。
尽管涉及完整参数更新的传统微调方法在各种任务中已经证明了其有效性,但它们的计算需求通常使得它们对于基座模型来说不切实际。
RoLA的理论分析:
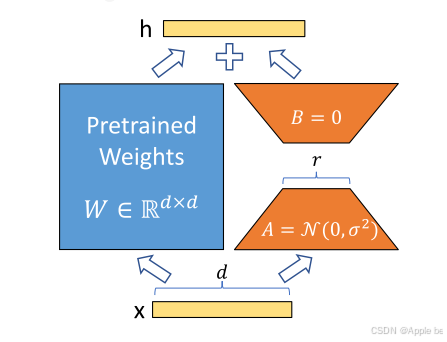
LoRA的数学公式集中在在微调过程中约束更新矩阵∆Wtobe 低秩,如图 2 所示,这通过矩阵分解实现:∆W = BA。矩阵 A 通常使用从随机高斯分布中抽取的值进行初始化,而矩阵 B 则使用零进行初始化,微调过程。在 LoRA 中,微调过程遵循以下关键原则:
• 原始预训练权重 W0 被保持冻结,在训练过程中不接收梯度更新。
• 低秩矩阵 A 和 B 包含唯一的可训练参数,捕捉任务特定的调整。
• 将W0 和∆W分别应用于输入向量 x,并将它们的输出合并。
• 输出∆Wx 通过α/r 进行缩放
•最终以f(x) = W0x +∆Wx = W0x +α/rBAx输出(其中α/r为缩放因子,相当于学习率)
至于RoLA到底为什么有效,还有为什么要使用低秩,和什么程度才算低秩,文章做了说明:
为什么说有效:可以通过神经网络切线核(NTK)理论来理解。
![]()
其中,K(SGD)LoRA 和 K(SGD)分别是 LoRA和全微调诱导的核,N是数据集中的样本数量,c 是梯度和输入的 L2 范数的上界,ϵ 是近似误差, δ 是由 4N2 exp(−(ϵ2 − ϵ3)r/4)给出的概率界限,其中 r 是 LoRA中使用的秩。
尽管 LoRA将更新限制在低秩子空间中,但它根据公式( 7 )有效地针对导致网络行为显著变化的梯度。通过关注这些关键梯度,LoRA保留了模型的泛化能力,确保网络对基本输入变化保持敏感,同时具有高度参数效率。
至于为什莫要使用低秩矩阵,这其实很好理解:
简单来说就是减少参数量和计算量:由这个公式∆W (d*d的矩阵)= B(d*r的矩阵)A(r*d的矩阵)(r<<d)原来需要计算d*d个参数,现在只需要计算2*d*r个参数了,极大的减少了计算量。
低秩的程度:
i )对于全连接神经网络,LoRA可以适应任何模型( f )以准确地表示一个较小的目标模型 (˜f),如果 LoRA的秩( r )满足:
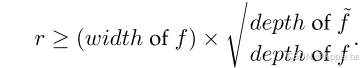
(ii) 对于 Transformer 网络,他们证明了任何模型都可以通过秩 ‑ (嵌入大小 /2)的 LoRA适配器适应到相同大小的目标模型。
对LoRA的理论总结:1.通过∆W = BA极大减少了微调所需要的参数量还有计算量。
2.f(x) = W0x +∆Wx = W0x +α/rBAx 更新矩阵可以明确地融入原始的冻结权重中。这种集成确保了适配后的模型在部署和推理过程中保持效率。
3.最终达成了通过调整低秩矩阵来进行微调的效果。
与此同时作者证明, A 主要作为输入的特征提取器,而 B将这些特征投影到期望的输出。这种不对称性表明,仅对 B进行微调可能比同时微调 A更有效。值得注意的是,他们的分析表明,随机初始化的 A 几乎可以与微调后的表现相当,挑战了同时更新两者的传统做法。通过仅关注更新B,研究人员可能实现更好的泛化,同时进一步减少可训练参数的数量,从而提高 LoRA微调的效率和有效性。
《LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》
背景:自然语言处理随着我们预训练的模型越来越大,全量微调,即重新训练所有模型参数,变得越来越不可行。
提出了Low‑Rank Adaptation,或称 LoRA,它冻结了预训练模型的权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层,大大减少了下游任务的可训练参数数量。
LoRA在微调上面的优势:
• 预训练模型可以共享并用于构建针对不同任务的许多小型 LoRA模块。我们可以冻结共享模型,并通过替换图 1 中的矩阵A 和B 来有效地切换任务,从而显著降低存储需求和任务切换开销。
• 由于我们不需要计算大多数参数的梯度或维护优化器状态,因此 LoRA在使用自适应优化器时使训练更加高效,并将硬件门槛降低了 3 倍。我们只需要优化注入的、远小的低秩矩阵。
• 我们的简单线性设计允许我们在部署时将可训练矩阵与冻结权重合并,在构造上引入了零推理延迟,与完全微调模型相比。
• LoRA是正交于许多先前方法的,并且可以与其中许多方法结合,例如前缀微调。
全微调与低秩微调:
全微调:

每个下游任务由一个上下文 ‑ 目标对训练数据集表示:Z = {(xi, yi)}i=1,..,N
低秩微调:

为方便理解到底那里体现了低秩,不妨将公式改写成:
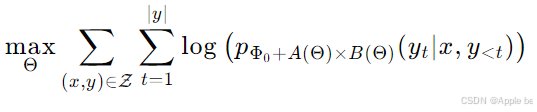
其中A(Θ) 和 B(Θ) 是由 Θ 编码的低秩矩阵
LoRA应用广泛的原因:
我们可以将 LoRA 应用于神经网络中任何子集的权重矩阵,以减少可训练参数的数量。在 Transformer 架构中,自注意力模块中有四个权重矩阵(Wq,Wk,Wv,Wo ),MLP 模块中有两个。我们将 Wq (或 Wk, Wv )视为一个维度为 dmodel ×dmodel 的单个矩阵,尽管输出维度通常被切割成注意力头。
实验:
微调过程:

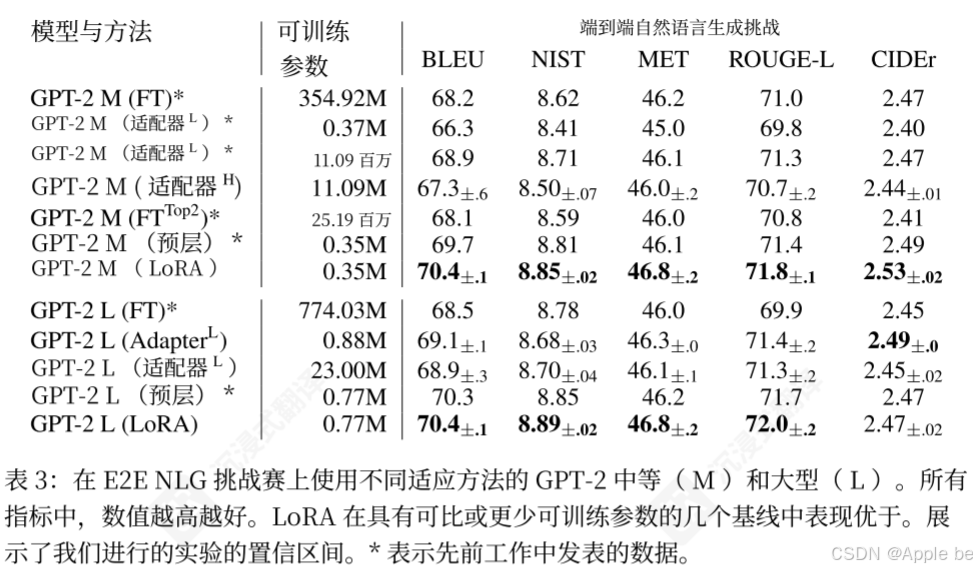
所有参数越大越好,可以看出LoRA的性能比较好。
前缀嵌入调整(PreEmbed ):
在输入标记之间插入特殊标记。这些特殊标记具有可训练的词嵌入,并且通常不在模型的词汇表中。这些标记放置的位置可能会影响性能。我们关注“前缀”,即将这些标记添加到提示的开头,以及“后缀”,即将这些标记添加到提示的末尾;作者使用 lp (分别 li )表示前缀(分别后缀)标记的数量。可训练参数的数量为 |Θ| = dmodel( lp + li )。
前缀层调整( PreLayer ):
是对前缀嵌入调整的扩展。我们不仅学习一些特殊标记的词嵌入(或者说,嵌入层之后的激活),还学习每个 Transformer (现有的大语言模型大多都是使用的transformer架构)层之后的激活。从先前层计算出的激活被简单地替换为可训练的激活。结果的可训练参数数量为( lp + li ),其中L是Transformer 层的数量。
我们在大多数实验中仅将 LoRA应用于Wq 和Wv。可训练参数的数量由秩 r 和原始权重的形状决定:|Θ| = 2× ˆLLoRA ×dmodel ×r,其中 ˆLLoRA 是我们应用 LoRA的权重矩阵数量。
之后作者在如下进行微调:
ROBERTA BASE/LARGE
DEBERTA XXL
GPT‑2 中 / 大型模型
扩展至GPT‑3 175B
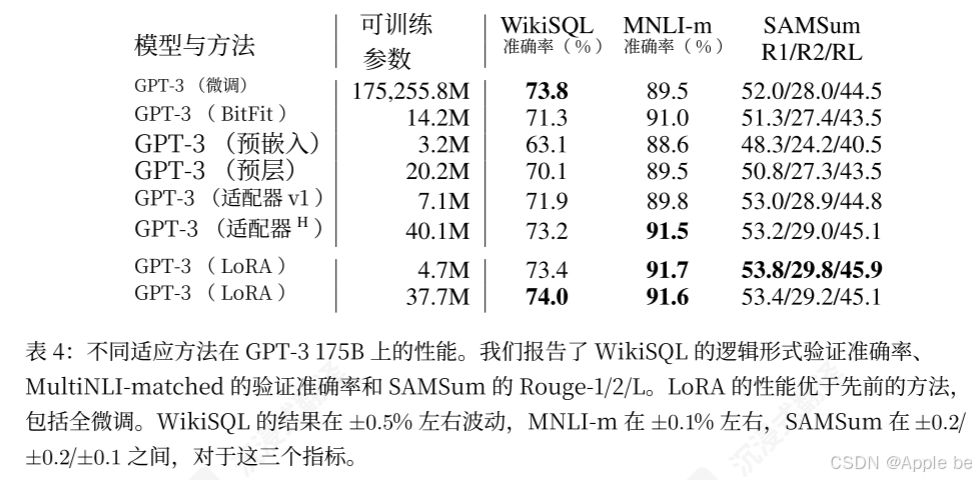
以下作者回答了一些问题:
1.应该将 LoRA 应用到 Transformer 中的哪些权重矩阵?
作者只考虑自注意力模块中的权重矩阵。在 GPT‑3 175B 上设置了18M 的参数预算(如果以 FP16 存储则约为 35MB ),如果只适配一种类型的注意力权重,则对应于 r = 8 ,如果适配两种类型,则对应于 r = 4,对所有 96 层进行适配。

要注意:将所有参数放入∆Wq 或∆Wk 会导致性能显著降低,而同时调整Wq 和Wv 可以获得最佳结果。这表明,即使是四阶也能在∆W 中捕捉到足够的信息,因此调整比单种权重具有更大秩的权重矩阵更为可取。
2.LoRA的最佳秩 r 是多少?

说明了,LoRA已经能够在非常小的 r (对于 {Wq,Wv} 来说比仅仅Wq 更有优势)下表现出竞争力。之后就对低秩矩阵的可信性做了分析,但文章没有给出具体的最佳R值。

















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









