






创新点:提出了YOLO算法(将图像检测任务归类为回归,而不是原先的依靠分类器),大大的提高了检测速度。
YOlO的原理:
-
将图像分成网格
把输入图像划分成 S×SS×S 的网格(比如 7×77×7),每个网格负责预测一定数量的物体。 -
每个网格预测多个边界框(Bounding Box)
-
每个边界框预测:中心坐标 (x,y)(x,y)、宽高 (w,h)(w,h)、置信度(是否包含物体)。
置信度:形式上,作者定义置信度为 Pr(Object) ∗ IOUtruthpred。如果该单元中没有物体存在,置信度分数应为零。否则,当然希望置信度分数等于预测框与真实框之间的交并比( IOU)。 -
同时预测物体的类别(比如“猫”“狗”)。
-
-
端到端一次性输出
YOLO 直接用卷积神经网络(CNN)处理图像,一次性输出所有网格的预测结果(边界框 + 类别),而不是像传统方法那样分多步处理。
依靠分类器进行图像检测:分两步(候选区域生成和分类判断)会生成大约2000个候选框,并对每一个进行分类。
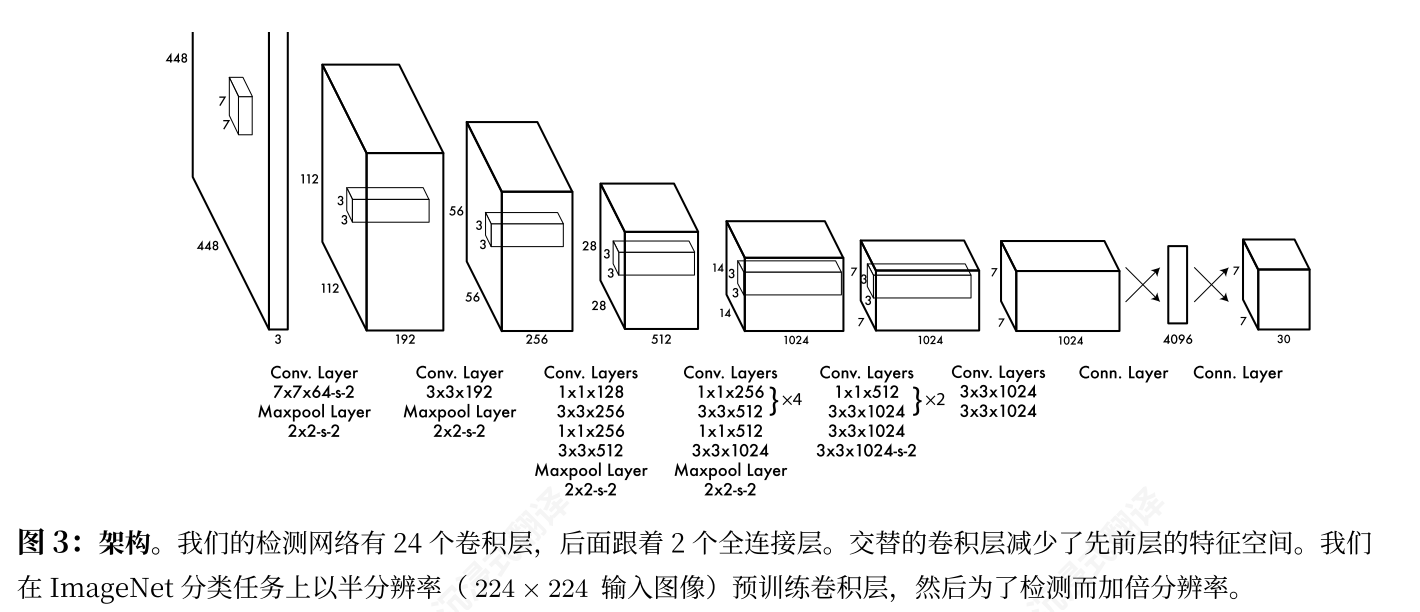
架构:
网络架构受到图像分类 GoogLeNet 模型的启发 [34]。我们的网络有 24 个卷积层,后面跟着 2 个全连接层。我们不是使用 GoogLeNet 中使用的 Inception模块,而是简单地使用 1×1 降维层,后面跟着 3×3 卷积层
YOLO的局限性:
由于每个网格单元只预测两个框并且只能有一个类别,YOLO对边界框预测施加了强烈的空间约束。这种空间约束限制了我们的模型可以预测的附近对象数量。我们的模型在处理成群出现的小型对象(如鸟群)时存在困难。
由于我们的模型从数据中学习预测边界框,因此在新的或非标准的纵横比或配置的对象上泛化能力较差。由于我们的架构从输入图像中具有多个下采样层,因此我们的模型在预测边界框时使用相对粗糙的特征。
最后,虽然我们使用近似检测性能的损失函数进行训练,但我们的损失函数在处理小边界框和大边界框中的错误时是相同的。在大边界框中的小错误通常是无害的,但在小边界框中的小错误对 IOU的影响要大得多。我们主要的错误来源是定位不准确。

















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









