







模拟退火理论(SA——Simulated Annealing)
和局部束搜索相反,模拟退火将最优化策略改变,引入随机噪声,不一定每次都是最优,但是内部机制保证了最终的走向是最优,总的过程可以理解为初期广泛探索(Exploration),逐步过渡到深挖(Exploitation)。其中机理比较复杂,我们逐步去理解。
基本思路

首先声明,我们这里还是要将函数优化到最大,如果要优化最小,符号都要变。
所谓退火就是从高温逐步降温的过程。在这个过程中,初期高温,状态容易改变,不稳定,后期低温,状态稳定。我们模拟退火中进行随机变化的概率就和温度有关。这里引入温度变量T,T怎么变呢?一般来说是指数变化 T = 0.9 9 t T 0 T=0.99^tT_0 T=0.99tT0,这个0.99是退火率,可以进行修改,t是时间。之所以采用指数变化而不是什么线性递减,也有门道,后面解释。
看代码,随着循环,t增大,T以指数速率先快后慢变小。之后进行邻域中的随机选择,而不是在邻域中找最优。这时结果就只能有两种,我们通过新结果和原结果的差距 △ E \triangle E △E判断:
- △ E > 0 \triangle E>0 △E>0,更优。那我们就直接笑纳。这个效果上相当于登山算法。
- △ E ≤ 0 \triangle E\leq 0 △E≤0, 相等或者更差,总之要么确实是不好的结果,要么再走走可能会碰到更好的结果,先苦后甜。那到底怎么抉择呢,这可能是个机遇,但是也有风险,所以我们要计算概率。
概率公式初步理解
接受坏结果的概率 P = e △ E T P=e^{\frac{\triangle E}{T}} P=eT△E,解析一下这个式子。
- 首先指数部分一定是负的,所以保证P是介于0-1之间的。
- 初期T大,不管E怎么变,比值总是接近于0,概率较大,所以很容易接受所有改动
- 中期T适中,由 ∣ △ E ∣ |\triangle E| ∣△E∣的大小决定是否接受,delta绝对值越大,接受概率越小,因为巨大的退步代表巨大的风险,合理。
- 后期T小,一般情况比值都更接近于负无穷,只有在 ∣ △ E ∣ |\triangle E| ∣△E∣特别小时能有接近于0的比值,才能接受,也就是说后期要么就是更优,直接接受,要么就是产生一个更差结果,我大概率不接受而保持原状,所以后期就相当于一个局部搜索。这里可见指数优点,在低温区变化够慢,可以保证足够的时间达到局部最优,保证收敛。其实还可以采取别的,比如现实世界的温度变化函数,但是规律一定是先快后慢。
如何理解步长逐渐缩小
我们进一步从步长的角度理解,这个步长是指 ∣ △ E ∣ |\triangle E| ∣△E∣,而这个常常和解空间中点的距离有较大的关系,所以我们就叫他步长:
- 刚开始T大,所以 ∣ △ E ∣ |\triangle E| ∣△E∣即使很大,也可以走出去,所以初期步长可大可小,可以接受各种结果。
- 但是到了后期,T变小, ∣ △ E ∣ |\triangle E| ∣△E∣一旦变大,给的概率就会变小,步子越大,越不容易接受,所以T越小,小步长的概率就越大,从这个角度理解,随着T减小,平均步长是会越来越小的。
宏观理解
再进行宏观理解,理解下这个算法的合理性与有效性:
- 从宏观角度理解,如果你把每次计算出来的概率输出,你会发现接受较差结果的概率是越来越小。
- 合理性。不需要担心算法质量越来越差,因为概率保证了质量。因为是随机搜索的,所以假定产生好结果的概率是0.5,那么产生坏结果的前提下再接受坏结果的概率肯定是小于0.5的,这就保证了在任何时候,总体上接受好结果的概率要大于接受坏结果的概率,保证方向是正确的。
- 收敛性。初期对坏结果的接受度很高,所以属于横冲直撞的广泛探索,不会收敛。后期温度降低,且保持足够长时间的低温。低温状态下,基本只会朝着优化方向走,所以在低温状态下相当于一个登山算法,而登山算法只要迭代次数够多,必然能达到局部最优。所以一定会收敛。
- 收敛较慢的特性保证了解的优秀性。
局部搜索实践:北理工最优化大作业——流水车间调度
n个器件,在m个机器上加工。
每个器件在一个机器上加工的时间都不同,会给出一个矩阵,告诉你哪个器件在哪个机器上的耗时。
求最好的顺序。
为什么顺序会影响时间呢?那是因为一个器件的加工,要等自己在前一个机器的加工完成,又要等上一个器件在当前机器的加工完成,这两个等待时间和顺序有关。
对于一种顺序,时间计算是很容易的,我后面也有现成的代码。
初探:邻域如何确定
问题来了,状态转移比较难。人家八皇后可以通过冲突数来确定状态变化,我们通过什么确定呢?或者准确说,我们在什么邻域里搜索呢?
既然是顺序,那么我每次变化就只能变化顺序,必须保证不冲突,就没办法对一个器件进行单独变化。但是可以明确的是,每次变化一定是交换两个工件的顺序,所以如何选定两个工件就是问题。是否存在一种启发性算法能找出合理的工件呢?我们还得从目标上下手。
经过我的一通查找,也看了一些论文,最后发现是有启发性算法的,但是比较麻烦,而且效果也就好那么一丢丢,性价比太低。所以最后的结论就是:不需要使用启发性算法,直接就进行邻域随机搜索。
你可能会怀疑,这和领域有什么关系呢?其实你只交换两个,或者只交换一部分,这已经是就近原则了。真正的全局纯随机,是利用np.random.shuffle函数将顺序彻底打乱,我试过这个方法,十分影响表现,所以不能用。这里也看出了,我们的三种交换策略确实和全局纯随机不一样。

基本函数结构
这里给出导入的包,以及要用的函数。
其中有三种交换策略,基础的使用点交换,论文中还提到了区间颠倒和区间交换,我也都写了,经过测试保证有正确的结果。
# 解流水车间调度问题
# 函数编写
# 读取一个用例
def read():
with open('flowshop-test-10-student.txt') as file_obj:
#with open('one_instance.txt') as file_obj:
line=file_obj.readline()#去除头两行
line=file_obj.readline()
line=file_obj.readline().split()# 获取n,m
n=int(line[0])
m=int(line[1])
data=[]# 逐行读取内容
for i in range(n):
part=file_obj.readline().split()# 将工件数据提取出来
part=[int(x) for x in part]# 类型装换
part=part[1::2]# 切片
data.append(part)
return data
# 时间到温度
def time_to_temp(time):
return 0.99**time*100
# 动态规划计算调度时间,schedule储存顺序
def all_time(data,schedule):
C=np.zeros((len(data),len(data[0])))
C[0][0]=data[schedule[0]][0]
for j in range(1,len(data[0])):# 计算1,m
C[0][j]=C[0][j-1]+data[schedule[0]][j]
for i in range(1,len(data)): # 计算n,1
C[i][0]=C[i-1][0]+data[schedule[i]][0]
for j in range(1,len(data[0])): # 填充
for i in range(1,len(data)):
C[i][j]=max(C[i-1][j],C[i][j-1])+data[schedule[i]][j]
#return C
return C[-1][-1]
# 邻域搜索
def two_exchange(pre_schedule): # 将选定区域中工件顺序颠倒
schedule=pre_schedule[:]
n=len(pre_schedule)
i=np.random.randint(0,n) # [low,high),恰好覆盖所有可能
j=np.random.randint(0,n)
if j<i: # 保持ij大小关系
temp=j
j=i
i=temp
for k in range(j-i+1):# 颠倒区间
schedule[j-k]=pre_schedule[i+k]
return schedule
def three_exchange(pre_schedule): # 交换两段子序列位置
n=len(pre_schedule)
nodes=np.random.randint(0,n,3)
nodes=sorted(nodes)
print(nodes)
schedule=pre_schedule[:nodes[0]] # 两边要边界,中间分给右边
schedule.extend(pre_schedule[nodes[1]:nodes[2]+1])
schedule.extend(pre_schedule[nodes[0]:nodes[1]])
schedule.extend(pre_schedule[nodes[2]+1:])
return schedule
def point_exchange(pre_schedule):# 随机两点交换
schedule=pre_schedule[:]
n=len(schedule)
i=np.random.randint(0,n) # [low,high),恰好覆盖所有可能
j=np.random.randint(0,n)
#print(f"exchange {i},{j}")
t=schedule[i]
schedule[i]=schedule[j]
schedule[j]=t
return schedule
登山搜索框架
用例:
这是一个简单的用例,用的时候保存成txt放在目录下,自己调整一下代码里的文件路径就好,
1
1
11
11^{11}
1111的解空间也还不算特别大,勉强可以遍历,实际后面我们会在50个工件级别的问题中计算,所以趁早死了遍历的心。
instance 0
optimal-result:7038
11 5
0 375 1 12 2 142 3 245 4 412
0 632 1 452 2 758 3 278 4 398
0 12 1 876 2 124 3 534 4 765
0 460 1 542 2 523 3 120 4 499
0 528 1 101 2 789 3 124 4 999
0 796 1 245 2 632 3 375 4 123
0 532 1 230 2 543 3 896 4 452
0 14 1 124 2 214 3 543 4 785
0 257 1 527 2 753 3 210 4 463
0 896 1 896 2 214 3 258 4 259
0 532 1 302 2 501 3 765 4 988
代码:
# 登山搜索
# 编码和初始化
data=read()
print(data)
schedule=list(range(len(data)))# 初始顺序调度
# 循环
t=0
T=time_to_temp(t)
epsilon=0.1 # 阈值温度
min_time=[] # 记录每个变化节点
min_t=[]
min_time.append(all_time(data,schedule))
min_t.append(0)
while T>epsilon:
# 多规则邻域搜索生成新解,协同比较
new_schedule=point_exchange(schedule)
# 判断新解情况,决定新状态
now_time=all_time(data,new_schedule)
if(now_time<min_time[-1]): # 耗时更少
min_time.append(now_time)
min_t.append(t)
schedule=new_schedule
# 更新时间和温度
t=t+1
T=time_to_temp(t)
min_time.append(min_time[-1])
min_t.append(t)
print(f"after {t} epoch",min_time[-1],schedule)
plt.xlabel('迭代次数')
plt.ylabel('调度总时间')
plt.plot(min_t,min_time)
一次结果,优化到7038,有时候会有一点差距,这个和运气有关系:
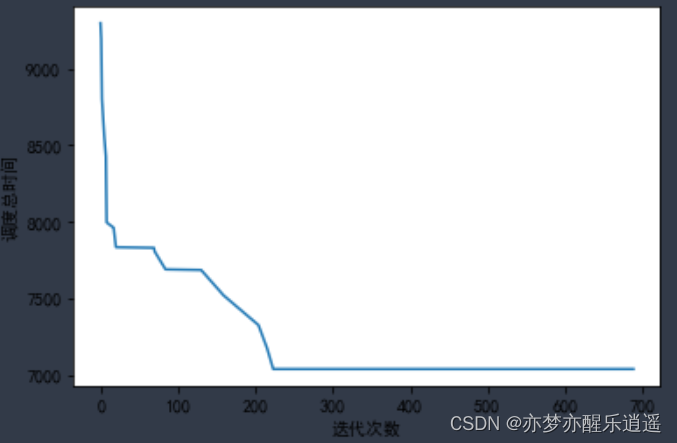
模拟退火框架
数据还是用的上面给出的数据,程序其实也仅仅是在对于新解判断的一步进行改动。
# 模拟退火
# 编码和初始化
data=read()
print(data)
schedule=list(range(len(data)))# 初始顺序调度
# 循环
t=0
T=time_to_temp(t)
epsilon=0.1 # 阈值温度
min_time=[] # 记录每个变化节点
min_t=[]
min_time.append(all_time(data,schedule))
min_t.append(0)
while T>epsilon:
# 多规则邻域搜索生成新解,协同比较
new_schedule=point_exchange(schedule)
# 判断新解情况,决定新状态
now_time=all_time(data,new_schedule)
if(now_time<min_time[-1]): # 耗时更少
min_time.append(now_time)
min_t.append(t)
schedule=new_schedule
else: # 概率接受更差结果
P=np.exp((min_time[-1]-now_time)/T)
if np.random.rand()<P: # 接受差结果
min_time.append(now_time)
min_t.append(t)
schedule=new_schedule
# 更新时间和温度
t=t+1
T=time_to_temp(t)
min_time.append(min_time[-1])
min_t.append(t)
print(f"after {t} epoch",min_time[-1],schedule)
plt.xlabel('迭代次数')
plt.ylabel('调度总时间')
plt.plot(min_t,min_time)
跑出来的图大概是这样,可以看到波动还是比较大的,但是最后可以达到更好的效果。
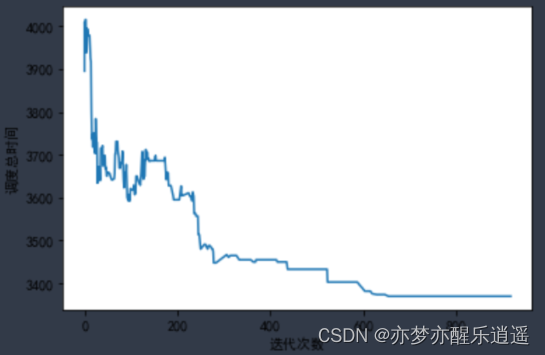
完全版本项目文件
项目包含加强版源代码,数据集,实验结果图,以及我写的论文 。
百度云
提取码:cyyy
上面给出的俩程序都很简单,实际上我们还可以通过一些技巧,提高5%左右的表现。我自己就是从3500优化到了3280的,基本上优化了 220 3250 = 6.8 % \dfrac{220}{3250}=6.8\% 3250220=6.8%,这么一看还是挺可观的。
具体的改进:
- 程序架构。其实有11组数据,所以要用新的read函数,一次性读取出11个矩阵,然后遍历逐个处理。
- 10组随机重启搜索。每个测试用例都要进行10次随机重启搜索,互不干扰
- 增加记忆机制,选择最好的组作为结果。这样可以降低结果对出生点的依赖。
- 实现三种邻域搜索,每次搜索都要从当前状态进行三种搜索,选择其中最好的结果,再进行判断是否保留。
- 图像绘制。采用1000dpi的清晰度,记录每个优化点的时间与结果,将10组都画在一张图里。最后保存到目录里,用于论文撰写。
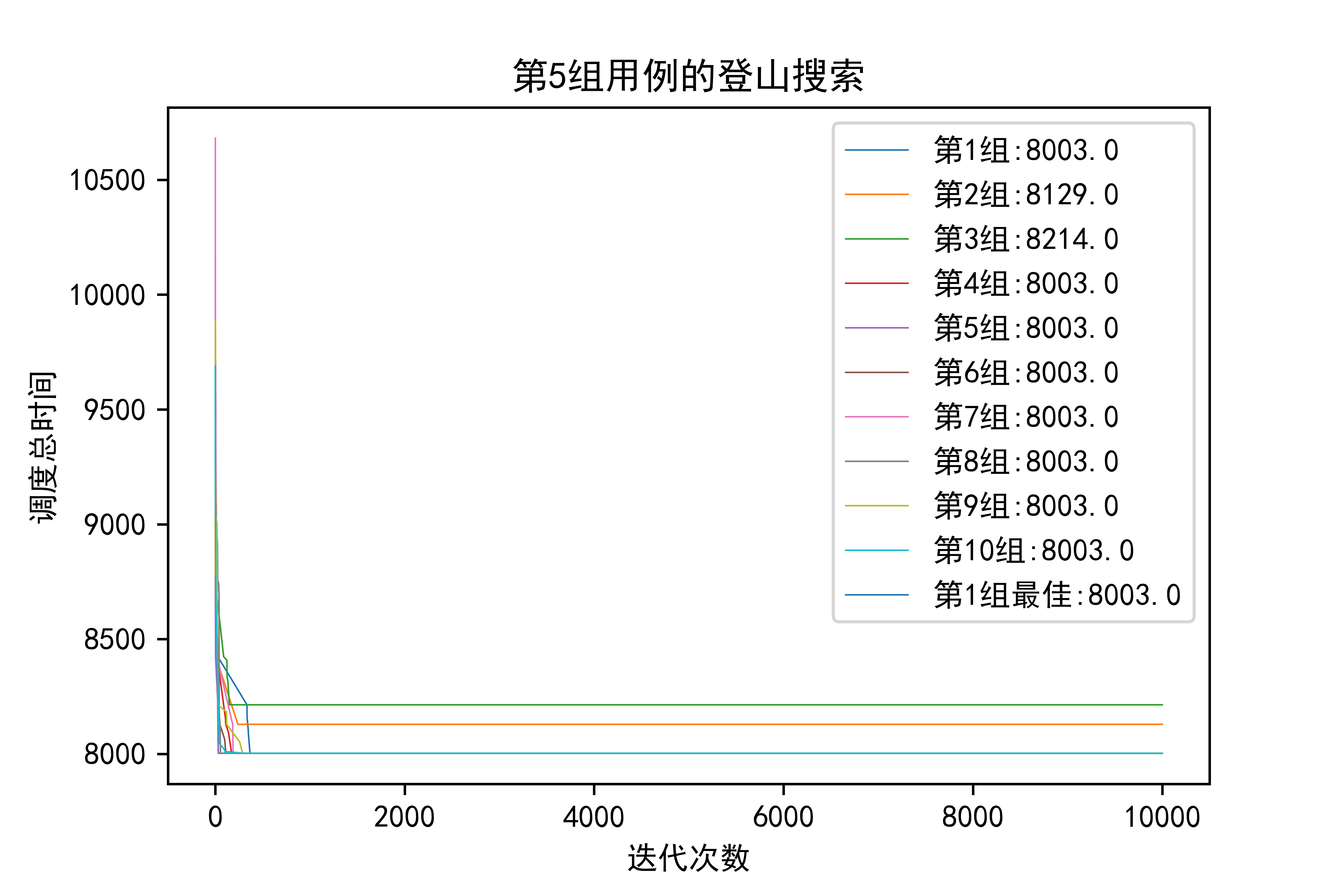
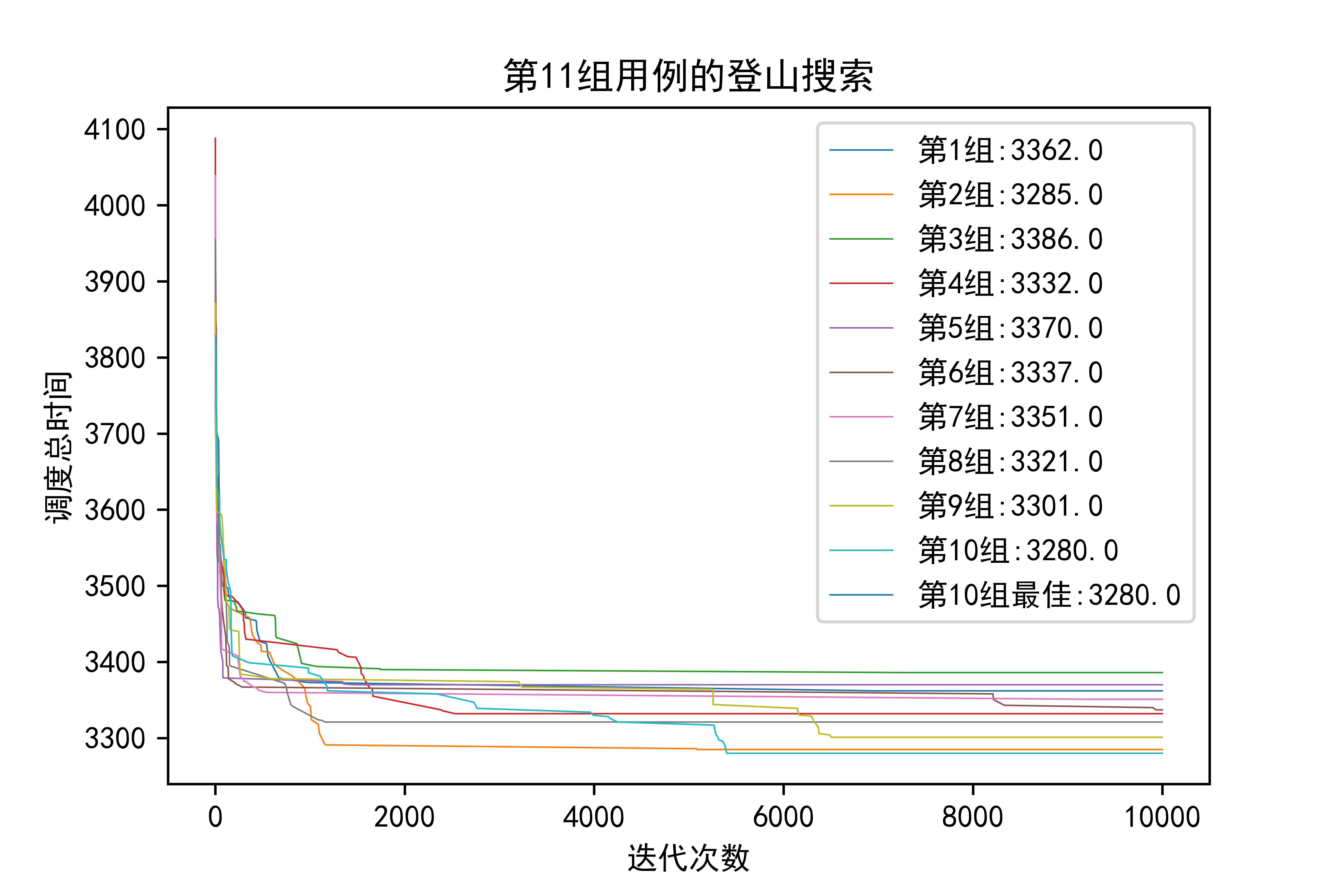
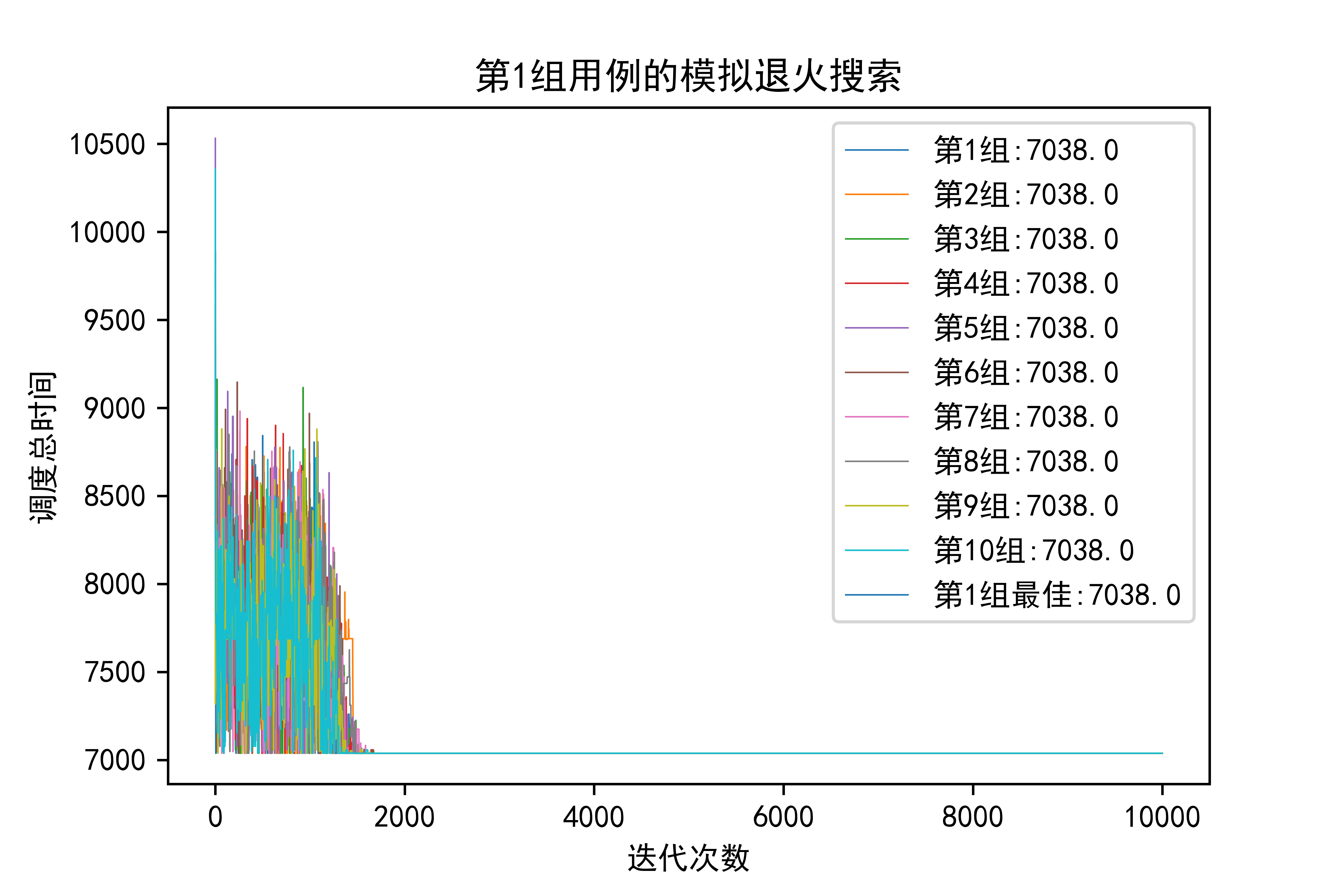
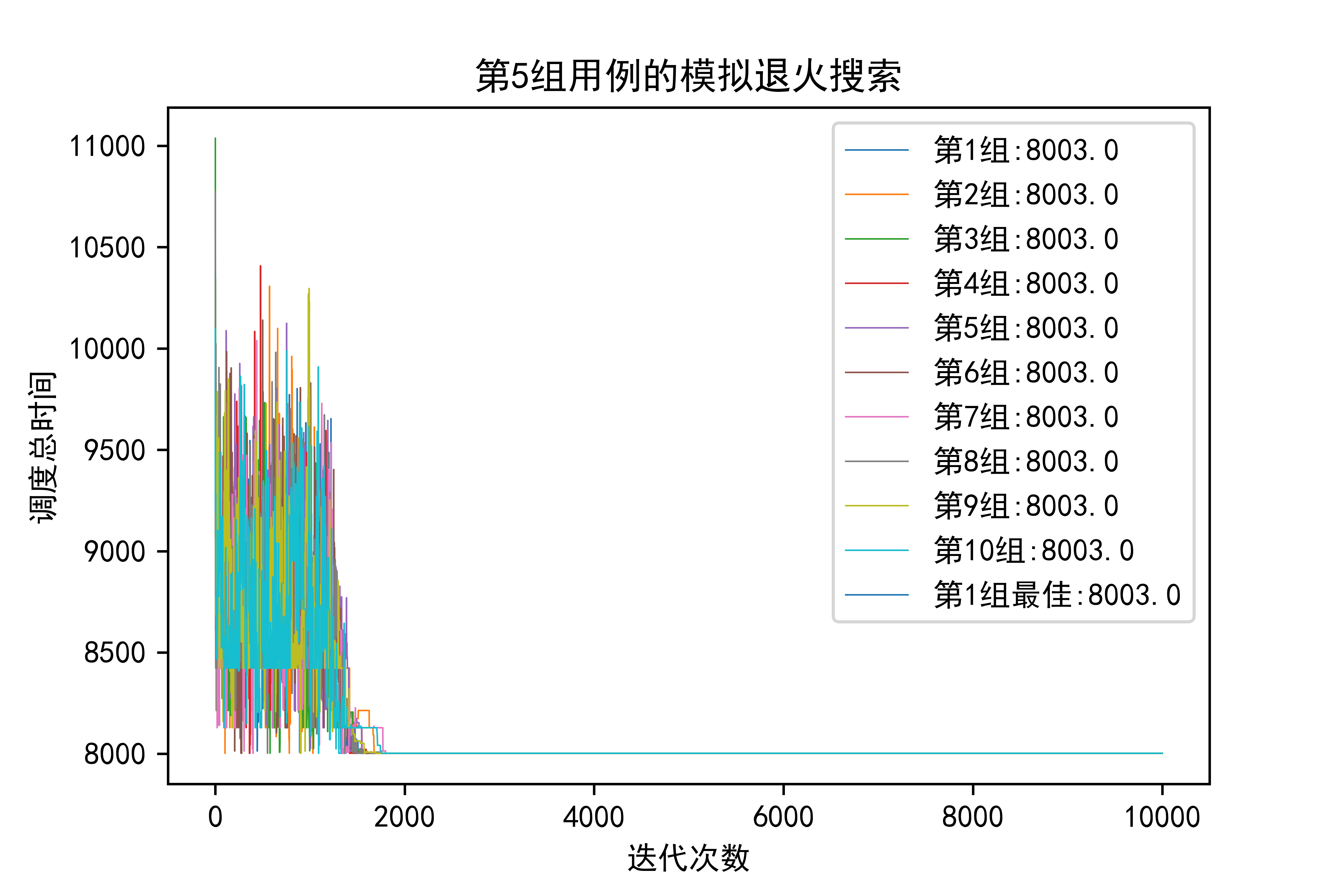
看看我最后的成果,从图中可以看出:
- 小规模问题上,登山搜索和模拟退火不会有太大差异
- 但是稍微上升到50个工件的规模,模拟退火就逐渐体现出优势,登山搜索10组才出来一个3280级别的,而模拟退火一眼看过去全是3280级别的,有理由认为登山搜索那个3280是偶然,也就是随机重启带来的好处,而模拟退火即使是只跑一组实验,结果也很稳定
- 如果上升到100工件,在结果上模拟退火应该是会更优的。


















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











